はじめに
学部生向けの機械学習体験として、scikit-learnを用いた気温予想プログラムを作成した。
また、とっつきやすさを重視して、エディタはGoogleColabを使用し、グラフで視覚化を図り理解しやすいシンプルな構成にした。
環境
言語:Python
エディタ:Google Colab
データの用意
気象庁 過去の気象データ・ダウンロードからダウンロードする。
日平均気温で10年分をダウンロードし、オプションは画像参照。

データのインポート
データは各自で事前ダウンロードするのが好ましいが、今回はGoogleDriveの共有ドライブに用意しているものをインポートして使用した。
任意のファイルはxxx.csvとしており、実行結果等はSapporo.csvを使用した。
# GoogleDriveをマウント
from google.colab import drive
drive.mount('/content/gdrive')
Mounted at /content/gdrive
上記表示が出力されればマウントは完了。
# 共有ドライブの温度データ保管しているディレクトリを指定してパスを通す
Temp_data = '/content/gdrive/Shareddrives/xxx/Temp'
GoogleDriveの共有設定を管理者に設定しなければエラーが出るため注意。
#ディレクトリの内容確認
!ls $Temp_data
Abashiri.csv Kobe.csv Nagoya.csv Osaka.csv Tokyo.csv
Fukuoka.csv Kumagaya.csv Naha.csv Sapporo.csv
今回は9個のファイルを準備した。
いずれも名前を変更しただけで気象庁からダウンロードしたままのデータ形式である。
#任意のファイルをコピー
!cp $Temp_data/xxx.csv .
データの用意は以上で完了。
データの下ごしらえ
気象庁からダウンロードしてきたデータは品質情報や均質番号が含まれる。
これらは今回の処理には不要なため事前に取り除いておく。
また、年月日についても扱いやすいように加工する。
# 数値計算ライブラリのインポート
import pandas as pd
# ファイルパス
file_path = 'xxx.csv'
# CSVファイルを読み込む
df = pd.read_csv(file_path, sep=",", encoding="SHIFT-JIS", skiprows=3)
# 列名の余分な空白を削除
df.columns = df.columns.str.strip()
# 不要な列を削除
df = df.drop(columns=['平均気温(℃).1', '平均気温(℃).2'])
# データフレームの内容を確認
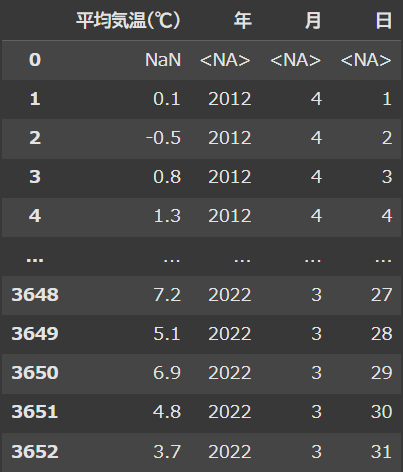
print(df.head())
年月日 平均気温(℃)
0 NaN NaN
1 2012/4/1 0.1
2 2012/4/2 -0.5
3 2012/4/3 0.8
4 2012/4/4 1.3
ここまでで品質情報や不要なヘッダーは取り除くことが出来た。
確認してみよう。
#書式確認
print(df.columns)
Index(['年月日', '平均気温(℃)'], dtype='object')
このように表示されれば問題ない。
ちなみに品質情報などが残っている場合以下のようになる。
Index(['年月日', '平均気温(℃)', '平均気温(℃).1', '平均気温(℃).2'], dtype='object')
最後に年月日を加工する。
#使いやすいように修正
df["年月日"] = pd.to_datetime(df["年月日"])
df["年"] = df["年月日"].dt.year.astype("Int64")
df["月"] = df["年月日"].dt.month.astype("Int64")
df["日"] = df["年月日"].dt.day.astype("Int64")
df = df.drop(["年月日"], axis =1)
df
以下のように表示されれば問題ない。
データの理解
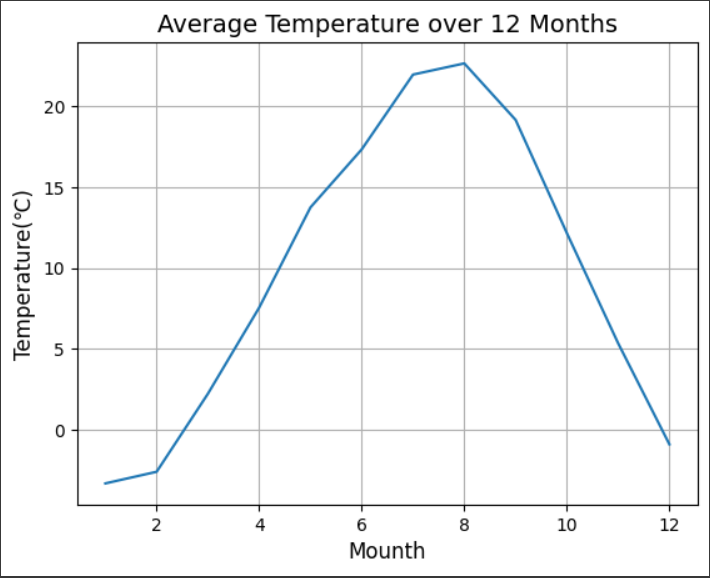
ここでは使用するデータがどのようなものか理解するためにグラフ化していく。
最初に月別平均気温をグラフ化する。
#グラフ化ライブラリのインポート
import matplotlib.pyplot as plt
#月平均気温の算出
df_month_mean = df.groupby(["月"])["平均気温(℃)"].mean()
#インデックスと値取得
df_month_mean_index =df_month_mean.index
df_month_mean = df_month_mean.values
#グラフ作成と書式
plt.plot(df_month_mean_index, df_month_mean)
plt.title("Average Temperature over 12 Months", fontsize=14)
plt.xlabel("Mounth", fontsize=12)
plt.ylabel("Temperature(℃)", fontsize=12)
plt.grid(True)
plt.show()
次に日別平均気温が25℃を超える日数をグラフ化して確認する。
#平均気温が25℃以上判定
hot_date_bool = (df["平均気温(℃)"] > 25 )
#抽出
hot_date_count = df[hot_date_bool]
#年ごとのカウント
hot_date_count_group = hot_date_count.groupby(["年"])["年"].count()
#年と日数の取得
df_year_count_index = hot_date_count_group.index
df_year_count = hot_date_count_group.values
#グラフ作成と書式
plt.plot(df_year_count_index, df_year_count)
plt.title("Annual Trend of Days Above 25℃", fontsize=14)
plt.xlabel("Year", fontsize=12)
plt.ylabel("Days", fontsize=12)
plt.grid(True)
plt.show()

データセットの用意
#numpyをインポート
import numpy as np
#データセット生成(ここでリスト化して処理をしやすくしてる)
def data_set(data):
x = []
y = []
temps = list(data["平均気温(℃)"])
#ループでデータ生成
for i in range(len(temps)):
if i < interval : continue
y.append(temps[i])
#特徴量作成(気温)
xa =[]
for j in range(interval):
k = i + j - interval
xa.append(temps[k])
x.append(xa)
return(x, y)
#教育用データとテストデータ振り分け(train_year->2022年以前を教育用。test_year->2022年以降をテストデータ。)
train_year = (df["年"] <= 2022)
test_year = (df["年"] > 2022)
#過去7日分のデータを使用
interval = 7
#教育用データとテストデータの生成
x_train,y_train = data_set(df[train_year])
x_test, y_test = data_set(df[train_year])
ここでは機械学習のデータセットを作成している。
xに特徴量、yに目的変数を入れ込んでいる。
目的変数とはモデルが予測または説明しようとする値のことであり、機械学習において、「答え」や「ゴール」となるデータを表す。今回の場合は気温である。
特徴量とは目的変数を予測するために使う情報であり、何に基づいて予測を行うかを表す。今回の場合は過去7日間の気温データである。
モデル作成と評価
用意したデータセットを使ってモデルを走らせてみる。
今回はScikit-learnのLinearRegressionを使用する。
LinearRegressionは線形回帰モデルで、特徴量と目的変数間の線形関係をモデル化する。
#Scikit-learnのLinearRegressionをインポート
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(x_train, y_train)
#予測値計算
y_pred = model.predict(x_test)
#テストデータをnumpy配列に変換
y_test =np.array(y_test)
#グラフ作成と書式
plt.figure(figsize=(10, 6), dpi=100)
plt.title("Temperature Prediction vs Actual", fontsize=14)
plt.xlabel("Days", fontsize=12)
plt.ylabel("Temperature (°C)", fontsize=12)
plt.grid(True)
plt.plot(y_test, c="y", label="Actual")
plt.plot(y_pred, c="b", label="Predicted")
plt.legend()
plt.show()

黄色で示されるのが実際の温度で、青色で示されるのが予測温度である。
つまり、黄色が見えている部分は予測が外れた値である。
最後に誤差がどれくらいあるのか数値で確認する。
#誤差計算モジュールのインポート
from sklearn.metrics import mean_absolute_error, mean_squared_error
#誤差の計算
y_diff = abs(y_pred - y_test)
mae = mean_absolute_error(y_test, y_pred)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
#最大誤差
print("Max = ", max(y_diff))
#平均絶対誤差(実際の値と予測値の間の絶対誤差の平均を計算。小さいほうが正確。)
print(f"Mean Absolute Error (MAE): {mae:.2f}°C")
#二乗平均平方根誤差(実際の値と予測値の差を2乗し、それを平均したもの。小さいほうが正確。)
print(f"Root Mean Squared Error (RMSE): {rmse:.2f}°C")
Max = 8.724579020747216
Mean Absolute Error (MAE): 1.58°C
Root Mean Squared Error (RMSE): 2.07°C
最後に
降雪地域や暑いことで有名な地域については最大誤差が大きくなりやすいようです(n=9)。
このプログラムを使って機械学習を体験しつつ、気象データの解析などにチャレンジしてみてください。
参考文献
福岡人データサイエンティストの部屋 -【LinearRegression】気温の予測【Python】
@TanakaSU(田中 遥輝)- 気温予想AIを作ってみる