はじめに
近年、人工知能ブームにより、人工知能を使ったトレーディング手法が盛んである。そこで、今回は深層強化学習を用いたシステムトレーディングを実施した。
まず、基本的な深層強化学習を用いたトレーディングモデルである。agentの行動として、 BUY、HOLD、SELLの三つの内一つを選択する。環境の戻り値として、状態(今現在保有しているポジションの価格、市場価格、手持ちのキャッシュ)、報酬(手持ちのキャッシュの変化値(含む益も含む))、終了(取引の終了か否か)、情報(ターミナルにディスプレイする情報)を返す。
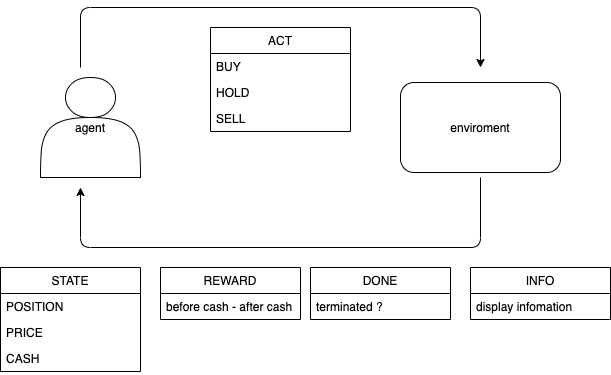
使用データについて
トレンド傾向の掴みやすさから、yahoo financeからGSPCの日足を使用した。
訓練データの期間:2015/1/1 - 2017/6/30
テストデータの期間:2017/7/1 - 2021/1/1
以下ソースコード
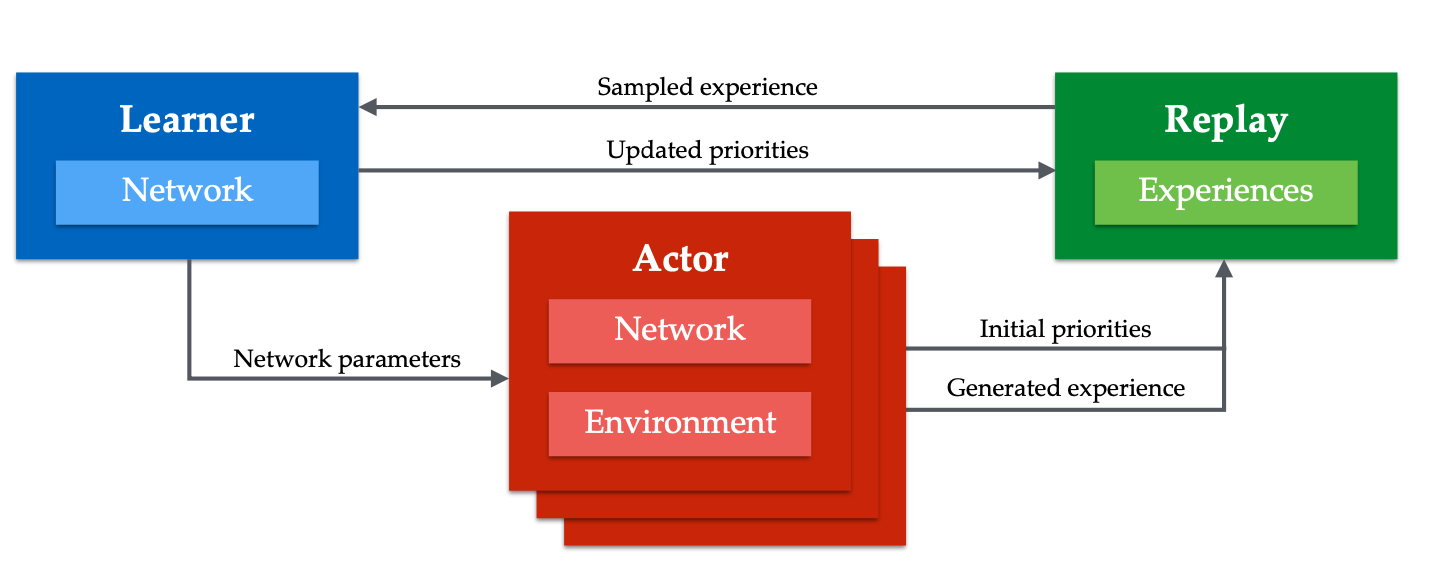
Ape-X1
Ape-Xは、代表的なoff-poicyであり、以下のモデルを加味したモデルである。
・Double Q-learning(Double DQN)
・優先度付き経験再生(Priority Experience Reply DQN)
・Dueling Network(Dueling Network DQN)
・並列分散処理(GORILA)
・Multi-Step learning
・固定化されたε-greedy法
Double Q-learning(Double DQN)2 3
Q-Learningモデル
\tilde{Q}(S_t, a) = R_{t+1}+\gamma \max _{a} Q\left(S_{t+1}, a; \boldsymbol{\theta}_{t}\right)
Double-QLearningでは以下の二つの式を用いる。
学習過程
\tilde{Q}(S_t, a) = R_{t+1}+\gamma Q\left(S_{t+1}, \operatorname{argmax}_{a} Q\left(S_{t+1}, a ; \boldsymbol{\theta}_{t}\right) ; \boldsymbol{\theta}_{t}'\right)
行動選択過程
a = \operatorname{argmax}_{a} Q\left(S_{t+1}, (a + a')\right)
実際のコードは以下のようになる。
学習
if s_flag == 11:
q = self.model.predict(state)
next_q = self.model_2.predict(next_state)
t = np.copy(q)
t[:, action] = reward + (1 - done) * self.gamma*np.max(next_q, axis=1)
self.model.train_on_batch(state, t)
else:
q = self.model_2.predict(state)
next_q = self.model.predict(next_state)
t = np.copy(q)
t[:, action] = reward + (1 - done) * self.gamma*np.max(next_q, axis=1)
self.model_2.train_on_batch(state, t)
2つもモデルを用意する。(Q1、Q2とする)
行動には、3つのパターンがある。
- Q1、Q2を足し合わせた行動
- Q1、Q1を足し合わせた行動
- Q2、Q2を足し合わせた行動
実際の行動は1のみ。
学習を行うのは2、3のどちらか一方を1/2の確率で選択する。
行動選択
def act(self, state,s_flag=12):
if np.random.rand() <= self.epsilon:
return np.random.choice(self.action_size)
act_values = self.brain._predict(state,s_flag)
if self.epsilon > self.epsilon_min:
self.epsilon *= self.r
return np.argmax(act_values)
Double Q-learning
Double DQN
qiitaの記事
優先度付き経験再生(Priority Experience Reply DQN)4
Experience Replayではすべての経験に対してランダムサンプリングを行うが、Prioritized Experience Replayでは学習する余地の大きくTD誤差が高い経験に対して集中的にサンプリングする。
δ_{t} = R_{t+1} + γ\:max_{a}Q_{target}(S_{t+1}, a')- Q(S_{t},a_{t})
上式で得られたδを下式を用いて、並び替え、経験を抽出する。
P(i) = \frac{{p_{i}}^{\alpha}}{\Sigma_{k}{p_{k}}^{\alpha}}
重点サンプリング
重要と思われる経験を集中的に学習する手法
Priority Experience Reply DQN
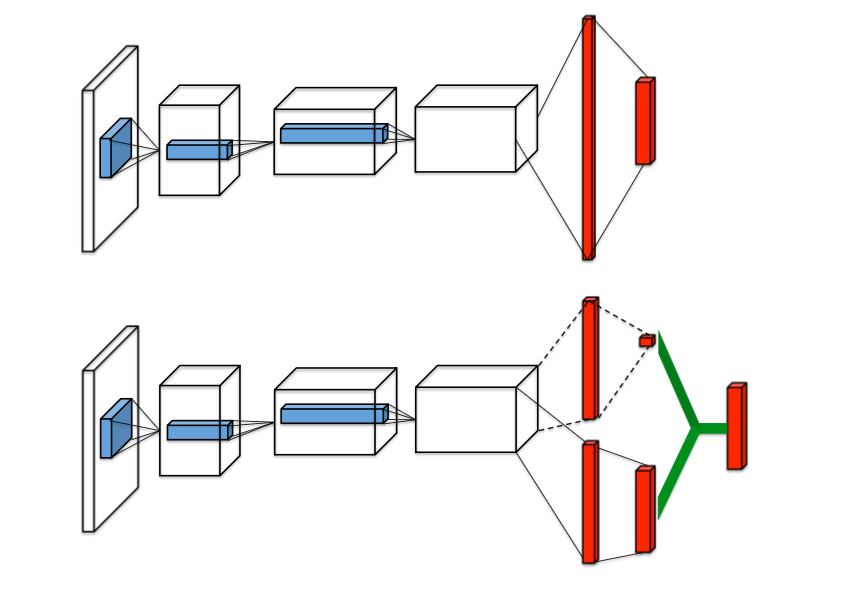
Dueling Network(Dueling Network DQN)5
Dueling Networkが他のモデルとは、大きく違うのは、学習の構造はDQNのままで、モデルを変化させることで、大きな成果を得た点である。
他のモデルのCNNや全結合層で構成されたQ-Networkでは、ノイズに影響されやすく、不安定。
そこで、一旦アドバンテージ(A)と状態価値関数(V)に分岐し、足し合わせることで、行動価値関数(Q)を求めることで、安定化を図った。
Q^{\pi}(s, a) = A^{\pi}(s, a) + V^{\pi}(s)
勾配クリッピングは401
並列分散処理(GORILA)6
GorilaはDQNを並列分散処理させたモデル
Parameter ServerとReplay memoryは全てのスレッドで共有する。そのため、DQNの時よりもReplay memoryのメモリ領域を拡張する必要がある。
Ape-Xとの、違いは、Ape-Xは重要サンプリングを行い経験をparameter serverに送信するのに対して、GORILAは経験の一様なサンプリングを行い勾配をparameter serverに送信する。
DQN
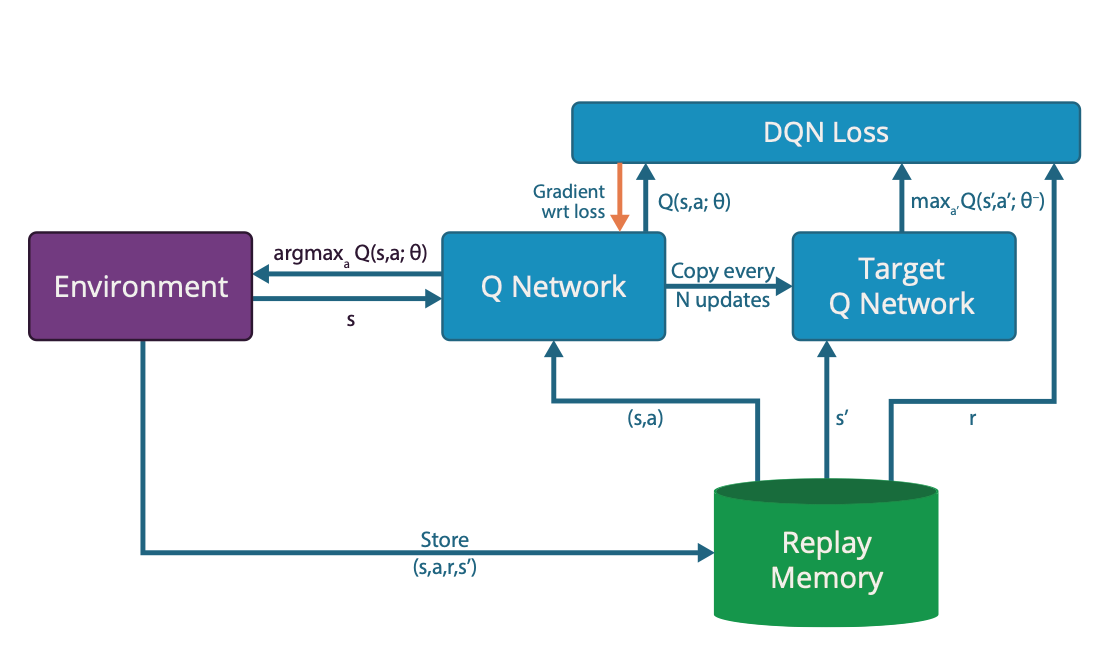
GOLIRA
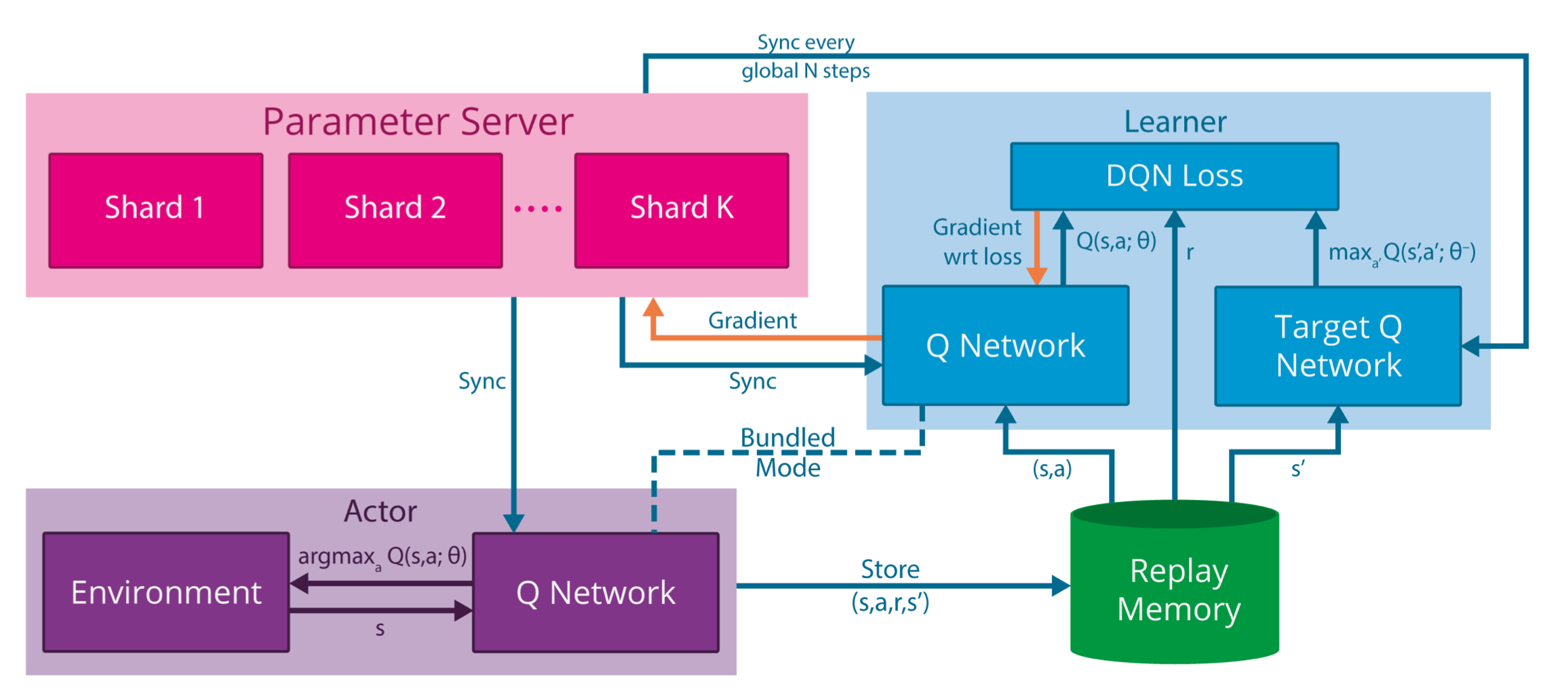
GOLIRA
qiitaの記事
Multi-Step learning1
DQN
δ_{t} = R_{t+1} + γ\:max_{a}Q_{target}(S_{t+1}, a')- Q(S_{t},a_{t})
n-stepDQN
δ_{t} = R_{t+1}+γ^{2}R_{t+2}+..+γ^{n-1}R_{t+n-1} + γ^{n}\:max_{a}Q_{target}(S_{t+n}, a')-Q(S_{t},a_{t})
n=3の時(1はn=3を用いている)
δ_{t} = R_{t+1} + γR_{t+1} + γ^{2}R_{t+2} + γ^{2}R_{t+2} + γ^{3}\:max_{a}Q_{target}(S_{t+3}, a') - Q(S_{t},a_{t})
固定化されたε-greedy法1
1より以下の値で実験を行なっている。
epsilon = 0.4
alfa = 7
N = agentの全数
i = agentの数(連番)
ε_{i} = ε^{1+\frac{i}{N-1}α}
実際は、処理速度の違いから、epsilonの値が高い方から、先に処理され、通常のε-greedy法に近くなる。
thread_num = 4
epsilon_list = np.array([])
epsilon = 0.4
alfa = 7
for i in range(thread_num):
num = 0.0
if ((thread_num - 1) != 0):
num = epsilon ** (1 + i * alfa / (thread_num - 1))
else:
num = epsilon
epsilon_list = np.append(epsilon_list, num)
εの値は以下の通り。
array([0.4 , 0.0471556 , 0.00555913, 0.00065536])
売買ルール
1.空売りは認めない
2.ポジションを持っている場合、追加注文を出せない。
3.最後のステップでポジションを全て売却する。
4.ポジションは全買い、全売り
5.所持金は1000000ドル
実装と結果
ソースコードはこちら
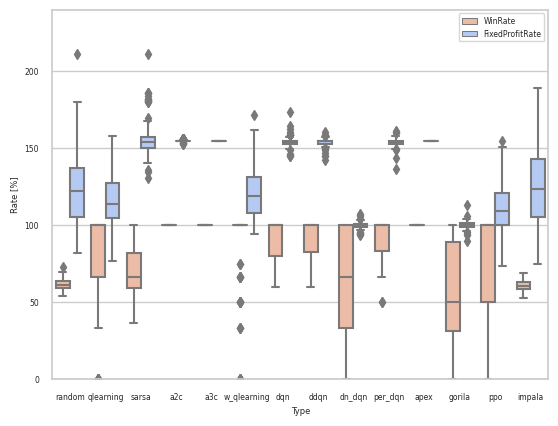
ソースコードはこちら
-
Dan Horgan, John Quan, David Budden, Gabriel Barth-Maron, Matteo Hessel, Hado van Hasselt, and David Silver. DISTRIBUTED PRIORITIZED EXPERIENCE REPLAY. In International Conference on Learning Representations, 2018. ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
Hado van Hasselt. Double Q-learning. In Advances in Neural Information Processing Systems, pp. 2613–2621, 2010. ↩
-
Hado van Hasselt, Arthur Guez, and David Silver. Deep reinforcement learning with double Q- learning. In Advances in Neural Information Processing Systems, 2016. ↩
-
Tom Schaul, John Quan, Ioannis Antonoglou, and David Silver. Prioritized experience replay. In International Conference on Learning Representations, 2016. ↩
-
Ziyu Wang, Tom Schaul, Matteo Hessel, Hado van Hasselt, Marc Lanctot, and Nando de Freitas. Dueling network architectures for deep reinforcement learning. In International Conference on Machine Learning, 2016. ↩
-
Arun. Nair, et al. Massively parallel methods for deep reinforcement learning. In International Conference on Machine Learning, 2015. ↩