飲食店情報検索システム 設計書(学習用)
🎓 学習目的のご注意
本設計書は、実際の本番運用を目的としたものではなく、若手エンジニアの学習を促進するための教材として作成されています。実際のプロジェクトでは、様々な制約条件やビジネス要件、法的要件などを考慮する必要があります。この設計書を通して、システム設計の基本的な考え方や技術選定の理由、実装のポイントを学んでいただくことを目的としています。
1. はじめに
📚 この章で学ぶこと
- 設計書の目的と対象読者について
- プロジェクトの背景と目的
- システムの全体像を把握する
🔑 重要な概念
- システム設計のゴールを明確にする
- ユーザーニーズを理解する
- システムの主要コンポーネントの概要を掴む
1.1 ドキュメントの目的
本ドキュメントは、飲食店情報検索システムの詳細な設計を記述するものです。
このドキュメントは、開発者(特に若手エンジニア)が理解しやすいよう工夫されており、システムの全体像から各コンポーネントの詳細までを説明しています。
学習目的として、システム設計のプロセスや考え方、技術選定の理由なども含め、実際の開発プロジェクトで役立つ知識を提供することを目指しています。
1.2 対象読者
- 開発チームメンバー(特に若手エンジニア)
- プログラミングの基礎知識はあるが、システム設計の経験が浅いエンジニア
- Web開発やデータ処理に興味のあるエンジニア
- プロジェクト管理者や技術リーダー
1.3 背景と目的
現在、飲食店情報は複数のウェブサイトに分散しており、ユーザーが総合的な情報を得るためには複数のサイトを閲覧する必要があります。
本システムは、これらの情報源からデータを自動的に収集し、統合された検索機能を提供することで、ユーザーの利便性を高めることを目的としています。
💡 学習ポイント
実際のプロジェクトでは、ビジネス要件を明確にすることが非常に重要です。なぜそのシステムが必要なのか、どのような問題を解決するのかを理解することで、適切な設計ができるようになります。
1.4 システム概要
本システムは以下の主要コンポーネントから構成されます:
-
データ収集バッチ:複数の情報源から飲食店データを自動的に収集するコンポーネント
- 学習レベル:中級 - API統合やデータ抽出の基本を理解している方向け
-
データストレージ:収集したデータを保存・検索するためのデータベース
- 学習レベル:基本〜中級 - RDBMSの基礎知識があれば理解可能
-
検索API:クライアントアプリケーションに検索機能を提供するAPIインターフェース
- 学習レベル:基本〜中級 - RESTful APIの基本を理解している方向け
-
モニタリング・管理機能:システムの状態監視と運用管理を行うコンポーネント
- 学習レベル:中級〜上級 - システム運用の知識がある方向け
📝 若手エンジニア向けメモ
システムは大きく分けると、「データを集める部分」「データを保存する部分」「データを提供する部分」「システムを監視する部分」の4つに分かれています。各部分の役割と相互関係を理解することが、システム設計の第一歩です。わからない用語があれば、用語集を参照してください。
1.5 学習のためのチェックポイント
- システムの目的と解決する問題を説明できる
- 4つの主要コンポーネントとその役割を説明できる
- なぜ複数の情報源からデータを収集する必要があるか理解している
- 各コンポーネントの学習レベルを確認し、自分の現在の知識レベルと比較できた
第2章:システムアーキテクチャ
📚 この章で学ぶこと
- システム全体の構成と各コンポーネントの関係
- 現代的なアーキテクチャパターンと選定基準
- 選定した技術スタックの概要
- データがシステム内をどのように流れるか
🔑 重要な概念
- アーキテクチャの分割方法
- クリーンアーキテクチャの原則
- 技術選定の考え方
- コンポーネント間の連携方法
2.1 アーキテクチャ概要
本システムは、バッチ処理とAPIサービスの2つの主要なサブシステムに分かれています。
バッチ処理はデータの収集と加工を担当し、APIサービスはクライアントからの検索リクエストを処理します。
データはリレーショナルデータベース(PostgreSQL)と検索に最適化されたNoSQLデータベース(Elasticsearch)の両方に保存されます。
💡 学習ポイント
多くのシステムでは、このように「データを収集・処理する部分」と「データを提供する部分」に分けて設計します。これにより、それぞれが独立して開発・運用できるようになります。
2.1.1 クリーンアーキテクチャの適用
本システムでは、ロバート・C・マーティンによって提唱されたクリーンアーキテクチャの原則を採用しています。これにより、ビジネスロジックを技術的な実装詳細から分離し、テスト容易性と保守性を向上させています。
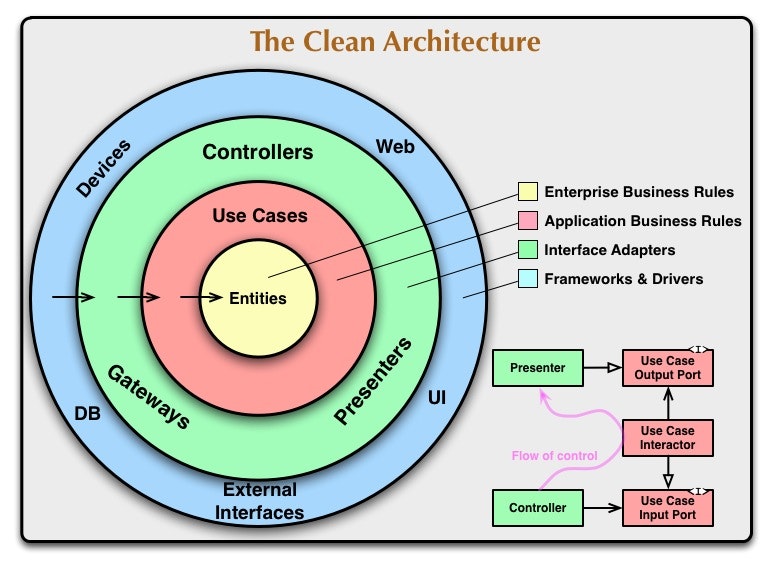
クリーンアーキテクチャの主な特徴:
- 依存関係の方向:内側の層は外側の層を知らない(依存しない)
- 関心の分離:各層は特定の責務を持つ
- ビジネスルールの独立性:ビジネスロジックはフレームワークやUIから独立している
クリーンアーキテクチャの各層:
- エンティティ層:ビジネスの中核となるオブジェクトとルール
- ユースケース層:アプリケーション固有のビジネスルール
- インターフェースアダプター層:外部インターフェースとの連携
- フレームワーク・ドライバー層:データベース、UI、外部APIなどの技術的詳細
📝 若手エンジニア向けメモ
クリーンアーキテクチャは最初は複雑に感じるかもしれませんが、「依存関係は内側に向ける」という基本原則を覚えておくと理解しやすくなります。ビジネスロジックを中心に据え、そこから外側の技術的な詳細に向かって依存するようにします。
2.2 技術スタック
以下の表は、本システムで使用する主な技術とその選定理由の概要です。詳細な説明は6. 技術選定とその理由で行います。
| コンポーネント | 技術要素 | 選定理由(概要) | 若手エンジニア向け学習難易度 |
|---|---|---|---|
| プログラミング言語 | Python 3.10+ | 豊富なライブラリ、開発効率の高さ | ★★☆☆☆(比較的習得しやすい) |
| データ収集 | 各種Web API、データインポートツール | 公式APIを活用、安定性の確保 | ★★★☆☆(API認証やエラー処理の知識が必要) |
| データベース (一次保存) | PostgreSQL 14 | オープンソース、堅牢性、地理空間データ対応 | ★★★☆☆(SQL基礎知識が必要) |
| データベース (検索用) | Elasticsearch 8 | 全文検索、高速クエリ、スケーラビリティ | ★★★★☆(概念理解が必要) |
| API | FastAPI | 高性能、自動ドキュメント生成、非同期サポート | ★★☆☆☆(Pythonに慣れていれば習得しやすい) |
| キャッシュ | Redis | 高速インメモリキャッシュ、TTL管理の容易さ | ★★★☆☆(概念理解が必要) |
| 監視・ロギング | Prometheus, Grafana, ELK Stack | 業界標準、豊富な可視化オプション | ★★★★☆(設定やデータ分析の知識が必要) |
| インフラ | Docker, Kubernetes | コンテナ化、スケーラビリティ、環境一貫性 | ★★★☆☆(基礎概念の理解が必要) |
| CI/CD | GitHub Actions, Jenkins | 自動テスト、継続的デプロイメント | ★★★☆☆(パイプライン構築の知識が必要) |
📝 若手エンジニア向けメモ
全ての技術を最初から完璧に理解する必要はありません。「Python + FastAPI + PostgreSQL」の基本的な組み合わせから始めて、徐々に他の技術も学んでいくことをお勧めします。
2.3 システム全体構成図
以下はシステム全体の構成図です。各コンポーネントの役割と関係性を示しています。
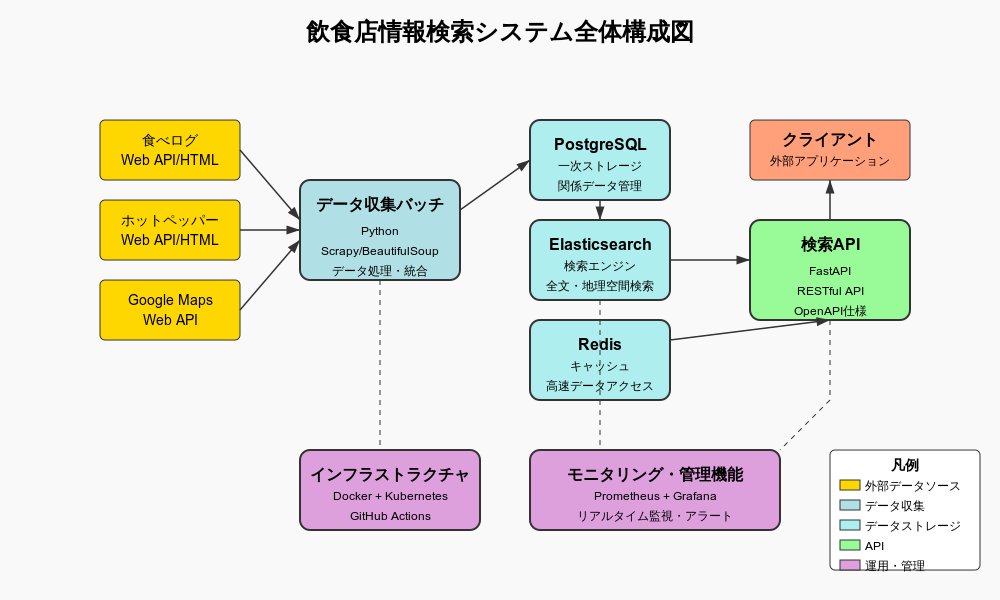
📋 図の補足説明
- データ収集バッチ:外部データソースからデータを定期的に収集します(左側)
- PostgreSQL:収集したデータの一次保存場所です(中央下)
- Elasticsearch:検索用にデータを最適化して保存します(中央下)
- FastAPI:クライアントからのリクエストを処理するAPIを提供します(中央)
- Redis:頻繁にアクセスされるデータをキャッシュします(中央)
- クライアント:システムを利用するユーザーインターフェースです(右側)
- 監視・管理:システム全体の状態を監視します(下部)
2.3.1 マイクロサービスvsモノリス
本システムでは、初期段階ではモノリシックなアーキテクチャを採用し、将来的にマイクロサービスへの移行を視野に入れた設計とします。この判断の理由は以下の通りです:
モノリシック構造の利点(初期段階):
- 開発の迅速性(サービス間通信の複雑さがない)
- デプロイとテストの単純さ
- チーム規模が小さい場合の適合性
- 全体の一貫性が保ちやすい
将来的なマイクロサービス化の方針:
- データ収集サービス(外部ソースとの連携)
- 検索APIサービス(ユーザー向けインターフェース)
- レコメンデーションサービス(パーソナライズ機能)
- ユーザー管理サービス(認証・認可)
💡 学習ポイント
アーキテクチャ選択は「トレードオフ」の問題です。マイクロサービスは柔軟性やスケーラビリティに優れていますが、運用の複雑さやオーバーヘッドも増加します。プロジェクトの規模、チーム構成、将来的な拡張性などを考慮して、適切なアーキテクチャを選択することが重要です。
2.4 システムコンポーネント詳細
2.4.1 データ収集バッチ
データ収集バッチは以下のサブコンポーネントで構成されます:
-
データソースモジュール:
- 各情報源に対応したデータ収集モジュール
- 共通の抽象クラス(DataSourceBase)を継承した実装
- 設定ファイルベースのデータソース定義
💡 学習ポイント
「抽象クラス」とは、共通の機能や構造を定義するための基本クラスです。これを継承することで、各データソース固有の実装が同じインターフェイスを持つようになり、コードの一貫性と再利用性が高まります。 -
バッチコア:
- スケジューラ:収集ジョブの実行スケジュールを管理
- ジョブマネージャ:実行中のジョブを管理し、状態を監視
- データプロセッサ:収集したデータの正規化と統合
-
データ取得ユーティリティ:
- API接続管理:APIキーと認証の管理
- スロットリング制御:API呼び出し頻度の最適化
- エラーハンドリング:一時的なエラーのリトライ処理
📝 若手エンジニア向けメモ
APIを利用する際は、各サービスの利用制限を遵守することが重要です。「リクエスト制御」はそのための仕組みで、一定時間に送るリクエスト数を制限します。また「リトライハンドラ」は一時的なエラーが発生した場合に自動的に再試行する仕組みです。
2.4.2 データストレージ
データストレージは以下のサブコンポーネントで構成されます:
-
一次ストレージ(PostgreSQL):
- 正規化されたデータモデル
- トランザクション整合性の確保
- 店舗、レビュー、施設情報などのリレーショナルデータ
💡 学習ポイント
「正規化」とは、データの重複を減らし、整合性を保つためにデータを整理する技術です。例えば、店舗と住所を別々のテーブルに分けることで、同じ住所を持つ複数の店舗があっても住所データが重複しないようにします。 -
検索用ストレージ(Elasticsearch):
- 全文検索に最適化されたインデックス
- 地理空間検索のためのgeoポイントデータ
- 複合クエリの高速処理
📝 若手エンジニア向けメモ
ElasticsearchはSQLデータベースとは異なり、「ドキュメント指向」のデータベースです。JSONのような形式でデータを保存し、複雑な検索条件や全文検索に強みがあります。 -
データ統合:
- 重複検出器:同一店舗の特定と統合
- データ正規化:住所、電話番号などのフォーマット統一
- データマイグレーター:PostgreSQLからElasticsearchへのデータ同期
-
キャッシュレイヤー(Redis):
- 人気検索クエリの結果キャッシュ
- セッション情報の一時保存
- レート制限の実装
💡 学習ポイント
「キャッシュ」とは、頻繁にアクセスされるデータを高速なストレージに一時的に保存する仕組みです。これにより、同じデータを何度も計算したり、データベースから取得したりする手間を省き、システム全体のパフォーマンスを向上させます。
2.4.3 検索API
検索APIは以下のサブコンポーネントで構成されます:
-
APIレイヤー:
- RESTコントローラ:HTTPリクエスト/レスポンスの処理
- 入力バリデーター:リクエストの検証
- レスポンスフォーマッター:JSONレスポンスの構築
📝 若手エンジニア向けメモ
「REST」とは、WebAPIの設計スタイルの一つで、URLとHTTPメソッド(GET/POST/PUT/DELETEなど)を使ってリソースを操作する方式です。例えば、GET /restaurants/123は店舗ID 123の情報を取得する操作を表します。 -
ビジネスロジック:
- 検索サービス:主要な検索ロジックの実装
- クエリビルダー:検索条件の構築
- フィルターサービス:検索結果のフィルタリング
-
データアクセス:
- Elasticsearch DAO:検索用データへのアクセス
- PostgreSQL DAO:詳細データの取得
- キャッシュマネージャ:キャッシュの管理
💡 学習ポイント
「DAO(Data Access Object)」とは、データベースへのアクセスを担当するオブジェクトです。これにより、ビジネスロジックとデータアクセスの責務を分離し、コードの保守性を高めることができます。
2.4.4 モニタリング・管理機能
モニタリング・管理機能は以下のサブコンポーネントで構成されます:
-
ロギングシステム:
- ログコレクター:各コンポーネントからのログ収集
- ログ分析:ログの集計と分析
-
メトリクスシステム:
- メトリクスコレクター:システム指標の収集
- ダッシュボード:リアルタイムな状態可視化
📝 若手エンジニア向けメモ
「メトリクス」とは、システムの状態を数値化した指標のことです。例えば、「1分あたりのリクエスト数」「平均応答時間」「エラー率」などがあります。これらを監視することで、システムの健全性を確認できます。 -
アラートシステム:
- アラートルール:異常検知のためのルール定義
- 通知サービス:管理者への通知
-
管理UI:
- システム状態:システム全体の状態確認
- ジョブ制御:バッチジョブの管理
- 設定管理:システム設定の変更
2.5 データフロー
データがシステム内でどのように流れるかを説明します。
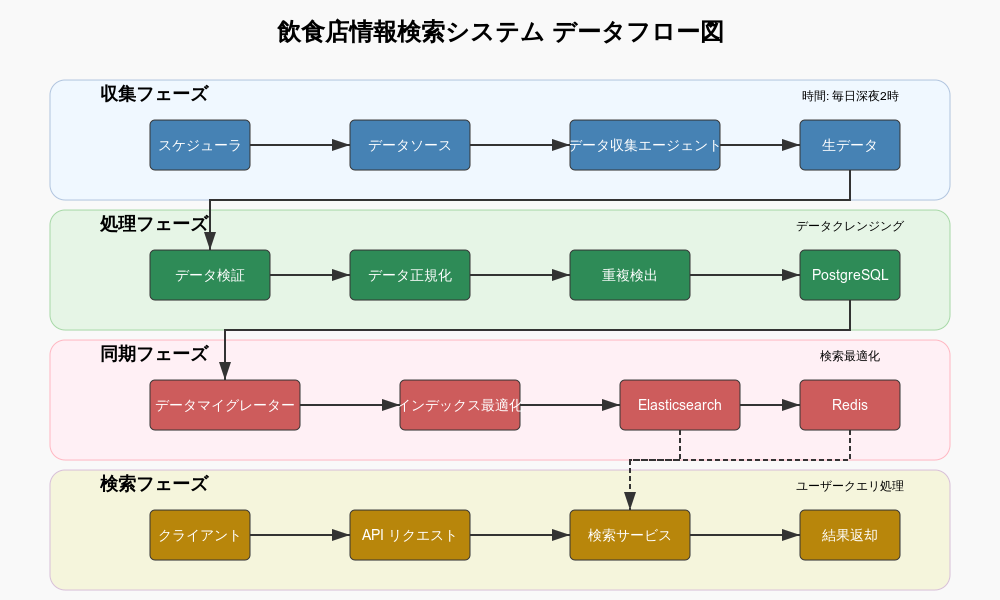
(注: 実際の画像はプロジェクトに合わせて作成してください)
-
収集フェーズ:
- スケジューラがジョブを開始
- 各データソースからデータを収集
- 収集したデータをデータプロセッサに送信
💡 学習ポイント
バッチ処理は定期的に(例:毎日深夜)実行され、最新のデータを収集します。公式APIがある場合はそれを利用し、効率的にデータを取得します。 -
処理フェーズ:
- データプロセッサがデータを検証、正規化
- 重複検出器が同一店舗を特定
- 正規化されたデータを一次ストレージに保存
📝 若手エンジニア向けメモ
同じ店舗が異なるソースに掲載されている場合があります。「重複検出」では、店名や住所、電話番号などから同一店舗を特定し、情報を統合します。 -
同期フェーズ:
- データマイグレーターが一次ストレージから検索用ストレージにデータを同期
- インデックスの最適化と更新
💡 学習ポイント
PostgreSQLとElasticsearchで同じデータを保持しますが、形式は異なります。PostgreSQLは関係性を重視し、Elasticsearchは検索速度を重視した形式です。 -
検索フェーズ:
- クライアントからの検索リクエストをAPIが受信
- 検索サービスがクエリを構築
- Elasticsearchで検索を実行
- 結果をフォーマットしてクライアントに返却
📝 若手エンジニア向けメモ
検索リクエストは、まずRedisキャッシュをチェックし、キャッシュにない場合はElasticsearchで検索を行います。これにより、同じ検索が繰り返された場合の応答速度が向上します。
2.6 API設計アプローチ
2.6.1 APIファーストアプローチ
本システムはAPIファーストアプローチを採用しています。これは、実装の前にAPI設計を行い、それを中心に開発を進める方法です。
APIファーストの利点:
- フロントエンドとバックエンドの並行開発が可能
- API仕様書がコントラクトとなり、チーム間の認識齟齬を減少
- モックサーバーを使った早期テストが可能
- クライアント開発者にとって予測可能なインターフェース
採用ツール:
- OpenAPI (Swagger) 仕様によるAPI定義
- FastAPIによる自動ドキュメント生成とバリデーション
💡 学習ポイント
APIファーストアプローチでは、「何をどのように提供するか」を先に決めることで、開発の方向性が明確になります。また、API仕様はチーム間のコミュニケーションツールとしても機能します。
2.6.2 RESTful APIデザイン原則
APIはRESTful原則に従って設計されています:
-
リソース指向:
- URLはリソース(名詞)を表す(例:
/restaurants) - HTTPメソッドで操作を表現(GET:取得、POST:作成など)
- URLはリソース(名詞)を表す(例:
-
階層構造:
- リソース間の関係をURLで表現(例:
/restaurants/{id}/reviews)
- リソース間の関係をURLで表現(例:
-
ステートレス:
- リクエスト間で状態を保持しない
- 必要な情報は全てリクエストに含める
-
統一インターフェース:
- 一貫したリソース識別子(URL)
- 適切なHTTPステータスコード
- HAL+JSONによるハイパーメディア
2.7 若手エンジニア向け解説:システム設計のポイント
システム設計を行う際の重要なポイントをいくつか紹介します:
-
責務の分離:
- 各コンポーネントは明確な役割を持ち、その責務に集中するべきです
- 例:データ収集バッチはデータの収集と加工に専念し、検索機能は持ちません
-
疎結合と高凝集:
- コンポーネント間は疎結合(依存関係が少ない)であるべき
- 各コンポーネント内は高凝集(関連する機能が集まっている)であるべき
- これにより、変更の影響範囲を限定し、保守性を高めることができます
-
段階的な設計と実装:
- 全ての機能を一度に実装するのではなく、核となる機能から段階的に実装
- 例:まず基本的な検索機能を実装し、その後フィルタリングやソート機能を追加
-
柔軟性と拡張性:
- 将来の要件変更や機能追加に対応できる柔軟な設計を心がける
- 例:新しいデータソースの追加が容易な設計にする
-
アーキテクチャ決定記録(ADR)の活用:
- 重要な設計決定とその理由を文書化する
- 後から「なぜこの技術/アプローチを選んだのか」が分かるようにする
🔍 チェックポイント
- システムの主要コンポーネントとその役割を説明できる
- データがシステム内をどのように流れるか理解している
- 各コンポーネント間の関係性を説明できる
- システム設計の基本的なポイントを理解している
- クリーンアーキテクチャの基本原則を説明できる
第3章:クラス設計
📚 この章で学ぶこと
- オブジェクト指向設計の基本と適用方法
- 設計パターンの実践的な活用
- クラス図の読み方と活用方法
- データ収集と検索APIの主要クラスの設計
🔑 重要な概念
- クラスの責務とカプセル化
- 継承と抽象クラスの活用
- インターフェースと実装の分離
- デザインパターンの適用
3.1 データ収集バッチのクラス図
以下はデータ収集バッチの主要クラスを示すクラス図です。
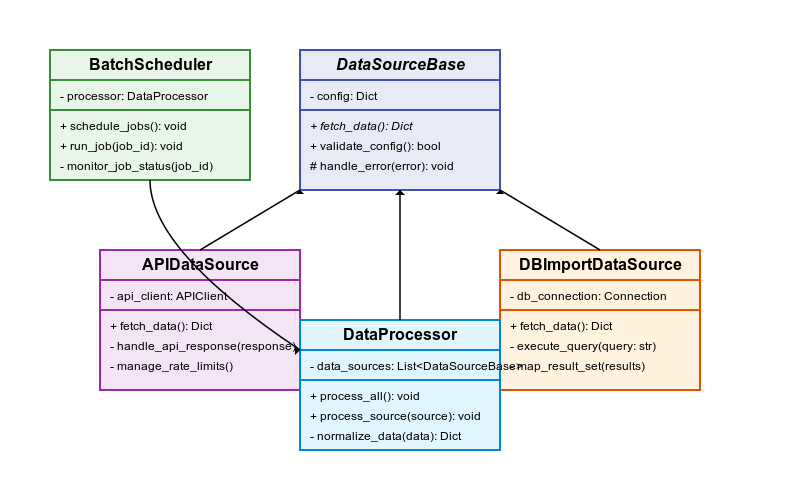
📋 クラス図の読み方
- 各ボックスは1つのクラスを表しています
- 上部にクラス名、中部に属性(変数)、下部に**操作(メソッド)**が記載されています
- 線は関係性を表し、矢印は継承や参照の方向を示しています
- 実線の矢印は「継承」、点線の矢印は「実装」または「依存」を表します
3.1.1 主要クラスの説明
DataSourceBase(抽象基底クラス)
- すべてのデータソース実装の基底クラス
- 抽象メソッド
fetch_data()を定義 - 共通の設定とエラーハンドリングを実装
APIDataSource
- API経由でデータを取得するデータソースの実装
- 認証やレート制限の管理を担当
- サブクラスでさらに特化した実装を提供
DBImportDataSource
- データベースインポート用のデータソース
- 外部データベースからのデータ取得機能
- トランザクション管理と整合性確保の仕組み
DataProcessor
- 収集したデータの処理と変換を担当
- データのクレンジングと正規化を実施
- 重複検出と統合のロジックを実装
BatchScheduler
- バッチジョブのスケジューリングを管理
- 各ジョブの依存関係とスケジュールを定義
- ジョブの実行状態を監視
3.2 検索APIのクラス図
以下は検索APIの主要クラスを示すクラス図です。
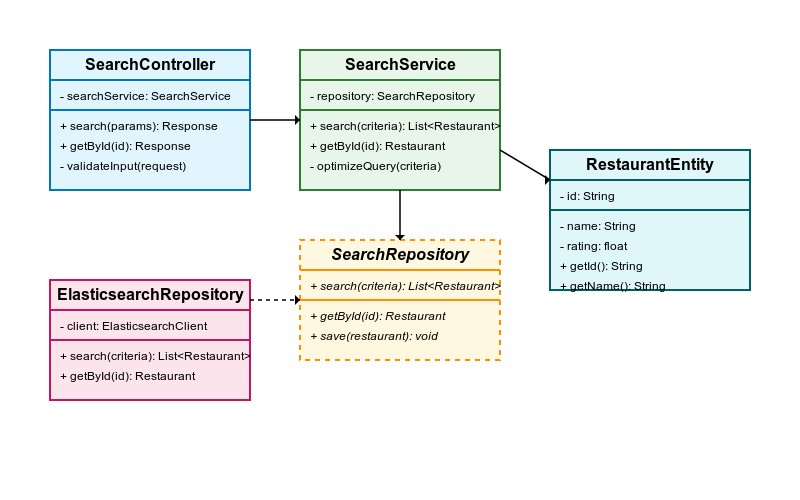
3.2.1 主要クラスの説明
SearchController
- クライアントからのHTTPリクエストを処理
- 入力パラメータのバリデーションを実施
- ビジネスロジック層へのリクエスト転送
- レスポンスの整形と返却
SearchService
- 検索のビジネスロジックを実装
- 検索条件の解析と最適化
- 適切なリポジトリの選択とクエリ実行
- 結果のフィルタリングと加工
SearchRepository(インターフェース)
- 検索データアクセスのための抽象インターフェース
- 検索実装の詳細を隠蔽
- テスト容易性を向上させる設計
ElasticsearchRepository
- SearchRepositoryインターフェースの実装
- Elasticsearchに対する具体的なクエリ実行
- クエリビルダーパターンの活用
RestaurantEntity
- ドメインモデルとしての飲食店エンティティ
- ビジネスルールとバリデーションの実装
- 不変条件の保証
3.3 適用したデザインパターン
本システムでは、以下のデザインパターンを活用しています:
3.3.1 リポジトリパターン
データアクセスの詳細を抽象化し、ドメインロジックに集中できるようにするパターンです。
# リポジトリインターフェース
class RestaurantRepository(ABC):
@abstractmethod
def find_by_id(self, id: str) -> Optional[Restaurant]:
pass
@abstractmethod
def search(self, criteria: SearchCriteria) -> List[Restaurant]:
pass
@abstractmethod
def save(self, restaurant: Restaurant) -> str:
pass
# 具体的な実装
class PostgresRestaurantRepository(RestaurantRepository):
def __init__(self, db_session: Session):
self.db_session = db_session
def find_by_id(self, id: str) -> Optional[Restaurant]:
db_restaurant = self.db_session.query(RestaurantModel).get(id)
if not db_restaurant:
return None
return self._map_to_entity(db_restaurant)
# 他のメソッド実装...
💡 学習ポイント
リポジトリパターンを使用することで、データの永続化方法を変更しても、ビジネスロジックを変更する必要がなくなります。例えば、PostgreSQLからMongoDBに変更する場合でも、新しいリポジトリ実装を作成するだけで済みます。
3.3.2 ファクトリーパターン
オブジェクトの生成ロジックを集約し、インスタンス生成の詳細を隠蔽するパターンです。
class DataSourceFactory:
@staticmethod
def create_data_source(source_type: str, config: Dict) -> DataSourceBase:
if source_type == "api":
return APIDataSource(config)
elif source_type == "db_import":
return DBImportDataSource(config)
elif source_type == "file_import":
return FileImportDataSource(config)
else:
raise ValueError(f"Unknown data source type: {source_type}")
📝 若手エンジニア向けメモ
ファクトリーパターンは、「どのように作るか」という詳細を隠蔽し、「何を作るか」に集中できるようにします。これにより、オブジェクト生成の複雑さを管理しやすくなります。
3.3.3 ストラテジーパターン
アルゴリズムをカプセル化し、実行時に切り替え可能にするパターンです。
# 戦略インターフェース
class SearchStrategy(ABC):
@abstractmethod
def search(self, query: str, filters: Dict) -> List[Dict]:
pass
# 具体的な戦略
class KeywordSearchStrategy(SearchStrategy):
def search(self, query: str, filters: Dict) -> List[Dict]:
# キーワードベースの検索実装
return keyword_based_search(query, filters)
class SemanticSearchStrategy(SearchStrategy):
def search(self, query: str, filters: Dict) -> List[Dict]:
# 意味ベースの検索実装
return semantic_based_search(query, filters)
# コンテキスト
class SearchEngine:
def __init__(self, strategy: SearchStrategy):
self.strategy = strategy
def set_strategy(self, strategy: SearchStrategy):
self.strategy = strategy
def execute_search(self, query: str, filters: Dict) -> List[Dict]:
return self.strategy.search(query, filters)
💡 学習ポイント
ストラテジーパターンを使用することで、検索アルゴリズムを実行時に切り替えることができます。例えば、単純なキーワード検索から、より高度な意味解析による検索に切り替えることが容易になります。
3.3.4 オブザーバーパターン
オブジェクト間の一対多の依存関係を定義し、あるオブジェクトの状態が変化した際に、依存するオブジェクトに通知するパターンです。
# オブザーバーインターフェース
class JobObserver(ABC):
@abstractmethod
def update(self, job_id: str, status: str, details: Dict):
pass
# 具体的なオブザーバー
class JobLogger(JobObserver):
def update(self, job_id: str, status: str, details: Dict):
log_entry = f"Job {job_id} status changed to {status}: {details}"
logger.info(log_entry)
class JobNotifier(JobObserver):
def update(self, job_id: str, status: str, details: Dict):
if status == "failed":
send_alert(f"Job {job_id} failed", details)
# 被観測者
class BatchJob:
def __init__(self, job_id: str):
self.job_id = job_id
self.status = "pending"
self.observers = []
def add_observer(self, observer: JobObserver):
self.observers.append(observer)
def remove_observer(self, observer: JobObserver):
self.observers.remove(observer)
def set_status(self, status: str, details: Dict = None):
self.status = status
self._notify_observers(details or {})
def _notify_observers(self, details: Dict):
for observer in self.observers:
observer.update(self.job_id, self.status, details)
📝 若手エンジニア向けメモ
オブザーバーパターンは、コンポーネント間の疎結合を実現するのに役立ちます。例えば、バッチジョブの状態変化を監視して、ログ記録、メール通知、ダッシュボード更新など、複数のアクションを実行したい場合に適しています。
3.4 関数型プログラミングの活用
本システムでは、オブジェクト指向だけでなく関数型プログラミングの概念も取り入れています。特にデータ処理パイプラインでは関数型アプローチが効果的です。
3.4.1 純粋関数
副作用のない関数を作成することで、テスト容易性と可読性を向上させています。
def normalize_address(address: str) -> str:
"""住所を正規化する純粋関数"""
# 外部状態に依存せず、同じ入力に対して常に同じ出力を返す
normalized = address.strip().upper()
# 都道府県名の統一
for pref_pattern, replacement in PREFECTURE_PATTERNS:
if pref_pattern.search(normalized):
normalized = pref_pattern.sub(replacement, normalized)
break
return normalized
3.4.2 関数合成
小さな関数を組み合わせて複雑な処理を構築します。
# 小さな関数
def extract_price_text(html_fragment: str) -> str:
"""HTMLから価格テキストを抽出"""
price_pattern = re.compile(r'(\d{1,3}(,\d{3})*円)')
match = price_pattern.search(html_fragment)
return match.group(1) if match else ""
def clean_price_text(price_text: str) -> str:
"""価格テキストから数字以外を除去"""
return re.sub(r'[^\d]', '', price_text)
def parse_price(price_str: str) -> Optional[int]:
"""文字列を整数価格に変換"""
try:
return int(price_str) if price_str else None
except ValueError:
return None
# 関数合成
def extract_price(html_fragment: str) -> Optional[int]:
"""HTMLから価格を抽出して整数に変換"""
return pipe(
html_fragment,
extract_price_text,
clean_price_text,
parse_price
)
💡 学習ポイント
関数型プログラミングでは、「何をするか」に焦点を当て、「どのように状態を変更するか」ではなく「どのように値を変換するか」を考えます。これにより、コードの予測可能性と再利用性が向上します。
3.4.3 高階関数
関数を引数として受け取ったり、関数を返したりする関数を活用します。
def filter_restaurants(restaurants: List[Restaurant],
predicate: Callable[[Restaurant], bool]) -> List[Restaurant]:
"""条件に合致するレストランをフィルタリング"""
return [r for r in restaurants if predicate(r)]
# 使用例
open_restaurants = filter_restaurants(
all_restaurants,
lambda r: r.is_open(current_time)
)
high_rated_restaurants = filter_restaurants(
all_restaurants,
lambda r: r.rating >= 4.0
)
3.5 若手エンジニア向け解説:クラス設計の基本
3.5.1 オブジェクト指向設計の基本原則
-
単一責任の原則(SRP):
- 一つのクラスは一つの責任を持つべき
- 例:
APIDataSourceはAPI経由のデータ取得のみを担当
💡 学習ポイント
クラスが複数の責任を持つと、一つの責任に関する変更が他の責任にも影響を与える可能性があります。責任を分離することで、変更の影響範囲を限定できます。 -
開放/閉鎖の原則(OCP):
- クラスは拡張に対して開かれ、修正に対して閉じられているべき
- 例:新しいデータソースを追加する場合、既存のコードを修正せずに
DataSourceBaseを継承した新クラスを追加するだけでよい
-
リスコフの置換原則(LSP):
- サブクラスはそのスーパークラスの代わりに使えるべき
- 例:
APIDataSourceやDBImportDataSourceは、DataSourceBase型の変数に代入して使用できる
-
インターフェイス分離の原則(ISP):
- クライアントは自分が使わないインターフェイスに依存すべきでない
- 例:検索サービスは検索機能のみを提供するインターフェイスを持つ
-
依存性逆転の原則(DIP):
- 高レベルモジュールは低レベルモジュールに依存すべきでない
- 例:検索サービスはElasticsearch具体実装ではなく、検索インターフェイスに依存する
3.5.2 クラス設計の実践ポイント
-
抽象クラスとインターフェイスの使い分け:
- 抽象クラス:いくつかの実装を含み、共通の機能を提供する場合
- インターフェイス:実装を含まず、単にメソッドの契約を定義する場合
📝 若手エンジニア向けメモ
Pythonでは、abcモジュールを使って抽象クラスを定義します。@abstractmethodデコレータで抽象メソッドを指定することで、サブクラスでの実装を強制できます。 -
依存性注入の活用:
- クラス内部で依存オブジェクトを直接生成せず、外部から注入する
- これにより、テストや機能拡張が容易になる
# 良くない例 class SearchService: def __init__(self): self.repository = ElasticsearchRepository() # 直接依存 # 良い例 class SearchService: def __init__(self, repository: SearchRepository): self.repository = repository # 依存を注入 -
適切な粒度でのクラス分割:
- 大きすぎるクラスは責任が多くなり、理解や保守が難しくなる
- 小さすぎるクラスは過度に複雑になる可能性がある
- 機能的なまとまりを考慮して適切な粒度を決定する
-
継承よりコンポジション:
- 継承は「is-a」関係(サブクラスはスーパークラスの一種)を表現
- コンポジションは「has-a」関係(クラスが他のクラスのインスタンスを持つ)を表現
- 多くの場合、継承よりもコンポジションの方が柔軟性が高い
💡 学習ポイント
例えば、SearchServiceが検索リポジトリを継承するのではなく、検索リポジトリのインスタンスを持つ(コンポジション)方が、後から検索リポジトリを入れ替えやすくなります。
3.5.3 効果的なクラス設計のためのTIPS
-
役割・責任・協調(RRC)モデル:
- 各クラスの役割(Role)を明確にする
- 各クラスの責任(Responsibility)を定義する
- クラス間の協調(Collaboration)方法を設計する
-
テスト駆動開発(TDD)の活用:
- テストを先に書くことで、使いやすいインターフェースを設計できる
- コードの品質と保守性が向上する
-
ドメイン駆動設計(DDD)の考慮:
- ユビキタス言語の採用(コードとビジネス用語の一致)
- ドメインモデルの適切な境界設定
- ドメイン知識のコードへの反映
🔍 チェックポイント
- オブジェクト指向設計の基本原則を説明できる
- クラス図の基本的な読み方を理解している
- データ収集バッチと検索APIの主要クラスとその関係を説明できる
- 適切なクラス設計の実践ポイントを理解している
- デザインパターンの基本的な適用方法を理解している
第4章:機能要件
📚 この章で学ぶこと
- システムが提供すべき具体的な機能
- 各機能の詳細仕様と実装方針
- 機能要件の考え方と記述方法
- ユーザーストーリーとジョブストーリーの作成方法
🔑 重要な概念
- 機能要件の抽出と優先順位付け
- 機能の詳細化と仕様の記述
- 各機能間の関連性と依存関係
- ユーザー中心設計(UCD)の考え方
4.1 データ収集機能
4.1.1 データ収集対象
以下の情報源からデータを収集します:
-
公式Web API(必須):
- 飲食店情報API
- 地図サービスAPI
- ユーザーレビューAPI
- 予約情報API
-
データベースインポート(必須):
- 飲食店マスターデータ
- 地域情報データ
- 営業時間データ
-
定期データフィード(オプション):
- 飲食店情報CSVフィード
- メニュー情報XMLフィード
- 特典情報JSONフィード
💡 学習ポイント
実際のプロジェクトでは、情報源の信頼性とデータの質を重視します。可能な限り公式に提供されているAPIやデータフィードを利用することで、安定した品質のデータを取得できます。
4.1.2 収集データ項目
以下のデータ項目を収集します:
-
基本情報:
- 店名(必須)
- 住所(必須)
- 電話番号
- 営業時間
- 定休日
- 公式サイトURL
-
料理情報:
- 料理ジャンル(必須)
- 価格帯
- メニュー情報(可能な場合)
- 支払い方法
-
評価情報:
- 総合評価(星評価など)
- レビュー数
- 個別レビュー(最新10件程度)
-
施設情報:
- 座席数
- 個室有無
- 禁煙/喫煙情報
- 駐車場有無
- Wi-Fi有無
- その他設備情報
-
メタデータ:
- データソース(収集元)
- 最終更新日時
- ソースURL
- 信頼性スコア
📝 若手エンジニア向けメモ
収集項目を明確に定義することで、データ構造の設計がしやすくなります。また、必須項目と任意項目を区別することで、データの整合性を保ちやすくなります。
4.1.3 収集スケジュール
データ収集は以下のスケジュールで実行されます:
- 基本実行頻度:毎日深夜2:00
- 差分更新方式:前回からの変更データのみを検出して更新
- 初回実行:全データの初期収集(時間がかかるため週末に実行)
- 手動実行:管理UIからの手動トリガーも可能
💡 学習ポイント
バッチ処理は、深夜など負荷の少ない時間帯に実行するのが一般的です。また、毎回全データを収集するのではなく、差分更新を行うことで効率化できます。
4.1.4 ロバストネス要件
データ収集の安定性を確保するための機能:
-
エラーハンドリング:
- 一時的なエラーの自動リトライ
- 指数バックオフアルゴリズム
- 永続的なエラーの記録と通知
-
APIクライアント:
- レート制限の遵守
- アクセストークンの管理
- エラーレスポンスの適切な処理
4.2 データ処理・ストレージ機能
4.2.1 データ検証と正規化
収集したデータに対して以下の処理を行います:
-
データ検証:
- スキーマ検証
- 必須項目の確認
- データ型チェック
- 異常値検出
📝 若手エンジニア向けメモ
データ検証は、不正なデータがシステムに入り込むのを防ぐ最初の防衛線です。例えば、電話番号が数字とハイフンのみで構成されているか、郵便番号が正しい形式かなどをチェックします。 -
データ正規化:
- 住所の正規化(都道府県、市区町村、番地などの分離)
- 電話番号の正規化(ハイフン統一など)
- 営業時間の構造化(開始時間、終了時間の分離)
- 料理ジャンルの標準化(サイト間での表記揺れ対応)
💡 学習ポイント
異なるソースから収集したデータは、同じ情報でも表記が異なる場合があります。例えば、「イタリアン」と「イタリア料理」は同じカテゴリを指しますが、表記が違います。これらを統一することで、検索や集計が正確になります。
4.2.2 重複検出と統合
同一店舗の特定と情報統合のための処理:
-
重複検出アルゴリズム:
- 店名の類似度計算(レーベンシュタイン距離など)
- 位置情報の近接性評価(地理的距離)
- 電話番号の一致確認
- 複合スコアリングによる判定
📝 若手エンジニア向けメモ
レーベンシュタイン距離とは、2つの文字列がどれだけ似ているかを数値化する方法の一つです。例えば、「すし太郎」と「寿司太郎」は表記は違いますが、類似度が高いと判断できます。 -
情報統合ルール:
- 情報源の信頼性による優先順位付け
- 最新データの優先
- 詳細度の高いデータの優先
- 矛盾するデータの解決戦略
💡 学習ポイント
同一店舗の情報を統合する際は、単純にデータを結合するだけでなく、どの情報を優先するかのルールが必要です。例えば、公式サイトからの情報は口コミサイトからの情報より優先するなどの判断基準を設けます。
4.2.3 データベーススキーマ
PostgreSQL(一次ストレージ):
restaurants テーブル(店舗情報)
| カラム名 | データ型 | 制約 | 説明 |
|---|---|---|---|
| id | SERIAL | PRIMARY KEY | 一意の店舗ID |
| name | VARCHAR(255) | NOT NULL | 店舗名 |
| address_id | INTEGER | FOREIGN KEY | 住所ID(addresses テーブル参照) |
| phone | VARCHAR(20) | NULL | 電話番号 |
| website | VARCHAR(255) | NULL | 公式サイトURL |
| rating | DECIMAL(3,1) | NULL | 総合評価スコア |
| price_range | VARCHAR(20) | NULL | 価格帯 |
| created_at | TIMESTAMP | DEFAULT CURRENT_TIMESTAMP | レコード作成日時 |
| updated_at | TIMESTAMP | DEFAULT CURRENT_TIMESTAMP | レコード最終更新日時 |
addresses テーブル(住所情報)
| カラム名 | データ型 | 制約 | 説明 |
|---|---|---|---|
| id | SERIAL | PRIMARY KEY | 一意の住所ID |
| prefecture | VARCHAR(20) | NOT NULL | 都道府県 |
| city | VARCHAR(50) | NOT NULL | 市区町村 |
| district | VARCHAR(50) | NULL | 地区・丁目 |
| street_address | VARCHAR(255) | NULL | 番地 |
| building | VARCHAR(255) | NULL | ビル名・建物名 |
| postal_code | VARCHAR(10) | NULL | 郵便番号 |
| latitude | DECIMAL(10,7) | NULL | 緯度 |
| longitude | DECIMAL(10,7) | NULL | 経度 |
business_hours テーブル(営業時間)
| カラム名 | データ型 | 制約 | 説明 |
|---|---|---|---|
| id | SERIAL | PRIMARY KEY | 一意の営業時間ID |
| restaurant_id | INTEGER | FOREIGN KEY | 店舗ID(restaurants テーブル参照) |
| day_of_week | INTEGER | NOT NULL | 曜日(0:日曜日 〜 6:土曜日) |
| open_time | TIME | NULL | 開店時間 |
| close_time | TIME | NULL | 閉店時間 |
| is_closed | BOOLEAN | DEFAULT FALSE | 休業日フラグ |
cuisine_types テーブル(料理ジャンル)
| カラム名 | データ型 | 制約 | 説明 |
|---|---|---|---|
| id | SERIAL | PRIMARY KEY | 一意のジャンルID |
| name | VARCHAR(50) | UNIQUE NOT NULL | 料理ジャンル名 |
restaurant_cuisine_types テーブル(店舗-料理ジャンル関連)
| カラム名 | データ型 | 制約 | 説明 |
|---|---|---|---|
| restaurant_id | INTEGER | FOREIGN KEY | 店舗ID(restaurants テーブル参照) |
| cuisine_type_id | INTEGER | FOREIGN KEY | 料理ジャンルID(cuisine_types テーブル参照) |
facilities テーブル(施設情報)
| カラム名 | データ型 | 制約 | 説明 |
|---|---|---|---|
| id | SERIAL | PRIMARY KEY | 一意の施設ID |
| name | VARCHAR(50) | UNIQUE NOT NULL | 施設・設備名 |
| category | VARCHAR(20) | NOT NULL | 施設カテゴリ |
restaurant_facilities テーブル(店舗-施設関連)
| カラム名 | データ型 | 制約 | 説明 |
|---|---|---|---|
| restaurant_id | INTEGER | FOREIGN KEY | 店舗ID(restaurants テーブル参照) |
| facility_id | INTEGER | FOREIGN KEY | 施設ID(facilities テーブル参照) |
reviews テーブル(レビュー情報)
| カラム名 | データ型 | 制約 | 説明 |
|---|---|---|---|
| id | SERIAL | PRIMARY KEY | 一意のレビューID |
| restaurant_id | INTEGER | FOREIGN KEY | 店舗ID(restaurants テーブル参照) |
| source | VARCHAR(50) | NOT NULL | レビュー元サイト |
| author | VARCHAR(100) | NULL | レビュー投稿者 |
| rating | DECIMAL(3,1) | NULL | レビュー評価点 |
| content | TEXT | NULL | レビュー本文 |
| review_date | TIMESTAMP | NULL | レビュー日時 |
| created_at | TIMESTAMP | DEFAULT CURRENT_TIMESTAMP | レコード作成日時 |
sources テーブル(データ収集元情報)
| カラム名 | データ型 | 制約 | 説明 |
|---|---|---|---|
| id | SERIAL | PRIMARY KEY | 一意のソースID |
| restaurant_id | INTEGER | FOREIGN KEY | 店舗ID(restaurants テーブル参照) |
| source_name | VARCHAR(50) | NOT NULL | データ収集元サイト名 |
| source_url | VARCHAR(255) | NULL | 収集元URL |
| source_id | VARCHAR(100) | NULL | 収集元サイトでの店舗ID |
| last_updated | TIMESTAMP | NULL | 最終更新日時 |
| reliability_score | DECIMAL(3,2) | NULL | データ信頼性スコア |
📝 若手エンジニア向けメモ
テーブル設計では、正規化によってデータを適切に分割し、関連テーブルを外部キー(FOREIGN KEY)で結びつけます。例えば、住所情報は別テーブル(addresses)に保存し、restaurants テーブルからは address_id で参照しています。
Elasticsearch(検索用ストレージ):
{
"mappings": {
"properties": {
"id": { "type": "keyword" },
"name": {
"type": "text",
"analyzer": "kuromoji",
"fields": {
"keyword": { "type": "keyword" }
}
},
"address": {
"properties": {
"full": { "type": "text" },
"prefecture": { "type": "keyword" },
"city": { "type": "keyword" },
"district": { "type": "keyword" },
"street_address": { "type": "text" },
"building": { "type": "text" }
}
},
"location": { "type": "geo_point" },
"phone": { "type": "keyword" },
"business_hours": {
"properties": {
"day_of_week": { "type": "integer" },
"open_time": { "type": "keyword" },
"close_time": { "type": "keyword" },
"is_closed": { "type": "boolean" }
}
},
"holidays": { "type": "keyword" },
"cuisine_types": { "type": "keyword" },
"price_range": {
"properties": {
"min": { "type": "integer" },
"max": { "type": "integer" },
"text": { "type": "keyword" }
}
},
"rating": { "type": "float" },
"review_count": { "type": "integer" },
"facilities": { "type": "keyword" },
"sources": {
"properties": {
"name": { "type": "keyword" },
"url": { "type": "keyword" },
"last_updated": { "type": "date" }
}
},
"created_at": { "type": "date" },
"updated_at": { "type": "date" }
}
},
"settings": {
"analysis": {
"analyzer": {
"kuromoji": {
"type": "custom",
"tokenizer": "kuromoji_tokenizer",
"filter": ["kuromoji_baseform", "kuromoji_part_of_speech"]
}
}
}
}
}
💡 学習ポイント
Elasticsearchでは、検索に最適化したスキーマ設計を行います。例えば、text型は全文検索用、keyword型は完全一致検索用です。また、日本語テキスト用のkuromoji解析器を使用することで、日本語の検索精度を向上させます。
4.3 検索API機能
4.3.1 APIエンドポイント
本システムのAPIは以下のエンドポイントを提供します:
-
検索API:
GET /api/v1/restaurants/search- 多様な条件での飲食店検索
-
詳細情報API:
GET /api/v1/restaurants/{id}- 特定の飲食店の詳細情報取得
-
フィルター情報API:
GET /api/v1/filters- 利用可能なフィルター条件の取得
-
ヘルスチェックAPI:
GET /api/v1/health- APIの状態確認
-
ドキュメントAPI:
GET /docs- OpenAPI仕様によるAPIドキュメント
📝 若手エンジニア向けメモ
RESTful APIでは、リソース(この場合は restaurants)を中心に設計し、HTTPメソッド(GET/POST/PUT/DELETEなど)を使って操作を表現します。パス変数({id}など)やクエリパラメータを使って、操作対象や条件を指定します。
4.3.2 検索パラメータ
検索APIでは以下のパラメータを受け付けます:
{
"keyword": "ピザ 新宿", // フリーテキスト検索
"location": { // 位置情報
"latitude": 35.6895,
"longitude": 139.6917,
"address": "東京都新宿区",
"area": "新宿"
},
"radius": 2.0, // 検索半径(km)
"cuisine_types": ["イタリアン", "ピザ"], // 料理ジャンル
"price_range": { // 価格帯
"min": 1000,
"max": 5000
},
"min_rating": 3.5, // 最低評価点
"open_now": true, // 現在営業中
"date_time": "2023-09-01T19:00:00", // 指定日時の空席検索
"facilities": ["個室あり", "駐車場あり"], // 施設条件
"page": 1, // ページ番号
"page_size": 20, // 1ページの表示件数
"sort_by": "rating_desc" // ソート条件
}
💡 学習ポイント
検索機能では、ユーザーが様々な条件で検索できるよう、十分なパラメータを用意することが重要です。同時に、全てのパラメータを必須にするのではなく、オプショナルにすることで、シンプルな検索から複雑な検索まで柔軟に対応できます。
4.3.3 レスポンス形式
検索結果は以下のJSON形式で返されます:
{
"meta": {
"total_results": 235,
"page": 1,
"page_size": 20,
"next_cursor": "eyJpZCI6MTIzNDV9"
},
"filters": {
"cuisine_types": ["イタリアン", "ピザ", "フレンチ", "和食", ...],
"facilities": ["個室あり", "駐車場あり", "禁煙席あり", ...],
"areas": ["新宿", "渋谷", "池袋", ...]
},
"items": [
{
"id": "12345",
"name": "ピザレストラン新宿",
"address": "東京都新宿区歌舞伎町1-2-3",
"distance": 0.8,
"cuisine_types": ["イタリアン", "ピザ"],
"price_range": {"min": 2000, "max": 3000, "text": "¥¥"},
"rating": 4.2,
"review_count": 128,
"open_status": "営業中 (22:00まで)",
"photo_url": "https://example.com/photos/12345.jpg",
"facilities": ["禁煙席あり", "Wi-Fi有り"],
"sources": ["公式サイト", "マップデータ"]
},
// 他の検索結果...
]
}
📝 若手エンジニア向けメモ
レスポンスには、検索結果(items)だけでなく、メタ情報(総件数、ページ情報など)やフィルター情報も含めることで、クライアント側での表示や次の操作をしやすくします。
詳細情報APIのレスポンスはさらに多くの情報を含みます:
{
"id": "12345",
"name": "ピザレストラン新宿",
"address": {
"full": "東京都新宿区歌舞伎町1-2-3 レストランビル2F",
"prefecture": "東京都",
"city": "新宿区",
"district": "歌舞伎町",
"street_address": "1-2-3",
"building": "レストランビル2F",
"postal_code": "160-0021"
},
"location": {"latitude": 35.6935, "longitude": 139.7035},
"phone": "03-1234-5678",
"website": "https://example.com/restaurant",
"cuisine_types": ["イタリアン", "ピザ"],
"price_range": {"min": 2000, "max": 3000, "text": "¥¥"},
"business_hours": [
{"day": "月", "open": "11:30", "close": "22:00"},
{"day": "火", "open": "11:30", "close": "22:00"},
// 他の曜日...
],
"holidays": ["毎週水曜日", "第3木曜日"],
"rating": 4.2,
"reviews": [
{
"source": "tabelog",
"author": "グルメ太郎",
"rating": 4.0,
"content": "ピザが美味しかったです。特にマルゲリータがおすすめです。",
"date": "2023-08-15"
},
// 他のレビュー...
],
"facilities": [
{"name": "禁煙席", "available": true},
{"name": "個室", "available": true, "detail": "6名までの個室あり"},
{"name": "駐車場", "available": false},
// 他の施設情報...
],
"photos": [
{"url": "https://example.com/photos/12345_1.jpg", "type": "外観"},
{"url": "https://example.com/photos/12345_2.jpg", "type": "料理"},
// 他の写真...
],
"sources": [
{"name": "tabelog", "url": "https://tabelog.com/restaurant/12345", "last_updated": "2023-08-20"},
{"name": "hotpepper", "url": "https://hotpepper.jp/restaurant/67890", "last_updated": "2023-08-15"}
],
"created_at": "2023-07-01T00:00:00Z",
"updated_at": "2023-08-20T15:30:45Z"
}
4.3.4 エラーハンドリング
APIは以下の形式でエラーレスポンスを返します:
{
"error": {
"code": "INVALID_PARAMETER",
"message": "Invalid parameter: radius must be between 0.5 and 10.0",
"details": {"parameter": "radius", "constraint": "0.5 <= radius <= 10.0"},
"request_id": "req-123456",
"timestamp": "2023-09-01T10:15:30Z"
}
}
主なエラーコード:
-
INVALID_PARAMETER: パラメータが不正 -
RESOURCE_NOT_FOUND: リソースが見つからない -
INTERNAL_ERROR: 内部エラー -
SERVICE_UNAVAILABLE: サービス一時停止中 -
RATE_LIMIT_EXCEEDED: レート制限超過
💡 学習ポイント
良いAPIは、エラーが発生した場合に明確な情報を提供します。エラーコード、メッセージ、詳細情報を含めることで、クライアント側でエラーを適切に処理できるようになります。
4.3.5 認証・認可
APIへのアクセスは以下の認証方式で保護されます:
-
APIキー認証:
- ヘッダー:
X-API-Key: {api_key} - シンプルかつ使いやすい認証方式
- ヘッダー:
-
JWT認証(拡張機能):
- Bearer トークン:
Authorization: Bearer {token} - ユーザー認証と権限管理に対応
- Bearer トークン:
-
レート制限:
- 基本制限: 60リクエスト/分
- 拡張プラン: 300リクエスト/分
- ヘッダーで残りリクエスト数を通知
📝 若手エンジニア向けメモ
APIキーはシンプルな認証方法ですが、漏洩すると誰でもそのキーを使えてしまうため、機密性の高いシステムではOAuth2などのより高度な認証方式を検討すべきです。また、レート制限を設けることで、サービスの安定性を確保できます。
4.4 モニタリング・管理機能
4.4.1 ロギング機能
システム全体のログは以下の方針で収集・管理されます:
-
ログレベル:
- DEBUG: 開発時の詳細情報
- INFO: 通常の操作情報
- WARNING: 潜在的な問題
- ERROR: エラー(手動対応が必要)
- CRITICAL: 重大なエラー(即時対応が必要)
-
ログ形式:
- JSON形式(構造化ログ)
- タイムスタンプ、レベル、コンポーネント名、メッセージを含む
- リクエストIDによる追跡可能性
💡 学習ポイント
構造化ログ(JSON形式など)を使用すると、ログの解析や検索が容易になります。また、リクエストIDのような追跡子を含めることで、複数のシステムを跨ぐ処理の追跡が可能になります。 -
ログストレージ:
- ローテーション: 日次、100MB上限
- 保存期間: 90日
- 集中ストレージへの転送
4.4.2 メトリクス収集
システムのパフォーマンスと状態を監視するための指標:
-
システムメトリクス:
- CPU使用率
- メモリ使用率
- ディスク使用率
- ネットワークトラフィック
-
アプリケーションメトリクス:
- リクエスト数(エンドポイント別)
- レスポンス時間の分布
- エラー率
- キャッシュヒット率
📝 若手エンジニア向けメモ
メトリクスは、システムの健全性を数値で表します。例えば、「レスポンス時間が急に長くなった」「エラー率が上昇した」などの異常を早期に検知できるようになります。 -
ビジネスメトリクス:
- 収集店舗数
- 更新レコード数
- 検索クエリパターン
- 人気のフィルター条件
4.4.3 アラート設定
異常を検知し、通知するためのアラート:
-
データ収集アラート:
- 連続失敗(3回以上)
- 収集量の異常減少(前日比30%以上減)
- 処理時間の異常(2時間以上)
-
APIアラート:
- 高エラー率(5%以上)
- 低レスポンス(平均3秒以上)
- 高負荷(90%以上のCPU使用率)
💡 学習ポイント
アラートは「ノイズ」と「見逃し」のバランスが重要です。あまりに敏感に設定すると頻繁に通知が来て無視されるようになり、逆に鈍感すぎると重要な問題を見逃す可能性があります。 -
ストレージアラート:
- ディスク容量警告(80%以上)
- データベース接続エラー
- インデックス更新失敗
-
通知チャネル:
- Eメール
- Slack
- SMS(重大な問題のみ)
4.4.4 管理インターフェース
システム管理者向けの管理UI:
-
ダッシュボード:
- システム状態の概要
- 主要メトリクスのグラフ
- アラート履歴
-
ジョブ管理:
- データ収集ジョブの状態確認
- ジョブの手動実行
- ジョブの一時停止/再開
📝 若手エンジニア向けメモ
管理インターフェースは、システムの状態を可視化し、必要な操作を行うための重要なツールです。特にバッチ処理のような自動実行されるジョブでは、状態確認や手動制御の機能が重要になります。 -
設定管理:
- データソースの管理
- システムパラメータの調整
- API設定の変更
-
ログビューワー:
- ログの検索と閲覧
- エラーの詳細確認
- トラブルシューティング支援
4.5 ユーザーストーリーとジョブストーリー
機能要件を具体的なユーザーシナリオとして表現することで、開発の焦点を明確にします。
4.5.1 ユーザーストーリー
ユーザーストーリーは「誰が、何をしたいのか、なぜそれをしたいのか」という形で表現します。
-
基本検索:
利用者として、料理のジャンルや地域で飲食店を検索したい。そうすることで、自分の好みや現在地に合った店舗を素早く見つけられるから。
-
詳細条件検索:
細かい希望条件を持つ利用者として、予算、設備(個室、禁煙席など)、営業時間などの詳細条件で飲食店を絞り込みたい。そうすることで、自分のニーズに完全に合致した店舗を見つけられるから。
-
現在地ベース検索:
外出中の利用者として、現在地から近い飲食店を検索したい。そうすることで、すぐに行ける場所の選択肢を知ることができるから。
-
評価ベース検索:
初めて訪れる地域の利用者として、評価の高い飲食店を見つけたい。そうすることで、品質の高いサービスを受けられる可能性を高められるから。
-
営業状況確認:
今すぐ食事したい利用者として、現在営業中の飲食店を検索したい。そうすることで、開店している店舗だけを表示し、時間を無駄にしないようにしたいから。
4.5.2 ジョブストーリー
ジョブストーリーは「状況、動機、期待する成果」というフレームワークで表現します。
-
急いで食事する場所を探す:
会議が長引いて時間がないとき、近くの評判の良い店ですぐに食事をしたい。そうすれば、次の予定に遅れることなく、満足のいく食事ができるから。
-
特別な日のレストランを探す:
記念日や重要な商談のとき、予算と目的に合った雰囲気の良いレストランを見つけたい。そうすれば、大切な機会を素晴らしい食事体験で演出できるから。
-
食事の前に設備を確認する:
子連れや車で出かけるとき、必要な設備(子供椅子、駐車場など)がある飲食店を探したい。そうすれば、到着後にトラブルなく快適に食事ができるから。
-
好みのジャンルで新しい店を発見する:
いつも同じ店ばかり行っていて飽きたとき、自分の好みのジャンルで未訪問の高評価の店を見つけたい。そうすれば、新しい食体験を楽しみながらも失敗のリスクを減らせるから。
-
予算内でグループでの食事場所を決める:
複数人での会食を計画するとき、予算内で全員の好みに合った店を見つけたい。そうすれば、グループ全体が満足できる選択ができるから。
4.6 若手エンジニア向け解説:機能要件の考え方
機能要件は「システムが何をするべきか」を定義するもので、システム設計の基礎となります。以下のポイントを押さえましょう:
-
ユーザー視点と運用視点の両方を考慮する:
- ユーザーが直接使う機能(検索APIなど)
- 運用に必要な機能(モニタリング、管理機能など)
- どちらも重要な機能要件です
-
優先順位をつける:
- 必須機能(Must Have)
- あると良い機能(Nice to Have)
- 将来的に検討する機能(Future Consideration)
- 限られたリソースの中で、重要な機能から実装していくことが大切です
-
詳細度のバランス:
- 詳細すぎると柔軟性が失われる
- 抽象的すぎると実装方針が定まらない
- 適切なレベルの詳細度で記述することが重要です
-
検証可能性:
- 要件が満たされたかどうかを判断できるよう、具体的かつ測定可能な形で記述する
- 例:「検索は高速であること」より「90%の検索リクエストが500ms以内に完了すること」の方が検証しやすい
-
ユーザーストーリーやジョブストーリーの活用:
- 抽象的な機能要件を具体的なシナリオに落とし込む
- 実装の目的と価値を明確にする
- チーム全体での認識共有を促進する
🔍 チェックポイント
- データ収集機能の主要な要素(対象、項目、スケジュール)を説明できる
- データ処理・ストレージ機能の役割と重要性を理解している
- 検索API機能の設計(エンドポイント、パラメータ、レスポンス形式など)を説明できる
- モニタリング・管理機能の必要性と主要コンポーネントを理解している
- ユーザーストーリーとジョブストーリーの違いと作成方法を説明できる
第5章:非機能要件
📚 この章で学ぶこと
- パフォーマンス、可用性、セキュリティなどの非機能要件
- システムの品質特性を定義する方法
- 非機能要件が実装に与える影響
- クラウドネイティブ環境での非機能要件
🔑 重要な概念
- 非機能要件の種類と重要性
- 要件の具体的な数値化
- トレードオフの考慮
- SLO (Service Level Objectives) の設定
5.1 パフォーマンス要件
5.1.1 レスポンスタイム
-
検索API:
- 平均レスポンス時間: 500ms以内
- 95パーセンタイル: 3秒以内
- 最大許容時間: 10秒
💡 学習ポイント
パフォーマンス要件では、平均値だけでなく、パーセンタイル値(例:95%のリクエストが何秒以内に完了するか)も重要です。これにより、一部のユーザーが極端に遅い応答を受けることを防げます。 -
詳細情報API:
- 平均レスポンス時間: 300ms以内
- 95パーセンタイル: 1秒以内
- 最大許容時間: 3秒
5.1.2 スループット
-
検索API:
- 平常時: 50リクエスト/秒
- ピーク時: 100リクエスト/秒
- バースト耐性: 200リクエスト/秒(短時間)
📝 若手エンジニア向けメモ
スループットは、システムが単位時間あたりに処理できるリクエスト数です。平常時だけでなく、イベントなどでアクセスが集中する「ピーク時」や、一時的なアクセス急増(「バースト」)にも対応できるよう設計することが重要です。 -
データ収集バッチ:
- データソースの制限を考慮
- 1ソースあたり5-20リクエスト/分
- 並列処理で効率化
5.1.3 容量要件
-
店舗数:
- 初期フェーズ: 約10万店舗
- 将来拡張: 最大100万店舗
-
ストレージ容量:
- PostgreSQL: 初期20GB、年間成長5GB
- Elasticsearch: 初期30GB、年間成長10GB
- ログ: 月間5GB
💡 学習ポイント
容量計画では、初期段階だけでなく、将来の成長も考慮することが重要です。データ量の増加に伴い、パフォーマンスが低下したり、ストレージが不足したりしないよう、余裕を持った設計が必要です。
5.2 可用性要件
5.2.1 稼働率
-
検索API:
- 目標稼働率: 99.9%(月間ダウンタイム43分以内)
- 計画メンテナンス: 月1回、深夜2時-4時
📝 若手エンジニア向けメモ
99.9%の稼働率(「スリーナイン」と呼ばれます)は、月に約43分のダウンタイムが許容されることを意味します。稼働率の数字が1桁増えるごとに(99.9%→99.99%など)、実現の難易度とコストは大幅に上昇します。 -
バッチ処理:
- 成功率: 95%以上
- 失敗時の自動リトライ
- 手動リカバリー手段の提供
5.2.2 障害回復
-
復旧時間目標(RTO):
- 検索API: 1時間以内
- バッチ処理: 4時間以内
-
復旧ポイント目標(RPO):
- データベース: 24時間以内
- ログ: 72時間以内
💡 学習ポイント
RTOとRPOは災害復旧計画の重要な指標です。RTOは「どれだけ早くシステムを復旧させるか」、RPOは「どの時点までのデータを復旧させるか」を表します。例えば、RPOが24時間なら、最大で24時間前のデータまで戻る可能性があることを意味します。
5.2.3 障害対策
-
単一障害点の排除:
- コンポーネント間の疎結合
- 冗長化(予算制約内で段階的に実装)
-
デグラデーション戦略:
- 一部データソースの障害時も検索機能を維持
- キャッシュを活用した縮退運転
- 非重要機能の一時停止
📝 若手エンジニア向けメモ
「デグラデーション(縮退)」とは、システムの一部が障害を起こした場合でも、重要な機能を維持するための戦略です。例えば、データベースに問題が発生しても、キャッシュを活用して基本的な検索機能を提供するなどの対応が考えられます。
5.3 セキュリティ要件
5.3.1 認証・認可
-
API認証:
- APIキー認証
- IPアドレス制限(オプション)
-
管理インターフェース:
- ユーザー名/パスワード認証
- 多要素認証(将来実装)
- ロールベースアクセス制御
💡 学習ポイント
セキュリティは「多層防御」の考え方が重要です。単一の防御策ではなく、複数の防御層を設けることで、一つの層が破られても次の層で防御できるようにします。
5.3.2 データ保護
-
通信の暗号化:
- すべてのエンドポイントでHTTPS使用
- TLS 1.2以上を要求
-
データの暗号化:
- 個人情報は保存時に暗号化
- 秘密情報(APIキーなど)は暗号化
📝 若手エンジニア向けメモ
データ保護では、「転送中のデータ」と「保存中のデータ」の両方を考慮する必要があります。HTTPSによる通信の暗号化と、データベースでの暗号化の両方が重要です。 -
アクセス制御:
- 最小権限の原則
- ロールベースのアクセス管理
5.3.3 脆弱性対策
-
入力検証:
- すべてのユーザー入力の検証
- SQLインジェクション対策
- クロスサイトスクリプティング(XSS)対策
💡 学習ポイント
入力検証は、セキュリティの基本です。外部から入ってくるデータは全て「信頼できない」と考え、適切に検証・サニタイズすることが重要です。特にSQLインジェクションやXSS(クロスサイトスクリプティング)などの一般的な攻撃に対する対策は必須です。 -
依存パッケージ管理:
- 定期的な脆弱性スキャン
- セキュリティアップデートの適用
-
ログ監査:
- セキュリティイベントのログ記録
- アクセスログの定期レビュー
5.3.4 OWASP Top 10対応
OWASPが定めるWebアプリケーションの主要な脆弱性に対する対策:
-
インジェクション対策:
- パラメータ化クエリの使用
- ORMの適切な活用
- ユーザー入力の厳格なバリデーション
-
認証とセッション管理:
- 安全なパスワードハッシュ(bcrypt)
- セッショントークンの安全な管理
- アカウントロックアウト機能
-
クロスサイトスクリプティング(XSS)対策:
- 出力エンコーディング
- Content Security Policy (CSP)の実装
- XSS-Filterヘッダーの設定
-
安全でないオブジェクト参照の防止:
- 適切なアクセス制御チェック
- ユーザー固有の識別子の使用
-
セキュリティ設定のハードニング:
- セキュアなHTTPヘッダー設定
- 不要なサービス・機能の無効化
- エラーメッセージの最小化
📝 若手エンジニア向けメモ
OWASPはWebアプリケーションセキュリティの標準的なガイドラインを提供する非営利団体です。OWASP Top 10は、最も重大で一般的なWebアプリケーションのセキュリティリスクをリストアップしたものであり、セキュア開発の基本として考慮すべき項目です。
5.4 拡張性・保守性要件
5.4.1 水平スケーラビリティ
-
APIサーバー:
- ステートレス設計
- 複数インスタンスによる負荷分散
- オートスケーリング対応(将来実装)
📝 若手エンジニア向けメモ
「ステートレス設計」とは、各リクエストが独立して処理され、サーバーがクライアントの状態を保持しない設計のことです。これにより、複数のサーバーでリクエストを処理することが容易になり、水平スケーリング(サーバー数を増やすこと)が可能になります。 -
バッチ処理:
- ワーカーの並列処理
- ジョブの分散実行
- 処理単位の分割
5.4.2 垂直スケーラビリティ
-
データベース:
- リソース増強の簡易化
- 段階的なアップグレードパス
- パフォーマンスチューニング容易性
💡 学習ポイント
「垂直スケーリング」とは、サーバーのスペック(CPU、メモリなど)を向上させることです。水平スケーリングと比べて実装は簡単ですが、単一サーバーの限界があります。両方のスケーリング方法をバランスよく考慮することが重要です。 -
検索エンジン:
- インデックス設計の最適化
- クエリパフォーマンスの監視と改善
- シャーディング対応(将来実装)
5.4.3 コード保守性
-
モジュール化:
- 責務の明確な分離
- インターフェースによる疎結合
- 単一責任の原則
📝 若手エンジニア向けメモ
「単一責任の原則」とは、「クラスを変更する理由は1つだけであるべき」という原則です。つまり、1つのクラスは1つの責任だけを持つべきです。これにより、コードの変更が他の部分に影響を与えにくくなります。 -
テスト容易性:
- 単体テストのカバレッジ
- モックによる外部依存の分離
- 自動テスト環境
-
設定管理:
- 環境変数による設定
- 設定ファイルの外部化
- ランタイム設定変更機能
5.4.4 クラウドネイティブ対応
クラウド環境で効果的に運用するための要件:
-
コンテナ化:
- Dockerコンテナによるパッケージング
- 環境の一貫性確保
- 依存関係の明確な管理
-
オーケストレーション:
- Kubernetesによるコンテナ管理
- 自動スケーリング設定
- ヘルスチェックと自動回復
-
GitOps:
- 宣言的インフラ定義
- バージョン管理されたインフラ設定
- 継続的デリバリーパイプライン
💡 学習ポイント
クラウドネイティブアプリケーションは、クラウド環境の特性(スケーラビリティ、弾力性、自動化など)を最大限に活用するように設計されています。コンテナ化とオーケストレーション技術を採用することで、環境間の一貫性を確保し、効率的なデプロイメントとスケーリングが可能になります。
5.5 運用性要件
5.5.1 監視と可観測性
-
観測データの収集:
- メトリクス収集(システム性能、ビジネスKPI)
- 分散トレーシング
- 構造化ログ
- イベント
-
ダッシュボード:
- リアルタイムモニタリング
- カスタマイズ可能なビュー
- アラート状態の可視化
-
アラート設定:
- 異常検知ベースのアラート
- 通知チャネルの多様性
- エスカレーションポリシー
5.5.2 運用自動化
-
自動化された運用タスク:
- バックアップと復元
- パッチ適用
- スケーリング操作
-
ランブック:
- 標準操作手順の文書化
- 障害対応マニュアル
- 定期的な訓練と改善
-
デプロイメント自動化:
- CI/CDパイプライン
- カナリアリリース
- 自動ロールバック機能
📝 若手エンジニア向けメモ
運用自動化は、人的ミスを減らし、運用効率を高めるために重要です。繰り返し行われる作業は自動化し、オペレーターはより価値の高い問題解決や改善活動に集中できるようにするのが理想的です。
5.6 SREアプローチによる品質目標
Google発祥のSRE(Site Reliability Engineering)の概念を取り入れた目標設定:
5.6.1 SLI (Service Level Indicators)
サービスの健全性を測定する指標:
- 可用性:成功したリクエストの割合
- レイテンシ:リクエスト処理にかかる時間
- 処理量:システムが処理できるリクエスト数
- エラー率:エラーが発生したリクエストの割合
5.6.2 SLO (Service Level Objectives)
SLIに対する目標値:
- 可用性SLO:30日間で99.9%のリクエストが成功すること
- レイテンシSLO:95%のリクエストが500ms以内に完了すること
- エラー率SLO:エラー率が0.1%を超えないこと
5.6.3 エラーバジェット
SLOを達成するために許容されるエラーの量:
- 計算方法:(1 - SLO) × 総リクエスト数
- 活用方法:エラーバジェットが残っている場合は新機能のリリースを加速、枯渇している場合は安定性向上に注力
💡 学習ポイント
SREアプローチでは、「100%の可用性を目指す」のではなく、「99.9%などの具体的な目標を定め、それを確実に達成する」という考え方をします。これにより、信頼性向上のための取り組みと、新機能開発のスピードのバランスを取ることができます。
5.7 若手エンジニア向け解説:非機能要件の重要性
非機能要件は、システムが「どのようにうまく動作するか」を定義するもので、ユーザー体験や運用効率に大きく影響します。以下のポイントを押さえましょう:
-
非機能要件は早期に検討する:
- 後からの変更が困難なことが多い
- アーキテクチャ選定に大きく影響する
- 開発初期から意識することが重要
-
具体的な数値で定義する:
- 「高性能」ではなく「平均応答時間500ms以内」など
- 測定可能な形で記述することで、要件達成の判断が容易になる
-
トレードオフを理解する:
- 高可用性と低コストはトレードオフの関係にある
- 高性能と実装の容易さはトレードオフの関係にある
- 全ての要件を最高レベルで満たすことは現実的でない場合が多い
-
段階的な実装計画を立てる:
- まずは基本的な要件を満たす
- その後、優先度の高い要件から段階的に強化する
- コストと効果のバランスを考慮する
-
定期的な見直しを行う:
- ユーザー数やデータ量の増加に伴う要件変更
- 新しい技術や手法の採用による改善可能性
- ビジネス要件の変化に応じた優先順位の調整
📝 若手エンジニア向けメモ
非機能要件は「目に見えにくい」ため、軽視されがちですが、システムの成功には機能要件と同等かそれ以上に重要です。特に、スケーラビリティやセキュリティの問題は、利用者が増えてから対応しようとすると、大幅な設計変更が必要になることがあります。
🔍 チェックポイント
- パフォーマンス要件の主要な指標(レスポンスタイム、スループット、容量)を説明できる
- 可用性要件の重要性と主要な指標(稼働率、RTO、RPO)を理解している
- セキュリティ要件の基本的な考え方と主要な対策を説明できる
- 拡張性・保守性要件がシステムの長期的な健全性にどう貢献するか理解している
- SREアプローチの基本概念(SLI、SLO、エラーバジェット)を説明できる
第6章:技術選定とその理由
📚 この章で学ぶこと
- システムに適した技術を選定する方法
- 各技術の長所と短所の比較
- 技術選定がシステム全体に与える影響
- 技術選定の意思決定プロセス
🔑 重要な概念
- 要件に基づいた技術選定の考え方
- 技術の成熟度とコミュニティの活発さの重要性
- チームの技術力との相性
- 将来の拡張性と保守性の考慮
6.1 技術選定の基本方針
本プロジェクトでは、以下の基本方針に基づいて技術を選定しました:
-
機能要件と非機能要件の充足:
- システム要件を満たす技術力を持っていること
- スケーラビリティ、パフォーマンス要件を満たせること
-
チームのスキルセットとの整合性:
- チームのスキルと経験に合った技術を優先
- 学習曲線と導入コストの考慮
-
コミュニティとエコシステム:
- 活発なコミュニティサポートの有無
- 充実したドキュメンテーション
- サードパーティライブラリの充実度
-
将来の拡張性:
- 将来のビジネス要件変化に対応できる柔軟性
- 新技術への移行容易性
-
コストと制約:
- ライセンスコストと運用コスト
- 組織のポリシーやコンプライアンス要件
💡 学習ポイント
技術選定は単に「流行りのもの」や「好み」で選ぶのではなく、プロジェクトの特性やチームの状況を考慮した戦略的な意思決定です。短期的な生産性だけでなく、長期的な保守性も重要な判断基準となります。
6.2 プログラミング言語:Python
選定理由:
- 豊富なライブラリエコシステム(データ処理、API開発、機械学習など)
- 開発速度の高さと可読性の良さ
- チーム内の技術スキルとの親和性
- 豊富なドキュメントとコミュニティサポート
- Web API開発からデータ処理まで幅広く対応可能
💡 学習ポイント
プログラミング言語の選定では、言語自体の特性だけでなく、ライブラリのエコシステムやチームの習熟度も重要な要素です。Pythonは特にデータ処理や機械学習の分野で強力なライブラリが豊富です。
代替検討:
- Node.js: 非同期処理に強いが、データ処理ライブラリがPythonほど充実していない
- Java: 堅牢だが開発速度が遅く、ボイラープレートコードが多い
- Go: 高性能だが、ライブラリエコシステムがPythonほど充実していない
📝 若手エンジニア向けメモ
どの言語も一長一短があります。例えば、Javaは型安全性が高く大規模開発に向いていますが、開発スピードは遅くなりがちです。Pythonは開発が速い反面、大規模になると型の問題などが出てくることがあります。プロジェクトの性質に合った言語を選びましょう。
6.2.1 意思決定プロセスの例
Pythonを選定するに至った意思決定プロセスを簡略化したADR(Architecture Decision Record)形式で示します:
# ADR-001: プログラミング言語としてPythonを選定
## ステータス
承認済み
## コンテキスト
- サービスには高速な開発サイクルが求められている
- データ処理とWeb API両方の機能が必要
- チームの多くのメンバーがPythonに習熟している
- 将来的な機械学習機能の追加可能性がある
## 決定
プロジェクトの主要言語としてPython 3.10+を採用する
## 代替案
- Node.js: Web APIに強いが、データ処理・機械学習のエコシステムが弱い
- Java: 型安全性に優れるが、開発速度が遅く、ボイラープレートコードが多い
- Go: パフォーマンスに優れるが、チームのスキルセットとの一致度が低い
## 判断基準
1. 機能要件の充足(重み: 30%): Python - 5/5, Node.js - 3/5, Java - 4/5, Go - 3/5
2. 開発効率(重み: 25%): Python - 5/5, Node.js - 4/5, Java - 2/5, Go - 3/5
3. チームスキル(重み: 20%): Python - 4/5, Node.js - 3/5, Java - 3/5, Go - 1/5
4. エコシステム(重み: 15%): Python - 5/5, Node.js - 4/5, Java - 5/5, Go - 3/5
5. 将来性(重み: 10%): Python - 4/5, Node.js - 4/5, Java - 3/5, Go - 5/5
加重平均スコア:
- Python: 4.7/5
- Node.js: 3.6/5
- Java: 3.35/5
- Go: 2.8/5
## 結果
Pythonが最も高いスコアを得た。特に、データ処理能力と開発効率の点で優位性が高い。
## 影響
- 型の安全性については、型ヒントとmypyを活用して補強する
- 高負荷部分は必要に応じてC拡張やGo/Rustでの実装を検討する
- パフォーマンスクリティカルな部分では非同期処理(asyncio)を活用する
📝 若手エンジニア向けメモ
ADR(Architecture Decision Record)は、重要な技術的意思決定を記録するための軽量な方法です。「なぜその決定をしたのか」を将来のチームメンバーが理解できるよう、コンテキスト、検討した選択肢、判断基準、予想される影響などを記録します。
6.3 データベース(一次ストレージ):PostgreSQL
選定理由:
- オープンソースでありながら高度な機能と安定性
- リレーショナルモデルによるデータ整合性の確保
- JSON型によるスキーマの柔軟性
- PostGISによる地理空間データのサポート
- 豊富なインデックスオプションと高度なクエリ機能
💡 学習ポイント
PostgreSQLは、オープンソースのリレーショナルデータベースの中でも特に機能が豊富です。特に地理空間データの処理能力(PostGIS)や、JSON型のサポートなど、NoSQLデータベースの利点も一部取り入れています。
代替検討:
- MySQL: シンプルだが、PostgreSQLより高度な機能が少ない
- MongoDB: 柔軟なスキーマだが、トランザクション整合性が弱い
- SQLite: 軽量だが、同時接続性能が低く大規模データに不向き
📝 若手エンジニア向けメモ
データベース選定では、データの構造(構造化データか非構造化データか)、トランザクションの重要性、スケーラビリティの要件などを考慮します。本システムでは、店舗情報のような構造化データを扱い、データの整合性が重要なため、リレーショナルデータベースが適しています。
6.4 データベース(検索ストレージ):Elasticsearch
選定理由:
- 全文検索に最適化されたアーキテクチャ
- 地理空間検索のネイティブサポート
- スケーラビリティとクラスタリング機能
- 複雑なクエリとフィルタリングの柔軟性
- 速度と機能のバランスの良さ
💡 学習ポイント
Elasticsearchは「検索」に特化したデータベースで、インデックスの構造や検索アルゴリズムが全文検索や複雑なクエリに最適化されています。また、分散システムとして設計されており、スケーラビリティにも優れています。
代替検討:
- Solr: 機能的に似ているが、構成が複雑
- Algolia: マネージドサービスで簡単だが、コストが高い
- PostgreSQLの全文検索: シンプルだが、複雑な検索や大量データには不向き
📝 若手エンジニア向けメモ
PostgreSQLにも全文検索機能はありますが、複雑な検索条件や大量のデータになると性能が不足する場合があります。Elasticsearchはそのような場合に威力を発揮しますが、運用の複雑さやリソース要件が高いというデメリットもあります。
6.5 API:FastAPI
選定理由:
- 高パフォーマンス(ASGIベース、Uvicornとの組み合わせ)
- 自動APIドキュメント生成(OpenAPI/Swagger対応)
- 型ヒントによる開発時の安全性向上
- 非同期処理のネイティブサポート
- データバリデーション機能の組み込み
💡 学習ポイント
FastAPIは比較的新しいフレームワークですが、パフォーマンスが高く、開発体験が優れていることから急速に人気を集めています。特に型ヒントを活用した自動バリデーションや、OpenAPI仕様に基づく自動ドキュメント生成など、開発効率を高める機能が充実しています。
代替検討:
- Flask: シンプルだが、FastAPIより低パフォーマンス
- Django: 多機能だが、APIのみの用途には過剰
- Express.js(Node.js): 非同期に強いが、チームのPython経験を活かせない
📝 若手エンジニア向けメモ
Webフレームワークの選択では、プロジェクトの規模や要件に合ったものを選ぶことが重要です。小規模なAPIならFlaskでも十分ですが、大規模なシステムや高いパフォーマンスが求められる場合はFastAPIやDjangoが適しています。また、チームの習熟度も重要な要素です。
6.6 キャッシュ:Redis
選定理由:
- 高速インメモリデータストア
- 多様なデータ構造のサポート
- キーの有効期限(TTL)管理の簡便さ
- パブリッシュ/サブスクライブ機能
- 豊富なクライアントライブラリ
💡 学習ポイント
Redisは単なるキャッシュ以上の機能を持つ「データ構造サーバー」です。文字列だけでなく、リスト、セット、ハッシュ、ソート済みセットなど多様なデータ構造をサポートしており、これらを活用することで複雑なデータ操作も効率的に行えます。
代替検討:
- Memcached: シンプルだが、Redisより機能が限定的
- ローカルメモリキャッシュ: 分散環境での一貫性に課題
- Hazelcast: 機能豊富だが設定が複雑
📝 若手エンジニア向けメモ
キャッシュを導入する目的は主にパフォーマンス向上ですが、「キャッシュの一貫性」という課題も考慮する必要があります。データが更新された場合、キャッシュも適切に更新または無効化しないと、古いデータが表示されてしまう可能性があります。
6.7 コンテナ技術:Docker & Kubernetes
選定理由:
- 環境の一貫性確保
- デプロイメントの簡素化
- スケーリングの柔軟性
- ロールバックの容易さ
- マイクロサービスアーキテクチャへの将来的な移行の容易さ
💡 学習ポイント
コンテナ技術は、アプリケーションとその依存関係を1つのパッケージにまとめることで、「開発環境では動くのに本番環境では動かない」という問題を解決します。また、Kubernetesのようなオーケストレーションツールを利用することで、複数のコンテナの管理やスケーリングを自動化できます。
代替検討:
- 仮想マシン(VM): リソース効率が低く、起動が遅い
- サーバーレス(AWS Lambda等): 特定の用途には適しているが、長時間実行プロセスには不向き
- 直接ホスト上にデプロイ: シンプルだが、環境差異や依存関係の問題がある
📝 若手エンジニア向けメモ
Dockerは開発環境と本番環境の「一貫性」を確保するのに非常に役立ちます。「自分のPCでは動くのに本番環境では動かない」という問題を大幅に減らせます。Kubernetesは複雑ですが、システムの成長に伴い、スケーリングや可用性の管理が容易になるという大きなメリットがあります。
6.8 CI/CD:GitHub Actions
選定理由:
- GitHubとの緊密な統合
- シンプルな設定ファイル(YAML)
- マトリックスビルドのサポート
- 豊富な事前構築されたアクション
- エコシステムの成長と活発なコミュニティ
💡 学習ポイント
CI/CD(継続的インテグレーション/継続的デリバリー)は、コードの変更をテスト、ビルド、デプロイするプロセスを自動化する方法です。これにより、品質確保と迅速なデプロイメントの両立が可能になります。
代替検討:
- Jenkins: 高度にカスタマイズ可能だが、設定が複雑
- CircleCI: クラウドベースで使いやすいが、固有の構文を学ぶ必要がある
- GitLab CI: GitLabと統合されているが、本プロジェクトではGitHubを使用
📝 若手エンジニア向けメモ
CI/CDツールは「手動作業を減らし、ヒューマンエラーを防ぐ」という大きなメリットがあります。テストの実行忘れやデプロイミスなどを防ぎ、開発チームは機能開発に集中できるようになります。
6.9 モニタリング:Prometheus + Grafana
選定理由:
- Prometheus: メトリクス収集と保存に最適化
- Grafana: 柔軟性の高い可視化ダッシュボード
- アラート機能の統合
- 幅広いエクスポーターの利用可能性
- オープンソースコミュニティの活発さ
💡 学習ポイント
Prometheusは「プル型」のモニタリングシステムで、定期的に監視対象からメトリクスを取得します。これにより、シンプルな構成と高い信頼性を実現しています。Grafanaはそのデータを視覚化するツールで、様々なデータソースに対応しています。
代替検討:
- ELK Stack: ログ解析に強いが、メトリクス特化ではない
- Datadog: 高機能だが有料
- カスタム監視: 開発コストが高い
📝 若手エンジニア向けメモ
モニタリングは「何を、どのように監視するか」を明確にすることが重要です。CPU使用率やメモリ使用率などの基本的なシステムメトリクスだけでなく、アプリケーション固有のメトリクス(リクエスト数、エラー率など)も監視することで、問題の早期発見と対応が可能になります。
6.10 インフラストラクチャ: AWS
選定理由:
- 幅広いサービスの提供
- スケーラビリティと柔軟性
- セキュリティ機能の充実
- マネージドサービスによる運用負荷の軽減
- 豊富なドキュメントとサポート
主要サービス:
- EC2: アプリケーションサーバー
- RDS for PostgreSQL: リレーショナルデータベース
- Amazon Elasticsearch Service: 検索エンジン
- ElastiCache: Redisキャッシュ
- EKS: Kubernetesクラスター管理
- S3: 静的リソースとバックアップストレージ
- CloudWatch: 監視とアラート
- Route53: DNS管理
- Certificate Manager: SSL証明書管理
💡 学習ポイント
クラウドプロバイダーの選択は、単に技術的な理由だけでなく、ビジネス要件(コスト、規制コンプライアンス、既存システムとの統合等)も考慮して行います。AWSは幅広いサービスとグローバルなインフラストラクチャを提供しており、多くのユースケースに対応できます。
代替検討:
- Google Cloud Platform (GCP): Kubernetesに強みがあるが、AWSより日本での導入実績が少ない
- Microsoft Azure: Microsoftエコシステムとの統合に優れるが、特定のサービスではAWSより機能が限定的
- オンプレミス: 完全な制御が可能だが、初期コストと運用コストが高い
📝 若手エンジニア向けメモ
クラウドサービスでは「従量課金」モデルが一般的ですが、プランニングが不足していると予想外のコストが発生する可能性があります。リソースの自動スケーリングには上限を設定したり、不要なリソースは自動的にシャットダウンするなどの対策が重要です。また、マネージドサービス(RDS、ElastiCacheなど)は、自前で構築・運用するよりも効率的に使えることが多いです。
6.11 若手エンジニア向け解説:技術選定の考え方
技術選定は、プロジェクトの成否を左右する重要な決断です。以下のポイントを考慮して技術を選定しましょう:
-
要件との適合性:
- 機能要件と非機能要件を満たせるか
- 特に重要な要件(例:パフォーマンス、セキュリティ)に対応できるか
- 将来的な要件変更にも対応できる柔軟性があるか
-
チームの技術力との相性:
- チームがすでに習熟している技術か
- 学習コストは許容範囲内か
- サポートやリソースは十分に得られるか
-
技術の成熟度とコミュニティ:
- 十分に実績のある技術か
- 活発なコミュニティとサポートがあるか
- ドキュメントや学習リソースは充実しているか
-
コストと制約:
- ライセンス費用や運用コストは予算内か
- ハードウェア要件は満たせるか
- 既存システムとの統合は容易か
-
長期的な展望:
- 技術の将来性はどうか
- ベンダーロックインのリスクはないか
- スケーラビリティと拡張性は確保できるか
6.11.1 技術選定の意思決定プロセス
-
要件の明確化:
- 機能要件と非機能要件を文書化
- 優先順位を決定
- 技術選定に影響する制約条件を特定
-
選択肢の洗い出し:
- 候補技術のリストを作成
- 各技術の基本情報を収集
- 明らかに不適切な選択肢を早期に除外
-
評価基準の設定:
- 重要な基準を特定(パフォーマンス、スケーラビリティ、学習曲線など)
- 基準ごとの重み付けを決定
- 評価方法を定義(スコアリングなど)
-
詳細評価:
- 各技術の長所・短所を分析
- 必要に応じてプロトタイプ作成
- 評価基準に基づいてスコアリング
-
意思決定と文書化:
- 評価結果に基づいて決定
- 決定理由を含む技術選定文書を作成(ADRなど)
- ステークホルダーとの共有と合意形成
💡 学習ポイント
「最新・最先端」の技術が常に最適というわけではありません。プロジェクトの性質、チームの状況、時間的制約などを総合的に考慮して、バランスの良い選択をすることが重要です。特に若手エンジニアが多いチームでは、学習コストと安定性を重視するとよいでしょう。
🔍 チェックポイント
- 各技術の選定理由と代替技術の比較を説明できる
- 技術選定の考え方と重要な要素を理解している
- チームの状況に合わせた技術選定の方法を説明できる
- 技術選定がプロジェクトの成功にどう影響するか理解している
- ADRなどの意思決定プロセスの文書化方法を理解している
第7章:開発・テスト計画
📚 この章で学ぶこと
- アジャイル開発プロセスの実践方法
- 効率的な開発環境の構築方法
- 効果的なテスト戦略の立案
- デプロイメントと運用の計画
- 若手エンジニア向けの学習アプローチ
🔑 重要な概念
- アジャイル開発のプラクティス
- テスト駆動開発(TDD)と継続的インテグレーション
- DevOpsの考え方
- 段階的な学習と実装
7.1 開発プロセス
7.1.1 アジャイル開発方法論の採用
本プロジェクトでは、柔軟性と迅速な価値提供を重視し、スクラムをベースにしたアジャイル開発方法論を採用します。
スクラムフレームワークの実践:
- スプリント: 2週間のタイムボックス
- スプリントプランニング: スプリントの開始時に行い、作業項目を決定
- デイリースタンドアップ: 15分間の日次ミーティング
- スプリントレビュー: スプリント終了時に成果物をデモ
- スプリントレトロスペクティブ: プロセス改善のための振り返り
💡 学習ポイント
アジャイル開発は、変化に対応しながら価値を継続的に提供するための方法論です。「計画通りにすべてを実行する」のではなく、「計画を継続的に見直しながら進める」というマインドセットが重要です。
プロダクトバックログの管理:
- ユーザーストーリー形式での要件記述
- 優先順位付けと見積もり
- バックログリファインメントの定期実施
カンバンボードの活用:
- 「To Do」「In Progress」「Review」「Done」の基本レーン
- WIP(Work In Progress)制限の実施
- 視覚的な進捗管理
📝 若手エンジニア向けメモ
WIP制限とは、「進行中の作業数を制限する」という考え方です。多数のタスクを同時進行させるよりも、少数のタスクに集中して完了させていく方が、全体としての効率が高まります。マルチタスキングによるコンテキストスイッチのコストを減らすことができます。
7.1.2 ユーザーストーリーマッピング
ユーザーストーリーは単なる機能リストではなく、ユーザージャーニーに沿って構造化します。
-
バックボーン(主要活動)の特定:
- 「飲食店を検索する」
- 「検索結果をフィルタリングする」
- 「店舗詳細を確認する」
-
ストーリーの階層化:
- エピック: 大きな機能群(例: 「検索機能」)
- ストーリー: 実装可能な単位(例: 「キーワードで検索する」)
- タスク: 開発作業(例: 「検索APIエンドポイント実装」)
-
リリース計画への活用:
- MVP(Minimum Viable Product)の特定
- 段階的なリリース計画
- 優先順位の可視化
💡 学習ポイント
ユーザーストーリーマッピングは、「機能のリスト」ではなく「ユーザーの体験」に焦点を当てた要件整理の手法です。これにより、「技術的には完成しているがユーザーには価値がない」という状況を避け、各リリースが意味のある価値を提供できるようになります。
7.1.3 イテレーティブな開発アプローチ
段階的に機能を拡充していくアプローチを採用します。
リリースの段階計画:
-
フェーズ1(MVP): 8週間
- 基本的な検索機能
- 店舗詳細表示
- シンプルなフィルタリング
-
フェーズ2: 6週間
- 高度な検索機能(複合条件)
- レビュー情報の統合
- 検索結果のソートオプション
-
フェーズ3: 8週間
- 位置情報を活用した検索
- レコメンデーション機能
- 外部サービス連携
📝 若手エンジニア向けメモ
MVPとは「実用最小限の製品(Minimum Viable Product)」のことで、核となる価値を提供できる最小限の機能セットを意味します。まずはMVPをリリースし、ユーザーフィードバックを得ながら改善していくことで、無駄な機能開発を避け、本当に必要な機能に集中できます。
7.2 開発環境
7.2.1 ローカル開発環境
開発者のローカル環境は以下の構成とします:
-
Docker Compose:
- PostgreSQL、Elasticsearch、Redisコンテナ
- API開発用のPythonコンテナ
- バッチ開発用のPythonコンテナ
- ローカル開発用の軽量K8s(Minikube/K3s)
💡 学習ポイント
Dockerを使用することで、「自分のPCでは動くのに他の環境では動かない」という問題を解消できます。全ての開発者が同じ環境で開発することで、環境差異によるバグを防止できます。 -
開発ツール:
- VSCode/PyCharm(IDE)
- Git(バージョン管理)
- pre-commit hooks(コードスタイル、リンターの自動実行)
- pytest(テスト実行)
📝 若手エンジニア向けメモ
pre-commit hooksは、コミット前に自動的にコードのチェックを行うツールです。コードスタイルの統一やリンターによるバグの早期発見など、コード品質を維持するのに役立ちます。最初は面倒に感じるかもしれませんが、長期的には大きなメリットがあります。
7.2.2 共有開発環境
チーム共有の開発環境:
-
構成:
- 開発環境(dev): 最新のコードを継続的にデプロイ
- テスト環境(staging): リリース候補のテスト用
- CI/CD用インフラ(GitHub Actions + セルフホストランナー)
- 共有データベースインスタンス
💡 学習ポイント
共有開発環境は、チームメンバー全員が同じ環境でテストできる場を提供します。ローカル環境では再現が難しい問題の検証や、複数人での統合テストに役立ちます。 -
データ管理:
- 匿名化された本番データのサンプル
- テスト用データセットの共有
- データリセット機能
7.2.3 DevOpsプラクティス
開発と運用の統合を促進するDevOpsプラクティスを導入します:
-
インフラストラクチャ・アズ・コード(IaC):
- Terraform による AWS リソース管理
- Kubernetes マニフェストによるコンテナ構成管理
- Helmチャートの活用
-
GitOps ワークフロー:
- Gitリポジトリを真実の源泉(Source of Truth)とする
- 環境設定の変更もプルリクエストで管理
- 変更の自動適用(ArgoCD など)
-
継続的インテグレーション(CI):
- 自動テスト実行
- コード品質チェック
- セキュリティスキャン
-
継続的デリバリー(CD):
- 開発環境への自動デプロイ
- ステージング環境への承認ベースデプロイ
- カナリアリリースの実施
📝 若手エンジニア向けメモ
DevOpsは「Development(開発)」と「Operations(運用)」を融合させた考え方です。従来は分離していた開発チームと運用チームの壁を取り払い、協力して品質の高いソフトウェアを素早くリリースし続けることを目指します。自動化や標準化によって、人的ミスを減らし、デプロイの頻度と信頼性を高めることができます。
7.3 テスト戦略
7.3.1 テスト駆動開発(TDD)
コア機能の開発ではTDDアプローチを採用します:
- 赤: まず失敗するテストを書く
- 緑: テストを通す最小限のコードを書く
- リファクタリング: コードを改善しながらテストを通し続ける
# TDDの例: 検索サービスのテスト
def test_search_by_keyword_returns_matching_restaurants():
# 1. 前提条件のセットアップ
repository = MockRestaurantRepository()
repository.add(Restaurant(id="1", name="ラーメン太郎", cuisine_type="ラーメン"))
repository.add(Restaurant(id="2", name="寿司花子", cuisine_type="寿司"))
search_service = SearchService(repository)
# 2. テスト対象の機能実行
results = search_service.search(keyword="ラーメン")
# 3. 期待される結果の検証
assert len(results) == 1
assert results[0].id == "1"
assert results[0].name == "ラーメン太郎"
💡 学習ポイント
TDDは「テストを先に書く」ことで、明確な要件定義と設計を促進します。また、自動テストによる早期のフィードバックにより、バグの早期発見と修正が可能になります。さらに、必要最小限のコードを書く習慣が身につき、シンプルで保守性の高いコードにつながります。
7.3.2 テストピラミッド
テストの種類とバランスを考慮したテスト戦略を実施します:
-
ユニットテスト(基盤: 多数):
- 個々のクラス、メソッド、関数の検証
- モックを使用した外部依存の分離
- 高速な実行と迅速なフィードバック
-
統合テスト(中間層: 中程度):
- コンポーネント間の連携検証
- 実際のデータベースとの連携
- エンドポイントごとの機能検証
-
E2Eテスト(頂点: 少数):
- 実際のユーザーフローの検証
- UI自動テスト(フロントエンド開発時)
- 本番に近い環境での実行
📝 若手エンジニア向けメモ
テストピラミッドは、テストの種類とその割合に関するベストプラクティスです。ベースとなる「ユニットテスト」を多く、頂点の「E2Eテスト」を少なく設計することで、テスト実行速度と信頼性のバランスを取ります。E2Eテストは実行に時間がかかり、不安定になりがちですが、ユーザーの視点からシステム全体を検証できる重要なテストです。
7.3.3 コード品質の確保
自動化されたコード品質チェックを導入します:
-
静的解析:
- pylint/flake8: コードスタイルとバグの可能性チェック
- mypy: 型チェック
- bandit: セキュリティ脆弱性チェック
-
コードカバレッジ:
- pytest-cov: テストカバレッジ計測
- 目標カバレッジ: ビジネスロジック95%、その他80%以上
- プルリクエスト時のカバレッジチェック
-
コードレビュー:
- プルリクエストベースのレビュー
- コードオーナーによる承認フロー
- レビューチェックリストの活用
# GitHub Actions での品質チェック例
name: Code Quality Checks
on:
pull_request:
branches: [ main, develop ]
jobs:
quality:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.10'
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements-dev.txt
- name: Lint with flake8
run: flake8 .
- name: Type check with mypy
run: mypy .
- name: Security check with bandit
run: bandit -r .
- name: Run tests and check coverage
run: |
pytest --cov=app --cov-report=xml
coverage report --fail-under=80
💡 学習ポイント
静的解析ツールは、コードを実行せずに潜在的な問題を見つける強力な手段です。これらのツールをCI/CDパイプラインに組み込むことで、問題のあるコードがリポジトリに入り込むのを防ぎ、コードベースの品質を維持できます。また、型チェックなどは実行時エラーを事前に発見するのに役立ちます。
7.4 デプロイメント戦略
7.4.1 環境構成
段階的なデプロイメント環境:
-
開発環境(dev):
- 目的: 開発中の機能テスト
- データ: 匿名化した本番データのサブセット
- 更新頻度: 頻繁(1日複数回)
- アクセス: 開発チームのみ
📝 若手エンジニア向けメモ
開発環境は、新機能の開発やバグ修正のためのテスト環境です。本番環境との差異を最小限に抑えつつも、開発の自由度を確保するバランスが重要です。また、本番データを使用する場合は、個人情報などの機密データを適切に匿名化することが必須です。 -
ステージング環境(staging):
- 目的: リリース前の最終確認
- データ: 本番に近いデータセット
- 更新頻度: リリース前(週1-2回)
- アクセス: 開発チームとQAチーム
-
本番環境(production):
- 目的: 実サービス提供
- データ: 実データ
- 更新頻度: 計画的(月1-2回)
- アクセス: 厳格に制限
7.4.2 デプロイメント手法
安全で効率的なデプロイメントを実現する手法:
-
ブルー/グリーンデプロイメント:
- 2つの同一環境(ブルーとグリーン)を用意
- 片方に新バージョンをデプロイ
- テスト後にトラフィックを切り替え
- 問題発生時は即座に元の環境に戻せる
-
カナリアリリース:
- トラフィックの一部(例: 10%)だけを新バージョンに流す
- 段階的に新バージョンへのトラフィックを増やす
- 問題があれば早期に発見でき、影響範囲も限定的
💡 学習ポイント
従来の「ビッグバンリリース」(一度に全ての環境を新バージョンに切り替える)と比較して、ブルー/グリーンデプロイメントやカナリアリリースは、リスクを分散し、問題発生時の影響を最小化できます。特に本番環境での予期せぬ問題に対して素早く対応できる点が大きな利点です。
7.4.3 リリース管理
リリースプロセスの標準化と品質確保:
-
リリース計画:
- スプリントごとのリリース候補の特定
- リリースノートの作成
- 依存関係の確認
-
リリース前チェックリスト:
- 全テストの合格確認
- パフォーマンステストの実施
- セキュリティチェックの完了
- ドキュメントの更新
-
リリース後の検証:
- リリース直後のモニタリング強化
- カナリアリリースの段階的進行
- ロールバック手順の準備
📝 若手エンジニア向けメモ
リリース管理は、「作ったものを安全に届ける」プロセスです。いくら良い機能を開発しても、リリース時にトラブルが発生しては意味がありません。リリース計画の立案、事前確認、リリース実行、事後確認という一連のプロセスを標準化することで、安定したリリースが可能になります。
7.5 運用計画
7.5.1 日常運用
日々の運用タスク:
-
監視:
- ダッシュボード確認(1日2回)
- アラート対応(随時)
- パフォーマンス傾向分析(週1回)
-
バックアップ:
- データベース: 日次フルバックアップ + 時間単位増分
- 設定ファイル: 変更時バックアップ
- ログ: 週次アーカイブ
💡 学習ポイント
バックアップは取るだけでなく、「リストア(復元)」のテストも定期的に行うことが重要です。実際の障害時にバックアップからの復旧ができなければ、バックアップの意味がありません。 -
定期メンテナンス:
- OS/ミドルウェアパッチ適用(月1回)
- 不要データのクリーンアップ(月1回)
- パフォーマンス分析と改善(隔月)
7.5.2 障害対応
障害発生時の対応手順:
-
検知:
- 自動アラート
- ユーザー報告
- 定期チェック
📝 若手エンジニア向けメモ
障害は早期発見が重要です。ユーザーからの報告を待つのではなく、監視システムによる自動検知を目指しましょう。「ユーザーより先に問題を知る」ことがベストです。 -
初期対応:
- 影響範囲の評価
- 一時的な緩和策の実施
- 関係者への通知
💡 学習ポイント
初期対応では、まず影響範囲を把握し、可能な限り迅速に影響を最小化する「緩和策」を講じることが重要です。例えば、問題のあるサーバーを一時的に切り離す、キャッシュを活用するなどの対応が考えられます。 -
根本解決:
- 原因分析
- 修正実施
- 確認テスト
-
事後処理:
- 障害報告書作成(ポストモーテム)
- 再発防止策の実施
- 監視・アラートの見直し
7.5.3 SRE(Site Reliability Engineering)のプラクティス
信頼性の高いサービス運用のためのSREプラクティス:
-
SLO (Service Level Objectives)の設定と追跡:
- 可用性、レイテンシ、エラー率などの目標値
- エラーバジェットの概念の導入
-
障害対応の自動化:
- Runbook の整備
- 自動修復の仕組み導入
- ChatOps によるオペレーション効率化
-
継続的な改善:
- ポストモーテム文化の醸成
- 「非難なし」の原則
- 再発防止に重点を置く
💡 学習ポイント
SREは、Googleが提唱したサービスの信頼性を向上させるための考え方と実践手法です。従来の「運用」をソフトウェアエンジニアリングの視点で捉え直し、自動化や定量的分析を重視します。特に「エラーバジェット」という考え方は、信頼性と革新のバランスを取るための有効な手段です。
7.6 若手エンジニア向け:段階的な学習アプローチ
本システムは複雑ですが、段階的に学習することで理解を深めながら進めることができます。以下に、若手エンジニア向けの学習ステップを示します。
7.6.1 基礎フェーズ(1-2ヶ月)
目標: システムの基本的な構造と主要技術の理解
学習内容:
- Python基礎とFastAPI入門
- PostgreSQLの基本操作
- RESTful APIの概念理解
- Gitによるバージョン管理
📝 実践タスク例
- 簡単なCRUD操作を行うAPIエンドポイントの実装
- PostgreSQLを使ったデータベース操作
- Gitを使ったコード管理と簡単なプルリクエスト
7.6.2 応用フェーズ(2-3ヶ月)
目標: システムの主要コンポーネントの実装と連携
学習内容:
- API開発の応用(パラメータ検証、エラーハンドリング)
- Elasticsearchによる検索実装
- ユニットテストとテスト駆動開発
- Docker基礎
📝 実践タスク例
- APIの拡張と改善
- Elasticsearchを使った検索機能の実装
- 作成したコードのユニットテスト作成
- Dockerを使った開発環境の構築
7.6.3 発展フェーズ(3-6ヶ月)
目標: システム全体の理解と高度な機能の実装
学習内容:
- 高度なAPI機能(キャッシュ、非同期処理)
- Redis キャッシュの活用
- パフォーマンスチューニング
- CI/CDとDevOpsの実践
📝 実践タスク例
- Redisを使ったキャッシュ機能の導入
- APIのパフォーマンス最適化
- GitHub Actionsを使ったCI/CDの構築
- Kubernetes上での展開
7.6.4 学習のコツ
-
小さく始めて継続する:
- 「1日30分」など、無理のない範囲から始める
- 習慣化のために同じ時間帯に学習する
- 小さな成功体験を積み重ねる
-
アクティブラーニング:
- 受動的な読書ではなく、実際にコードを書く
- 疑問点を実験で確かめる
- 「分かった気」にならずに実践する
-
チームでの学び合い:
- わからないことは先輩に質問する
- 学んだことを他のメンバーと共有する
- コードレビューを積極的に活用する
💡 学習ポイント
学習の進捗は人それぞれです。自分のペースで着実に進めることが大切です。また、全ての技術を深く理解する必要はなく、必要な部分から優先的に学んでいくことが効率的です。
7.7 アジャイル開発とウォーターフォール開発の比較
プロジェクトの特性に応じた開発手法の選択のために、主要な開発方法論の比較を行います。
7.7.1 開発手法の特徴
| 特徴 | アジャイル | ウォーターフォール |
|---|---|---|
| 開発サイクル | 反復的、インクリメンタル | 線形、シーケンシャル |
| 要件の柔軟性 | 変更に対応 | 最初に固定 |
| 顧客フィードバック | 頻繁(スプリントごと) | 主に開発後 |
| ドキュメンテーション | 必要最小限 | 包括的 |
| リスク管理 | 早期発見・対応 | 前工程での予測 |
| 適したプロジェクト | 変化が予想される、革新的 | 要件が明確、規制が厳しい |
| チーム構成 | 小規模、クロスファンクショナル | 専門性に基づく分業 |
7.7.2 ハイブリッドアプローチ
実際のプロジェクトでは、両方の手法の長所を取り入れたハイブリッドアプローチが有効な場合もあります:
- 計画段階: 要件の明確化、大まかなアーキテクチャ設計など、ウォーターフォール的なアプローチ
- 実装段階: 機能ごとの反復的な開発、定期的なレビューなど、アジャイル的なアプローチ
- リリース段階: 体系的なテスト、ドキュメント整備など、ウォーターフォール的なアプローチ
📝 若手エンジニア向けメモ
どの開発手法が「正しい」ということはなく、プロジェクトの性質(規模、複雑さ、要件の明確さ、リスク許容度など)に合わせて適切な手法を選択または組み合わせることが重要です。また、手法自体よりも、チームの協働やコミュニケーションといった原則を重視することで、どの手法でも成功確率を高められます。
7.7.3 本プロジェクトでのアジャイル採用理由
本プロジェクトでアジャイルを採用した主な理由:
- 要件の不確実性: ユーザーニーズが全て明確でなく、フィードバックを取り入れながら進化させる必要がある
- 技術的な探索: いくつかの技術選択や実装アプローチは実際に試しながら評価する必要がある
- 早期価値提供: コア機能から段階的にリリースすることで、早期に価値を提供し、フィードバックを得たい
- チーム構成: 小規模な横断的チームで柔軟に協力しながら開発を進める体制に適している
🔍 チェックポイント
- アジャイル開発のプラクティスと利点を説明できる
- テストピラミッドの考え方と各テストレベルの目的を理解している
- CI/CDパイプラインの構成要素と利点を説明できる
- デプロイメント手法(ブルー/グリーン、カナリア)の違いを理解している
- 若手エンジニアとしての段階的な学習アプローチを計画できる
第8章:技術的な考慮事項
📚 この章で学ぶこと
- データ収集APIの効率的な利用方法
- データ処理とストレージの最適化テクニック
- 検索パフォーマンスを向上させる方法
- 運用管理を容易にするアプローチ
🔑 重要な概念
- APIアクセスの最適化
- データの正規化と統合
- 検索インデックスの最適化
- 監視とロギングの重要性
8.1 データ収集の効率化と安定性
8.1.1 API利用の最適化
外部APIを安定して効率的に利用するための戦略:
-
レート制限の遵守:
- APIごとの制限に合わせた呼び出し頻度の調整
- バースト制限と時間枠制限の両方を考慮
- トークンバケットアルゴリズムの実装
💡 学習ポイント
トークンバケットアルゴリズムは、API呼び出しのレート制限を実装する効果的な方法です。一定の間隔でバケットにトークンが追加され、各API呼び出しでトークンを消費します。バケットが空になると、トークンが追加されるまで待機します。 -
エラー処理:
- 一時的なエラーの自動リトライ
- 指数バックオフアルゴリズム
- 永続的なエラーの記録と通知
# 指数バックオフを用いたAPIリクエスト例
def fetch_with_retry(url, max_retries=5, base_delay=1, max_delay=60):
retries = 0
while retries < max_retries:
try:
response = requests.get(url, timeout=10)
response.raise_for_status()
return response.json()
except (requests.exceptions.RequestException, ValueError) as e:
retries += 1
if retries >= max_retries:
logger.error(f"Failed after {max_retries} attempts: {url}")
raise MaxRetriesExceeded(f"Failed after {max_retries} attempts") from e
# 指数バックオフ計算 (1, 2, 4, 8, 16...)
delay = min(base_delay * (2 ** (retries - 1)), max_delay)
# ランダム要素の追加 (±30%)
jitter = random.uniform(0.7, 1.3)
sleep_time = delay * jitter
logger.warning(f"Retry {retries}/{max_retries} after {sleep_time:.2f}s due to: {e}")
time.sleep(sleep_time)
-
認証管理:
- APIキーやトークンの安全な保管
- トークン更新の自動化
- 複数アカウントでの負荷分散(必要な場合)
8.1.2 バッチ処理の効率化
バッチ処理の最適化手法:
-
並列処理:
- マルチスレッドまたはマルチプロセス
- 非同期I/O(asyncio)の活用
- タスクキューシステム(Celery等)の活用
📝 若手エンジニア向けメモ
並列処理は処理速度を向上させますが、適切なタスク分割とリソース管理が重要です。特にI/O待ちの多いタスク(APIリクエストなど)では、非同期処理が効果的です。 -
バッチサイズの最適化:
- メモリ使用量とスループットのバランス
- 変動するデータ量への対応
- 処理の進捗を追跡可能な粒度
-
障害復旧:
- チェックポイント機能
- 再開可能な設計
- トランザクション整合性の確保
8.2 データ処理とストレージ
8.2.1 データ検証と正規化
収集したデータに対して以下の処理を行います:
-
データ検証:
- スキーマ検証
- 必須項目の確認
- データ型チェック
- 異常値検出
📝 若手エンジニア向けメモ
データ検証は、不正なデータがシステムに入り込むのを防ぐ最初の防衛線です。例えば、電話番号が数字とハイフンのみで構成されているか、郵便番号が正しい形式かなどをチェックします。 -
データ正規化:
- 住所の正規化(都道府県、市区町村、番地などの分離)
- 電話番号の正規化(ハイフン統一など)
- 営業時間の構造化(開始時間、終了時間の分離)
- 料理ジャンルの標準化(表記揺れ対応)
💡 学習ポイント
異なるソースから収集したデータは、同じ情報でも表記が異なる場合があります。例えば、「イタリアン」と「イタリア料理」は同じカテゴリを指しますが、表記が違います。これらを統一することで、検索や集計が正確になります。
8.2.2 重複検出と統合
同一店舗の特定と情報統合のための処理:
-
重複検出アルゴリズム:
- 店名の類似度計算(レーベンシュタイン距離など)
- 位置情報の近接性評価(地理的距離)
- 電話番号の一致確認
- 複合スコアリングによる判定
📝 若手エンジニア向けメモ
レーベンシュタイン距離とは、2つの文字列がどれだけ似ているかを数値化する方法の一つです。例えば、「すし太郎」と「寿司太郎」は表記は違いますが、類似度が高いと判断できます。 -
情報統合ルール:
- 情報源の信頼性による優先順位付け
- 最新データの優先
- 詳細度の高いデータの優先
- 矛盾するデータの解決戦略
8.2.3 データベース最適化
パフォーマンスとスケーラビリティを確保するためのデータベース設計:
-
インデックス戦略:
- 検索クエリに適したインデックス設計
- 複合インデックスの活用
- インデックス更新オーバーヘッドの考慮
💡 学習ポイント
インデックスは検索を高速化しますが、書き込み時のオーバーヘッドも増加させます。よく使われる検索条件に合わせてインデックスを設計し、不要なインデックスは作成しないことが重要です。 -
パーティショニング:
- 地域別または時間別のデータ分割
- クエリパフォーマンスの向上
- メンテナンス性の向上
-
読み取りレプリケーション:
- 読み取り負荷の分散
- 地理的な冗長性
- レプリケーション遅延の考慮
8.3 検索パフォーマンスの最適化
8.3.1 Elasticsearchインデックス設計
効率的な検索を実現するためのElasticsearchインデックス設計:
-
インデックス戦略:
- 季節や地域に基づくシャーディング
- 適切なシャード数の設定
- レプリカによる冗長性と読み取りパフォーマンスの向上
📝 若手エンジニア向けメモ
Elasticsearchのインデックスは、内部的に「シャード」と呼ばれる単位に分割されます。適切なシャード数とサイズの設定が、パフォーマンスに大きく影響します。シャードが多すぎると管理オーバーヘッドが増加し、少なすぎると並列処理の恩恵を受けられません。 -
マッピング最適化:
- フィールドタイプの最適化
- 解析器の適切な選択
- マルチフィールド定義(例:同じデータに対して全文検索用と完全一致検索用の両方のフィールドを定義)
// 店名フィールドのマルチフィールド定義例
"name": {
"type": "text",
"analyzer": "kuromoji",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
8.3.2 クエリ最適化
検索クエリの効率化方法:
-
クエリ構造の最適化:
- フィルターコンテキストの活用(bool/filter)
- クエリ文字列の事前解析と最適化
- 複合条件の効率的な構築
💡 学習ポイント
Elasticsearchでは、「クエリコンテキスト」と「フィルターコンテキスト」という2つの検索モードがあります。スコアリング(関連度計算)が必要ない条件は、フィルターコンテキストで記述することで、パフォーマンスが向上し、結果もキャッシュされやすくなります。 -
ページネーション最適化:
- search_after方式の採用(深いページ対応)
- カーソルベースのページネーション
- 最大結果数の制限(10,000件)
-
集約クエリの最適化:
- ファセット検索の効率的な実装
- 適切なバケットサイズ
- キャッシュの活用
8.3.3 キャッシュ戦略
Redisを使った効果的なキャッシュ戦略:
-
キャッシュレベル:
- クエリレベル: 同一検索条件の結果をキャッシュ
- エンティティレベル: 頻繁にアクセスされる個別店舗情報
- 計算値レベル: 集計結果や導出データ
-
TTL(生存時間)設定:
- 人気検索クエリ: 1時間
- 店舗詳細情報: 24時間
- ランキングデータ: 12時間
- メタデータ: 48時間
📝 若手エンジニア向けメモ
キャッシュの「鮮度」と「ヒット率」はトレードオフの関係にあります。TTL(Time To Live)を短くすると最新データが反映されやすくなりますが、キャッシュミスが増えてデータベースへの負荷が高まります。逆に長くすると古いデータが表示される可能性がありますが、キャッシュヒット率が向上します。 -
キャッシュ無効化戦略:
- 更新イベントに基づく選択的無効化
- パターンベースの無効化(プレフィックス指定)
- 定期的な全キャッシュ更新(深夜)
8.4 運用管理の容易性
8.4.1 ログ収集と分析
効果的なログ管理戦略:
-
ログ構造:
- JSON形式の構造化ログ
- 標準フィールド(タイムスタンプ、レベル、コンポーネントなど)
- コンテキスト情報(リクエストID、ユーザーIDなど)
- 詳細エラー情報(スタックトレースなど)
💡 学習ポイント
構造化ログ(特にJSON形式)は、後からの検索や分析が容易です。例えば、特定のユーザーに関するログだけを抽出したり、エラーレベルごとに集計したりといった操作が簡単になります。また、リクエストIDのような「相関ID」を各ログに含めることで、複数のコンポーネントを跨ぐ一連の処理を追跡することができます。 -
集中ログ管理:
- ELK(Elasticsearch, Logstash, Kibana)スタックの活用
- ログの集約と検索機能
- ダッシュボードによる可視化
-
ログの活用方法:
- パターン分析によるシステム診断
- 異常検知のためのベースライン確立
- ユーザー行動分析への応用
8.4.2 メトリクス収集
システムのパフォーマンスと状態を監視するためのメトリクス収集:
-
収集すべきメトリクス:
- インフラメトリクス(CPU, メモリ, ディスク, ネットワーク)
- アプリケーションメトリクス(レスポンス時間, エラー率, リクエスト数)
- ビジネスメトリクス(ユーザーアクション, 機能利用状況)
-
監視ダッシュボード:
- リアルタイムモニタリング
- トレンド分析
- アラート状態の可視化
📝 若手エンジニア向けメモ
メトリクスは、システムの健全性を数値で表します。例えば、「レスポンス時間が急に長くなった」「エラー率が上昇した」などの異常を早期に検知できるようになります。また、時系列データとして蓄積することで、システムの変化を追跡し、将来の傾向を予測することも可能になります。
8.4.3 コンテナ監視
コンテナ環境でのモニタリング:
-
Kubernetes監視:
- ノードとポッドの健全性
- リソース使用率
- オートスケーリングイベント
-
サービスメッシュ:
- サービス間通信の監視
- トレーシングの実装
- トラフィック制御
-
DevOpsツールの連携:
- CI/CDパイプラインとの連携
- 障害検知時の自動ロールバック
- セルフヒーリング機能
8.4.4 セキュリティ監視
セキュリティの継続的な監視と対応:
-
脆弱性スキャン:
- コードスキャン(SAST)
- コンテナイメージスキャン
- 依存パッケージのセキュリティ監視
-
異常検知:
- 異常なアクセスパターンの検出
- 権限昇格の監視
- データ流出の兆候検知
-
インシデント対応:
- セキュリティイベントの自動分類
- インシデント対応ワークフローの自動化
- セキュリティチームとの連携
8.5 若手エンジニア向け解説:実装時の注意点
システムを実装する際に、若手エンジニアが特に注意すべきポイントをいくつか紹介します:
8.5.1 コードの品質
-
シンプルさを重視する:
- 複雑な解決策より、理解しやすいシンプルな解決策を選ぶ
- 「賢すぎる」コードは保守が難しくなりがち
- 「今日の賢いコードは明日のレガシーコード」という格言を覚えておく
-
ドキュメントとコメント:
- コードは「何をしているか」、コメントは「なぜそうしているか」を説明
- 複雑なロジックには必ずコメントを残す
- 関数やクラスには適切なドキュメント文字列を記述
-
エラー処理:
- 例外は具体的に捕捉し、漠然とした except: は避ける
- エラーメッセージは具体的かつ有用な情報を含める
- ユーザーに表示するエラーと内部ログは区別する
# 良くない例 try: data = process_data() except: print("Error occurred") # 良い例 try: data = process_data() except ValueError as e: logger.error(f"Invalid data format: {e}") return {"error": "データの形式が不正です"} except IOError as e: logger.error(f"Failed to read data: {e}") return {"error": "データの読み込みに失敗しました"}
8.5.2 パフォーマンスの考慮
-
早すぎる最適化を避ける:
- まずは正しく動作するコードを書く
- 実際にボトルネックが特定された部分のみ最適化する
- プロファイリングツールを活用して問題箇所を特定する
-
メモリ使用量に注意:
- 大量のデータを扱う場合は、ストリーミング処理を検討
- 不要なオブジェクトは適切に解放する
- 特に長時間実行するバッチ処理ではメモリリークに注意
-
データベースアクセスの最適化:
- 必要最小限のデータだけを取得する(全カラムの取得を避ける)
- 適切なインデックスを設定する
- N+1問題を避ける(ループ内でのデータベースクエリ)
# 良くない例(N+1問題) restaurants = db.query(Restaurant).all() for restaurant in restaurants: reviews = db.query(Review).filter(Review.restaurant_id == restaurant.id).all() # レビュー処理... # 良い例(ジョインを使用) restaurants_with_reviews = db.query(Restaurant).join(Review).all()
8.5.3 セキュリティの基本
-
ユーザー入力の検証:
- すべての入力データをバリデーションする
- クライアント側の検証だけでなく、サーバー側でも必ず検証する
- パラメータ化されたクエリを使用してSQLインジェクションを防ぐ
-
機密情報の管理:
- パスワードやAPIキーなどをハードコーディングしない
- 環境変数や設定ファイルを使用する
- バージョン管理システムに機密情報をコミットしない
-
適切な権限管理:
- 最小権限の原則に従う
- データベースアクセスやAPIアクセスに適切な権限制限を設ける
- デフォルトで「拒否」し、必要な権限のみを明示的に許可する
8.5.4 デバッグとトラブルシューティング
-
効果的なロギング:
- 適切なログレベルを使い分ける(DEBUG, INFO, WARNING, ERROR, CRITICAL)
- コンテキスト情報を含めたログメッセージを残す
- 機密情報はログに残さない
-
段階的なデバッグ:
- 問題を小さく分割して一つずつ解決する
- 仮説を立ててテストするアプローチを取る
- デバッグツール(pdb, ipdb など)の活用
-
リグレッションテスト:
- バグ修正後は、同じバグが再発しないことを確認するテストを追加
- 「これは直ったはず」と思い込まず、必ず検証する
- 自動テストでカバーできない場合は、手順書を残す
💡 学習ポイント
コーディングは技術的なスキルだけでなく、「職人技」の側面もあります。良いコードを書くには経験が必要ですが、先人の知恵(設計パターン、ベストプラクティスなど)を学ぶことで近道ができます。また、他の人のコードを読むことも非常に効果的な学習方法です。
📝 若手エンジニア向けメモ
完璧なコードを書こうとして身動きが取れなくなるよりも、まずは「動くコード」を書き、それを徐々に改善していく方がはるかに効率的です。また、わからないことを質問することは決して恥ではありません。むしろ、質問しないことの方が長期的には問題を引き起こします。
🔍 チェックポイント
- API利用の最適化方法(レート制限、エラー処理など)を理解している
- データ処理とストレージの最適化テクニックを説明できる
- Elasticsearchでのインデックス設計とクエリ最適化のポイントを理解している
- ログ収集とメトリクス監視の重要性と実装方法を説明できる
- コード品質、パフォーマンス、セキュリティの基本的な考慮事項を理解している
第9章:将来の拡張性
📚 この章で学ぶこと
- システムの長期的な成長と進化の計画
- 機能と容量の両面での拡張性の確保方法
- 技術的な負債を最小限に抑えるアプローチ
- マイクロサービスへの段階的移行戦略
🔑 重要な概念
- スケーラブルなアーキテクチャ設計
- 段階的な機能拡張のプランニング
- 技術的な柔軟性と変更容易性
- ドメイン駆動設計による境界の明確化
9.1 機能拡張ロードマップ
将来的に実装を検討している機能:
-
フェーズ2:
- 予約状況の表示と連携
- メニュー情報の拡充
- モバイルアプリ対応のAPI拡張
📝 若手エンジニア向けメモ
機能拡張は、ユーザーの需要や技術的な実現可能性を考慮して計画することが重要です。また、各フェーズで追加する機能は、互いに関連性があるものをグループ化すると、開発効率や一貫性の面でメリットがあります。例えば、予約機能とメニュー情報は、ユーザーが予約する際の判断材料として関連性が高いです。 -
フェーズ3:
- パーソナライズされたレコメンデーション機能
- ソーシャルサインインと口コミ機能
- 高度な検索フィルター(アレルギー対応、席タイプなど)
💡 学習ポイント
大きな機能追加(例:レコメンデーション機能)は、アーキテクチャやデータモデルに大きな影響を与える可能性があります。そのため、初期設計の段階から、そのような拡張の可能性を考慮しておくことが重要です。例えば、ユーザープロファイルや行動履歴をモデル化できるような柔軟なデータ構造を採用しておくと良いでしょう。 -
フェーズ4:
- 他業種(宿泊施設、観光スポットなど)への拡大
- AI搭載チャットインターフェース
- APIマーケットプレイス(サードパーティ開発者向け)
📝 若手エンジニア向けメモ
長期的な拡張計画は、ビジョンを持って進めることが大切ですが、市場やユーザーニーズの変化に応じて柔軟に調整する準備も必要です。また、各フェーズの終了時には、次のフェーズの内容を見直し、優先順位を再評価するプロセスを設けることをお勧めします。
9.1.1 機能拡張の設計原則
新機能追加時に考慮すべき設計原則:
-
既存機能との整合性:
- 一貫したユーザー体験
- 統一された用語と概念
- 相互運用性の確保
-
拡張ポイントの活用:
- プラグインアーキテクチャの利用
- 設定による機能拡張
- フィーチャーフラグの活用
-
段階的リリース:
- A/Bテストによる検証
- カナリアリリースの活用
- フィードバックループの確立
💡 学習ポイント
フィーチャーフラグ(機能フラグ)は、コードベースに新機能を安全に追加するための手法です。フラグの状態に応じて機能をオン/オフできるため、まだ完成していない機能を本番環境にデプロイし、特定のユーザーや内部テスターのみに公開することができます。これにより、継続的デリバリーを実現しながらも、ユーザーへの影響を制御できます。
9.2 スケーリングプラン
システムの成長に対応するためのスケーリング計画:
9.2.1 水平スケーリング
-
APIサーバーのスケーリング:
- インスタンス数の自動調整(Kubernetes HPA)
- リージョン別デプロイメント
- グローバルロードバランシング
💡 学習ポイント
「水平スケーリング」とは、サーバーの数を増やすことでシステムの処理能力を向上させるアプローチです。これには、サーバー間でステートを共有しない「ステートレス」な設計が前提となります。例えば、セッション情報をサーバーではなくRedisなどの共有ストレージに保存することで、どのサーバーがリクエストを処理しても同じ結果が得られるようになります。 -
データベースのスケーリング:
- 読み取りレプリカの追加
- シャーディングの導入
- 連合クエリの最適化
-
検索エンジンのスケーリング:
- クラスターノードの追加
- インデックスのシャーディング
- データ分布の最適化
9.2.2 垂直スケーリング
-
リソース割り当ての最適化:
- ワークロードパターンに基づく設計
- 自動スケーリング(垂直)の設定
- パフォーマンス指標に基づく調整
📝 若手エンジニア向けメモ
「垂直スケーリング」とは、サーバーのスペック(CPU、メモリなど)を向上させることです。水平スケーリングと比較して実装は簡単ですが、単一サーバーの限界があります。コスト効率を考慮しつつ、水平スケーリングと垂直スケーリングを適切に組み合わせることが重要です。 -
データベースインスタンスサイズ:
- 段階的なアップグレードパス
- 読み取り/書き込み分離
- 専用インスタンスタイプの選定
9.2.3 キャッシュスケーリング
-
マルチレイヤーキャッシュ:
- エッジキャッシュ(CDN)
- アプリケーションキャッシュ
- データベースクエリキャッシュ
-
分散キャッシュクラスター:
- Redis Clusterの構成
- シャード分散戦略
- フェイルオーバー設定
-
キャッシュ効率の最適化:
- TTL階層化(頻度に応じた保存期間)
- プリウォーミング戦略
- 適応的キャッシュポリシー
📝 若手エンジニア向けメモ
キャッシュは「早すぎる最適化」の罠に陥りやすい領域です。複雑なキャッシュ戦略を最初から実装するのではなく、まずは単純なキャッシュから始め、実際のワークロードやボトルネックを観測した後で、必要に応じて高度な戦略を導入していくことをお勧めします。
9.2.4 フェーズ別のスケーリングポイント
| フェーズ | 予想負荷 | スケーリングポイント | 対策 |
|---|---|---|---|
| 初期 | ~100 req/min | なし | 単一インスタンスで対応 |
| 成長期 | ~1,000 req/min | APIサーバー | ロードバランサー導入、インスタンス数3-5に増加 |
| 成熟期 | ~5,000 req/min | データベース、キャッシュ | PostgreSQLのレプリケーション、Elasticsearchクラスター拡張、Redisクラスター導入 |
| 拡大期 | 10,000+ req/min | 全コンポーネント | データベースシャーディング、CDN導入、マイクロサービス化検討 |
💡 学習ポイント
スケーリングは「必要になったときに」行うことが重要です。過度に先を見越した設計は複雑性を増し、開発速度を低下させる可能性があります。代わりに、将来のスケーリングを容易にするための「拡張ポイント」を設計時に考慮しておくという考え方がおすすめです。また、定期的な負荷テストを実施し、システムの限界を把握しておくことも大切です。
9.3 マイクロサービスへの進化
9.3.1 マイクロサービス移行戦略
モノリスからマイクロサービスへの段階的な移行アプローチ:
-
ドメインの分析と境界の特定:
- 業務機能に基づくドメイン分割
- 結合度と凝集度の評価
- 通信パターンの分析
-
ストラングラーフィグパターン:
- 新機能をマイクロサービスとして実装
- 既存機能の段階的な移行
- APIゲートウェイを使った統合
💡 学習ポイント
ストラングラーフィグパターン(Strangler Fig Pattern)は、モノリスからマイクロサービスへの移行を段階的に行うアプローチです。名前は、大きな木に絡みつき、最終的に元の木を覆い尽くすイチジクツルの成長パターンに由来しています。このパターンでは、モノリスを一度に置き換えるのではなく、機能ごとに段階的にマイクロサービスに移行していきます。 -
サービスメッシュの導入:
- サービス間通信の標準化
- 分散トレーシングの実現
- 認証・認可の一元管理
9.3.2 候補マイクロサービス
将来的に分割が考えられる主要なマイクロサービス:
-
検索サービス:
- 全文検索機能
- 検索クエリ処理
- 検索結果ランキング
-
データ収集サービス:
- 外部ソース連携
- データ変換と正規化
- データ整合性管理
-
レコメンデーションサービス:
- ユーザープロファイリング
- 協調フィルタリング
- コンテキスト対応推薦
-
ユーザー管理サービス:
- 認証・認可
- プロファイル管理
- プリファレンス設定
📝 若手エンジニア向けメモ
マイクロサービスはしばしば銀の弾丸として語られますが、モノリスにも多くの利点(シンプルさ、開発効率など)があります。小規模なチームやプロジェクトの初期段階では、むしろモノリスの方が適している場合が多いです。マイクロサービスへの移行は、システムの複雑さや規模が十分に大きくなってから検討するのが一般的です。
9.3.3 サービス間通信設計
マイクロサービス化に備えた通信設計:
-
同期通信方式:
- REST API(HTTP/HTTPS)
- gRPC(高性能RPC)
- GraphQL(柔軟なクエリ)
-
非同期通信方式:
- メッセージキュー(RabbitMQ, Kafka)
- イベント駆動アーキテクチャ
- パブリッシュ/サブスクライブモデル
💡 学習ポイント
マイクロサービス間の通信方式には、同期通信と非同期通信の2つの大きなアプローチがあります。同期通信はレスポンスを待つ形式で、実装はシンプルですが、依存関係が強くなります。非同期通信は、メッセージを送信して処理を続行する形式で、耐障害性が高く疎結合になりますが、実装の複雑さが増します。システムの要件に応じて適切な方式を選択することが重要です。 -
データ整合性の確保:
- SAGA パターン
- イベントソーシング
- 最終的な一貫性の受け入れ
9.4 技術更新計画
技術的な柔軟性を確保するための計画:
9.4.1 技術スタックの更新
-
バックエンドフレームワーク:
- FastAPI → FastAPI 2.0 / Starlette
- 非同期処理の強化
-
データベース:
- PostgreSQL → PostgreSQL 15+ / CockroachDB
- 分散データベースへの移行検討
-
検索エンジン:
- Elasticsearch → Elasticsearch 8+ / OpenSearch
- ベクトル検索機能の活用
9.4.2 新技術の導入検討
-
サーバーレスコンピューティング:
- AWS Lambda / Google Cloud Functions
- バッチ処理のサーバーレス化
- コスト効率とスケーラビリティの向上
-
コンテナオーケストレーション:
- Kubernetesの本格活用
- サービスメッシュ(Istio)の導入
- GitOpsによるデプロイメント自動化
-
AIと機械学習:
- レコメンデーションエンジンの強化
- 自然言語処理によるクエリ理解
- 画像認識によるメニュー分析
📝 若手エンジニア向けメモ
新技術の導入は、明確なメリットがある場合に行うべきです。「流行っているから」という理由だけで新技術を採用すると、不必要な複雑さやリスクを招く可能性があります。新技術を評価する際は、学習コスト、移行コスト、運用コスト、そして何よりも「解決したい問題に対する適合性」を十分に検討することが重要です。
9.4.3 技術的負債の管理
-
定期的なリファクタリング:
- 四半期ごとの技術的負債スプリント
- コードの品質指標の監視
- 自動テストカバレッジの維持
-
依存関係の管理:
- ライブラリの定期的な更新
- 脆弱性スキャンの自動化
- 非推奨APIの置き換え計画
-
ドキュメントの更新:
- アーキテクチャ決定記録(ADR)の維持
- コードとドキュメントの一貫性確保
- ナレッジベースの継続的改善
💡 学習ポイント
「技術的負債」とは、短期的な解決策を選ぶことで将来的に追加のコストが発生することを指します。例えば、時間的制約から十分なテストを書かずにリリースしたコードは、将来的にバグが発生しやすく、保守も難しくなります。技術的負債は完全に避けることはできませんが、その存在を認識し、定期的に「返済」(リファクタリングなど)することが重要です。
9.5 クラウドネイティブへの進化
9.5.1 クラウドネイティブアーキテクチャへの移行
-
コンテナ化:
- すべてのコンポーネントのDockerコンテナ化
- マルチステージビルドの採用
- イメージサイズの最適化
-
オーケストレーション:
- Kubernetes環境への完全移行
- Helmチャートによるデプロイメント
- カスタムオペレーターの開発
-
クラウドサービスの活用:
- マネージドデータベース(RDS, Aurora)
- マネージドElasticsearch(Amazon ES, Elastic Cloud)
- クラウドネイティブな監視・ロギング(CloudWatch, Datadog)
9.5.2 マルチクラウド戦略
-
クラウドベンダーロックインの回避:
- 抽象化レイヤーの使用
- クラウド間の相互運用性の確保
- フェイルオーバー戦略の設計
-
リージョン戦略:
- 地理的な冗長性の確保
- データレジデンシーの考慮
- リージョン間レプリケーション
-
コスト最適化:
- 動的リソース割り当て
- スポットインスタンスの活用
- リザーブドインスタンスとセービングプランの検討
📝 若手エンジニア向けメモ
クラウドネイティブ化は、単にアプリケーションをクラウドに移行するだけではなく、クラウドの特性(スケーラビリティ、弾力性、従量課金など)を最大限に活用するようにアーキテクチャを再設計することを意味します。例えば、常時稼働のサーバーではなく、オンデマンドで起動するサービスを使うことで、コスト効率を大幅に向上させることができます。
9.6 若手エンジニア向け解説:将来を見据えた設計
システムの将来的な拡張性を確保するためのポイントをいくつか紹介します:
9.6.1 拡張性を考慮した設計原則
-
インターフェースと実装の分離:
- 抽象インターフェースを定義し、具体的な実装はその背後に隠す
- これにより、実装を変更しても、インターフェースを利用する側への影響を最小限に抑えられる
- 例:データアクセス層をインターフェースで定義し、PostgreSQLからMongoDBに変更してもビジネスロジック層は変更不要
# 良い例(インターフェースと実装の分離) class RestaurantRepository: """レストランデータアクセスのインターフェース""" def find_by_name(self, name): raise NotImplementedError class PostgresRestaurantRepository(RestaurantRepository): """PostgreSQLを使った実装""" def find_by_name(self, name): # PostgreSQL固有の実装 pass class ElasticsearchRestaurantRepository(RestaurantRepository): """Elasticsearchを使った実装""" def find_by_name(self, name): # Elasticsearch固有の実装 pass -
設定の外部化:
- ハードコードされた値を避け、設定ファイルや環境変数で外部から設定可能にする
- これにより、コードを変更せずに動作を調整できる
- 例:データベース接続情報、バッチ処理の頻度、キャッシュのTTLなど
# 良い例(設定の外部化) import os from dotenv import load_dotenv load_dotenv() class Config: """設定クラス""" DATABASE_URL = os.getenv("DATABASE_URL", "postgresql://localhost/restaurant_db") ELASTICSEARCH_URL = os.getenv("ELASTICSEARCH_URL", "http://localhost:9200") CACHE_TTL = int(os.getenv("CACHE_TTL", "3600")) # デフォルト1時間 BATCH_INTERVAL = int(os.getenv("BATCH_INTERVAL", "86400")) # デフォルト1日 -
プラグイン機構の活用:
- 新機能を追加する際にコア部分を変更しなくても良いように設計する
- これにより、機能拡張時のリスクと労力を削減できる
- 例:新たなデータソースを追加する場合、既存コードを変更せずプラグインとして追加できる
# 良い例(プラグイン機構) class DataSourceManager: """データソース管理クラス""" def __init__(self): self.data_sources = {} def register_data_source(self, source_name, source_class): """新しいデータソースを登録""" self.data_sources[source_name] = source_class() def fetch_all(self): """全てのデータソースからデータを取得""" results = {} for source_name, source in self.data_sources.items(): try: data = source.fetch_data() results[source_name] = data except Exception as e: logging.error(f"Error fetching data from {source_name}: {e}") return results
9.6.2 バランスの取れた拡張性
拡張性は重要ですが、過剰な柔軟性は複雑性を増し、開発効率やパフォーマンスに悪影響を与える場合があります。以下のポイントを考慮してバランスの取れた設計を目指しましょう:
-
YAGNI原則(You Aren't Gonna Need It):
- 実際に必要になるまで機能を追加しない
- 「将来必要かもしれない」という理由だけで複雑な設計を導入しない
-
段階的リファクタリング:
- 完璧な設計を最初から目指すのではなく、実際のニーズに応じて段階的に改善する
- これにより、過度の設計や不要な複雑性を避けられる
-
明確な境界の設定:
- システムの各部分の責任範囲を明確に定義する
- これにより、一部の変更が全体に波及するリスクを低減できる
💡 学習ポイント
拡張性と単純さはトレードオフの関係にあることが多いです。拡張性の高い設計は概して複雑になりがちですが、複雑さはメンテナンスコストの増加や新しいバグの導入リスクを高めます。実際のプロジェクトでは、現在の要件と予見可能な将来のニーズを考慮しつつ、適切なバランス点を見つけることが重要です。
📝 若手エンジニア向けメモ
特に若手エンジニアは「柔軟で拡張性の高い設計」を目指しがちですが、実際には「シンプルで理解しやすい設計」の方が長期的には価値があることが多いです。必要になったときにリファクタリングするという選択肢も常に念頭に置き、「今の問題を解決するのに必要十分な複雑さ」を目指すことがおすすめです。
🔍 チェックポイント
- 機能拡張のロードマップとその優先順位付けの考え方を理解している
- 水平スケーリングと垂直スケーリングの違いと適用場面を説明できる
- マイクロサービスへの段階的移行方法と課題を理解している
- 技術的負債の概念と管理方法を理解している
- 拡張性を確保するための設計原則を説明できる
第10章:ナレッジ共有とチーム開発の実践
目次
- 10.1 効果的な技術ドキュメンテーション
- 10.2 チーム開発とコラボレーション
- 10.3 若手エンジニア向け育成計画
- 10.4 継続的学習文化の構築
- 10.5 若手エンジニア向け解説:技術力向上のコツ
📚 この章で学ぶこと
- 効果的な知識共有と技術ドキュメントの作成方法
- 近代的なチーム開発プラクティスとツール
- 若手エンジニアの育成とメンタリング手法
- 継続的な学習文化を醸成する方法
🔑 重要な概念
- ナレッジの形式知化と効率的な共有方法
- 効果的なチームコラボレーションプラクティス
- 継続的な技術的成長を促進する組織文化
- 若手エンジニアの効果的な成長支援手法
10.1 効果的な技術ドキュメンテーション
チーム内のナレッジ共有のための文書化手法を解説します。
10.1.1 コード文書化
-
インラインコメント:
- 複雑なロジックの説明
- 非直感的な実装の理由
- 将来の注意点や既知の制約
📝 若手エンジニア向けメモ
コードの文書化は、将来の自分自身や他のエンジニアのためのものです。特に、「なぜそのように実装したのか」という背景情報は、コードだけでは理解しづらいため、コメントとして残しておくと非常に有用です。ただし、過度なコメントは逆に可読性を下げることもあるので、バランスが重要です。 -
ドキュメント文字列(Docstring):
- 関数・メソッドの目的
- パラメータと戻り値の説明
- 使用例とエッジケース
def search_restaurants(keyword=None, location=None, radius=None, cuisine_type=None, price_range=None, page=1, page_size=20):
"""飲食店を検索する
複数の条件を組み合わせて飲食店を検索します。すべてのパラメータはオプションですが、
keyword または location のいずれかは指定することをお勧めします。
Args:
keyword (str, optional): 検索キーワード。店名や料理名などのフリーテキスト。
location (dict, optional): 検索の中心位置。{'latitude': float, 'longitude': float} 形式。
radius (float, optional): 検索半径(km)。デフォルトは2.0km。
cuisine_type (str, optional): 料理ジャンル(例: 'イタリアン', '寿司')。
price_range (dict, optional): 価格帯。{'min': int, 'max': int} 形式。
page (int, optional): 取得するページ番号。1から開始。
page_size (int, optional): 1ページあたりの結果数。最大100。
Returns:
dict: 検索結果。以下の構造を持つ:
{
'total': int, # 総ヒット数
'items': list, # 店舗リスト
'page': int, # 現在のページ
'page_size': int # ページサイズ
}
Raises:
ValueError: パラメータが不正な場合
SearchError: 検索処理でエラーが発生した場合
Examples:
>>> results = search_restaurants(keyword="ラーメン", location={"latitude": 35.6895, "longitude": 139.6917})
>>> print(f"Found {results['total']} restaurants")
"""
# 実装...
-
アーキテクチャドキュメント:
- コンポーネント図
- データフロー図
- シーケンス図
💡 学習ポイント
良いアーキテクチャドキュメントは、詳細すぎず抽象的すぎない「ちょうど良いレベル」で作成することが重要です。全てを文書化するのではなく、理解するのが難しい部分や、設計上の重要な決定に焦点を当てると効果的です。また、図やダイアグラムは文字よりも多くの情報を伝えることができるため、積極的に活用しましょう。
10.1.2 開発ガイド
-
開発環境セットアップ:
- 前提条件
- インストール手順
- 初期設定と検証
-
コーディング規約:
- PEP 8準拠のPythonコーディングスタイル
- プロジェクト固有の命名規則
- コードレビュー基準
-
デプロイメントフロー:
- ブランチ戦略
- CI/CDプロセス
- リリース手順
📝 若手エンジニア向けメモ
開発ガイドは、特に新しいメンバーがスムーズに開発を始められるよう整備することが重要です。「自分は知っている」からといって省略せず、基本的なことも丁寧に文書化しておくと、後で大きく時間を節約できます。また、定期的に見直し、実際の開発プロセスと文書が乖離していないか確認することも大切です。
10.1.3 ドキュメント管理のベストプラクティス
-
ドキュメントのバージョン管理:
- ソースコードと同様にGitなどでバージョン管理
- 更新履歴と担当者の記録
- プルリクエストによるレビュープロセス
-
ドキュメントの鮮度維持:
- 定期的な見直しと更新(四半期に一度など)
- コードの大きな変更時には関連ドキュメントも更新
- 「最終更新日」の明記と古いドキュメントの警告表示
-
アクセシビリティの確保:
- チーム全員がアクセスできる中央リポジトリでの管理
- 検索可能なフォーマット(Markdown, HTML)の使用
- 体系的な目次と相互リンクの整備
💡 学習ポイント
ドキュメントは「作るだけ」では不十分です。チームメンバーがすぐに必要な情報にアクセスできるよう、検索性と構造化を意識しましょう。また、ドキュメントは「生きもの」であり、システムの進化と共に更新し続ける必要があります。
10.1.4 アーキテクチャ決定記録(ADR)
設計上の重要な決定を記録するためのADR(Architecture Decision Record):
-
ADRの構成:
- タイトル(何を決定したか)
- ステータス(提案中、承認済み、廃止など)
- コンテキスト(決定の背景)
- 決定内容
- 代替案と比較
- 結果(予想される影響)
-
ADRの管理:
- ソースコードリポジトリと共に管理
- 連番付与による整理
- 関連ADRへの参照
# ADR-001: 検索エンジンとしてElasticsearchを採用
## ステータス
承認済み
## コンテキスト
飲食店検索システムでは、全文検索と地理空間検索の両方の能力を持つ検索エンジンが必要。
また、将来的にはレコメンデーション機能への拡張も検討している。
## 決定
検索エンジンとしてElasticsearch 8.x を採用する。
## 代替案
1. PostgreSQLの全文検索機能
- 利点: 追加システム不要、学習コスト低
- 欠点: 高度な全文検索機能が限定的、スケーラビリティに制約
2. Solr
- 利点: 成熟した全文検索エンジン、多様な機能
- 欠点: 設定がやや複雑、地理空間検索はElasticsearchより劣る
3. Algolia (SaaS)
- 利点: 管理不要、高速、UI連携容易
- 欠点: コスト高、カスタマイズ性に制限
## 判断基準
- 全文検索性能(重み: 30%): Elasticsearch 5/5, PostgreSQL 3/5, Solr 4/5, Algolia 5/5
- 地理空間検索(重み: 25%): Elasticsearch 5/5, PostgreSQL 4/5, Solr 3/5, Algolia 4/5
- スケーラビリティ(重み: 20%): Elasticsearch 5/5, PostgreSQL 3/5, Solr 4/5, Algolia 5/5
- 運用コスト(重み: 15%): Elasticsearch 3/5, PostgreSQL 5/5, Solr 3/5, Algolia 5/5
- チームの習熟度(重み: 10%): Elasticsearch 4/5, PostgreSQL 5/5, Solr 2/5, Algolia 2/5
加重平均スコア:
- Elasticsearch: 4.55/5
- PostgreSQL: 3.8/5
- Solr: 3.35/5
- Algolia: 4.35/5
## 影響
- 運用面: Elasticsearchクラスターの管理と監視が必要
- 開発面: ElasticsearchのAPI理解とクエリ最適化のスキルが必要
- インフラ面: メモリ要件が比較的高い(最小8GB推奨)
📝 若手エンジニア向けメモ
ADRは「何をなぜ決めたのか」を明確に記録するためのツールです。これにより、後から「なぜこの技術を使ったのか」「なぜこの設計にしたのか」といった疑問に答えることができます。特に、チームメンバーが入れ替わる中で、過去の決定の理由を理解するのに役立ちます。
10.2 チーム開発とコラボレーション
技術力向上と効率的な開発のためのチーム開発プラクティス:
10.2.1 共同開発手法
-
ペアプログラミング:
- 目的と効果:
- 知識の共有と移転
- コードの品質向上
- チームビルディング
- 実施方法:
- ドライバー(コードを書く人)とナビゲーター(方向性を考える人)の役割分担
- 定期的な役割交代(30分ごとなど)
- 集中タイムボックス(2時間程度)の設定
💡 学習ポイント
ペアプログラミングは、単なる「教える/教わる」の関係ではなく、互いに知識や視点を共有し合う活動です。ナビゲーターは、ドライバーがコードを書くのを単に見守るのではなく、大局的な視点から方向性を考え、潜在的な問題点を指摘するという積極的な役割を担います。また、ドライバーとナビゲーターを定期的に交代することで、両者が異なる視点を体験できるというメリットがあります。 - 目的と効果:
-
モブプログラミング:
- 概要:
- 3人以上での共同プログラミング
- 1人がドライバー、残りがナビゲーターとなる
- 定期的な役割交代(15分ごとなど)
- メリット:
- チーム全体での知識共有
- リアルタイムのコードレビュー
- 問題解決の多様なアプローチ
📝 若手エンジニア向けメモ
モブプログラミングは、一見非効率に思えるかもしれませんが、複雑な問題解決や重要な設計決定には非常に効果的です。特に、チーム全体が同じ問題についての理解を共有できるため、後でのコミュニケーションコストが大幅に削減されるというメリットがあります。ただし、全ての作業に適用するものではなく、チームで議論すべき重要なタスクに絞って活用するのが効果的です。 - 概要:
-
アジャイル開発プラクティス:
- スクラム:
- デイリースタンドアップ(15分の短い進捗共有)
- スプリント計画(2週間程度の作業計画)
- レトロスペクティブ(振り返りとプロセス改善)
- カンバン:
- 可視化されたワークフロー管理
- WIP(Work In Progress)制限による流れの最適化
- 継続的なプロセス改善
💡 学習ポイント
アジャイル開発は「計画よりも変化への対応を重視する」アプローチです。完璧な計画を立てることよりも、短いサイクルで実装→フィードバック→改善を繰り返すことで、変化する要件や状況に柔軟に対応します。ただし、「アジャイル=プロセスなし」ではなく、むしろ効果的なプロセスや規律が重要です。 - スクラム:
10.2.2 コードレビュー文化
-
目的:
- コード品質の向上
- ナレッジ共有
- チーム内基準の統一
-
レビュープロセス:
- プルリクエストによる変更提案
- レビュー担当者の明示的なアサイン
- 明確なレビュー基準
📝 若手エンジニア向けメモ
コードレビューは、単に問題点を指摘するための場ではなく、学びと共有の場でもあります。「この方が良い」と思う実装方法を提案する際は、なぜそれが良いのかの理由も添えることで、お互いの学びになります。また、良い点も積極的に指摘することで、ポジティブなフィードバック文化を育むことができます。 -
レビュー文化の醸成:
- 建設的なフィードバック
- 良い点の積極的な評価
- 学びと改善に焦点を当てた姿勢
-
コードレビューのベストプラクティス:
- 小さな変更を頻繁にレビュー
- 明確なレビューチェックリスト
- 自動化ツールとの併用(静的解析、フォーマッター)
- タイムリーなレビュー(24時間以内を目標)
# コードレビューチェックリスト
## 機能面
- [ ] 機能要件を満たしているか
- [ ] エッジケースが考慮されているか
- [ ] エラー処理は適切か
## 品質面
- [ ] テストは十分に書かれているか
- [ ] パフォーマンスは考慮されているか
- [ ] セキュリティリスクはないか
## 保守性
- [ ] コードは理解しやすいか
- [ ] 命名は適切か
- [ ] コメントは必要十分か
- [ ] 過剰な複雑さはないか
## 一貫性
- [ ] コーディング規約に従っているか
- [ ] アーキテクチャパターンは一貫しているか
- [ ] 既存のライブラリやユーティリティを適切に活用しているか
10.2.3 継続的インテグレーション/デリバリー (CI/CD)
-
CI/CDパイプラインの構成:
- コード変更のプッシュをトリガーとした自動ビルド
- 静的解析とコードスタイルチェック
- 自動テスト(単体、統合、E2E)
- 自動デプロイ(ステージング、本番環境)
-
環境管理:
- 開発環境、テスト環境、ステージング環境、本番環境の分離
- 環境ごとの設定管理(環境変数、設定ファイル)
- インフラストラクチャ・アズ・コード(IaC)による環境再現性
💡 学習ポイント
CI/CDは「小さな変更を頻繁に、安全に本番環境に届ける」ための仕組みです。これにより、変更のリスクを低減し、フィードバックサイクルを短縮できます。また、デプロイメントの自動化により、人的ミスを減らし、運用効率を向上させることができます。 -
ブランチ戦略:
- GitFlow:
-
developブランチをベースに開発 - 機能開発は
featureブランチで - リリース準備は
releaseブランチで - 緊急修正は
hotfixブランチで
-
- GitHub Flow:
-
mainブランチは常にデプロイ可能 - 新機能開発は全て
featureブランチで - プルリクエスト、レビュー、テスト後に
mainへマージ
-
- Trunk Based Development:
- 短命なフィーチャーブランチ
- 頻繁な
mainブランチへの統合(1日に複数回) - フィーチャーフラグによる未完了機能の隠蔽
📝 若手エンジニア向けメモ
ブランチ戦略は、チームの規模やリリースサイクルに合わせて選択するのが良いでしょう。例えば、小規模なチームや頻繁なデプロイを行うプロジェクトではシンプルなGitHub Flowが適している一方、複数のバージョンを同時にサポートする必要があるプロジェクトではGitFlowが適しているかもしれません。 - GitFlow:
10.2.4 技術共有会
-
定期開催:
- 週1回のランチ&ラーン
- 月1回の深堀りセッション
- 四半期ごとの技術動向レビュー
-
発表トピック例:
- 新技術の調査レポート
- 実装した機能の解説
- トラブルシューティング事例共有
- 外部カンファレンスの参加報告
💡 学習ポイント
技術共有会は、チーム内の知識を均質化し、個人の専門領域を広げる機会となります。また、発表することで自分自身の理解も深まり、説明スキルも向上するという一石二鳥の効果があります。技術共有会を成功させるためには、「知っていることを共有する」という文化醸成と、適切な時間配分(準備と発表)が重要です。 -
効果的な運営:
- 事前の発表者ローテーション
- 適切な資料準備の奨励
- Q&Aセッションの時間確保
- 録画や資料の保存による非同期的な共有
10.2.5 インナーソース
組織内オープンソースの実践:
-
概念:
- 組織内でのオープンソースのプラクティス適用
- コード、ドキュメント、ツールの共有と協働
-
メリット:
- 重複作業の削減
- 品質と再利用性の向上
- チーム間の協働促進
💡 学習ポイント
インナーソースとは、オープンソースソフトウェア開発の手法と文化を組織内に適用するアプローチです。これにより、チームの境界を越えた協力が促進され、「車輪の再発明」を防ぎ、組織全体としての効率が向上します。具体的には、共通ライブラリやツールをチーム間で共有し、プルリクエストやイシュートラッキングなどの手段で協働するという形で実践されます。 -
実践方法:
- 共通ライブラリの整備
- 明確なドキュメント提供
- 貢献ガイドラインの策定
- オープンな議論の場(イシュートラッカー、フォーラム)
10.2.6 分散チームでの効果的な協働
-
リモート/ハイブリッド環境での協働:
- 非同期コミュニケーションの最適化:
- 詳細な文書化と状況コンテキストの共有
- 質問と回答のデータベース化
- 検索可能な共有リソースの整備
- 同期的なコラボレーション:
- 効果的なビデオ会議の運営(アジェンダ、時間管理)
- バーチャルホワイトボードの活用
- 画面共有とペアプログラミングセッション
📝 若手エンジニア向けメモ
リモート/ハイブリッド環境では、対面でのコミュニケーションが減少するため、意識的に情報を共有することが重要です。「自分だけが知っている情報」を減らし、「チーム全体が共有している情報」を増やすことを意識しましょう。また、文書化と非同期コミュニケーションのスキルは、リモート環境での効果的な協働に不可欠です。 - 非同期コミュニケーションの最適化:
-
チームの心理的安全性の確保:
- フィードバックの建設的な提供と受け取り
- 失敗を学びの機会として受け入れる文化
- 多様な意見や視点の尊重
- 定期的な1on1ミーティングによる個別サポート
💡 学習ポイント
心理的安全性とは、「チーム内で自分の考えや懸念を恐れることなく表明できる」という状態を指します。これは、イノベーションや継続的改善の基盤となる重要な要素です。心理的安全性が高いチームでは、問題の早期発見や多様な視点からの解決策の創出が促進されます。
10.3 若手エンジニア向け育成計画
若手エンジニアの成長を支援するための具体的な計画:
10.3.1 段階的なタスク割り当て
-
レベル別タスク設計:
- Level 1: 基本的な機能実装、バグ修正(明確な指示あり)
- Level 2: 小〜中規模の機能開発(ある程度の自由度あり)
- Level 3: 複雑な機能設計、パフォーマンス最適化(高い自律性)
📝 若手エンジニア向けメモ
最初から難しいタスクに挑戦するのではなく、まずは基本的なタスクで自信をつけ、徐々に難易度を上げていくアプローチが効果的です。「小さな成功体験」の積み重ねが、技術的な成長につながります。 -
成長トラッキング:
- 四半期ごとのスキル評価
- 達成したマイルストーンの記録
- 次の成長目標の設定
10.4 継続的学習文化の構築
組織的な学習文化を醸成するためのアプローチ:
10.4.1 学習する組織の特徴
-
失敗から学ぶ文化:
- 失敗を非難せず、教訓として扱う
- ポストモーテム(事後分析)の実施
- 学んだ教訓の共有
-
実験を奨励する姿勢:
- 革新的なアイデアの試行
- 「失敗してもよい」という安全な環境
- 実験の結果と学びの共有
📝 若手エンジニア向けメモ
真の学習は、成功だけでなく失敗からも得られます。「失敗は恥ずかしいこと」という考えを捨て、「失敗は学びの機会」と捉える姿勢が成長につながります。失敗した場合は、その原因を分析し、次に活かすための教訓を導き出すことに集中しましょう。 -
知識共有の評価:
- ナレッジ共有活動の評価基準への組み込み
- 共有による貢献の認知と評価
- メンタリングやドキュメント作成の価値認識
10.4.2 テクニカルコミュニケーションの強化
-
わかりやすい説明の技術:
- 抽象度の適切な調整
- 視覚的な補助の活用
- 専門用語の適切な使用
-
効果的な質問と回答:
- 具体的で明確な質問の仕方
- コンテキストを含めた情報提供
- 建設的なフィードバックの提供方法
💡 学習ポイント
テクニカルコミュニケーションは、技術的なスキルと同様に、エンジニアにとって重要なスキルです。特に複雑な技術的概念を、技術的な背景が異なる相手にも理解できるように説明する能力は、チーム内での協働やキャリア発展において非常に価値があります。 -
ドキュメンテーションスキル:
- 目的と対象読者を明確にした文書作成
- 構造化された情報提示
- 適切な抽象度での情報提供
10.4.3 リモート/ハイブリッド環境でのナレッジ共有
-
非同期コミュニケーションの最適化:
- 明確で詳細な文書化
- 質問と回答のデータベース化
- 検索可能な共有リソースの整備
-
バーチャルコラボレーションツール:
- オンラインホワイトボード
- 画面共有とペアプログラミングツール
- リモートワークショップの実施方法
📝 若手エンジニア向けメモ
リモート/ハイブリッド環境では、対面でのコミュニケーションが減少するため、意識的に情報を共有することが重要です。「自分だけが知っている情報」を減らし、「チーム全体が共有している情報」を増やすことを意識しましょう。また、文書化と非同期コミュニケーションのスキルは、リモート環境での効果的な協働に不可欠です。 -
バーチャルコミュニティの形成:
- オンライン学習グループ
- バーチャル勉強会
- テーマ別チャットチャネル
10.4.4 デベロッパー・エクスペリエンスの最適化
-
開発環境の整備:
- 統一された開発環境の構築(Docker等)
- 簡単なセットアップ手順
- 自動化された初期設定と検証
-
ツールの充実:
- コード生成・補完ツール
- 静的解析とエラー検出
- リファクタリング支援
💡 学習ポイント
デベロッパー・エクスペリエンス(DX)は、エンジニアの生産性と満足度に直結します。良いDXは「開発者が本質的な問題解決に集中できる環境」を提供し、煩雑な作業や環境構築のフラストレーションを減らします。これにより、学習曲線の短縮やチーム全体の生産性向上につながります。 -
知識アクセスの迅速化:
- チャットボット等を活用した情報検索
- ナレッジグラフによる関連情報の発見
- コンテキスト考慮型の推奨システム
10.5 若手エンジニア向け解説:技術力向上のコツ
エンジニアとしての技術力を効果的に向上させるためのヒントをいくつか紹介します:
10.5.1 学習のアプローチ
-
「T字型」のスキル獲得:
- 広く浅く多くの技術に触れる(横棒)
- 特定の分野で深い専門性を持つ(縦棒)
- 全てを極めようとするのではなく、強みを作りつつ視野を広げる
📝 若手エンジニア向けメモ
特に若手のうちは、様々な技術に触れて「どんな技術があるのか」「自分が興味を持てる分野は何か」を探索することが大切です。その上で、特に興味を持った分野については深掘りして専門性を高めていくと良いでしょう。 -
アウトプット駆動学習:
- 学んだことを言語化・コード化する
- ブログ記事や社内共有会での発表
- 小さなプロジェクトでの実装
💡 学習ポイント
インプット(読書、動画視聴など)だけでなく、アウトプット(コーディング、記事執筆、発表など)を意識的に行うことで、理解が深まります。「人に説明できる」レベルになることを目指しましょう。 -
コミュニティへの参加:
- 社内外の勉強会やカンファレンス
- オープンソースプロジェクトへの貢献
- 技術コミュニティでの質問や回答
📝 若手エンジニア向けメモ
コミュニティに参加することで、自分一人では気づかない視点や知識を得られます。また、「自分より少し先を行く人」の存在は、学習のモチベーションにもなります。初めは緊張するかもしれませんが、多くのコミュニティは初心者に対してオープンです。
10.5.2 効率的な学習習慣
-
小さく始めて継続する:
- 「1日30分」など、無理のない範囲から始める
- 習慣化のために同じ時間帯に学習する
- 小さな成功体験を積み重ねる
-
アクティブラーニング:
- 受動的な読書ではなく、実際にコードを書く
- 疑問点を実験で確かめる
- 「分かった気」にならずに実践する
💡 学習ポイント
プログラミングは「読む」より「書く」ことで身につきます。本やチュートリアルを読むだけでなく、学んだことを実際にコードで試してみることが大切です。また、分からないことがあったら、すぐに答えを見るのではなく、まずは自分で考え、調べることも重要な学びになります。 -
振り返りと整理:
- 学んだことを定期的に振り返る
- ノートやドキュメントに整理する
- 知識の関連性やマップを作る
📝 若手エンジニア向けメモ
学習した内容は、時間が経つと忘れていくものです。定期的に振り返りを行い、自分なりにまとめておくことで、知識の定着率が高まります。また、整理することで知識の関連性が見えてきて、理解が深まることもあります。
10.5.3 困ったときの対処法
-
効果的な質問の仕方:
- 具体的な状況と期待する結果を説明
- 自分が試したことを共有
- 質問の目的を明確に
💡 学習ポイント
「〇〇がわかりません」という漠然とした質問より、「〇〇をしようとして△△のエラーが出ました。□□を試してみましたが解決しませんでした」という具体的な質問の方が、回答する側も的確なアドバイスがしやすくなります。 -
デバッグの基本姿勢:
- 問題を特定するための切り分け
- 仮説を立てて検証する
- ログやエラーメッセージを丁寧に読む
📝 若手エンジニア向けメモ
デバッグは「探偵の推理」のようなものです。証拠(ログやエラーメッセージ)を集め、仮説を立て、検証していきます。問題解決のプロセスを楽しむくらいの気持ちで取り組むと、デバッグ力が向上します。 -
リソースの活用:
- 公式ドキュメントの参照
- Stack Overflowなどの技術Q&Aサイト
- コミュニティのフォーラムやチャット
💡 学習ポイント
困ったときのリソースとして、まず公式ドキュメントを参照するクセをつけましょう。次に、同じ問題に直面した人の解決策を探すために、技術Q&Aサイトを活用します。それでも解決しない場合は、コミュニティに質問するという段階的なアプローチが効果的です。
10.5.4 最新技術のキャッチアップ方法
-
情報収集の習慣化:
- テックブログの定期的なチェック
- RSS/ニュースレターの購読
- ソーシャルメディアの技術アカウントのフォロー
-
選択的な深掘り:
- トレンドを把握した上で関心分野を選定
- FOMO(取り残される恐怖)に振り回されない
- 実用性と自分のキャリアパスを考慮した選択
📝 若手エンジニア向けメモ
技術トレンドは常に変化していますが、全てを追いかける必要はありません。興味を持ったものや、現在の仕事に関連するものを優先的に学ぶのが効率的です。また、基礎となる概念(アルゴリズム、データ構造、設計パターンなど)は長く役立つので、これらへの投資も重要です。 -
ハンズオンでの学習:
- チュートリアルの実践
- サイドプロジェクトでの活用
- 既存プロジェクトへの試験的導入
🔍 チェックポイント
- 効果的なドキュメント管理のポイントを理解している
- チーム内でのナレッジ共有活動の種類と目的を説明できる
- 若手エンジニアの成長を支援する具体的な方法を理解している
- 自己学習のための効果的なアプローチを説明できる
- テクニカルコミュニケーションの重要性と改善方法を理解している
第11章:リスク管理と対策
目次
- 11.1 リスク管理フレームワーク
- 11.2 セキュリティリスクと対策
- 11.3 システム障害リスク
- 11.4 プロジェクト管理リスク
- 11.5 法的・倫理的リスク
- 11.6 若手エンジニア向け解説:リスク思考の重要性
📚 この章で学ぶこと
- プロジェクトにおける様々なリスクの特定と分析方法
- セキュリティ、システム障害、プロジェクト管理上のリスク対策
- 法的・倫理的リスクへの対応アプローチ
- リスク管理を日常の開発活動に組み込む方法
🔑 重要な概念
- リスク管理の体系的アプローチ
- セキュアバイデザイン(設計段階からのセキュリティ対策)
- 障害対応とビジネス継続計画
- コンプライアンスとプライバシー保護
11.1 リスク管理フレームワーク
プロジェクトのリスクを体系的に管理するためのフレームワーク:
11.1.1 リスク管理プロセス
-
リスクの特定:
- ブレインストーミングセッション
- チェックリストの活用
- 過去プロジェクトの教訓
- ステークホルダーインタビュー
-
リスクの分析と評価:
- 影響度の評価(低・中・高)
- 発生確率の評価(低・中・高)
- リスクスコア = 影響度 × 発生確率
- 優先度付け
📝 若手エンジニア向けメモ
リスク評価では、定量的な基準を設けることが重要です。例えば、影響度は「ユーザー数への影響」「ダウンタイム」「金銭的損失」などの観点から評価し、発生確率は過去の事例や類似システムの統計データなどを参考にすると良いでしょう。 -
リスク対応計画:
- 回避:リスクの原因を取り除く
- 軽減:影響または確率を下げる対策を講じる
- 転嫁:第三者にリスクを移転(保険など)
- 受容:対策コストが高すぎる場合は受け入れる
-
モニタリングと再評価:
- 定期的なリスクレビュー(毎月など)
- 新規リスクの継続的な特定
- 既存リスクの状態変化の追跡
- 対策の有効性評価
11.1.2 リスクレジスター
リスクを一元管理するためのツール:
| リスクID | 説明 | カテゴリ | 影響度 | 発生確率 | リスクスコア | 対応戦略 | 対応策 | 責任者 | ステータス |
|----------|------|----------|--------|----------|--------------|----------|--------|--------|------------|
| R-001 | データベース障害による検索機能停止 | システム | 高(3) | 中(2) | 6 | 軽減 | レプリケーション構成、自動フェイルオーバー導入 | インフラ担当 | 進行中 |
| R-002 | APIキー漏洩によるセキュリティ侵害 | セキュリティ | 高(3) | 低(1) | 3 | 軽減+転嫁 | キーローテーション、アクセス監視、サイバー保険 | セキュリティ担当 | 完了 |
| R-003 | 開発リソース不足による納期遅延 | プロジェクト | 中(2) | 中(2) | 4 | 軽減 | 優先機能の絞り込み、外部リソースの確保 | PM | 監視中 |
💡 学習ポイント
リスクレジスターは「生きた文書」として扱い、定期的に更新することが重要です。形式的な文書作成にとどまらず、チーム全体でリスクを共有し、それぞれの対応策について議論する場を設けることで、リスク管理の文化を醸成できます。
11.1.3 リスクコミュニケーション
-
ステークホルダーへの報告:
- 経営層:高レベルなリスク概要と対応状況
- チームメンバー:詳細な技術リスクと対応方法
- クライアント:サービスに影響するリスクと対策
-
リスクコミュニケーションのポイント:
- 透明性:リスクの隠蔽や過小評価をしない
- 明確さ:専門用語を避け、分かりやすく伝える
- バランス:過度の不安を煽らず、事実に基づいて伝える
- タイムリー:重大リスクは発見次第、迅速に共有
📝 若手エンジニア向けメモ
リスクを報告することは「問題を作り出している」のではなく、「潜在的な問題を早期に発見し、対処する機会を作っている」ことを理解しましょう。良いチームでは、リスク報告が評価される文化が醸成されています。
11.2 セキュリティリスクと対策
アプリケーションのセキュリティリスクとその対策:
11.2.1 OWASP Top 10対策
Open Web Application Security Project(OWASP)が公開する主要な脆弱性への対策:
-
インジェクション攻撃:
- リスク:SQLインジェクション、コマンドインジェクションなど
- 対策:
- パラメータ化クエリの使用
- ORM(Object-Relational Mapping)の活用
- ユーザー入力の厳格なバリデーション
💡 学習ポイント
インジェクション攻撃は、ユーザー入力を適切に検証・サニタイズせずにデータベースクエリやコマンドに組み込むことで発生します。パラメータ化クエリを使用することで、入力値とクエリ構造を分離し、攻撃を防止できます。 -
認証・セッション管理の不備:
- リスク:認証バイパス、セッションハイジャックなど
- 対策:
- 強力なパスワードポリシーの適用
- 多要素認証の導入
- JWTなどの安全なトークン管理
- 適切なセッションタイムアウト設定
-
クロスサイトスクリプティング(XSS):
- リスク:ユーザーブラウザでの悪意あるスクリプト実行
- 対策:
- 出力エンコーディング
- Content Security Policy(CSP)の実装
- XSS防御ライブラリの使用
-
安全でないデシリアライゼーション:
- リスク:信頼できないデータのデシリアライズによるコード実行
- 対策:
- 信頼できないソースからのデータをデシリアライズしない
- デシリアライズ前の型チェックと検証
- 最小権限原則の適用
📝 若手エンジニア向けメモ
セキュリティ対策は「絶対に安全」というものはなく、複数の防御層(多層防御)を設けることが重要です。また、セキュリティは「一度対応すれば終わり」ではなく、新たな脅威に対応するため継続的な更新と学習が必要です。
11.2.2 APIセキュリティ
REST APIのセキュリティリスクと対策:
-
認証と認可:
- リスク:不正アクセス、権限昇格
- 対策:
- JWTベースの認証
- OAuth 2.0/OpenID Connectの活用
- 細粒度のアクセス制御
- APIキーのセキュアな管理
-
レート制限:
- リスク:DoS攻撃、API濫用
- 対策:
- IPベース、ユーザーベース、エンドポイントベースの制限
- バーストトラフィックへの対応
- 429ステータスコード(Too Many Requests)の適切な返却
-
入出力検証:
- リスク:無効なデータ処理、情報漏洩
- 対策:
- スキーマベースの入力検証
- レスポンスのフィルタリング
- エラーメッセージの適切な抽象化
💡 学習ポイント
APIセキュリティでは、「認証(誰であるかの確認)」と「認可(何ができるかの制御)」を明確に分離することが重要です。また、APIキーなどの認証情報は環境変数などで管理し、ソースコードにハードコーディングしないよう注意しましょう。
11.2.3 データ保護
データセキュリティに関するリスクと対策:
-
データ暗号化:
- リスク:データ漏洩時の情報流出
- 対策:
- 転送中の暗号化(TLS 1.2+)
- 保存時の暗号化(AES-256など)
- 適切な鍵管理
-
パーソナルデータの保護:
- リスク:個人情報漏洩、プライバシー法違反
- 対策:
- 最小限のデータ収集
- データの匿名化/仮名化
- アクセス制御とログ記録
- データ使用目的の明確化
-
データバックアップと復旧:
- リスク:データ損失、ランサムウェア被害
- 対策:
- 定期的なバックアップ
- 3-2-1バックアップ戦略(3つのコピー、2種類の媒体、1つはオフサイト)
- リストア手順の定期的なテスト
📝 若手エンジニア向けメモ
データ保護では、「必要なデータだけを必要な期間だけ保持する」という原則が重要です。不要なデータを収集・保持することは、セキュリティリスクを高めるだけでなく、法規制(GDPR、個人情報保護法など)への対応も複雑になります。
11.2.4 セキュアな開発ライフサイクル(SDLC)
開発プロセス全体でのセキュリティ対策:
-
設計段階:
- 脅威モデリング(STRIDE, DREAD)
- セキュリティ要件の定義
- アーキテクチャリスクレビュー
-
実装段階:
- セキュアコーディングガイドラインの遵守
- ピアレビューによるセキュリティチェック
- 静的解析ツールの活用
-
テスト段階:
- セキュリティテスト(SAST, DAST)
- ペネトレーションテスト
- 依存ライブラリの脆弱性スキャン
-
運用段階:
- セキュリティモニタリング
- インシデント対応計画
- 定期的な脆弱性評価
💡 学習ポイント
セキュリティは開発の最後に「追加する」ものではなく、設計段階から考慮すべき要素です。これを「セキュアバイデザイン」と呼びます。開発の早い段階でセキュリティ問題を発見するほど、修正コストは低く抑えられます。
11.3 システム障害リスク
システム運用上のリスクと対策:
11.3.1 単一障害点(SPOF)の排除
-
インフラ冗長化:
- リスク:ハードウェア障害、ネットワーク障害によるサービス停止
- 対策:
- 複数サーバーによる負荷分散
- マルチAZ/リージョン配置
- 自動フェイルオーバーの実装
-
データベース冗長化:
- リスク:データベース障害によるデータ損失・サービス停止
- 対策:
- プライマリ/レプリカ構成
- 自動バックアップと定期的なリカバリテスト
- 読み取り/書き込み分散
📝 若手エンジニア向けメモ
冗長化は単に「複数のコンポーネントを用意する」だけでは不十分です。障害検知と自動切り替えの仕組み、定期的な動作確認、運用手順の整備も含めて考える必要があります。また、冗長化によって複雑性が増すこともあるため、バランスを考慮することが重要です。 -
サービス依存関係の管理:
- リスク:外部サービス障害の連鎖
- 対策:
- 依存関係の可視化
- フォールバックメカニズムの実装
- サーキットブレーカーパターンの適用
11.3.2 スケーラビリティ確保
-
負荷予測と容量計画:
- リスク:急激な負荷増加によるパフォーマンス低下
- 対策:
- 定期的な負荷テスト
- 将来の成長を考慮したキャパシティプランニング
- 自動スケーリングの実装
-
パフォーマンスボトルネックの特定:
- リスク:特定コンポーネントの限界によるシステム全体の性能低下
- 対策:
- 定期的なパフォーマンスプロファイリング
- 分散トレーシングによるボトルネック特定
- 継続的なパフォーマンス最適化
💡 学習ポイント
スケーラビリティは「問題が発生してから」ではなく、設計段階から考慮することが重要です。特に、データベースやキャッシュなどのステートフルなコンポーネントは、後からのスケーリングが難しいことが多いため、初期設計で注意が必要です。
11.3.3 障害検知と対応
-
モニタリングとアラート:
- リスク:障害の検知遅延による影響拡大
- 対策:
- 多層的なモニタリング(インフラ、アプリケーション、ビジネスKPI)
- アラートの適切な閾値設定
- オンコールローテーションの確立
-
インシデント対応プロセス:
- リスク:非体系的な対応による復旧遅延
- 対策:
- 標準的なインシデント対応手順の整備
- 重大度別の対応フロー
- エスカレーションパスの明確化
📝 若手エンジニア向けメモ
インシデント対応では「まず影響を最小化する」ことが優先です。完全な原因究明や恒久対策は、緊急対応の後に行うことが多いです。また、「誰が悪かったか」ではなく「何が問題でどう改善するか」に焦点を当てた文化が重要です。 -
障害からの学習:
- ポストモーテム(事後分析)の実施
- 根本原因分析(RCA)
- 再発防止策の実装と検証
11.3.4 ディザスタリカバリと事業継続
-
ディザスタリカバリ計画:
- リスク:大規模災害によるシステム全体の利用不能
- 対策:
- 復旧目標の設定(RPO, RTO)
- バックアップと復元手順の整備
- 定期的な復旧訓練
-
事業継続計画(BCP):
- リスク:長期的なサービス中断による事業影響
- 対策:
- 優先業務の特定
- 代替手段の準備
- コミュニケーション計画の策定
💡 学習ポイント
ディザスタリカバリ計画では、「復旧ポイント目標(RPO:どの時点までのデータを復旧するか)」と「復旧時間目標(RTO:どれだけ早く復旧するか)」を明確にすることが重要です。これらの目標は、コストとのバランスを考慮して設定します。
11.4 プロジェクト管理リスク
プロジェクト進行上のリスクと対策:
11.4.1 スケジュールリスク
-
見積もり誤差:
- リスク:過度に楽観的な見積もりによる納期遅延
- 対策:
- 複数の見積もり方法の併用(トップダウン、ボトムアップ)
- 過去プロジェクトのデータに基づく見積もり
- バッファの適切な設定(+20〜50%)
-
スコープクリープ:
- リスク:要件の追加・変更による作業量増加
- 対策:
- 明確な要件定義と優先順位付け
- 変更管理プロセスの確立
- MVPアプローチの採用
📝 若手エンジニア向けメモ
見積もりは「確約」ではなく「予測」であることを理解しましょう。初期段階では不確実性が高いため、幅を持たせた見積もりや、段階的に精度を高めていくアプローチが効果的です。また、見積もりを出す際は、その前提条件や制約も明確に伝えることが重要です。 -
依存関係の管理:
- リスク:外部依存による遅延連鎖
- 対策:
- 依存関係の早期特定とマッピング
- クリティカルパスの管理
- 代替案の事前検討
11.4.2 リソースリスク
-
チーム構成:
- リスク:スキルギャップ、リソース不足
- 対策:
- 必要スキルの早期特定
- クロストレーニングの実施
- 外部リソースの計画的活用
-
メンバー離脱:
- リスク:主要メンバーの突然の離脱
- 対策:
- 知識共有の徹底
- ドキュメンテーションの充実
- バックアップ要員の育成
💡 学習ポイント
プロジェクトの「バス係数」(そのメンバーがバスに轢かれたら困る度合い)を意識しましょう。特定の個人にのみ知識や経験が集中していると、その人が不在になった場合に大きなリスクとなります。知識の共有と分散が重要です。 -
予算管理:
- リスク:予算超過、リソース制約
- 対策:
- 定期的な予算レビュー
- 段階的な投資判断
- コスト最適化の継続的実施
11.4.3 コミュニケーションリスク
-
ステークホルダー管理:
- リスク:期待値のミスマッチ、サポート不足
- 対策:
- ステークホルダー分析と関係構築
- 定期的な状況報告
- 早期の問題提起と協力要請
-
チーム内コミュニケーション:
- リスク:情報の分断、誤解
- 対策:
- 定期的な進捗会議
- チャットやドキュメント共有の活用
- 対面/リモートのバランス確保
📝 若手エンジニア向けメモ
問題や懸念事項は、早めに共有することが重要です。「自分で解決しようとして報告が遅れる」よりも、「早めに共有して一緒に対策を考える」ほうが、結果的にはプロジェクトのリスクを減らすことができます。 -
リモートワークの課題:
- リスク:孤立感、協業効率低下
- 対策:
- 定期的な1on1ミーティング
- バーチャルペアプログラミング
- オンラインホワイトボードの活用
11.4.4 技術的負債
-
短期的な解決策の蓄積:
- リスク:将来的な保守性・拡張性の低下
- 対策:
- 技術的負債の可視化(コードの品質メトリクス等)
- 「返済」のための定期的な時間確保
- リファクタリングの文化醸成
-
不適切なアーキテクチャ選択:
- リスク:スケーラビリティ問題、パフォーマンスボトルネック
- 対策:
- 定期的なアーキテクチャレビュー
- 段階的な改善計画
- 将来を見据えた設計判断
💡 学習ポイント
技術的負債は「借金」のようなものです。短期的にはスピードを得られますが、放置すると「利子」(保守コスト増、変更困難性など)が増大します。完全に避けることは現実的ではありませんが、意識的に管理し、定期的に「返済」することが重要です。
11.5 法的・倫理的リスク
法令遵守や倫理的考慮に関するリスク:
11.5.1 データプライバシー
-
個人情報保護:
- リスク:個人情報保護法違反、GDPR違反
- 対策:
- プライバシーバイデザイン原則の採用
- 個人情報の最小限収集
- データ処理の法的根拠の明確化
- プライバシーポリシーの整備と遵守
-
ユーザー同意管理:
- リスク:情報利用に関する同意取得不備
- 対策:
- 明示的な同意取得の仕組み
- 同意の撤回・変更機能
- データ使用目的の透明な説明
📝 若手エンジニア向けメモ
データプライバシーに関する法規制は国や地域によって異なります。グローバルに展開するサービスでは、最も厳しい基準(多くの場合EUのGDPR)に合わせた対応を検討することが一般的です。不明点は法務部門や専門家に相談することをお勧めします。
11.5.2 知的財産権
-
ライセンス遵守:
- リスク:オープンソースライセンス違反
- 対策:
- 使用ライブラリのライセンス確認
- ライセンス条項の遵守(著作権表示など)
- 商用利用制限の確認
-
競合知的財産の尊重:
- リスク:特許侵害、著作権侵害
- 対策:
- 特許調査の実施
- 独自開発の推進
- 必要に応じたライセンス取得
💡 学習ポイント
オープンソースライセンスには様々な種類があり、条件も異なります。例えば、MIT/BSDライセンスは比較的緩やかな条件ですが、GPLは派生物のソースコード公開を求めるなど、より厳格な条件があります。利用前に必ずライセンス条項を確認しましょう。
11.5.3 アクセシビリティとインクルージョン
-
アクセシビリティ基準:
- リスク:障害を持つユーザーの排除、差別
- 対策:
- WCAGガイドラインの遵守
- スクリーンリーダー対応
- キーボードナビゲーション対応
-
多様性への配慮:
- リスク:特定グループへの差別・偏見
- 対策:
- インクルーシブな言語の使用
- 多様なユーザーテスト
- バイアスの認識と軽減
📝 若手エンジニア向けメモ
アクセシビリティへの配慮は、単なる法的リスク回避ではなく、より多くのユーザーに価値を提供するための重要な取り組みです。早期からの対応が、後からの大規模な修正を防ぎ、結果的にコスト削減にもつながります。
11.5.4 APIデータ利用の倫理
-
データソースの利用規約遵守:
- リスク:利用規約違反、法的紛争
- 対策:
- 各データソースの利用規約調査
- 許可された用途での利用
- 必要なクレジット表示
-
倫理的なデータ収集:
- リスク:過度なデータ収集、透明性欠如
- 対策:
- 目的明確化と必要最小限の
第12章:用語集と参考資料
目次
📚 この章で学ぶこと
- プロジェクトで使用される主要な技術用語の定義
- システム設計とプロジェクト管理の専門用語
- 各分野の学習に役立つリソースと図書の紹介
- 若手エンジニアのためのスキルアップロードマップ
🔑 重要な概念
- 専門用語の正確な理解と使用法
- 継続的な学習のためのリソース活用法
- 技術スタック別の学習優先順位
12.1 技術用語集
プロジェクトで使用される主要な技術用語の説明:
12.1.1 基本技術用語
| 用語 | 説明 | 初心者向け解説 |
|---|---|---|
| API (Application Programming Interface) | ソフトウェアコンポーネント間の通信方法を定義したインターフェース | アプリケーション同士が会話するための「共通言語」のようなもの |
| REST (Representational State Transfer) | HTTPプロトコルを利用したWebサービス設計の原則 | リソース(データ)をURLで表し、HTTPメソッド(GET/POST等)で操作する設計スタイル |
| JSON (JavaScript Object Notation) | 軽量なデータ交換フォーマット | 人間にも機械にも読みやすい形式のデータ表現方法 |
| ORM (Object-Relational Mapping) | オブジェクト指向言語とリレーショナルデータベース間の変換技術 | プログラミング言語のオブジェクトとデータベースのテーブルを橋渡しする技術 |
| CRUD | Create(作成)、Read(読取)、Update(更新)、Delete(削除)の頭文字 | データ操作の基本的な4つの操作を表す用語 |
12.1.2 フロントエンド技術
| 用語 | 説明 | 初心者向け解説 |
|---|---|---|
| SPA (Single Page Application) | ページ遷移なしで動作するWebアプリケーション | 一度ロードした後はページ全体を再読み込みせず動的に内容を更新するWebアプリ |
| レスポンシブデザイン | 異なる画面サイズに自動適応するUIデザイン手法 | スマホからPCまで、画面サイズに合わせて最適な表示に自動調整する設計 |
| PWA (Progressive Web App) | ネイティブアプリのような体験を提供するWebアプリ | オフライン対応やプッシュ通知などの機能を持つ高機能Webアプリ |
| DOM (Document Object Model) | HTMLやXML文書をプログラムから操作するためのAPI | Webページの構造を木構造で表現し、JavaScriptで操作できるようにする仕組み |
| SSR (Server-Side Rendering) | サーバー側でHTMLを生成してクライアントに送る手法 | サーバーでページの内容を完成させてから送信する方式(初期表示が速い) |
12.1.3 バックエンド技術
| 用語 | 説明 | 初心者向け解説 |
|---|---|---|
| RDBMS | リレーショナルデータベース管理システム | データを表形式で保存し、関連付けて管理するデータベースシステム |
| NoSQL | 非リレーショナルデータベース | 表形式にこだわらない柔軟なデータ構造を持つデータベース |
| ミドルウェア | アプリケーションとシステムソフトウェアの間に位置するソフトウェア | アプリケーションの「仲介役」として動作するソフトウェア層 |
| マイクロサービス | 小さく独立したサービスの集合体としてのアプリケーション設計 | 大きなアプリを機能ごとに小さな独立したサービスに分割する設計手法 |
| コンテナ化 | アプリケーションとその依存関係を一つのパッケージにまとめる技術 | アプリと必要な環境を「箱(コンテナ)」にまとめて、どこでも同じように動作させる技術 |
📝 若手エンジニア向けメモ
専門用語は「知っているふり」をせず、分からない場合は質問することが重要です。専門用語の誤解は、後々大きな問題を引き起こす可能性があります。また、概念を自分の言葉で説明できるようになることで、本当の理解に近づきます。
12.1.4 データベース関連用語
| 用語 | 説明 | 初心者向け解説 |
|---|---|---|
| インデックス | データベースの検索を高速化するための仕組み | 本の索引のように、データの場所をすぐに見つけられるようにする仕組み |
| トランザクション | 一連のデータベース操作を不可分な単位として扱う機能 | 複数の操作をひとまとめにし、全部成功するか全部失敗するかのどちらかになる仕組み |
| 正規化 | データの冗長性を減らし、一貫性を高めるためのプロセス | データの重複を減らし、整理するプロセス(同じデータを複数箇所に保存しない) |
| シャーディング | データベースを複数のサーバーに分割する手法 | 大量のデータを複数のサーバーに分散して保存・処理する方法 |
| ORM | Object-Relational Mapping(オブジェクト関係マッピング) | プログラムのオブジェクトとデータベースのテーブルを橋渡しする技術 |
12.1.5 インフラストラクチャ用語
| 用語 | 説明 | 初心者向け解説 |
|---|---|---|
| IaaS | Infrastructure as a Service | サーバーやネットワークなどのインフラをクラウドで提供するサービス |
| PaaS | Platform as a Service | アプリケーション実行環境をクラウドで提供するサービス |
| SaaS | Software as a Service | ソフトウェア自体をクラウドで提供するサービス |
| コンテナオーケストレーション | 複数のコンテナの運用・管理を自動化する技術 | 多数のコンテナの配置や通信、スケーリングなどを自動で管理する仕組み |
| CI/CD | Continuous Integration/Continuous Delivery | コードの継続的な統合とデリバリーを自動化するプロセス |
12.1.6 セキュリティ用語
| 用語 | 説明 | 初心者向け解説 |
|---|---|---|
| 認証 (Authentication) | ユーザーの身元を確認するプロセス | 「あなたは誰か」を確認するプロセス(ログインなど) |
| 認可 (Authorization) | ユーザーのアクセス権限を制御するプロセス | 「何ができるか」を制御するプロセス(権限管理) |
| JWT | JSON Web Token | 認証情報を安全にやり取りするためのトークン形式 |
| HTTPS | HTTP over SSL/TLS | データを暗号化して送受信するセキュアなHTTP |
| CORS | Cross-Origin Resource Sharing | 異なるドメイン間でのリソース共有を制御するセキュリティ機能 |
💡 学習ポイント
セキュリティ関連の用語は特に正確な理解が重要です。例えば「認証」と「認可」は似ていますが、まったく異なる概念です。認証は「あなたが誰であるか」を確認するプロセスで、認可は「あなたが何をする権限があるか」を決定するプロセスです。この違いを理解することは、適切なセキュリティ設計の基本です。
12.2 システム設計用語
システム設計で使用される主要な用語:
12.2.1 アーキテクチャパターン
| 用語 | 説明 | 初心者向け解説 |
|---|---|---|
| レイヤードアーキテクチャ | 機能を水平レイヤーに分割する設計 | プレゼンテーション層、ビジネスロジック層、データアクセス層など、役割ごとに層を分ける設計 |
| マイクロサービスアーキテクチャ | 独立した小さなサービスの集合体による設計 | 大きなアプリケーションを独立して動作する小さなサービスに分割する設計 |
| イベント駆動アーキテクチャ | イベントの生成と消費に基づく設計 | システムコンポーネント間でイベント(出来事)のメッセージをやり取りする設計 |
| サーバーレスアーキテクチャ | サーバー管理を抽象化し、関数単位で実行する設計 | サーバーの管理をクラウドに任せ、必要な時に必要な処理だけ実行する設計 |
| モノリシックアーキテクチャ | 単一のコードベースによる統合アプリケーション | 全ての機能が一つのアプリケーションとして統合されている設計 |
12.2.2 デザインパターン
| 用語 | 説明 | 初心者向け解説 |
|---|---|---|
| シングルトン | クラスのインスタンスが一つだけ存在することを保証するパターン | 特定のクラスのオブジェクトが一つだけ作られるようにする仕組み |
| ファクトリー | オブジェクト生成を専門のクラスに委譲するパターン | オブジェクトの作成を専門の「工場」に任せるパターン |
| オブザーバー | オブジェクトの状態変化を他のオブジェクトに通知するパターン | あるオブジェクトの変化を監視し、変化があった時に通知を受け取る仕組み |
| ストラテジー | アルゴリズムを切り替え可能にするパターン | アルゴリズムを交換可能にして、状況に応じて最適な方法を選べるようにするパターン |
| デコレーター | オブジェクトに動的に機能を追加するパターン | 既存のオブジェクトに新しい機能を「装飾」のように追加するパターン |
📝 若手エンジニア向けメモ
デザインパターンは「問題に対する定型的な解決策」であり、車輪の再発明を防ぎます。ただし、パターンを適用すること自体が目的ではなく、問題に適したパターンを選ぶことが重要です。「パターンのための設計」ではなく「問題解決のためのパターン」という視点を持ちましょう。
12.2.3 クリーンアーキテクチャと関連概念
| 用語 | 説明 | 初心者向け解説 |
|---|---|---|
| クリーンアーキテクチャ | 関心の分離に基づく層状アーキテクチャ | ビジネスロジックを中心に置き、外部依存から保護する設計手法 |
| 依存性逆転の原則 | 高レベルモジュールが低レベルモジュールに依存すべきでない原則 | 実装の詳細ではなく、抽象(インターフェース)に依存するべきという原則 |
| ユースケース | システムがユーザーのために実行する特定の機能 | システムが「何をするか」を表す機能単位 |
| エンティティ | ビジネスルールをカプセル化するオブジェクト | ビジネスの核となるオブジェクトと、それに関するルール |
| リポジトリパターン | データアクセスを抽象化するパターン | データの保存と取得を行うコードを、使用する側から隠蔽するパターン |
12.2.4 分散システム概念
| 用語 | 説明 | 初心者向け解説 |
|---|---|---|
| CAP定理 | 一貫性、可用性、分断耐性の3つを同時に満たせないという定理 | 分散システムでは、データの一貫性、システムの可用性、ネットワーク障害への耐性の3つを同時に100%満たすことはできないという原則 |
| 最終的一貫性 | 時間が経てば全てのレプリカが一貫した状態になるという保証 | いずれは全てのサーバーで同じデータ状態になることを保証する一貫性モデル |
| シャーディング | データを複数のノードに分散して保存する手法 | 大量のデータを複数のサーバーに分けて保存する方法 |
| レプリケーション | データを複数のノードに複製する手法 | 同じデータを複数のサーバーに複製して保存する方法 |
| 負荷分散 | 複数のノードに処理を分散する技術 | リクエストを複数のサーバーに振り分けて、処理負荷を分散させる仕組み |
12.2.5 API設計概念
| 用語 | 説明 | 初心者向け解説 |
|---|---|---|
| RESTful API | REST原則に基づくAPI設計 | リソース(データ)をURLで表し、HTTPメソッドで操作するAPI |
| GraphQL | クライアント指定のデータ取得が可能なクエリ言語 | 必要なデータだけを1回のリクエストで取得できるAPI仕様 |
| OpenAPI/Swagger | REST APIの仕様を記述するためのフォーマット | APIの仕様を文書化し、テスト・生成ができるツール |
| API Gateway | APIへのアクセスを一元管理するサービス | 複数のAPIへのアクセスを制御し、認証・ログ・変換などの共通処理を行うサービス |
| API First開発 | APIの設計から始める開発アプローチ | システム実装前にAPIを設計し、それを中心に開発を進める手法 |
💡 学習ポイント
システム設計では、適切な抽象化レベルを選ぶことが重要です。詳細すぎる設計は柔軟性を失い、抽象的すぎる設計は具体的な実装指針を与えません。設計図は「チームの共通理解を促進するためのコミュニケーションツール」という視点で、適切な詳細度を考慮しましょう。
12.3 プロジェクト管理用語
プロジェクト管理で使用される主要な用語:
12.3.1 アジャイル開発関連用語
| 用語 | 説明 | 初心者向け解説 |
|---|---|---|
| スクラム | 反復的・漸進的な開発手法の一種 | チームが短い期間(スプリント)で機能を開発し、定期的に振り返りながら進める手法 |
| スプリント | スクラムにおける1〜4週間の開発期間 | 特定の機能を開発するために区切られた期間(1〜4週間) |
| カンバン | 視覚的なタスク管理手法 | タスクをカードに書いて、作業状態(ToDo/進行中/完了など)を可視化する手法 |
| ユーザーストーリー | ユーザー視点で記述された要件 | 「〜として、〜したい。なぜなら〜だから」という形式でユーザーのニーズを記述した要件 |
| バックログ | 未実施の作業項目のリスト | これから実施するタスクをまとめたリスト(優先順位付け) |
12.3.2 見積もりと計画
| 用語 | 説明 | 初心者向け解説 |
|---|---|---|
| ストーリーポイント | タスクの相対的な複雑さや作業量を表す単位 | 具体的な時間ではなく、タスクの難しさや大きさを相対的に表す点数 |
| ベロシティ | チームが一定期間に完了できる作業量 | チームが1スプリントで完了できるストーリーポイントの合計 |
| バーンダウンチャート | 残作業量の推移を視覚化したグラフ | 時間の経過と共に残りの作業がどれだけ減っているかを示すグラフ |
| クリティカルパス | プロジェクト完了までの最短経路上にあるタスク群 | プロジェクトの期間に直接影響するタスクの連鎖 |
| MVP (Minimum Viable Product) | 最小限の機能を持つ製品 | 最小限の機能で価値を提供できる製品バージョン |
📝 若手エンジニア向けメモ
見積もりは常に不確実性を含むことを理解しましょう。特に初期段階では±50%程度の誤差があるのが普通です。また、見積もりを「コミットメント(約束)」と混同しないことも重要です。見積もりは「現在の知識に基づく予測」であり、新たな情報が得られたら更新されるべきものです。
12.3.3 品質管理
| 用語 | 説明 | 初心者向け解説 |
|---|---|---|
| TDD (Test-Driven Development) | テスト駆動開発 | テストを先に書いてから実装を行う開発手法 |
| BDD (Behavior-Driven Development) | 振る舞い駆動開発 | システムの振る舞いを自然言語で記述し、それをテストに変換する開発手法 |
| CI (Continuous Integration) | 継続的インテグレーション | コードの変更を定期的に統合し、自動テストを実行する手法 |
| CD (Continuous Delivery/Deployment) | 継続的デリバリー/デプロイメント | ソフトウェアを自動的にテスト環境/本番環境にリリースする手法 |
| コードカバレッジ | テストがコードをカバーしている割合 | テストによって実行されるコードの割合 |
12.3.4 チーム開発手法
| 用語 | 説明 | 初心者向け解説 |
|---|---|---|
| ペアプログラミング | 2人で1つのコードを書く手法 | 2人のプログラマーが1台のコンピュータで協力してコードを書く手法 |
| モブプログラミング | チーム全体で1つのコードを書く手法 | チーム全員が同じ問題に取り組み、1人がコードを書き、他のメンバーが方向性を示す手法 |
| コードレビュー | 他のプログラマーによるコードの検査 | 書いたコードを他のプログラマーがチェックし、品質を高める活動 |
| プルリクエスト/マージリクエスト | コード変更の提案と確認のプロセス | 変更したコードをメインブランチに取り込む前に、レビューを受けるプロセス |
| ** |
-
ファイル名: スネークケース(例:
restaurant_service.py) -
クラス名: パスカルケース(例:
RestaurantService) -
関数/メソッド名: スネークケース(例:
get_restaurant_by_id) -
変数名: スネークケース(例:
restaurant_list) -
定数: 大文字のスネークケース(例:
MAX_RESULTS) -
プライベートメンバー: 先頭にアンダースコア(例:
_private_method) -
特殊メソッド: 前後にダブルアンダースコア(例:
__init__)
# 良い例
class RestaurantService:
"""レストラン関連のサービスクラス"""
MAX_RESULTS = 100
def __init__(self, repository):
self._repository = repository
def get_restaurants(self, max_results=None):
"""レストランのリストを取得する"""
if max_results is None:
max_results = self.MAX_RESULTS
return self._repository.get_all(limit=max_results)
コードスタイル
- インデント: 4スペース(タブではなく)
- 行の長さ: 最大88文字
-
インポート順:
- 標準ライブラリ
- サードパーティライブラリ
- ローカルアプリケーション/ライブラリ
-
インポート形式:
- モジュール全体のインポートが望ましい(
import xxx) - ただし、広く使われているライブラリの一部は直接インポートも可(
from xxx import yyy)
- モジュール全体のインポートが望ましい(
# 良い例
import os
import json
from datetime import datetime
import requests
from fastapi import FastAPI, Depends
from app.models import Restaurant
from app.services import RestaurantService
ドキュメンテーション
- Docstring形式: Google形式またはSphinx形式(プロジェクト内で統一)
- モジュールDocstring: ファイルの先頭に、モジュールの目的を記述
- クラスDocstring: クラスの責務と使用方法を記述
- 関数Docstring: 機能、引数、戻り値、例外、使用例を記述
def search_restaurants(query=None, cuisine_type=None, min_rating=None, page=1, page_size=20):
"""
レストランを検索する関数
Args:
query (str, optional): 検索キーワード
cuisine_type (str, optional): 料理ジャンル
min_rating (float, optional): 最低評価(1.0-5.0)
page (int): ページ番号(1から開始)
page_size (int): 1ページあたりの結果数
Returns:
dict: 検索結果。以下の構造:
{
"total": int, # 全件数
"items": list[Restaurant], # レストランリスト
"page": int, # 現在のページ
"page_size": int # ページサイズ
}
Raises:
ValueError: 引数の値が不正な場合
Examples:
>>> result = search_restaurants(query="ラーメン", min_rating=4.0)
>>> print(f"Found {result['total']} restaurants")
"""
型アノテーション
- 関数の引数と戻り値には型アノテーションを付ける
- 複雑な型には
typingモジュールを活用する - 型アノテーションが複雑になりすぎる場合は適宜調整する
from typing import List, Dict, Optional, Union, Any
def get_restaurant_by_id(id: int) -> Optional[Dict[str, Any]]:
"""指定されたIDのレストラン情報を取得する"""
# 実装...
def search_restaurants(
query: Optional[str] = None,
cuisine_types: Optional[List[str]] = None,
price_range: Optional[Dict[str, int]] = None
) -> Dict[str, Any]:
"""レストランを検索する"""
# 実装...
エラー処理
- 例外は適切に捕捉し、より具体的な例外に変換する
- 例外クラスの階層を活かした構造的な例外処理を行う
- ロギングとユーザーへのエラーメッセージは分離する
try:
restaurant = await restaurant_service.get_by_id(restaurant_id)
if restaurant is None:
raise HTTPException(status_code=404, detail="Restaurant not found")
return restaurant
except HTTPException:
# すでに適切な形式のため再発生
raise
except ValueError as e:
# 入力値エラーはクライアントエラーとして変換
logger.warning(f"Invalid input for restaurant {restaurant_id}: {str(e)}")
raise HTTPException(status_code=400, detail=str(e))
except Exception as e:
# 予期しないエラーはログに記録し、一般的なエラーメッセージを返す
logger.error(f"Unexpected error getting restaurant {restaurant_id}: {str(e)}", exc_info=True)
raise HTTPException(status_code=500, detail="An unexpected error occurred")
13.2.2 SQLのベストプラクティス
クエリの記述スタイル
- キーワードは大文字(例:
SELECT,WHERE) - テーブル名/カラム名は小文字のスネークケース
- 各句(
SELECT,FROM,WHEREなど)は別の行に - 条件や結合は明確にインデントする
- 長いクエリは適切に改行・インデントする
-- 良い例
SELECT
r.id,
r.name,
r.rating,
c.name AS cuisine_type
FROM
restaurants r
JOIN
restaurant_cuisine_types rct ON r.id = rct.restaurant_id
JOIN
cuisine_types c ON rct.cuisine_type_id = c.id
WHERE
r.rating >= 4.0
AND r.price_level <= 3
AND c.name IN ('イタリアン', '和食', 'フレンチ')
ORDER BY
r.rating DESC,
r.name ASC
LIMIT 20 OFFSET 40;
パフォーマンスを考慮したSQL
- 適切なインデックスを定義・活用する
- 不要なカラムのSELECTを避ける(
SELECT *禁止) - JOINは必要最小限に留める
- 大きな結果セットには常にLIMITを付ける
- 複雑な条件は適切に括弧で囲む
-- インデックス作成例
CREATE INDEX idx_restaurants_rating ON restaurants (rating DESC);
CREATE INDEX idx_restaurants_cuisine_price ON restaurants (cuisine_type, price_level);
-- パフォーマンスを考慮したクエリ例
SELECT
r.id,
r.name,
r.rating
FROM
restaurants r
WHERE
r.cuisine_type = 'イタリアン'
AND r.price_level BETWEEN 2 AND 3
AND r.rating >= 4.0
ORDER BY
r.rating DESC
LIMIT 10;
13.2.3 REST API設計ガイドライン
エンドポイント命名
- リソース名は複数形の名詞(例:
/restaurants,/reviews) - リソースの階層関係はURLパスで表現(例:
/restaurants/{id}/reviews) - 動詞はHTTPメソッドで表現し、URLには含めない
- 検索・フィルタリングはクエリパラメータで表現(例:
/restaurants?cuisine=italian)
HTTP動詞の適切な使用
-
GET: リソースの取得(読み取り専用) -
POST: 新しいリソースの作成 -
PUT: リソース全体の置き換え(べき等) -
PATCH: リソースの一部更新 -
DELETE: リソースの削除
# 良い例
GET /restaurants # レストラン一覧の取得
GET /restaurants/{id} # 特定レストランの取得
POST /restaurants # 新しいレストランの作成
PUT /restaurants/{id} # レストラン情報の全体更新
PATCH /restaurants/{id} # レストラン情報の一部更新
DELETE /restaurants/{id} # レストランの削除
GET /restaurants/{id}/reviews # 特定レストランのレビュー一覧
レスポンス形式
- 成功レスポンスは一貫した形式で返す
- エラーレスポンスも一貫した形式で返す
- ページネーション情報は明示的にレスポンスに含める
- HATEOAS原則に基づき、関連リソースへのリンクを提供する
// 成功レスポンス例(一覧)
{
"meta": {
"total": 235,
"page": 2,
"page_size": 20,
"total_pages": 12
},
"links": {
"self": "/api/restaurants?page=2",
"first": "/api/restaurants?page=1",
"prev": "/api/restaurants?page=1",
"next": "/api/restaurants?page=3",
"last": "/api/restaurants?page=12"
},
"items": [
{
"id": 21,
"name": "レストランA",
"rating": 4.5,
"links": {
"self": "/api/restaurants/21",
"reviews": "/api/restaurants/21/reviews"
}
},
// ...他のアイテム
]
}
// エラーレスポンス例
{
"error": {
"code": "INVALID_PARAMETER",
"message": "Rating must be between 1.0 and 5.0",
"details": {
"field": "rating",
"value": 6.0,
"constraint": "1.0 <= rating <= 5.0"
},
"request_id": "req-123456"
}
}
13.2.4 コードレビューチェックリスト
機能面
- 機能要件を満たしているか
- エッジケースが考慮されているか
- エラー処理は適切か
- パフォーマンスは要件を満たすか
コード品質
- コードはDRY原則に従っているか(重複がないか)
- 命名は明確で一貫性があるか
- 適切なコメントと説明があるか
- 型アノテーションは正確か
セキュリティ
- ユーザー入力は適切に検証されているか
- SQLインジェクションなどの脆弱性はないか
- 機密情報の扱いは適切か
- 認証・認可は正しく実装されているか
テスト
- ユニットテストはあるか
- エッジケースや異常系のテストも含まれているか
- モックやスタブは適切に使用されているか
- 十分なカバレッジがあるか
13.3 設計ドキュメントテンプレート
13.3.1 機能設計ドキュメント
# 機能設計ドキュメント:[機能名]
## 1. 概要
[機能の概要と目的、解決する課題について1-2段落で説明]
## 2. 要件
### 2.1 機能要件
- [具体的な機能要件をリスト形式で記述]
### 2.2 非機能要件
- **パフォーマンス**: [レスポンスタイム、スループットなどの要件]
- **セキュリティ**: [セキュリティ要件]
- **可用性**: [可用性要件]
- **拡張性**: [将来の拡張に関する要件]
## 3. ユーザーストーリー
[ユーザーの視点からのシナリオを記述]
**例**:
> ユーザーとして、料理ジャンルと価格帯でレストランを検索し、評価の高い順に表示したい。これにより、自分の好みと予算に合ったレストランを効率的に見つけることができる。
## 4. 技術設計
### 4.1 API設計
[HTTPメソッド] [エンドポイント]
リクエスト:
[リクエストパラメータやボディの例]
レスポンス:
[レスポンスの例]
### 4.2 データモデル
[関連するデータモデル(テーブル、スキーマなど)の説明]
### 4.3 アルゴリズム/ロジック
[重要なビジネスロジックや処理フローの説明]
## 5. インターフェース設計
[UI/UXの設計、モックアップ、ワイヤーフレームなど]
## 6. テスト計画
[テスト範囲、テストシナリオ、テスト環境などの説明]
## 7. 実装スケジュール
[タスクの分解と見積もり]
## 8. 懸念事項
[潜在的な問題点や検討事項]
13.3.2 アーキテクチャ決定記録(ADR)
# アーキテクチャ決定記録(ADR)
## ADR-[番号]: [タイトル]
### ステータス
[提案 | 承認済み | 却下 | 置き換え | 廃止]
### コンテキスト
[この決定を行う背景と必要性]
### 決定
[具体的に何を決定したか]
### 代替案
[検討した他の選択肢と比較]
**選択肢1**: [説明]
- **利点**: [メリット]
- **欠点**: [デメリット]
**選択肢2**: [説明]
- **利点**: [メリット]
- **欠点**: [デメリット]
### 判断基準
[意思決定の評価基準と比較]
| 基準 | 重み | 選択肢1 | 選択肢2 | 選択肢3 |
|------|-----|---------|---------|---------|
| [基準1] | [30%] | [4/5] | [3/5] | [5/5] |
| [基準2] | [25%] | [5/5] | [4/5] | [3/5] |
| [基準3] | [20%] | [3/5] | [5/5] | [2/5] |
| ... | ... | ... | ... | ... |
| **加重スコア** | 100% | [4.2/5] | [3.9/5] | [3.5/5] |
### 影響
[この決定がシステムやチームに与える影響]
### 関連ADR
- [関連するADRへの参照]
13.3.3 バグレポートテンプレート
# バグレポート
## 基本情報
- **ID**: [バグID]
- **報告者**: [名前]
- **報告日**: [YYYY-MM-DD]
- **優先度**: [高 | 中 | 低]
- **深刻度**: [クリティカル | 高 | 中 | 低]
- **ステータス**: [新規 | 確認済み | 修正中 | 修正済み | 却下]
- **担当者**: [名前]
## 概要
[バグの簡潔な説明]
## 再現手順
1. [手順1]
2. [手順2]
3. [手順3]
...
## 期待される動作
[本来期待される動作]
## 実際の動作
[実際に観察された動作]
## 環境
- **OS**: [OS名とバージョン]
- **ブラウザ/クライアント**: [名前とバージョン]
- **バックエンド環境**: [環境情報]
- **デバイス**: [関連する場合]
## スクリーンショット/動画
[あれば添付]
## ログ/エラーメッセージ
[関連するログやエラーメッセージ]
## 補足情報
[その他の関連情報]
13.4 チェックリスト集
13.4.1 リリース前チェックリスト
機能検証
- すべての要件が実装されていることを確認
- エッジケースを含めた機能テストが完了
- フロントエンド(UI)テストが完了
- 複数環境(ブラウザ、デバイスなど)での動作確認
- ユーザーストーリーに基づいた受け入れテストが完了
コード品質
- すべてのコードレビューコメントが対応済み
- リンター/静的解析によるコードチェックが通過
- ユニットテスト、統合テストが通過
- コードカバレッジが目標値を達成
- パフォーマンステストで性能要件を満たすことを確認
セキュリティ
- セキュリティチェックリストに基づくレビューが完了
- 脆弱性スキャンを実施
- 機密情報の取り扱いを検証
- 認証・認可のテスト完了
- 入力値の検証が適切に行われていることを確認
インフラストラクチャ
- 本番環境の構成が最新
- スケーリング設定の確認
- バックアップと復旧手順の確認
- 監視とアラートが設定済み
- 緊急時の対応フローの確認
ドキュメンテーション
- API仕様書が更新済み
- 運用マニュアルが更新済み
- リリースノートの作成
- ユーザードキュメントの更新
- 内部開発者向けドキュメントの更新
13.4.2 コードレビューチェックリスト
機能
- 要件を満たしているか
- ビジネスロジックは正しいか
- エッジケースが考慮されているか
- バックワードコンパティビリティは維持されているか
- 国際化・ローカライズ対応は適切か(必要な場合)
コード品質
- コーディング規約に準拠しているか
- 命名は明確で理解しやすいか
- コメントは適切か(複雑なロジックの説明など)
- 不要なコードやコメントはないか
- リファクタリングの余地はないか
アーキテクチャ
- アーキテクチャパターンに準拠しているか
- 責務の分離は適切か
- コンポーネント間の依存関係は適切か
- インターフェースは明確に定義されているか
- 設計上の懸念事項はないか
テスト
- ユニットテストは適切に書かれているか
- エッジケースのテストがあるか
- 異常系のテストがあるか
- テストのカバレッジは十分か
- モックやスタブは適切に使用されているか
セキュリティ
- 入力検証は適切か
- SQL/NoSQLインジェクションの対策はあるか
- XSS対策はあるか
- CSRF対策はあるか
- 認証・認可のチェックは適切か
パフォーマンス
- 非効率なアルゴリズムや処理はないか
- データベースクエリは最適化されているか
- N+1問題は回避されているか
- キャッシュは適切に使用されているか
- リソース利用(メモリ、CPU)は適切か
13.4.3 セキュリティチェックリスト
認証と認可
- 強力なパスワードポリシーが適用されている
- 多要素認証(MFA)のサポート
- セッショントークンは安全に管理されている
- 権限チェックがすべての保護されたリソースに適用されている
- APIエンドポイントの認可チェックが網羅的
入力検証とサニタイゼーション
- すべての入力が検証されている
- 型、長さ、形式、範囲などの検証ルールが適用されている
- HTML/JavaScript出力のエスケープ処理が行われている
- SQLインジェクション対策が行われている
- ファイルアップロードの検証と制限が行われている
データ保護
- 機密データは保存時に暗号化されている
- 転送中のデータはTLS/SSLで保護されている
- APIキーやシークレットは安全に管理されている
- 個人情報の取り扱いはプライバシーポリシーに準拠している
- データ取得のレート制限が設定されている
エラー処理とロギング
- エラーメッセージに機密情報が含まれていない
- 例外が適切に捕捉・処理されている
- セキュリティイベントが適切にログに記録されている
- ログに機密情報が含まれていない
- ログのアクセス制御と保持ポリシーが定義されている
インフラストラクチャセキュリティ
- 不要なサービスやポートが無効化されている
- すべてのシステムコンポーネントが最新の状態に保たれている
- セキュリティヘッダー(CSP, X-XSS-Protection等)が設定されている
- CORSポリシーが適切に設定されている
- DDoS対策が検討されている
13.5 開発環境セットアップガイド
13.5.1 ローカル開発環境構築手順
前提条件
- Python 3.10以上
- Docker と Docker Compose
- Git
- VS Code (推奨エディタ)
リポジトリのクローンと初期設定
# リポジトリをクローン
git clone https://github.com/your-org/restaurant-search-system.git
cd restaurant-search-system
# 仮想環境を作成して有効化
python -m venv venv
source venv/bin/activate # Windowsの場合: venv\Scripts\activate
# 依存パッケージのインストール
pip install -r requirements.txt
pip install -r requirements-dev.txt # 開発用の追加パッケージ
# pre-commitフックのインストール
pre-commit install
環境変数の設定
.env.example ファイルを .env としてコピーし、必要に応じて値を調整します。
cp .env.example .env
# エディタで.envを編集
Dockerコンテナの起動
# 開発用のコンテナを起動
docker-compose -f docker-compose.dev.yml up -d
# コンテナの状態を確認
docker-compose ps
起動されるコンテナ:
- PostgreSQL (ポート: 5432)
- Elasticsearch (ポート: 9200)
- Redis (ポート: 6379)
- Kibana (ポート: 5601) - Elasticsearchの管理UI
データベースのセットアップ
# マイグレーションの実行
alembic upgrade head
# (オプション) テストデータの投入
python scripts/seed_database.py
アプリケーションの起動
# APIサーバーを開発モードで起動
uvicorn app.main:app --reload --port 8000
# 別のターミナルでバッチ処理を開発モードで起動 (必要な場合)
python -m app.batch.scheduler --dev
動作確認
以下のURLにアクセスして動作確認を行います:
- API: http://localhost:8000/
- API ドキュメント: http://localhost:8000/docs
- Kibana: http://localhost:5601/
13.5.2 VS Code 設定
推奨拡張機能
{
"recommendations": [
"ms-python.python",
"ms-python.vscode-pylance",
"ms-azuretools.vscode-docker",
"ms-vscode-remote.remote-containers",
"eamodio.gitlens",
"editorconfig.editorconfig",
"streetsidesoftware.code-spell-checker",
"ryanluker.vscode-coverage-gutters",
"matangover.mypy"
]
}
作業スペース設定
.vscode/settings.json を以下のように設定します:
{
"python.linting.enabled": true,
"python.linting.flake8Enabled": true,
"python.linting.mypyEnabled": true,
"python.formatting.provider": "black",
"python.formatting.blackArgs": [
"--line-length=88"
],
"editor.formatOnSave": true,
"editor.codeActionsOnSave": {
"source.organizeImports": true
},
"python.testing.pytestEnabled": true,
"python.testing.unittestEnabled": false,
"python.testing.nosetestsEnabled": false,
"python.testing.pytestArgs": [
"tests"
],
"[python]": {
"editor.rulers": [
88
]
},
"files.exclude": {
"**/.git": true,
"**/.svn": true,
"**/.hg": true,
"**/CVS": true,
"**/.DS_Store": true,
"**/__pycache__": true,
"**/.pytest_cache": true,
"**/venv": true
}
}
13.5.3 コードベース構造
restaurant-search-system/
├── app/ # アプリケーションコード
│ ├── api/ # APIエンドポイント
│ ├── application/ # アプリケーションサービス
│ ├── batch/ # バッチ処理
│ ├── core/ # コア設定
│ ├── domain/ # ドメインモデル
│ ├── infrastructure/ # インフラストラクチャ
│ └── main.py # アプリエントリーポイント
├── tests/ # テストコード
│ ├── unit/ # ユニットテスト
│ ├── integration/ # 統合テスト
│ ├── functional/ # 機能テスト
│ └── conftest.py # テスト共通設定
├── scripts/ # ユーティリティスクリプト
├── migrations/ # データベースマイグレーション
├── docs/ # ドキュメント
├── .github/ # GitHub Actions設定
├── .vscode/ # VS Code設定
├── docker/ # Dockerファイル
├── docker-compose.yml # Docker Compose設定
├── docker-compose.dev.yml # 開発用Docker Compose設定
├── .env.example # 環境変数テンプレート
├── .gitignore # Gitの無視設定
├── .pre-commit-config.yaml # pre-commit設定
├── requirements.txt # 依存パッケージ
├── requirements-dev.txt # 開発用依存パッケージ
├── pyproject.toml # Python プロジェクト設定
├── setup.cfg # パッケージング設定
└── README.md # プロジェクト概要
13.5.4 開発ワークフロー
ブランチ戦略
GitHubフロー(シンプルなフィーチャーブランチフロー)を採用します:
-
mainブランチは常に最新の安定版 - 新機能開発はフィーチャーブランチで実施
- ブランチ名:
feature/機能名 - バグ修正:
fix/バグ名 - リファクタリング:
refactor/内容
- ブランチ名:
- 開発完了後、PRを作成して
mainにマージ - CIによる自動テスト実行後、コードレビューを経てマージ
開発サイクル
-
タスク選択
- JIRAやGitHub Issuesからタスクを選択
- タスクの理解と必要に応じた詳細化
-
ブランチ作成
git checkout main git pull git checkout -b feature/my-new-feature -
実装
- コーディング規約に従って実装
- 適宜コミット(粒度の小さい論理的なまとまりで)
- コミットメッセージは「何をしたか」が明確に
-
テスト
# 静的解析 flake8 app tests mypy app # ユニットテスト pytest tests/unit/ # 統合テスト pytest tests/integration/ -
プルリクエスト
- PR作成前に最新の
mainを取り込むgit checkout main git pull git checkout feature/my-new-feature git merge main # または git rebase main git push origin feature/my-new-feature - GitHub UIでPRを作成
- PR説明文に変更内容、テスト方法、注意点などを記載
- PR作成前に最新の
-
コードレビュー
- レビューコメントに対応
- 必要に応じて修正をコミット
- CIが全て通過することを確認
-
マージと後処理
- レビュー承認後、
mainにマージ - ローカルの後処理
git checkout main git pull git branch -d feature/my-new-feature
- レビュー承認後、
デバッグ方法
1. ログ出力によるデバッグ
import logging
# ロガーの取得
logger = logging.getLogger(__name__)
# 各レベルでのログ出力
logger.debug("デバッグ情報: %s", some_variable)
logger.info("情報: 処理を開始します")
logger.warning("警告: 想定外の値です: %s", value)
logger.error("エラー: 処理に失敗しました", exc_info=True) # 例外情報を含める
2. デバッガーの使用
import pdb
# コード内にブレークポイントを設定
def some_function():
x = calculate_something()
pdb.set_trace() # この行で実行が停止し、対話的デバッグが可能
y = process_data(x)
return y
VS Codeでは、.vscode/launch.json を設定することで、より高度なデバッグが可能です:
{
"version": "0.2.0",
"configurations": [
{
"name": "Python: FastAPI",
"type": "python",
"request": "launch",
"module": "uvicorn",
"args": [
"app.main:app",
"--reload"
],
"jinja": true,
"justMyCode": false
},
{
"name": "Python: Current File",
"type": "python",
"request": "launch",
"program": "${file}",
"console": "integratedTerminal",
"justMyCode": false
}
]
}
3. テスト駆動デバッグ
問題の再現テストを作成し、デバッグする方法:
def test_problematic_scenario():
# 問題を再現する条件をセットアップ
input_data = {"problematic": "value"}
# 問題の発生する関数を呼び出し
result = function_with_bug(input_data)
# 期待される正しい動作をアサート
assert result["status"] == "success"
13.5.5 CI/CD パイプライン
GitHub Actions を使用した CI/CD パイプラインの設定例:
# .github/workflows/main.yml
name: CI/CD Pipeline
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
lint:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: 3.10
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements-dev.txt
- name: Lint with flake8
run: flake8 app tests
- name: Type check with mypy
run: mypy app
test:
runs-on: ubuntu-latest
services:
postgres:
image: postgres:14
env:
POSTGRES_PASSWORD: postgres
POSTGRES_USER: postgres
POSTGRES_DB: test_db
ports:
- 5432:5432
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:8.5.0
env:
discovery.type: single-node
xpack.security.enabled: false
ports:
- 9200:9200
redis:
image: redis:6
ports:
- 6379:6379
steps:
- uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: 3.10
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install -r requirements-dev.txt
- name: Run tests
run: |
pytest tests/unit
pytest tests/integration
- name: Upload coverage reports
uses: codecov/codecov-action@v1
deploy-staging:
needs: [lint, test]
if: github.event_name == 'push' && github.ref == 'refs/heads/main'
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Deploy to staging
run: |
# ステージング環境へのデプロイスクリプト
echo "Deploying to staging..."
# 実際のデプロイコマンド
📝 若手エンジニア向けメモ
CI/CD パイプラインは、コードの品質を保ちながら迅速にデプロイするための重要な仕組みです。各ステップ(静的解析、テスト、ビルド、デプロイ)が自動化されることで、人的ミスを減らし、開発サイクルを高速化できます。また、問題が早期に発見されるため、修正コストも低減します。
13.5.6 トラブルシューティングガイド
共通の問題と解決策
1. データベース接続エラー
症状: OperationalError: could not connect to server: Connection refused
対策:
- Docker ComposeでDBコンテナが起動しているか確認
docker-compose ps - 環境変数の設定が正しいか確認
cat .env | grep DATABASE_URL - ポートの競合がないか確認
sudo lsof -i :5432 # PostgreSQLのデフォルトポート
2. Elasticsearchインデックス作成エラー
症状: ConnectionError: Connection error
対策:
- Elasticsearchコンテナのステータス確認
docker-compose logs elasticsearch - メモリ設定の確認と調整
# docker-compose.ymlのElasticsearchサービス設定 environment: - "ES_JAVA_OPTS=-Xms512m -Xmx512m" # メモリ設定を調整 - Elasticsearchの動作確認
curl http://localhost:9200/_cluster/health
3. 依存パッケージの競合
症状: ImportError: cannot import name 'xxx' from 'yyy'
対策:
- 仮想環境を再作成
rm -rf venv python -m venv venv source venv/bin/activate pip install -r requirements.txt - 依存パッケージのバージョン確認
pip freeze | grep package_name -
pip install --upgradeで特定パッケージを更新
4. APIレスポンスエラー
症状: 期待したレスポンスが返ってこない、エラーステータスコードが返る
対策:
- ログを確認
tail -f logs/app.log - curlで手動テスト
curl -v http://localhost:8000/api/endpoint - 入力データの形式を確認
curl -v -X POST http://localhost:8000/api/endpoint \ -H "Content-Type: application/json" \ -d '{"key": "value"}'
💡 学習ポイント
トラブルシューティングでは、問題を適切に切り分け、仮説を立てて検証するという科学的なアプローチが効果的です。「何が起きているのか」「期待する動作は何か」「違いは何か」を明確にし、一度に一つの変数だけを変更してテストすることで、より効率的に問題の原因を特定できます。
🔍 チェックポイント
- プロジェクトの主要コンポーネントの実装例を理解している
- Python、SQL、REST APIの各コーディング規約を把握している
- 効果的な設計ドキュメントの作成方法を理解している
- プロジェクトの各フェーズで使用するチェックリストの内容を把握している
- 開発環境のセットアップとトラブルシューティングの基本を理解している能なオブジェクトです。一方、値オブジェクトは識別性を持たず、その値自体が重要な不変のオブジェクトです。
アプリケーション層(ユースケース)
# application/queries/search_restaurants.py
from dataclasses import dataclass
from typing import List, Optional
from domain.entities.restaurant import Restaurant
from domain.repositories.restaurant_repository import RestaurantRepository
@dataclass
class SearchRestaurantsQuery:
"""レストラン検索クエリ"""
keyword: Optional[str] = None
cuisine_type: Optional[str] = None
price_level_min: Optional[int] = None
price_level_max: Optional[int] = None
min_rating: Optional[float] = None
location: Optional[str] = None
radius_km: Optional[float] = None
page: int = 1
page_size: int = 20
class SearchRestaurantsHandler:
"""レストラン検索ユースケースハンドラ"""
def __init__(self, repository: RestaurantRepository):
self.repository = repository
async def handle(self, query: SearchRestaurantsQuery) -> List[Restaurant]:
"""検索クエリを処理する"""
# リポジトリ経由でデータを取得
restaurants = await self.repository.search(
keyword=query.keyword,
cuisine_type=query.cuisine_type,
price_level_min=query.price_level_min,
price_level_max=query.price_level_max,
min_rating=query.min_rating,
location=query.location,
radius_km=query.radius_km,
page=query.page,
page_size=query.page_size
)
return restaurants
# application/commands/create_restaurant.py
from dataclasses import dataclass
from typing import List, Optional
from domain.entities.restaurant import Restaurant
from domain.value_objects.address import Address
from domain.repositories.restaurant_repository import RestaurantRepository
from core.exceptions import BusinessLogicException
@dataclass
class CreateRestaurantCommand:
"""レストラン作成コマンド"""
name: str
cuisine_types: List[str]
prefecture: str
city: str
street: str
building: Optional[str] = None
price_level: int = 2
class CreateRestaurantHandler:
"""レストラン作成ユースケースハンドラ"""
def __init__(self, repository: RestaurantRepository):
self.repository = repository
async def handle(self, command: CreateRestaurantCommand) -> Restaurant:
"""コマンドを処理する"""
# ビジネスルールの検証
if len(command.name) < 2:
raise BusinessLogicException("Restaurant name must be at least 2 characters")
if not 1 <= command.price_level <= 4:
raise BusinessLogicException("Price level must be between 1 and 4")
# エンティティの作成
address = Address(
prefecture=command.prefecture,
city=command.city,
street=command.street,
building=command.building
)
# 仮のID(実際はリポジトリで採番)
restaurant = Restaurant(
id=-1, # 仮のID
name=command.name,
cuisine_types=command.cuisine_types,
address=address,
price_level=command.price_level
)
# リポジトリ経由で保存
created_restaurant = await self.repository.create(restaurant)
return created_restaurant
💡 学習ポイント
アプリケーション層は、ドメイン層の能力を活用してユーザーの意図(ユースケース)を実現する層です。コマンド(状態変更)とクエリ(参照)を分離することで、責任の明確化と単一責任の原則を実現しています。この層では、ドメインレベルのビジネスルールだけでなく、アプリケーションレベルのルール(権限チェックなど)も実装されます。
インフラストラクチャ層
# infrastructure/database.py
from sqlalchemy import create_engine, Column, Integer, String, Float, DateTime, ForeignKey, Table
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, relationship
from core.config import settings
# データベース接続
SQLALCHEMY_DATABASE_URL = settings.DATABASE_URL
engine = create_engine(SQLALCHEMY_DATABASE_URL)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
Base = declarative_base()
# infrastructure/repositories/restaurant_repository.py
from typing import List, Optional, Dict, Any
from sqlalchemy.orm import Session
from sqlalchemy import func
from domain.entities.restaurant import Restaurant
from domain.value_objects.address import Address
from domain.value_objects.rating import Rating
from domain.repositories.restaurant_repository import RestaurantRepository
from infrastructure.database import SessionLocal
from infrastructure.models.restaurant import RestaurantModel, CuisineTypeModel
from infrastructure.search.elasticsearch_client import ElasticsearchClient
class SQLAlchemyRestaurantRepository(RestaurantRepository):
"""SQLAlchemyを使用したRestaurantRepositoryの実装"""
def __init__(self, search_client: ElasticsearchClient):
self.search_client = search_client
async def get_by_id(self, id: int) -> Optional[Restaurant]:
"""IDによるレストラン取得"""
with SessionLocal() as db:
db_restaurant = db.query(RestaurantModel).filter(RestaurantModel.id == id).first()
if db_restaurant is None:
return None
return self._map_to_entity(db_restaurant)
async def search(
self,
keyword: Optional[str] = None,
cuisine_type: Optional[str] = None,
price_level_min: Optional[int] = None,
price_level_max: Optional[int] = None,
min_rating: Optional[float] = None,
location: Optional[str] = None,
radius_km: Optional[float] = None,
page: int = 1,
page_size: int = 20
) -> List[Restaurant]:
"""検索条件によるレストラン検索"""
# Elasticsearchで検索を実行
search_query = self._build_search_query(
keyword, cuisine_type, price_level_min, price_level_max,
min_rating, location, radius_km
)
search_results = await self.search_client.search(
"restaurants",
search_query,
(page - 1) * page_size,
page_size
)
# 見つかったIDリストでSQLAlchemyから詳細データを取得
ids = [hit["_id"] for hit in search_results["hits"]["hits"]]
if not ids:
return []
with SessionLocal() as db:
db_restaurants = db.query(RestaurantModel).filter(RestaurantModel.id.in_(ids)).all()
# 検索結果の順序を保持するためのソート
id_to_position = {id: idx for idx, id in enumerate(ids)}
db_restaurants.sort(key=lambda r: id_to_position.get(r.id, 0))
return [self._map_to_entity(db_restaurant) for db_restaurant in db_restaurants]
async def create(self, restaurant: Restaurant) -> Restaurant:
"""レストランの新規作成"""
db_restaurant = RestaurantModel(
name=restaurant.name,
price_level=restaurant.price_level,
prefecture=restaurant.address.prefecture,
city=restaurant.address.city,
street=restaurant.address.street,
building=restaurant.address.building,
created_at=restaurant.created_at,
updated_at=restaurant.updated_at
)
# 料理タイプの設定
db_restaurant.cuisine_types = [
CuisineTypeModel(name=cuisine_type)
for cuisine_type in restaurant.cuisine_types
]
# データベースに保存
with SessionLocal() as db:
db.add(db_restaurant)
db.commit()
db.refresh(db_restaurant)
# Elasticsearchにインデックス
await self.search_client.index(
"restaurants",
db_restaurant.id,
self._map_to_search_doc(db_restaurant)
)
# エンティティにマッピングして返却
return self._map_to_entity(db_restaurant)
def _map_to_entity(self, db_restaurant: RestaurantModel) -> Restaurant:
"""データベースモデルからドメインエンティティへのマッピング"""
address = Address(
prefecture=db_restaurant.prefecture,
city=db_restaurant.city,
street=db_restaurant.street,
building=db_restaurant.building
)
rating = None
if db_restaurant.rating_score is not None and db_restaurant.rating_count is not None:
rating = Rating(
score=db_restaurant.rating_score,
count=db_restaurant.rating_count
)
return Restaurant(
id=db_restaurant.id,
name=db_restaurant.name,
cuisine_types=[cuisine.name for cuisine in db_restaurant.cuisine_types],
address=address,
price_level=db_restaurant.price_level,
rating=rating,
created_at=db_restaurant.created_at,
updated_at=db_restaurant.updated_at
)
def _map_to_search_doc(self, db_restaurant: RestaurantModel) -> Dict[str, Any]:
"""データベースモデルから検索ドキュメントへのマッピング"""
return {
"name": db_restaurant.name,
"cuisine_types": [cuisine.name for cuisine in db_restaurant.cuisine_types],
"address": {
"prefecture": db_restaurant.prefecture,
"city": db_restaurant.city,
"street": db_restaurant.street,
"full": f"{db_restaurant.prefecture}{db_restaurant.city}{db_restaurant.street}"
},
"price_level": db_restaurant.price_level,
"rating": db_restaurant.rating_score,
"rating_count": db_restaurant.rating_count,
"created_at": db_restaurant.created_at.isoformat(),
"updated_at": db_restaurant.updated_at.isoformat()
}
def _build_search_query(
self,
keyword: Optional[str] = None,
cuisine_type: Optional[str] = None,
price_level_min: Optional[int] = None,
price_level_max: Optional[int] = None,
min_rating: Optional[float] = None,
location: Optional[str] = None,
radius_km: Optional[float] = None
) -> Dict[str, Any]:
"""検索クエリの構築"""
query = {
"bool": {
"must": [],
"filter": []
}
}
# キーワード検索
if keyword:
query["bool"]["must"].append({
"multi_match": {
"query": keyword,
"fields": ["name^3", "cuisine_types^2", "address.full"],
"type": "best_fields"
}
})
# 料理タイプのフィルタリング
if cuisine_type:
query["bool"]["filter"].append({
"term": {"cuisine_types": cuisine_type}
})
# 価格帯のフィルタリング
price_range = {}
if price_level_min is not None:
price_range["gte"] = price_level_min
if price_level_max is not None:
price_range["lte"] = price_level_max
if price_range:
query["bool"]["filter"].append({
"range": {"price_level": price_range}
})
# 評価のフィルタリング
if min_rating is not None:
query["bool"]["filter"].append({
"range": {"rating": {"gte": min_rating}}
})
# 位置情報検索
if location and radius_km:
# 位置情報の実装はシンプル化(実際には座標の解決が必要)
query["bool"]["filter"].append({
"bool": {
"should": [
{"match": {"address.prefecture": location}},
{"match": {"address.city": location}},
{"match": {"address.full": location}}
]
}
})
return {"query": query}
📝 若手エンジニア向けメモ
インフラストラクチャ層は、ドメイン層とアプリケーション層を実現するための具体的な技術実装を提供します。この例では、データベースとの連携やElasticsearchを使った検索実装が含まれています。リポジトリパターンを使用することで、ドメイン層はデータの取得方法や保存方法を知る必要がなく、インフラストラクチャの詳細から保護されています。
API層(プレゼンテーション層)
# api/routes/restaurants.py
from fastapi import APIRouter, Depends, HTTPException, Query
from typing import List, Optional
from api.schemas.restaurant import RestaurantResponse, CreateRestaurantRequest
from api.dependencies import get_restaurant_query_handler, get_restaurant_command_handler
from application.queries.search_restaurants import SearchRestaurantsQuery, SearchRestaurantsHandler
from application.commands.create_restaurant import CreateRestaurantCommand, CreateRestaurantHandler
from core.exceptions import BusinessLogicException
router = APIRouter(prefix="/restaurants", tags=["restaurants"])
@router.get("/", response_model=List[RestaurantResponse])
async def search_restaurants(
keyword: Optional[str] = Query(None, description="検索キーワード"),
cuisine_type: Optional[str] = Query(None, description="料理ジャンル"),
price_level_min: Optional[int] = Query(None, ge=1, le=4, description="最低価格帯"),
price_level_max: Optional[int] = Query(None, ge=1, le=4, description="最高価格帯"),
min_rating: Optional[float] = Query(None, ge=1, le=5, description="最低評価点"),
location: Optional[str] = Query(None, description="地域・エリア"),
radius_km: Optional[float] = Query(None, gt=0, description="検索半径(km)"),
page: int = Query(1, ge=1, description="ページ番号"),
page_size: int = Query(20, ge=1, le=100, description="1ページあたりの件数"),
query_handler: SearchRestaurantsHandler = Depends(get_restaurant_query_handler)
):
"""
飲食店を検索します。
様々な条件でフィルタリングが可能です。
"""
# クエリオブジェクトの作成
query = SearchRestaurantsQuery(
keyword=keyword,
cuisine_type=cuisine_type,
price_level_min=price_level_min,
price_level_max=price_level_max,
min_rating=min_rating,
location=location,
radius_km=radius_km,
page=page,
page_size=page_size
)
# ユースケースハンドラの実行
restaurants = await query_handler.handle(query)
# ドメインエンティティからレスポンススキーマへの変換
return [RestaurantResponse.from_entity(restaurant) for restaurant in restaurants]
@router.post("/", response_model=RestaurantResponse, status_code=201)
async def create_restaurant(
request: CreateRestaurantRequest,
command_handler: CreateRestaurantHandler = Depends(get_restaurant_command_handler)
):
"""
新しい飲食店情報を登録します。
"""
try:
# コマンドオブジェクトの作成
command = CreateRestaurantCommand(
name=request.name,
cuisine_types=request.cuisine_types,
prefecture=request.prefecture,
city=request.city,
street=request.street,
building=request.building,
price_level=request.price_level
)
# ユースケースハンドラの実行
restaurant = await command_handler.handle(command)
# ドメインエンティティからレスポンススキーマへの変換
return RestaurantResponse.from_entity(restaurant)
except BusinessLogicException as e:
# ビジネスロジック例外の変換
raise HTTPException(status_code=400, detail=str(e))
except Exception as e:
# 予期しない例外のログ記録と変換
logger.error(f"Unexpected error creating restaurant: {str(e)}", exc_info=True)
raise HTTPException(status_code=500, detail="Internal server error")
💡 学習ポイント
API層(プレゼンテーション層)は、外部とのインターフェースを提供する層です。HTTPリクエストのパラメータや本文からユースケースの入力(コマンドやクエリ)を作成し、ユースケースハンドラに処理を委譲します。また、ドメインエンティティをAPIレスポンス用のスキーマに変換する役割も担います。この層では、ルーティング、入力検証、エラーハンドリング、レスポンス形式などのAPIに関する懸念事項が扱われます。
13.1.3 検索機能の実装
# infrastructure/search/elasticsearch_client.py
from typing import Dict, Any, List, Optional
from elasticsearch import AsyncElasticsearch
from core.config import settings
import logging
logger = logging.getLogger(__name__)
class ElasticsearchClient:
"""Elasticsearchクライアント"""
def __init__(self):
self.client = AsyncElasticsearch([settings.ELASTICSEARCH_URL])
async def create_index(self, index_name: str, mappings: Dict[str, Any]) -> None:
"""インデックスの作成"""
try:
if not await self.client.indices.exists(index=index_name):
await self.client.indices.create(
index=index_name,
body=mappings
)
logger.info(f"Created index '{index_name}'")
else:
logger.info(f"Index '{index_name}' already exists")
except Exception as e:
logger.error(f"Error creating index '{index_name}': {str(e)}", exc_info=True)
raise
async def index(self, index_name: str, doc_id: str, document: Dict[str, Any]) -> None:
"""ドキュメントのインデックス"""
try:
await self.client.index(
index=index_name,
id=doc_id,
body=document,
refresh=True # 即時検索可能に
)
except Exception as e:
logger.error(f"Error indexing document {doc_id}: {str(e)}", exc_info=True)
raise
async def search(
self,
index_name: str,
query: Dict[str, Any],
from_: int = 0,
size: int = 10,
sort: Optional[List[Dict[str, Any]]] = None
) -> Dict[str, Any]:
"""検索の実行"""
try:
body = {"query": query}
if sort:
body["sort"] = sort
response = await self.client.search(
index=index_name,
body=body,
from_=from_,
size=size
)
return response
except Exception as e:
logger.error(f"Error searching in index '{index_name}': {str(e)}", exc_info=True)
raise
async def delete(self, index_name: str, doc_id: str) -> None:
"""ドキュメントの削除"""
try:
await self.client.delete(
index=index_name,
id=doc_id,
refresh=True
)
except Exception as e:
logger.error(f"Error deleting document {doc_id}: {str(e)}", exc_info=True)
raise
async def bulk(self, actions: List[Dict[str, Any]]) -> Dict[str, Any]:
"""バルク操作の実行"""
try:
return await self.client.bulk(body=actions, refresh=True)
except Exception as e:
logger.error(f"Error performing bulk operation: {str(e)}", exc_info=True)
raise
async def close(self) -> None:
"""クライアントのクローズ"""
await self.client.close()
# 飲食店検索インデックスの設定
RESTAURANT_INDEX_MAPPINGS = {
"settings": {
"analysis": {
"analyzer": {
"kuromoji_analyzer": {
"type": "custom",
"tokenizer": "kuromoji_tokenizer",
"filter": ["kuromoji_baseform", "kuromoji_part_of_speech"]
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "kuromoji_analyzer",
"fields": {
"keyword": {"type": "keyword"}
}
},
"cuisine_types": {"type": "keyword"},
"address": {
"properties": {
"prefecture": {"type": "keyword"},
"city": {"type": "keyword"},
"street": {"type": "text"},
"full": {"type": "text", "analyzer": "kuromoji_analyzer"}
}
},
"location": {"type": "geo_point"},
"price_level": {"type": "integer"},
"rating": {"type": "float"},
"rating_count": {"type": "integer"},
"created_at": {"type": "date"},
"updated_at": {"type": "date"}
}
}
}
# スクリプト:インデックス作成
async def setup_elasticsearch_indices():
"""Elasticsearchインデックスの初期設定"""
client = ElasticsearchClient()
try:
await client.create_index("restaurants", RESTAURANT_INDEX_MAPPINGS)
logger.info("Elasticsearch indices setup completed")
finally:
await client.close()
📝 若手エンジニア向けメモ
Elasticsearchは全文検索と地理空間検索に優れたデータストアです。インデックス設計では、検索ニーズに合わせたマッピングやアナライザーの設定が重要です。日本語テキストの場合、単語の分かち書きや活用形の正規化などを行う「kuromoji」のようなアナライザーを使用するのが一般的です。また、キーワード検索と完全一致検索を両立させるため、同じフィールドに複数のインデックス方法(マルチフィールド)を設定する手法も効果的です。
13.1.4 キャッシュ実装
# infrastructure/cache/redis_cache.py
from typing import Any, Optional, TypeVar, Dict, Generic, Callable
import json
import hashlib
import redis.asyncio as redis
from core.config import settings
import logging
from datetime import timedelta
T = TypeVar('T')
logger = logging.getLogger(__name__)
class RedisCache(Generic[T]):
"""Redis を使用したキャッシュ実装"""
def __init__(self, prefix: str, ttl: int = 3600):
"""
Args:
prefix: キャッシュキーのプレフィックス
ttl: キャッシュのTTL(秒)
"""
self.prefix = prefix
self.ttl = ttl
self.redis = redis.from_url(settings.REDIS_URL)
def _make_key(self, key: str) -> str:
"""キャッシュキーの生成"""
return f"{self.prefix}:{key}"
def _hash_dict(self, data: Dict[str, Any]) -> str:
"""辞書からハッシュ値を生成"""
serialized = json.dumps(data, sort_keys=True)
return hashlib.md5(serialized.encode()).hexdigest()
async def get(self, key: str) -> Optional[T]:
"""キャッシュからデータを取得"""
full_key = self._make_key(key)
try:
data = await self.redis.get(full_key)
if data:
return json.loads(data)
return None
except Exception as e:
logger.error(f"Error getting cache key {full_key}: {str(e)}")
return None
async def set(self, key: str, value: T, ttl: Optional[int] = None) -> bool:
"""キャッシュにデータを設定"""
full_key = self._make_key(key)
ttl = ttl or self.ttl
try:
serialized = json.dumps(value)
await self.redis.setex(full_key, ttl, serialized)
return True
except Exception as e:
logger.error(f"Error setting cache key {full_key}: {str(e)}")
return False
async def delete(self, key: str) -> bool:
"""キャッシュからデータを削除"""
full_key = self._make_key(key)
try:
await self.redis.delete(full_key)
return True
except Exception as e:
logger.error(f"Error deleting cache key {full_key}: {str(e)}")
return False
async def clear_pattern(self, pattern: str) -> int:
"""パターンに一致するキャッシュを削除"""
full_pattern = self._make_key(pattern)
try:
keys = []
async for key in self.redis.scan_iter(match=full_pattern):
keys.append(key)
if keys:
return await self.redis.delete(*keys)
return 0
except Exception as e:
logger.error(f"Error clearing cache pattern {full_pattern}: {str(e)}")
return 0
async def get_or_set(self, key: str, factory: Callable[[], T], ttl: Optional[int] = None) -> T:
"""キャッシュから取得、なければ生成して設定"""
result = await self.get(key)
if result is not None:
logger.debug(f"Cache hit for {key}")
return result
logger.debug(f"Cache miss for {key}")
value = await factory()
await self.set(key, value, ttl)
return value
async def close(self) -> None:
"""接続のクローズ"""
await self.redis.close()
# キャッシュを使用するサービスの例
class CachedRestaurantService:
"""キャッシュを使用したレストランサービス"""
def __init__(self, repository, cache: RedisCache):
self.repository = repository
self.cache = cache
async def get_restaurant_by_id(self, restaurant_id: int):
"""IDによるレストラン取得(キャッシュ使用)"""
cache_key = f"restaurant:{restaurant_id}"
# キャッシュから取得、なければリポジトリから取得してキャッシュ
return await self.cache.get_or_set(
cache_key,
lambda: self.repository.get_by_id(restaurant_id)
)
async def search_restaurants(self, **search_params):
"""レストラン検索(キャッシュ使用)"""
# 検索パラメータからキャッシュキーを生成
params_hash = self.cache._hash_dict(search_params)
cache_key = f"search:{params_hash}"
return await self.cache.get_or_set(
cache_key,
lambda: self.repository.search(**search_params),
ttl=1800 # 検索結果は30分キャッシュ
)
async def create_restaurant(self, restaurant_data):
"""レストラン作成(関連キャッシュ無効化)"""
# 新しいレストランを作成
restaurant = await self.repository.create(restaurant_data)
# 関連するキャッシュを無効化
await self.cache.clear_pattern("search:*")
return restaurant
💡 学習ポイント
キャッシュは、パフォーマンスを向上させるための重要な技術です。しかし、キャッシュの一貫性の確保(キャッシュの無効化タイミングなど)は難しい問題の一つです。適切なTTL(有効期限)の設定や、データ更新時の関連キャッシュの無効化が重要です。また、キャッシュは完全なデータストアではなく、あくまで「高速化のための補助」であり、キャッシュがなくても(低速でも)システムは動作する必要があります。
13.2 コーディング規約
13.2.1 Python コーディング規約
命名規則
-
ファイル名: スネークケース(例:
restaurant_service.py) -
クラス名: パスカルケース(例:
RestaurantService) - **関数# 第13章:付録
目次
📚 この章で学ぶこと
- プロジェクトの主要部分のコード例と実装パターン
- コーディング規約と一貫性あるコードベース維持の方法
- 効果的な設計ドキュメントのテンプレート
- プロジェクトのさまざまな段階で活用できるチェックリスト
- 開発環境のセットアップと構成管理の手順
🔑 重要な概念
- エレガントで可読性の高いコード作成のベストプラクティス
- 効果的なドキュメント作成と知識共有
- 開発プロセスの標準化と効率化
13.1 コード例と実装リファレンス
プロジェクトの主要コンポーネントの実装例:
13.1.1 FastAPIによるRESTfulエンドポイント実装
基本的なAPIエンドポイント
from fastapi import FastAPI, HTTPException, Depends, Query
from typing import List, Optional
from pydantic import BaseModel, Field
import logging
# モデル定義
class RestaurantBase(BaseModel):
name: str
cuisine_type: str
address: str
rating: Optional[float] = None
price_level: Optional[int] = Field(None, ge=1, le=4)
class RestaurantCreate(RestaurantBase):
pass
class Restaurant(RestaurantBase):
id: int
class Config:
orm_mode = True
# APIアプリケーション初期化
app = FastAPI(
title="飲食店検索API",
description="飲食店の検索と詳細情報提供を行うAPI",
version="1.0.0"
)
# ロガー設定
logger = logging.getLogger("api")
# 依存性(後でDIコンテナと連携)
def get_restaurant_service():
# 実際の実装では、DIコンテナからサービスを取得
return RestaurantService()
# エンドポイント実装
@app.get("/restaurants/", response_model=List[Restaurant], tags=["restaurants"])
async def get_restaurants(
name: Optional[str] = Query(None, description="店名による絞り込み"),
cuisine_type: Optional[str] = Query(None, description="料理ジャンルによる絞り込み"),
min_rating: Optional[float] = Query(None, ge=0, le=5, description="最低評価点"),
service: RestaurantService = Depends(get_restaurant_service)
):
"""
飲食店情報を取得します。
各種パラメータによる絞り込みが可能です。
"""
try:
logger.info(f"Restaurant search request: name={name}, cuisine={cuisine_type}, min_rating={min_rating}")
restaurants = await service.search_restaurants(
name=name,
cuisine_type=cuisine_type,
min_rating=min_rating
)
return restaurants
except Exception as e:
logger.error(f"Error searching restaurants: {str(e)}", exc_info=True)
raise HTTPException(status_code=500, detail="Internal server error")
@app.get("/restaurants/{restaurant_id}", response_model=Restaurant, tags=["restaurants"])
async def get_restaurant(
restaurant_id: int,
service: RestaurantService = Depends(get_restaurant_service)
):
"""
指定されたIDの飲食店情報を取得します。
"""
try:
restaurant = await service.get_restaurant_by_id(restaurant_id)
if restaurant is None:
raise HTTPException(status_code=404, detail="Restaurant not found")
return restaurant
except HTTPException:
raise
except Exception as e:
logger.error(f"Error fetching restaurant {restaurant_id}: {str(e)}", exc_info=True)
raise HTTPException(status_code=500, detail="Internal server error")
@app.post("/restaurants/", response_model=Restaurant, tags=["restaurants"])
async def create_restaurant(
restaurant: RestaurantCreate,
service: RestaurantService = Depends(get_restaurant_service)
):
"""
新しい飲食店情報を登録します。
"""
try:
new_restaurant = await service.create_restaurant(restaurant)
return new_restaurant
except Exception as e:
logger.error(f"Error creating restaurant: {str(e)}", exc_info=True)
raise HTTPException(status_code=500, detail="Internal server error")
📝 若手エンジニア向けメモ
FastAPIは型アノテーションを活用し、自動的に入力検証とOpenAPI文書を生成してくれます。Pydanticモデルを使った明確なデータ構造定義と、Dependsを使った依存性の注入が特徴的です。エンドポイント関数は非同期(async/await)で実装することも可能で、これによりI/O待ちなどでブロックせずに高いスループットを実現できます。
エラーハンドリングとミドルウェア
from fastapi import FastAPI, Request, status
from fastapi.responses import JSONResponse
from fastapi.middleware.cors import CORSMiddleware
import time
import uuid
import logging
from prometheus_client import Counter, Histogram
# メトリクス定義
REQUEST_COUNT = Counter("api_requests_total", "Total API requests", ["method", "endpoint", "status"])
REQUEST_LATENCY = Histogram("api_request_latency_seconds", "API request latency", ["method", "endpoint"])
app = FastAPI()
# CORSミドルウェア
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 本番では具体的なオリジンを指定
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# カスタム例外クラス
class BusinessLogicException(Exception):
def __init__(self, detail: str, code: str = "BUSINESS_RULE_VIOLATION"):
self.detail = detail
self.code = code
super().__init__(detail)
# 例外ハンドラー
@app.exception_handler(BusinessLogicException)
async def business_logic_exception_handler(request: Request, exc: BusinessLogicException):
return JSONResponse(
status_code=status.HTTP_400_BAD_REQUEST,
content={
"error": {
"code": exc.code,
"message": exc.detail,
"request_id": request.state.request_id
}
}
)
@app.exception_handler(Exception)
async def generic_exception_handler(request: Request, exc: Exception):
# 予期しない例外をログに記録
logging.error(
f"Unhandled exception: {str(exc)}",
exc_info=True,
extra={"request_id": request.state.request_id}
)
return JSONResponse(
status_code=status.HTTP_500_INTERNAL_SERVER_ERROR,
content={
"error": {
"code": "INTERNAL_ERROR",
"message": "An unexpected error occurred",
"request_id": request.state.request_id
}
}
)
# メトリクス・ロギングミドルウェア
@app.middleware("http")
async def metrics_middleware(request: Request, call_next):
# リクエストIDを生成
request_id = str(uuid.uuid4())
request.state.request_id = request_id
# メトリクス記録開始
start_time = time.time()
# エンドポイント名(パスパラメータを正規化)
endpoint = request.url.path
try:
# リクエスト処理
response = await call_next(request)
# メトリクス記録
duration = time.time() - start_time
REQUEST_LATENCY.labels(
method=request.method,
endpoint=endpoint
).observe(duration)
REQUEST_COUNT.labels(
method=request.method,
endpoint=endpoint,
status=response.status_code
).inc()
# リクエストIDをレスポンスヘッダーに追加
response.headers["X-Request-ID"] = request_id
return response
except Exception as e:
# 例外時もメトリクスを記録
duration = time.time() - start_time
REQUEST_LATENCY.labels(
method=request.method,
endpoint=endpoint
).observe(duration)
REQUEST_COUNT.labels(
method=request.method,
endpoint=endpoint,
status=500
).inc()
# 例外を再発生
raise
💡 学習ポイント
エラーハンドリングは、単に例外をキャッチするだけでなく、クライアントに有用な情報を提供し、サーバー側でも適切に問題を追跡できるようにすることが重要です。ミドルウェアを使用することで、リクエスト処理の前後に共通のロジック(ロギング、メトリクス収集、認証など)を挿入できます。これにより、エンドポイント実装がビジネスロジックに集中でき、コードの重複も避けられます。
13.1.2 クリーンアーキテクチャ実装
ディレクトリ構造
src/
├── api/ # プレゼンテーション層(FastAPI)
│ ├── dependencies.py
│ ├── middleware.py
│ └── routes/
│ ├── restaurants.py
│ └── health.py
├── core/ # アプリケーションコア
│ ├── config.py # 設定管理
│ ├── exceptions.py # カスタム例外
│ └── logging.py # ログ設定
├── domain/ # ドメイン層
│ ├── entities/ # エンティティ
│ │ └── restaurant.py
│ ├── value_objects/ # 値オブジェクト
│ └── services/ # ドメインサービス
│ └── restaurant_service.py
├── application/ # ユースケース層
│ ├── commands/ # コマンド(書き込み操作)
│ │ └── create_restaurant.py
│ └── queries/ # クエリ(読み取り操作)
│ └── search_restaurants.py
├── infrastructure/ # インフラストラクチャ層
│ ├── database.py
│ ├── repositories/ # リポジトリ実装
│ │ └── restaurant_repository.py
│ └── search/ # 検索エンジン連携
│ └── elasticsearch_client.py
└── main.py # アプリケーションのエントリーポイント
ドメイン層
# domain/entities/restaurant.py
from dataclasses import dataclass
from typing import Optional, List
from datetime import datetime
from domain.value_objects.address import Address
from domain.value_objects.rating import Rating
@dataclass
class Restaurant:
"""レストランエンティティ"""
id: int
name: str
cuisine_types: List[str]
address: Address
price_level: int
rating: Optional[Rating] = None
created_at: datetime = datetime.now()
updated_at: datetime = datetime.now()
def update_rating(self, new_rating: Rating) -> None:
"""レストランの評価を更新する"""
self.rating = new_rating
self.updated_at = datetime.now()
def change_price_level(self, new_level: int) -> None:
"""価格帯を変更する"""
if not 1 <= new_level <= 4:
raise ValueError("Price level must be between 1 and 4")
self.price_level = new_level
self.updated_at = datetime.now()
# domain/value_objects/address.py
@dataclass(frozen=True)
class Address:
"""住所を表す値オブジェクト"""
prefecture: str
city: str
street: str
building: Optional[str] = None
def __str__(self) -> str:
if self.building:
return f"{self.prefecture}{self.city}{self.street} {self.building}"
return f"{self.prefecture}{self.city}{self.street}"
# domain/value_objects/rating.py
@dataclass(frozen=True)
class Rating:
"""評価を表す値オブジェクト"""
score: float # 1.0 - 5.0
count: int
def __post_init__(self):
if not 1.0 <= self.score <= 5.0:
raise ValueError("Rating score must be between 1.0 and 5.0")
if self.count < 0:
raise ValueError("Rating count cannot be negative")
@property
def is_reliable(self) -> bool:
"""十分なレビュー数があるかどうか"""
return self.count >= 10
📝 若手エンジニア向けメモ
ドメイン層は、ビジネスロジックの中心です。技術的な詳細(データベース、Web APIなど)に依存せず、純粋なビジネスルールを表現します。エンティティはビジネスにおける主要な概念を表し、一意に識別可能で変更可