この記事について
先日、AWS Amplify AI kitが公開され、Bedrockのモデルを活用したAI機能を数行のコードで簡単に実装できるようになりました。
今回はawsが公開してる、AWS Amplify AI kitを使ったサンプルを改変してknowledgeBaseと統合してみたので、その紹介をしたいと思います。
今回作成したリポジトリは以下です。
knowledgeBaseを使ったことがある人を対象読者として想定しています。使ったことがない人向けの記事は後日作成予定です🙏
基本のチャット機能
chat: a.conversation({
aiModel: a.ai.model("Claude 3.5 Sonnet"),
systemPrompt: `You are a helpful assistant`,
})
.authorization((allow) => allow.owner()),
Amplifyのデータスキーマに、Conversationのroutes設定をこのように行うと、ストリーミングの対話APIが作成することができます。このconversationにはtoolを設定することができます。(ドキュメント)。このtoolにretrieveをする関数(Query tools)を設定することで、RAGを構築します。
RAGの構築
1.knowledgeBaseの作成
Amplifyには、knowledgeBaseをデータスキーマやストレージのように簡潔に定義できる機能はないので、custom resourcesを使って定義します。(ドキュメント)
amplify/custom/下に以下のようにknowledgeBaseの定義をします。
import { appConfig } from "./../../config";
import { v4 as uuidv4 } from "uuid";
import { Construct } from "constructs";
import * as iam from "aws-cdk-lib/aws-iam";
import * as bedrock from "aws-cdk-lib/aws-bedrock";
interface KnowledgeBaseProps {
storageArn: string;
}
export class KnowledgeBase extends Construct {
public readonly knowledgeBaseId: string;
constructor(scope: Construct, id: string, props: KnowledgeBaseProps) {
super(scope, id);
const {
pineconeEndpoint,
pineconeApiKeySecretArn,
embeddingModelArn,
} = appConfig;
const uid = uuidv4();
const knowledgeBaseRole = new iam.Role(this, `KnowledgeBaseRole`, {
roleName: `knowledgeBase-role-${uid}`,
assumedBy: new iam.ServicePrincipal("bedrock.amazonaws.com"),
inlinePolicies: {
inlinePolicy1: new iam.PolicyDocument({
statements: [
new iam.PolicyStatement({
resources: [pineconeApiKeySecretArn],
actions: ["secretsmanager:GetSecretValue"],
}),
new iam.PolicyStatement({
resources: [embeddingModelArn],
actions: ["bedrock:InvokeModel"],
}),
new iam.PolicyStatement({
resources: [props.storageArn, `${props.storageArn}/*`],
actions: ["s3:ListBucket", "s3:GetObject"],
}),
],
}),
},
});
const knowledgeBase = new bedrock.CfnKnowledgeBase(this, "KnowledgeBase", {
knowledgeBaseConfiguration: {
type: "VECTOR",
vectorKnowledgeBaseConfiguration: {
embeddingModelArn,
},
},
name: `knowledgeBase-${uid}`,
roleArn: knowledgeBaseRole.roleArn,
storageConfiguration: {
pineconeConfiguration: {
connectionString: pineconeEndpoint,
credentialsSecretArn: pineconeApiKeySecretArn,
fieldMapping: {
metadataField: "metadata",
textField: "text",
},
},
type: "PINECONE",
},
});
this.knowledgeBaseId = knowledgeBase.ref;
new bedrock.CfnDataSource(this, "BedrockKnowledgeBaseDataStore", {
name: `knowledgeBase-data-source-${uid}`,
knowledgeBaseId: knowledgeBase.ref,
dataSourceConfiguration: {
s3Configuration: {
bucketArn: props.storageArn,
inclusionPrefixes: ["rag-resources/"],
},
type: "S3",
},
});
}
}
ベクトルDBを変更したい場合は、storageConfigurationを変更してください。
これを、createStack()で既存のリソースと統合します。
const knowledgeBaseStack = backend.createStack("knowledgeBase");
const knowledgeBase = new KnowledgeBase(knowledgeBaseStack, "KnowledgeBase", {
storageArn: backend.storage.resources.bucket.bucketArn,
});
2.retrieveするためのHTTP resolverを作成する。
実際にtoolとして使用するためのHTTP resolverをamplify/data/resolvers/kbResolver.jsに作成します。
export function request(ctx) {
const { input } = ctx.args;
return {
resourcePath: "/knowledgebases/<your-knowledgeBase-id>/retrieve",
method: "POST",
params: {
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({
retrievalQuery: {
text: input,
},
}),
},
};
}
export function response(ctx) {
const responseBody = JSON.parse(ctx.result.body);
const retrievalResults = responseBody.retrievalResults || [];
const texts = retrievalResults.map(result => result.content.text);
return JSON.stringify(texts);
}
ドキュメントでは、response()が
export function response(ctx) {
return JSON.stringify(ctx.result.body);
}
と定義されていますが、これだとtokenの量が多くなりすぎて処理が重くなってしまったので、textのみを返しています。(レスポンスの型)
作成したファイルをエントリポイントとして、スキーマに加えます。
knowledgeBase: a
.query()
.arguments({ input: a.string() })
.handler(
a.handler.custom({
dataSource: "KnowledgeBaseDataSource",
entry: "./resolvers/kbResolver.js",
}),
)
.returns(a.string())
.authorization((allow) => allow.authenticated()),
次に、これをtoolとして使えるように、定義してあるchatに加えます。
chat: a.conversation({
aiModel: a.ai.model("Claude 3 Haiku"),
systemPrompt: `You are a helpful assistant`,
+ tools: [
+ a.ai.dataTool({
+ name: 'searchDocumentation',
+ description: 'Performs a similarity search over the documentation',
+ query: a.ref('knowledgeBase'),
+ }),
]
})
.authorization((allow) => allow.owner()),
最後にbackend.tsでHTTP resolverがretirveするための設定を行います。
const KnowledgeBaseDataSource = backend.data.resources.graphqlApi.addHttpDataSource(
"KnowledgeBaseDataSource",
`https://bedrock-agent-runtime.${cdk.Stack.of(backend.data).region}.amazonaws.com`,
{
authorizationConfig: {
signingRegion: cdk.Stack.of(backend.data).region,
signingServiceName: "bedrock",
},
}
);
KnowledgeBaseDataSource.grantPrincipal.addToPrincipalPolicy(
new PolicyStatement({
resources: [
`arn:aws:bedrock:${
cdk.Stack.of(backend.data).region
}:<your-aws-accountId>:knowledge-base/${knowledgeBase.knowledgeBaseId}`,
],
actions: ["bedrock:Retrieve"],
})
);
実際に動かしてみる
-
事前準備
1.pineconeのアカウントを作成し、dimensionsが1024のindexを作成する。(こちらを参考にしてください)
2.pineconeのapi keyをシークレットマネージャーに保存する。(こちらを参考にしてください) -
環境構築
1.リポジトリをcloneして、npm installもしくはyarnでパッケージをインストールします。
2.claude-ai/amplify/config.tsに事前準備で作ったpineconeのエンドポイントをpineconeEndpointに、シークレットマネージャーのarnをpineconeApiKeySecretArnに入れます。
また、claude-ai/amplify/backend.tsに構築先のawsのユーザーIDを<your-aws-accountId>に入れます。
3.sandbox環境を立ち上げます。
cd claude-ai && npx ampx sandbox
4.awsのコンソールからbedrock→knowledgeBaseへ移動し、作成されたknwoledgeBaseのidをclaude-ai/amplify/data/resolvers/kbResolver.jsの<your-knowledgeBase-id>に入れます。
5.コンソールのknowledgeBaseからソースリンクへ行き、RAGの参照資料をアップロードします。(サポートしているファイル)
6.アップロードが完了したら、同期ボタンを押し、同期を完了させます。
- チャットしてみる
-
claude-ai/でnpm run devもしくはyarn devを実行しlocalhostを立ち上げます。 - 次のような画面が表示されるので、アカウントを作成します。
3.Create Chatボタンを押して、アップロードしたドキュメントに沿った質問をしてみましょう。
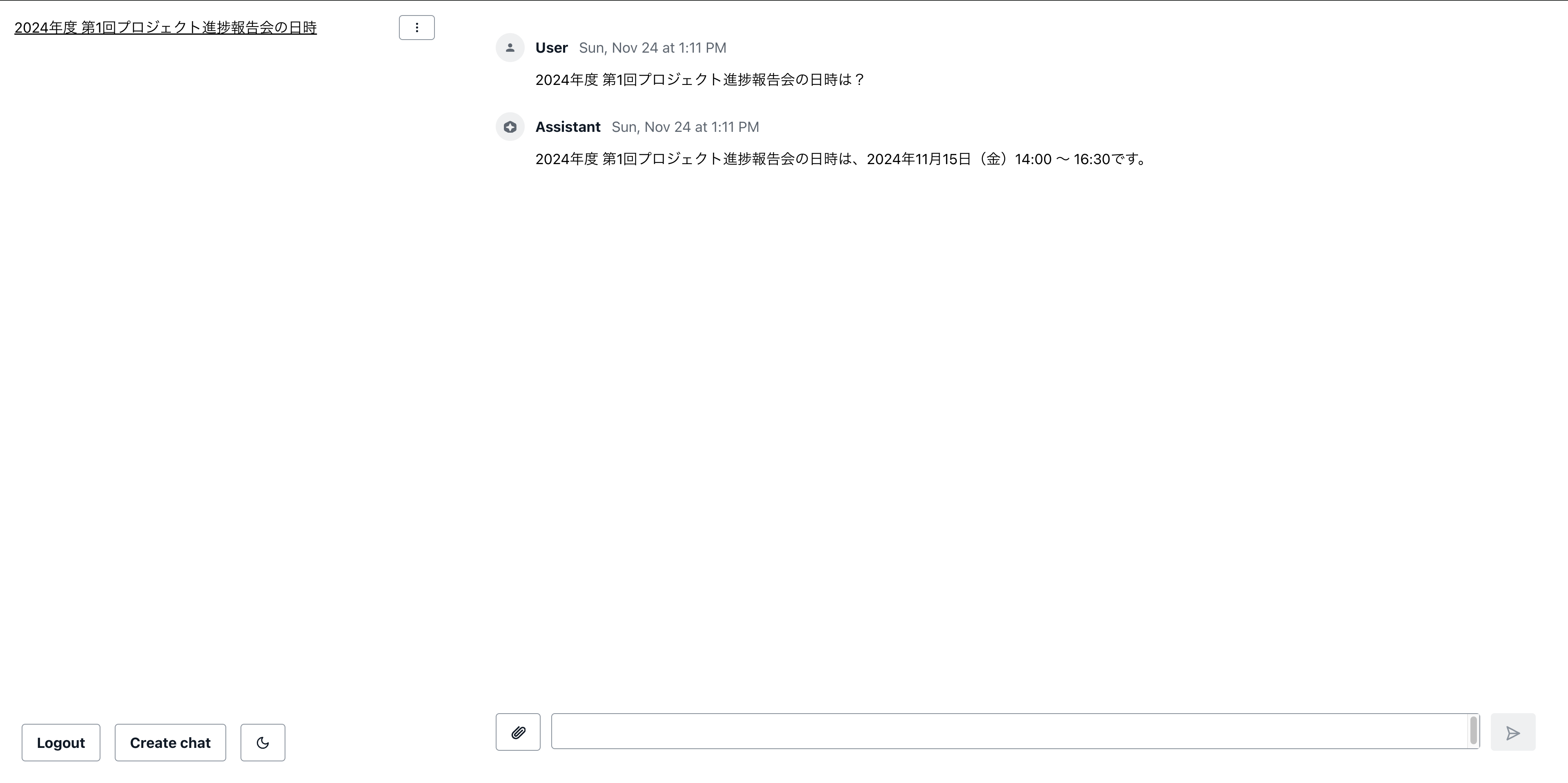
ここでは、アップロードしてあった架空の議事録ファイルについて答えることができることが確認できました!
リソースの削除
作ったリソースは忘れずに削除しましょう。以下のコマンドで削除できます。
npx ampx sandbox delete
最後に
公開されたAmplify AI kitにはまだまだ機能があるので、試したいと思います。
改善案や質問等あればコメントお願いします!