はじめに
IBM iでの大容量のファイルを扱う際に、圧縮ファイルのやり取りができると便利です。圧縮ファイルと言えばzipが定番ですが、最近はより高圧縮な7z形式ファイルでデータの授受することが増えてきたので、IBM iで直接7zファイルを扱う方法を記します。
目標
IBM iで7z形式ファイルの圧縮と解凍ができるようになる
準備
IBM i にSSH接続
ssh username@[IBM i IP address / Host name]
p7zipをIBM iにインストール
yum install p7zip
※yumコマンドやp7zipが見つからない場合は、以下の記事を参考にRPM環境やリポジトリ―の準備を先に行ってください。
圧縮
TEST_2GB.FILEというSAVFをテストで使いました。オリジナルサイズは2,206 MiBです。
圧縮してみる(7z a [圧縮後のファイル名] [圧縮対象ファイル] ・・・)
7z a TEST_2GB.7z TEST_2GB.FILE
圧縮後は153 MiBになったので、圧縮率は93%でした。圧縮にかかった時間は約7分でした。
-rw-r--r-- 1 sugata 0 160866173 Dec 13 14:54 TEST_2GB.7z
-rw-r--r-- 1 sugata 0 2312395008 Nov 14 11:30 TEST_2GB.FILE
圧縮処理時のCPU負荷は高いです。QUSRWRK/QPOZSPWP ジョブでPGM-7z機能が圧縮ジョブとして動いてますが、この環境だとCPU使用率が130%くらいまで上がっていました。(Power9 0.25コア Uncapped環境なので、0.33コアくらい使っている計算になります)
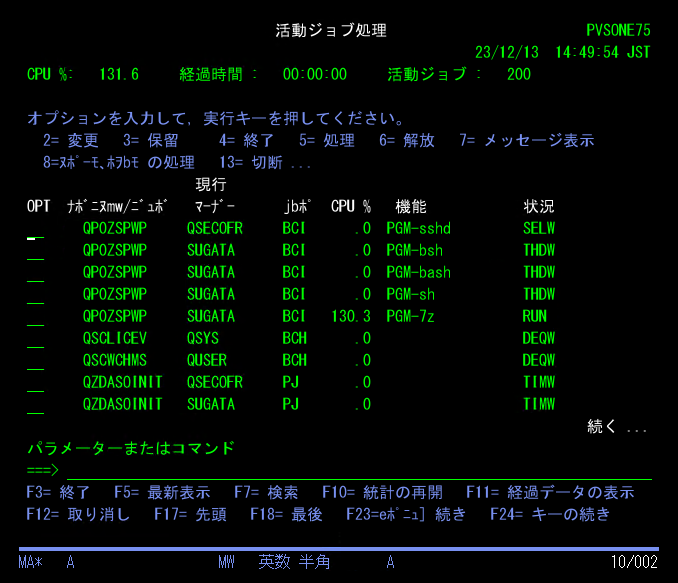
解凍(展開)
解凍してみる(7z x [解凍対象7zファイル])
7z x TEST_2GB.7z
解凍時もCPU使用率は130%くらいまで上がってました。しかし、解凍時間は早くて、25秒程度で完了しました。
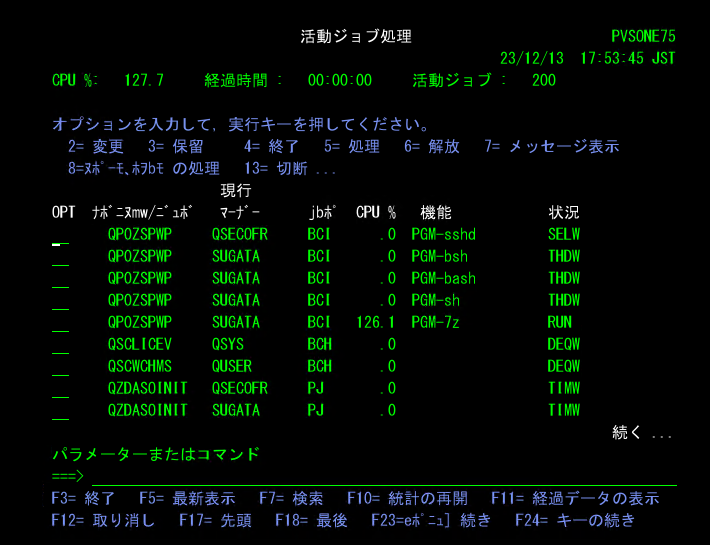
LIBオブジェクトの操作
圧縮も解凍もLIBに対して直接操作できます。7zファイル自体はIFSに置く前提です。
例:SAVFを圧縮してIFSに7zファイルを作成
7z a TEST_FROM_LIB.7z /QSYS.LIB/QIITA.LIB/TEST_2GB.FILE
例:IFSの7zファイルからLIBに直接SAVFを展開
7z x TEST_2GB.7z -o/QSYS.LIB/QIITA.LIB
最後に
今回は2GBほどのファイルで記事にしましたが、圧縮前200GB以上のファイルでも問題なく動くことを確認しています。7z形式は圧縮率が高いので、大きいファイルほど、そして回線帯域が厳しい環境ほど、7z形式でのファイル送受信の価値が出てくると思います。クラウド環境への移行を想定したパフォーマンステストを予定してますので、データが集まったタイミングでまた記事化したいと思います。
コマンドリファレンス
7-Zip 16.02 : Copyright (c) 1999-2016 Igor Pavlov : 2016-05-21
p7zip Version 16.02 (locale=C,Utf16=off,HugeFiles=on,64 bits,1 CPU BE)
Usage: 7z <command> [<switches>...] <archive_name> [<file_names>...]
[<@listfiles...>]
<Commands>
a : Add files to archive
b : Benchmark
d : Delete files from archive
e : Extract files from archive (without using directory names)
h : Calculate hash values for files
i : Show information about supported formats
l : List contents of archive
rn : Rename files in archive
t : Test integrity of archive
u : Update files to archive
x : eXtract files with full paths
<Switches>
-- : Stop switches parsing
-ai[r[-|0]]{@listfile|!wildcard} : Include archives
-ax[r[-|0]]{@listfile|!wildcard} : eXclude archives
-ao{a|s|t|u} : set Overwrite mode
-an : disable archive_name field
-bb[0-3] : set output log level
-bd : disable progress indicator
-bs{o|e|p}{0|1|2} : set output stream for output/error/progress line
-bt : show execution time statistics
-i[r[-|0]]{@listfile|!wildcard} : Include filenames
-m{Parameters} : set compression Method
-mmt[N] : set number of CPU threads
-o{Directory} : set Output directory
-p{Password} : set Password
-r[-|0] : Recurse subdirectories
-sa{a|e|s} : set Archive name mode
-scc{UTF-8|WIN|DOS} : set charset for for console input/output
-scs{UTF-8|UTF-16LE|UTF-16BE|WIN|DOS|{id}} : set charset for list files
-scrc[CRC32|CRC64|SHA1|SHA256|*] : set hash function for x, e, h commands
-sdel : delete files after compression
-seml[.] : send archive by email
-sfx[{name}] : Create SFX archive
-si[{name}] : read data from stdin
-slp : set Large Pages mode
-slt : show technical information for l (List) command
-snh : store hard links as links
-snl : store symbolic links as links
-sni : store NT security information
-sns[-] : store NTFS alternate streams
-so : write data to stdout
-spd : disable wildcard matching for file names
-spe : eliminate duplication of root folder for extract command
-spf : use fully qualified file paths
-ssc[-] : set sensitive case mode
-ssw : compress shared files
-stl : set archive timestamp from the most recently modified file
-stm{HexMask} : set CPU thread affinity mask (hexadecimal number)
-stx{Type} : exclude archive type
-t{Type} : Set type of archive
-u[-][p#][q#][r#][x#][y#][z#][!newArchiveName] : Update options
-v{Size}[b|k|m|g] : Create volumes
-w[{path}] : assign Work directory. Empty path means a temporary directory
-x[r[-|0]]{@listfile|!wildcard} : eXclude filenames
-y : assume Yes on all queries