大手メールサービス側の優れたスパム判定器のおかげで、セクシーそうなメールやセクシーそうな薬のメールを毎朝仕事前に削除クリックすることが、ここ最近はめっきり無くなったかと思います。これもAIの恩恵ですね。てきめんに。
自然言語に対する深層学習という観点では、画像処理に比べてまだ伸びしろが大きいかと思います。それはひとえに言語現象がいかに複雑なものであるかを表していると考えられます。技術応用の可能性はかなり大きい。開拓時代ですね。
ここでは、深層学習ライブラリであるPyTorchを利用して、スパム判定器の自作過程をご説明します。つまり、文書の分類問題を、リカレントニューラルネットワーク(以下RNN)の一種であるLSTMで行います。
教師データ
教師データはスパムかどうか手動でラベル付された英語SMSのテキストデータです。Tiago A. Almeida氏とJosé María Gómez Hidalgo氏の貢献により、オープンデータとして以下[1]から入手できます。
SMSSpamCollection
データ容量: 466KB
サンプル数は5574であり、747のスパムが含まれます。ここではこのうちの80%を学習用、残りを評価用に使います。
データ前処理
データ前処理として2タスク、語彙をリストアップし、ラベルと文書のインデックス化は必ずやらねばなりません。さらに追加で考えられるのは、クレンジング、ストップワード、あるいは何らかのルールベース処理などですが、学習の向上に貢献できるかどうかはここでは検証していません。
...
# index list
labels = []
texts = []
word_to_ix = {}
for line in lines:
label, txt = line.split('\t')
txt = txt.strip()
if label == 'spam':
labels.append(1)
else:
labels.append(0)
texts.append(txt)
words = txt.split()
for w in words:
if w not in word_to_ix:
word_to_ix[w] = len(word_to_ix)
...
# tockenize
idx = []
for text in texts:
words = text.split()
idx_new = []
for w in words:
idx_new.append(word_to_ix[w])
idx.append(idx_new)
...
ラベルは各行先頭にあり、区切りのタブの後が文章です。
学習モデル
LSTM(Long Short Term Memory)というRNNを使います。勾配消失(あるいは爆発)問題により、素のRNNが使われるケースは少ないかもしれません。ニューラルネットワークの構成要素として大きく3つあります。
まず1つ目は、語彙のスパースな空間を密な分散表現[2]にするレイヤー。自然言語処理に必須の分散表現を、PyTorchでは簡単に利用できます。
self.emb = nn.Embedding(vocab_size, hidden_size)
2つ目は、LSTMレイヤー。分散表現から潜在的な特徴を発見する部分。第一引数と第二引数は違う数値でも問題ありません。語彙数によって一般的に数百のレンジで調整しますが、ここでは200を採用します。上記の第二引数と一致します。
self.lstm = nn.LSTM(hidden_size, hidden_size, num_layers)
3つ目は、最終タイムステップの隠れ層を全結合層に入力し、分類のネットワークに相当する部分。入力次元はLSTMの隠れ層(上記の第二引数)と一致します。
elf.fc = nn.Linear(hidden_size, num_classes)
学習と評価
PyTorchでのLSTMにおいては、入力データは常に3次元のテンソルです。以下の引数の先頭から、シーケンス数(文章の単語数)、バッチ数(文章が可変長なためオンライントレーニングであり、この場合は1)、語彙の特徴次元数(分散表現の次元数)となります。なお、計算に利用したプラットフォームは、前回の例(AIが不得意な日本語文法)と同様にAWSのGPUインスタンスを利用しました。
mat = embedded.view(len(x), 1, -1)
以下のコードは、LSTMの隠れ層を全結合層に与える部分です。最終タイムステップの隠れ層を入力に使います。
out = self.fc(out[-1])
パラメータのチューニングは、何回か学習をさせながらの試行錯誤で行います。今回の例で学習を大きく左右するパラメータは、学習率、レイヤー数、隠れ層のサイズです。
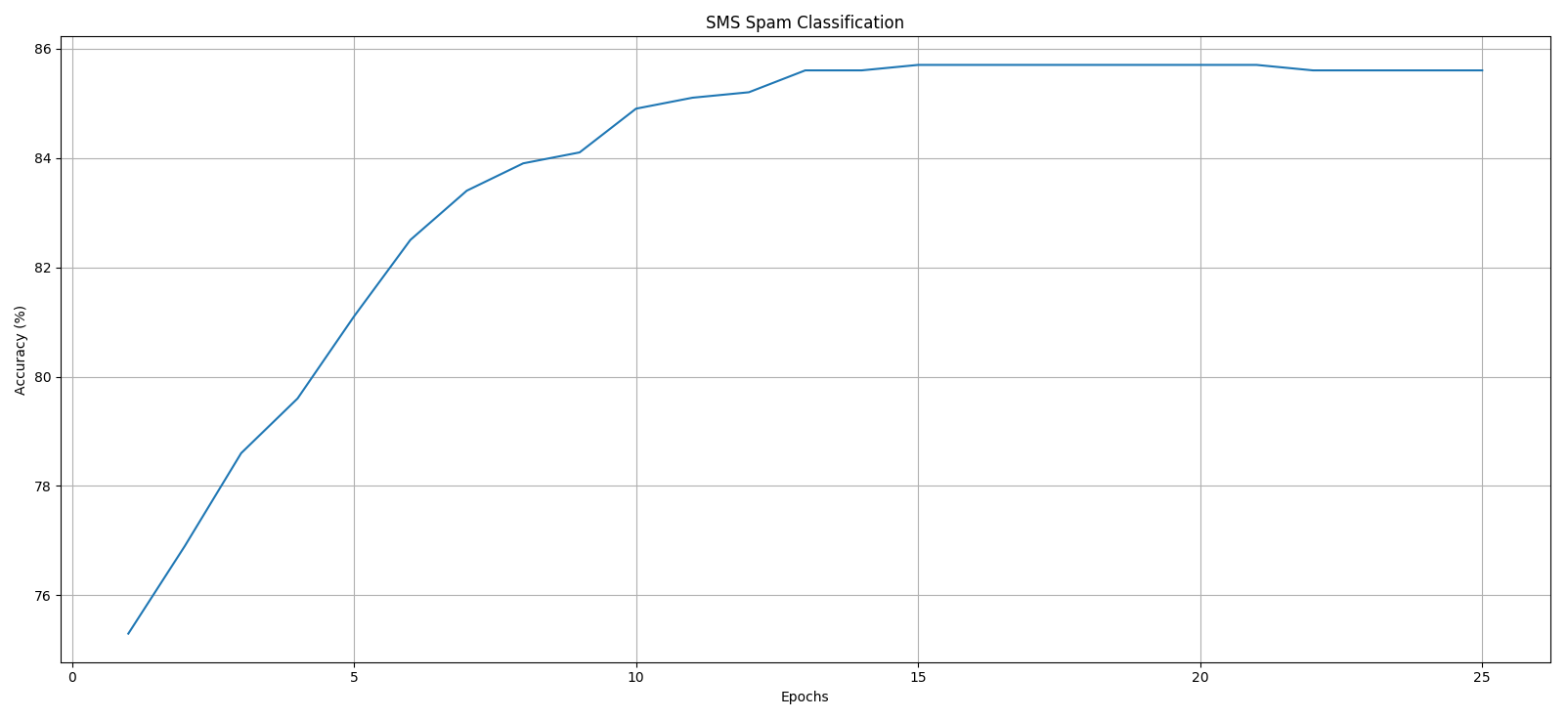
図1. エポックと精度の推移
評価データに対する精度は85.6%です。なお、今回の場合、学習率をかなり低く(0.0000002)設定しないとかなり早期に飽和してしまうことが分かりました。
全コード
import codecs
import torch
import torch.nn as nn
import torch.autograd as autograd
from torch.autograd import Variable
import torch.nn.functional as F
import numpy as np
# all train data, tsv
fi = 'SMSSpamCollection'
with codecs.open(fi, 'r', 'utf-8') as f:
lines = f.readlines()
f.close()
# index list
labels = []
texts = []
word_to_ix = {}
for line in lines:
label, txt = line.split('\t')
txt = txt.strip()
if label == 'spam':
labels.append(1)
else:
labels.append(0)
texts.append(txt)
words = txt.split()
for w in words:
if w not in word_to_ix:
word_to_ix[w] = len(word_to_ix)
# tockenize
idx = []
for text in texts:
words = text.split()
idx_new = []
for w in words:
idx_new.append(word_to_ix[w])
idx.append(idx_new)
# to devide into train data and test data
shuffler = np.random.permutation(len(labels))
idx = np.array(idx)
labels = np.array(labels)
idx = idx[shuffler ]
labels = labels[shuffler ]
ratio_train = 0.8
n_train = (int)(ratio_train * len(idx))
x_train = idx[:n_train]
x_test = idx[n_train:]
y_train = labels[:n_train].tolist()
y_test = labels[n_train:].tolist()
# network params
learning_rate = 0.0000002
hidden_size = 200
num_layers = 1
num_classes = 2
num_epochs = 25
using_cuda = torch.cuda.is_available()
class RNN(nn.Module):
def __init__(self, using_cuda, vocab_size, hidden_size, num_layers, num_classes):
super(RNN, self).__init__()
self.using_cuda = using_cuda
self.hidden_size = hidden_size
self.num_layers = num_layers
self.num_classes = num_classes
self.hidden = None
self.emb = nn.Embedding(vocab_size, hidden_size)
self.lstm = nn.LSTM(hidden_size, hidden_size, num_layers)
self.fc = nn.Linear(hidden_size, num_classes)
def init_hidden(self):
h0 = torch.zeros(self.num_layers, 1, self.hidden_size)
c0 = torch.zeros(self.num_layers, 1, self.hidden_size)
if self.using_cuda:
return (Variable(h0.cuda()), Variable(c0.cuda()))
else:
return (Variable(h0), Variable(c0))
def forward(self, x):
embedded = self.emb(x)
mat = embedded.view(len(x), 1, -1)
self.hidden = self.init_hidden()
out, self.hidden = self.lstm(mat, self.hidden)
out = self.fc(out[-1])
out = F.log_softmax(out, dim=1)
return out
rnn = RNN(using_cuda, len(word_to_ix), hidden_size, num_layers, num_classes)
criterion = nn.NLLLoss()
if using_cuda:
print('cuda')
rnn.cuda()
criterion.cuda()
optimizer = torch.optim.Adam(rnn.parameters(), lr=learning_rate)
# train
for epoch in range(num_epochs):
rnn.train()
for i, line in enumerate(x_train):
print('\r{0}/{1}'.format(i+1, len(x_train)), end=', ')
x = torch.LongTensor(line)
y = torch.LongTensor([y_train[i]])
if using_cuda:
x = x.cuda()
y = y.cuda()
x = Variable(x)
y = Variable(y)
optimizer.zero_grad()
rnn.hidden = rnn.init_hidden()
outputs = rnn(x)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
# test
rnn.eval()
correct = 0
for i, line in enumerate(x_test):
x = torch.LongTensor(line)
x = Variable(x)
if using_cuda:
x = x.cuda()
rnn.hidden = rnn.init_hidden()
outputs = rnn(x)
_, pred = torch.max(outputs.data, 1)
if using_cuda:
pred = pred.cpu()[0]
else:
pred = pred[0]
if pred == y_test[i]:
correct += 1
print('epoch: {0}/{1}, accuracy: {2}%'.format(epoch+1, num_epochs, "%.1f" % (100 * correct / len(y_test))))
まとめと課題
課題として2つあり、1つは学習済みモデルの保存、2つ目は学習済みモデルを利用した文章分類の実装です。これらは
次回にご紹介できればと考えています。
参考情報
[1] SMS Spam Collection v. 1
http://www.dt.fee.unicamp.br/~tiago/smsspamcollection/
[2] Word Embeddings: Encoding Lexical Semantics
https://pytorch.org/tutorials/beginner/nlp/word_embeddings_tutorial.html