2年前にプチ話題になったアレです
過去の記事
2年前に書いた時から若干アップデートがあるのでそれについても書きたいと思います。
ボットでやっていること
- 1時間に1回、提供先企業一覧のPDFをダウンロードできるページにいく
- PDFをダウンロードして提供先企業一覧を取得
- スクレイピングだけでいけると思ったらPDFで提供されていたのでparseするのが大変だったw
- 新着があればボットでつぶやく
ってだけです。
ちなみにPDFをダウンロードしてスクレイピングするロジックは2年間で一切手を加えていませんが、だいたい動いているようです。
使っている技術
- ruby
-
Padrino Framework
- 全部入りのRails と シンプルな Sinatra の中間くらいのフレームワーク
- リリース当時はスクレイピングとボットのみだったのでpadrinoはおろかsinatraすら不要だったのですが、スキーマのmigrationを自前で実装するのが嫌だったのでpadrinoを採用
- 後からwebを追加したくなったので(後述)、結果的にはpadrino使ったのは正解だった
- Heroku
HTMLのスクレイピング
Mechanize を使ってます。
- メリット
- 軽い
- Ruby単体で動く
- デメリット
- htmlのbodyのparseしかしないので、jsでDOMが操作されている場合には使えない
Ajaxがふんだんに使われたページをスクレイピングするには phantomjs + Capybara + poltergeist の組み合わせが鉄板だと思います。(が、phantomjsはデバッグしづらいのが。。。)
参考: Rails4 + Capybara + PhantomJS (poltergeist) なテスト環境 - (゚∀゚)o彡 sasata299's blog
実際のソースコードで解説します
def download_ccc_pdf(dest_pdf_file)
# mechanizeのインスタンスを初期化
agent = Mechanize.new
# http://qa.tsite.jp/faq/show/25129 を開く
agent.get("http://qa.tsite.jp/faq/show/25129")
# <a href="/attachment_file/〜.pdf"> のようなリンクを探す
download_link = agent.page.link_with(href: %r(/attachment_file/.+\.pdf))
# リンクが見つからなければエラー
raise "Not found download_link" unless download_link
# リンク先のPDFをダウンロードしてファイルに保存する
pdf_content = agent.get_file(download_link.href)
File.open(dest_pdf_file, "wb") do |file|
file.write(pdf_content)
end
end
pdfのスクレイピング
pdf-reader というgemを使ってます。
pdfをrubyから読むためのgemはいくつか使ってみたのですが、今回はこのgemじゃないとうまくテキストで取得出来ませんでした。(cccのpdfはExcelをpdfに変換してるみたいなのですが、他のgemだとセルの中のテキストが列単位でしか取得できない。pdf-readerだとpdfとしてレンダリングされる時の実際の座標もある程度考慮してくれる模様)
ダウンロードしたpdfをテキストで読み込む
def read_pdf(pdf_file)
pdf_content = ""
reader = PDF::Reader.new(pdf_file)
reader.pages.each do |page|
pdf_content << page.text
end
pdf_content
end
これ自体は特別なことをしていないんですが、そのままだと下記のようにpdf内の日付がうまく取得できませんでした
1 TSUTAYA・蔦屋書店 2014/10/2提携先:TSUTAYAフランチャイズチェーン加盟企業
2 JX日鉱日石エネルギー株式会社 2014/10/2提携先:ENEOS
3 株式会社アプラス 2014/10/2提携サービス:Tカードプラス, Tカードプラスα ,TSUTAYAWカード
4 株式会社Misumi 2014/10/2提携先:BOOKSmisumi,Misumiグループ(ガス・水)
5 JR九州ドラッグイレブン株式会社 2014/10/2提携先:ドラッグイレブン
モンキーパッチで文字描画の位置を無理矢理変えて対応してます。
class PDF::Reader::PageLayout
# fix rate: 1.05 -> 1.5
def col_count
@col_count ||= ((@page_width / @mean_glyph_width) * 1.5).floor
end
end
pdfを文字列で取得でした後は正規表現でparseしてます
def parse_ccc_pdf(pdf_file)
companies = []
read_pdf(pdf_file).each_line do |line|
line = line.strip
matched_data = %r(
^(?<no>[0-9]+)\s*
(?<company_name>.+)\s*
(?<receipted_date>[0-9]{4}/[0-9]{1,2}/[0-9]{1,2})
(?<destination_name>.+)$)x.match(line)
next unless matched_data
companies << Company.new(
no: matched_data[:no].to_i,
company_name: matched_data[:company_name].strip,
receipted_date: matched_data[:receipted_date].strip,
destination_name: matched_data[:destination_name].strip,
)
end
companies
end
ソースコード中の正規表現の
%r(
^(?<no>[0-9]+)\s*
(?<company_name>.+)\s*
(?<receipted_date>[0-9]{4}/[0-9]{1,2}/[0-9]{1,2})
(?<destination_name>.+)$)x.match(line)
は
/^([0-9]+)\s*(.+)\s*([0-9]{4}\/[0-9]{1,2}\/[0-9]{1,2})(.+)$/ =~ line
と同等ですが下記のような工夫があります
-
$1や$2だと分かりづらいので(?<no>[0-9]+)や(?<company_name>.+)のように名前付きキャプチャを使う -
/〜/だと正規表現内にスラッシュがあるとエスケープしないといけないので%r(〜)を使う
クローラ
作った当初は
- Heroku schedulerの無料枠は1日1回実行のみ。(1時間に1回実行は有料)
- インスタンスを24時間フル稼働していても無料
ということもあり sidekiq-cron のプロセスを常駐して30分に1回実行していたのですが、2015年4月頃 1 に新しい料金体系が発表され
- 24時間インスタンスを起動し続けると有料になる
- その代わりHeroku schedulerが無料でも1時間に1回動かせるようになった
ということになり、Heroku Schedulerで1時間に1回動かすようにしています。
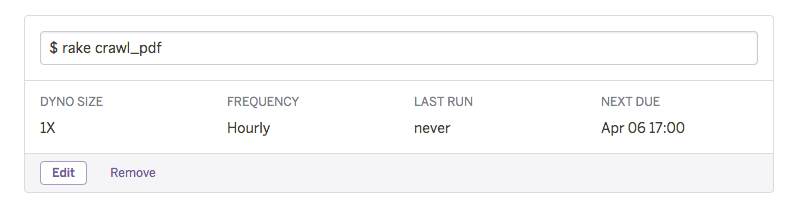
元々workerで実行してた頃の名残で、rake task内でworkerのインスタンスを perform しています。
desc "crawl pdf"
task :crawl_pdf => :environment do
PdfCrawlWorker.new.perform
end
web画面
特にどこにもアナウンスしていなかったですが、レコードを見るのにローカルから padrino console するだけだと不便だったのでwebで見れるようにしています。
自分が見れればいい感あったので画面は雑です
-
自分が対応した日付より推測 https://github.com/sue445/ccc_privacy_crawler/pull/25 ↩