はじめに
Glue Studio を使ってデータ加工のしてみたいと思います。どんなデータ加工をするのかというと、次の画像の感じです。

「部品データ」に、部品を表すコードと名前が存在しています。このコードを変換したいと思います。変換のルールは「コード変換ルール」に存在しています。この 2 つを掛け合わせて、変換後部品データを作ります。
この変換は、Glue Studio 上で JOIN で結合すると簡単に実現できます。手順を見ながらやってみましょう。
データの準備
以下の csv データを S3 Bucket に準備します。Glue Studio としては、RDS や Redshift 等でも良いですが、一番手軽に準備できる csv を用意します。
buhin.csv
buhin,name
0001,部品A
0002,部品B
0003,部品C
0004,部品D
0005,部品E
codetransform.csv
before,after
0001,aaaa
0002,bbbb
0003,cccc
0004,dddd
0005,eeee
S3 Bucket に csv データをアップロードしました。

Glue Studio データ加工フローの作成
AWS Glue の画面を開いて、Virtual ETL を選択します。

Visual with a source and target を選択して、Create を押します。
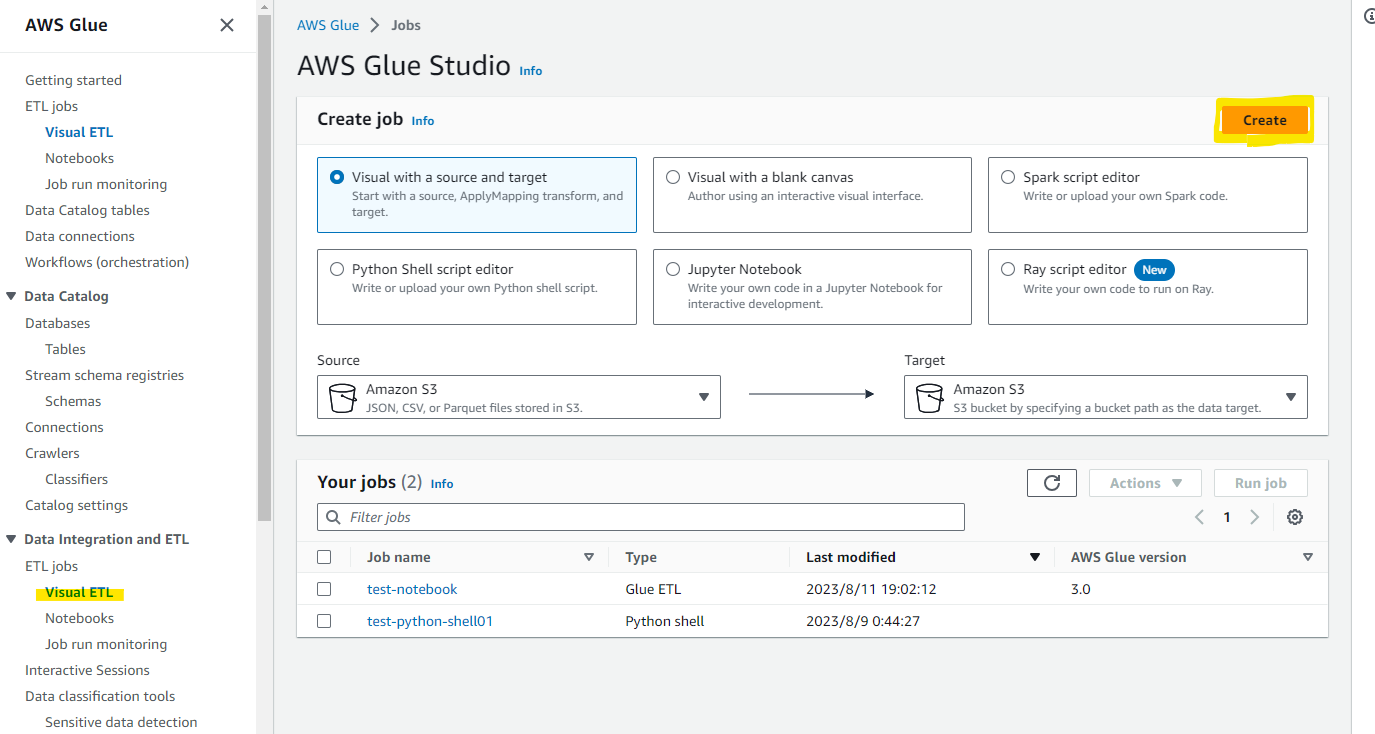
デフォルトで用意されているフローを GUI で編集する画面にきりかわりました。

データソースを定義できます。元から配置されている S3 Bucket を選択して、格納した csv データを指定します。

2 つのデータを結合したいので、+ ボタンをおします。

Data の Source から Amazon S3 を選択します。

結合したいデータを選択します。また、テンプレートで存在していた使わないボックスは削除しました。

2 つのデータを結合したいので、JOIN を選択します。

Outer Join を選択します。また、どの列を結合の条件するかも選択できます。buhin と before で結合します。

Data preview を押すと、現在のフローの結果が計算され、結合されている状況が見えます。buhin と before を結合したので、同じコードを表す列が 2 つあります。

before 列は不要なので、Drop Fields のboxを配置して、before を選択します。

Preview を見ると、before が消えました。

Rename Field で after の名前を変更します。

bufin_converted という名前に変わりました。

その後、保存する先の Target を選択します。今回は、Amazon S3 にしておきます。

保存先の csv データの詳細を指定します。csv のまま保存することもできますし、Parquet 形式などにもできます。今回はシンプルに格納します。(Partition Key を指定して格納も出来そうでした。)

Job details を選択します。

worker 数を 10 から 2 に変更します。

Save を押します。

ジョブの実行
Run ボタンを押すと、実際にジョブを実行できます。
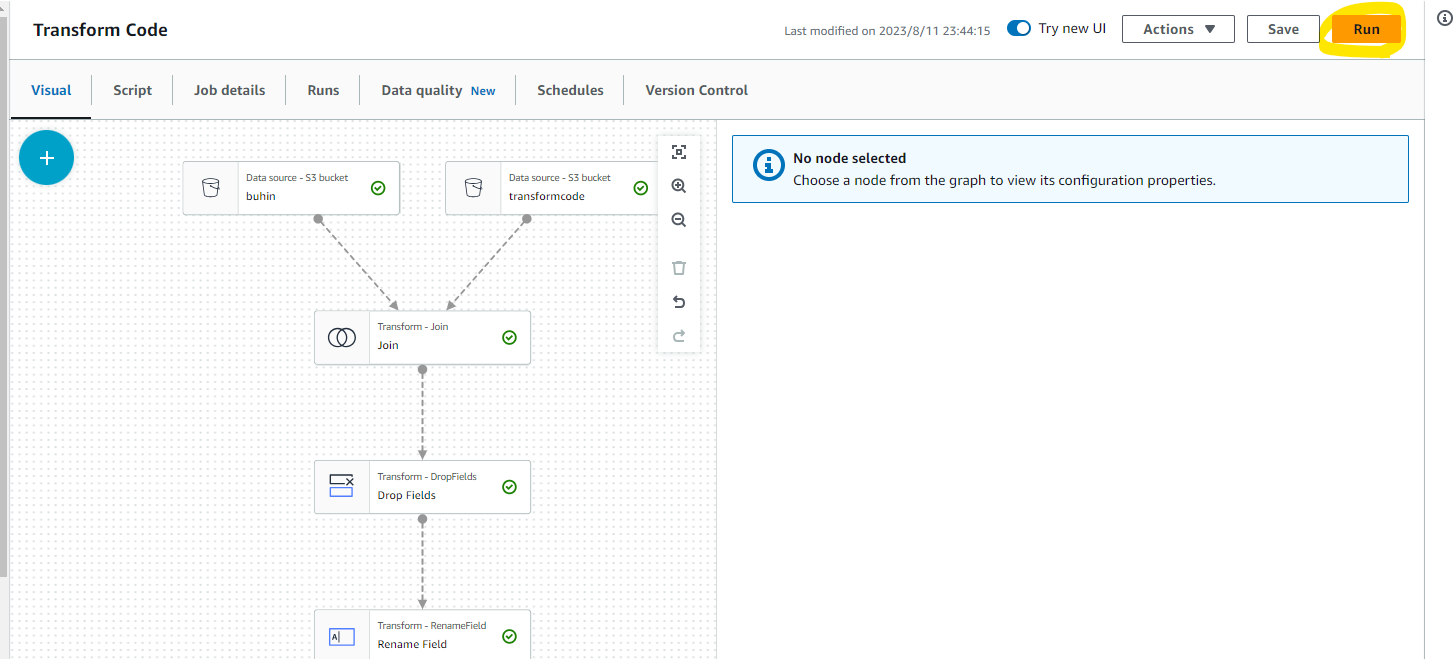
ジョブ実行の進捗具合がわかります。
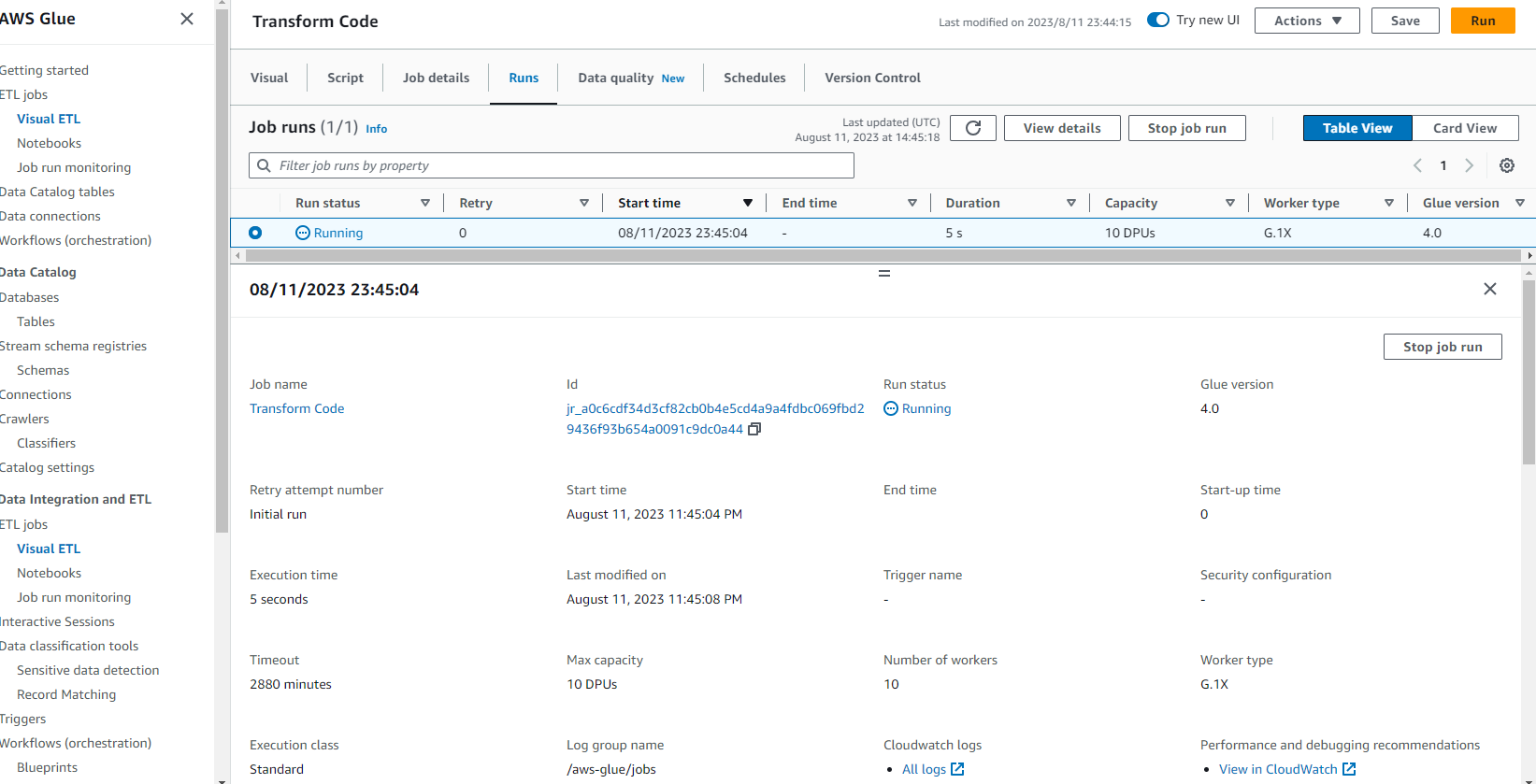
実行時間 1 分ほどで完了します。

S3 にデータ加工結果が、複数のファイルに分割されて保存されています。
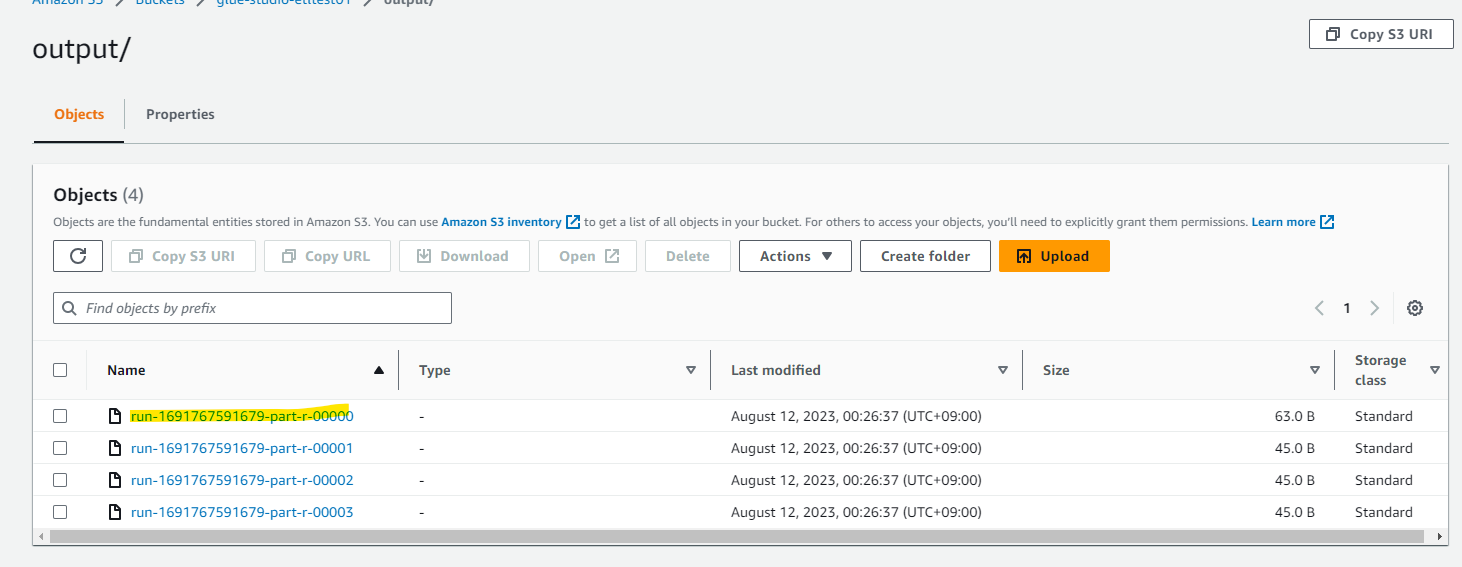
きちんと加工されていました。
