はじめに
Mars Flag Advent Calendar 2023 25日目担当の菅です。機能に引き続きよろしくお願いします。
前回は、弊社マーズフラッグが検索を扱う会社であることから、24日では、検索OSSであるSolrを使って、検索の体験をできる環境を整えました。
今回は、日本語を検索する際に必ずといっていいほど必要になってくるtokenizeについて体験してみましょう!!
※本記事は、「Solr入門(Solrを動かしてみよう!!)
」にて作成した環境で実施しています。
1. tokenizeとは
文章を単語に分割することを「tokenize」と言います。
検索を行う際にSolr側で文章をそのまま理解することができないため、tokenize等の前処理を行い、検索精度を高めます。
今回は、日本語検索でよく用いられる
- 意味ベースでtokenizeする形態素解析
- 文字数ベースでtokenizeするNgram
の二つを体験してみましょう。
2. 形態素解析
2-a. 形態素解析とは
形態素解析とは、事前に用意した辞書を用いて、文章内の単語毎(形態素)に分割することを言います。
関西国際空港
↓
関西 | 国際 | 空港
Solrでは、形態素解析を用いることで、検索語内の単語を分析し、検索の意図を汲んだキーワードマッチングに役立ちます。
ただし、辞書上に載っていない固有名詞などの単語を分析できない欠点もあります。
2-a. 形態素解析を使ってみよう
Solrでは日本語に対する形態素解析が標準で搭載されていますので今回はそちらを試してみます。
1. http://localhost:8983/solr/#/gettingstarted/analysis上にアクセスし、
「Field Value (Index)」に関西国際空港と入力
2. 「Analyse Fieldname / FieldType」に「text_ja」を選択し「Analyse Values」ボタンをクリック
形態素解析結果が表示されます
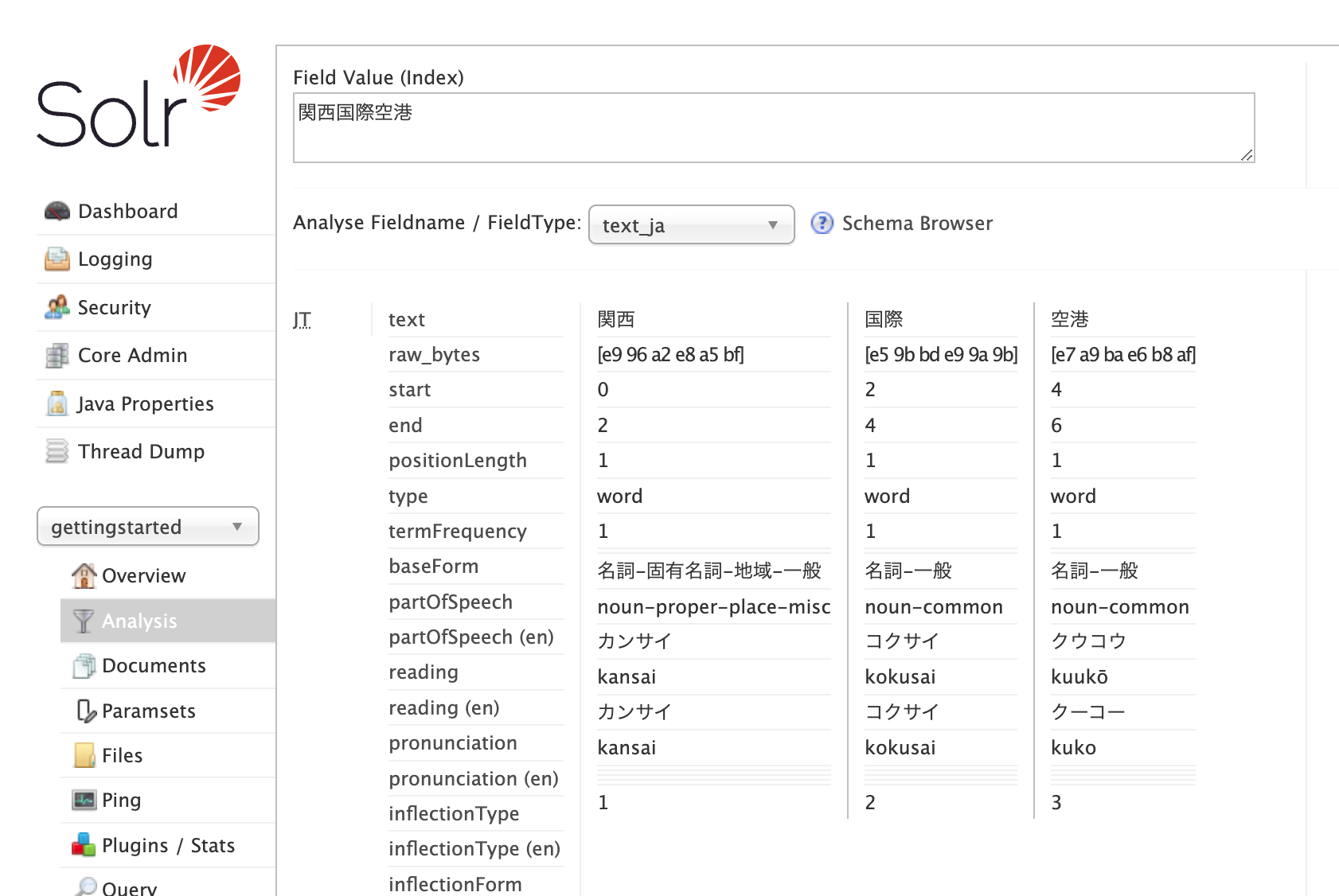
分割されている様子が確認できます。
3. Ngram
3-a. Ngramとは
意味を考慮するNgramに対し、意味を考慮せず単語をN文字毎に分割し検索を行う手法です
例えば、「関西国際空港」をN=2で分割すると下記の様になります
関西国際空港
↓
関西 | 西国 | 国際 | 際空 | 空港
Solrでは、Ngramを用いいることで検索漏れを防ぎます。
ただし、Nを小さくするほど検索数が増える一方、欲しくない情報も検索に引っかかってしまう検索ノイズが発生しやすくなります。
3-b. Ngram用Tokenizerの作成
残念ながら標準にNgramのみのtokenizerがないため、tokenizerの作成を行います。
1. http://localhost:8983/solr/#/gettingstarted/schemaにアクセスし、
「Manipulate Field Type」ボタンをクリック。
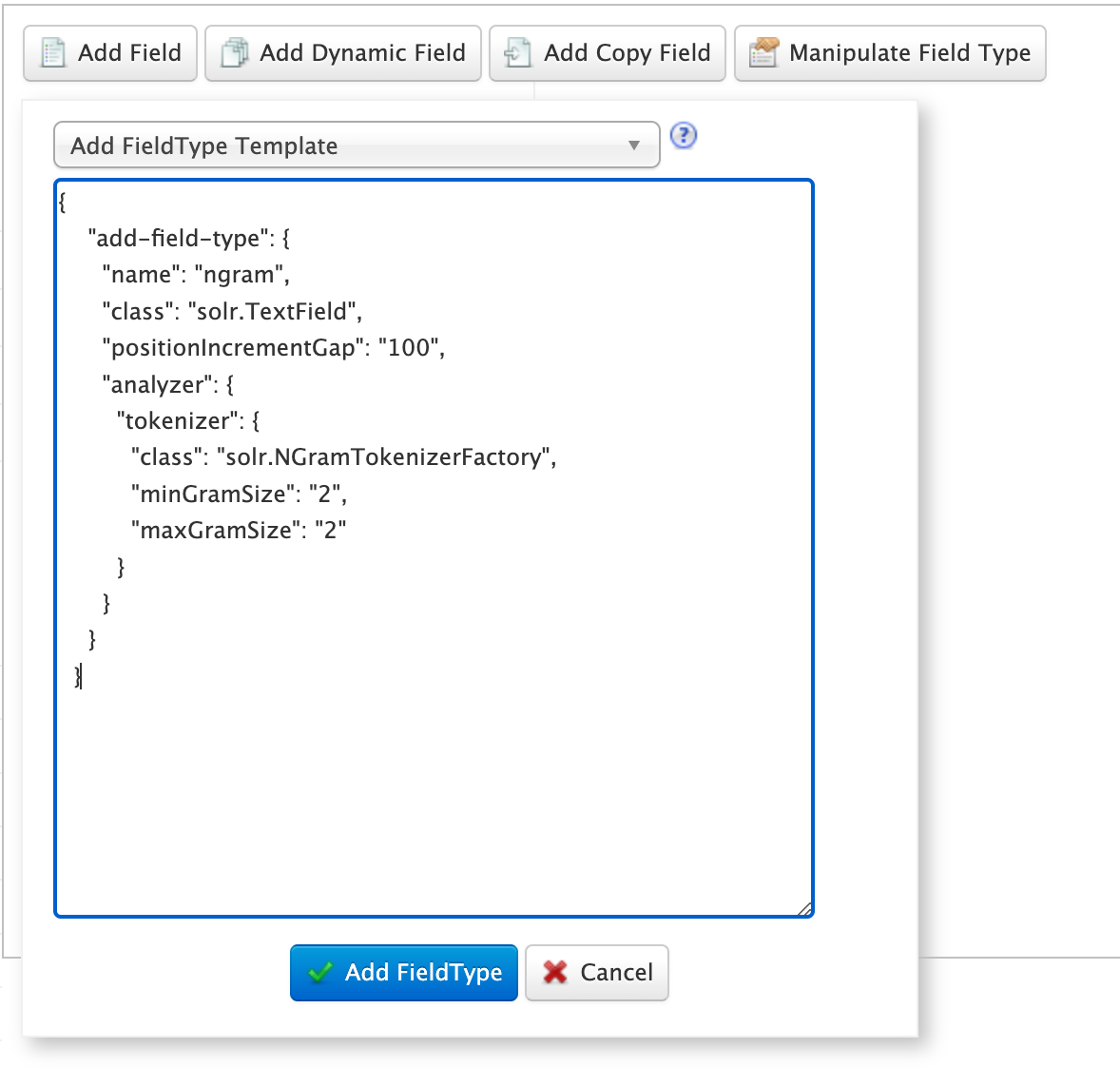
2. 表示されるeditorに下記を入力
{
"add-field-type": {
"name": "nGram",
"class": "solr.TextField",
"positionIncrementGap": "100",
"analyzer": {
"tokenizer": {
"class": "solr.NGramTokenizerFactory",
"minGramSize": "2",
"maxGramSize": "2"
}
}
}
}
参考: https://solr.apache.org/guide/solr/latest/indexing-guide/tokenizers.html#n-gram-tokenizer
3. 「Add FiledType」をクリック
3-c. Ngramを使ってみよう
作成したnGramを試してみます。
1. http://localhost:8983/solr/#/gettingstarted/analysis上にアクセスし、
「Field Value (Index)」に関西国際空港と入力
2. 「Analyse Fieldname / FieldType」に「nGram」を選択し「Analyse Values」ボタンをクリック

分割されている様子が確認できます。