はじめに
最近は競馬のデータ分析をいろいろ試しています。その中でnetkeibaさんにある掲示板のデータを分析したら面白い知見が得られるんじゃないかと考えたのでやってみた。
用意したもの
- Python
- Selenium
- BeautifulSoup
- MeCab
- NEologd
- KHCoder
データスクレイピング(クローリング)
netkeibaさんの掲示板サイトは動的サイトですのでSeleniumで操作してHTMLを持ってきます。
今回は明日(10/9)に開催される京都大賞典の掲示板を取得してきます。
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import time
import re
# Seleniumをヘッドレスで実行する
options = Options()
options.add_argument("--headless")
URL = "https://race.netkeiba.com/race/bbs.html?race_id=202308020311&rf=special_sidemenu"
file_name = "2023_京都大賞典.txt"
driver = webdriver.Chrome(options=options)
driver.get(URL)
# 一番下のレス番号を取得
res_no = driver.find_elements(By.CLASS_NAME, "Res_No")[-1].text
# [??]なので中心のみを抽出
res_no = int(res_no[1:-1])
# 最後のレスになるまでループ
print("ボタン操作開始")
while res_no!=1:
# 「もっと表示する」ボタンを探す
more_btn = driver.find_element(By.ID, "MoreComment01")
# ボタンを押す
driver.execute_script("arguments[0].click();", more_btn)
time.sleep(1)
res_no = driver.find_elements(By.CLASS_NAME, "Res_No")[-1].text
res_no = int(res_no[1:-1])
print("最後のレス番号:",res_no)
print("コメント処理開始")
# BeautifulSoupに渡して解析
page = driver.page_source
soup = BeautifulSoup(page, "html.parser")
# 余計な文字を削除
comments = [i.text.replace("\nフォローする", "").replace("\n", "").replace("\u3000", "")
for i in soup.find_all("p", attrs={"class":"Comment"})]
# [>>??]というようなレスをしているコメントの数字部分を削除する
for i in range(len(comments)):
res = re.match(r">>[0-9]+", comments[i])
if res is not None:
res_body = res.group()
comments[i] = comments[i].replace(res_body, "")
comment_all = "。\n".join(comments)
print("ファイル保存")
# 保存
with open("レース掲示板/"+file_name, "w", encoding='utf-8') as b:
b.write(comment_all)
print("処理終了")
細かい処理の説明は省きますが、ざっくり書くと
- seleniumでサイトを開く
- 「もっと表示する」ボタンを最後のレス番号が1になるまで押し続ける
- HTMLを持ってくる
- BeautifulSoupで解析しつつ、余分な文字を削除する
です。
KHCoderで共起分析
我らがKHCoderで分析します。
自宅のPCにはMeCabとNEologdの環境がなかったので以下の記事を参考に構築しておきました。
KHCoderを起動して、新規→出力したテキストファイルを選択→前処理の実行→共起ネットワークの作成、で完成したのがこちらの図です。
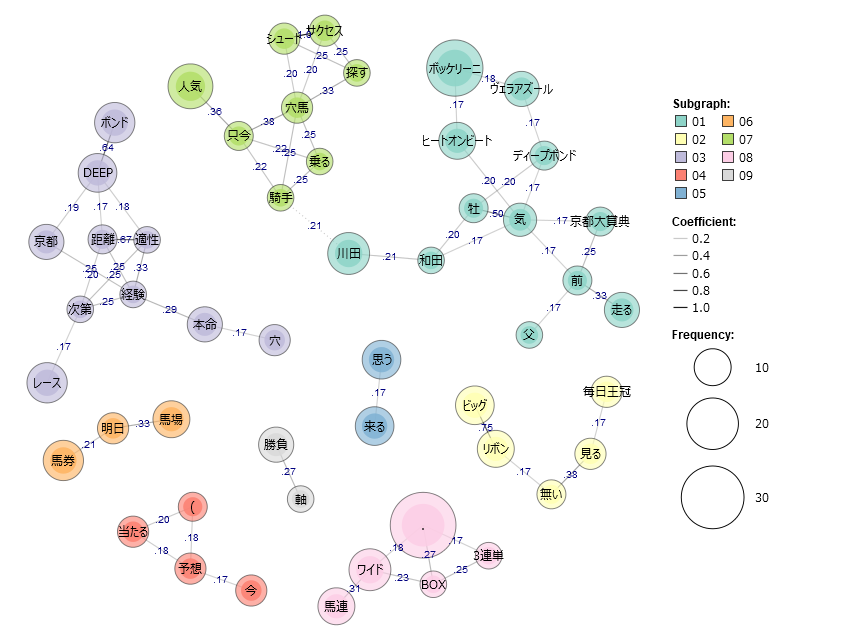
正直言うと微妙ですね...
ぱっと見でみんなが穴馬として指名しているサクセスシュート...いや出馬表にいないじゃん!
人気しそうな馬は右上に固まっていますね。
良くも悪くも単語ごとの関係性のため、
- 予想-当たる
- 馬連-ワイド-BOX-3連単
- 穴-本命
のような、わかりきってる関係性や、
- DEEP-ボンド
- サクセス-シュート
- ビッグ-リボン
といった馬の名前が分かれている関係性もあります。
ただ、
- DEEP-ボンド-京都-経験-本命
- ビッグ-リボン-無い
- 牡(馬)-(人)気
といった関係性が出てるのはとても良いです。
まとめ
今回は掲示板データを使った共起分析というテーマでやってみました。課題はあるものの、自分だと見落としていたポイントなどを発見できたり、ほかの人の予想を確認できるという点では可能性を感じました。
とりあえず改善点として、
- 馬の名前は一つになるようにユーザ辞書の追加
- 競馬の用語は改めてユーザ辞書へ登録
- テキストの前処理をもう少し頑張る
- 表示するエッジの数を閾値を定めて表示する
といったところでしょうか。次の開催日にはまた良い結果を出せたらと思います。
参考文献
- netkeiba、https://www.netkeiba.com/
- 京都大賞典(G2) レース掲示板、https://race.netkeiba.com/race/bbs.html?race_id=202308020311&rf=special_sidemenu
- WindowsのMeCab+NEologdの入れ方、https://qiita.com/yakipudding/items/0372dc79bb5722fa4b8b