はじめに
前回の記事 Asakusa FrameworkとImpalaを連携してBIツールで可視化する では、Hadoop上で大規模なデータを処理することを想定したアーキテクチャの実装方式を紹介しました。
今回は、データベース上の業務データを Asakusa on M3BPへ連携するための実装方法を紹介します。
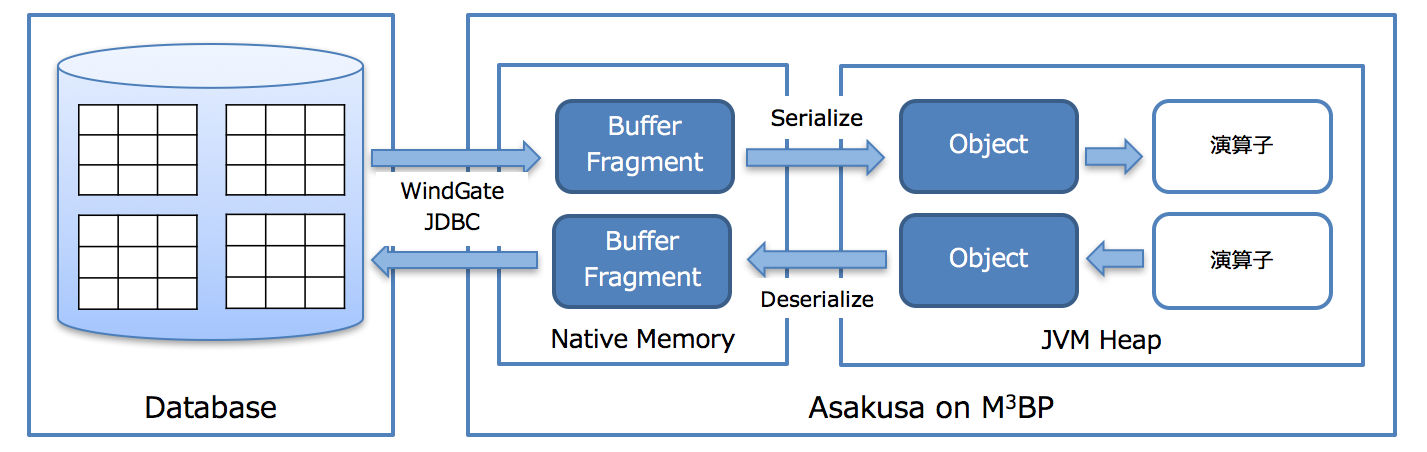
アーキテクチャの特徴をまとめると下図のようになります。
- DBのテーブルとM3BPはWindGate JDBCダイレクト・モードで連携します。テーブルのデータはネットワークを経由してM3BPプロセス上で管理されているバッファに直接入出力されます。
- Asakusa演算子の処理はJVMのマルチスレッド上で(デフォルトだとCPUコア毎)行われるためM3BPのバッファとJVMのHeap領域のオブジェクト間で Ser/Des が行われます。
- Disk I/O が発生しないため、メモリ上にデータが載りきる(約数十GB程度まで)場合は非常に高速です。(※筆者の実績でOracleのストアドプロシージャで数時間かかっていたのがM3BPへ移行することで数分まで短縮した事例があります)
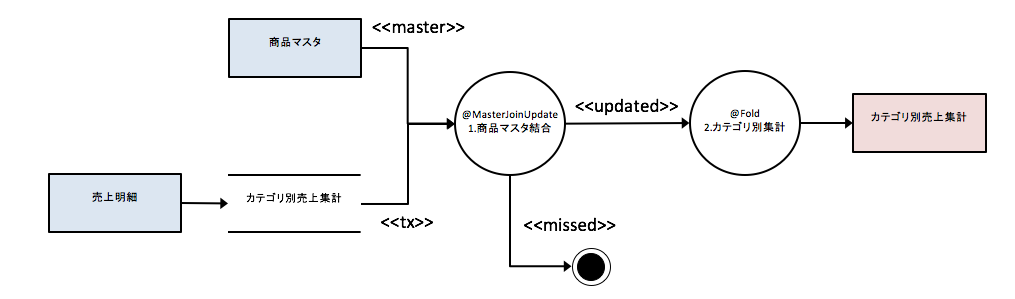
この記事でやりたいこと
サンプルアプリケーションは「売上明細」テーブルと「商品マスタ」テーブルをDBから入力してカテゴリ毎の販売金額を集計し、「カテゴリ別売上集計」テーブルへ出力します。
「1.商品マスタ結合」の処理
- 以下の条件で商品マスタを結合します。
- 売上明細.商品コード = 商品マスタ.商品コード かつ
- 商品マスタ.マスタ適用開始日 <= 売上明細.売上日時 かつ
- 売上明細.売上日時 <= 商品マスタ.マスタ適用終了日
- 以下をカテゴリ別売上集計に設定します。
- 商品マスタ.カテゴリーコード
- 商品マスタ.カテゴリー名
- 売上明細.数量 × 商品マスタ.単価を売上金額に設定
「2.カテゴリ別集計」の処理
カテゴリーコードをキーに数量、販売金額を合計する
入出力のテーブル定義は次のとおりです。
- 売上明細(SALES_DETAIL)
| 項目 | 型 | PK |
|---|---|---|
| 売上日時(SALES_DATE_TIME) | DATETIME | 〇 |
| 商品コード(ITEM_CODE) | VARCHAR(13) | 〇 |
| 数量(AMOUNT) | INT |
- 商品マスタ(ITEM_INFO)
| 項目 | 型 | PK |
|---|---|---|
| 商品コード(ITEM_CODE) | VARCHAR(13) | 〇 |
| 商品名(ITEM_NAME) | VARCHAR(128) | |
| カテゴリーコード(CATEGORY_CODE) | CHAR(4) | |
| カテゴリー名(CATEGORY_NAME) | CHAR(128) | |
| 単価(UNIT_PRICE) | INT | |
| マスタ登録日(REGISTERED_DATE) | DATE | |
| マスタ適用開始日(BEGIN_DATE) | DATE | 〇 |
| マスタ適用終了日(END_DATE) | DATE |
- カテゴリ別売上集計(CATEGORY_SUMMARY)
| 項目 | 型 | PK |
|---|---|---|
| カテゴリーコード(CATEGORY_CODE) | CHAR(4) | |
| カテゴリー名(CATEGORY_NAME) | CHAR(128) | |
| 数量(AMOUNT) | INT | |
| 売上金額(SELLING_PRICE) | INT |
動作環境
以下の環境で動作確認をしています。
- CentOS Linux release 7.4.1708
- MySQL Community Server Ver 5.7.21
- JDK 1.8.0_161
- Gradle 4.5.1
事前作業として、CentOS上に上記記載のソフトウェア(MySQL,JDK,Gradle)がインストール済であること。
ソースコードはGitHubにあります。
DBデータの準備
CREATE DATABASE demo;
CREATE USER demo@'%' IDENTIFIED BY 'demo';
GRANT ALL ON demo.* TO demo@'%';
CREATE USER demo@localhost IDENTIFIED BY 'demo';
GRANT ALL ON demo.* TO demo@localhost;
CREATE TABLE demo.SALES_DETAIL
(
SALES_DATE_TIME DATETIME NOT NULL COMMENT '売上日時',
ITEM_CODE VARCHAR(13) NOT NULL COMMENT '商品コード',
AMOUNT INT NOT NULL COMMENT '数量',
PRIMARY KEY(SALES_DATE_TIME, ITEM_CODE)
) COMMENT = '売上明細';
CREATE TABLE demo.ITEM_INFO
(
ITEM_CODE VARCHAR(13) NOT NULL COMMENT '商品コード',
ITEM_NAME VARCHAR(128) COMMENT '商品名',
CATEGORY_CODE CHAR(4) NOT NULL COMMENT 'カテゴリーコード',
CATEGORY_NAME VARCHAR(128) COMMENT 'カテゴリー名',
UNIT_PRICE INT NOT NULL COMMENT '単価',
REGISTERED_DATE DATE NOT NULL COMMENT 'マスタ登録日',
BEGIN_DATE DATE NOT NULL COMMENT 'マスタ適用開始日',
END_DATE DATE NOT NULL COMMENT 'マスタ適用終了日',
PRIMARY KEY(ITEM_CODE, BEGIN_DATE)
) COMMENT = '商品マスタ';
CREATE TABLE demo.CATEGORY_SUMMARY
(
CATEGORY_CODE CHAR(4) NOT NULL COMMENT 'カテゴリーコード',
CATEGORY_NAME VARCHAR(128) COMMENT 'カテゴリー名',
AMOUNT INT NOT NULL COMMENT '数量',
SELLING_PRICE INT NOT NULL COMMENT '売上金額'
) COMMENT = 'カテゴリ別売上集計';
INSERT INTO SALES_DETAIL VALUES ('2017-03-31 23:59:59','4922010001000',3);
INSERT INTO SALES_DETAIL VALUES ('2017-04-01 10:30:00','4922010001000',3);
INSERT INTO SALES_DETAIL VALUES ('2017-04-01 10:31:00','4922010001001',2);
INSERT INTO SALES_DETAIL VALUES ('2017-04-01 10:32:00','4922010001000',1);
INSERT INTO SALES_DETAIL VALUES ('2017-04-01 10:33:00','4922010001002',1);
INSERT INTO SALES_DETAIL VALUES ('2017-04-01 10:35:00','4922020002000',3);
INSERT INTO SALES_DETAIL VALUES ('2017-04-01 10:36:00','4922020002001',1);
INSERT INTO SALES_DETAIL VALUES ('2017-04-01 10:38:00','4922020002000',1);
INSERT INTO SALES_DETAIL VALUES ('2017-04-01 10:39:00','4922010001002',1);
INSERT INTO SALES_DETAIL VALUES ('2017-04-01 10:41:00','4922010001001',2);
INSERT INTO SALES_DETAIL VALUES ('2017-04-01 10:42:00','4922010001002',1);
INSERT INTO SALES_DETAIL VALUES ('2017-04-02 10:10:00','4922020002002',2);
INSERT INTO ITEM_INFO VALUES ('4922010001000','ミルクチョコレートM','1600','チョコレート菓子',120,'2017-04-01','2017-04-01','2018-01-19');
INSERT INTO ITEM_INFO VALUES ('4922010001000','ミルクチョコレートM','1600','チョコレート菓子',130,'2018-01-20','2018-01-20','2019-12-31');
INSERT INTO ITEM_INFO VALUES ('4922010001001','PREMIUM アソートチョコレート','1600','チョコレート菓子',330,'2017-04-01','2017-04-01','2019-12-31');
INSERT INTO ITEM_INFO VALUES ('4922010001002','アーモンドクランチミニ','1600','チョコレート菓子',140,'2017-04-01','2017-04-01','2019-12-31');
INSERT INTO ITEM_INFO VALUES ('4922020002000','カップ麺 しょうゆ','1401','カップ麺',98,'2017-04-01','2017-04-01','2019-12-31');
INSERT INTO ITEM_INFO VALUES ('4922020002001','カップ麺 塩','1401','カップ麺',98,'2017-04-01','2017-04-01','2019-12-31');
INSERT INTO ITEM_INFO VALUES ('4922020002002','カップ麺 カレー','1401','カップ麺',120,'2017-04-01','2017-04-01','2019-12-31');
commit;
作成したSQLファイルを反映します。
mysql -u demo -p demo < demo.sql
開発環境の準備
プロジェクトフォルダを作成します。このサンプルでは以下のフォルダ上で作業します。
mkdir asakusa-example-windgate
プロジェクトフォルダ配下にGradleスクリプトファイルを作成します。主に以下の設定を追加しています。
- Asakusa on M3BP Pluginの追加
- Windgate JDBC ダイレクト・モードの設定
- MySQLのJDBCライブラリをデプロイメントアーカイブファイルに含めるための設定
Gradleスクリプトの詳細については、Asakusa Gradle Plugin リファレンス を参照してください。
group 'com.example'
buildscript {
repositories {
maven { url 'http://asakusafw.s3.amazonaws.com/maven/releases' }
maven { url 'http://asakusafw.s3.amazonaws.com/maven/snapshots' }
}
dependencies {
classpath group: 'com.asakusafw.gradle', name: 'asakusa-distribution', version: '0.10.0'
}
}
apply plugin: 'asakusafw-sdk'
apply plugin: 'asakusafw-organizer'
apply plugin: 'asakusafw-m3bp'
apply plugin: 'eclipse'
asakusafw {
m3bp {
option 'm3bp.native.cmake.CMAKE_TOOLCHAIN_FILE', System.getProperty('m3bp.toolchain')
option 'windgate.jdbc.direct', '*'
}
}
asakusafwOrganizer {
profiles.prod {
hadoop.embed true
assembly.into('.') {
put 'src/dist/prod'
}
}
extension {
libraries += ['mysql:mysql-connector-java:5.1.45']
}
}
プロジェクトフォルダの下で、下記のGradleコマンドを実行してEclipseのプロジェクトとしてインポートします。なお、IntelliJ IDEAを利用したい場合は、公式のIntelliJの利用を参照してください。
なお、Eclipseを使うのであれば、Shafu(Asakusa開発用のEclipseプラグイン)の利用も検討してください。
gradle eclipse
M3BPの設定
M3BPの設定はm3bp.propertiesファイルに記述します。ここでは、WindGate JDBC ダイレクトモードのJDBCドライバーに関する設定を記述しています。
下記プロパティキーに含まれる example が入出力定義クラスに設定するprofileNameに該当します。
詳しくは、Asakusa on M3BPの最適化設定を参照してください。
com.asakusafw.dag.jdbc.example.url=jdbc:mysql://localhost/demo
com.asakusafw.dag.jdbc.example.driver=com.mysql.jdbc.Driver
com.asakusafw.dag.jdbc.example.properties.user=demo
com.asakusafw.dag.jdbc.example.properties.password=demo
データモデルクラスの生成
DMDL(Data Model Definition Language)スクリプトファイルを作成します。
入力モデルの「売上明細」・「商品マスタ」、出力モデルの「カテゴリ別売上集計」を定義しています。
データベースのカラムに対応するプロパティには、@windgate.jdbc.columnを指定します。
Windgateの設定については詳しくは、DataModelJdbcSupportの自動生成を参照してください。
"売上明細"
@windgate.jdbc.table(
name = "demo.SALES_DETAIL"
)
sales_detail = {
"売上日時"
@windgate.jdbc.column(name = "SALES_DATE_TIME")
sales_date_time : DATETIME;
"商品コード"
@windgate.jdbc.column(name = "ITEM_CODE")
item_code : TEXT;
"数量"
@windgate.jdbc.column(name = "AMOUNT")
amount : INT;
};
"商品マスタ"
@windgate.jdbc.table(
name = "demo.ITEM_INFO"
)
item_info = {
"商品コード"
@windgate.jdbc.column(name = "ITEM_CODE")
item_code : TEXT;
"商品名"
@windgate.jdbc.column(name = "ITEM_NAME")
item_name : TEXT;
"商品カテゴリコード"
@windgate.jdbc.column(name = "CATEGORY_CODE")
category_code : TEXT;
"商品カテゴリ名"
@windgate.jdbc.column(name = "CATEGORY_NAME")
category_name : TEXT;
"単価"
@windgate.jdbc.column(name = "UNIT_PRICE")
unit_price : INT;
"マスタ登録日"
@windgate.jdbc.column(name = "REGISTERED_DATE")
registered_date : DATE;
"マスタ適用開始日"
@windgate.jdbc.column(name = "BEGIN_DATE")
begin_date : DATE;
"マスタ適用終了日"
@windgate.jdbc.column(name = "END_DATE")
end_date : DATE;
};
"カテゴリ別売上集計"
@windgate.jdbc.table(
name = "demo.CATEGORY_SUMMARY"
)
category_summary = {
sales_date_time : DATETIME;
item_code : TEXT;
@windgate.jdbc.column(name = "CATEGORY_CODE")
category_code : TEXT;
@windgate.jdbc.column(name = "CATEGORY_NAME")
category_name : TEXT;
@windgate.jdbc.column(name = "AMOUNT")
amount : INT;
@windgate.jdbc.column(name = "SELLING_PRICE")
selling_price : INT;
};
以下のGradleコマンドを実行すると、作成したスクリプトファイルを元にAsakusa Frameworkで利用可能なデータモデルクラスが生成されます。(プロジェクトフォルダの下で実行してください)
gradle compileDMDL
入出力定義クラス
それぞれ入出力定義クラスには、m3bp.propertiesファイル内で定義したJDBCの設定に関連付けるためのprofileNameを設定します。
また、売上明細テーブルに関連するSalesDetailFromJDBC.javaクラスには、SQLのWHERE句に該当する条件式を追加しています。${DATE}にはバッチ起動時の引数の値が代入されます。
package com.example.jobflow;
import com.example.modelgen.dmdl.jdbc.AbstractSalesDetailJdbcImporterDescription;
public class SalesDetailFromJDBC extends AbstractSalesDetailJdbcImporterDescription {
@Override
public String getProfileName() {
return "example";
}
@Override
public String getCondition() {
return "SALES_DATE_TIME between '${DATE} 00:00:00' and '${DATE} 23:59:59'";
}
}
package com.example.jobflow;
import com.example.modelgen.dmdl.jdbc.AbstractItemInfoJdbcImporterDescription;
public class ItemInfoFromJDBC extends AbstractItemInfoJdbcImporterDescription {
@Override
public String getProfileName() {
return "example";
}
}
package com.example.jobflow;
import com.example.modelgen.dmdl.jdbc.AbstractCategorySummaryJdbcExporterDescription;
public class CategorySummaryToJDBC extends AbstractCategorySummaryJdbcExporterDescription {
@Override
public String getProfileName() {
return "example";
}
}
演算子クラスの作成
DFDに記述したプロセスの内、「1.商品マスタ結合」と「2.カテゴリ別集計」を演算子として実装します。
「1.商品マスタ結合」は、joinItemInfoメソッド(MasterJoinUpdate演算子)で実装しています。商品コードのみでは等価結合にならないので、マスタ選択条件を(MasterSelection補助演算子)で追加しています。
「2.カテゴリ別集計」は、summarizeByCategoryメソッド(Fold演算子)で実装しています。カテゴリーコードをキーに畳み込み処理をしながら数量と売上金額を集計しています。
package com.example.operator;
import java.util.List;
import com.asakusafw.runtime.value.Date;
import com.asakusafw.runtime.value.DateTime;
import com.asakusafw.runtime.value.DateUtil;
import com.asakusafw.vocabulary.model.Key;
import com.asakusafw.vocabulary.operator.Fold;
import com.asakusafw.vocabulary.operator.MasterJoinUpdate;
import com.asakusafw.vocabulary.operator.MasterSelection;
import com.example.modelgen.dmdl.model.CategorySummary;
import com.example.modelgen.dmdl.model.ItemInfo;
public abstract class SummarizeSalesOperator {
private final Date dateBuffer = new Date();
@MasterSelection
public ItemInfo selectAvailableItem(List<ItemInfo> candidates, CategorySummary sales) {
DateTime dateTime = sales.getSalesDateTime();
dateBuffer.setElapsedDays(DateUtil.getDayFromDate(
dateTime.getYear(), dateTime.getMonth(), dateTime.getDay()));
for (ItemInfo item : candidates) {
if (item.getBeginDate().compareTo(dateBuffer) <= 0
&& dateBuffer.compareTo(item.getEndDate()) <= 0) {
return item;
}
}
return null;
}
@MasterJoinUpdate(selection = "selectAvailableItem")
public void joinItemInfo(
@Key(group = "item_code") ItemInfo info,
@Key(group = "item_code") CategorySummary sales) {
sales.setCategoryCodeOption(info.getCategoryCodeOption());
sales.setCategoryNameOption(info.getCategoryNameOption());
sales.setSellingPrice(sales.getAmount() * info.getUnitPrice());
}
@Fold
public void summarizeByCategory(@Key(group = "category_code") CategorySummary left, CategorySummary right) {
left.setAmount(left.getAmount() + right.getAmount());
left.setSellingPrice(left.getSellingPrice() + right.getSellingPrice());
}
}
ジョブフロークラスの作成
DFDの設計に従って、「売上明細(sales)」と「商品マスタ(item)」を入力して「1.商品マスタ結合(joinItemInfo)」へ結線して「2.カテゴリ別集計(summarizeByCategory)」処理の結果を「カテゴリ別集計(categorySummary)」へ出力するように実装します。
package com.example.jobflow;
import com.asakusafw.vocabulary.flow.Export;
import com.asakusafw.vocabulary.flow.FlowDescription;
import com.asakusafw.vocabulary.flow.Import;
import com.asakusafw.vocabulary.flow.In;
import com.asakusafw.vocabulary.flow.JobFlow;
import com.asakusafw.vocabulary.flow.Out;
import com.asakusafw.vocabulary.flow.util.CoreOperatorFactory;
import com.example.modelgen.dmdl.model.CategorySummary;
import com.example.modelgen.dmdl.model.ItemInfo;
import com.example.modelgen.dmdl.model.SalesDetail;
import com.example.operator.SummarizeSalesOperatorFactory;
import com.example.operator.SummarizeSalesOperatorFactory.JoinItemInfo;
import com.example.operator.SummarizeSalesOperatorFactory.SummarizeByCategory;
@JobFlow(name = "summarizeSalesJob")
public class SummarizeSalesJob extends FlowDescription {
final In<SalesDetail> sales;
final In<ItemInfo> item;
final Out<CategorySummary> categorySummary;
public SummarizeSalesJob(
@Import(name = "sales", description = SalesDetailFromJDBC.class)
In<SalesDetail> sales,
@Import(name = "item", description = ItemInfoFromJDBC.class)
In<ItemInfo> item,
@Export(name = "result", description = CategorySummaryToJDBC.class)
Out<CategorySummary> categorySummary) {
this.sales = sales;
this.item = item;
this.categorySummary = categorySummary;
}
@Override
protected void describe() {
CoreOperatorFactory core = new CoreOperatorFactory();
SummarizeSalesOperatorFactory operator = new SummarizeSalesOperatorFactory();
JoinItemInfo joinedItem
= operator.joinItemInfo(item, core.restructure(sales, CategorySummary.class));
core.stop(joinedItem.missed);
SummarizeByCategory summarized = operator.summarizeByCategory(joinedItem.updated);
categorySummary.add(summarized.out);
バッチクラスの作成
ジョブフロー(SummarizeSalesJob)を実行するバッチクラスを実装します。
package com.example.batch;
import com.asakusafw.vocabulary.batch.Batch;
import com.asakusafw.vocabulary.batch.BatchDescription;
import com.example.jobflow.SummarizeSalesJob;
@Batch(name = "example.summarizeSales")
public class SummarizeBatch extends BatchDescription {
@Override
protected void describe() {
run(SummarizeSalesJob.class).soon();
}
}
アプリケーションのビルド、デプロイ
事前に、M3BPのビルド環境に必要なパッケージをインストールします。
sudo yum -y install cmake
sudo yum -y install make
sudo yum -y install gcc-c++
sudo yum -y install hwloc
下記例のように、.bash_profileなどに環境変数ASAKUSA_HOMEを設定します。
export ASAKUSA_HOME=$HOME/asakusa
プロジェクトフォルダからgradle assembleコマンドを実行してM3BP用のデプロイメントアーカイブファイルを作成します。
作成したファイルはASAKUSA_HOME環境変数のパス上に展開してsetup.jarコマンドを実行します。
gradle assemble
rm -rf $ASAKUSA_HOME
mkdir -p $ASAKUSA_HOME
cp ./build/asakusafw-*.tar.gz $ASAKUSA_HOME
cd $ASAKUSA_HOME
tar xzf asakusafw-*.tar.gz
java -jar $ASAKUSA_HOME/tools/bin/setup.jar
アプリケーションの実行
YAESSでバッチIDを引数に指定してアプリケーションをM3BP上で実行します。バッチパラメータ DATE に 2017-04-01を指定します。
入力定義クラスのSalesDetailFromJDBC.javaで設定した条件により、バッチ引数に指定した日付の売上明細データが処理対象になります。
$ASAKUSA_HOME/yaess/bin/yaess-batch.sh m3bp.example.summarizeSales -A DATE=2017-04-01
実行結果はCATEGORY_SUMMARYテーブルに登録されています。
mysql -u demo -p demo -e 'select * from CATEGORY_SUMMARY';
Enter password:
+---------------+--------------------------+--------+---------------+
| CATEGORY_CODE | CATEGORY_NAME | AMOUNT | SELLING_PRICE |
+---------------+--------------------------+--------+---------------+
| 1600 | チョコレート菓子 | 11 | 2220 |
| 1401 | カップ麺 | 5 | 490 |
+---------------+--------------------------+--------+---------------+
最後に
前々回の記事(Asakusa Frameworkで Hello, World!)ではWindows上のVanilla、前回の(Asakusa FrameworkとImpalaを連携してBIツールで可視化する)ではHadoop上のSpark、今回はM3BPについて、Asakusaの実行エンジンを紹介してきました。ここまでの記事を見て頂けたらおわかりかと思いますがソースコードの修正は必要なく、build.gradleのプラグイン設定を変更するたけで実行エンジンを切り替えることができます。
データの規模によってどのようなアーキテクチャが最適か検討する際に参考になれば幸いです。