はじめに
こんにちは、すぎもんです![]()
企業内に点在する大量のデータを集約・蓄積し、データの統合と分析を可能にするため、データウェアハウス(DWH)の必要性が高まっています。
DWHを活用すれば、必要なデータを入れて分析を行えるため、業務の効率化に繋げられます。
Snowflakeとは
Snowflake はクラウド上に展開で実行されるDWHです。
Amazon Web Services、Microsoft Azure、Google Cloud Storage といったクラウドサービスで使用の基盤上に構築できます。
データレイクとして想定するAWS S3等クラウドサービスのストレージにあるファイルをロード(読み込み)、およびアンロード(書き出し)を行うことができます。
今回やること
今回は、HULFT Squareを活用して以下の処理が実行できることを確認していきます。
・Snowflake⇒データアンロード
・ストレージ(ファイル)⇒Snowflakeのデータロード
パフォーマンスを確認するため、1GBを超えるデータのロードを実施致します。
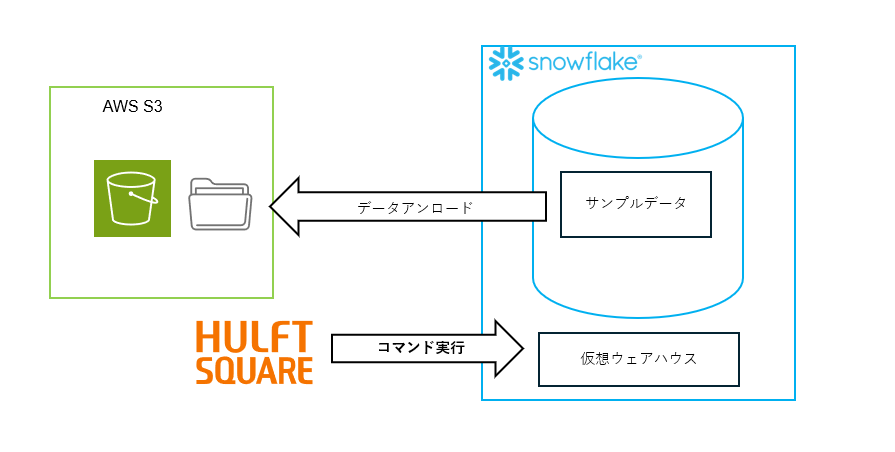
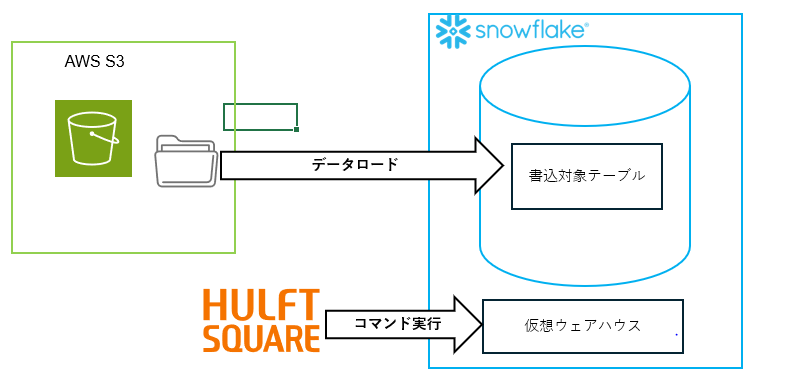
環境イメージ
ファイルはAWS S3上に配置し、Snowflakeへのデータ移行を行うために「外部ステージ」と「ストレージ統合」を設定し、データ連携を実施していきます。
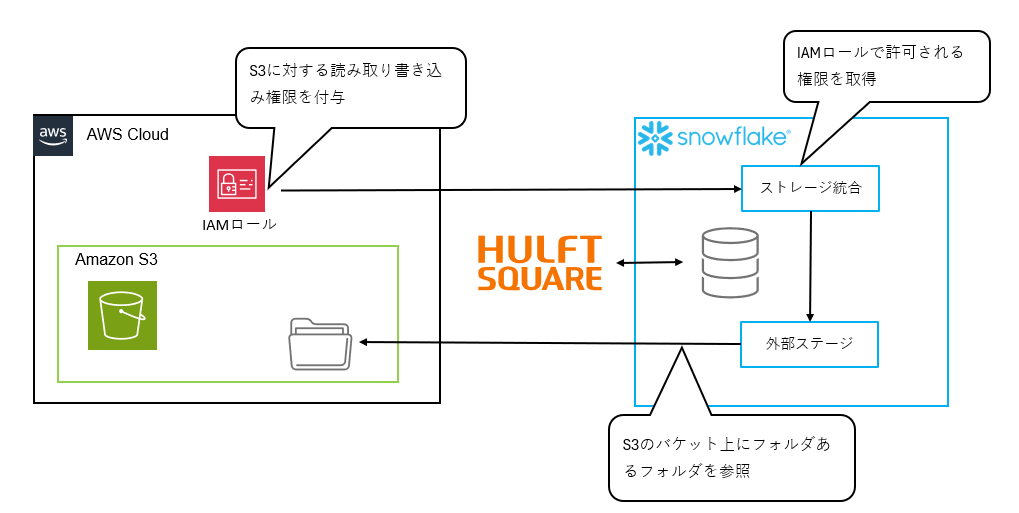
外部ステージとストレージ統合の利用前提条件は下記の通りです。
1.SnowflakeのエディションはStandard以上であること
2.AWSとSnowflakeが同じリージョンであること
今回はSnowFlakeOnAWSとAmazonS3は共に同一のリージョンに構築しています。
また、今回の検証のウェアハウスサイズは最小のXSです。
検証環境準備
1.Snowflake側
1-1.「外部ステージ」の参照先であるS3バケット情報の取得
AWSのS3コンソールを開き、「外部ステージ」で参照するS3バケットの以下の情報を取得します。
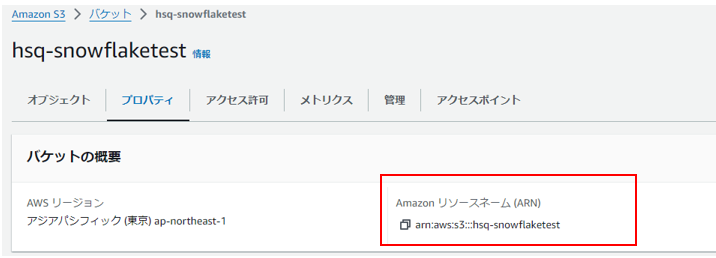
・ARN:arn:aws:s3:::[S3バケットの名称] (例:arn:aws:s3:::hsq-snowflaketest)
・S3 URI:s3://[S3バケットの名称]/ (例:s3://hsq-snowflaketest/)
1-2.S3バケットに対しての読込/書込を許可するIAMポリシー作成
AWSのIAMコンソールを開きます。
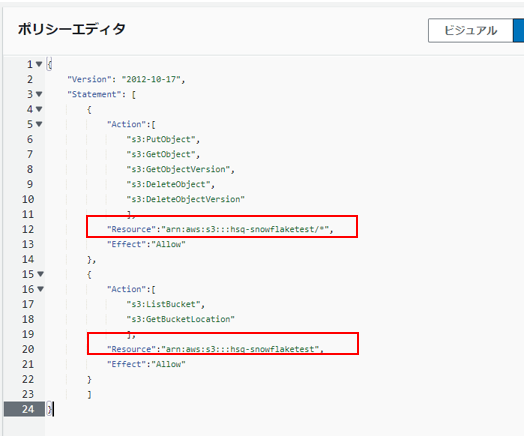
JSONエディターを開き、以下のポリシーをエディターの画面に貼り付けます。
Snowflakeではフォルダー(およびサブフォルダー)内のファイルにアクセスするためにはS3バケットおよびフォルダーに対する次の権限が必要です。
s3:GetObject
s3:GetObjectVersion
s3:ListBucket
s3:PutObject
s3:DeleteObject
s3:DeleteObjectVersion
{
"Version": "2012-10-17",
"Statement": [
{
"Action":[
"s3:PutObject",
"s3:GetObject",
"s3:GetObjectVersion",
"s3:DeleteObject",
"s3:DeleteObjectVersion"
],
"Resource":"[S3バケットのARN]/*",
"Effect":"Allow"
},
{
"Action":[
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource":"[S3バケットのARN]",
"Effect":"Allow"
}
]
}
[S3バケットのARN] の箇所を手順1-1で取得したS3バケットのARNに書き換えます
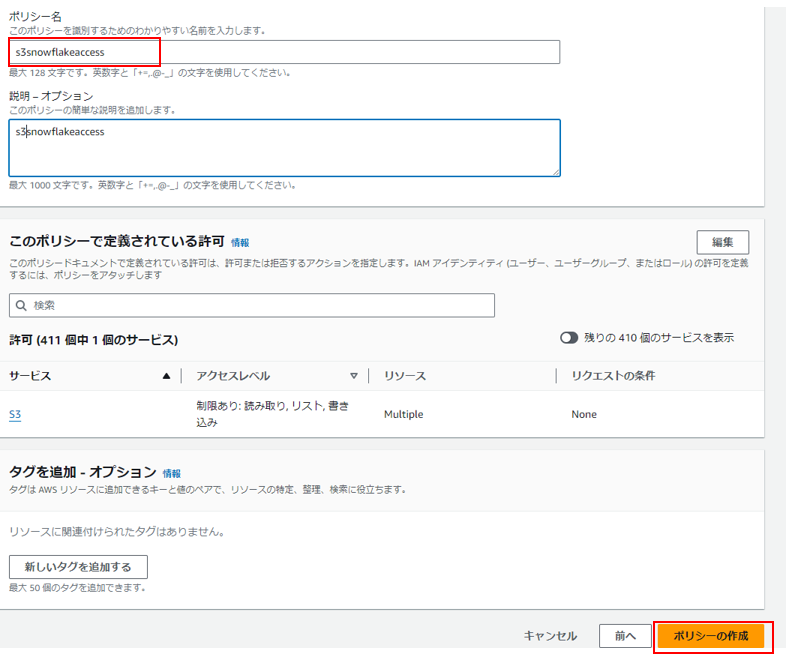
識別しやすいポリシー名でポリシーを作成します。 (例:s3snowflakeaccess)
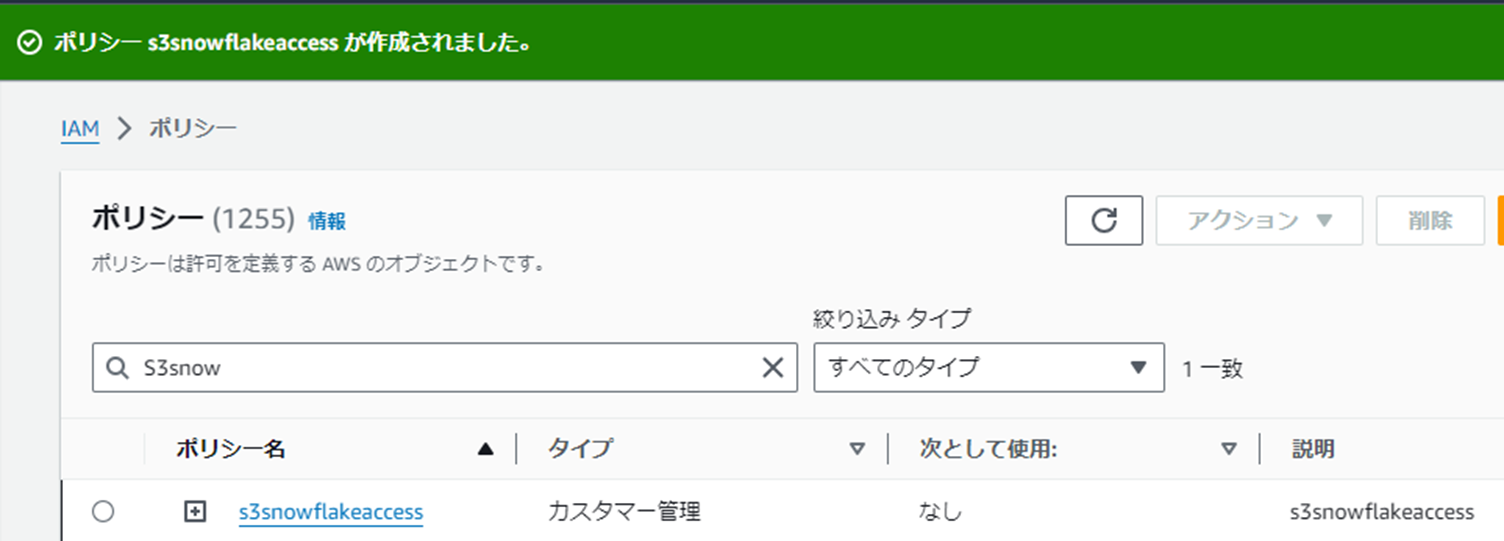
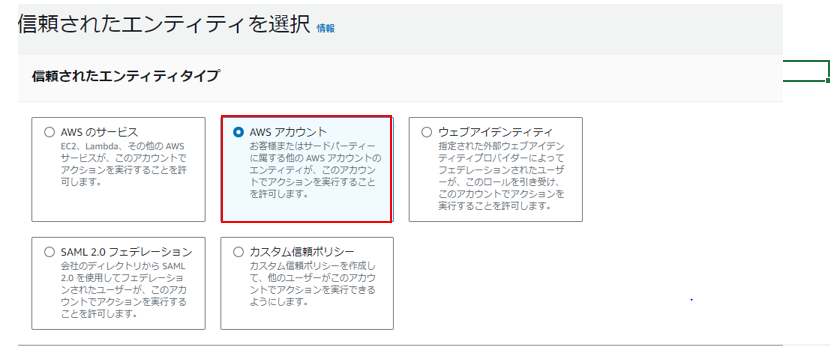
1-3.IAMロール作成
[信頼されたエンティティを選択] 画面にて [アカウントID] と [外部ID] にダミー値を入力して作成していきます。
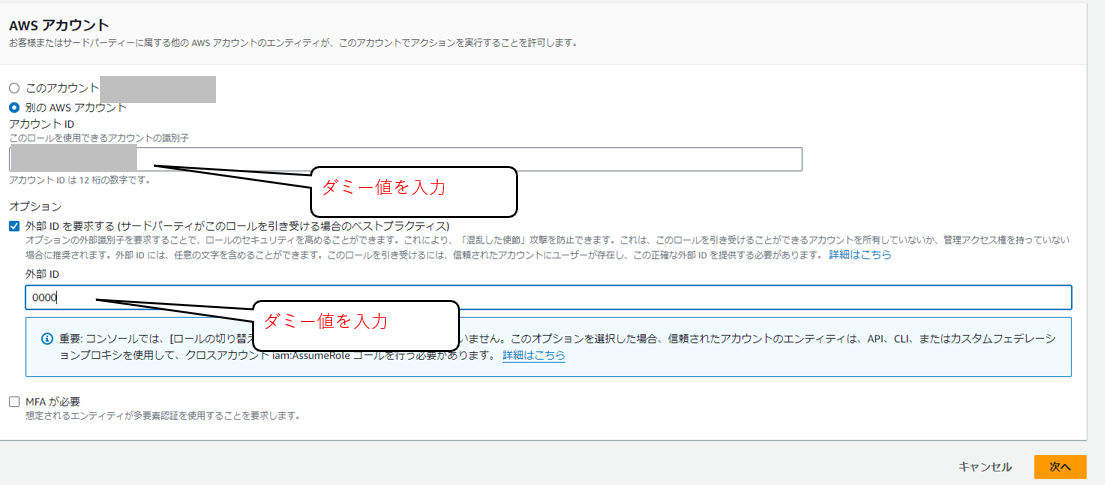
後述の手順「1-4.ストレージ統合作成」にてSnowflakeが使用するAWSのIAMユーザーと「外部ID」を取得できます。
後述の手順で、「AWSアカウント」の部分にSnowflakeが使用するAWSのIAMユーザー、「外部ID」の部分にストレージ統合で使うIDに書き換えます。
手順1-②で作成したIAMポリシーを紐付けます。
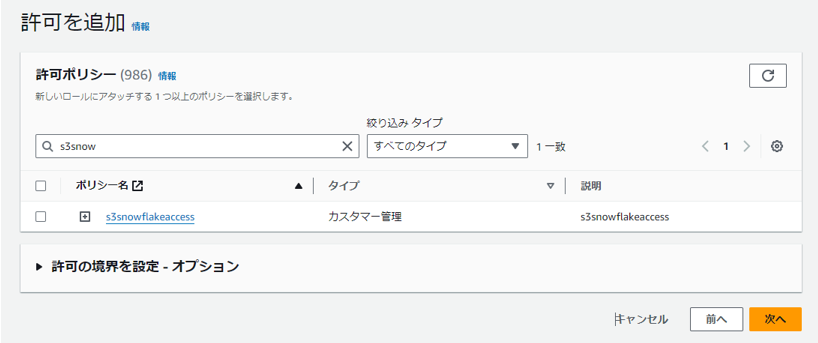
識別しやすいロール名でロールを作成します。 (例:s3snowflakeaccessrole)
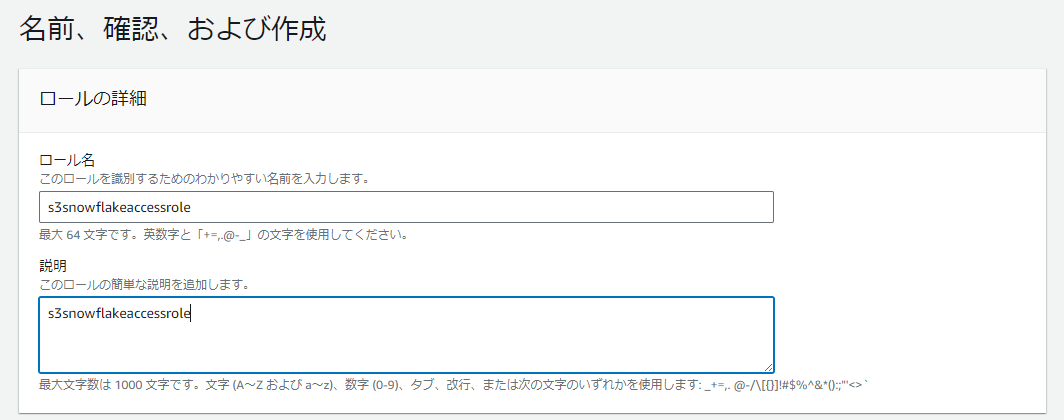
作成したIAMロールの [ARN] を取得し、控えておきます。直後の「1-4.ストレージ統合作成」にて使用します。
1-4.ストレージ統合作成
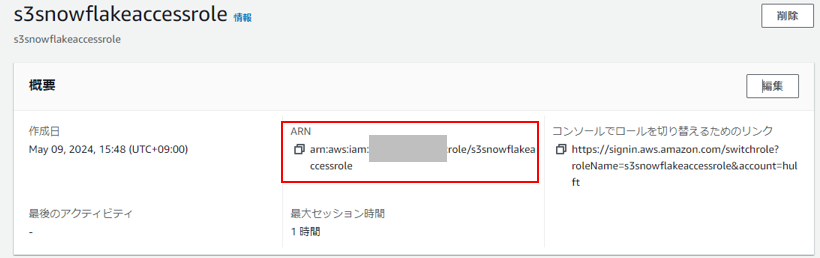
SnowflakeのWebコンソールSnowsightにログインし、[CREATE STORAGE INTEGRATION] を実行します
CREATE STORAGE INTEGRATION <任意のストレージ統合の名称>
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = S3
ENABLED = TRUE
STORAGE_AWS_ROLE_ARN = '<手順1-3で取得したIAMロールのARN>'
STORAGE_ALLOWED_LOCATIONS = ('<手順1-1で取得したS3バケットのS3 URI>');
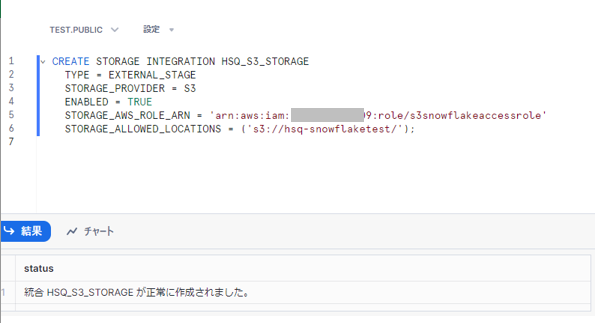
正常に作成されたことを確認後、[DESC INTEGRATION] を実行し、Snowflakeが使用するAWSの [IAMユーザー] と [外部ID] を取得します。
DESC INTEGRATION <手順1-4で作成した「ストレージ統合」の名称>;
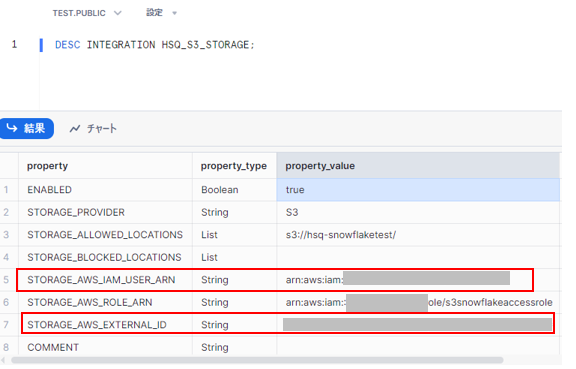
STORAGE_AWS_IAM_USER_ARN:[IAMユーザー]
STORAGE_AWS_EXTERNAL_ID:[外部ID]
AWSのIAMコンソールを開き、上記のIAMユーザーと外部IDの情報を基にIAMロールを修正します。
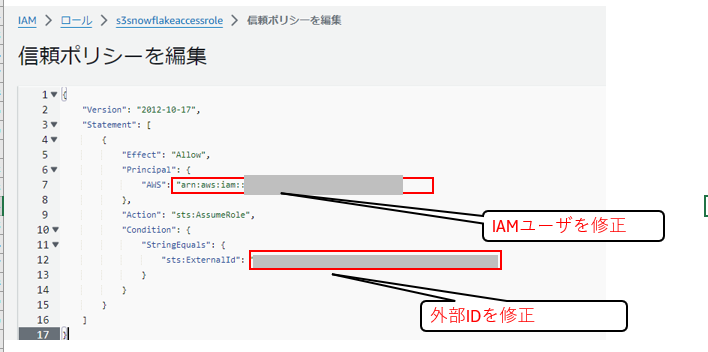
1-5.外部ステージ作成
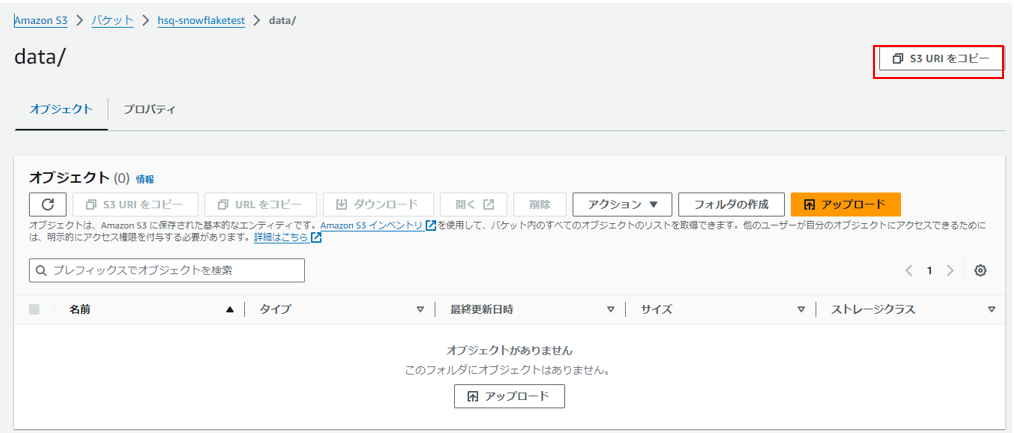
AWSのS3コンソールを開き、「外部ステージ」の参照先フォルダの**[S3 URI**[を取得します
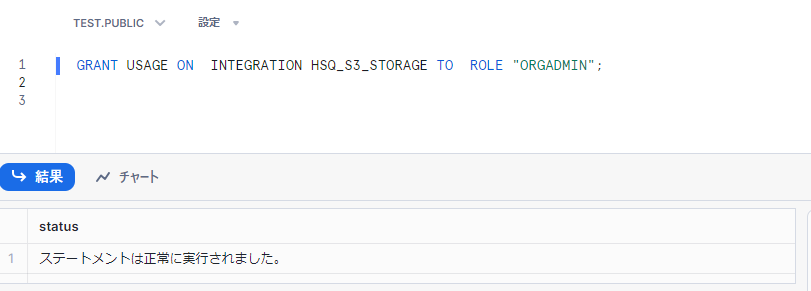
SnowflakeのWebインターフェイスにログインし、「外部ステージ」を使うロールに対して、「ストレージ統合」の使用権限を付与します。
GRANT USAGE ON <ストレージ統合の名称> TO ROLE <外部ステージを使うロール>;
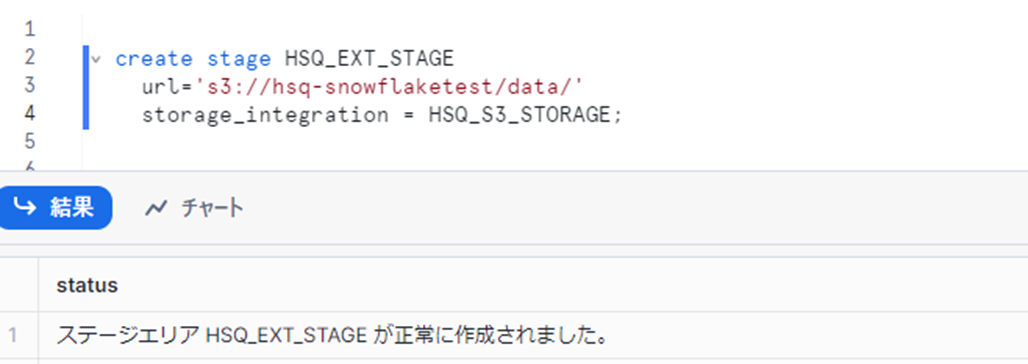
[CREATE STAGE] を実行し、「外部ステージ」を作成します。
create stage <作成する外部ステージの名称>
url='<手順1-5で取得した外部ステージの参照先フォルダのS3 URL>'
storage_integration = <ストレージ統合の名称>;
2.HULFT Square側
ここからはHULFT SquareからSnowflakeへ接続する設定を実施していきます。
2-1.コネクション作成
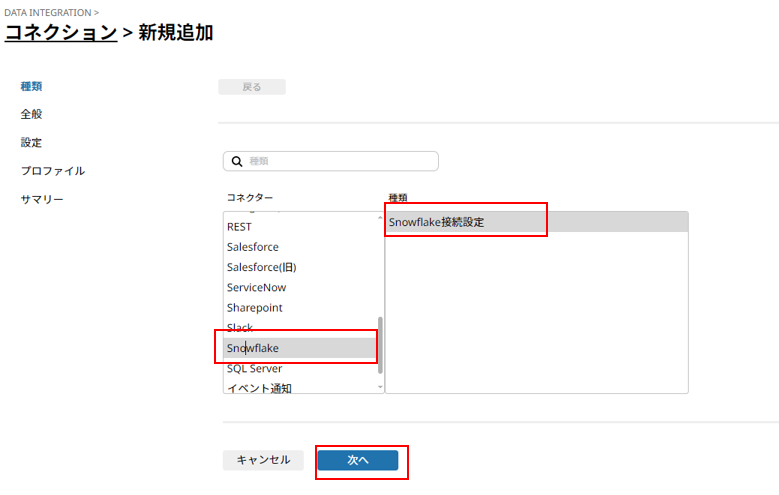
[名前] 任意の名前、今回はSnowflakeTESTを入力して**[次へ]**をクリック
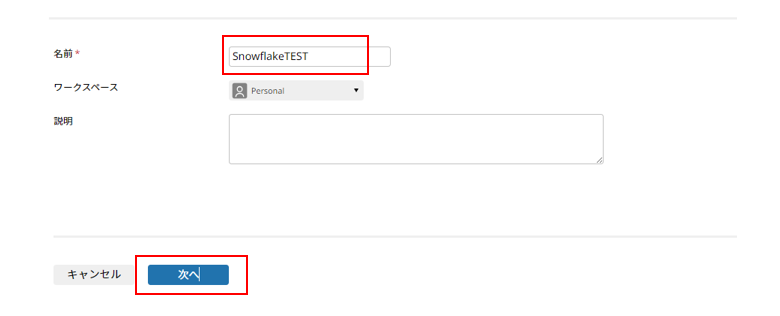
[アカウント識別子] 等必要項目に値を入力して**[次へ]**をクリック
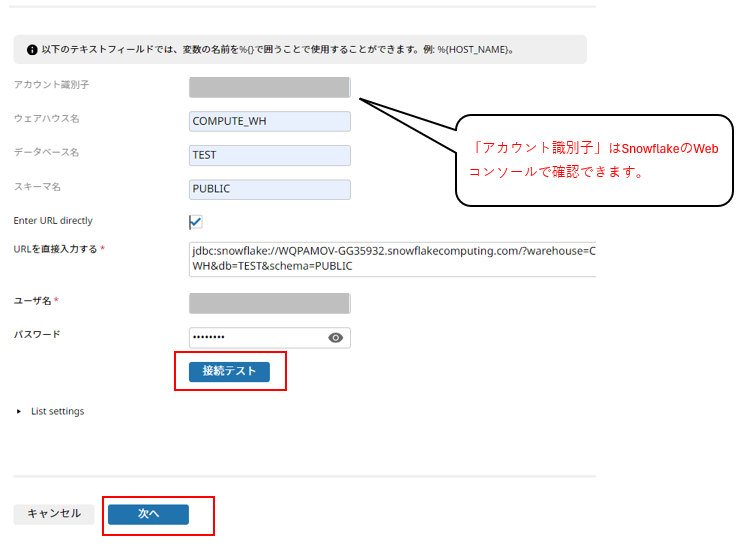
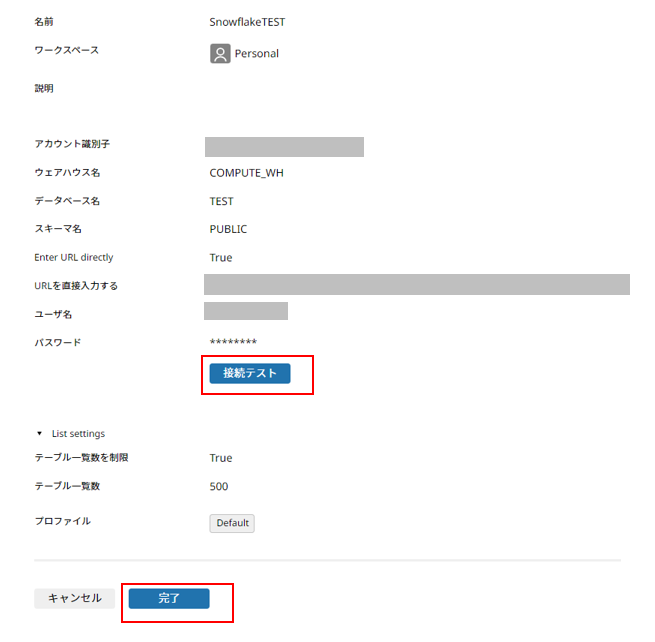
[接続テスト] の成功を確認後、[完了] をクリックし、コネクション作成は終了です。
検証実施
1.データアンロード
今回まずテストデータ準備を兼ねてSnowflakeのサンプルデータをS3の外部ステージにアンロードしていきます
抽出対象データは下記の通りです。
| スキーマ名 | テーブル名 | サイズ | レコード数 |
|---|---|---|---|
| TPCH_SF100 | CUSTOMER | 1GB | 1500万 |
1-1.データアンロード用スクリプト作成
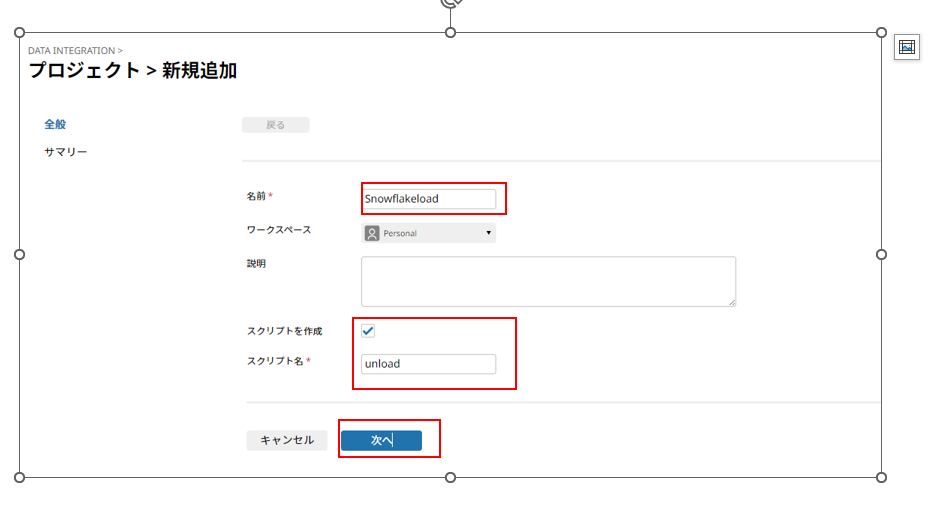
デプロイ単位であるプロジェクトを新規作成し、配下に実行用のスクリプトを作成していきます。
以下の項目を入力後、[次へ] クリックします。
[名前] 任意の名前、今回はSnowflakeloadを入力
[スクリプトを作成] にチェックを入れる
[スクリプト名] 任意の名前、今回はunloadを入力
[デザイナを起動] をクリックし、[HULFT Square Designer] を起動し、スクリプトを作成していきます。
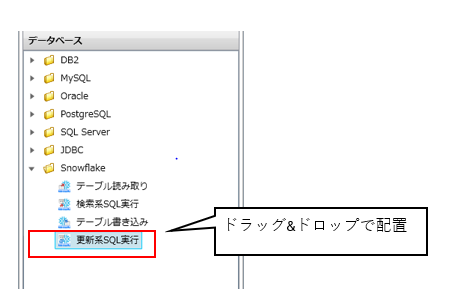
「Snowflake更新系SQL実行」アイコンの配置
[ツールパレット] より [データベース>Snowflake>更新系SQL実行] アイコンを選択しドラッグ&ドロップしてスクリプトキャンバスへ配置します。
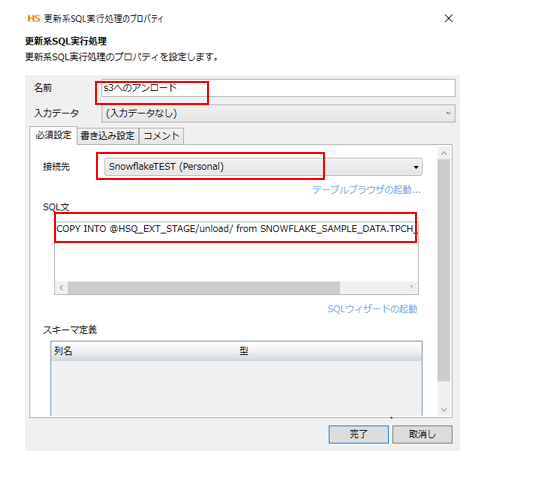
[名前] 任意の名前、今回はS3へのアンロードを入力
[接続先] 今回は前述で作成したSnoWflaketestコネクションを選択
[SQL文] 外部ステージへのアンロードを意味するCopy into文を入力
COPY INTO @HSQ_EXT_STAGE/unload/ from SNOWFLAKE_SAMPLE_DATA.TPCH_SF100.CUSTOMER;
下記のように [start] から [END] までドラッグ&ドロップでプロセスフローの矢印を繋ぐとデータアンロード用スクリプトの完成です。
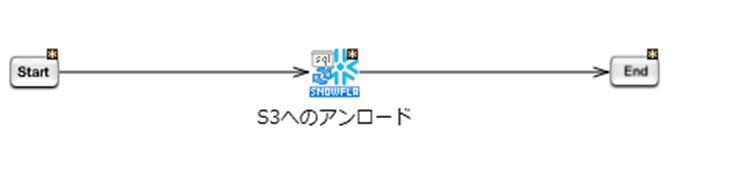
1-2.データアンロード用スクリプト実行確認
デザイナ画面からスクリプトの実行を確認後、S3のコンソールへログインするとgzファイルのデータがアンロードされていることが確認できます。
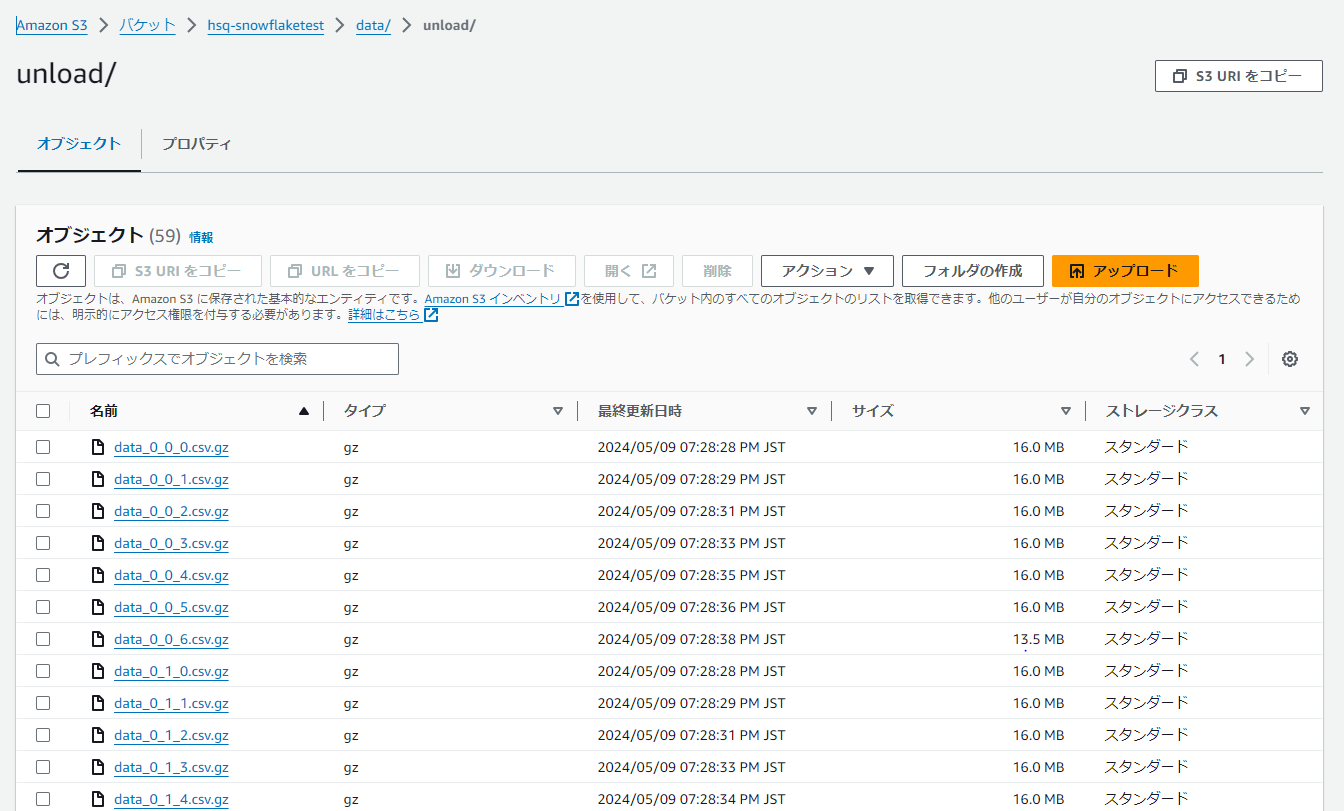
Copy into文でアンロードを実施した場合、デフォルトでgzファイルに圧縮してS3に格納されます。
ウェアハウスサイズXSでの実行時間は約13秒でした。
2.データロード
アンロードしたサンプルデータを別スキーマの同一構造のテーブルへロードしていきます。
書き込み対象テーブルの定義は下記の通りです
create or replace TABLE TEST.PUBLIC.CUSTOMER (
C_CUSTKEY NUMBER(38,0),
C_NAME VARCHAR(25),
C_ADDRESS VARCHAR(40),
C_NATIONKEY NUMBER(3,0),
C_PHONE VARCHAR(18),
C_ACCTBAL NUMBER(6,2),
C_MKTSEGMENT VARCHAR(25),
C_COMMENT VARCHAR(400)
);
2-1.データロード用スクリプト作成
作成済みであるSnowflakeloadプロジェクト配下に実行用のスクリプトを作成していきます。
[スクリプト名] 任意の名前、今回はdataloadを入力
「Snowflake更新系SQL実行」アイコンの配置
[ツールパレット] より [データベース>Snowflake>更新系SQL実行] アイコンを選択しドラッグ&ドロップしてスクリプトキャンバスへ配置します。
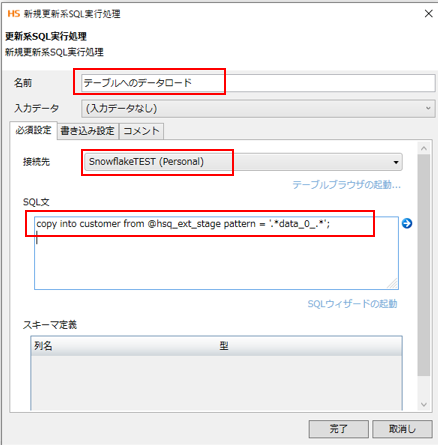
[名前] 任意の名前、今回はテーブルへのデータロードを入力
[接続先] 今回は前述で作成したSnoWflaketestコネクションを選択
[SQL文] customorテーブルへのロードを意味するCopy into文を入力
copy into customer from @hsq_ext_stage pattern = '.*data_0_.*';
外部ステージのファイルを取得する際はpattren句と正規表現を用いて、フォルダ配下のファイルを複数取得することが可能です。
下記のように [start] から [END] までドラッグ&ドロップでプロセスフローの矢印を繋ぐとデータアンロード用スクリプトの完成です。

2-2.データロード用スクリプト実行確認
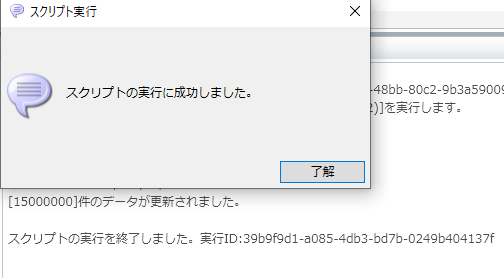
デザイナ画面からスクリプトの正常終了と1500万件のデータが更新されたことが確認できます。
ウェアハウスサイズXSでの実行時間は約17秒でした。
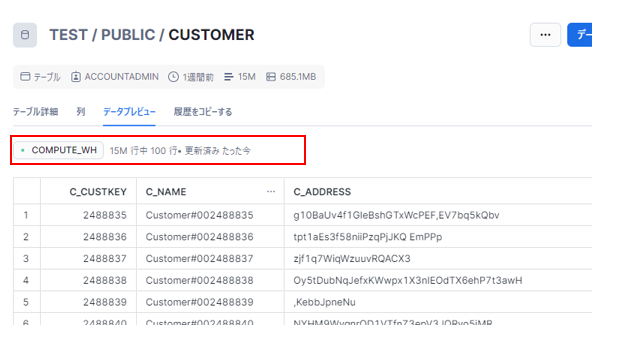
また、SnowflakeのWebインターフェイスからも対象のテーブルに1500万件のデータが反映されていることが確認できます。
おわりに
いかがだったでしょうか。
HULFT SquareからSnowflakeへ接続し、AWS S3とのデータ連携が実現できることを確認できました。
SnowflakeとAWS S3間で外部ステージ設定を実施した後は、GUIでデータ連携プログラムを構築できることがHULFT Squareが持つ強みといえます。
また、当ブログでは実施していませんが、Snowflakeへのデータロード前にS3へ貯めたファイルのデータ変換ができることもHULFT Squareを利用することで得られるメリットです。
当ブログが、SnowflakeとHULFT Squareとの連携構築の一助にもなれば幸いです。
ここまで読んでいただきありがとうございました。それでは、また!