TL;DR
xgboost というPython ライブラリ(パッケージ?)を使ったときに
トレーニングデータを sklearn の datasets.load_iris() ではなく
データを CSVファイルでもらったので、それを pandasで読んだら
なんか相当つまづいたのでそのときの行ったことメモです。
あまり説明などが正確ではありませんことをご承知おきください。
何がしたかった? (目的)
xgboost を使った目的は、Feature Importance を出力したかったからです。
Feature Importance とは、(私の理解で言えば)
多クラス分類問題や、回帰分析をする際に、
カラム(説明変数)ごとに出力結果に与える影響の度合いを数値化したものです。
例えば、カレーを作るをときに、
このカレーの味を決めているのはどの調味料の影響が大きいのか
(ターメリックなのか?, コリアンダーなのか?, ガラムマサラなのか? みたいな)
をスコアとして出力してくれるみたいな感じです。(たぶん)
今回はその前段階の トレーニングデータの読み込みでつまづいたので、
そちらにフォーカスして書いていこうと思います。
sklearn datasets 付属のトレーニングデータで学習をする。
普通に AIトレーニングをする場合、Dataset に sklearnに付属しているものを使うことも多いかと思います。 単にライブラリの使い方を知りたいだけならそれで良いと思うので、最初は sklearn の Iris dataset を用いて出力を行いました。
- Iris Dataset ってなんぞ? という方向け。
アヤメデータを使った機械学習の流れを簡単にまとめてみた
プログラムを書きます。
# ----- 多クラス分類問題 -----
import xgboost as xgb
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
"""XGBoost で多クラス分類するサンプルコード"""
# Iris データセットを読み込む
dataset = datasets.load_iris()
x, y = dataset.data, dataset.target
x_train, x_test, y_train, y_test = train_test_split(x, y,
test_size=0.3, # データ全体の 30% をtest dataとする。
shuffle=True, # シャッフルしてね。
stratify=y # ラベル全部入れてね。
)
# xgboost は DMatrix に整形したデータとパラメータを train メソッドに渡してモデルを作成します。
# # 雑にいうと、学習データからxgboost用のデータを生成する。
dtrain = xgb.DMatrix(x_train, label=y_train)
dtest = xgb.DMatrix(x_test, label=y_test)
xgb_params = {
'objective': 'multi:softmax', # 多クラス分類問題なので softmax
'num_class': 3, # 分類するクラス数
'eval_metric': 'mlogloss' # 多クラスの損失関数(対数関数)
}
evals = [(dtrain, 'train'), (dtest, 'eval')]
evals_result = {}
bst = xgb.train(xgb_params, # param と
dtrain, # train data を渡す
num_boost_round=100, # 最大 100回
early_stopping_rounds=10, # 10回やって伸びがないとき打ち切り
evals=evals, # あとでグラフ書くためのやつ。
evals_result=evals_result # 出力を取っておくやつ。
)
# 予測
y_pred = bst.predict(dtest)
# 予測の正確性
acc = accuracy_score(y_test, y_pred)
print('Accuracy:', acc)
# --- 学習結果をグラフで描画 ---
train_metric = evals_result['train']['mlogloss']
plt.plot(train_metric, label='train logloss')
eval_metric = evals_result['eval']['mlogloss']
plt.plot(eval_metric, label='eval logloss')
plt.grid()
plt.legend()
plt.xlabel('rounds')
plt.ylabel('logloss')
plt.show()
とまあ、参考を見本として書いてみます。
そして実行してみます。 $ python xgb_skl.py
(result of xgb_skl.py)
[0] train-mlogloss:0.749101 eval-mlogloss:0.746322
Multiple eval metrics have been passed: 'eval-mlogloss' will be used for early stopping.
Will train until eval-mlogloss has not improved in 10 rounds.
[1] train-mlogloss:0.5422 eval-mlogloss:0.534497
[2] train-mlogloss:0.403809 eval-mlogloss:0.402243
[3] train-mlogloss:0.307853 eval-mlogloss:0.307246
[4] train-mlogloss:0.236608 eval-mlogloss:0.242919
[5] train-mlogloss:0.187216 eval-mlogloss:0.200595
[6] train-mlogloss:0.149031 eval-mlogloss:0.167618
[7] train-mlogloss:0.120982 eval-mlogloss:0.146892
[8] train-mlogloss:0.099261 eval-mlogloss:0.133691
[9] train-mlogloss:0.083686 eval-mlogloss:0.124833
[10] train-mlogloss:0.071938 eval-mlogloss:0.119053
[11] train-mlogloss:0.062597 eval-mlogloss:0.109477
[12] train-mlogloss:0.055532 eval-mlogloss:0.104074
[13] train-mlogloss:0.04971 eval-mlogloss:0.103363
[14] train-mlogloss:0.044946 eval-mlogloss:0.102786
[15] train-mlogloss:0.040545 eval-mlogloss:0.101006
[16] train-mlogloss:0.03746 eval-mlogloss:0.102609
[17] train-mlogloss:0.034801 eval-mlogloss:0.102399
[18] train-mlogloss:0.032773 eval-mlogloss:0.102475
[19] train-mlogloss:0.031438 eval-mlogloss:0.101436
[20] train-mlogloss:0.03016 eval-mlogloss:0.100204
[21] train-mlogloss:0.029128 eval-mlogloss:0.099538
[22] train-mlogloss:0.028322 eval-mlogloss:0.099757
[23] train-mlogloss:0.027761 eval-mlogloss:0.10053
[24] train-mlogloss:0.027199 eval-mlogloss:0.103029
[25] train-mlogloss:0.026732 eval-mlogloss:0.103819
[26] train-mlogloss:0.026244 eval-mlogloss:0.106163
[27] train-mlogloss:0.025838 eval-mlogloss:0.105426
[28] train-mlogloss:0.025515 eval-mlogloss:0.106862
[29] train-mlogloss:0.025144 eval-mlogloss:0.107733
[30] train-mlogloss:0.024842 eval-mlogloss:0.109133
[31] train-mlogloss:0.024523 eval-mlogloss:0.109736
Stopping. Best iteration:
[21] train-mlogloss:0.029128 eval-mlogloss:0.099538
Accuracy: 0.9777777777777777
(markdown のcodeの箇所で
bash を指定したのですが、この配色って何事なのですかね..)
shiracamusさんにご指摘いただき
bashスクリプトだと思ってます。
コンソール出力結果なので、consoleやtextを指定するといいです。
bash => console に指定を変更したら直りました。
ご指摘ありがとうございます。
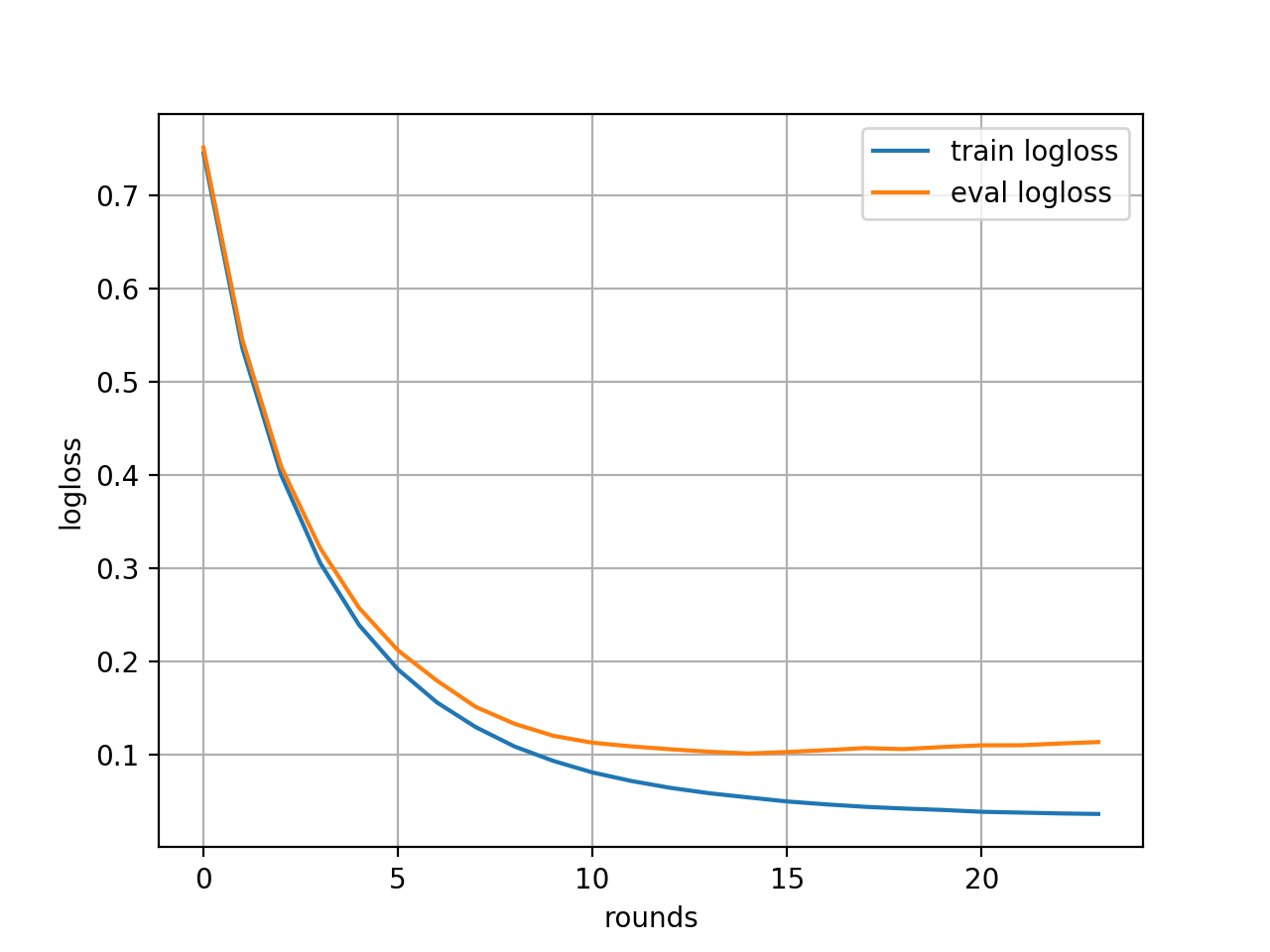
少し、成績が良すぎる気もしますが
と、このように手軽に使うことができました。
先人のおかげですね。巨人の肩に乗った気分です。
そして、本題へ。
今回は xgboost の使い方を知るのはもちろんのこと、
トレーニングデータに, 任意のCSVデータを読み込んでトレーニングができること
(もっと言えば Feature Importance を得られること)
ですので、改変していこうと思います。
ちなみに学習しようする CSVファイルはこんな感じです。
PetalLength,SepalLength,SepalWidth,Species
1.4,5.1,3.5,1
1.4,4.9,3,1
1.3,4.7,3.2,1
1.5,4.6,3.1,1
...
いや、結局 Iris dataやないの !! というコメントは受け付けませんので悪しからず..
(だから見せられるのですよ..)
(このデータ、貰い物なのであまりイチャモンは付けられないのですが、
sklearn の Iris dataset と比べてなぜ、カラムが1つ少ないのでしょうか..謎です..)
そんなことはさておき、ちょこっと変えてみます。
# ----- 多クラス分類問題を扱う -----
import xgboost as xgb
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 読み込むデータを datasets の irisから 自分で指定した CSVファイルに変更
file_pass = '(parent_dir)/Fishers_Irises_train.csv'
iris_csv = pd.read_csv(file_pass, header=None)
# Dataflame の確認 :print('data flame :', iris_csv)
# 0 ~ 2列目を特徴量として使う
x = iris_csv.iloc[:, :3]
# 確認 :
print('Feature data :', X)
# 3列目が正解ラベル
y = iris_csv.iloc[:, 3]
# 確認 :
print('answer :', y)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, shuffle=True)
# 確認たち :
# print("x_train.shape : ", x_train.shape)
# print("x_test.shape : ", x_test.shape)
# print("y_train.shape : ", y_train.shape)
# print("y_test.shape : ", y_test.shape)
dtrain = xgb.DMatrix(x_train, label=y_train)
dtest = xgb.DMatrix(x_test, label=y_test)
xgb_params = {
'objective': 'multi:softmax',
'num_class': 3,
'eval_metric': 'mlogloss'
}
evals = [(dtrain, 'train'), (dtest, 'eval')]
evals_result = {}
bst = xgb.train(xgb_params,
dtrain,
num_boost_round=100,
early_stopping_rounds=10,
evals=evals,
evals_result=evals_result
)
y_pred = bst.predict(dtest)
acc = accuracy_score(y_test, y_pred)
print("Accuracy : ", acc)
\デン/ きました。エラーです。
TypeError: sequence item 0: expected str instance, numpy.int64 found
調べます。
Pythonで配列に数値が入っている時にjoinするとエラーになるってお話
なるほど。
そういえば、sklearn の方はどうやって指定してたんだっけ..
iris = datasets.load_iris()
x, y = iris.data, iris.target
あっ.. object..
雑に見ます。
print(iris.data)
print(type(iris.data))
# [out] <class 'numpy.ndarray'>
お? NumPy配列だって?
Pandas の DataFrameをNumPy配列に変換する方法を検索
pandas.DataFrame, pandas.Seriesいずれもvaliues属性でNumPy配列numpy.ndarryを取得できる。
なるほど。
やってみよう。
file_pass = '(parent_dir)/Fishers_Irises_train.csv'
iris_csv = pd.read_csv(file_pass, header=None)
# dataframe.values => np.array にできる。
"""
iris = load_data_iris()
type(iris.data)
>>> <class 'numpy.ndarray'>
となっていることから、load_data_iris()で読み込んだ data はNumPy配列..
(pandas dataframe ではないことに注意!)
ということは、普通の CSV を pandas で読み込んだのなら、
それを dataframe.values して NumPy配列にしてあげればいけそう。
"""
## iloc[1:]指定しているのはヘッダを読まないため。
x = iris_csv.iloc[1:, :3]
x = x.values
# 確認 :
print('Feature data :', x)
y = iris_csv.iloc[1:, 3]
y = y.values
# 確認 :
print('answer :', y)
よし。これで実行!
\デン (すまん、ウチできへんわ) /
xgboost.core.XGBoostError: [18:33:52] src/objective/multiclass_obj.cu:110: SoftmaxMultiClassObj: label must be in [0, num_class).
なになに?
なるほど。正解ラベルは 0 スタート, class数終わり でなければならないらしい。
さっき print した y を見ると [1, 2, 3] であるから 1引けばいいんでしょ。
y = iris_csv.iloc[1:, 3]
y = y.values
y = y -1
実行 ! \デン(あかんて)/
TypeError: unsupported operand type(s) for -: 'str' and 'int'
知ってた。
ああ。 dataframe.values で変換すると
str型が格納された list (正確には NumPy配列)で返ってくるんだ..
## iloc[1:]指定しているのはヘッダを読まないため。
x = iris_csv.iloc[1:, :3]
# 訓練データは浮動小数点数が入っているので float型に変換します。
x = x.values.astype(float)
# 確認 :
print('Feature data :', X)
y = iris_csv.iloc[1:, 3]
# 正解ラベルは整数なので int に型変換
y = y.values.astype(int)
# 正解ラベル -1 (broad cast)
y = y -1
# 確認 :
print('answer :', y)
よし。良さげ。
そして、完成へ..
import numpy as np
import xgboost as xgb
import pandas as pd
# 結局 sklearn は使うんですけどもね。
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 読み込むデータを datasets の irisから 自分で指定した CSVファイルに変更
file_pass = '(parent_dir)/Fishers_Irises_train.csv'
iris_csv = pd.read_csv(file_pass, header=None)
## iloc[1:]指定しているのはヘッダを読まないため。
x = iris_csv.iloc[1:, :3]
x = x.values.astype(float)
# 確認 :print('Feature data :', X)
y = iris_csv.iloc[1:, 3]
y = y.values.astype(int)
y = y -1
# 確認 :print('answer :', y)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, shuffle=True, random_state=42, stratify=y)
dtrain = xgb.DMatrix(x_train, label=y_train)
dtest = xgb.DMatrix(x_test, label=y_test)
xgb_params = {
'objective': 'multi:softmax',
'num_class': 3,
'eval_metric': 'mlogloss'
}
evals = [(dtrain, 'train'), (dtest, 'eval')]
evals_result = {}
bst = xgb.train(xgb_params,
dtrain,
num_boost_round=100,
early_stopping_rounds=10,
evals=evals,
evals_result=evals_result
)
y_pred = bst.predict(dtest)
acc = accuracy_score(y_test, y_pred)
print("Accuracy : ", acc)
実行します。 (どきどき)
$ python xgb.py
[0] train-mlogloss:0.737199 eval-mlogloss:0.815741
Multiple eval metrics have been passed: 'eval-mlogloss' will be used for early stopping.
Will train until eval-mlogloss has not improved in 10 rounds.
[1] train-mlogloss:0.526851 eval-mlogloss:0.665976
[2] train-mlogloss:0.390387 eval-mlogloss:0.581466
[3] train-mlogloss:0.297312 eval-mlogloss:0.535163
[4] train-mlogloss:0.230717 eval-mlogloss:0.51511
[5] train-mlogloss:0.183676 eval-mlogloss:0.509129
[6] train-mlogloss:0.148959 eval-mlogloss:0.516375
[7] train-mlogloss:0.123137 eval-mlogloss:0.530359
[8] train-mlogloss:0.103713 eval-mlogloss:0.549003
[9] train-mlogloss:0.087338 eval-mlogloss:0.564854
[10] train-mlogloss:0.075128 eval-mlogloss:0.582741
[11] train-mlogloss:0.066544 eval-mlogloss:0.604145
[12] train-mlogloss:0.059427 eval-mlogloss:0.628322
[13] train-mlogloss:0.052418 eval-mlogloss:0.638301
[14] train-mlogloss:0.047923 eval-mlogloss:0.657022
[15] train-mlogloss:0.04462 eval-mlogloss:0.672324
Stopping. Best iteration:
[5] train-mlogloss:0.183676 eval-mlogloss:0.509129
Accuracy : 0.8333333333333334
無事にトレーニングできたみたいです! やったね。
振り返りと、まとめ。
少し Accuracyが落ちているのは
- たぶんカラムが1つ少ないことと、
- ハイパーパラメータとかをきちんと調整してないから
だと思います..そこまで手が回らなかった..
kerasとか、TensorFlowもそうですが、sklearn とかでも、とにかく
「もう出来上がっているもの」って便利なのですけど、
object とか、メソッドとかが絡み合っていて
自分なりに解釈するのに時間がかかりますよね。
あれですね。冷凍食品って手軽なんですが、
自分の好きな食べ物を冷凍食品にしたいと思ったとき思考停止する感じです。
きっともっと上等なやり方はあったのでしょうが、
ぼくの実力では、力技で型変換を繰り返したりするのが精一杯でした。
備忘録なので、あまり参考にならないかもしれませんが、
よろしければ, 次は
Feature Importance の出力についても記事にしてみようかと
思いますのでご覧いただけたら幸いです。