はじめに
Amazon Kinesis Data Analytics は、一言で表現するとストリーミングデータに対する分析・集計・データ加工を行うためのサービスです。構成図で表現すると、こんな感じで他サービスと組み合わせることができます。

この構成図のポイントを整理します。
- IoT デバイスから生まれる多くのストリームデータを、IoT Core が受け取る
- IoT Core のルールを指定して、Kinesis Data Streams にストリームデータを流す
- Kinesis Data Streams から、Kinesis Data Analytics にストリームデータを連携する
- Kinesis Data Analytics は流れ込んでくるストリームデータに対する、データ分析・集計・加工が行える
- 例えば 1 分おきの平均データを集計して、後続の Kinesis Data Streams に流すことが出来る
- それ以降は、Lambda など自由に構成できるので、好きなようにデータをハンドリングする
一般的に、リアルタイムにデータが生成されるストリームデータを使って、一定期間ごとの集計を行うのは大変な作業です。データが少ないうちは問題なくても、データが増えたときのパフォーマンスを考慮すると、困難さが予想できます。そこで、Kinesis Data Analytics を使うと、AWS 側にインフラの管理負担を任せながら Java, Scala, Python, SQL を使って、データの集計が出来ます。
例えば次のような SQL クエリーを Kinesis Data Analytics に渡すことで、ストリームデータを 1 分ごとに集計してくれます。TUMBLE_START や TUMBLE_END, TUMBLE の部分で、集計の期間を指定できます。下の SQL クエリーの例では、60 秒おきの平均データを集計しています。
%flink.ssql(type=update)
INSERT INTO people_data_destination
SELECT
ROOM,
TUMBLE_START(EVENTTIME, INTERVAL '60' SECOND) as WINDOW_START,
TUMBLE_END(EVENTTIME, INTERVAL '60' SECOND) as WINDOW_END,
AVG(PEOPLE) as AVG_PEOPLE_COUNT,
COUNT(*) as RECORD_COUNT
FROM
people_data
GROUP BY
ROOM,
TUMBLE(EVENTTIME, INTERVAL '60' SECOND);
概要を説明したので、具体的な構成方法を見ていきましょう。
Kinesis Data Analytics は 2 種類ある
はじめに、Kinesis Data Analytics を触っていくうえで、混乱しがちな点を整理します。Kinesis Data Analytics は、大きくわけて 2 種類のアプリケーション構成方法があります。
- Amazon Kinesis Data Analytics for Apache Flink
- Amazon Kinesis Data Analytics for SQL Applications
基本的には、上側の「Amazon Kinesis Data Analytics for Apache Flink」の方を利用することがおすすめです。FAQ に次の一文が書かれています。
新しいプロジェクトでは、SQL アプリケーション用の Kinesis Data Analytics ではなく、新しい Kinesis Data Analytics Studio を使用することをお勧めします。Kinesis Data Analytics Studio は使いやすさと高度な分析機能を組み合わせており、洗練されたストリーム処理アプリケーションでも数分で構築できます。
Kinesis Data Analytics Studio では、SQL クエリーやコードを書きながら、リアルタイムに集計結果を確認できるので、効率的に作業できるメリットがあると感じています。Amazon Kinesis Data Analytics for Apache Flink を先に利用できるか検討してみることをおすすめします。
また、Flink 版と SQL 版は、AWS の Document や、利用する機能が異なるので、混乱しないように進めていきましょう。
前提条件
この記事で言及する範囲は、次の点線部分です。
IoT Core 周りは、こちらの記事 で構築しています。Lambda のタンブリングウィンドウに関する記事ですが、作業内容としては同じなので参考にしてみてください。
Kinesis Data Streams の設定
Kinesis Data Analytics の前後にある、Kinesis Data Streams を 2 個作成します。
- Source : Kinesis Data Analytics の入力元
- Destination : Kinesis Data Analytics の出力先
Kinesis Data Streams のページに移動して、Create data stream を押します。
今回は、テスト用途なので、Provisioned 1 で構成していきます。
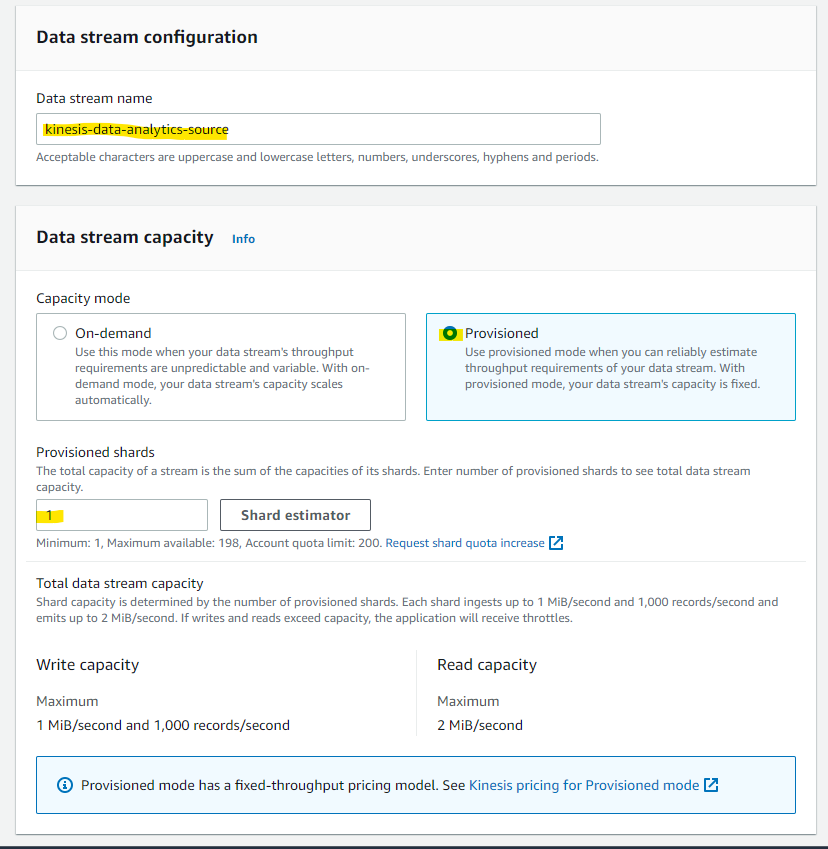
Create data stream を押します
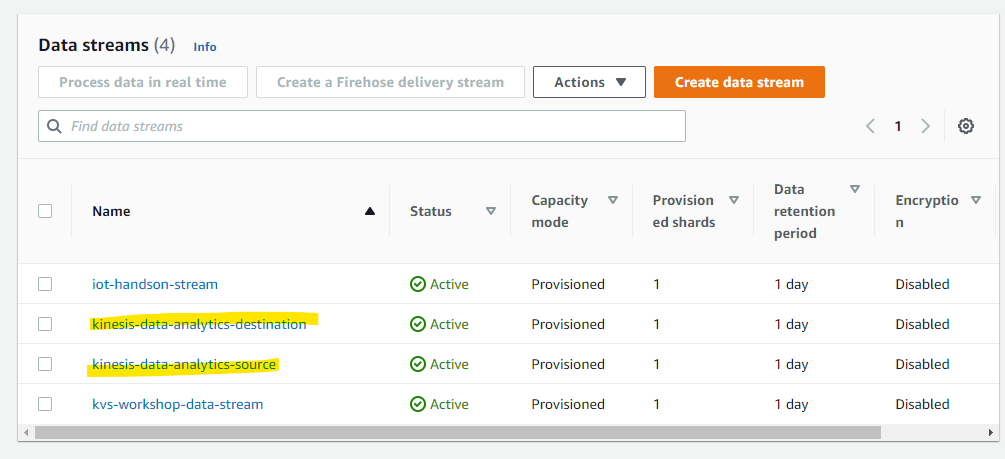
作成されました。

同様に、Destination 用の Kinesis Data Stream を作成しました
IoT Core Rule を設定
IoT Core の MQTT Topic に送付された JSON データを、Kinesis Data Streams に出力するために、IoT Core Rule を設定します。
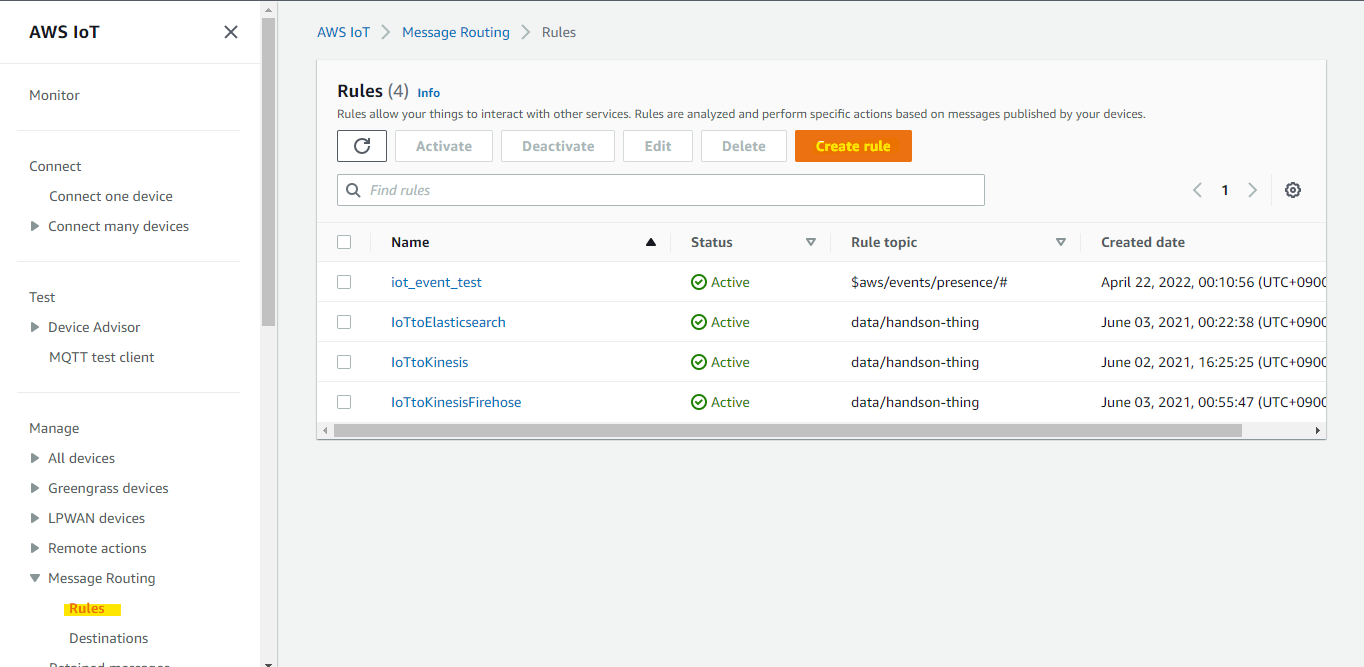
Rule の名前を適当に指定します
KinesisDataAnalyticsTest

Rule の名前や条件を指定します。
次のように FROM に MQTT Topic 名を指定することで、Topic data/kinesis-test-device のデータを全て Kinesis Data Streams に流すことが出来ます。IoT 疑似デバイス側の Amazon Linux 2 から、1秒に1回 data/kinesis-test-device にデータが送付されます。
SELECT * FROM 'data/kinesis-test-device'

次のパラメータを入力します。
- IoT Core を経由して、次に送付する Kinesis Data Streams を指定
- Partition Key は、なんでもよいので newuuid を指定
- IAM Role を指定
${newuuid()}

Create を押します

Kinesis Data Analytics Studio を作成
Kinesis Data Analytics の アプリケーションを作成するために、一旦作業環境として Kinesis Data Analytics Studio Notebook を作成します。Create Studio notebook を押します。
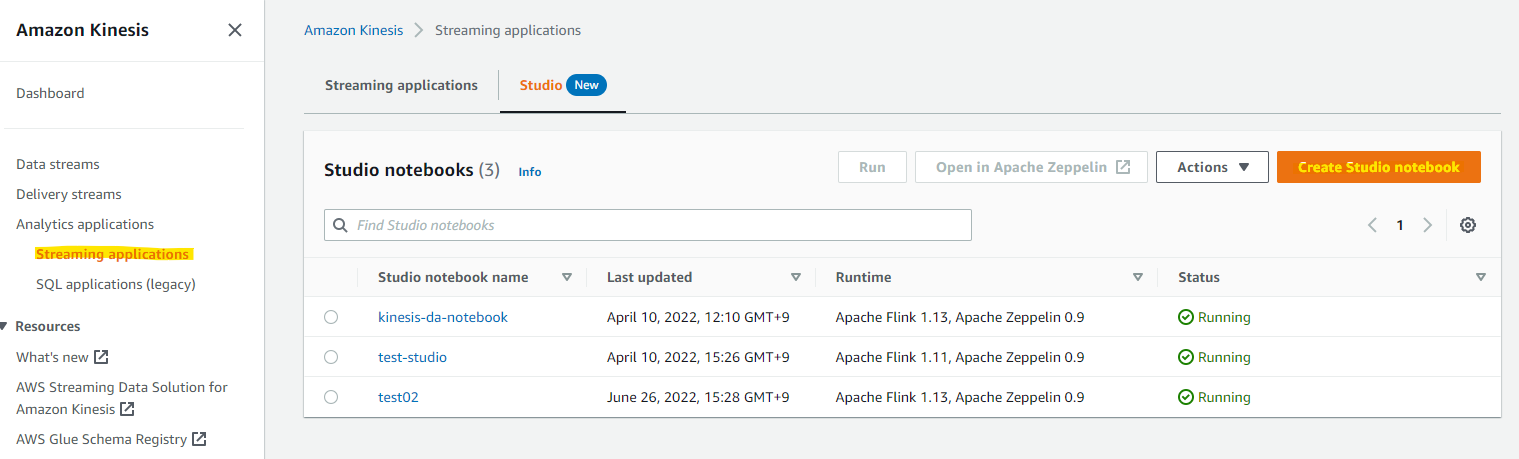
Custom with custom settings を選択して、Notebook の名前を指定します

Glue の Database に、Kinesis Data Analytics 用のものを用意して、Create を押します
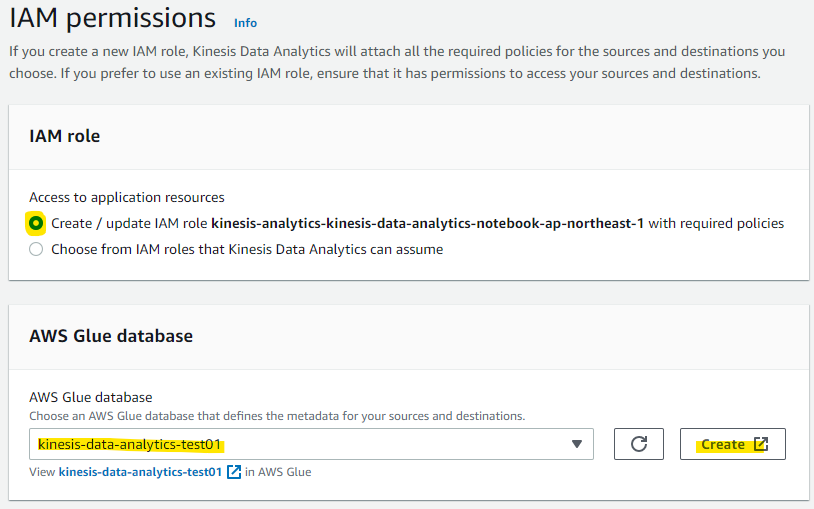
Kinesis Data Analytics の入力元・出力元の Kinesis Data Stream を選択して、Next を押します。

Studio としてのリソースや、ログに関する設定があります。これらはデフォルトでいきます。

Studio で作成したアプリケーションコードをデプロイする先として、S3 バケットを選択します。Kinesis Data Analytics 用に新たに作成した方がわかりやすいと思います。

Next を押します

Create Studio notebook を押します。

Studio が作成されました。作成直後は Ready 状態で動いていないので、Run を押します。

Studio notebook を動かしたときには、1 時間あたりの費用が発生するメッセージが表示されています。起動しっぱなしにはしないように気を付けつつ、Run を押します。

Running を待機する間、IAM Role の権限設定を行います。Glue Studio が Kinesis Data Streams に接続するために、IAM Role に権限の追加が必要です。IAM Role のリンクをクリックします。

Attach policies を押します。
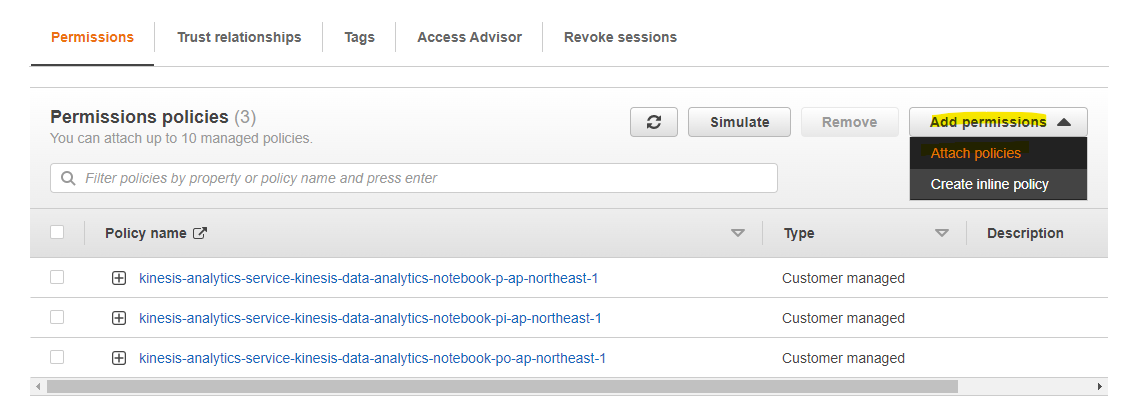
今回は作業をシンプルにするために、AdministratorAccess を利用しますが、実際の本番環境などでは最低限の権限設定が良いです。

2-3 分待機すると、Studio Notebook の Status が Running となるため、Open in Apache Zeppelin を選択します

動作確認用の Note 作成
Zeppein の画面が開かれました。ここで、新たに Note を構成して、アプリケーションをデプロイする前のテーブル作成や動作確認などをしていきます。Create new note を選択します。
好きな名前を付けて Create をします。
PreTableCreateNote

新しい Note の画面が表示されました
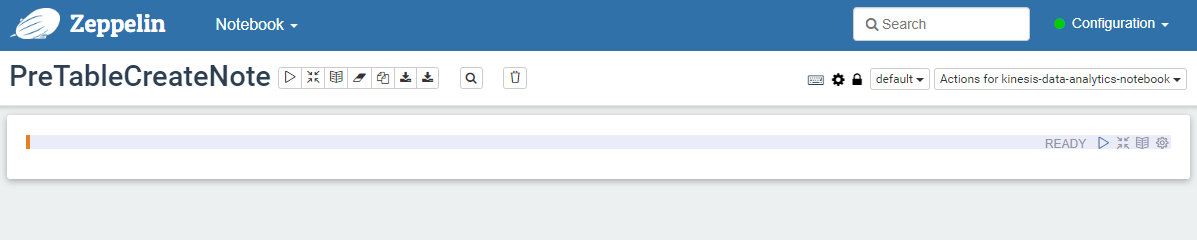
IoT Core から Kinesis Data Streams に送られてくる JSON データは次の形式です
{
"ROOM": 7,
"EVENTTIME": "2022-04-10T12:56:09",
"PEOPLE": 32
}
上の JSON データに合うように、Studio 上で CREATE TABLE をしていきます。
-
WARTERMARK は、Apache Flink の Document に詳細が記載されています。今回は、AWS Blog の内容を参考にして、5秒を指定しておきます。
-
一般に、ウォーターマークとは、ストリームのその時点までに、あるタイムスタンプまでのすべてのイベントが到着しているはずだという宣言である。
-
https://nightlies.apache.org/flink/flink-docs-master/docs/concepts/time/#event-time-and-watermarks
-
%flink.ssql
CREATE TABLE people_data (
ROOM INTEGER,
EVENTTIME TIMESTAMP(3),
PEOPLE DOUBLE,
WATERMARK FOR EVENTTIME AS EVENTTIME - INTERVAL '5' SECOND
)
PARTITIONED BY (ROOM)
WITH (
'connector' = 'kinesis',
'stream' = 'kinesis-data-analytics-source',
'aws.region' = 'ap-northeast-1',
'scan.stream.initpos' = 'LATEST',
'format' = 'json',
'json.timestamp-format.standard' = 'ISO-8601'
)
Note で上記の CREATE TABLE 文を実行すると、記事の環境では、約 40 秒後に、Table has been created と表示され、テーブル定義を作成できます。

余談ですが、CREATE TABLE を行った結果、Glue Data Catalog にテーブル定義が作成されました。Athena や Redshift Spectrum と同じような仕組みですね。

Studio 上で、作成した TABLE に SELECT できます。次のクエリーを入力して再生ボタンを押します。
-
(type=update)と指定することで、Kinesis Data Streams から流れてくるデータをリアルタイムに更新しつづけてくれます
%flink.ssql(type=update)
SELECT * FROM people_data;
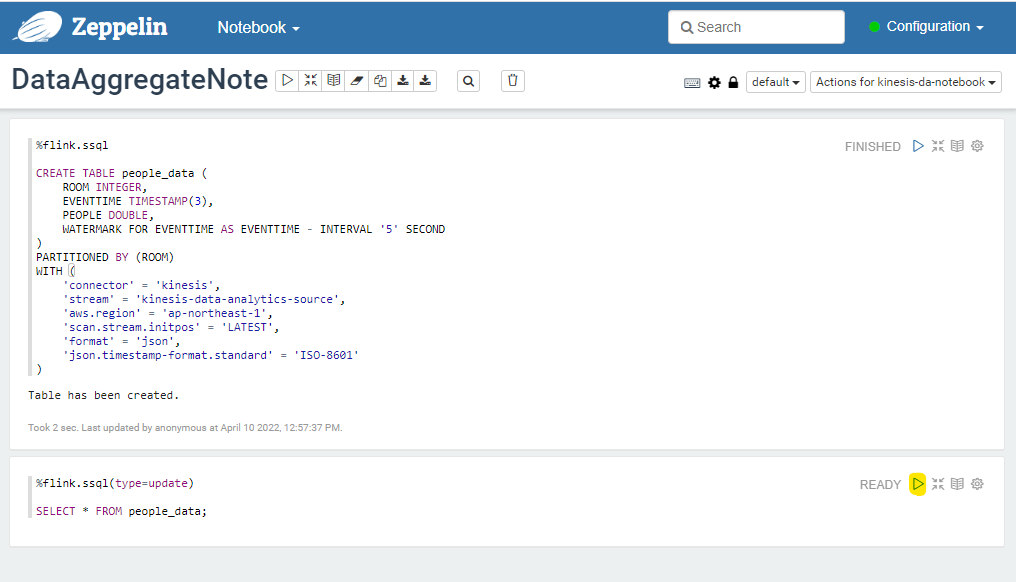
デフォルトでは、テーブル形式でデータが表示されます。1秒に1回あらたなデータが送られてきて、リアルタイムに更新され続けています
Note 上で可視化の見栄えもカスタマイズができます。例えば、平均人数をパイチャートで表示できます。
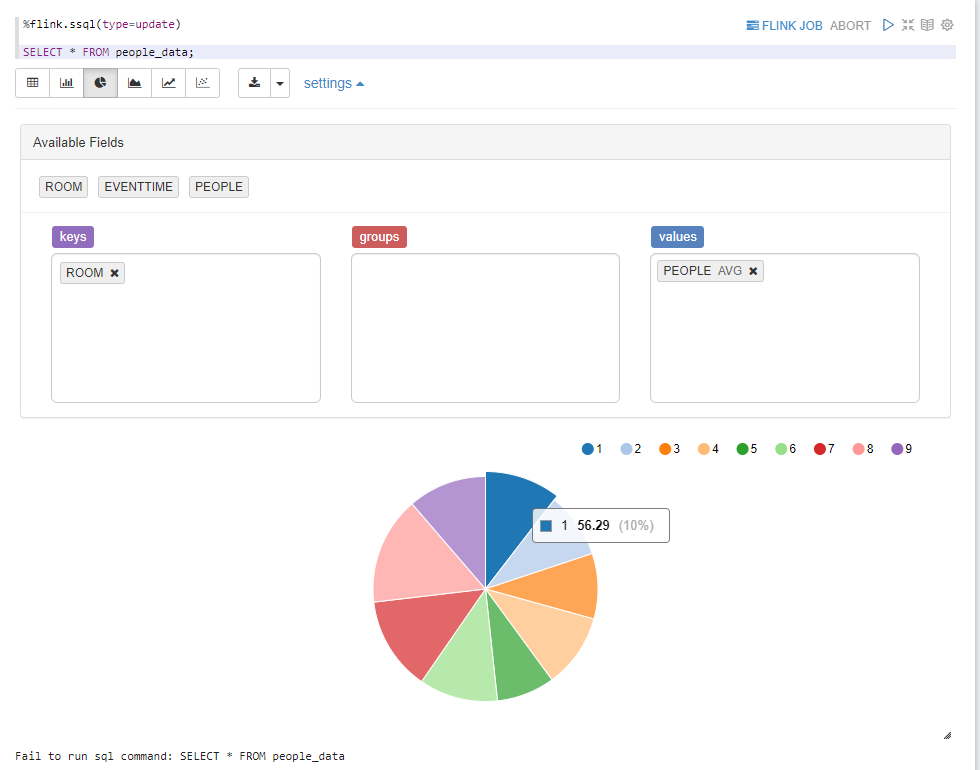
では次に、実際に 1 分おきに集計を行うクエリーを実行してみましょう。次の Document を参考にしてクエリーを組み立てました
-
AWS Document
-
Apache Flink Document
%flink.ssql(type=update)
SELECT
ROOM,
TUMBLE_START(EVENTTIME, INTERVAL '60' SECOND) as WINDOW_START,
TUMBLE_END(EVENTTIME, INTERVAL '60' SECOND) as WINDOW_END,
AVG(PEOPLE) as AVG_PEOPLE_COUNT,
COUNT(*) as RECORD_COUNT
FROM
people_data
GROUP BY
ROOM,
TUMBLE(EVENTTIME, INTERVAL '60' SECOND)
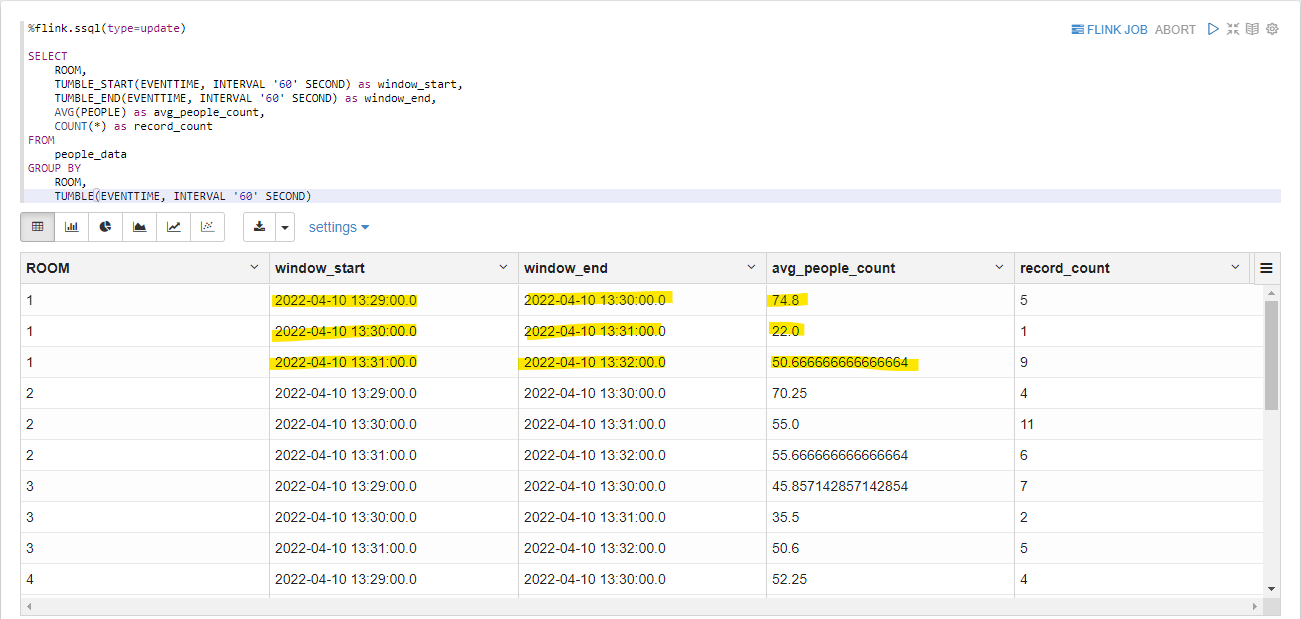
以下の実行結果のように、部屋ごとに、1分周期で平均人数が集計されていることがわかります。
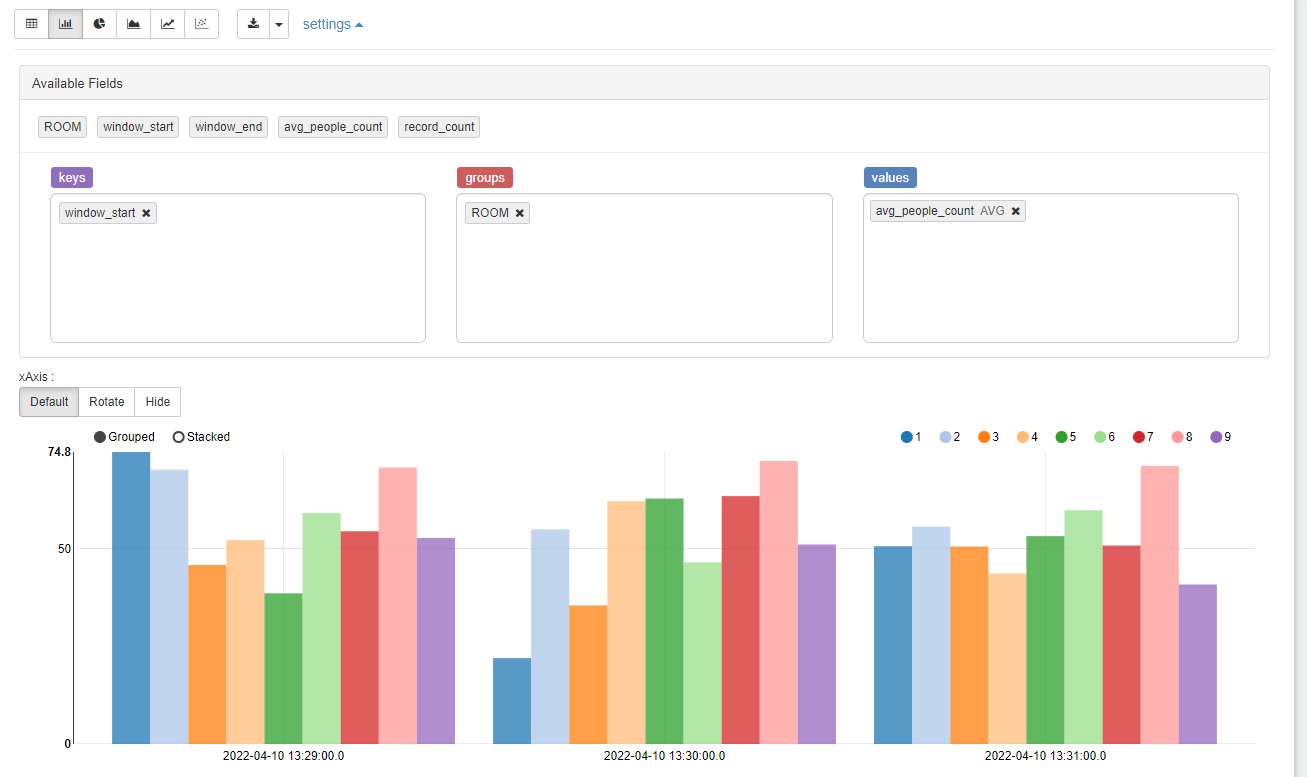
こんな感じに見た目の変更も可能です。
この集計したデータを、出力先の Kinesis Data Streams に接続するために、Create Table を行います。
%flink.ssql
CREATE TABLE people_data_destination (
ROOM INTEGER,
WINDOW_START TIMESTAMP(3),
WINDOW_END TIMESTAMP(3),
AVG_PEOPLE_COUNT DOUBLE,
RECORD_COUNT BIGINT
)
WITH (
'connector' = 'kinesis',
'stream' = 'kinesis-data-analytics-destination',
'aws.region' = 'ap-northeast-1',
'scan.stream.initpos' = 'LATEST',
'format' = 'json',
'json.timestamp-format.standard' = 'ISO-8601'
)
実行します
さきほどと同様に、自動的に Glue の Table に登録されています

この次の SQL クエリーが、実際に集計した結果を次の Kinesis Data Streams に流すものです。INSERT INTO に SELECT 句を付けています。SELECT 句には、TUMBLE に関する指定で 60 秒ごとに集計するように指定しています。
%flink.ssql(type=update)
INSERT INTO people_data_destination
SELECT
ROOM,
TUMBLE_START(EVENTTIME, INTERVAL '60' SECOND) as WINDOW_START,
TUMBLE_END(EVENTTIME, INTERVAL '60' SECOND) as WINDOW_END,
AVG(PEOPLE) as AVG_PEOPLE_COUNT,
COUNT(*) as RECORD_COUNT
FROM
people_data
GROUP BY
ROOM,
TUMBLE(EVENTTIME, INTERVAL '60' SECOND);

集計されているか、出力先の Kinesis Data Streams の中身を確認します。
%flink.ssql(type=update)
SELECT * FROM people_data_destination;
無事に 出力先 Kinesis Data Streams に連携されていることがわかります。素敵ですね。

デプロイ用の Note 作成
ここまでの手順で、正常に集計用のクエリーが動作することがわかりました。Kinesis Data Analytics のアプリケーションをデプロイ用の、新しい Note を作成します。Create new note を選びます。
適当な名前を入れて、Create を押します。
DataAggregation

次のクエリーを入力します。1 分の集計データを、Kinesis Data Streams に格納するクエリーです。
%flink.ssql(type=update)
INSERT INTO people_data_destination
SELECT
ROOM,
TUMBLE_START(EVENTTIME, INTERVAL '60' SECOND) as WINDOW_START,
TUMBLE_END(EVENTTIME, INTERVAL '60' SECOND) as WINDOW_END,
AVG(PEOPLE) as AVG_PEOPLE_COUNT,
COUNT(*) as RECORD_COUNT
FROM
people_data
GROUP BY
ROOM,
TUMBLE(EVENTTIME, INTERVAL '60' SECOND);

Studio で作成したアプリケーションのデプロイ
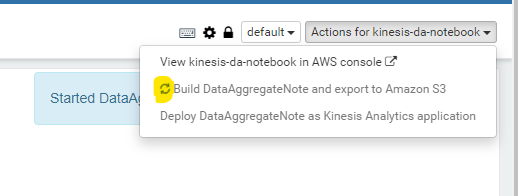
デプロイするために、まずビルドが必要です。Studio Note 上で、Build DataAggregateNote and export to Amazon S3 を選択します。

Build and export を選択します

Started となり、開始されました

ぐるぐるまわって、Build 中なことがわかります
3分ほどまつと、Build されました
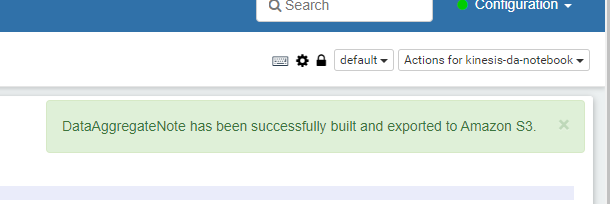
Deploy を押します

Deploy using AWS console を選択します。
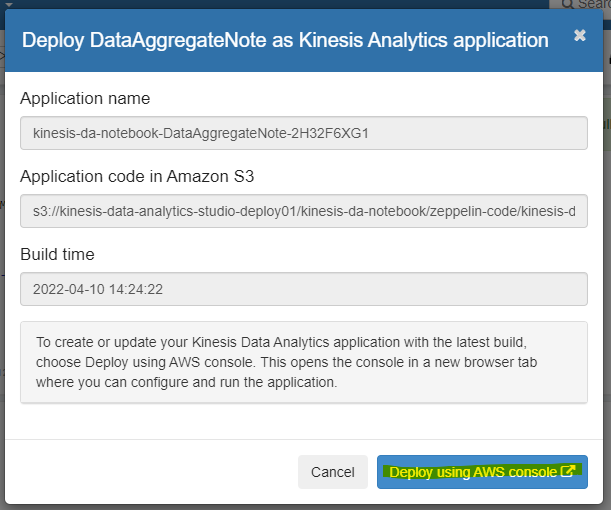
AWS マネージメントコンソールに切り替わります。Studio notebook で利用した IAM Role を指定します。
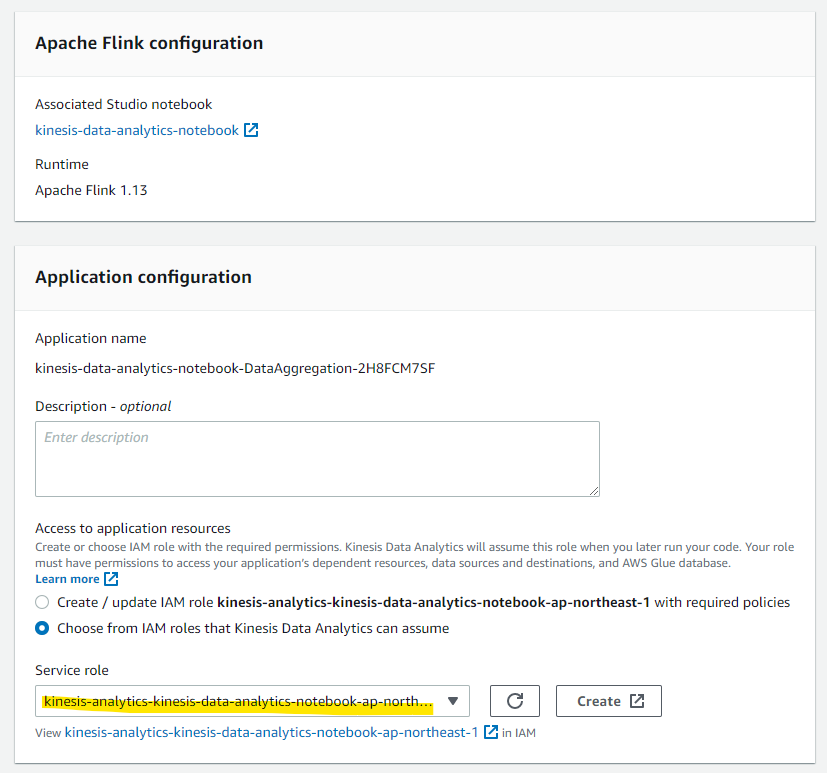
Create streaming application を押します。

Streaming Application が作成されました。
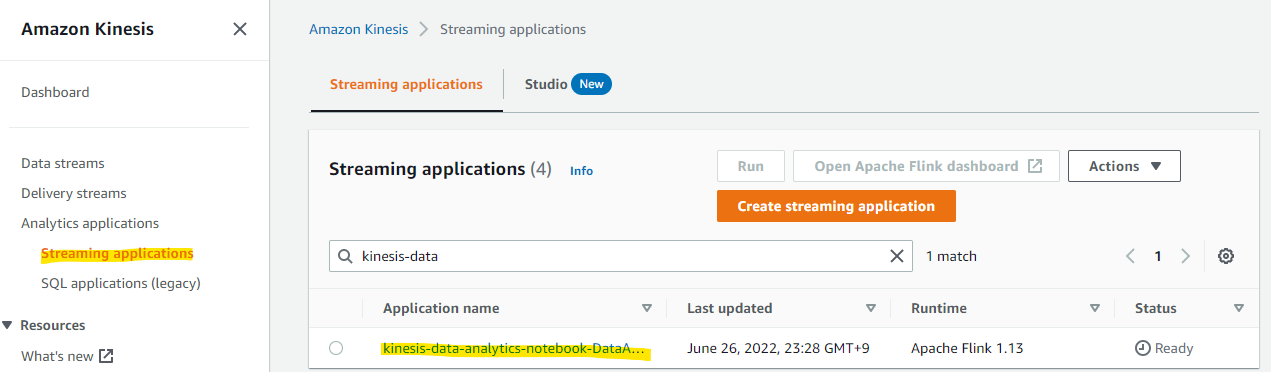
デプロイしたアプリケーションは、Run を押すことで動作開始します。

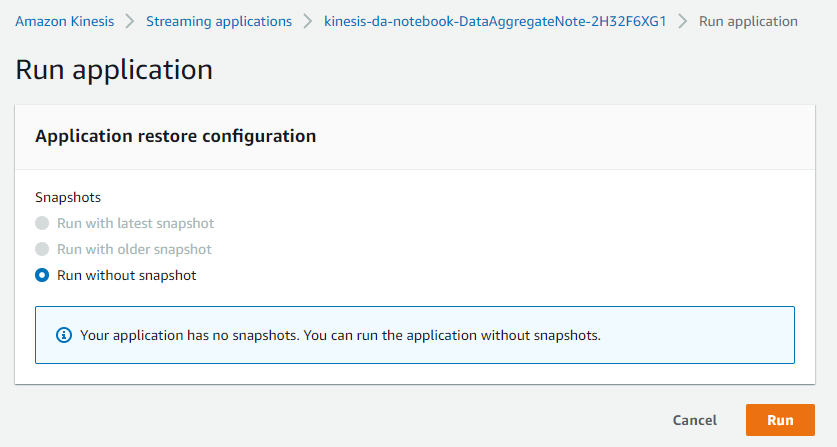
このまま Run を押します。
Running になりました。作成したアプリケーションが稼働し、自動的に IoT から流れてくるデータを 1 分おきに集計して、Kinesis Data Streams に格納してくれているはずです。

動作確認
Studio Notebook 上で、出力先の Kinesis Data Stream の内容を SELECT で確認してみます
%flink.ssql(type=update)
SELECT * FROM people_data_destination;
すると、正しく 1 分ごとのデータが出力されています!デプロイしたアプリケーションが正しく動作していることがわかりました。

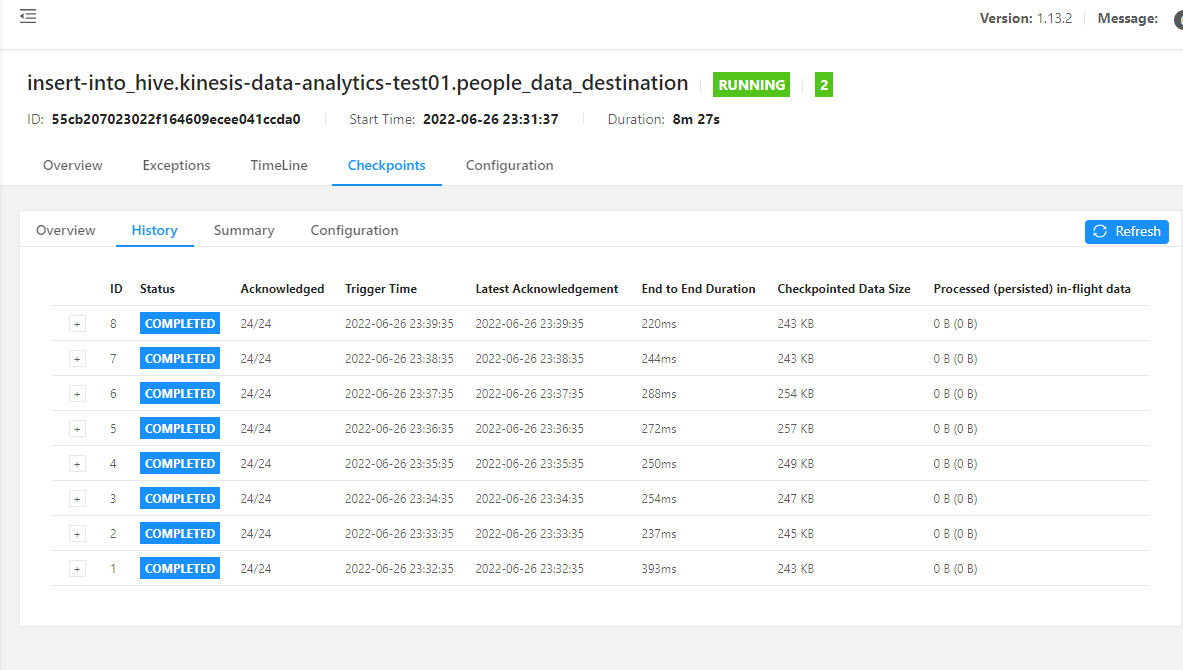
ただの興味ですが、Kinesis Data Analytics で動かしているアプリケーションで、Flink Dashboard を確認してみます。

すると、なにやら動作していることがわかります。

こんな画面が見えます

こんな画面が見えます
検証を通じてわかったこと
- Kinesis Data Analytics には、データ加工のための SQL クエリやコードを書きながら、リアルタイムに加工結果を確認できるエディターの Studio notebook が存在している
- Studio notebook で作成したコードは、Studio notebook の画面上からデプロイを進められる
- Java, Scala, Python, SQL を利用してデータ変換のコードを書ける
- 1分ごとに集計をしたときに、その期間内にデータが来なかった場合、何も処理されない
- 表現を変えると、欠損値として Null や 0 を出すようなことは難しい。その期間の 行データは生成されない
- Studio 上で、CREATE TABLE を行うと、Glue Data Catalog にテーブル定義が作成される
- Legacy SQL アプリケーションよりも、Flink 版を利用した方が良い
- 新しい Flink の SQL でも、タンプリングウィンドウやスライディングウィンドウがある
- Kinesis Data Analytics には、オートスケール機能がある。スケール条件は Document に詳細が書かれている
- CPUの使用率が75%以上の状態が15分間続くと、アプリケーションはスケールアップします
- CPU使用率が10パーセント以下の状態が6時間続くと、アプリケーションはスケールダウンします
- https://docs.aws.amazon.com/ja_jp/kinesisanalytics/latest/java/how-scaling.html
- オートスケーリングで、parallelism が変更されると、一時的にダウンタイムが発生する
- Studio Note で、同時にジョブを実行できる上限が parallelism で制限されている
- parallelism が 4 の場合は、Note 上で実行できるジョブの同時実行数が 4 になる
- Studio Note で、parallelism の上限を変更した場合、一時的に Studio Note が開けなくなるダウンタイムが発生する
- 数分のダウンタイムあり
- ダウンタイム前に実行していたジョブは、停止される
参考URL
Kinesis Data Analytics に関する AWS Blog
https://aws.amazon.com/jp/blogs/news/introducing-amazon-kinesis-data-analytics-studio-quickly-interact-with-streaming-data-using-sql-python-or-scala/
Kinesis Data Analytics の Document
Tumbling window や Sliding window のサンプルが掲載されている
https://docs.aws.amazon.com/kinesisanalytics/latest/java/how-zeppelin-sql-examples.html
Apache Flink SQL Document
SQL クエリーに関する Document
https://nightlies.apache.org/flink/flink-docs-release-1.7/dev/table/sql.html
ウォーターマークについて
一般に、ウォーターマークとは、ストリームのその時点までに、あるタイムスタンプまでのすべてのイベントが到着しているはずだという宣言である。
https://nightlies.apache.org/flink/flink-docs-master/docs/concepts/time/#event-time-and-watermarks
https://acro-engineer.hatenablog.com/entry/2017/05/11/120000
http://vishnuviswanath.com/flink_eventtime.html
https://www.oreilly.com/library/view/introduction-to-apache/9781491977132/ch04.html