こんにちは,sugarlです.
普段は大学では,Transformerを用いた数学タスクに関する研究をしています.
今回はDNNで稀にみられるgrokkingと呼ばれる検証ロスが訓練ロスに遅れて低下する現象について論文ベースで紹介します.
同様の内容をスライドにまとめているのでこっちも合わせてみてもらえると嬉しいです!
Grokkingとは?
学習データに汎化した後,モデルの汎化性能が向上する現象のことで,「遅効学習」とも呼ばれます.
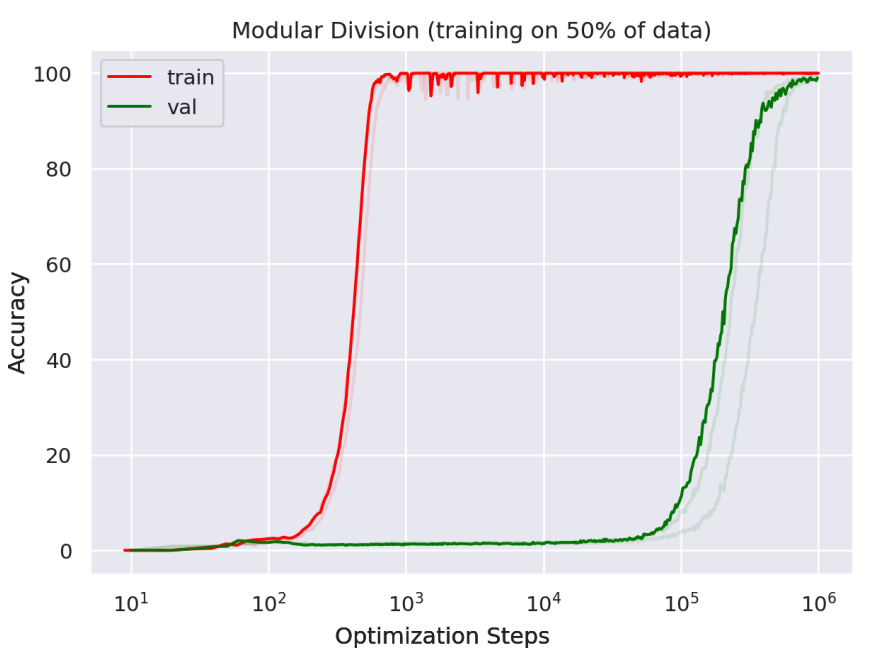
以下の図は1,000stepsでtrainの精度は100%近くになっているのに対してvalの精度は100,000stepsあたりでようやく伸び始めています.
このようにDNNではしばしばモデルのvalデータに対する汎化が遅れて発生することがあります.
Powerら[1]によってこの現象が発見された当初はTransformerの特定のタスクの場合のみ発生する現象だとされていました.
しかし,近年コンピュータビジョンのタスクや他のDNNモデルでもこの現象が確認されるようになり,DNN学習における一般的な性質であると考えられます.
LUメカニズムによってGrokkingが起きる?
Power[1]らの研究ではTransformerを用いてアルゴリズムタスク(モジュラ演算)を行う状況下で確認されており,Transformerの特定タスクに起こる現象だと考えられてきた.
しかし,Liu[2]らの研究によると画像分類や分子特性予測において
MLPやTransformer,GCNなどのモデルでGrokkingが発生することが確認された.
Liuらの発見したLUメカニズムによってGrokkingは説明でき,これによるとモデルの重みのスケールと正則化がGrokking発生に影響すると考えられる.
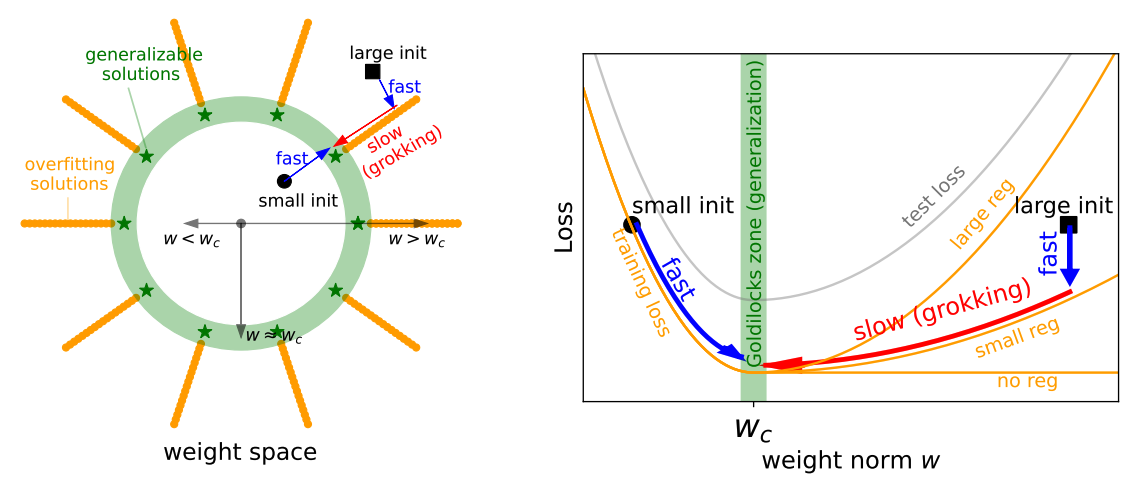
まず,一般的に重み空間上の汎化解は下図(a)の緑の領域で描かれた部分にあると言われる.
緑円で描かれた領域の内側は重みスケールが汎化解より小さく,逆に縁の外側は重みスケールが汎化解より大きい.
仮に,汎化解よりも小さいスケールで重みを初期化した場合はGrokkingは発生せず,通常通り訓練ロスとテストロスが低下する.
ちなみにLiuらの論文では下の右図のtraining lossとtest lossがそれぞれL字とU字の形をしていることから”LUメカニズム”と呼ばれた.
また,Grokkingは訓練データ数や取り組むタスクの表現にも影響を受け発生する.
訓練データ数が多くなることでGrokkingは起こりづらくなり,逆にデータ数が少ない場合はGrokkingが発生しやすい.
取り組むタスクは足し算のような数学タスクの方がモデルの中間表現に対する依存性が高くなりGrokkingが起こりやすくなる.
敵対的訓練でもGrokkingは起きる?
通常訓練した深層学習モデルは敵対的なノイズに弱く簡単に騙せることが知られている.(敵対的攻撃や訓練に関して詳しく知りたい場合は別記事[4][5]を参照していただきたい)
敵対的訓練はモデルをこのような敵対的なノイズに強くする訓練手法を指す.
このような訓練では通常の訓練のテスト精度とは別に頑健性を測る精度がある.
Humayun[3]らの研究ではこの頑健性精度がテスト精度に比べて遅れて向上する現象を発見しました.
実験ではLiuらの研究の結果を踏襲し,Grokkingが起きやすくするため,モデルの重みスケールを通常より大きくして敵対的訓練を行っていた.
そのため,Humayunらの結果は敵対的訓練でのGrokkingとして捉えることができる.
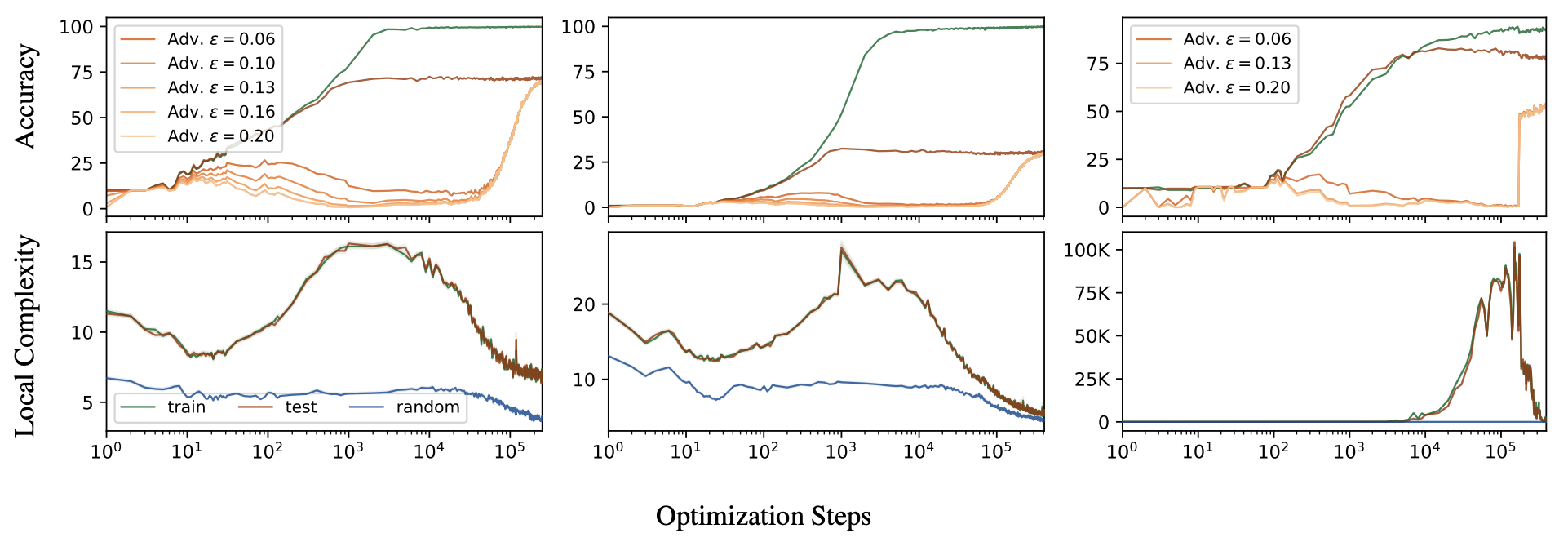
上の図のAccuracyグラフを見ると敵対的訓練でもGrokkingが起きていることがわかる.
次に,この図内にもある”Local Complexity”という指標について説明する.
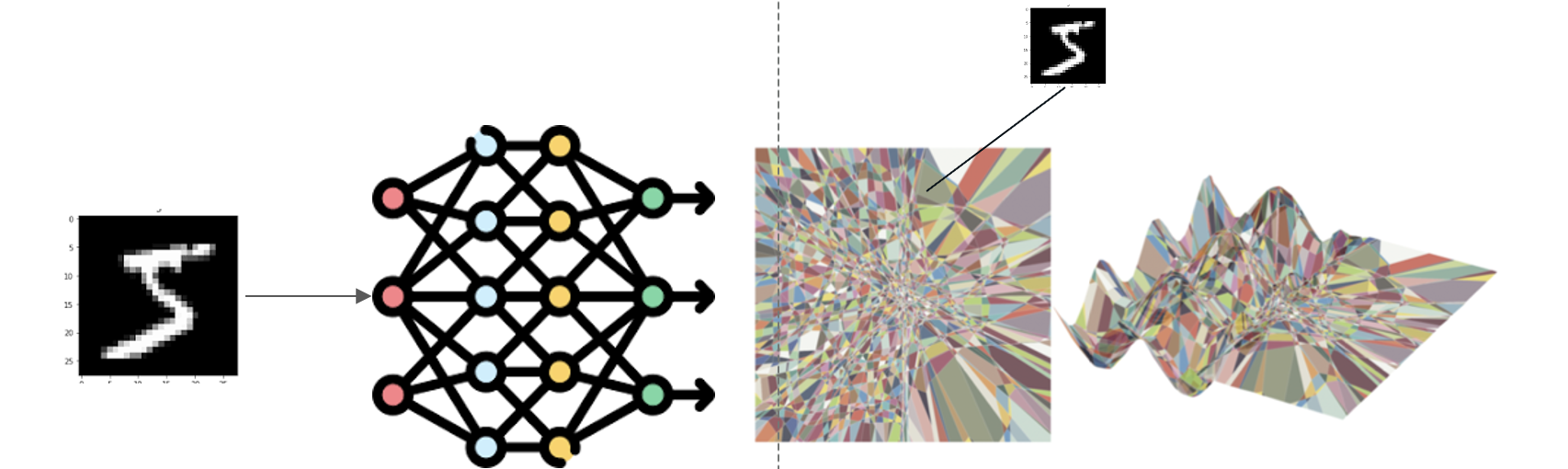
DNNは下図のように入力データを異なる領域にプロットします.
図内の色のついている領域は区分線形領域と呼ばれる.
Humayunらはデータを入力した時のデータ周囲の区分線形領域の数を測ることで入力空間上での複雑度を示す”Local Complexity”という指標を提案した.
上の図を見ると頑健性精度に関してGrokkingが起きている時にLocal Complexityが低下している.
つまり,Grokkingが起きる時は入力データ周辺の複雑度が低下していることがわかる.
まとめ
今回は,DNNで稀にみられる現象Grokkingに関して関連論文をもとに説明していきました.
DNNにおける興味深い性質であるGrokkingに関する説明は最近積極的に研究されているようです.
しかし,まだ完全には解明されておらず,それぞれの論文の説明は限界があるように感じました.
個人的には数学的なタスクはGrokkingが起こりやすい点に興味があり,現状のDNNは数学の問題を学習ベースで解くためにはわかっていない部分が多いのだと感じました.
今後の研究の進展が楽しみです!
参考文献
- [1] GROKKING: GENERALIZATION BEYOND OVERFITTING ON SMALL ALGORITHMIC DATASETS, A.Power et al., https://arxiv.org/pdf/2201.02177
- [2] Omnigrok: Grokking Beyond Algorithmic Data, Z.Liu et al., https://arxiv.org/abs/2210.01117
- [3] Deep Networks Always Grok and Here is Why, A.Humayun et al., https://arxiv.org/pdf/2402.15555
- [4] 敵対的学習 (Adversarial Training), https://www.mbsd.jp/aisec_portal/defense_adversarial_training.html
- [5] AI セキュリティと敵対的サンプルの脅威, https://www.nri-secure.co.jp/blog/hostile-sample#:~:text=%E7%B4%B9%E4%BB%8B%E3%81%97%E3%81%BE%E3%81%99%E3%80%82-,%E6%95%B5%E5%AF%BE%E7%9A%84%E3%82%B5%E3%83%B3%E3%83%97%E3%83%AB%E3%81%A8%E3%81%AF,%E7%94%BB%E5%83%8F%E3%81%AA%E3%81%A9%E3%82%92%E6%8C%87%E3%81%97%E3%81%BE%E3%81%99%E3%80%82
- [6] 【論文瞬読】深層学習モデルの『遅効学習』の謎に迫る - Grokkingの新たな発見, https://note.com/ainest/n/n924c71cf7d93