はじめに
「強化学習と自然言語処理を用いたチャットボット」を作る前工程として、「自然言語処理(BERT)を用いたチャットボット」を作ります。
レポジトリはこちらです。
BERTとは1
BERTは、google検索やDeeplなどで使われています。とても、高精度で使用しやすいです。
BERTの学習では、事前学習とファインチューニングの二つに分かれます。事前学習で言語の基礎を学習し、ファインチューニングで、個別のタスクに合うように調整します。
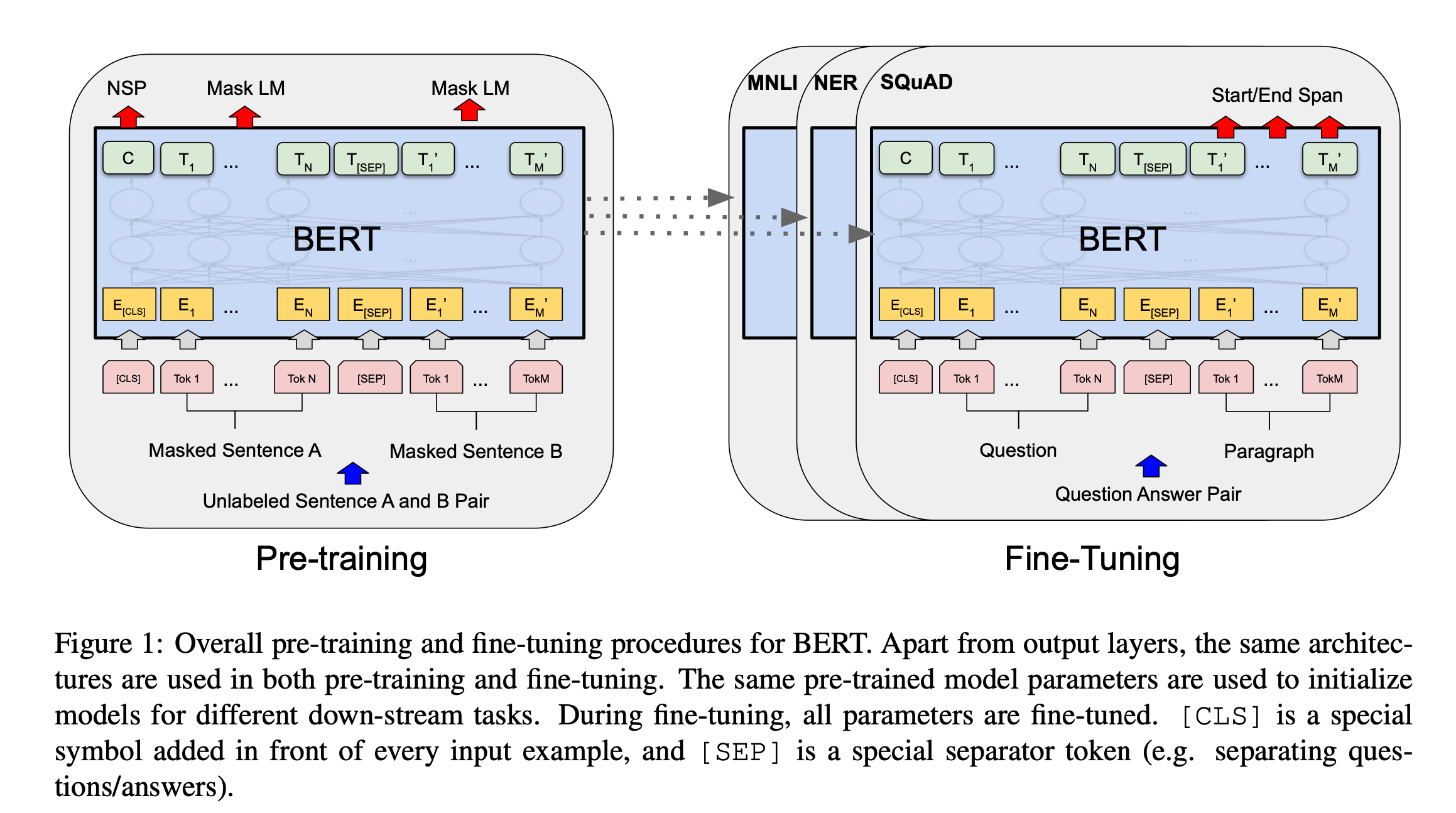
事前学習
事前学習は、その言語がどうゆう構造なのか、単語の意味はどういう意味なのかなど言語の基礎を理解させます。具体的には、TransformerがMask Language ModelとNext Sentence Predictionで文章から、文脈を双方向に学習します。
Mask Language Model
文章から、特定の単語を15%ランダムに選び、[MASK]トークンに置き換えます。
['[CLS]', '私', 'は', '[MASK]', 'に', '所属', 'しています', '[SEP]']
[MASK]された単語を文脈から予測します。
[MASK]=公安9課
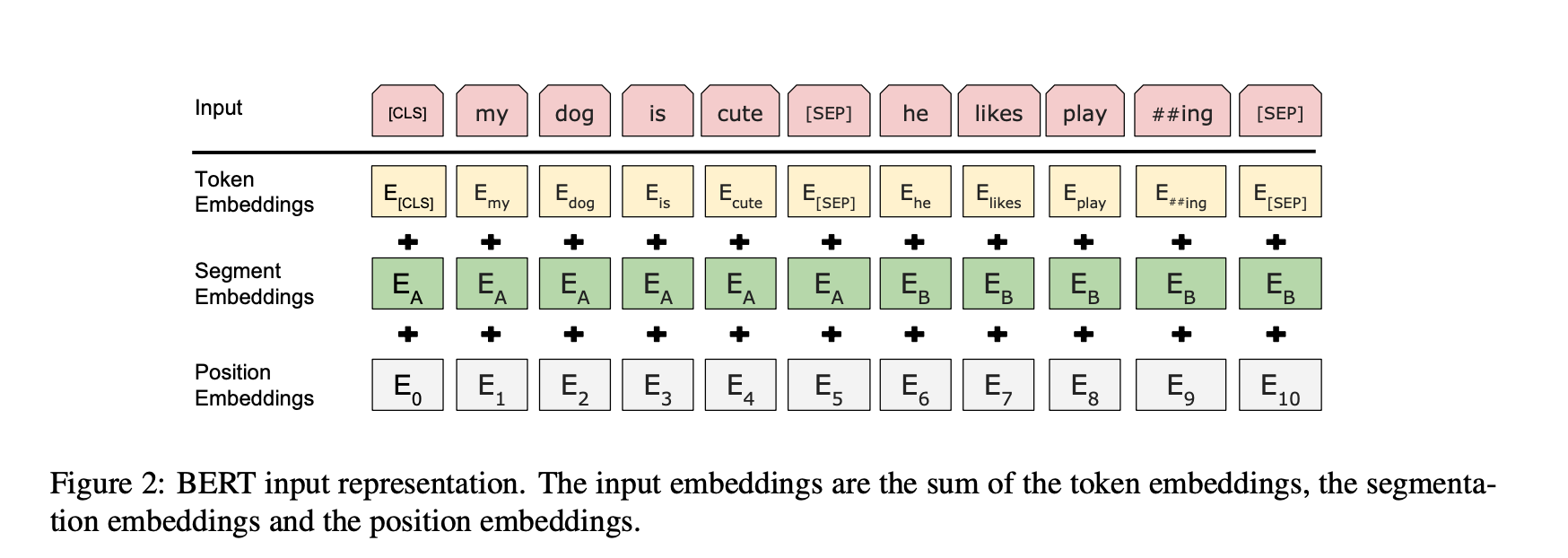
Next Sentence Prediction
二つの文章に関係があるかを判定します。後ろの文章を50%の確率で、無関係な文章と置き換えます。後ろの文章が意味的に正しければIsNext、正しくなければNotNextの判定をします。

形態素解析
形態素解析とは、日本語を意味を持つ最小単位に分割することです。日本語は、英語と違い、スペースで区切られていないので、形態素解析が必要です。
今回は、 MeCab を Python から使用する際のラッパーライブラリであるfugashiを使います。
私 / は / 公安9課 / に / 所属 / して / います
初めまして / ボク / は / 、 / タチコマ
分かち書き
文節ごとに空白で区切ることを言います。
私 は 公安9課 に 所属 して います
初めまして ボク は 、 タチコマ
転移学習(ファインチューニング)
事前学習で得られたパラメータを初期値として、ラベル付きのデータでファインチューニングを行います。
実装
HuggingFaceとは
HuggingFaceとは、自然言語処理に特化したディープラーニングのフレームワークです。
コーディングをする際に以下のサイトを参考にしました。
データセット
もしくは、
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
pip install -r requirements.txt
!pip install fugashi[unidic-lite] ipadic datasets
!python ./examples/legacy/question-answering/run_squad.py \
--model_type=bert \
--model_name_or_path=cl-tohoku/bert-base-japanese-whole-word-masking \
--do_train \
--do_eval \
--train_file=DDQA-1.0_RC-QA_train.json \
--predict_file=DDQA-1.0_RC-QA_dev.json \
--per_gpu_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 10 \
--max_seq_length 384 \
--doc_stride 128 \
--overwrite_output_dir \
--output_dir output/
from transformers import BertJapaneseTokenizer, AutoModelForQuestionAnswering
import torch
model = AutoModelForQuestionAnswering.from_pretrained('output/')
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
def reply(context, question):
inputs = tokenizer.encode_plus(question, context, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
output = model(**inputs)
answer_start = torch.argmax(output.start_logits)
answer_end = torch.argmax(output.end_logits) + 1
answer = tokenizer.convert_tokens_to_string(tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
answer = answer.replace(' ', '')
return answer
チューニング用文章
私の名前は、思考戦車のタチコマです。私は公安9課に所属しています。
思考戦車とは人工ニューロチップを用いた人工知能(AI)を搭載し、自ら「思考」し自律的に行動することができる戦車
context = '私の名前は、思考戦車のタチコマです。私は公安9課に所属しています。'\
'思考戦車とは人工ニューロチップを用いた人工知能(AI)を搭載し、'\
'自ら「思考」し自律的に行動することができる戦車'
question = "あなたの名前は?"
answer = reply(context, question)
print("question: " + question)
print("answer: " + answer)
question = "あなたの所属は?"
answer = reply(context, question)
print("question: " + question)
print("answer: " + answer)
question = "思考戦車とは何ですか?"
answer = reply(context, question)
print("question: " + question)
print("answer: " + answer)
question: あなたの名前は?
answer: 思考戦車のタチコマ
question: あなたの所属は?
answer: 公安9課
question: 思考戦車とは何ですか?
answer: 人工ニューロチップを用いた人工知能(AI)を搭載し、
自ら「思考」し自律的に行動することができる戦車
組み込み
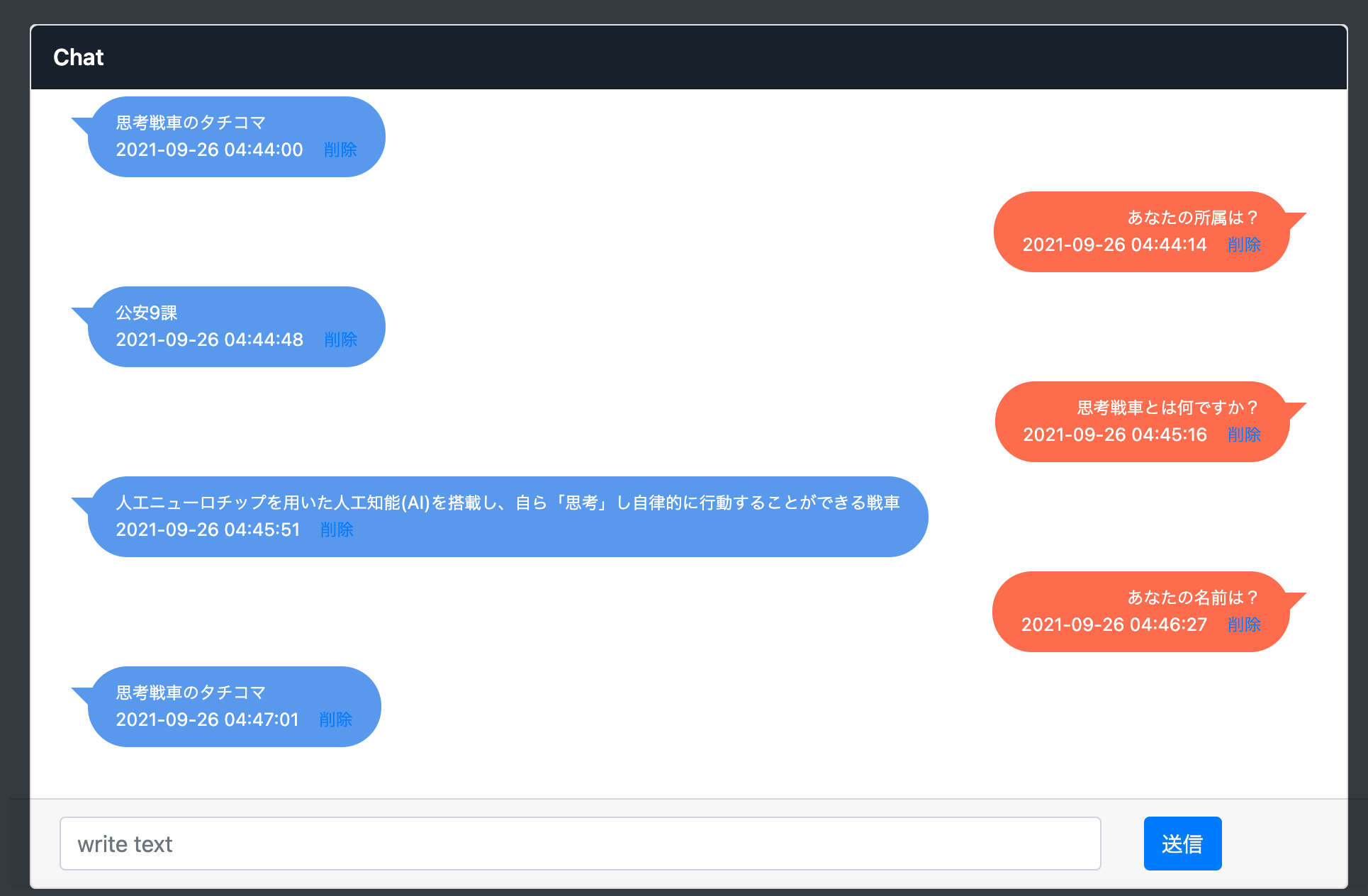
質問に対して、回答ができていると思います。
ただ、かなり無機質な回答ですね。
そこで、回答文に口調変換を行い、個性付けを行う必要があります。
口調変換
類似文章検索
類似文章検索とは、元の文章を比較して、どれだけ近いかを確率で表します。
つまり、「質問+bertからの応答」により近い文章を検索することができます。
例えば、
「あなたの名前は?思考戦車のタチコマ」と「私はタチコマです。」
0.7184281945228577
「あなたの名前は?思考戦車のタチコマ」と「私は犬のことがとても好きです。」
0.6292034983634949
となります。
from bert_score import score
def calc_bert_score(cands, refs):
Precision, Recall, F1 = score(cands, refs, lang="ja", verbose=False)
return F1.numpy().tolist()
cand = "あなたの名前は?思考戦車のタチコマ"
refs = ["私はタチコマです。","私は犬のことがとても好きです。","初めまして!ボクは、タチコマ!"]
cands = []
for i in refs:
cands.append(cand)
f1 = calc_bert_score(cands, refs)
data = []
for item, ref in zip(f1, refs):
data.append([item, ref])
data.sort(reverse=True)
print()
print(cand)
for it,it2 in data:
print(it,' ',it2)
あなたの名前は?思考戦車のタチコマ
0.7184281945228577 私はタチコマです。
0.7169045209884644 初めまして!ボクは、タチコマ!
0.6292034983634949 私は犬のことがとても好きです。
口調変換
今回は、bertからの返答に以下の操作をすることで、口調変換をし、個性を添加することにします。
(a)bertからの返答+「だよ」
(b)類似文章検索を用いて、「bertに対する質問+bertからの返答」に最も近い個性を持った想定文章
この二つを組み合わせることにします。
どの文章が出るかは、下記の確率により、選択したいと思います。
係数の0.5は(a)の出る確率を制御しています。
おおよそ、係数と同じような確率になります。
def change_prob(data):
prob = []
for item in data:
prob.append(item[0])
leng = len(prob)
prob[0] = prob[0] * leng * 0.5
m = nn.Softmax(dim=1)
input = torch.tensor(prob)
input = torch.reshape(input, (1, leng))
output = m(input)
x_numpy = output.to('cpu').detach().numpy().copy()
return x_numpy.reshape(leng,)
組み込み
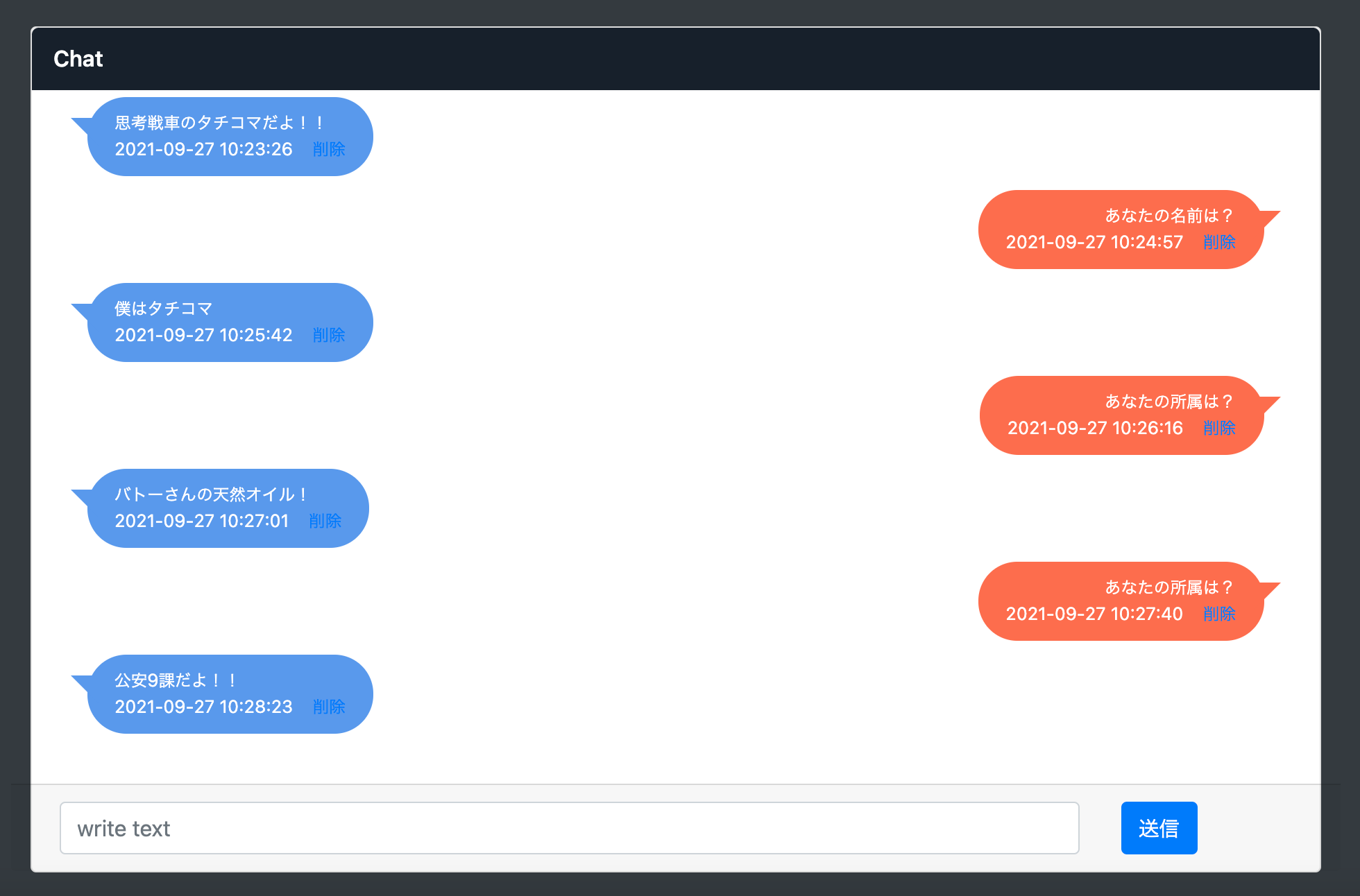
-
'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding', Jacob Devlin Ming-Wei Chang Kenton Lee Kristina Toutanova, (2019), Google AI Language ↩