みなさんこんにちは。suginokoです。
前回の記事で【リモートワーク】Web会議で自分の顔を画像に変えるのをmediaPipe+p5jsでやってみた【顔見せNG】という記事を書きました。
結果、mediaPipe(Face Mesh)は性能としてよかったので「これで会議の時に顔隠せるじゃん!」って思って自分の中では満足したのですが。。。
『もっと高精度(?)の「表情分析」がやってみたい!』ということでface-api.jsを試してみました。
調査背景
前回mediaPipeのFace Meshを使ったのは「他の顔認証のライブラリよりも分析能力に長けている」という情報を得ていたので使用しました。
感覚としてですが分析精度は
顔認証
mediaPipeのFace Mesh >>>> face-api.js
表情分析
face-api.js >>>>> mediaPipeのFace Mesh(というかできるの?)
くらいに思っていたんです。
ただ、実装を進めるにつれその精度に擬妙をもちはじめ、face-api.jsのデモを使ったところ『もしかして、Face Meshの顔認証って微妙なんじゃないか?(表情分析ないからどうなんだろう)』と思うようになりました。
また、個人的に『自分の顔を画像と置き換えて顔を隠しながら表情を切り替えられたら面白そう』なんで(まあ二番三番煎じ感はありますが)調査&実装してみたいなと。
最終的な目的としては、前回の記事と同じく、弊社の顔出し推奨デーで顔を隠すためです。
今回は 表情もつくというところが大きなポイント です。
※MicroSoftのAzureのFace APIとは別物で、face-api.jsを使った話です。
また、Face Meshとの比較もしていこうと思います。
開発環境
- Node v18系
- Next.js(使いたかっただけ
landmarkの比較
face-apiでの実装(主要部分だけ
// faceapiの情報をload
const loadModels = () => {
Promise.all([
faceapi.nets.tinyFaceDetector.loadFromUri(MODEL_PATH), // 顔認識
faceapi.nets.faceLandmark68Net.loadFromUri(MODEL_PATH), // 顔のlandmarks
faceapi.nets.faceRecognitionNet.loadFromUri(MODEL_PATH),
faceapi.nets.faceExpressionNet.loadFromUri(MODEL_PATH) // 顔の表情
]).then(res => {
setIsLoadedModels(true)
getVideo()
}).catch((err) => {
console.log('loadModels error', err)
})
}
// video情報を取得し、ビデオを映す
const getVideo = () => {
navigator.mediaDevices.getUserMedia({ video: true })
.then(stream => {
videoRef.current.srcObject = stream
setIsCaptureVideo(true)
videoRef.current.onloadedmetadata = async (e) => {
videoRef.current.play()
await playFaceTracking()
}
})
.catch(err => {
console.log('getvideo err', err)
setIsCaptureVideo(false)
})
}
const playFaceTracking = () => {
if (videoRef && videoRef.current) {
const video = videoRef.current as HTMLVideoElement
const createMedia = canvasRef.current as HTMLCanvasElement
faceapi.matchDimensions(createMedia, { width: video.clientWidth, height: video.clientHeight })
setInterval(async () => {
// 一人分の顔取得
const result = await faceapi.detectSingleFace(video, new faceapi.TinyFaceDetectorOptions()).withFaceLandmarks().withFaceExpressions();
//
if (result) {
const resizedDetections = faceapi.resizeResults(result, { width: video.clientWidth, height: video.clientHeight })
const ctx = createMedia.getContext('2d')
createMedia && ctx.clearRect(0, 0, video.clientWidth, video.clientHeight)
faceapi.draw.drawDetections(createMedia, resizedDetections) // 顔を認識
faceapi.draw.drawFaceExpressions(createMedia, resizedDetections) // 顔の表情を表示
faceapi.draw.drawFaceLandmarks(createMedia, resizedDetections, { drawLines: true }) // 顔のlandmarkを表示
}
}, 100)
}
}
useEffect(() => {
loadModels()
}, [])
landmark出してみると
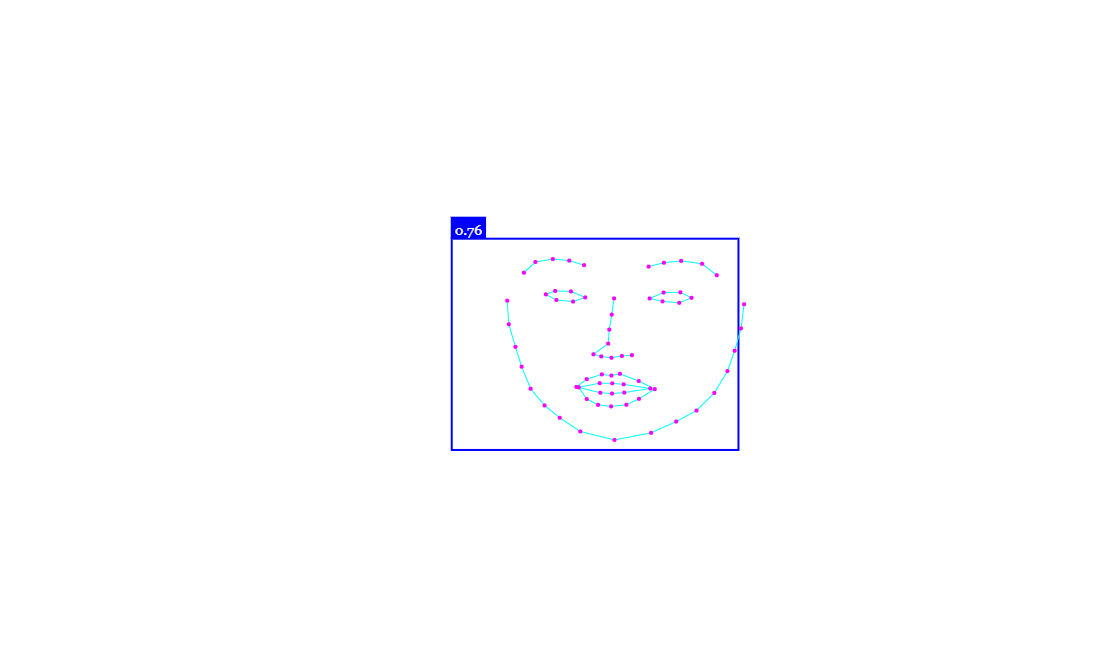
前回の記事ではvideo映像+landmarkをcanvasに出すことができましたが、face-api.jsではlandmarkだけがcanvasに出力される感じでした。
なので使用するとなるとvideoタグ(自身のカメラ映像)+canvas(画像を表示したり、landmark顔に乗っけたり)で被せて使用する、ということなんですね。
また、Face Meshはlandmark数が468なのに対し、face-api.jsではlandmark数が68みたいなので、全然違いますね。
Face Meshの方が細かめに取得します。
顔認識の精度の比較
ココでいう精度は、例えば顔を横に向いたり下を向いたりしても顔が認識されるのか、顔を素早く移動させると動かしても認識できるのか、というところを見ていきます。
とりあえずFace Meshで実装したように、顔を画像で隠してみます。
※処理変わったところだけ書いていきます
face-apiでの実装(主要部分だけ
// faceapiの情報をload
const loadModels = () => {
// ...
}
// video情報を取得し、ビデオを映す
const getVideo = () => {
// ...
}
// 顔を画像に変える
const changeFace = (result: any, canvas: HTMLCanvasElement, video: HTMLVideoElement, img) => {
const ctx = canvas.getContext('2d')
ctx.clearRect(0, 0, video.clientWidth, video.clientHeight)
canvas.width = video.clientWidth // レスポンシブ対応
canvas.height = video.clientHeight // レスポンシブ対応
const box = result.detection.box
const box_x = box.x
const box_y = box.y * 0.9 // landmark的におでこが見えるので少し上に
const box_width = box.width * 1.2 // landmark的に画像が小さいので気持ち大きめで表示
const box_height = box.height * 1.2
// let img: HTMLImageElement = new Image()
// img.src = FACE[0].path
ctx.drawImage(img, box_x, box_y, box_width, box_height)
}
const playFaceTracking = () => {
if (videoRef && videoRef.current) {
const video = videoRef.current as HTMLVideoElement
const createMedia = canvasRef.current as HTMLCanvasElement
faceapi.matchDimensions(createMedia, { width: video.clientWidth, height: video.clientHeight })
let img: HTMLImageElement = new Image()
img.src = FACE[0].path
setInterval(async () => {
// 一人分の顔取得
const result = await faceapi.detectSingleFace(video, new faceapi.TinyFaceDetectorOptions()).withFaceLandmarks().withFaceExpressions();
//
if (result) {
const resizedDetections = faceapi.resizeResults(result, { width: video.clientWidth, height: video.clientHeight })
changeFace(resizedDetections, createMedia, video, img)
}
}, 100)
}
}
useEffect(() => {
loadModels()
}, [])

顔を隠すことが出来ましたが、おでこが出ているのが気になります。。。
顔の認識におでこは入らないみたいです。。。(これでも画像配置位置をすこし上にしています。。)
比較
Face Meshもface-api.jsでも場合は割と顔を横に向けて、結構な角度でも顔を画像で隠してくれている感がありました。
Face Mesh

face-api.js

Face Meshの方がlandmark数が多いからか横顔も顔の面積に応じて変化させてくれてますね。
また、Face Meshは割と顔を揺らしても顔を画像が隠してくれている感じもします。(素敵)

しかし、face-api.jsは上記のGifのように顔を横に揺らすと自分の素顔が余裕で出てしまいました。(そのため画像は自粛します。。。)
動体検出と意味ではFace Meshの方が『精度高め?』な感じがします。
表情分析
表情分析に関してはFace Meshではできないので、face-api.jsのみでの実装になります。
表情を分析して、表情ごとに顔の画像を差し替える処理を書いてみます。
※処理変わったところだけ書いていきます
// faceapiの情報をload
const loadModels = () => {
// ...
}
// meetからvideo情報を取得し、ビデオを映す
const getVideo = () => {
// ...
}
// 顔の表情を分析する
// 固定小数点形式で出さないと小数点が正しくわからないので変換する
// 1に近い値を表情として表示する
const expression = async (result: any) => {
const data = result
// 配列にして固定小数点形式で文字列に変換
const expressionsArr = Object.entries(data.expressions)
const dataArr = expressionsArr.map((item: any, index: number) => {
item[1].toFixed(3)
// 小数点で比較すると面倒だったので100倍しておく
item[1] = item[1] * 100
return item
})
// 高い数値の表情を画像として出力する
const max = Math.max.apply(null, dataArr.map((o) => o[1]))
const resultFace = dataArr.find((v => Math.floor(v[1]) == Math.floor(max)))
return { path: faceData[`${ resultFace[0] }`] || FACE[`${ resultFace[0] }`], face: resultFace[0] || 'natural' }
}
// 顔を画像に変える
const changeFace = (result: any, canvas: HTMLCanvasElement, video: HTMLVideoElement, img: HTMLImageElement) => {
const ctx = canvas.getContext('2d')
ctx.clearRect(0, 0, video.clientWidth, video.clientHeight)
canvas.width = video.clientWidth // レスポンシブ対応
canvas.height = video.clientHeight // レスポンシブ対応
const box = result.detection.box
const box_x = Math.floor(box.x)
const box_y = Math.floor(box.y * 0.9) // landmark的におでこが見えるので少し上に
const box_width = Math.floor(box.width * 1.2) // landmark的に画像が小さいので気持ち大きめで表示
const box_height = (box.height * 1.2)
ctx?.drawImage(img, box_x, box_y, box_width, box_height)
}
const faceLoop = async (video: HTMLVideoElement, canvas: HTMLCanvasElement, img: HTMLImageElement) => {
// 一人分の顔取得
const result = await faceapi.detectSingleFace(video, new faceapi.TinyFaceDetectorOptions()).withFaceLandmarks().withFaceExpressions();
//
if (result) {
const resizedDetections = faceapi.resizeResults(result, { width: video.clientWidth, height: video.clientHeight })
const src = await expression(resizedDetections)
// img onloadしてから呼ばないと画像がバツバツ切れるくさい
img.onload = () => {
changeFace(resizedDetections, canvas, video, img)
}
img.src = src.path
img.alt = src.face
}
requestAnimationFrame(async () => await faceLoop(video, canvas, img))
}
const playFaceTracking = () => {
// ...
}
useEffect(() => {
loadModels()
setFaceData(FACE)
}, [])

このように表情を解析して画像を切り替えることができます。
これはFace Meshではできません。
面白いですね。
まとめ
Face Meshもface-api.jsもどっちも触ってみて、「どっちも良さがあってよかったな」と思いました。
どちらも会議中に顔を隠すことはできましたし、一応目的は達成したかなと思います。
最後に比較のまとめ書いておきます。
Face Mesh
- Video映像と顔認証によるもろもろの対応を一緒にCanvasに載せる感じで使用する
- landmark数が多いので細かい顔分析ができる(landmark数が468でface-apiの9.5倍以上!)
- landmark数が多いだけにどこが顔のlandmarkのポイントなのか把握がめんどくさい→前回の記事参照
- 顔を横に向けても割と顔認証してくれる
- 顔に画像を乗せたとき、結構顔を揺らしても顔を認識するため、顔認証としての精度は高め
- 表情分析はできない。できないがFace Mesh以外にもできることがあるのでそれはMediaPipeの公式を見てみてください。
face-api.js
- Video映像と顔認証は同居せず、Video映像はVideoタグ、顔認証はCanvasタグを使って重ねて使用する
- landmark数はFace Meshほど多くはないが、顔分析はできる(landmark数が68)
- landmark数がFace Meshより少なく、割と記事も多いのでどこのlandmarkのポイントが顔のパーツなのかFace Meshに比べるとわかりやすい
- 顔を横に向けても割と顔認証してくれる
- 顔に画像を乗せたとき、結構顔を揺らすと 素顔を晒すことになる ので、利用用途によっては少し気をつける必要がある。
- 表情分析ができる。顔認証で他にできることがあるのでそれはface-api.jsを見てみてください。