はじめに
Amazon Fraud Detector は、機械学習でオンライン不正をより早く検出するためのマネージドサービスです。機械学習に今まで触れてきてない方でも、データを用意するだけで不正検出を始められることが出来ます。新規のアカウント登録や、クーポンの発行、トランザクションの精査など、様々なユースケースで利用できるといわれています。
概要だけではどういったことがうれしいのか理解しにくいため、Getting Started で実際に触ってみました。ぜひ、みなさんも試してみてください。
やること
AWS Document に、Getting Started が公開されているので、内容を理解しながらこれを行ってみます。この Getting Started のシナリオは、「新規アカウント登録が、不正なものかどうかを検知する」ものになっています。
サンプルデータを S3 バケットに格納
AWS Document に csv サンプルデータが公開されているので、ダウンロードをします。
ダウンロードした csv ファイルには、新規アカウント登録した人の、IP アドレス、メールアドレス、住所、ブラウザの UserAgent、郵便番号、電話番号、時刻などが含まれています。また、Amazon Fraud Detector の学習方法は「教師あり学習」なので、教師ラベルが必要です。EVENT_LABEL が教師ラベルとなっており、legit が正当なデータで、fraud が不正データを示しています。
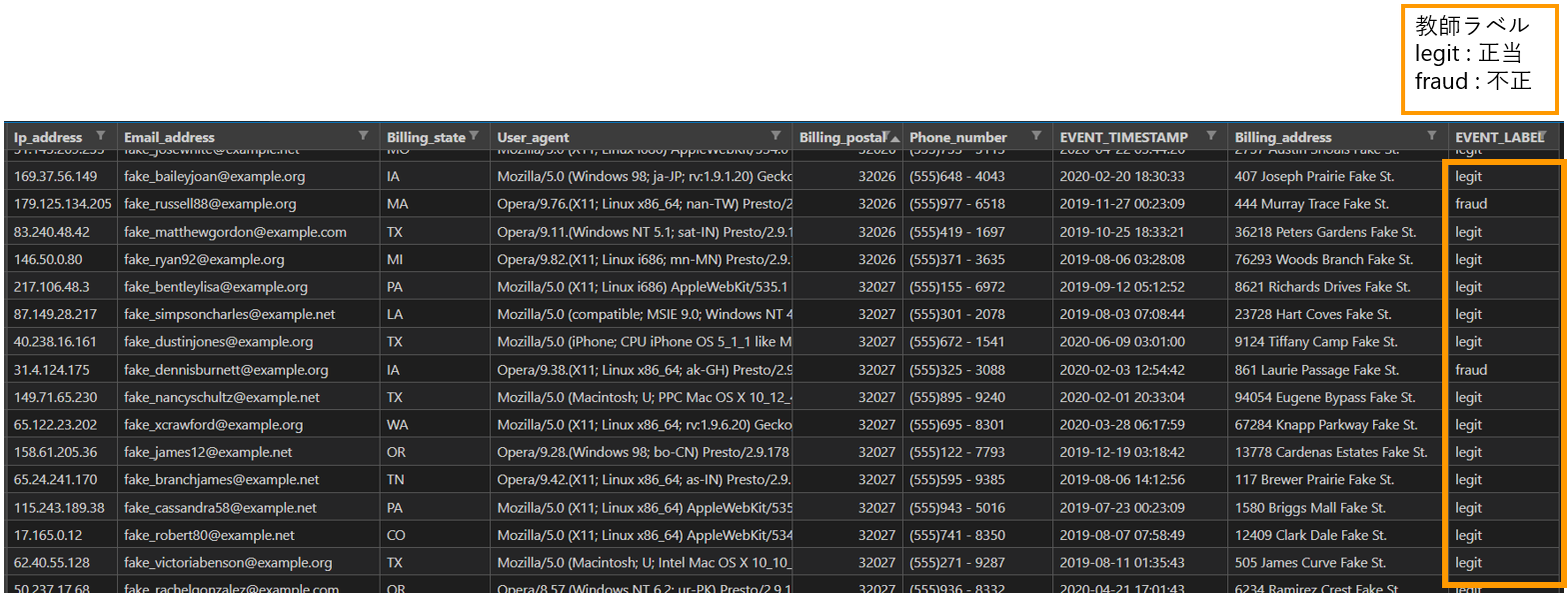
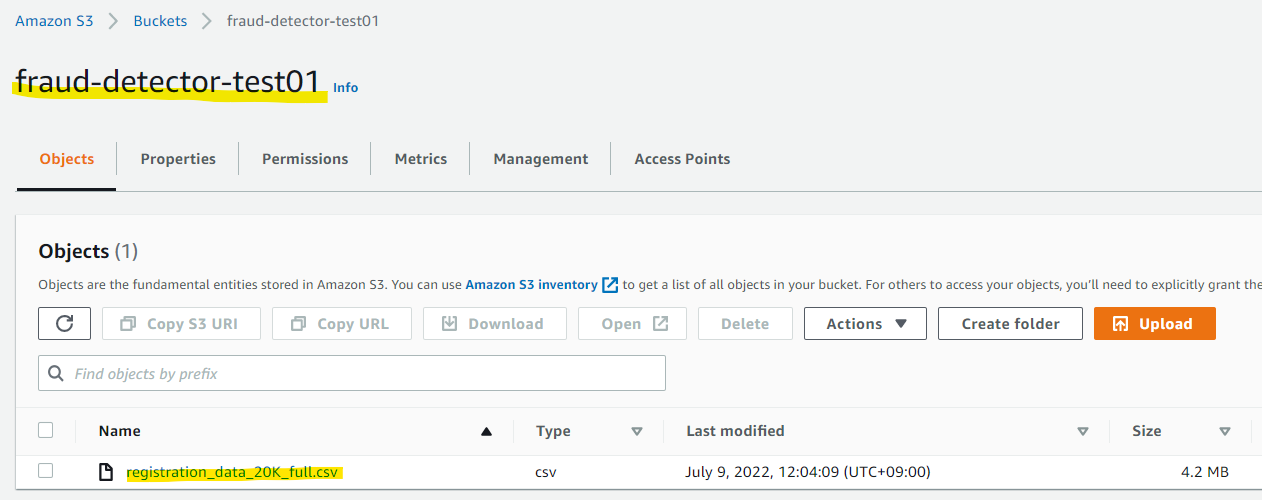
この csv ファイルを S3 バケットに格納します。
Event の作成
Amazon Fraud Detector を利用する際に、まず Event という一個の枠組みを作成します。Event は AWS Document で説明されている文章を引用すると、「イベントとは、不正リスクを評価される組織のビジネス活動のことです。Amazon Fraud Detectorは、イベントに対する不正の予測を生成します。」となっています。ざっくり表現すると、不正予測をするときの「何を不正検知の対象にするのか定義するもの」みたいなイメージでしょうか。
Amazon Fraud Detector の画面で、Event を開いて、Create を押します。
適当に名前をいれて、Create new entity を選択します。
Entity は、イベントの実行者を表現します。今回は、ユーザーによる新規アカウント登録なので、sample_customer と名前を付けます。
次に、Event variables から、Select variables from a training dataset を選択します。Event variables とは、不正を評価したいイベント (この記事だと新規アカウント登録) で利用するデータのことです。IP アドレスや、メールアドレス、住所、電話番号などが挙げられます。
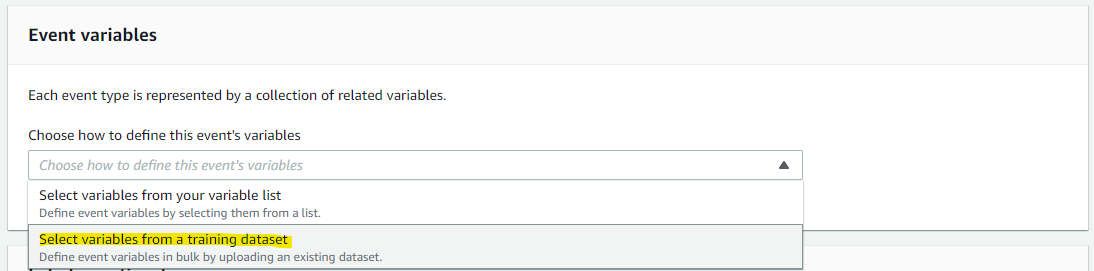
Fraud Detector が S3 からデータセットを読み取るので、それに利用する IAM Role を設定します。
サンプルデータをアップロードした、S3 Bucket の名前を指定します。
サンプルデータを選択して、Upload を押します
すると、S3 Bucket にアップロードしたサンプルデータの中身を読み取って、Event variable として認識してくれました。認識してくれた Variable の type を指定します。クリックしてみると、
Fraud Detector 側で用意されている選択肢がたくさん出てきます。それぞれ合うものを選んでいきます。
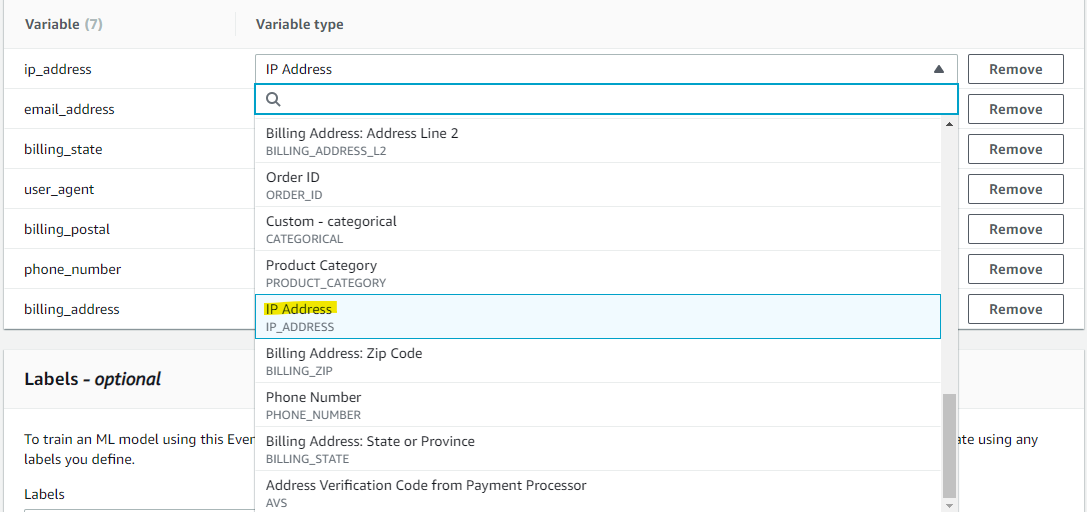
それぞれ、当てはまりそうな Variable Type を選択しました。
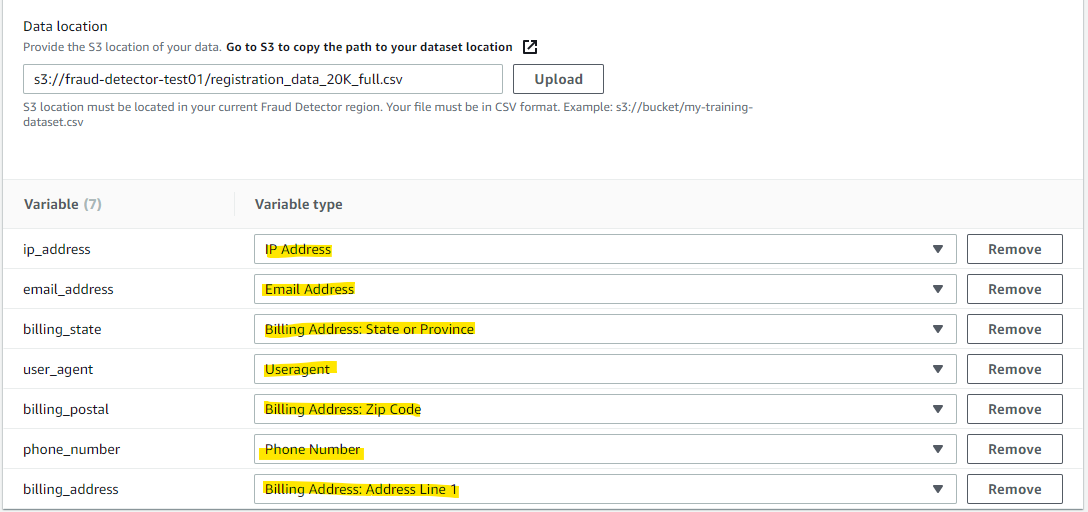
教師データにつかう Label を作成します
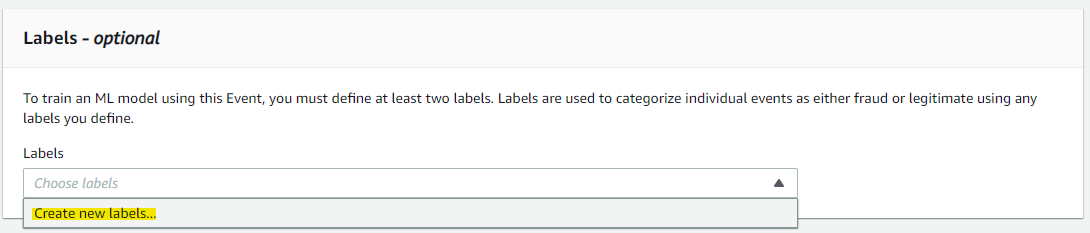
fraud を入れて、Create label を押します。
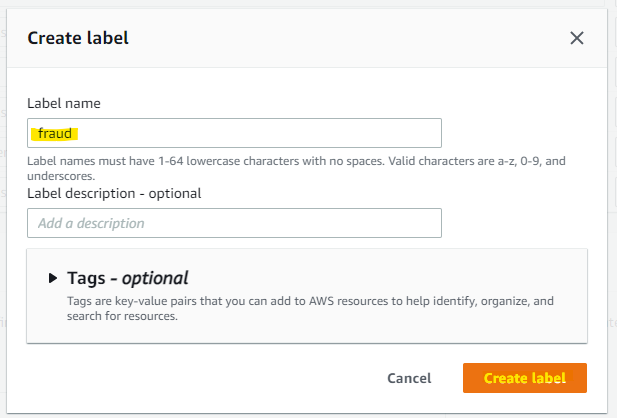
同様に legit も作成します。
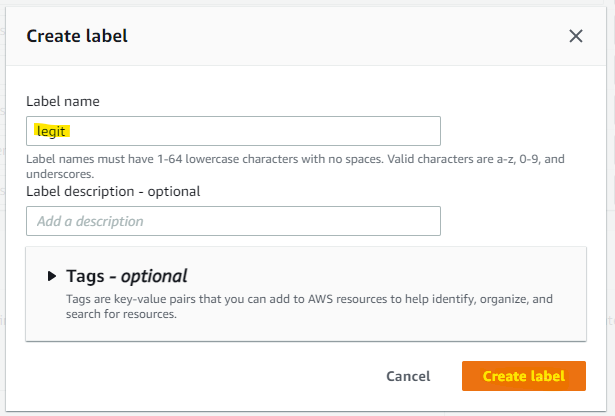
Label を作成できたので、Create event type を押します。
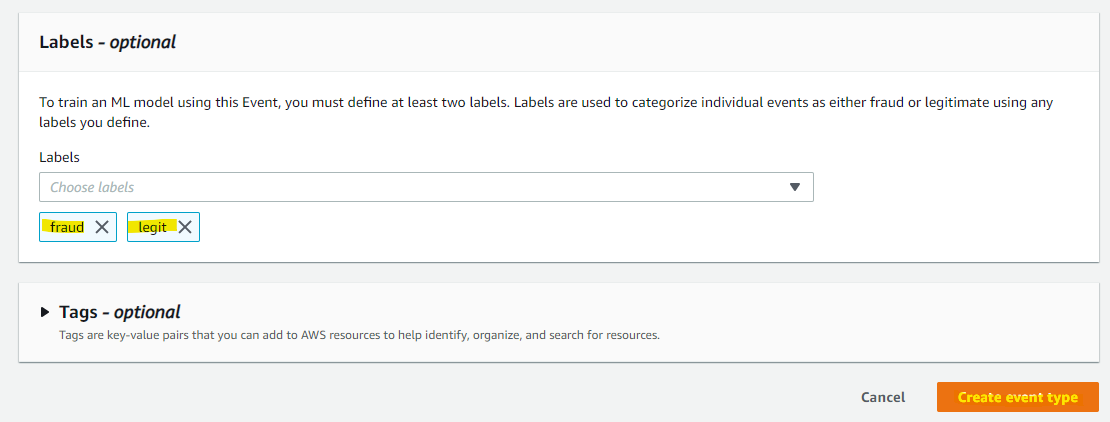
このように、sample_registration が作成できました。
Model の作成
Models のページから、Create model を選びます
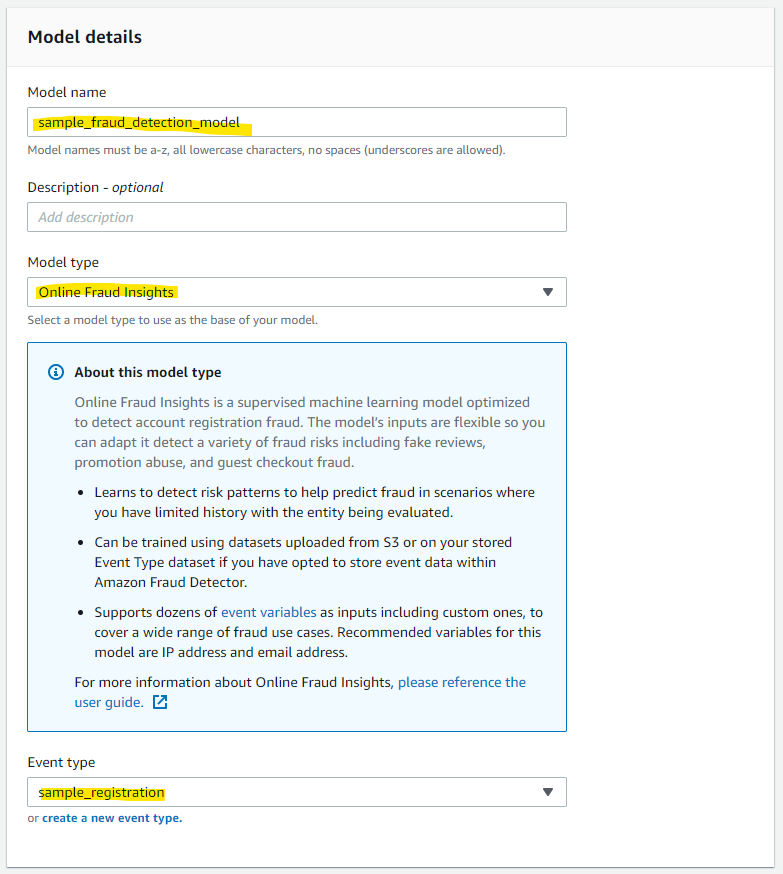
以下のパラメータを入れます。
- Model name
- Model type : Online Fraud Insights を指定します
- Event type : 先ほど作成した Event を指定します
**Online Fraud Insights **は、アカウント登録詐欺を検出するために最適化された教師ありの機械学習モデルです。このモデルの入力は柔軟で、偽のレビュー、プロモーションの不正使用、ゲストのチェックアウト詐欺など、さまざまな詐欺リスクを検出するために適応させることができます。
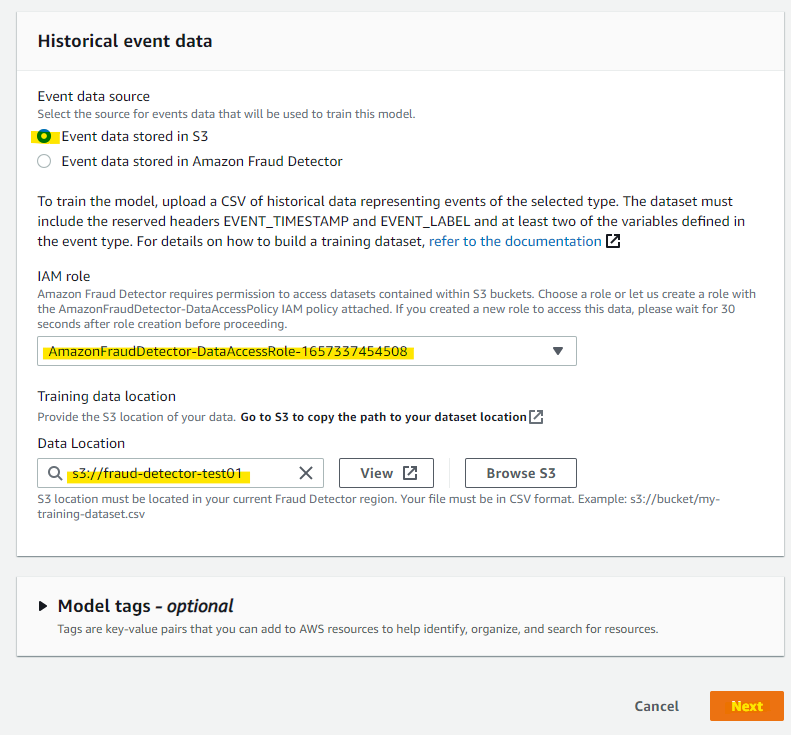
S3 に配置したサンプルデータのバケットを指定して、Next を押します
学習に利用するデータ、また、ラベルとして利用するデータを指定して、Next を選びます。
モデルのトレーニングを行います。
モデルの学習が始まりました。トレーニングは、約 45 分ほどかかります。
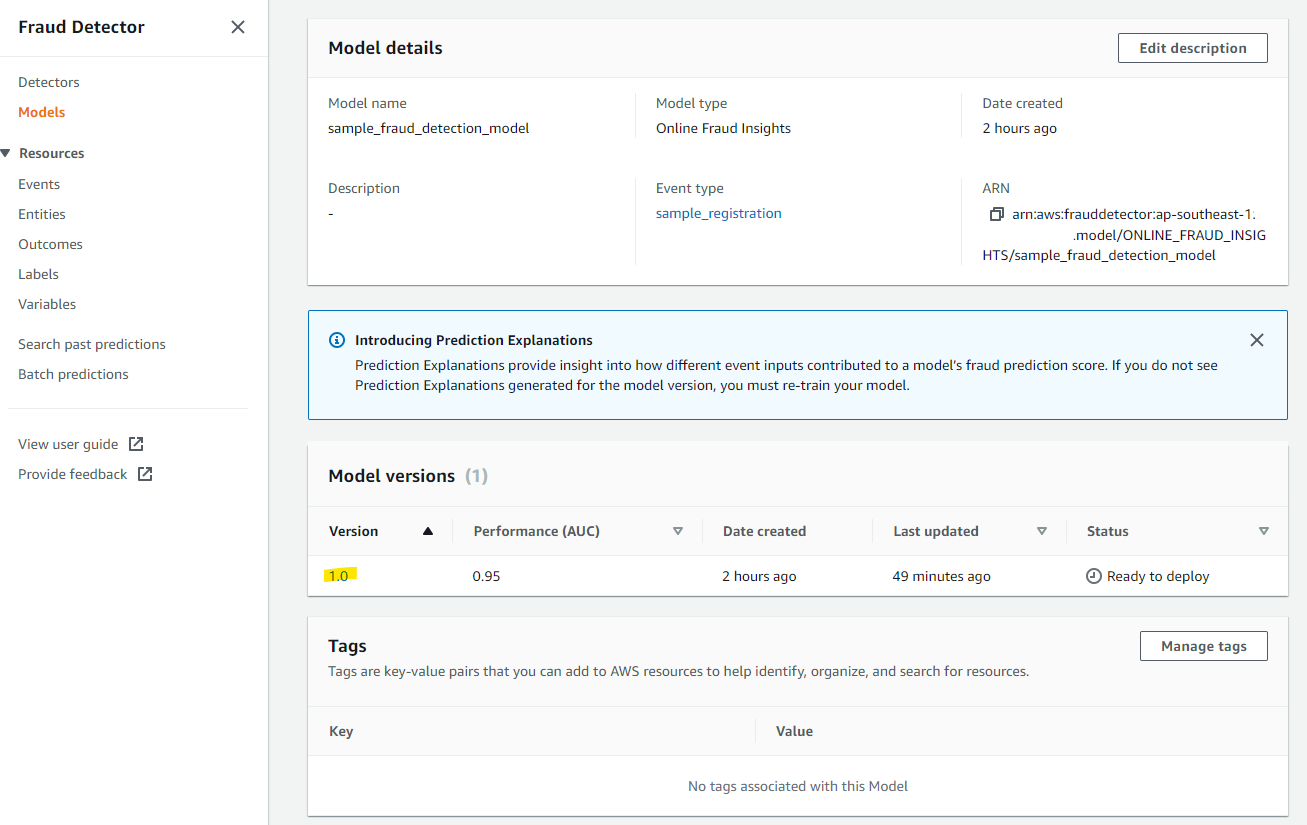
約 45 分後、Ready to deploy になりました
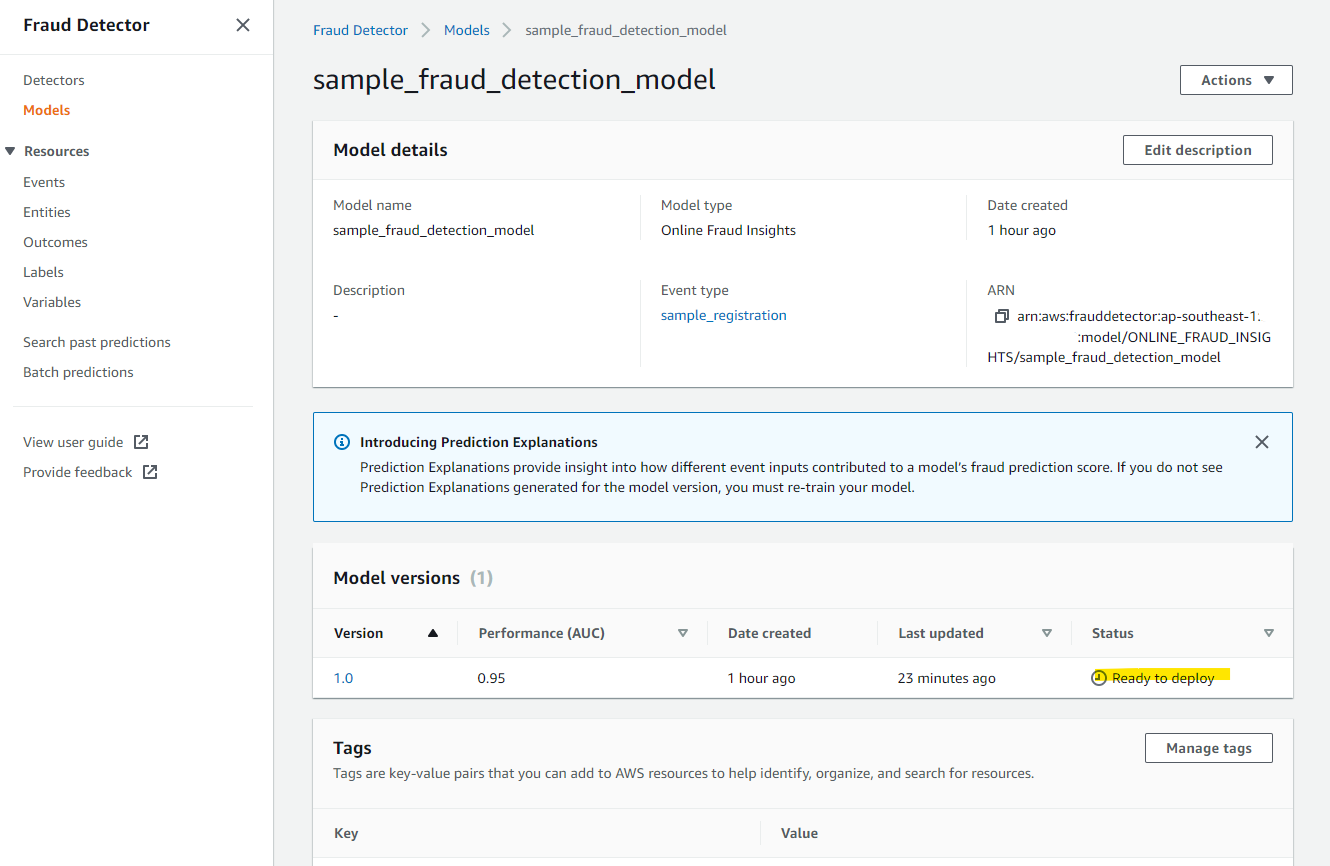
Model の評価
Fraud Detector では、トレーニングに渡したデータのうち、15 % のデータはトレーニングに使われていません。85 % のデータでモデルを学習したあとに、使っていない 15 % のデータをつかって学習モデルの評価を行ってくれています。評価データをみてみましょう。学習したモデルの Version 1.0 をクリックします。
Score distribution にヒストグラムが表示されています。横軸はモデルが評価したスコアで、縦軸がイベントの数です。緑色が正当なデータで、青色が不正なデータを表現しています。不正な青色のデータは、ヒストグラムの右側に偏っていることがわかります。なんとなく、775 以上のスコアになると、不正なデータが多くなっていることがわかります。
このヒストグラム上でクリックすることで、閾値を変更したときのシミュレーションが簡単に出来ます。例えば、下の画像のように、775 を不正検出の閾値にしてみます。
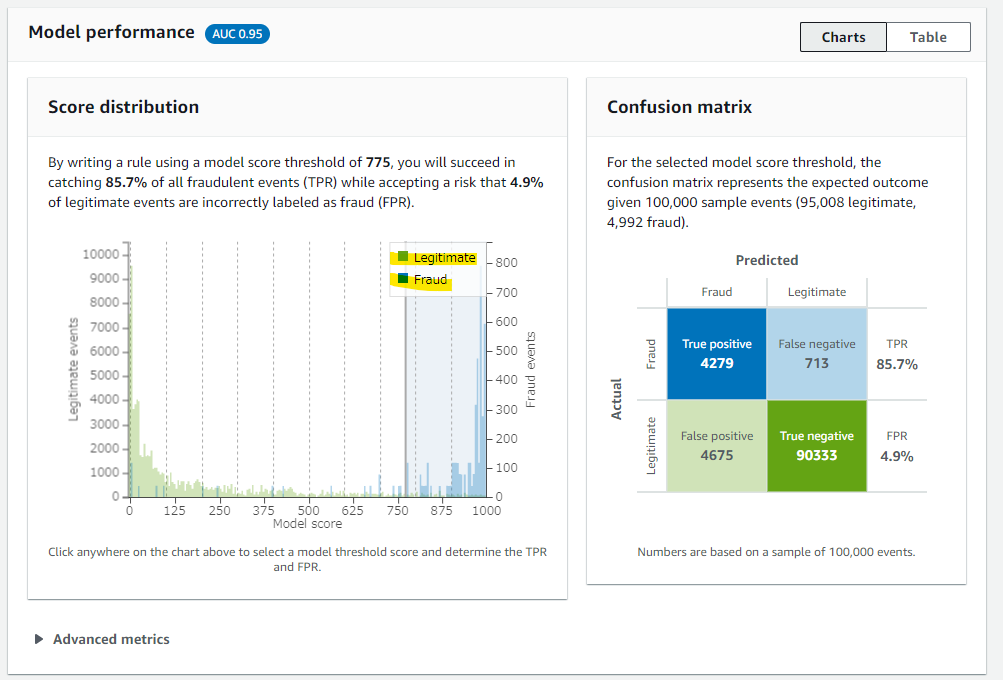
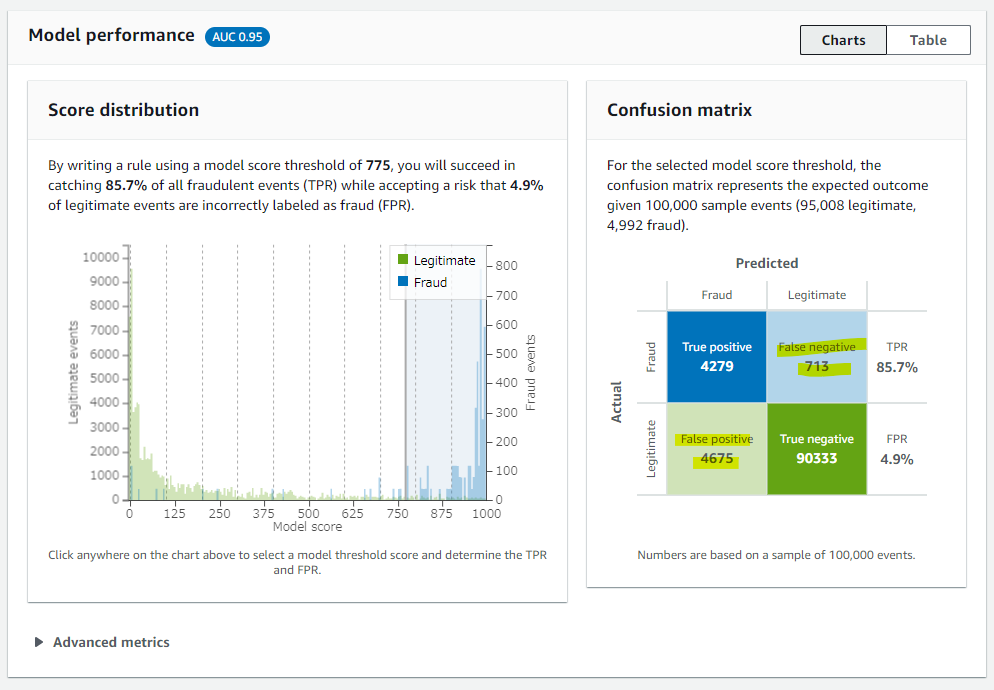
775 を閾値にしたときに、偽陽性(False Positive : 本当は正当だけど不正と判断された)・偽陰性(False Negative : 本当は不正だけと、正当と判断された) の数を動的に確認できます。775 を閾値にすると、偽陽性が 4675 で偽陰性が 713 ですね。どの閾値が最適なのかは、ビジネスの状況に応じてケースバイケースで考える内容です。陽性を検出した時に行うアクションと、偽陰性として見逃したときのコストを比較してバランスを見ながら判断する形になると思います。
今回の記事では、以下の閾値にさだめます。
- 900 以上 : 高リスク
- 775 ~ 900 未満 : 中リスク
- 775 未満 : 低リスク
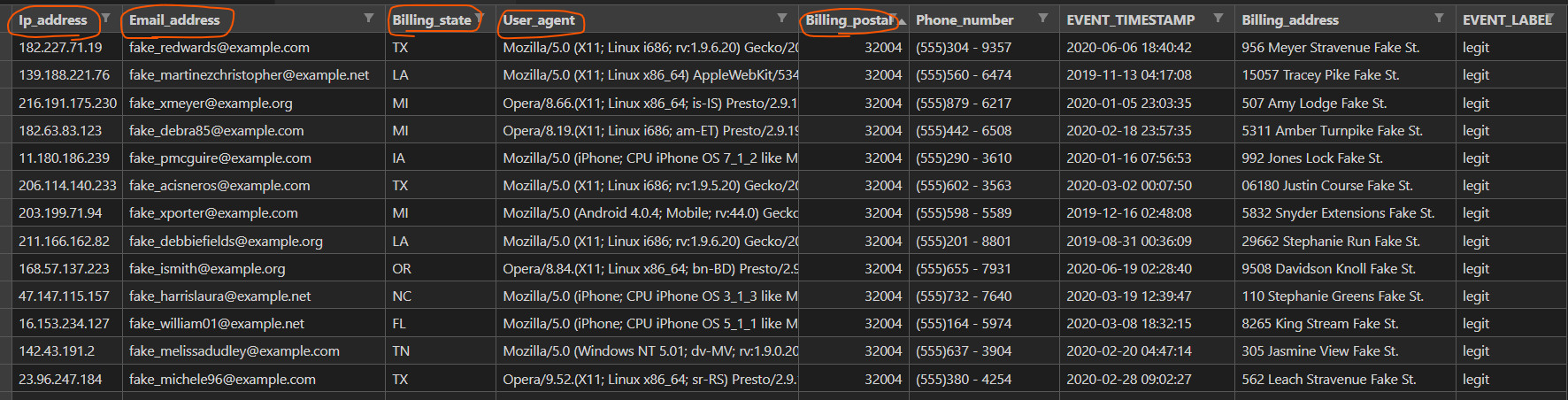
また、不正と判断するにあたって、重要だと思われる項目を評価してくれる機能があります。相対的な評価となっており、数値が高いほうが不正を判断するにあたって、重要な項目と考えられます。今回の例では、billing_state(州の名前)、billing_postal(郵便番号)、email_address, user_agent, ip_address が一定の影響を与えていそうな項目として表示されています。

この辺りのデータが不正を判断するにあたって、一定レベルで有用と判断されました。
Model のデプロイ
それでは、実際に Model をデプロイして推論を出来るようにしていきます。Deploy model version を選択します。
Deploy version を押します。
Deploy 処理が走ります。
Active に変わりました
Detector を作成
Model をデプロイしましたが、まだ推論できるわけではありません。Detector を作成し、これに Model を紐づける必要があります。
Create detector を選択します。
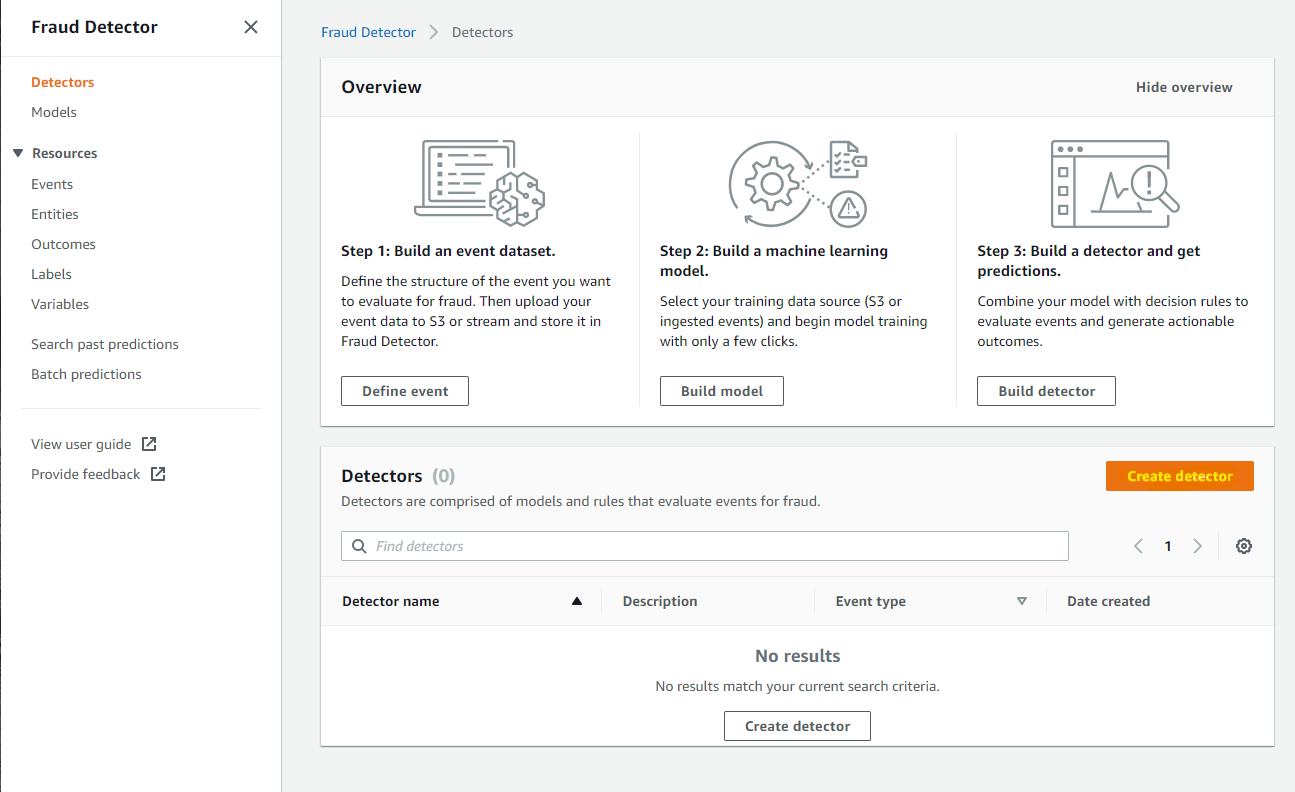
Detector name を適用なものを入力、Event Type は最初に作成したものを指定します。
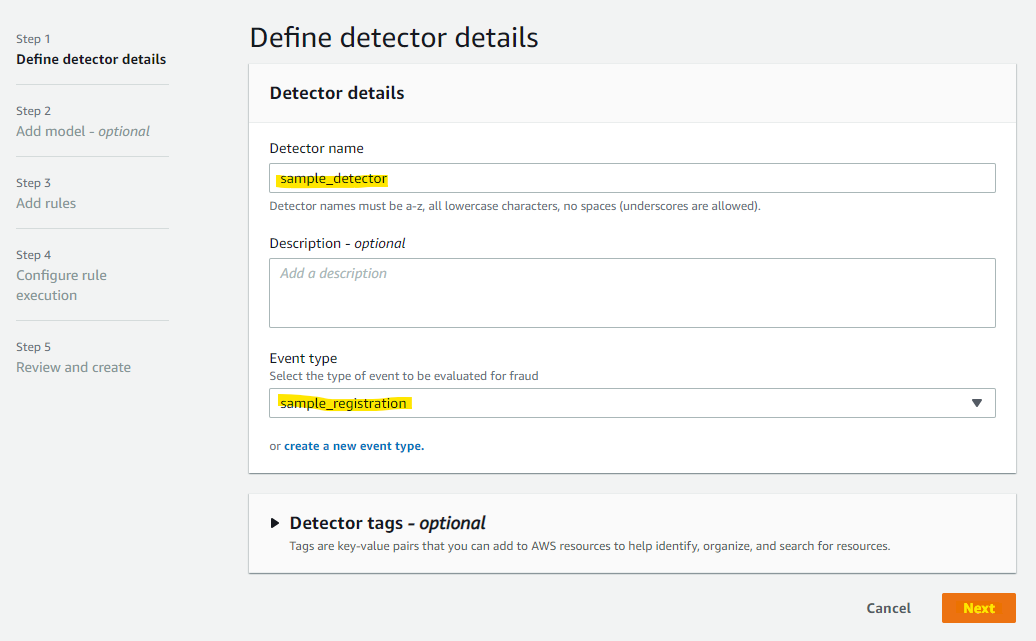
Add model を押します。
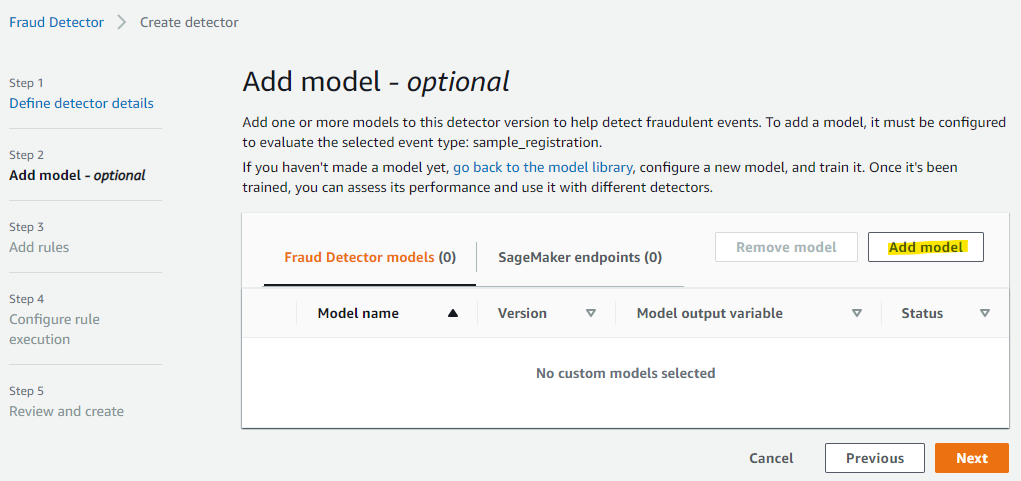
デプロイしたモデルを選択して、Add model を押します。
追加されたので、Next を押します。
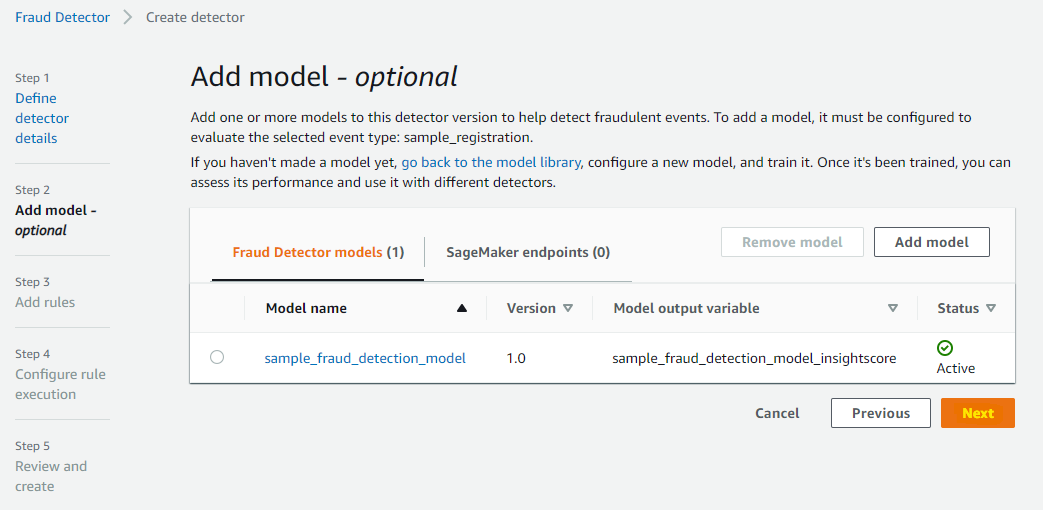
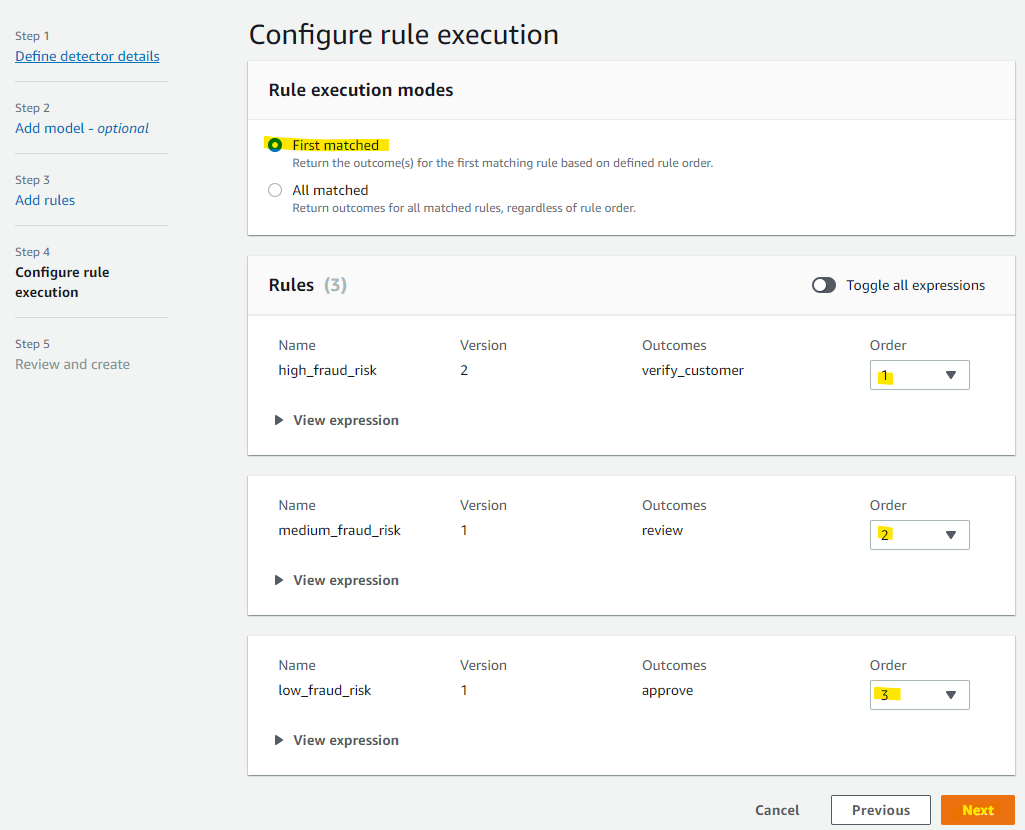
Detector のルールを決めていきます。どれくらいのスコアだったら、高リスクなのか、といった条件を指定していきます。
次のように、「900 以上のスコア」という条件を入れます。その後、Create a new outcome を選択します。
$sample_fraud_detection_model_insightscore > 900
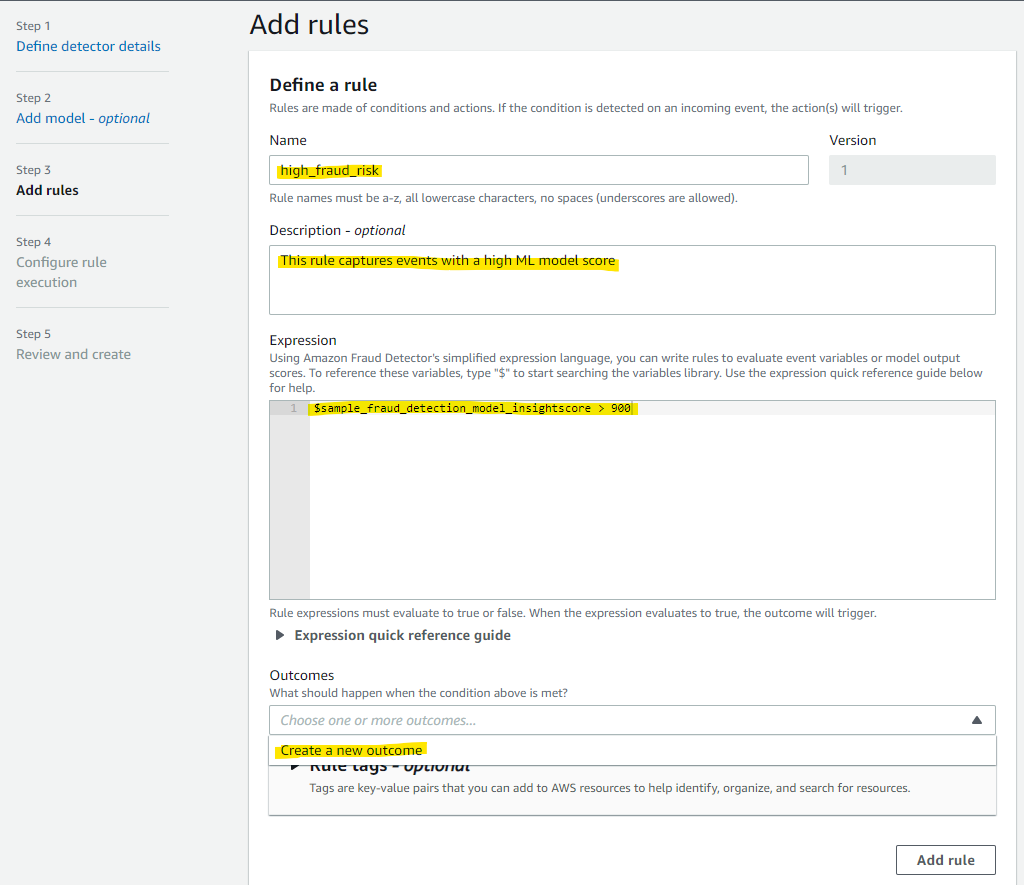
verify_customer と入力して、Save outcome を選択します。
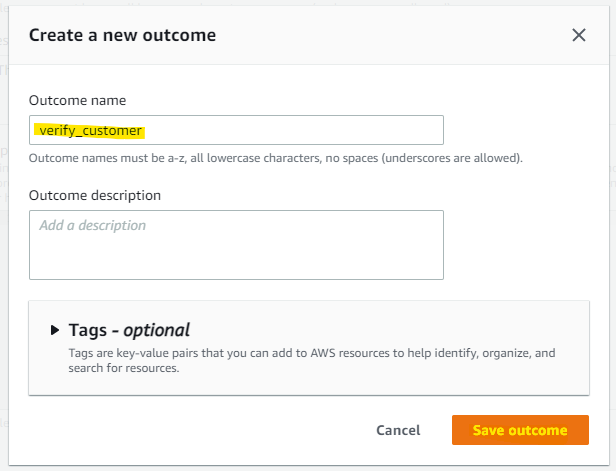
同様に次のルールを入れていきます。
-
Rule name:
medium_fraud_riskOutcome:
reviewExpression
$sample_fraud_detection_model_insightscore <= 900 and $sample_fraud_detection_model_insightscore > 775 -
Rule name:
low_fraud_riskOutcome:
approveExpression:
$sample_fraud_detection_model_insightscore <= 775
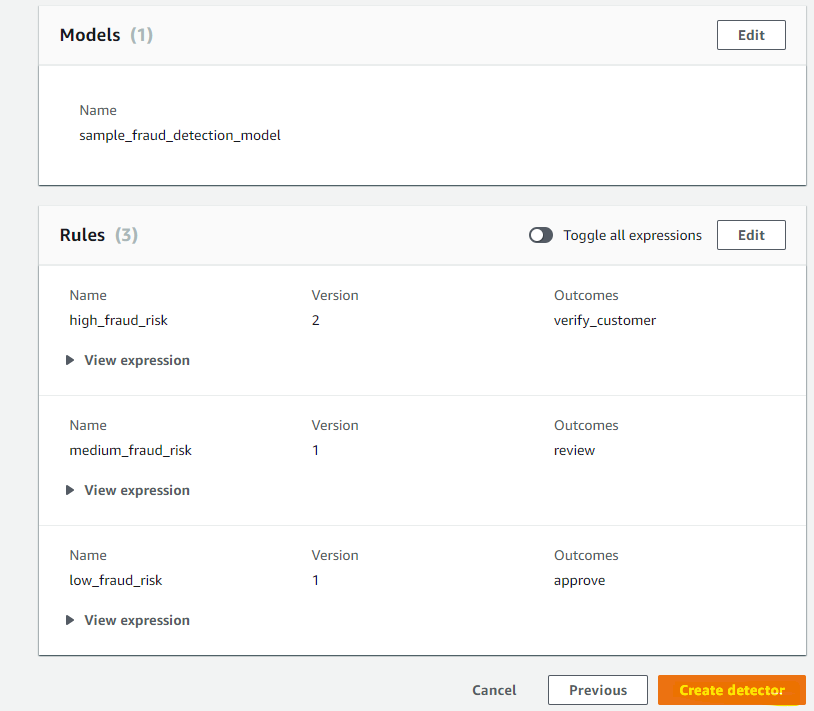
3 つのルールが出来たので、Next を押します。
ルールの優先度に関する設定です。一致したルールがあったときに、それ以降のルールを評価するかどうかを指定します。今回は、リスクが高い順で評価し、一致したルールがあったらそれで終わりにします。
Create detector を押します。
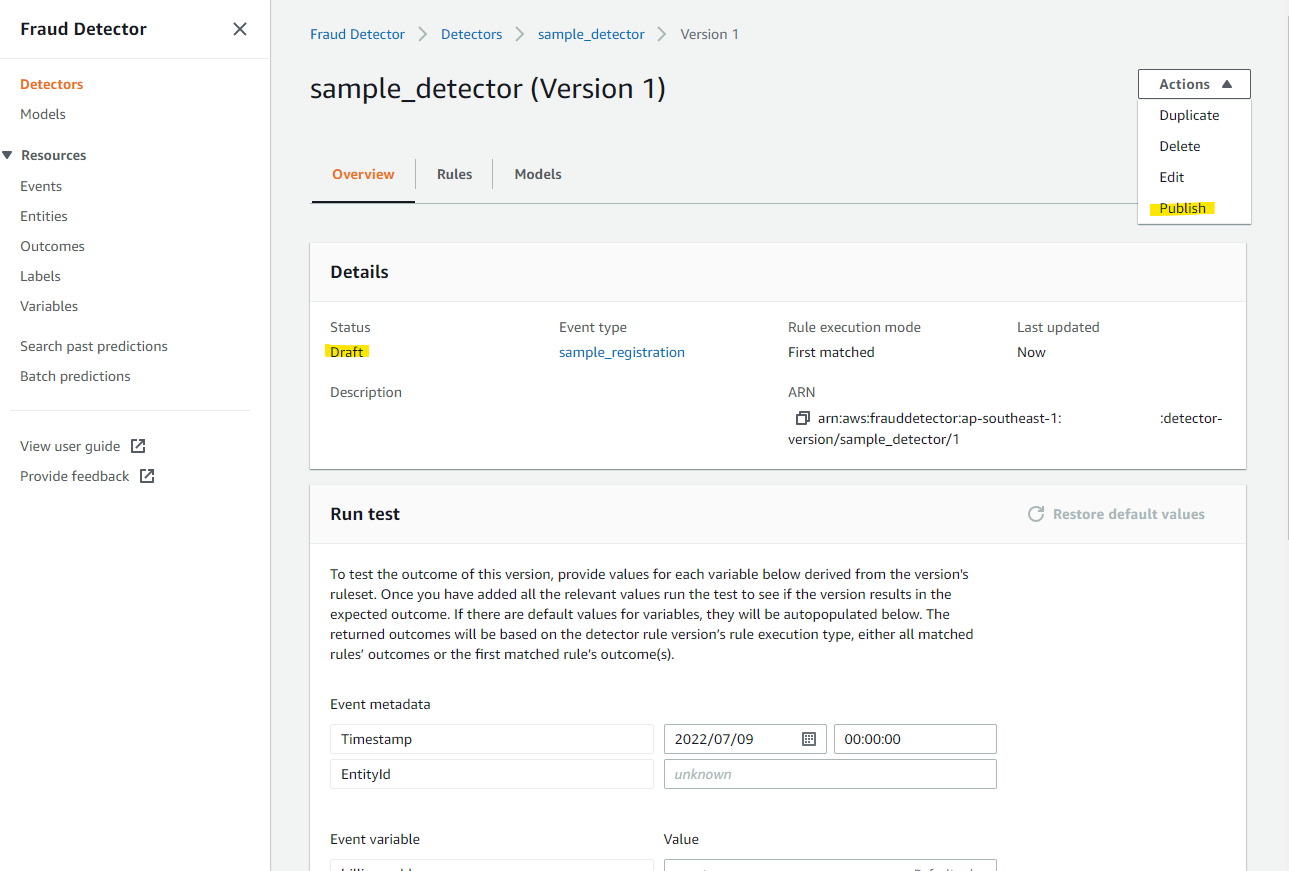
Detector の Publish
Detector が作成できました。Status が Draft になっているので、Publish を押して公開します。
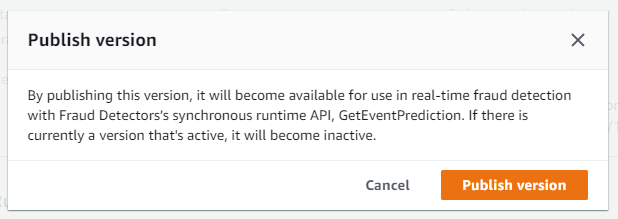
Publish version を押します。
推論を行う
これで公開できました。AWS マネージメントコンソール上で、推論を実際に行うことができます。
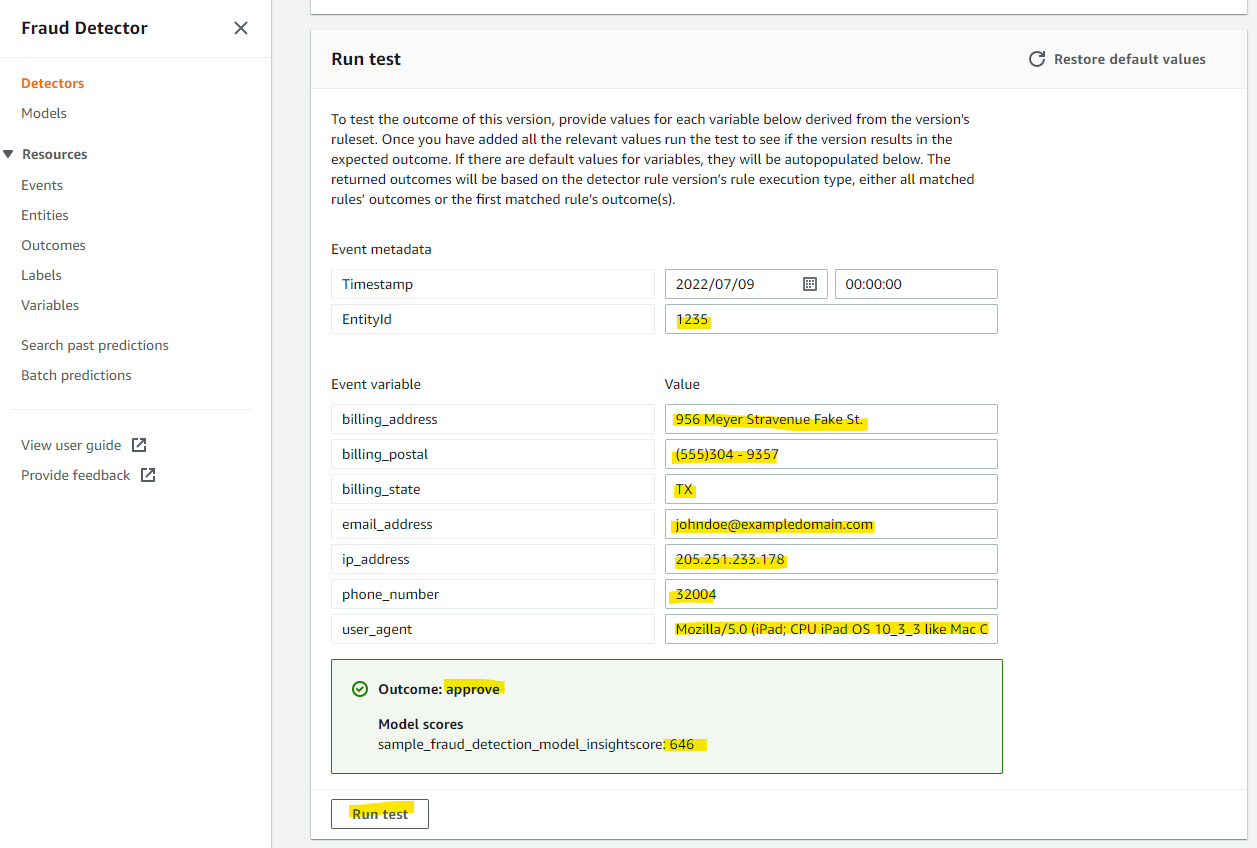
次のデータを入れて、Run test をしてみます。
1234
956 Meyer Stravenue Fake St.
(555)304 - 9357
TX
johndoe@exampledomain.com
205.251.233.178
32004
Mozilla/5.0 (iPad; CPU iPad OS 10_3_3 like Mac OS X) AppleWebKit/532.2 (KHTML, like Gecko) CriOS/34.0.827.0 Mobile/13K063 Safari/532.2
このように、結果とスコアが表示されます。こちらの入力データは、646 なので、Approved として評価されました。
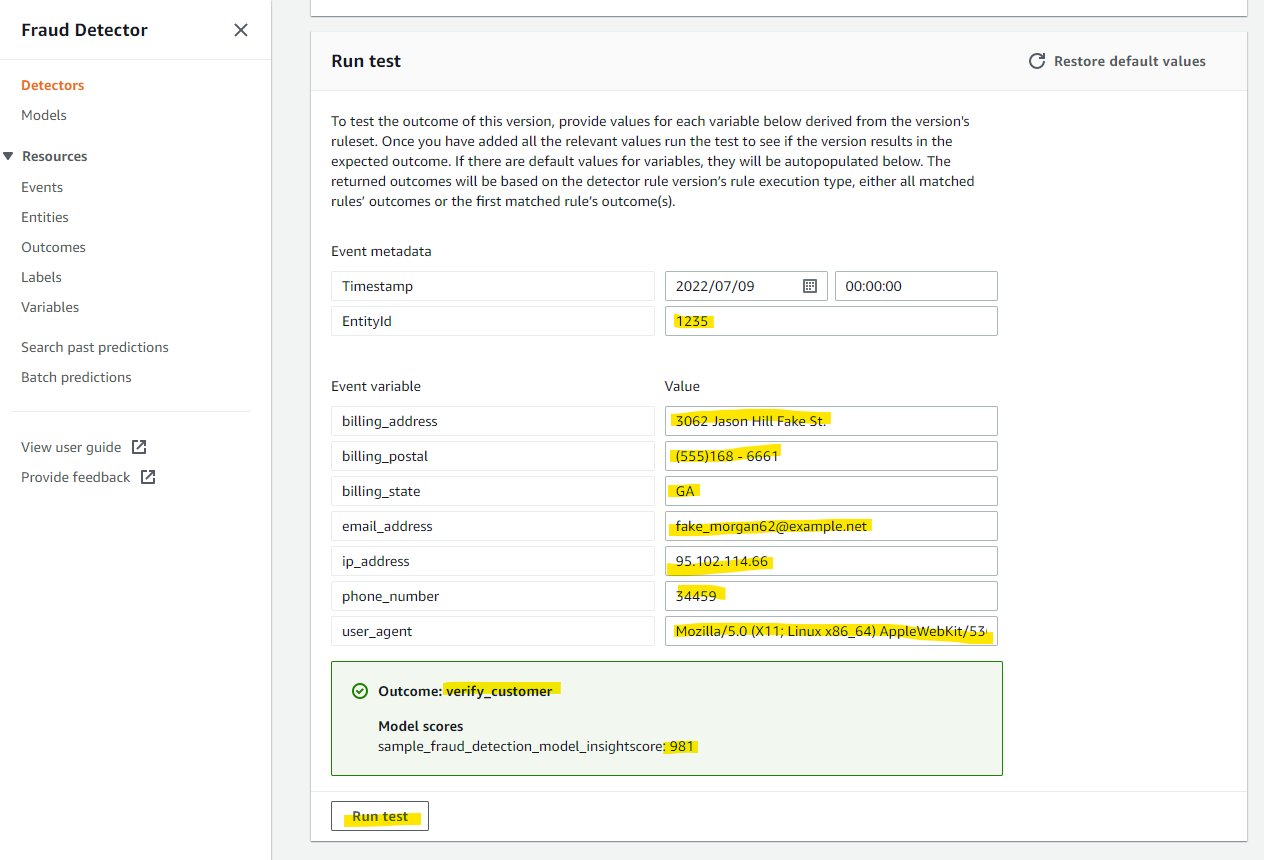
他のデータも入れてみます。
1235
3062 Jason Hill Fake St.
(555)168 - 6661
GA
fake_morgan62@example.net
95.102.114.66
34459
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.2 (KHTML, like Gecko) Chrome/55.0.881.0 Safari/536.2
こちらの結果では、Score が 981 となっており、高リスクと判断されました。
Python から推論を行う
もちろん、SDK を使って推論を行うこともできます。Python のサンプルコード があり、これを参考に組み立てました。
- Region は、シンガポールリージョンを指定 (東京や大阪は、2022年7月現在、 Fraud Detector が提供されていない)
- Entity などのデータを渡して、レスポンスを print している
import boto3
import json
fraudDetector = boto3.client(
'frauddetector', region_name="ap-southeast-1") # Singapore Region
response = fraudDetector.get_event_prediction(
detectorId='sample_detector',
eventId='802454d3-f7d8-482d-97e8-c4b6db9a0428',
eventTypeName='sample_registration',
eventTimestamp='2022-07-09T00:00:00Z',
entities=[{'entityType': 'sample_customer', 'entityId': '1234'}],
eventVariables={
'billing_address': '956 Meyer Stravenue Fake St.',
'billing_postal': '33359',
'billing_state': 'GA',
'email_address': 'fake_morgan62@example.net',
'ip_address': '95.102.114.66',
'phone_number': '(555)304 - 9357',
'user_agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.2 (KHTML, like Gecko) Chrome/55.0.881.0 Safari/536.2'
}
)
print(json.dumps(response, indent=4))
これを実行してみます
python detect-test.py
実行例
- score が 981.0 と返ってきている
- ruleResults が、verify_customer と返ってきている
- 呼びだし元のアプリケーションで、スコアとルール評価結果の両方のデータが取得できるので、あとはアプリケーション側で好きなようにコントールできる
- 東京リージョンの EC2 から、シンガポールリージョンの推論を呼びだしたときのレスポンスタイムは、100回ほど試したら、 890 ミリ秒前後で収まっていた。リアルタイムの処理に組み込むのも、クリティカルな問題にはななそう。また、非同期に推論を行う方法もアリだと思われる。
{
"modelScores": [
{
"modelVersion": {
"modelId": "sample_fraud_detection_model",
"modelType": "ONLINE_FRAUD_INSIGHTS",
"modelVersionNumber": "1.0"
},
"scores": {
"sample_fraud_detection_model_insightscore": 981.0
}
}
],
"ruleResults": [
{
"ruleId": "high_fraud_risk",
"outcomes": [
"verify_customer"
]
}
],
"ResponseMetadata": {
"RequestId": "33a88e3c-b5ab-4461-9881-812ad25faa32",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"date": "Sat, 09 Jul 2022 11:23:54 GMT",
"content-type": "application/x-amz-json-1.1",
"content-length": "303",
"connection": "keep-alive",
"x-amzn-requestid": "33a88e3c-b5ab-4461-9881-812ad25faa32"
},
"RetryAttempts": 0
}
}
検証を通じてわかったこと
- Fraud Detector のサポートリージョンに、東京や大阪がない。サポートしている他のリージョンに、蓄積したデータを持っていき、モデルを学習して、日本から推論を呼びだす方式が考えられる
- シンガポールリージョンなど
- 東京からシンガポールリージョンの推論を呼びだしたとき、だいたい 890ミリ秒前後となった
- 用意するデータについて
- csv データ (UTF-8)
- 最低でも、1万行のデータが必要
- そのなかには、不正と分類している400行のデータと、正当と分類している400行のデータが含まれている必要がある。
- 期間は、最低でも3週間分。長くて 6か月のデータが推奨
- NULL が許容される列もあるが、NULL が多すぎると精度に影響を与えるので、あまりない方がいい
- https://docs.aws.amazon.com/frauddetector/latest/ug/create-event-dataset.html
- 用意するデータのカスタマイズ
- 学習に使うデータには、不正判断に利用できると考えられる任意のデータを追加できる
- メールアドレス、電話番号、住所、IP アドレス、Useragent など
- https://docs.aws.amazon.com/frauddetector/latest/ug/create-event-dataset.html
- ユースケースに合わせて、2 つのモデルタイプを選択できる
- Online Fraud Insights : 不正検知を行いたい対象の、過去のデータが存在しない場合に最適化されている。例えば、新規のアカウント登録など。勾配ブースティング(gradient tree boosting) が使われているとのこと。
- Transaction Fraud Insights : 不正検知を行いたい対象の、過去のデータが存在する場合に最適化されている。例えば、既存顧客で過去の購入履歴がある場合など。勾配ブースティング(gradient tree boosting) が使われているとのこと。
- https://docs.aws.amazon.com/frauddetector/latest/ug/choosing-model-type.html
- Online Fraud Insights について
- 数十の学習データ変数 (Event variables) がサポートされている。IP アドレスと電子メールは効果的なので、学習データに含めるとよい。
- Transaction Fraud Insights
- 数十の学習データ変数 (Event variables) がサポートされている。IPアドレス、電子メールアドレス、支払手段タイプ、注文価格、およびカードBINを含めることをお勧めします。
- Fraud Detector には、2 種類のストレージ領域をサポートしている
- 外部ストレージ : S3
- 内部ストレージ : Fraud Detector 内部に保存される。GetEventPrediction や SendEvent API を使用して、内部ストレージに保存または更新することができる。または、バッチインポート機能を使用して大きなデータセット(最大1GB)をインポートすることができる。
- https://docs.aws.amazon.com/frauddetector/latest/ug/storing-events-sendevent-api.html
- 検出のスコアは、0~1000 までで評価される。このスコアの意味は、偽陽性 (false positive) の割合を示している。この詳細は Document を参照。
- 学習したモデルの評価について。
- 学習として渡したデータの 15 % は学習に使用せず、検証として利用されます。詳細はこちら、
- https://docs.aws.amazon.com/frauddetector/latest/ug/training-performance-metrics.html
- 学習データの中で、不正判断として使えるデータなのか、ただのノイズデータなのかを評価してくれる Model variable importance 機能がある。
- 0.00 ~ 10.00 の範囲で相対的な重要度が評価される
- 他のデータと比べて、あまりにも高い数値が出ている場合は過学習の可能性もあるので、その項目に対するビジネス上の状況をみながら、都度判断すると良いと考えられる
-
https://docs.aws.amazon.com/frauddetector/latest/ug/model-variable-importance.html

- https://docs.aws.amazon.com/frauddetector/latest/ug/model-variable-importance.html
参考 URL
Fraud Detector Getting Started
https://docs.aws.amazon.com/frauddetector/latest/ug/get-started.html
Amazon Fraud Detectorが本日GAになりました!
https://dev.classmethod.jp/articles/amazon-fraud-detector-ga/
データセットについて
https://docs.aws.amazon.com/frauddetector/latest/ug/create-event-dataset.html
コアコンセプトについて。Event Type などの用語の説明が書かれている
https://docs.aws.amazon.com/frauddetector/latest/ug/frauddetector-ml-concepts.html