はじめに
分散処理基盤の Hadoop と、SQL ライクに Hadoop のデータにアクセスするための Hive があります。今回は、Hive の外部テーブルとして、Oracle Cloud の Object Storage を参照する手順を確認していきます。Object Storage には、S3互換APIがあり、s3a:// という識別子でHDFSとして利用が出来ます。
Hadoop や Hive そのものは、CentOS上にインストールしていきます。以下のオフィシャルな手順を参考にします。
Hadoop
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html#Download
Hive
https://cwiki.apache.org/confluence/display/Hive/GettingStarted
なお、Hive のメタストアには、MySQL 8.0.19 を使用しています。MySQL そのものの構築はこちらの記事で実施しています。
バージョン情報
- Hadoop : 3.2.1
- Hive : 3.1.2
- MySQL : 8.0.19 (Hive Metastore)
Customer Secret Keys 生成
Object Storage を S3 API でアクセスするためには、OCI IAM ユーザー上で、Customer Secret Key を生成する必要があります。Customer Secret Key を生成することで、Access Key と Secret Key が生成されます。この2種類の Key が必要です。
OCI Console の右上のユーザー名を選択して、ユーザーの詳細画面へ移動します。
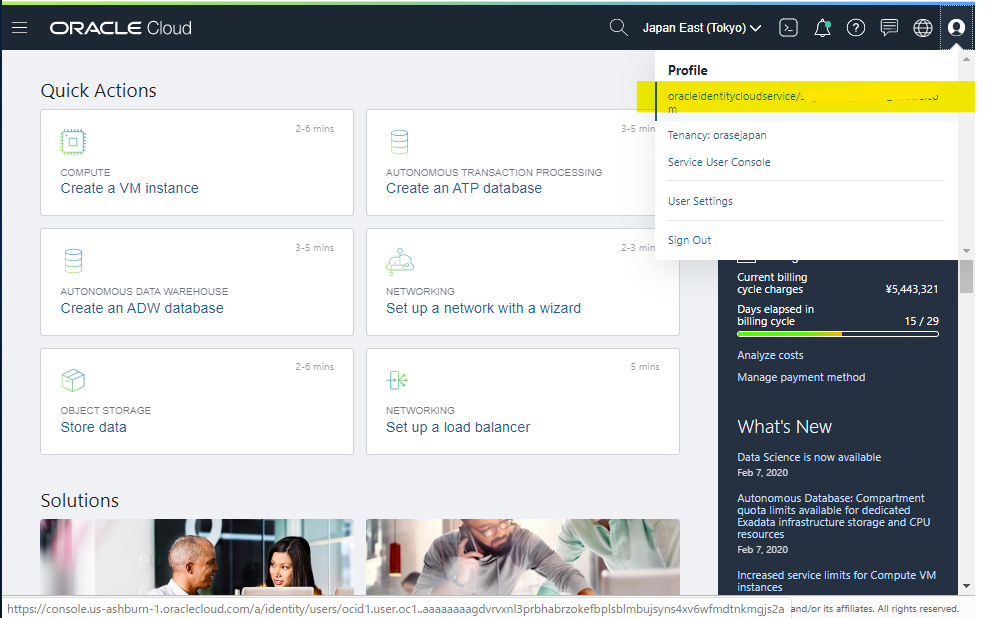
Customer Secret Keys のメニューに移動して、Generate Secret Key を押します
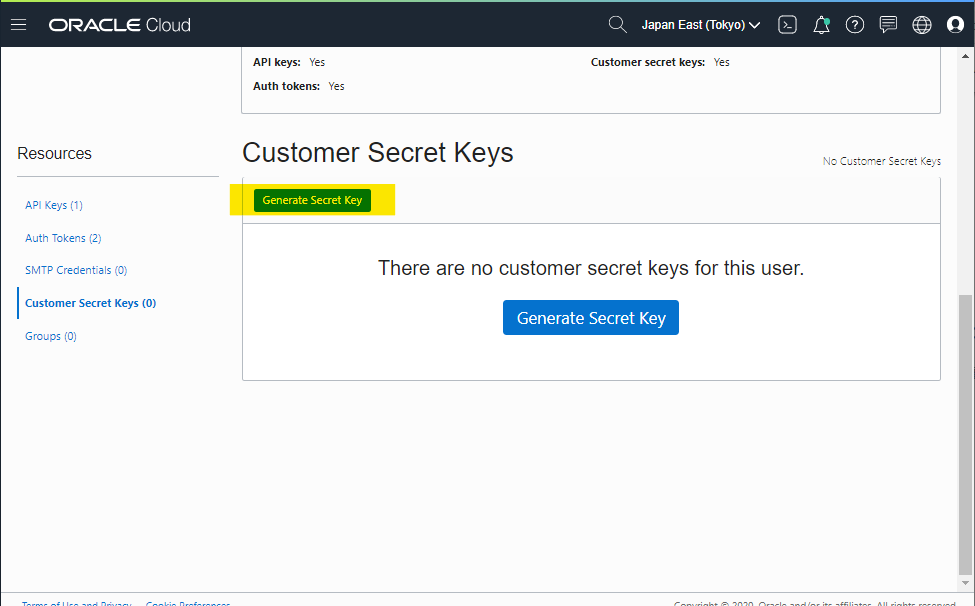
適当に NAME を指定して、Generate Secret Key を押します。
- NAME :
s3 compat
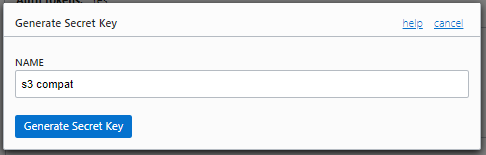
Key が表示されます。これは Secret Key です (画像のkeyは、現在無効化しています)
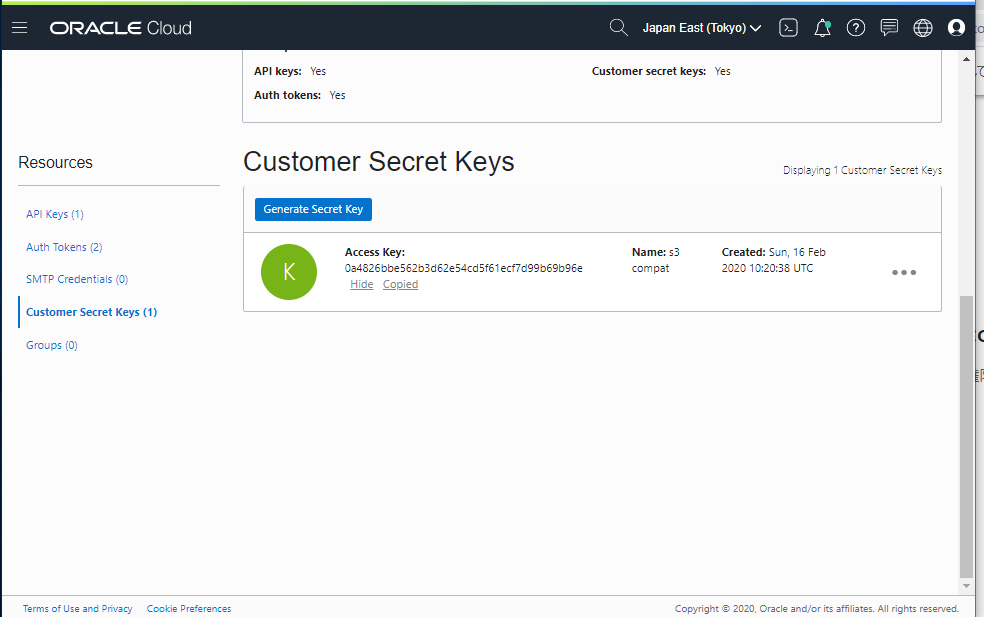
画面を戻すと、Access Key が表示されています。
Object Storage の Endpoint
OCI 上で次の2つの情報を確認すると、Endpoint を把握することが出来ます
- Region Identifier
- Bucket の Namespace
Region Identifier は、次の Document に書かれています

Bucket の Namespaceは、OCI Console で詳細を開くと確認できます。

これを、以下の書式にあてはめると、S3互換APIのEndpointがわかります
https://<Namespace>.compat.objectstorage.<Region Identifier>.oraclecloud.com
Firewalld 停止
CentOSの外側でファイアウォールを構成するため、CentOS 上の Firewalld を停止
sudo systemctl stop firewalld
sudo systemctl disable firewalld
Open JDK 8 の Install
Presto の動作に必要な Java 8 (記事の手順ではOpen JDK 8) を Install します。好きな JDK 8 で問題ないです。
sudo yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
ssh設定
localhostにパスワード無しでssh接続できるようにします。
ssh-keygen
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
ssh接続できるか検証
ssh localhost
Hadoop Install
以下に公開
http://ftp.kddilabs.jp/infosystems/apache/hadoop/common/hadoop-3.2.1/
今回は、3.2.1

ダウンロード
mkdir ~/hadoop
cd ~/hadoop
wget http://ftp.kddilabs.jp/infosystems/apache/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
解凍
tar xfvz hadoop-3.2.1.tar.gz
確認
[opc@hyve hadoop]$ ls -la ~/hadoop/hadoop-3.2.1/
total 124
drwxr-xr-x. 9 opc opc 149 Sep 10 2018 .
drwxrwxr-x. 3 opc opc 53 Apr 26 07:54 ..
-rw-r--r--. 1 opc opc 99253 Sep 10 2018 LICENSE.txt
-rw-r--r--. 1 opc opc 15915 Sep 10 2018 NOTICE.txt
-rw-r--r--. 1 opc opc 1366 Sep 10 2018 README.txt
drwxr-xr-x. 2 opc opc 194 Sep 10 2018 bin
drwxr-xr-x. 3 opc opc 20 Sep 10 2018 etc
drwxr-xr-x. 2 opc opc 106 Sep 10 2018 include
drwxr-xr-x. 3 opc opc 20 Sep 10 2018 lib
drwxr-xr-x. 2 opc opc 239 Sep 10 2018 libexec
drwxr-xr-x. 2 opc opc 4096 Sep 10 2018 sbin
drwxr-xr-x. 4 opc opc 31 Sep 10 2018 share
環境変数設定
bashrc に追記
echo 'export HADOOP_HOME=$HOME/hadoop/hadoop-3.2.1/' >> ~/.bashrc
bashrc 再読み込み
source ~/.bashrc
Hadoop の環境設定シェルを編集
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
# export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr
動作確認のために、Hadoop コマンドを実行して、Help が表示されるのを確認します。
cd $HADOOP_HOME
bin/hadoop
実行例
[opc@hivenew hadoop-3.2.1]$ bin/hadoop
Usage: hadoop [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
or hadoop [OPTIONS] CLASSNAME [CLASSNAME OPTIONS]
where CLASSNAME is a user-provided Java class
OPTIONS is none or any of:
--config dir Hadoop config directory
--debug turn on shell script debug mode
--help usage information
buildpaths attempt to add class files from build tree
hostnames list[,of,host,names] hosts to use in slave mode
hosts filename list of hosts to use in slave mode
loglevel level set the log4j level for this command
workers turn on worker mode
SUBCOMMAND is one of:
Admin Commands:
daemonlog get/set the log level for each daemon
Client Commands:
archive create a Hadoop archive
checknative check native Hadoop and compression libraries availability
classpath prints the class path needed to get the Hadoop jar and the required libraries
conftest validate configuration XML files
credential interact with credential providers
distch distributed metadata changer
distcp copy file or directories recursively
dtutil operations related to delegation tokens
envvars display computed Hadoop environment variables
fs run a generic filesystem user client
gridmix submit a mix of synthetic job, modeling a profiled from production load
jar <jar> run a jar file. NOTE: please use "yarn jar" to launch YARN applications, not this command.
jnipath prints the java.library.path
kdiag Diagnose Kerberos Problems
kerbname show auth_to_local principal conversion
key manage keys via the KeyProvider
rumenfolder scale a rumen input trace
rumentrace convert logs into a rumen trace
s3guard manage metadata on S3
trace view and modify Hadoop tracing settings
version print the version
Daemon Commands:
kms run KMS, the Key Management Server
SUBCOMMAND may print help when invoked w/o parameters or with -h.
HDFS 構成
HDFS で使用する2個のディレクトリを作成
mkdir -p ~/hdfs/{name,data}
core-site.xml を編集します。s3互換APIとして、Object Storage へアクセスするための情報を記載しています。環境に合わせて、Secret Keys や Endpoint の値は変更してください。
cat <<'EOF' > $HADOOP_HOME/etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>fs.s3a.impl</name>
<value>org.apache.hadoop.fs.s3a.S3AFileSystem</value>
</property>
<property>
<name>fs.s3a.access.key</name>
<value>f657832e68601301111522501b62ea41c7244b3a</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>g54cbhisD8i+xougkKfaDhNajWmEuT7NUiVj1QRqORi=</value>
</property>
<property>
<name>fs.s3a.path.style.access</name>
<value>true</value>
</property>
<property>
<name>fs.s3a.endpoint</name>
<value>nryjxkqe0mhq.compat.objectstorage.ap-tokyo-1.oraclecloud.com</value>
</property>
</configuration>
EOF
hdfs-site.xml
cat <<'EOF' > $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/home/opc/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/opc/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
EOF
S3互換APIを触るための設定
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
末尾に以下を追加します。
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HADOOP_HOME/share/hadoop/tools/lib/*
namenode を初期化します
cd $HADOOP_HOME
bin/hadoop namenode -format
実行例
[opc@hyve hadoop-2.8.5]$ bin/hadoop namenode -format
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
20/04/26 09:45:18 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: user = opc
STARTUP_MSG: host = hyve.pubsubnet01.testvcn.oraclevcn.com/10.0.0.6
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.8.5
省略
20/04/26 09:45:19 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
20/04/26 09:45:19 INFO util.ExitUtil: Exiting with status 0
20/04/26 09:45:19 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hyve.pubsubnet01.testvcn.oraclevcn.com/10.0.0.6
************************************************************/
[opc@hyve hadoop-2.8.5]$
name 配下にfileが生成
[opc@hyve hdfs]$ tree ~/hdfs
/home/opc/hdfs
|-- data
`-- name
`-- current
|-- VERSION
|-- fsimage_0000000000000000000
|-- fsimage_0000000000000000000.md5
`-- seen_txid
3 directories, 4 files
[opc@hyve hdfs]$
NameNode と DataNode を起動します
cd $HADOOP_HOME
sbin/start-dfs.sh
yes を入力
[opc@hyve hadoop-2.8.5]$ sbin/start-dfs.sh
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/opc/hadoop/hadoop-2.8.5/logs/hadoop-opc-namenode-hyve.out
localhost: starting datanode, logging to /home/opc/hadoop/hadoop-2.8.5/logs/hadoop-opc-datanode-hyve.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
ECDSA key fingerprint is SHA256:PkOuUBKh6uLQv1mCIEuBzu/Gn3ri1EkbdHlkK7RBkm0.
ECDSA key fingerprint is MD5:5c:b4:99:eb:c8:aa:76:a9:70:54:09:d0:13:e3:af:15.
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /home/opc/hadoop/hadoop-2.8.5/logs/hadoop-opc-secondarynamenode-hyve.out
[opc@hyve hadoop-2.8.5]$
なお、停止方法はこちら
cd $HADOOP_HOME
sbin/stop-dfs.sh
HDFS の参照コマンドを実行できるか確認。結果は何も表示されなくてOK
cd $HADOOP_HOME
bin/hadoop fs -ls /
ディレクトリ作成
bin/hadoop fs -mkdir /user
確認
bin/hadoop fs -ls /
実行例
[opc@hyve hadoop-2.8.5]$ bin/hadoop fs -ls /
Found 1 items
drwxr-xr-x - opc supergroup 0 2020-04-26 09:58 /user
[opc@hyve hadoop-2.8.5]$
Hadoop WebUI にアクセス
このコマンドで全てを起動
cd $HADOOP_HOME
sbin/start-all.sh
次のアドレスでアクセスすると表示される
http://youripaddress:9870
Object Storage へのアクセステスト
hadoop で s3a:// 識別子を使ってアクセステストを行います。実際には、OCI の Object Storage へアクセスをしています。
cd $HADOOP_HOME
bin/hadoop fs -ls s3a://inputbucket/
実行例
[opc@hivenew hadoop-3.2.1]$ bin/hadoop fs -ls s3a://inputbucket/
2020-05-02 13:32:54,344 INFO impl.MetricsConfig: Loaded properties from hadoop-metrics2.properties
2020-05-02 13:32:54,396 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s).
2020-05-02 13:32:54,396 INFO impl.MetricsSystemImpl: s3a-file-system metrics system started
Found 4 items
drwxrwxrwx - opc opc 0 2020-05-02 13:32 s3a://inputbucket/multi
-rw-rw-rw- 1 opc opc 9388 2020-05-01 11:01 s3a://inputbucket/outout.zip
-rw-rw-rw- 1 opc opc 135 2020-04-24 19:48 s3a://inputbucket/pre_1h.csv
drwxrwxrwx - opc opc 0 2020-05-02 13:32 s3a://inputbucket/testcsv.csv
2020-05-02 13:32:55,360 INFO impl.MetricsSystemImpl: Stopping s3a-file-system metrics system...
2020-05-02 13:32:55,360 INFO impl.MetricsSystemImpl: s3a-file-system metrics system stopped.
2020-05-02 13:32:55,360 INFO impl.MetricsSystemImpl: s3a-file-system metrics system shutdown complete.
[opc@hivenew hadoop-3.2.1]$
作成テスト
cd $HADOOP_HOME
bin/hadoop fs -touchz s3a://inputbucket/testhadoop.txt
実行例
[opc@hivenew hadoop-3.2.1]$ bin/hadoop fs -touchz s3a://inputbucket/testhadoop.txt
2020-05-02 17:12:30,767 INFO impl.MetricsConfig: Loaded properties from hadoop-metrics2.properties
2020-05-02 17:12:30,831 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s).
2020-05-02 17:12:30,831 INFO impl.MetricsSystemImpl: s3a-file-system metrics system started
2020-05-02 17:12:32,421 INFO impl.MetricsSystemImpl: Stopping s3a-file-system metrics system...
2020-05-02 17:12:32,421 INFO impl.MetricsSystemImpl: s3a-file-system metrics system stopped.
2020-05-02 17:12:32,421 INFO impl.MetricsSystemImpl: s3a-file-system metrics system shutdown complete.
[opc@hivenew hadoop-3.2.1]$
実際に Object Storage を確認すると、正常に作成されています

Hive Install
以下のURLを開いて、ダウンロード先を確認します

CentOSにダウンロードします
mkdir ~/hive
cd ~/hive
wget https://archive.apache.org/dist/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
解凍
tar xfvz apache-hive-3.1.2-bin.tar.gz
確認
[opc@hivenew hive]$ ls -la apache-hive-3.1.2-bin
total 56
drwxrwxr-x. 10 opc opc 184 May 2 13:49 .
drwxrwxr-x. 3 opc opc 71 May 2 13:49 ..
-rw-r--r--. 1 opc opc 20798 Aug 22 2019 LICENSE
-rw-r--r--. 1 opc opc 230 Aug 22 2019 NOTICE
-rw-r--r--. 1 opc opc 2469 Aug 22 2019 RELEASE_NOTES.txt
drwxrwxr-x. 3 opc opc 157 May 2 13:49 bin
drwxrwxr-x. 2 opc opc 4096 May 2 13:49 binary-package-licenses
drwxrwxr-x. 2 opc opc 4096 May 2 13:49 conf
drwxrwxr-x. 4 opc opc 34 May 2 13:49 examples
drwxrwxr-x. 7 opc opc 68 May 2 13:49 hcatalog
drwxrwxr-x. 2 opc opc 44 May 2 13:49 jdbc
drwxrwxr-x. 4 opc opc 12288 May 2 13:49 lib
drwxrwxr-x. 4 opc opc 35 May 2 13:49 scripts
環境変数設定
bashrc に追記
echo 'export HIVE_HOME=$HOME/hive/apache-hive-3.1.2-bin/' >> ~/.bashrc
bashrc 再読み込み
source ~/.bashrc
guavaライブラリのバージョンを統一
Hadoop と Hive で guava のバージョンが異なっており、以下のエラーが出ました。
[opc@hivenew bin]$ ./schematool -dbType mysql -initSchema
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/opc/hive/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/opc/hadoop/hadoop-3.2.1/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1357)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1338)
at org.apache.hadoop.mapred.JobConf.setJar(JobConf.java:536)
at org.apache.hadoop.mapred.JobConf.setJarByClass(JobConf.java:554)
at org.apache.hadoop.mapred.JobConf.<init>(JobConf.java:448)
at org.apache.hadoop.hive.conf.HiveConf.initialize(HiveConf.java:5141)
at org.apache.hadoop.hive.conf.HiveConf.<init>(HiveConf.java:5104)
at org.apache.hive.beeline.HiveSchemaTool.<init>(HiveSchemaTool.java:96)
at org.apache.hive.beeline.HiveSchemaTool.main(HiveSchemaTool.java:1473)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:323)
at org.apache.hadoop.util.RunJar.main(RunJar.java:236)
[opc@hivenew bin]$
locate コマンドでみると、バージョンの違いがわかります。
- Hadoop :
guava-27.0-jre.jar - Hive :
guava-19.0.jar
[opc@hivenew hadoop]$ locate guava
/home/opc/hadoop/hadoop-3.2.1/share/hadoop/common/lib/guava-27.0-jre.jar
/home/opc/hadoop/hadoop-3.2.1/share/hadoop/common/lib/listenablefuture-9999.0-empty-to-avoid-conflict-with-guava.jar
/home/opc/hadoop/hadoop-3.2.1/share/hadoop/hdfs/lib/guava-27.0-jre.jar
/home/opc/hadoop/hadoop-3.2.1/share/hadoop/hdfs/lib/listenablefuture-9999.0-empty-to-avoid-conflict-with-guava.jar
/home/opc/hive/apache-hive-3.1.2-bin/lib/guava-19.0.jar
Hive 側を削除
rm /home/opc/hive/apache-hive-3.1.2-bin/lib/guava-19.0.jar
Hadoop から Hive へ Copy
cp -p /home/opc/hadoop/hadoop-3.2.1/share/hadoop/common/lib/guava-27.0-jre.jar /home/opc/hive/apache-hive-3.1.2-bin/lib/
MySQL用JDBC Driver 配置
Hive Metastore として MySQL を使用するため、アクセスするための Driver をダウンロードします。MySQL のバージョンと合致したものをインストールします。

CentOS にダウンロード
mkdir ~/jdbc
cd ~/jdbc
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-8.0.19.tar.gz
解凍
tar xfvz mysql-connector-java-8.0.19.tar.gz
HIVE HOME に copy
cp -p mysql-connector-java-8.0.19/mysql-connector-java-8.0.19.jar $HIVE_HOME/lib/
MySQL 上で設定
MySQL サーバーに root ユーザーでログインします
mysql -u root -h 10.0.0.13 -p
Hive Metastore として使用するために、Database やユーザー・権限設定を行います。
create database hive_metastore default character set 'latin1';
use hive_metastore;
create user hive identified by '#nan_jf3Tr>41';
grant all privileges on hive_metastore.* to 'hive'@'%';
一度抜けたあとに、hive ユーザーでログインできるか確認します。Hive サーバーから、ログインできればOKです。
mysql -u hive -h 10.0.0.13 -p
HIVE Metastore の設定
MySQL を Hive Metastore として設定します。接続先のIPアドレスやパスワードは適宜変更してください。
cat <<'EOF' > $HIVE_HOME/conf/hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://10.0.0.13/hive_metastore?useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>#nan_jf3Tr>41</value>
</property>
<property>
<name>datanucleus.fixedDatastore</name>
<value>false</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/tmp/hive</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/tmp/hive</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/tmp/hive</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
</configuration>
EOF
MySQL のスキーマを初期化します
cd $HIVE_HOME/bin
./schematool -dbType mysql -initSchema --verbose
実行例
[opc@hyve bin]$ ./schematool -dbType mysql -initSchema
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/opc/hive/apache-hive-2.3.6-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/opc/hadoop/hadoop-2.8.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://10.0.0.5/hive_metastore?autoReconnect=true&useSSL=false
Metastore Connection Driver : com.mysql.cj.jdbc.Driver
Metastore connection User: hive
Starting metastore schema initialization to 2.3.0
Initialization script hive-schema-2.3.0.mysql.sql
Initialization script completed
schemaTool completed
[opc@hyve bin]$
HIVE コマンドで Object Storage に接続
Object Storage には、以下のcsv形式の2個のファイルがアップロードされています。
multi1.csv
rank,name
1,satou
2,suzuki
3,tanaka
multi2.csv
rank,name
4,sugiyama
5,kato
アップロードされている様子です。

Hive CLI を起動します
$HIVE_HOME/bin/hive
実行例
[opc@hyve bin]$ $HIVE_HOME/bin/hive
which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/opc/.local/bin:/home/opc/bin)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/opc/hive/apache-hive-2.3.6-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/opc/hadoop/hadoop-2.8.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/home/opc/hive/apache-hive-2.3.6-bin/lib/hive-common-2.3.6.jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive>
database を create します。名前は適当に sugi にします。
CREATE DATABASE sugi COMMENT 'sugi test';
sugi database 上で、test1 という名前の外部表を定義します。s3a:// と指定していますが、OCI Object Storage を参照しています。
CREATE EXTERNAL TABLE sugi.test1 (
rank int,
name string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
stored as textfile LOCATION 's3a://inputbucket/multi'
tblproperties ("skip.header.line.count"="1");
Selectしてみます。
select * from sugi.test1 limit 20;
実行例。Object Storage 上のデータが確認出来ます。
hive> select * from sugi.test1 limit 20;
OK
1 satou
2 suzuki
3 tanaka
4 sugiyama
5 kato
Time taken: 1.653 seconds, Fetched: 5 row(s)
hive>
rankに絞ってSelectしてみます。
select rank from sugi.test1 limit 20;
実行例
hive> select rank from sugi.test1 limit 20;
OK
1
2
3
4
5
Time taken: 0.231 seconds, Fetched: 5 row(s)
hive>
参考URL
Hadoop Official Site
http://hadoop.apache.org/
Hive Official Site
https://hive.apache.org/