はじめに
近年、人工知能ブームにより、人工知能を使ったトレーディング手法が盛んである。そこで、今回は深層強化学習を用いたシステムトレーディングを実施した。
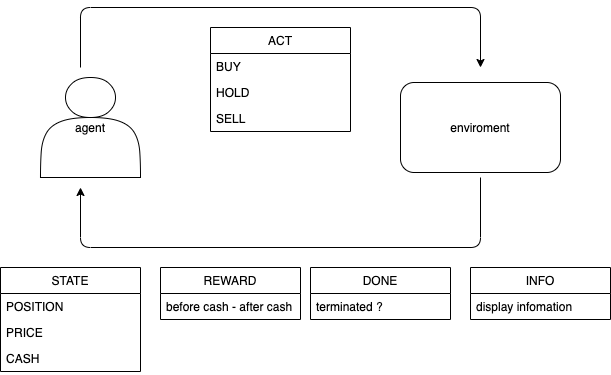
まず、実際の深層強化学習モデルである。agentの行動として、 BUY、HOLD、SELLの三つの内一つを選択する。環境の戻り値として、状態(今現在保有しているポジションの価格、市場価格、手持ちのキャッシュ)、報酬(手持ちのキャッシュの変化値(含む益も含む))、終了(取引の終了か否か)、情報(ターミナルにディスプレイする情報)を返す。
使用データについて
トレンド傾向の掴みやすさから、yahoo financeからGSPCの日足を使用した。
訓練データの期間:2015/1/1 - 2017/6/30
テストデータの期間:2017/7/1 - 2021/1/1
以下ソースコード
Double-QLearning1
Q-Learningモデル
\tilde{Q}(S_t, a) = R_{t+1}+\gamma \max _{a} Q\left(S_{t+1}, a; \boldsymbol{\theta}_{t}\right)
Double-QLearningでは以下の二つの式を用いる。
学習過程
\tilde{Q}(S_t, a) = R_{t+1}+\gamma Q\left(S_{t+1}, \operatorname{argmax}_{a} Q\left(S_{t+1}, a ; \boldsymbol{\theta}_{t}\right) ; \boldsymbol{\theta}_{t}'\right)
行動選択過程
a = \operatorname{argmax}_{a} Q\left(S_{t+1}, (a + a')\right)
実際のコードは以下のようになる。
学習
if s_flag == 11:
q = self.model.predict(state)
next_q = self.model_2.predict(next_state)
t = np.copy(q)
t[:, action] = reward + (1 - done) * self.gamma*np.max(next_q, axis=1)
self.model.train_on_batch(state, t)
else:
q = self.model_2.predict(state)
next_q = self.model.predict(next_state)
t = np.copy(q)
t[:, action] = reward + (1 - done) * self.gamma*np.max(next_q, axis=1)
self.model_2.train_on_batch(state, t)
2つもモデルを用意する。(Q1、Q2とする)
行動には、3つのパターンがある。
- Q1、Q2を足し合わせた行動
- Q1、Q1を足し合わせた行動
- Q2、Q2を足し合わせた行動
実際の行動は1のみ。
学習を行うのは2、3のどちらか一方を1/2の確率で選択する。
行動選択
def act(self, state,s_flag=12):
if np.random.rand() <= self.epsilon:
return np.random.choice(self.action_size)
act_values = self.brain._predict(state,s_flag)
if self.epsilon > self.epsilon_min:
self.epsilon *= self.r
return np.argmax(act_values)
売買ルール
1.空売りは認めない
2.ポジションを持っている場合、追加注文を出せない。
3.最後のステップでポジションを全て売却する。
4.ポジションは全買い、全売り
5.所持金は1000000ドル
実装と結果
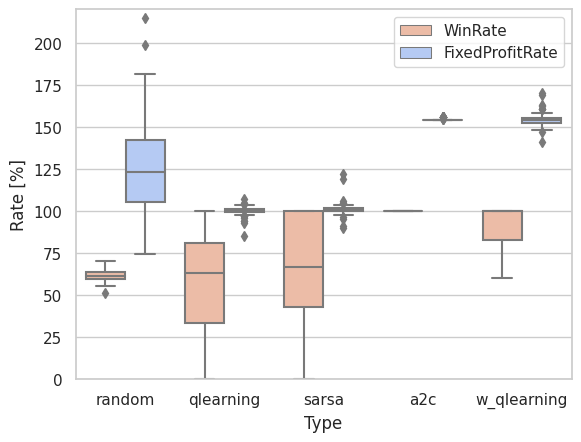
qlearningより、勝率、収益率の向上が見られる。
ソースコードはこちら
ソースコードはこちら
-
H. van Hasselt, "Double Q-learning", Advances in Neural Information Processing Systems,(2010), 23:2613–2621 ↩