初めに
こんにちは。すぎもんです![]()
以前、「Azure OpenAI On Your Dataを使ってみた」という記事を書きました。
Azure OpenAI On Your DataとHULFT Squareの連携は、企業が所有する社内システムにある非公開データをChatGPTのような高度な言語モデルと組み合わせることで企業のデータ活用とAI導入を革新的に進化させる可能性を秘めています。この組み合わせにより、社内データをRAGとして蓄積させAIに必要な情報だけを抽出させ社内の他のSaaSや異なるサービス、システムと連携させることが可能になります。
そこで今回は、Azure OpenAI On Your DataとHULFT Squareの連携方法をご紹介し実際に動かしてみるところまで詳しく解説します。この連携により、企業のデジタルトランスフォーメーション(DX)をさらに加速させ、データドリブンな意思決定を支援する強力なツールとなることが期待できます。
今回やること
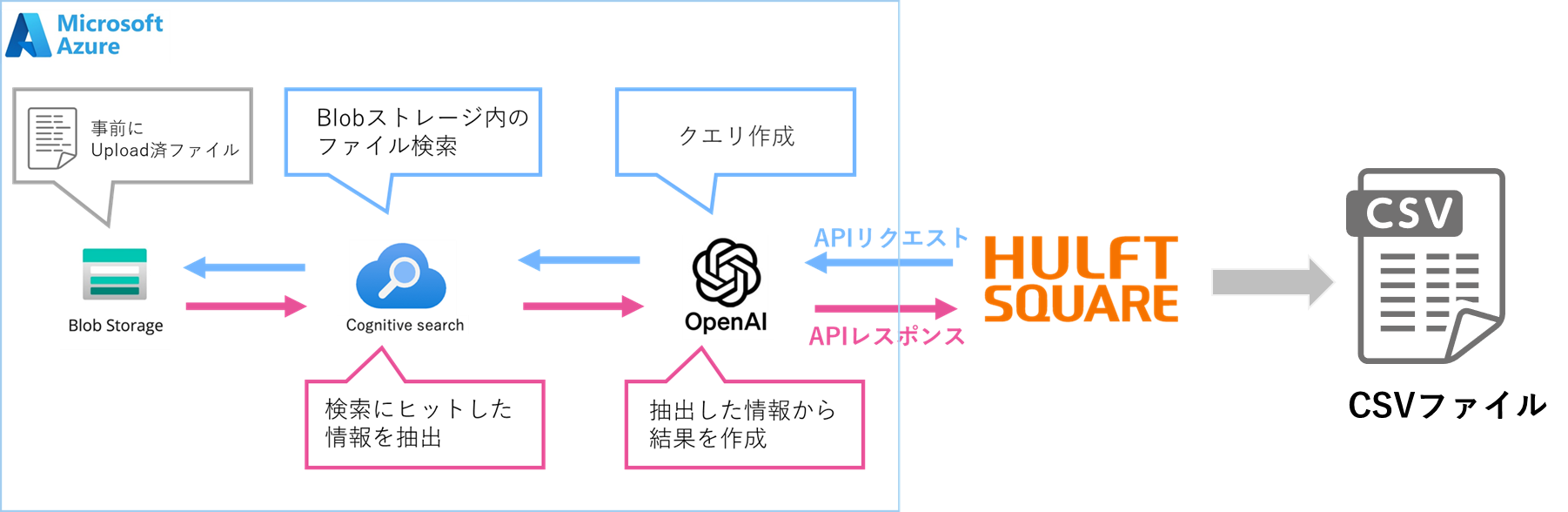
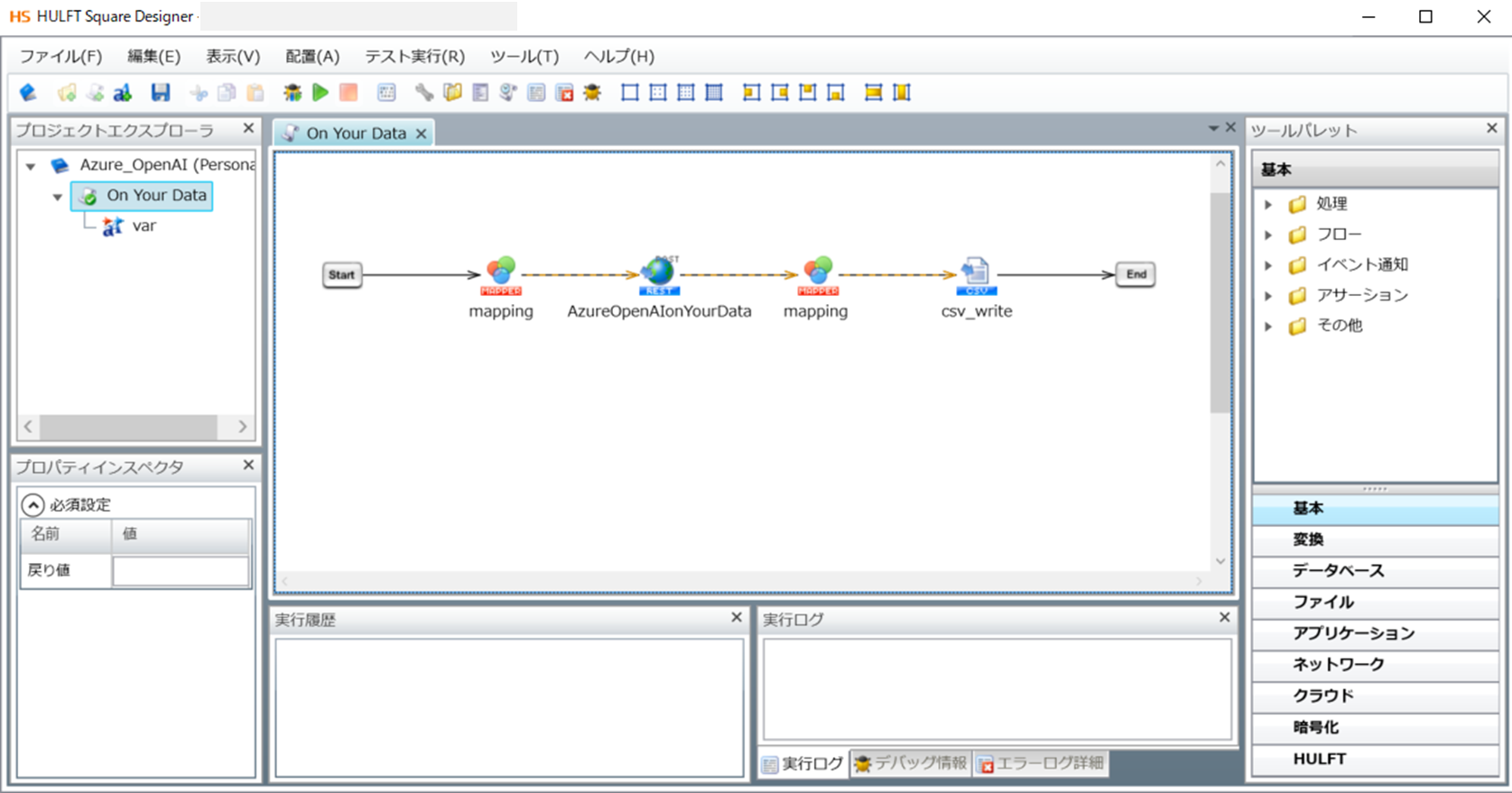
実施するのに必要な設定
1.コネクション
2.RESTコネクター
3.入力側マッパー
4.出力ファイル
5.出力側マッパー
6.実行してみる


1.コネクション
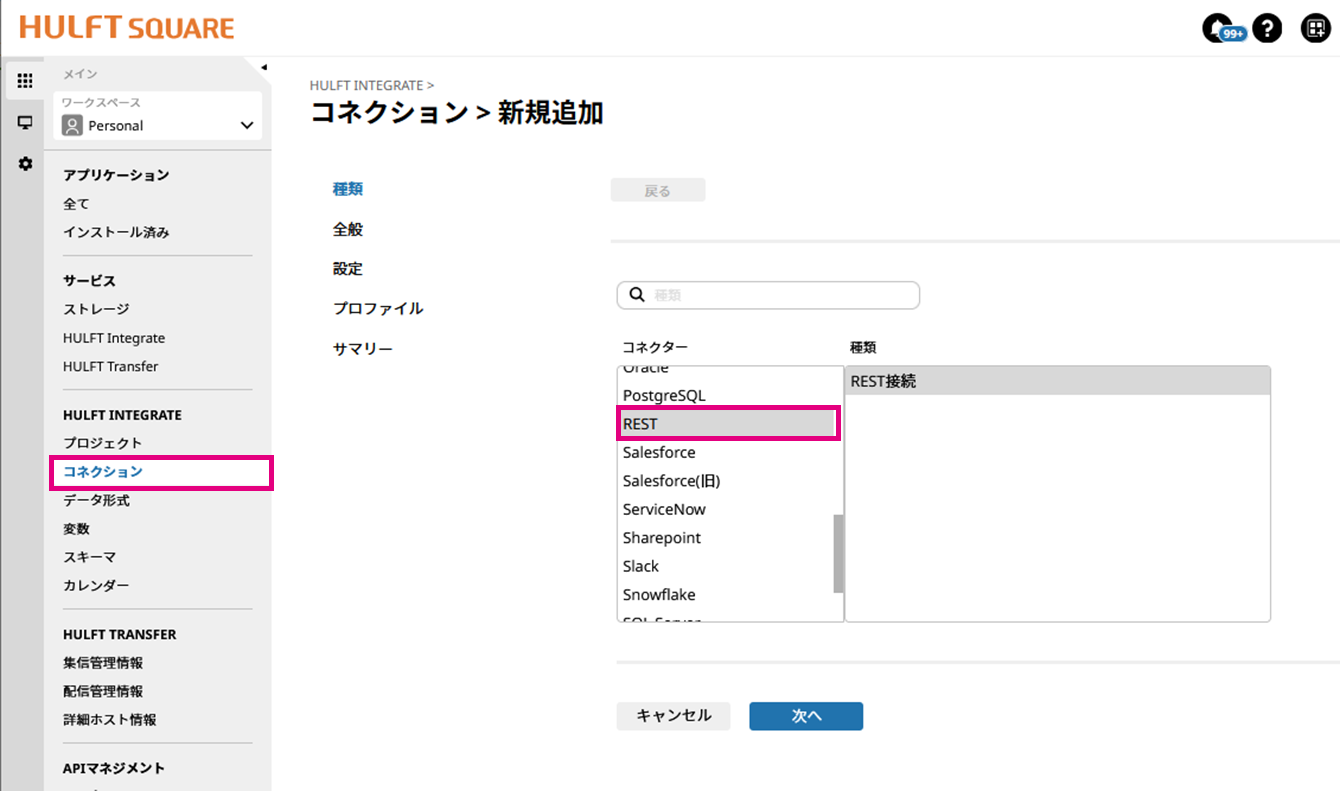
HULFT Squareのコネクションを設定します。
名前:REST接続(Azure OpenAI Service On Your Data)
URL:<➀YOUR_RESOURCE_NAME>
前回の記事参照
<➀YOUR_RESOURCE_NAME>は前回設定したものを使います。
補足:https://<「1.Azure OpenAI」に設定したサービス名:GPT >.openai.azure.com

2.RESTコネクター

Azure OpenAI On Your DataにAPIをコールするための設定をしていきます。
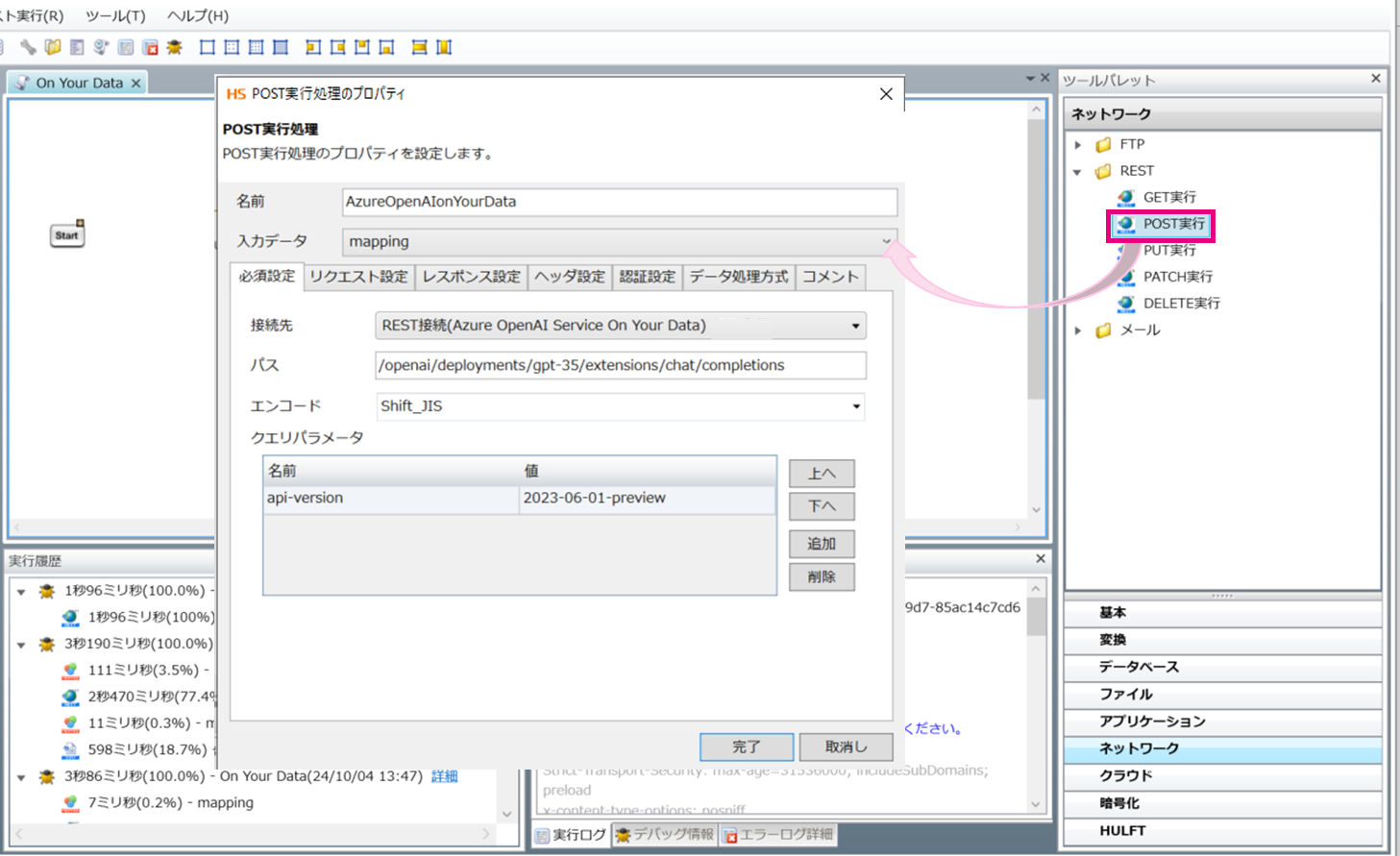
HULFT Squareのデザイナー画面で「ツールパレット > ネットワーク > REST > POST」をドラッグ&ドロップでキャンバスに配置していきます。
「必須設定」
パス:/openai/deployments/<➁YOUR_DEPLOYMENT_NAME>/extensions/chat/completions
クリエパラメーター
名前:api-version
値 :2023-06-01-preview
前回の記事参照
<➁YOUR_DEPLOYMENT_NAME>は前回設定したものを使います。
補足:「1.Azure OpenAI」に設定したデプロイ名:gpt-35
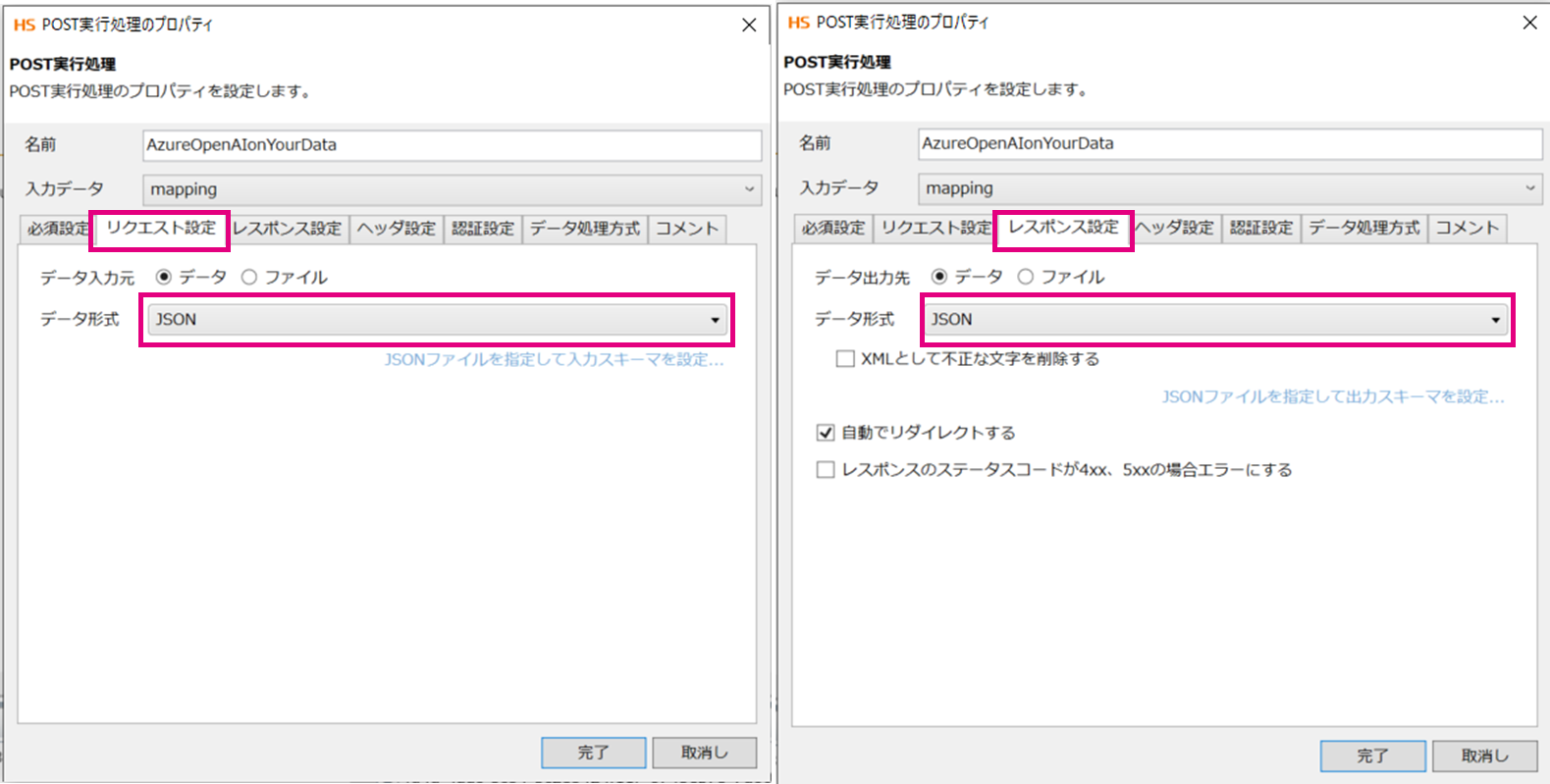
「リクエスト設定」
データ形式:Json
「レスポンス設定」
データ形式:Json
「ヘッダー設定」
リクエストヘッダー
| 名前 | 値 |
|---|---|
Content-Type |
application/json |
api-key |
<➂YOUR_API_KEY> |
chatgpt_url |
<➃YOUR_RESOURCE_URL> |
chatgpt_key |
<➄YOUR_API_KEY> |
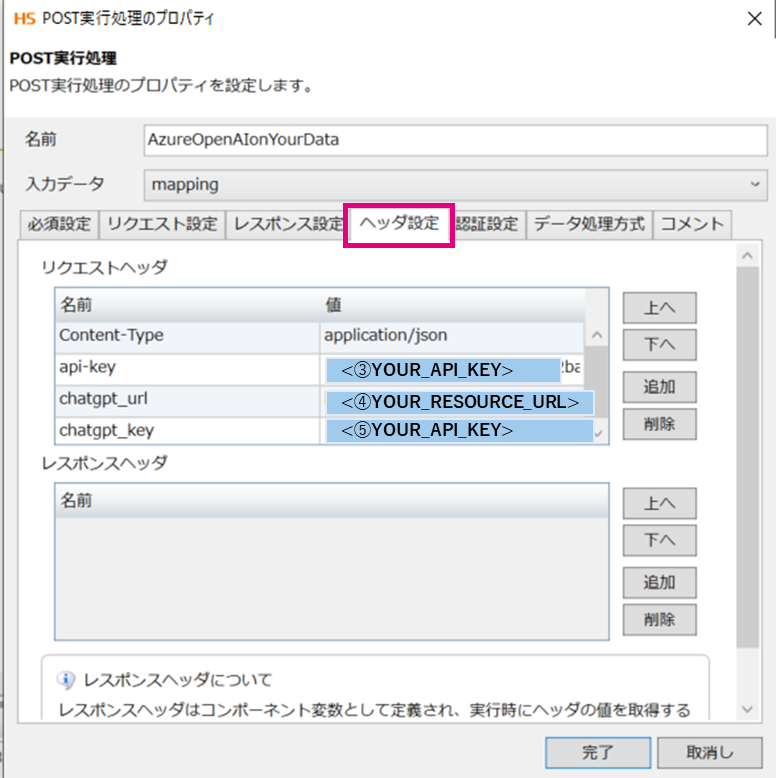
前回の記事参照
<➂YOUR_API_KEY>
補足:「6. コマンドで実行してみる」チャットプレイグラウンドで出した”AzureSearchリソースキー”
<➃YOUR_RESOURCE_URL>
補足:「1.Azure OpenAI」「➁デプロイ」でデプロイしたGPT-35の”ターゲットURL”
<➄YOUR_API_KEY>
補足:「1.Azure OpenAI」「➁デプロイ」でデプロイしたGPT-35の”キー”
3.入力側マッパー
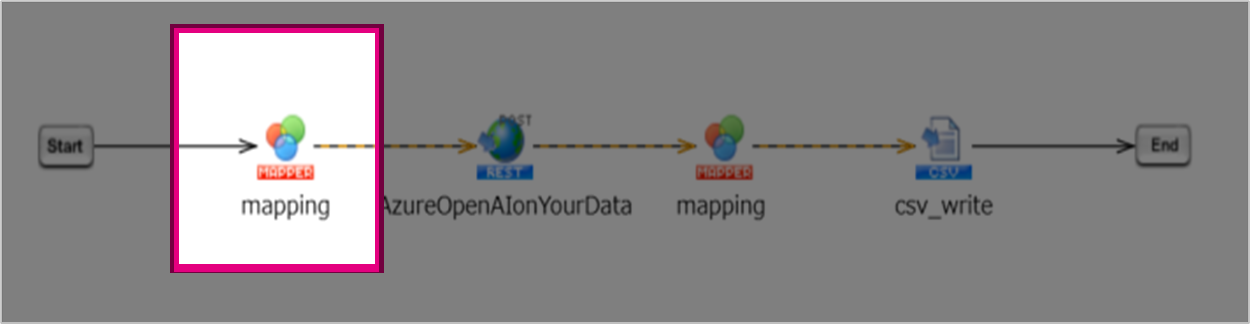
次に、リクエストをコールするための設定をしていきます
リクエストをする為のmapperを設定していきます。
下記JsonをHULFT Squareのスキーマに設定します。
{
"extensions": [],
"dataSources": [
{
"type": "AzureCognitiveSearch",
"parameters": {
"endpoint": "'<➅YOUR_AZURE_COGNITIVE_SEARCH_ENDPOINT>'",
"key": "'<➆YOUR_AZURE_COGNITIVE_SEARCH_KEY>'",
"indexName": "'<➇YOUR_AZURE_COGNITIVE_SEARCH_INDEX_NAME>'"
}
}
],
"messages": [
{
"role": "user",
"content": "What are Yamada Shoji's sales?"
}
],
"temperature": 0.7,
"top_p": 0.95,
"max_tokens": 800,
"stop": null,
"stream": false
}
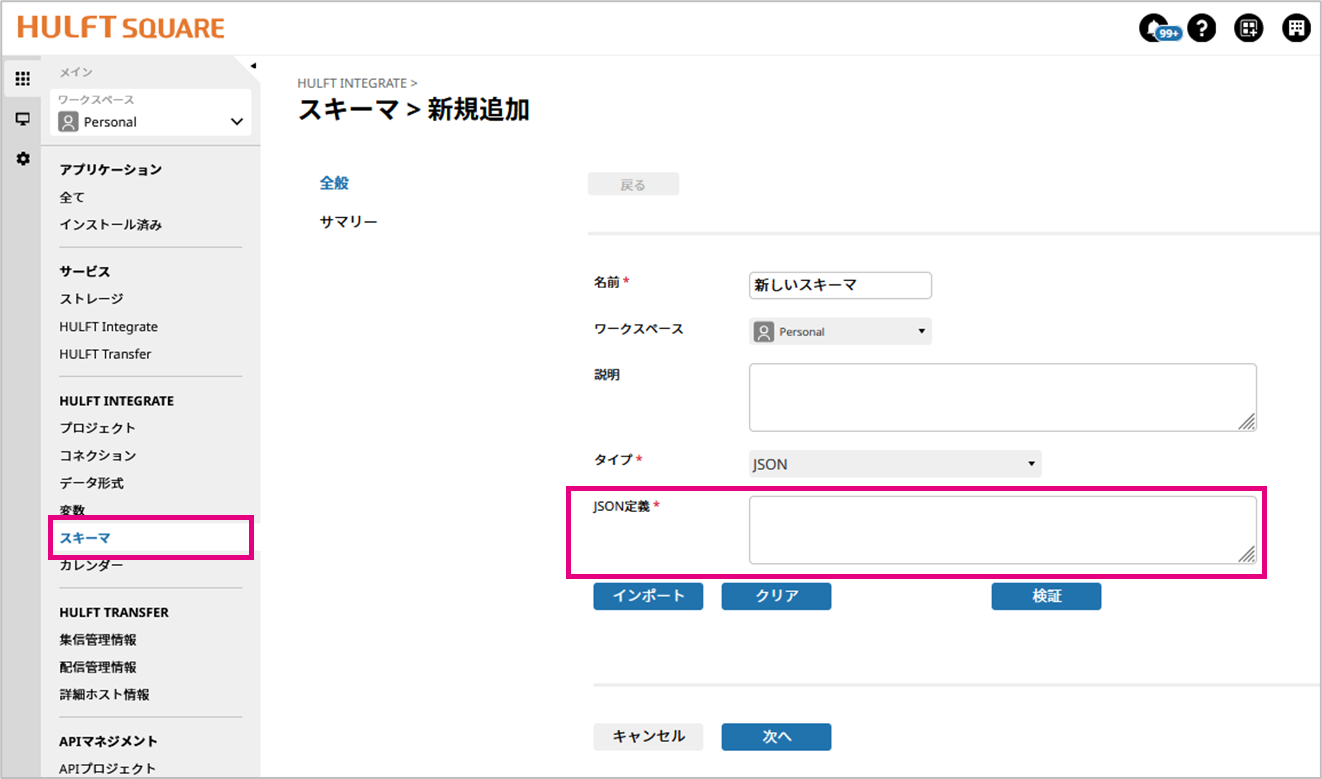
マッパーからスキーマを読み取ります。
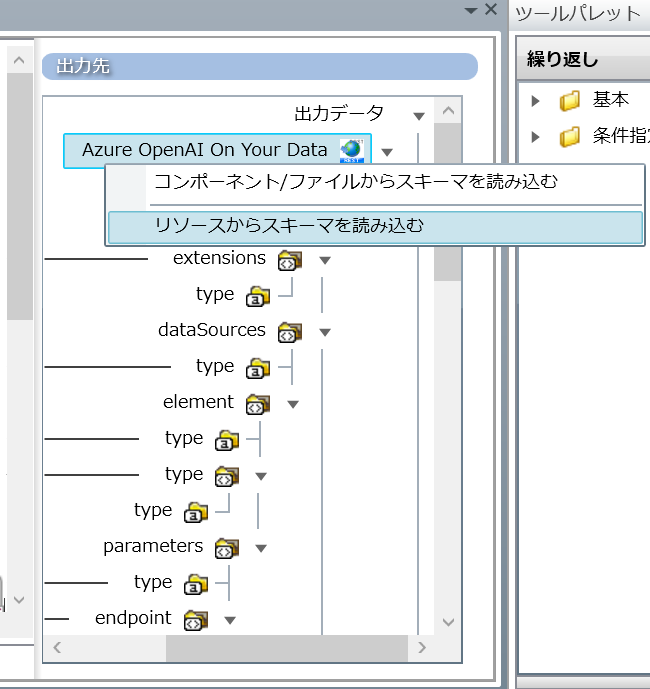
HULFT SquareのマッパーでJsonの構造に合わせて、画像のようにアイコンと出力先の項目をつかってつないでいきます。
※マッパーの仕様により今回は「array」や「object」も指定します。

”単一文字列”ロジック
| 出力先 | アイコン設定値 |
|---|---|
| "extensions" | [] |
| type |
array *mapperの仕様 |
| type |
object *mapperの仕様 |
| "type" | AzureCognitiveSearch |
| type |
object *mapperの仕様 |
| "endpoint" | <➅YOUR_AZURE_COGNITIVE_SEARCH_ENDPOINT> |
| "key" | <➆YOUR_AZURE_COGNITIVE_SEARCH_KEY> |
| "indexName" | <➇YOUR_AZURE_COGNITIVE_SEARCH_INDEX_NAME> |
| type |
array *mapperの仕様 |
| type |
object *mapperの仕様 |
| "role" | user |
| "content" | AIに質問するプロンプト |
”数値定数”ロジック
| 出力先 | アイコン設定値 |
|---|---|
| "temperature" | 0.7 |
| "top_p" | 0.95 |
| "max_tokens" | 800 |
その他のロジック
| 出力先 | アイコン設定値 |
|---|---|
| "stop" |
null (null値ロジック) |
| "stream" |
false (真偽値定数ロジック) |
"content"に入れるプロンプト
今回は下記プロンプトを入れます。

4.出力ファイル

Azure OpenAI On Your Dataが返してきた結果を書き込むファイルを設定します。
今回はCSVファイルに書き込んでいきます。
HULFT Squareのデザイナー画面で「ツールパレット > ファイル > CSV > CSVファイル書き込み」をドラッグ&ドロップでキャンバスに配置していきます。
今回は下記のように設定しました。
ファイルパス:/Personal/Demo.csv
列一覧
列名:Answer

5.出力側マッパー

Azure OpenAI On Your Dataの「出力結果(レスポンス)」を「書き込みにファイル」と繋げる設定をします。
レスポンスJson の構造
「"index": 0」は欲しい値ではないので「"index": 1」の値だけ取得できるようにマッパーで設定する必要があります。

HULFT Squareのスキーマには下記のように設定します。
{
"id": "id",
"model": "gpt-35-turbo-16k",
"created": 1723700923,
"object": "chat.completion",
"choices": [
{
"index": 0,
"messages": [
{
"index": 1,
"role": "assistant",
"content": "Answer",
"end_turn": true
}
]
}
],
"usage": {
"prompt_tokens": 3599,
"completion_tokens": 51,
"total_tokens": 3650
}
}
「3.入力側マッパー」と同様に”リソースからスキーマを読み込む”で「入力元」のリソースを設定します。
HULFT Squareのマッパーで「入力元」と「出力先」の項目を、画像のようにつないでいきます。

使用したアイコンは下記になります。
| アイコン名 | アイコン設定値 |
|---|---|
条件による抽出 |
なし |
単一文字列定数 |
1 |
同じ |
なし |
6.実行してみる
早速実行してみたいと思います。
➀Blobストレージ内に格納している読み取るデータの確認
今回は、Blobストレージにあらかじめこちらのデータを格納して読み込ませておきました。
社内データ(営業会議議事録)

➁実行
デバック実行を行います。

正常に完了しました。

➂確認
結果を確認してみます。
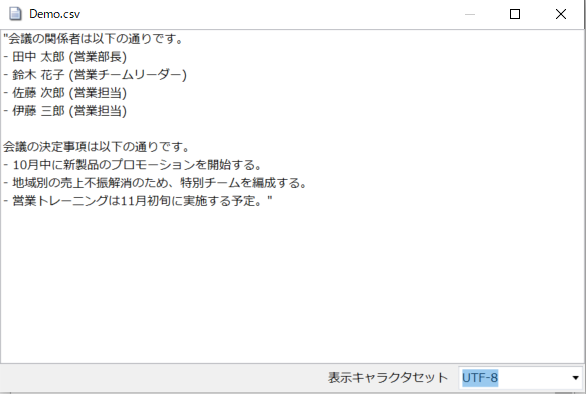
会議の関係者と、会議の決定事項を要約出来ているのが確認出来ます。
最後に
いかがでしたでしょうか、生成AIに安心して社内データ入れられるだけではなく、そのAIの出力結果も他のシステムに安心して受け渡せることで業務使用でのハードルが下がるのではないでしょうか。
また、生成AIの開発が進む中で柔軟に連携出来るシステムがあることで活用の幅も広がるかと思います。
HULFT SquareはAzureとの連携実績もあり下記のAPIと組み合わせることも可能です。
➀ HULFT Square Blobストレージコネクター
➁ Azure AI Searchインデクサー実行API
上記2つを利用することで、
「ファイルアップロード → インデクサー実行(ファイル読み取り) → Azure AI Search(検索)」という流れを一元化することも出来ます。
このブログでは、今後も様々なTopics記事や接続検証等、皆さんの参考になるような記事を投稿していきたいと思います!
それでは、また!![]()