全てのnullを、生まれる前に消し去りたい 。全ての宇宙、過去と未来の全てのnullを、この手で。
サマリ
2dのデータがある。
特定の行や特定の列に、nullが高頻度で発生している。
この時、行と列を適切に削除し、nullの無いデータを作りたい。
その際、なるべくデータ量を残したい(データ量 = $\text{rows} \times \text{columns}$ が最大)になるような行・列削除アルゴリズムがほしい。
以下に、逐次的な削除アルゴリズムを乗せる。
最後に、「特定の行や特定の列に、nullが高頻度で発生している」という仮定が"満たされない"場合には、このアルゴリズムがデータ量最大の解を与えない具体例を載せる。
今後の課題としては、逐次的でない方法、または、逐次的であって、データ量最大の解を得るアルゴリズムがほしい。
っていうか、普通にそういういい感じのやつ知ってたら誰か教えてください。
絶対こんなの誰かがすでに解決してるはずでしょ、、、
問題意識
例として、次の問題とデータを考えます。
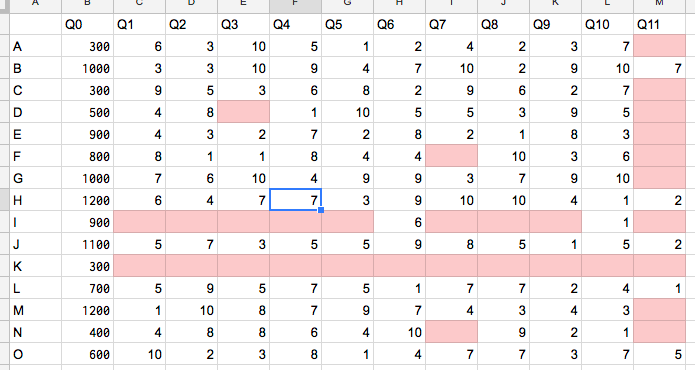
- A〜Oは人
- Q0はその人の年収
- Q1〜Q11は任意で受験したテストの結果
- たとえば、Q1はSPAの言語、Q2はSPAの非言語、Q3はTOEIC…とか
をまとめたデータだとしましょう。
社員の生産性upのために、テストの結果と年収で適当に回帰分析をかけてみて、一番係数がでかいものについての勉強を全社員でやってみるとか。
そんな感じの事を考えています。
(別の分析しろとかは言わないでね、たとえ話なので)
しかし、まぁ、常識的に考えてデータは欠損するわけです。そして、これでは回帰分析にかけられません。
たとえば、Iさん、Kさんは、これに賛同していないのかほとんど試験を受けていません。
また、Q11は、最近導入された試験なのか、受験人数が少ないです。
目で見れば、Iさん、Kさんの行と、Q11の列を抜いて、ほかもうちょい抜くと、こんな感じになります。
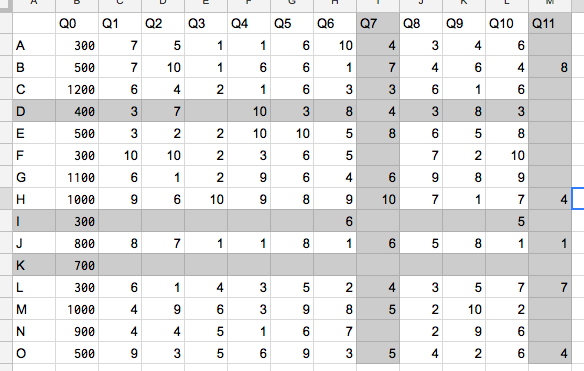
残っているデータ量が最大になるような、行・列の削除アルゴリズムが欲しかったけど、見つからなかったので作りました。
アルゴリズム概要
ざっくり、次の手法。
データ量が最も少ない行たちを特定。そいつらが持っているデータ量を計算
データ業が最も少ない列たちを特定。そいつらが持っているデータ量を計算
行達と列達で、データ量が少ない方を消す。
上記3行を繰り返す。
例:
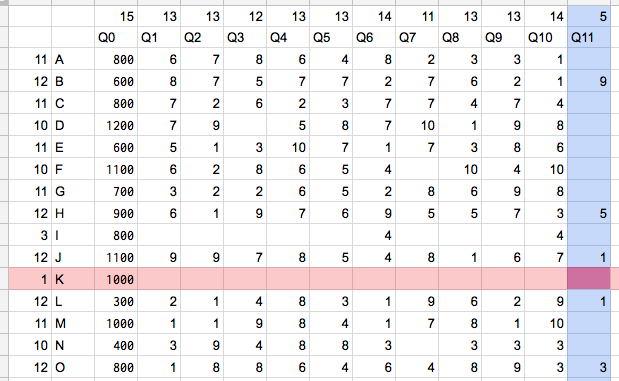
行Kがデータ量最小の行。これを削除した時に失うデータ量は1
列Q11がデータ量最小の列。これを削除した時に失うデータ量は5
→行Kを削除
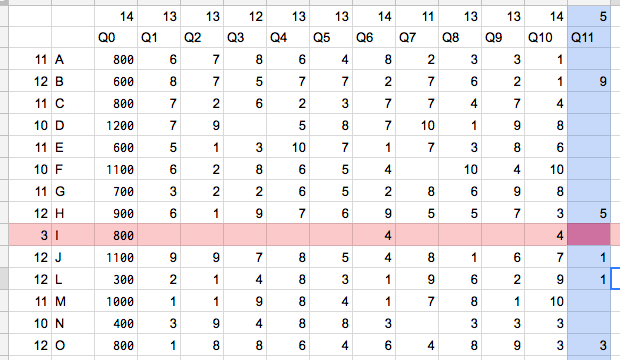
行Iがデータ量最小の行。これを削除した時に失うデータ量は3
列Q11がデータ量最小の列。これを削除した時に失うデータ量は5
→行Iを削除
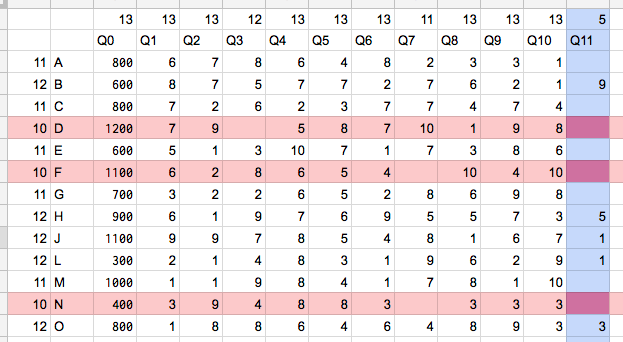
行D, F, Nがデータ量最小の行。これを削除した時に失うデータ量は30(=10×3)
列Q11がデータ量最小の列。これを削除した時に失うデータ量は5
→列Q11を削除
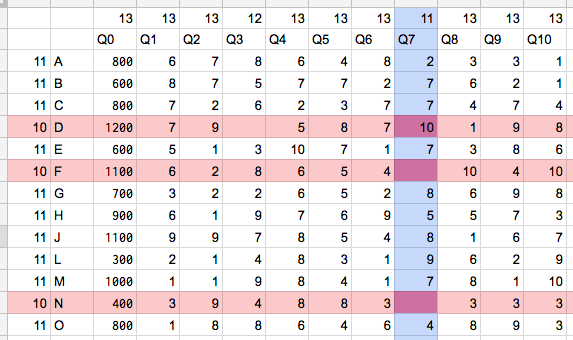
行D, F, Nがデータ量最小の行。これを削除した時に失うデータ量は30(=10×3)
列Q7がデータ量最小の列。これを削除した時に失うデータ量は11
→列Q7を削除
注意!行は1つのみ見るとデータ量10で列Q7の11より小さいが、データ量10の行を消すことになると、結局このステップで30のデータ量を失うことになる。列や行単体でのデータ量ではなく、それを全部消した時に失うデータ量で計算する!
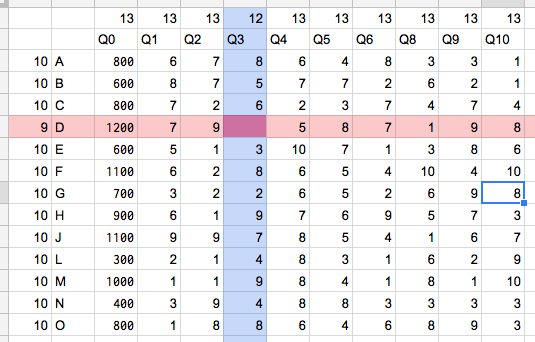
行Dがデータ量最小の行。これを削除した時に失うデータ量は9
列Q3がデータ量最小の列。これを削除した時に失うデータ量は12
→行Dを削除
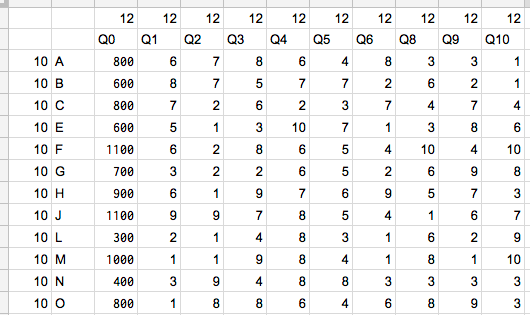
やったぜ
アルゴリズム
以下の一連のstepを、nullがなくなるまで繰り返す
step1
「データ量最小の行」の保持するデータ量を $d^r_\text{min}$、そのデータ量の行数を $n^r_\text{min}$とし、データ量最小の行を取り除いた時に失われるデータ量を
$$L^r_{min} = d^r_\text{min} \times n^r_\text{min} = d^r_\text{min}n^r_\text{min}$$
とかく。
step2
「データ量最小の列」の保持するデータ量を $d^c_\text{min}$、そのデータ量の列数を $n^c_\text{min}$とし、データ量最小の列を取り除いた時に失われるデータ量を
$$L^c_{min} = d^c_\text{min} \times n^c_\text{min} = d^c_\text{min}n^c_\text{min}$$
とかく。
step3
$L^r_{min} < L^c_{min}$ なら、データ量最小の行をすべて消す。
$L^r_{min} > L^c_{min}$ なら、データ量最小の列をすべて消す。
等しい場合は、適当に好きな方消して下さい。
(さっきの例だと、テスト削るのはやりたい分析的にダメージでかいので、優先的に人を消すとか。)
データ量最大の部分集合を取れない例
次の例の場合、データ量最大の部分集合を取れない。
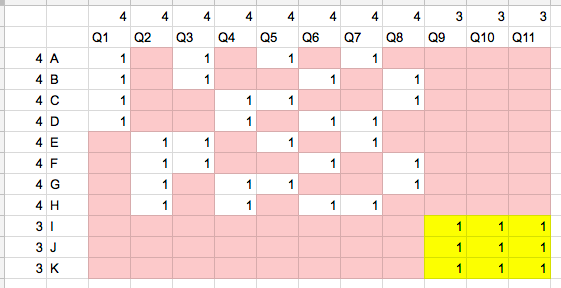
この場合、行・列を削除して、データ量最大の部分集合を作ると、それは黄色の部分だが、実際には真っ先に削除される。
このデータの場合、「特定の行や特定の列に、nullが高頻度で発生している」という仮定が"満たされない"ので、このような現象が起こるといえる。