どうも。
今日のアドベントカレンダーは、数学博士データサイエンティストこと杉山がお送りします。
さてさて。
最近、Webマーケ界隈でアトリビューション分析とか、LTVとか、よく聞きますよね。
なので、その両方を思い切ってうちの主力事業の広告効果分析に入れてみましたぜ!というお話です。
先日、アドエビスさんのイベントAD EBiS Partner Forum 2017 in Autumn | アドエビス/広告効果測定を基軸としたマーケティングプラットフォームでお話させていただいた話の、もう少し詳細なバージョンです。
(上のほうが概論で、下のほうが詳細になるので、皆さん好きな箇所を呼んでください。
そしていいねしてください(^^)(^^)(^^))
ラストクリックCPAからアトリビューション分析へ
皆さん一番良く使うのが、ラストクリックCPAだと思います。
CPAはCost Per Acquisitionの略で、要は、1人のユーザーを連れてくるのにいくらかかったのかという指標です。CPA1,000円の広告とCPA10,000円の広告があったら、前者の広告のほうが10倍効率がいいということになりますね。
しかし最近では、このラストクリックCPAは問題があるんじゃないのと言われています。
ちょっと自分が買い物をするときのことを想像してみて下さい。
こういうパターンよくあると思います。
- Facebookで商品の広告を見て、サイトに行って購入を検討した
- 後から思い出して、やっぱ欲しいな〜と思ってググる
- 目的のサイトに行って購入
このパターンの場合、ラストクリックCPAでは、Googleがその購入を生み出したと判定してしまいます。(ラストクリック:最後にクリックされた広告を評価する)
ですが、本質的な貢献をしているのはFacebookのはずです。なのに評価されない。
この問題を解決するため、ラストクリックのみならず、その前に見ていた広告も評価しようよというのがアトリビューション分析です。
これ以上詳しい話はこちらへ!→アトリビューション分析の方法|デジタルマーケティングラボ
今回アトリビューション分析の対象となったのは転職サイトGreenです。
(実は、今回のアドベントカレンダーに協賛しています。いいねが多かった記事の執筆者には豪華景品が…!)
今回の分析では、GreenにおけるCVである、登録・応募それぞれの直前100広告とファーストクリックを分析しております。
ラストクリックCPA + LTV → ROAS
さてさて。
CPAの弱点はもう1つあります。
それは、全てのCVは当価値なのか?という問題です。
例えば、amazonに新規登録した人がいたとして、僕が登録するのと、石油王が登録するのでは、amazonが享受できる利益が全然違いますよね。
僕を1,000円の広告費で獲得するより、石油王を10,000円で獲得できる方がいいですよね。
ですが、CPAという観点では僕を獲得した広告は1,000円、石油王を獲得した広告は10,000円なので、僕を獲得した広告が高評価になってしまうのです。
それの解決策の1つがLTVです。
LTVとは、Life Time Valueの略で、要は、その人がいくらお金を落としてくれるかです。
例えば、僕のLTVは10,000円で、石油王のLTVが100,000,000円だとしましょう。
そしたら、明らかに石油王広告の方がいいですよね。
ここで登場する概念がROASです。Return Over Ad Spendの略で、要は、1円の広告費がいくらの売上を生んだのか?です(CPAとは逆に、大きい方が嬉しい指標です)
僕を獲得した広告なら、 $\displaystyle \textrm{ROAS} = \frac{10000}{1000} = 10$ 、石油王を獲得した広告なら $\displaystyle \textrm{ROAS} = \frac{100000000}{10000} = 1000$ です。
石油王広告のROASの方が高いので、無事石油王広告を評価できたことになります!
Greenの場合は、購入の概念がないので、応募の回数や、職種の相性等を分析することになります。
(ここからガチになりますぜ…!)
アトリビューション分析の実際
実際には、次のようなことを考えて次のようなことを実装しています。
結局は、本質的に、その広告が触れたことによる価値はどのくらいだっただろうかというのを、正確に評価できればいいのです。
例えば、とある人がGreenに登録する前に、3つの広告A, B, Cに触れていたとしましょう。
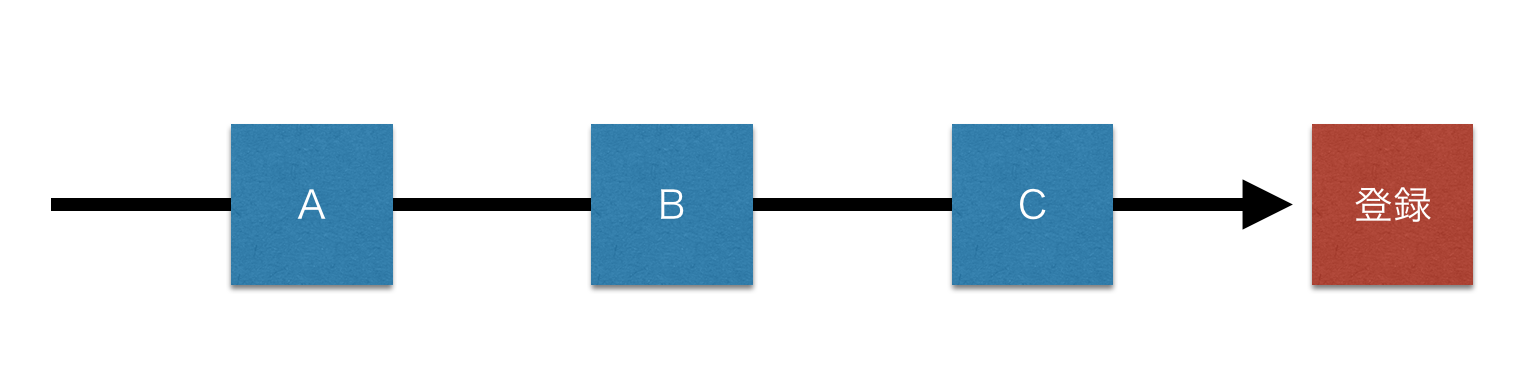
旧来のラストクリックの方法では、
A, Bが獲得した登録は0、Cが獲得した登録は1となります。
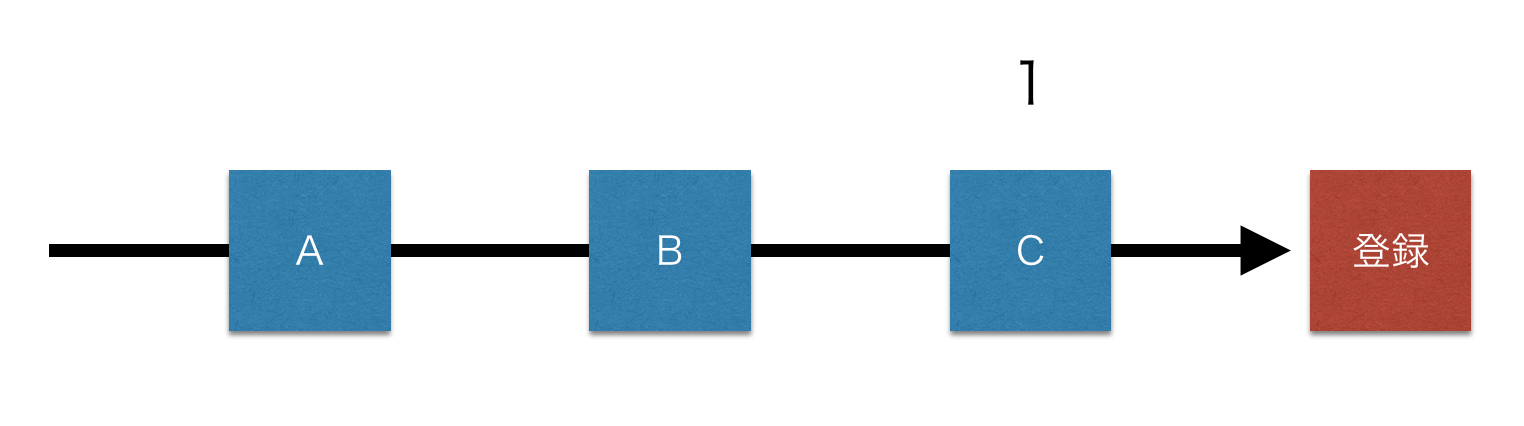
アトリビューション分析の場合は、例えば、A, B, Cがそれぞれ均等な役割を果たしたと考えて、
A, B, Cそれぞれが $\displaystyle \frac13$ 件の応募を獲得したと考えます。

もうちょっと進化させて、「最後の広告はやっぱもっと偉いんじゃない?」とか、「最初に触れた広告も大事じゃない?」とかもにょもにょ考えると、結局こんな感じになったりします。
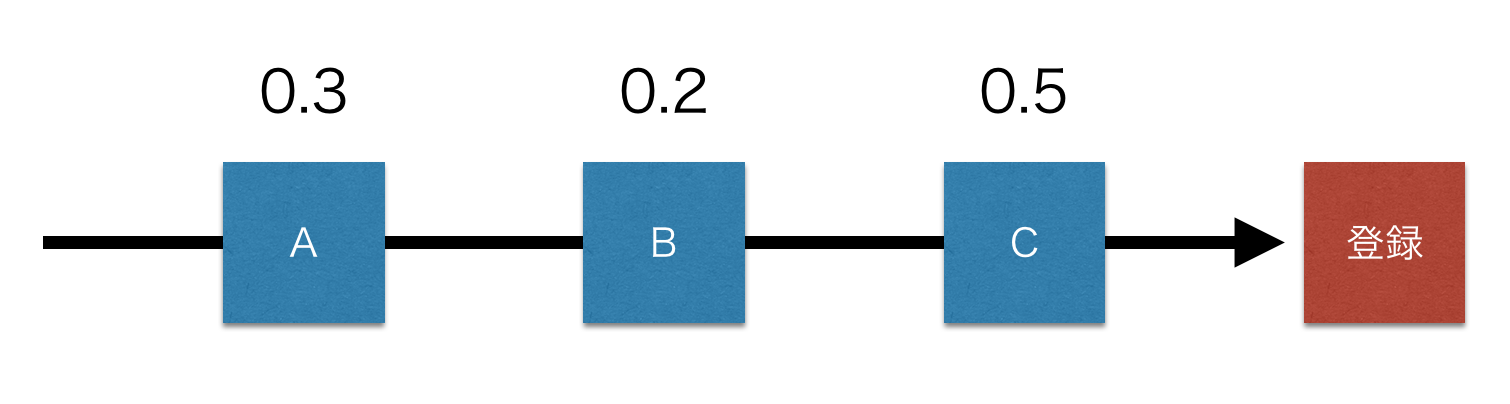
お分かりいただけますでしょうか。
このように、CVが発生した際に、そのCVの成果を、合計が1になるように、いままで触れてきた広告たちに配分することがアトリビューション分析です。
その配分方法を考えるのが肝になります。
Greenの場合は、つぎの3つくらいの条件が満たされればいいだろうというところに落ち着きました。
- Clickの方が、Viewより高評価
- CV直前の方が、時間差が開いてるものより高評価
- ファーストクリック、ラストクリックは高評価
この3つを満たすように適当に数式を組み、pythonで実装したという感じです。
具体的には下記の順序で計算しています。
- 登録と応募直前の100広告のデータを取得
- 登録と応募の直前100広告、合計200広告の貢献度を0〜1で付ける
- この数値が、Click>View、直前>昔のとなるように
- 合計が1を超えていたら、合計が1になるように調整
そんな感じです。
使う式は1次式、min、Maxくらいなので、お手軽です。
LTVの実際
ここでは、それなりにそれっぽい分析をしております。
あまり詳細に話し出すと変な話になるのですが、ざっくりと言うと、似たユーザーの過去の行動履歴のデータを集め、新規に入ってきた人のデータからどういう行動を取るかを予測し、いい感じにLTVを分析しているという感じです。
いい感じにね、いい感じ。いろんな属性でカテゴリ分けしたらサンプル数減っちゃったから困っちゃってBayes推定を部分的に導入して乗り切ったり、いろいろいろいろね。
最初は書く気まんまんでしたが、詳しい話はとてもとてもwebにはかけないので、興味がある方は是非ご連絡下さいw→このアカウントにDMください
全体の概念図
なんかよくあるあの図です。
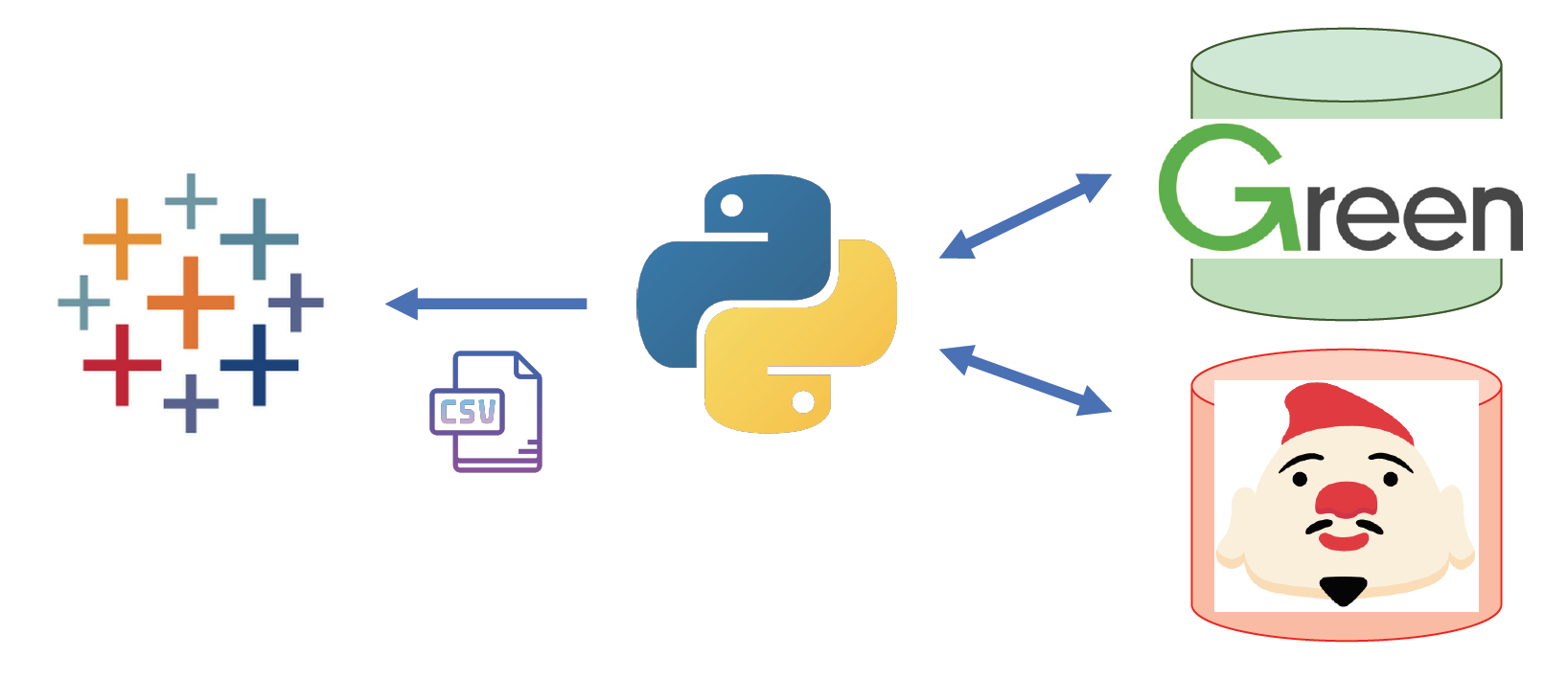
実際にはこんな感じ。
Pythonで書いたコード君が、Greenの事業データベースにアクセスしLTVをいい感じに計算し、
アドエビスにAPI経由でアクセスしここにためている広告接触履歴データにアクセスしてPythonくんが計算し、
吐き出したcsvをtableauで見るという感じです。
事業DBもキレイに整理されているので僕はSQL叩くだけだし、
広告接触履歴データもアドエビスのユーザーベースAPIを叩けばキレイに出て来るし、
あとは分析するだけでした。
巨人の方に乗るとはこの事。ありがたい限りです。
僕は会社に入ってから真面目にプログラミングをはじめましたが、Pythonを片手間で初めて3ヶ月程度経過したタイミングで作り始めたのがこれでした。
総計2ヶ月くらいかかりましたが、ちゃんとエンジニアが作れば一瞬なのだとおもいます。
意外にも、それくらい非常にシンプルに単純に組めます。
良かったこと&苦労したこと
良かったことはたくさんあります。
今まで気づいていなかった高効率 / 低効率広告を発見できたり、
そもそも適正なCPAをROASをもとに算出できるし、
っていうか、いくら投資していくら回収できていたのかという経営者が一番知りたい情報を知れるし、、、
といい事だらけです。実際、アトリビューション分析をやった後、広告費の20%くらいの投資先が変わりました。
ほかにもいろいろ分かることは多く、そもそも全広告接触履歴があるので、接触からCVまでの時間差データを用いると、その広告はどのファネルに当たっているのかをデータから定量的に出せたり、
そもそもどういうCVパスがあるのかを確認できたり、
広告接触履歴データが持っている情報量には圧倒されます。
一方、難しいことも多かったです。
この手の分析は、結局、大量の謎の数値の組が返ってくるだけなので、解釈をするのが難しいです。
また、取り入れた要素が多いので、ROASの上下があったときに、原因特定しに行くのが難しいという点があります。(CPA = CPC / CVR的な簡単な分解は出来ません)
まだまだちゃんと情報量を読み取れていない感が強く、意思決定につなげるのは今でも苦戦しています。
むすびに
と、まあ、そんな感じです。
自分としては初めて手掛けた大きなデータ分析プロジェクトだったので、成功も失敗も失敗も失敗もたくさんありました。
そういう話をしたほうが良かったのかな?w
もし興味がある人がいましたら、適当にお話しましょう〜。
そういえば、次回のアドベントカレンダーでは、組織改善プラットフォームwevoxに機械学習を入れた事例について簡単にお話します。
Greenといい、wevoxといい、yentaといい、いい感じに分析ニーズが高まってきております。
けど人が足りない!というわけで、僕と一緒にデータ分析したい仲間を求めています。
興味のある方は、こちらのアカウントにDMをくださいな!
自分で言うのはなんか嫌ですが、数学PhDデータサイエンティストマンと一緒にデータ分析で世の中に価値を提供するの、悪くないと思います。損はさせません。興味ある方、是非どうぞ!