はじめに
Oracle Cloud Integration では、ETL 機能を提供する Data Integration サービスがあります。Data Integration は、様々なデータアセットからデータを取り込み、データのクレンジング・変換・再形成・変換などの ETL 処理が出来るフルマネージドサービスです。サーバー管理が不要で、GUI で視覚的にわかりやすく ETL 処理を表現できます。
ファイルの分割方法を簡単に紹介します。ファイル内の特定の列の値によって、出力するファイルを分割したい用途を想像しています。具体例は次の通りです。
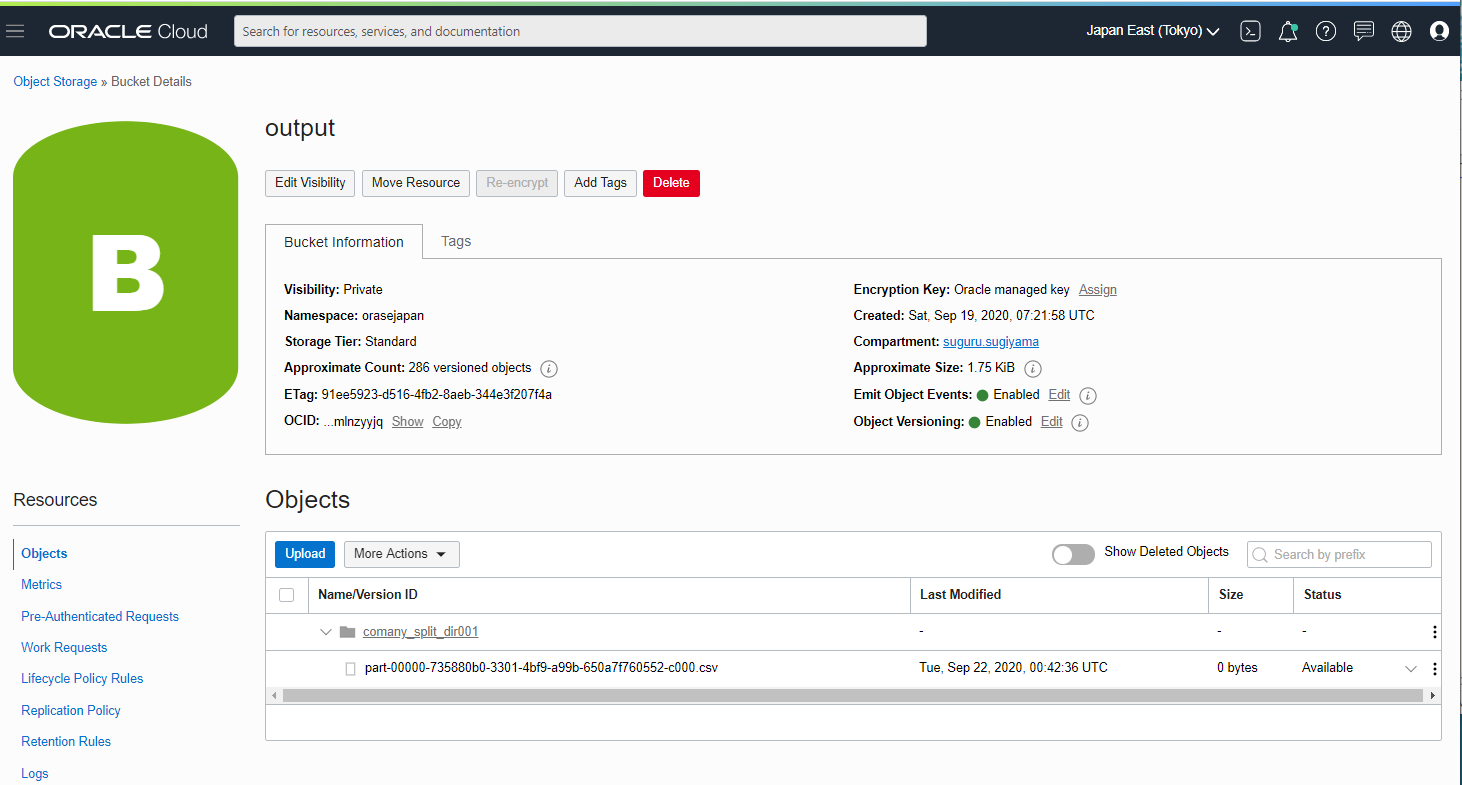
データ変換前です。Object Storage に user-split.csv というファイルがあります。
name,userrank,company
sugiyama,bronze,a
tanaka,silver,b
kimura,gold,c
satou,bronze,a
koga,silver,b
komikado,gold,c
suzuki,bronze,a
eto,silver,b
kato,platinum,c
company の列は、a, b, c と3種類の会社があります。この3種類の会社ごとにファイルを分割して出力する方法を紹介します。
留意点
Data Integration 側で、受け取ったデータの company を解析して、ファイルを動的に分割は出来ません。Data Integration のタスクを実行側で「companyには、このデータが存在しているはずだから、この名前で分割をしてね」とパラメータを与えることで、想定した動きに出来ます。
データ分割する Data Flow を作成
まず、Input の csv ファイルを定義します。

Company Name で Filter を設定する部分です。Parameter 化をするので、わかりやすい説明を入れています。

Data Tab を確認し、エラーが発生しないことを確認します。Filter の条件を please input company name としているため、No items found となるのは正常です。

Filter に、Parameter を Assign します

Add New Parameter を押します
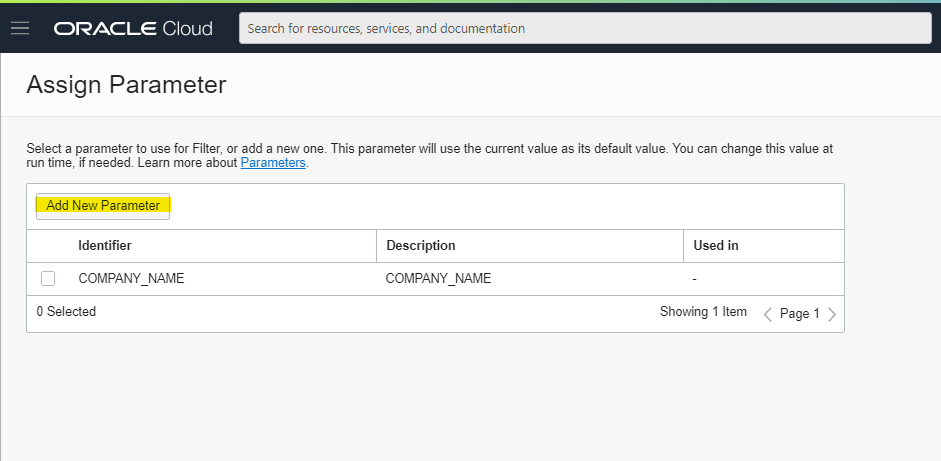
Identifier にわかりやすい名前を入れて、Add をします

Assign します

表示が変わります

Target の Object Storage の設定を入れます
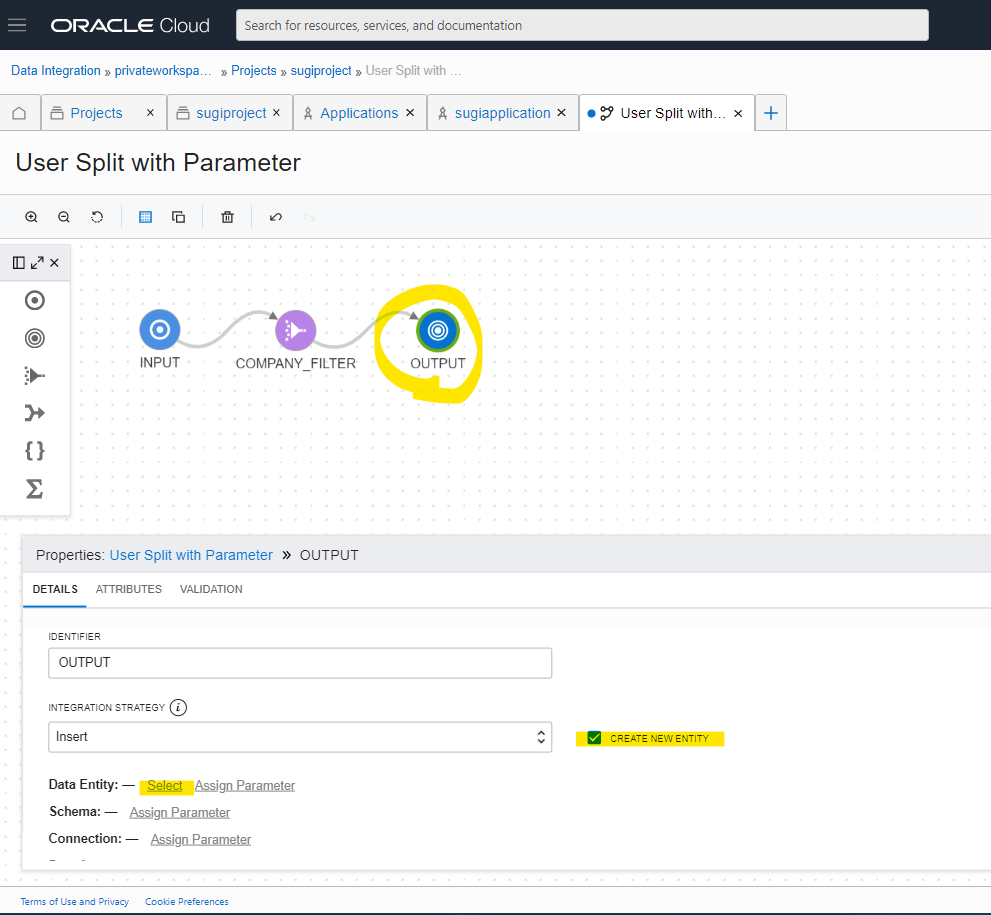
Output Bucket と、そこに作成する Directory Name を指定

最後に、Validate して、Save and Close をします

動作確認
作成した Data Flow を、Integration Task として作成して、Application に Publish した上で、動作確認してみます
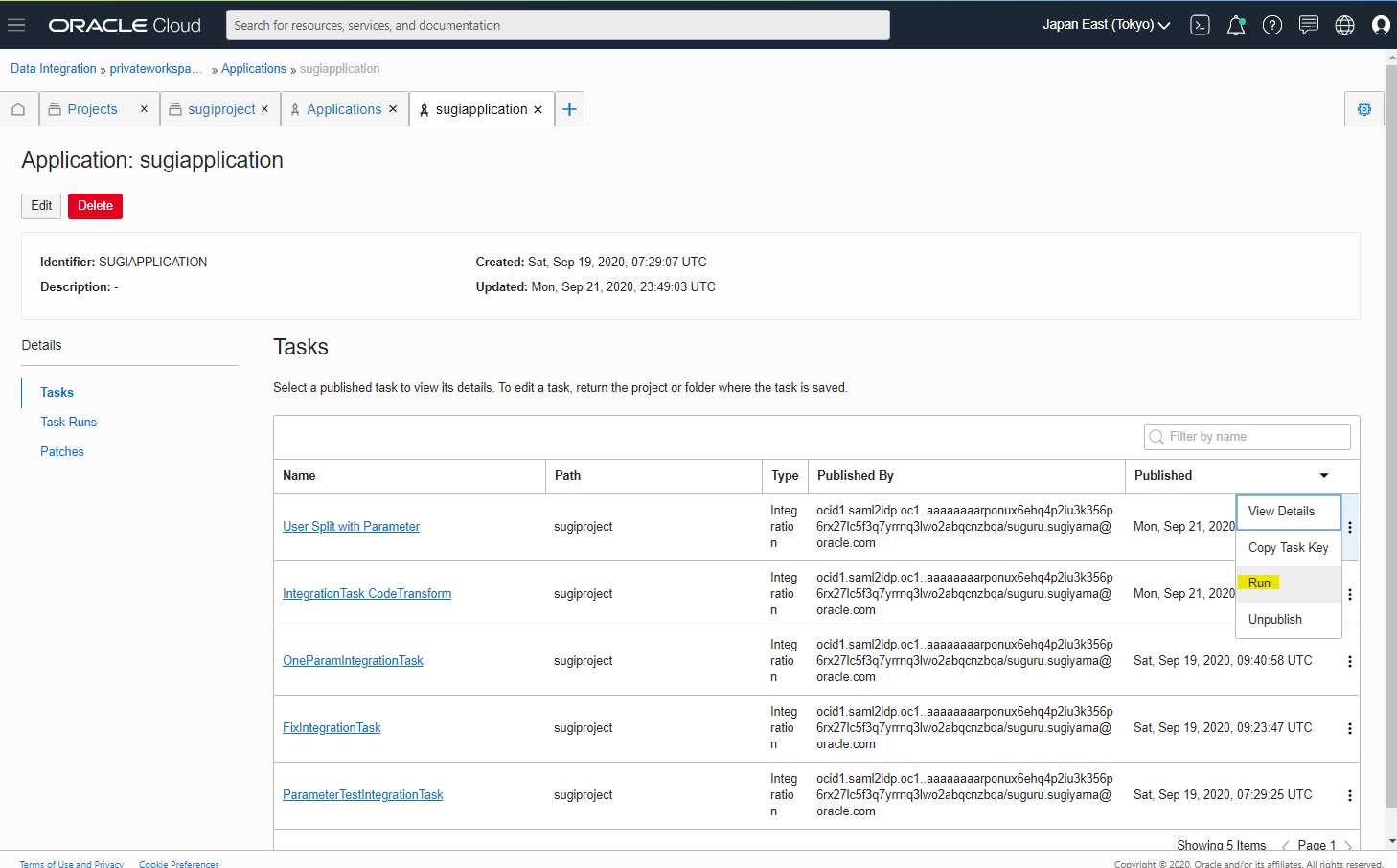
Parameter で指定した名前が、Edit 出来るようになっています。Edit を押します。

Condition をそのまま編集できる画面になっています
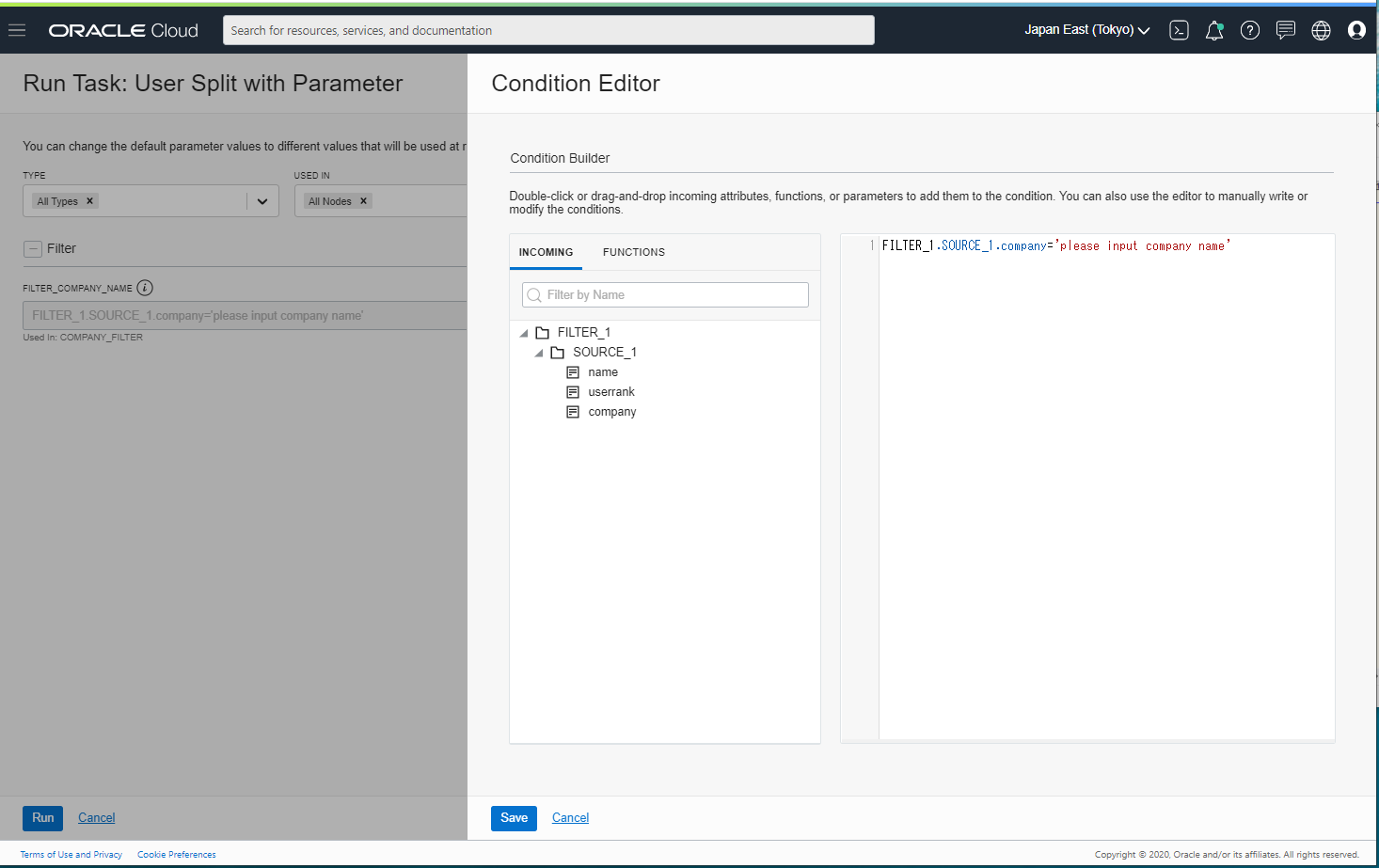
Company Name が a をフィルターしてみます
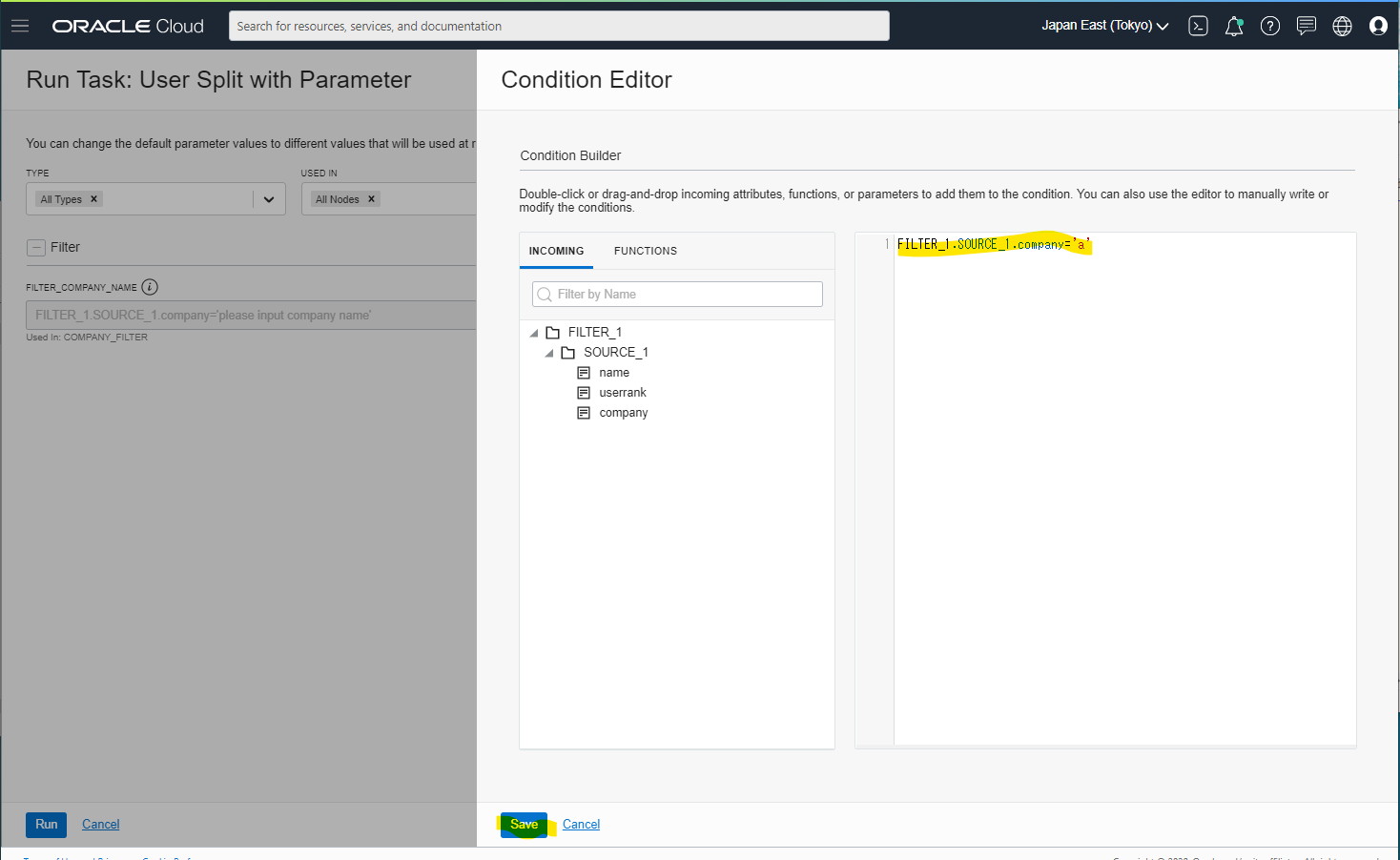
Runします

Task Runs の一覧に出力されています。一定時間後に、Success となります。

output bucket に出力されています
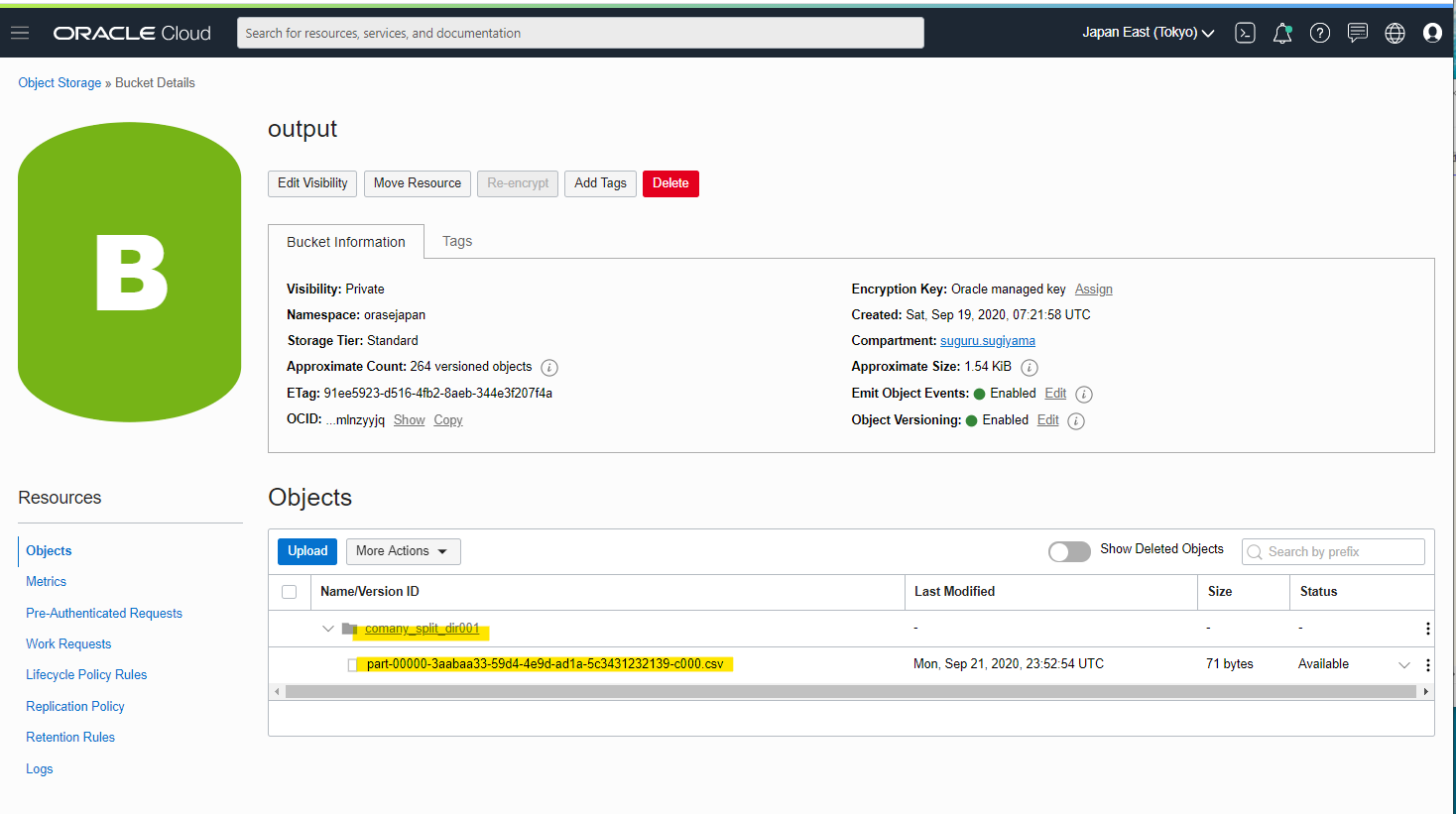
ファイルの中身を見てみると、こんな感じになっています。正しく a でフィルターされていますね。
name,userrank,company
sugiyama,bronze,a
satou,bronze,a
suzuki,bronze,a
同じような方法で、パラメータに、b や c を入力すると、意図したファイル分割が出来ます。
想定外のデータ出力
今回の方法は、Task の実行側で Filter の条件を指定する方法です。a や b, c Company ということが分かっているので、指定しています。ただ、e といった想定外のデータが入ったときには、それを検知したいと思うはずです。データ加工のタスクを実行する際に、次のようにパラメータを与えるのが良いと思います
- 欲しいデータ。次の名前でフィルターする
abc
- 想定外のデータ。検知はしたい
-
a,b,c以外のデータをフィルター
-
想定外のデータは、想定外専用の Object Storage を用意して、そこに出力すると良いでしょう。例を挙げます。次のデータを与えたときに、一番下の d company に所属している erroruser を検知したいと思うはずです。
name,userrank,company
sugiyama,bronze,a
tanaka,silver,b
kimura,gold,c
satou,bronze,a
koga,silver,b
komikado,gold,c
suzuki,bronze,a
eto,silver,b
erroruser,hoge,d
これを実現するための方法を確認してみましょう。Task Run する時のパラメータで、次の Condition を指定すると、a,b,c のどれでもないデータを抽出できます
NOT FILTER_1.SOURCE_1.company = 'a'
AND
NOT FILTER_1.SOURCE_1.company = 'b'
AND
NOT FILTER_1.SOURCE_1.company = 'c'
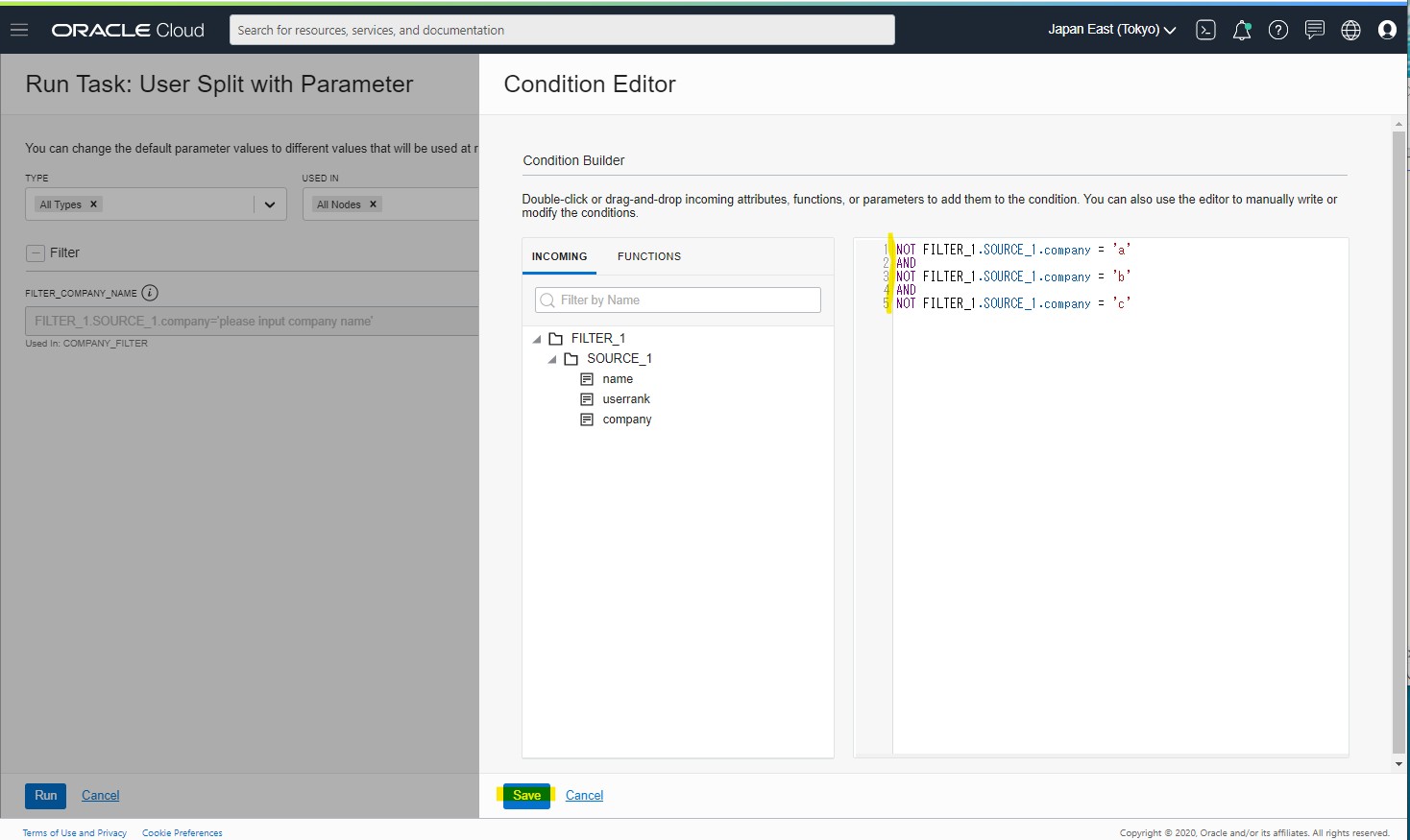
上記で実行したときの実行例です。

csv ファイルの中身です
name,userrank,company
erroruser,hoge,d
実際の運用では、エラーデータ格納用の Object Storage Bucket を用意して、ファイルが格納されたことを検知して Functions を起動させ、ファイルの中身にデータがあれば、Notification などで Email や Slack 通知をすると良いでしょう。
付録 : 指定した Company Name がなかったとき
a, b, c といった Company Name を指定してフィルターをします。この時、指定した名前のデータが無かった時はどのような挙動になるでしょうか? 結論は、Task が正常に終了し、中身が空のデータが出来上がります。見てみましょう。
e でフィルターしてみます。e のデータは無いので、中身が空のデータが出来上がる予定です。

Task が成功します。
中身は空ですが、Directory と空のファイルが出来上がります