はじめに
競馬の新馬戦予想は、出走馬に関する過去のデータが乏しく難しいものです。そこで、netkeibaの馬毎の掲示板データを用いて、機械学習を活用した新馬戦の予測に挑戦しました。この記事では、データ収集から学習、予測までのプロセスと、その結果について詳しく紹介します。
データ収集
netkeibaから新馬戦に関するデータをスクレイピングで収集しました。対象としたのは2022年にJRAが開催した新馬戦301件、出走した馬3948頭分の掲示板データです。スクレイピング後は、データの前処理として、Unicode正規化や特殊文字の除去などを行いました。
def preprocessing_text(text):
text = unicodedata.normalize('NFC', text)
# ()で囲まれた部分を削除
emoji= r'\([^)]*\)'
text = re.sub(emoji, "", text)
text = re.sub(r'[^\w\s]', "", text)
text = text.replace("\n", "")
return text
学習データの作成
学習データは、doc2vecを使用してベクトル化しました。目的変数としては、各馬の掲示板コメントからその馬が3着以内に入るかどうかを予測する二値分類です。最終的に得られた学習データは26,920件でした。
# 文書をトークン化して、TaggedDocument形式に変換
tagged_data = [TaggedDocument(words=word_tokenize(_d.lower()),
tags=[str(i)]) for (i, (_d, _l)) in df_train.iterrows()]
# Doc2Vecモデルの構築とトレーニング
model = Doc2Vec(vector_size=20, min_count=1, epochs=100)
model.build_vocab(tagged_data)
model.train(tagged_data, total_examples=model.corpus_count, epochs=model.epochs)
# 文書ベクトルを取得
vectors = [model.dv[i] for i in range(len(tagged_data))]
# ターゲット(ラベル)の準備
labels = [label for _, label in df_train.values]
# 簡単なモデルで動作確認
# データをトレーニングセットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(vectors, labels, test_size=0.25, random_state=42)
# ロジスティック回帰モデルのトレーニング
lr_model = LogisticRegression()
lr_model.fit(X_train, y_train)
# モデルの精度をテスト
print("モデルの精度: ", lr_model.score(X_test, y_test))
# モデルの精度: 0.6462179868969625
学習と予測
機械学習モデルにはLightGBMを採用し、Optunaでハイパーパラメータのチューニングを行いました。KFoldを使用して汎化性能を測定し、性能評価にはPrecision、Recall、F-score、Accuracy、AUCを用いました。
kf = KFold(n_splits=5, shuffle=True)
vectors = np.array(vectors)
labels = np.array(labels)
scores = []
models = []
# KFoldで精度を求める
for i, (train_index, test_index) in enumerate(kf.split(vectors,labels)):
print(f"Fold {i}:")
X_train = vectors[train_index]
y_train = labels[train_index]
X_test = vectors[test_index]
y_test = labels[test_index]
dtrain = lgb.Dataset(X_train, label=y_train)
deval = lgb.Dataset(X_test, label=y_test)
params = {
'objective': 'binary',
'verbose': 0,
'random_state': 1,
'metrics': 'auc'
}
model = lgb.train(params, train_set=dtrain, valid_sets=deval)
y_pred_proba = model.predict(X_test)
y_pred = np.where(y_pred_proba>=0.5, 1, 0)
confu = confusion_matrix(y_test, y_pred) # 混同行列
# print(confu)
p = precision_score(y_test, y_pred, average='macro') # 精度
r = recall_score(y_test, y_pred, average='macro') # 再現率
f1 = f1_score(y_test, y_pred, average='macro') # F値
acc = accuracy_score(y_test, y_pred) # 正解率
auc = roc_auc_score(y_test, y_pred_proba)
print('精度 {:.2f}、再現率 {:.2f}、F値 {:.2f}、正解率 {:.2f}、AUC {:.2f}'.format(p, r, f1, acc, auc))
scores.append((p, r, f1, acc, auc))
結果
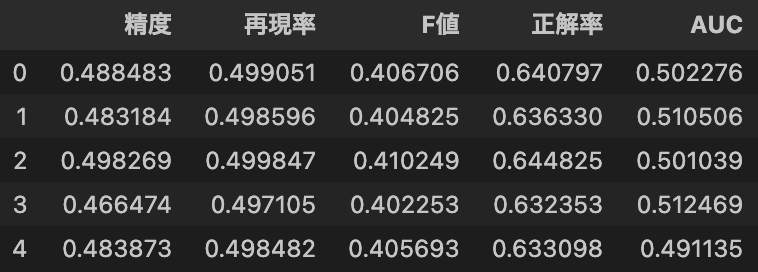
残念ながら、どの予測精度も期待ほど高くなかったことが判明しました。特にAUCはほぼ0.5と、ランダム予測と同等の精度でした。この結果から、掲示板データだけを使用した予測は困難であると結論付けられます。
pd.DataFrame(scores, columns=["精度", "再現率", "F値", "正解率", "AUC"])
考察
予測精度の向上には、他の機械学習モデルとのアンサンブル学習や、血統情報などの追加特徴量の活用が有効と考えています。ただし、厩舎コメントなど一部のデータは有料コンテンツのため、活用には制限があります。
まとめ
netkeibaの掲示板データを用いた新馬戦の予測は難しいものの、機械学習による競馬予想の可能性を探る第一歩となりました。今後はさらなるデータの探求と、予測モデルの改善に挑みたいと思います。