電子書籍ってやっぱいい!
エンジニアは技術書をいっぱい保持したり、参照することが社内外問わず多いと思います。
初心者エンジニアの自分でも紙や電子書籍でいろいろ調べます。
ただ、いちいちリュックにいれてたらつらいので電子書籍で持ち運びたい。
できれば、kindleとかkoboとか特定の形式でなくepub/pdf形式で欲しい...
ただ、いちいち検索ボックスに入力するのたるいなーってなったわけです
そこでselenium
ブラウザの自動操作を可能にしてくれます htmlのタグの要素を出力するとか、クリックするとか
これ使えばいいんじゃないかと考えたわけです
ただ、今回は難しいことは使わず、電子書籍の検索結果のURLはほとんど定型なので、それを一部利用してquery部分のみ変更+seleniumでその検索結果をばんばん出してやります
セットアップ
python3は入っている前提
seleniumインストール
pip install selenium
webdriverのダウンロード
https://sites.google.com/a/chromium.org/chromedriver/downloads
上記サイトから自分の環境に合わせてダウンロード
pythonコード
crawl.py
# -*- coding: utf-8 -*-
import os
from selenium import webdriver
import sys
# fetch abs path
dir_path = os.path.dirname(os.path.realpath(__file__))
try:
book_title = sys.argv[1]
except IndexError:
with open("title.txt") as f:
book_title = f.read()
# fetch book titles you want
with open("crawl_urls.txt") as f:
urls = [v.rstrip() for v in f.readlines()]
driver = webdriver.Chrome(executable_path=dir_path + '/chromedriver')
for index, url in enumerate(urls):
if index == 0:
driver.get(url.format(book_title))
else:
driver.execute_script("window.open('');")
driver.switch_to_window(driver.window_handles[index])
driver.get(url.format(book_title))
ざっくり解説
- crawl_urls.txtデータにpdf/epub対応のサイトのURLを一行ずつ記載しておきます(今回は翔泳社、gihyo, 達人出版会、マイナビブックスにしました)
- python実行時、引数に欲しい本のキーワードを指定(e.g. python)
- クロームタブが記載したurl分立ち上がりその検索結果が表示される
実行例
python3 crawl.py python
結果
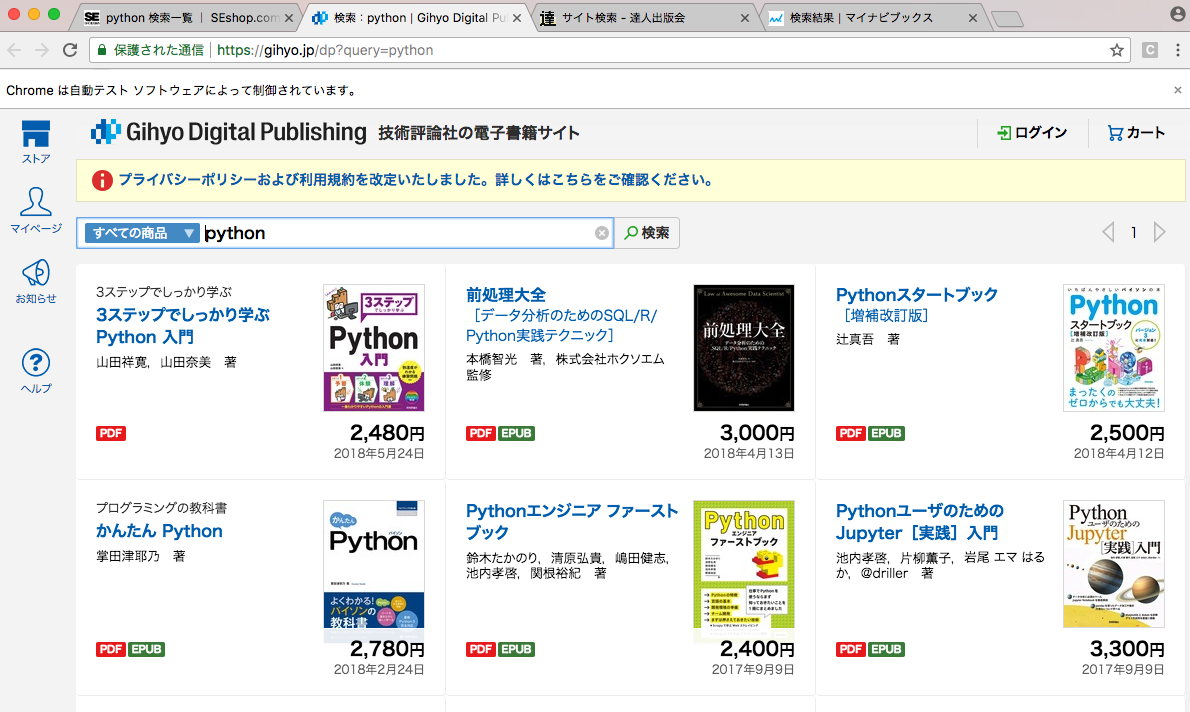
こんな感じでpythonの本を探してくれました
今後はseleniumをもっとうまくつかいこなして複雑な操作をおまかせしたいですね
レポジトリはこちら