Optunaは、ハイパーパラメータ探索を自動化する素晴らしいライブラリです。そのtrials_dataframe機能は、探索の過程を詳細に記録し、一覧できるため非常に便利です。以下のコードは、Optunaでの探索を行う基本的な例です。
study = optuna.create_study(direction='maximize')
stusy.optimize(objective, n_trials=100)
study.trials_dataframe()
しかし、このDataFrameをそのままStreamlit上で表示すると見づらさを感じるかもしれません。特に、大量のトライアルを扱う場合には、より明瞭に結果を見る必要があります。
例えば、Optunaの標準出力がこちらです
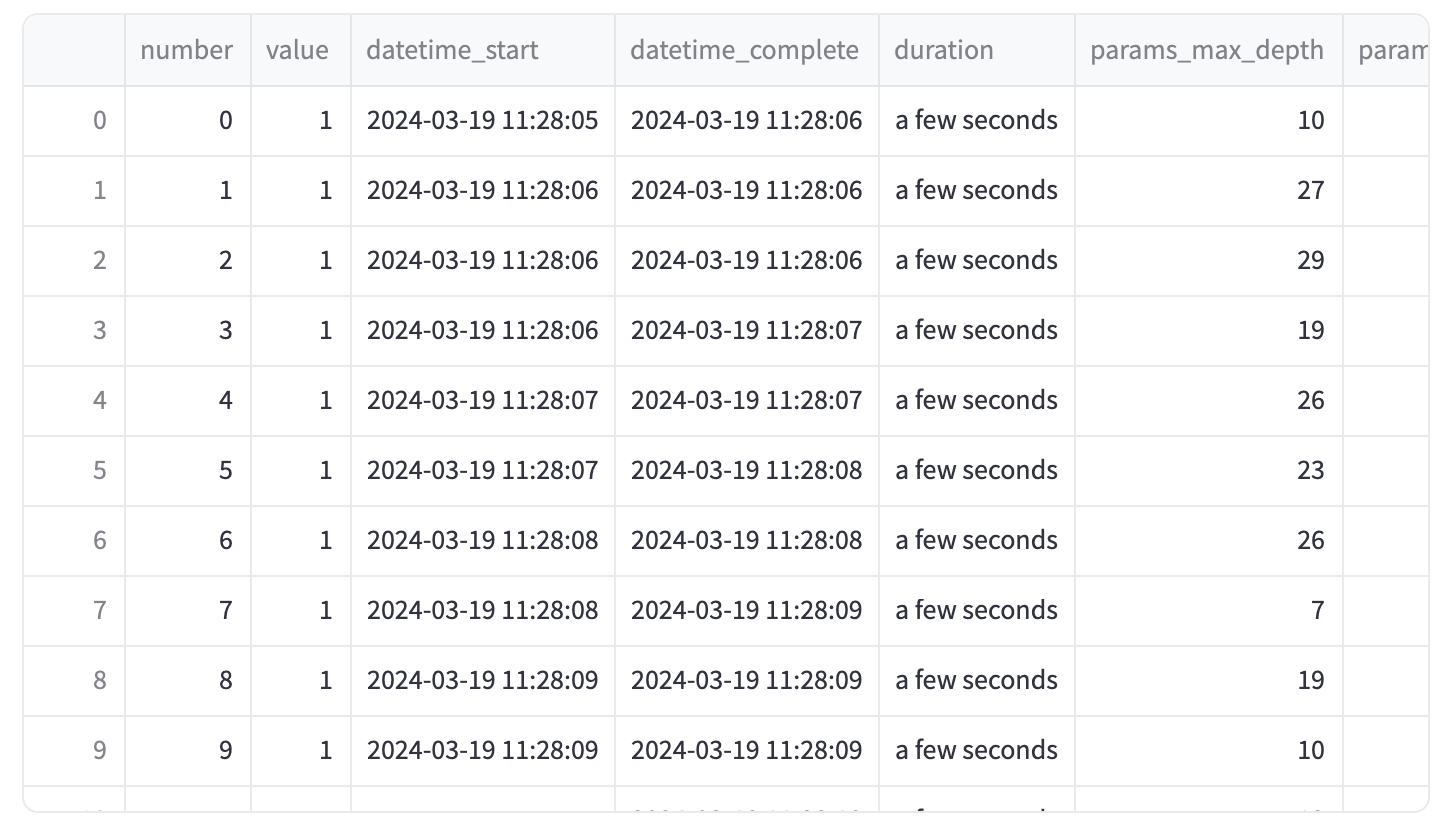
これを、次のように見やすく変換したいと考えます:
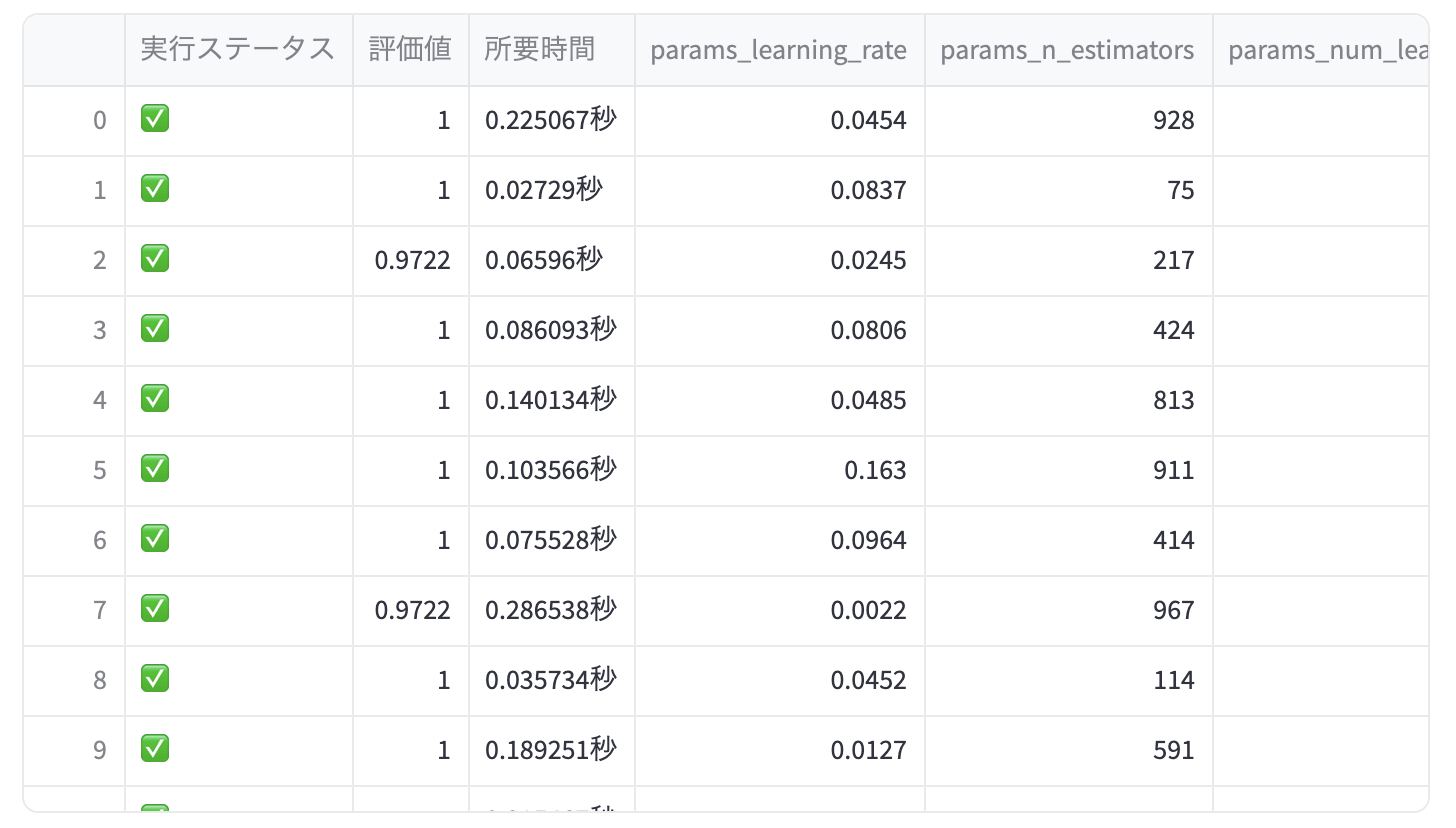
実際の変換コード
以下に、この変換を実現する実際のコードを共有します。このコードでは、不要な列の削除、ステータスの視覚化、所要時間の単位変換、列の順序変更、および列名の日本語化を行っています。
def get_trials_dataframe(self):
opt_result = self.study.trials_dataframe()
# st.write(opt_result)
opt_result = opt_result.drop(["number", "datetime_start",
"datetime_complete"], axis=1)
# ステータスを見やすく
opt_result['state'] = opt_result['state'].map(lambda x: '✅' if x == 'COMPLETE' else '❌')
# duration列を変換する(秒単位から分または時間単位に)
def convert_duration(timedelta):
seconds = timedelta.total_seconds() # Timedeltaから秒数を取得
if isinstance(seconds, str):
return seconds
elif seconds >= 3600:
return f"{seconds / 3600:.2f}時間"
elif seconds >= 60:
return f"{seconds / 60:.2f}分"
else:
return f"{seconds}秒"
opt_result['duration'] = opt_result['duration'].apply(convert_duration)
# 順番を入れ替える
columns_order = ['state', 'value', 'duration'] + [col for col in opt_result.columns if col.startswith('params_')]
opt_result = opt_result[columns_order]
# 日本語化
column_name_map = {
"value": "評価値",
"duration": "所要時間",
"state": "実行ステータス",
}
# パラメータのカラム名を特定するための正規表現パターン
params_pattern = re.compile(r'^params_')
# パラメータ以外の列名を日本語に変換
new_columns = {}
for col in opt_result.columns:
if not params_pattern.match(col):
# パラメータ以外の列名を変更
new_columns[col] = column_name_map.get(col, col)
else:
# パラメータの列名はそのままにするか、適宜変更する
# 例: 'params_learning_rate' -> '学習率'
# new_columns[col] = '日本語の列名' # 必要に応じて
pass
# 列名の変更を適用
opt_result.rename(columns=new_columns, inplace=True)
return opt_result
この関数をStreamlitアプリケーションで使用することで、Optunaの探索結果をより一目で理解しやすくすることができます。これにより、ハイパーパラメータのチューニングプロセスがよりスムーズになります。