第0章 Day1の復習
0.1 数式の流れ
\begin{eqnarray}
E(\mathbb{y})&=&\frac12\sum_{j=1}^{l}\left(y_j-d_j \right)^2=\frac12\|\mathbb{y}-\mathbb{d}\|^2\\
\mathbb{y}&=&\mathbb{u}^{(l)}\\
\mathbb{u}^{(l)}&=&\mathbb{w}^{(l)}\mathbb{z}^{(l-1)}+\mathbb{b}^{(l)}\\
\frac{\partial E}{\partial w_{ji}^{(2)}}&=&\frac{\partial E}{\partial \mathbb{y}}\times \frac{\partial \mathbb{y}}{\partial \mathbb{u}}\times \frac{\partial \mathbb{u}}{\partial w_{ji}^{(2)}}\\
\frac{\partial E(\mathbb{y})}{\partial \mathbb{y}}&=&\frac{\partial }{\partial \mathbb{y}}\frac12\|\mathbb{y}-\mathbb{d}\|^2=\mathbb{y}-\mathbb{d}\\
\frac{\partial \mathbb{y(\mathbb{u})}}{\partial \mathbb{u}}&=&\frac{\partial \mathbb{u}}{\partial \mathbb{u}}=1
\end{eqnarray}
確認テスト:連鎖率を使い、$\displaystyle\frac{dz}{dx}$を求めよ。
\left\{
\begin{array}{l}
z=t^2 \\
t=x+y
\end{array}
\right.
答:微分の連鎖率は
$$\frac{dz}{dx}=\frac{dz}{dt}\times\frac{dt}{dx}$$
\left\{
\begin{array}{l}
\frac{dz}{dt}=2t \\
\frac{dt}{dx}=1
\end{array}
\right.
より
$$\frac{dz}{dx}=\frac{dz}{dt}\times\frac{dt}{dx}=2t\times 1=2(x+y)$$
第1章 勾配消失問題
誤差逆伝播法が下位層に進んでいくにつれて勾配がどんどん緩やかになっていく。
そのため、下位層のパラメータがほとんど変わらず、全体最適解に収束しなくなる。
下図のようにグラフ等で可視化することで勾配消失を起こしているかどうか確認できる。
学習がうまくいった例
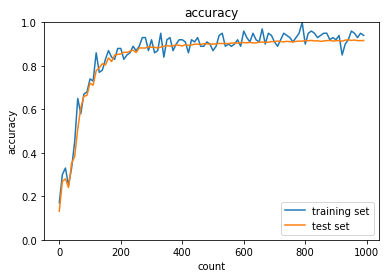
1.1 活性化関数・シグモイド(sigmoid)関数
シグモイド関数 $\sigma(x)$ は、入力が実数のとき必ず出力が0と1に収まる単調増加関数
$$\sigma(x)=\frac{1}{1+\exp(-ax)}=\frac{1}{1+e^{-ax}}$$
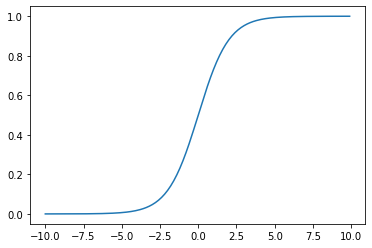
import matplotlib.pyplot as plt
import numpy as np
import math
x = np.arange(-10, 10, 0.1)
e = math.e
y = 1 / (1 + e**-x)
plt.plot(x, y)
plt.show()
シグモイド関数の微分はシグモイド関数自身で表現できる。
$$\sigma^{\prime}(x)=a\sigma(x)\big(1-\sigma(x) \big)=\frac{e^{-x}}{(1+e^{-x})^2}$$
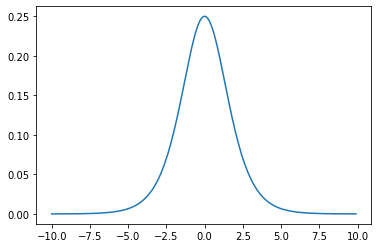
import matplotlib.pyplot as plt
import numpy as np
import math
x = np.arange(-10, 10, 0.1)
e = math.e
y = e**-x / (1 + e**-x)**2
plt.plot(x, y)
plt.show()
ON/OFFしかないステップ関数に対して、
シグモイド関数は、勾配消失問題を起こす代表的な活性化関数。
微分した結果に問題がある。
シグモイド関数を微分した結果は最大値が0.25となるため、下位層に進むにつれて0.25の2乗、更に2乗となっていくため0に終息していく。
確認テスト:シグモイド関数を微分したとき、入力値が0のとき最大値を取る。
その時の値として正しいものは?
答:0.25
1.2 勾配消失の解決方法
・活性化関数の選択
・重みの初期値設定
・バッチ正規化
1.2.1 勾配消失の解決方法
シグモイド関数では勾配消失が起こる
⇒ 勾配消失が起きづらい活性化関数
⇒ ReLU関数(Rectified Linear Unit:ランプ関数、正規化線形関数)
今最も使われている活性化関数
微分した結果が$x\leqq 0$ の時は $0$、$x>1$の時は、$1$となる。
これによって2つ良いことがある。
微分した結果に1があるため、勾配消失問題がうまいこと解消できる。
微分値が0になるとき、重みが更新され使われなくなる。
必要な重みだけしか残らなくなり、必要な部分だけ抽出される(スパース化される)ことになる。
f(x)=\left\{
\begin{array}{l}
x \qquad (x>0)\\
0 \qquad (x\leqq 0)
\end{array}
\right.
実装
Googleドライブのマウント・sys.pathの設定
from google.colab import drive
drive.mount('/content/drive')
import sys
sys.path.append('/content/drive/My Drive/DNN_code')
勾配消失(シグモイド関数)
import numpy as np
from common import layers
from collections import OrderedDict
from common import functions
from data.mnist import load_mnist
import matplotlib.pyplot as plt
# mnistをロード
(x_train, d_train), (x_test, d_test) = load_mnist(normalize=True, one_hot_label=True)
train_size = len(x_train)
print("データ読み込み完了")
# 重み初期値補正係数
wieght_init = 0.01
# 入力層サイズ
input_layer_size = 784
# 中間層サイズ
hidden_layer_1_size = 40
hidden_layer_2_size = 20
# 出力層サイズ
output_layer_size = 10
# 繰り返し数
iters_num = 2000
# ミニバッチサイズ
batch_size = 100
# 学習率
learning_rate = 0.1
# 描写頻度
plot_interval=10
# 初期設定
def init_network():
network = {}
network['W1'] = wieght_init * np.random.randn(input_layer_size, hidden_layer_1_size)
network['W2'] = wieght_init * np.random.randn(hidden_layer_1_size, hidden_layer_2_size)
network['W3'] = wieght_init * np.random.randn(hidden_layer_2_size, output_layer_size)
network['b1'] = np.zeros(hidden_layer_1_size)
network['b2'] = np.zeros(hidden_layer_2_size)
network['b3'] = np.zeros(output_layer_size)
return network
# 順伝播
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
hidden_f = functions.sigmoid
u1 = np.dot(x, W1) + b1
z1 = hidden_f(u1)
u2 = np.dot(z1, W2) + b2
z2 = hidden_f(u2)
u3 = np.dot(z2, W3) + b3
y = functions.softmax(u3)
return z1, z2, y
# 誤差逆伝播
def backward(x, d, z1, z2, y):
grad = {}
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
hidden_d_f = functions.d_sigmoid
last_d_f = functions.d_softmax_with_loss
# 出力層でのデルタ
delta3 = last_d_f(d, y)
# b3の勾配
grad['b3'] = np.sum(delta3, axis=0)
# W3の勾配
grad['W3'] = np.dot(z2.T, delta3)
# 2層でのデルタ
delta2 = np.dot(delta3, W3.T) * hidden_d_f(z2)
# b2の勾配
grad['b2'] = np.sum(delta2, axis=0)
# W2の勾配
grad['W2'] = np.dot(z1.T, delta2)
# 1層でのデルタ
delta1 = np.dot(delta2, W2.T) * hidden_d_f(z1)
# b1の勾配
grad['b1'] = np.sum(delta1, axis=0)
# W1の勾配
grad['W1'] = np.dot(x.T, delta1)
return grad
# パラメータの初期化
network = init_network()
accuracies_train = []
accuracies_test = []
# 正答率
def accuracy(x, d):
z1, z2, y = forward(network, x)
y = np.argmax(y, axis=1)
if d.ndim != 1 : d = np.argmax(d, axis=1)
accuracy = np.sum(y == d) / float(x.shape[0])
return accuracy
for i in range(iters_num):
# ランダムにバッチを取得
batch_mask = np.random.choice(train_size, batch_size)
# ミニバッチに対応する教師訓練画像データを取得
x_batch = x_train[batch_mask]
# ミニバッチに対応する訓練正解ラベルデータを取得する
d_batch = d_train[batch_mask]
z1, z2, y = forward(network, x_batch)
grad = backward(x_batch, d_batch, z1, z2, y)
if (i+1)%plot_interval==0:
accr_test = accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
# パラメータに勾配適用
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
network[key] -= learning_rate * grad[key]
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()
データ読み込み完了
Generation: 10. 正答率(トレーニング) = 0.05
: 10. 正答率(テスト) = 0.1032
Generation: 20. 正答率(トレーニング) = 0.08
: 20. 正答率(テスト) = 0.0982
Generation: 30. 正答率(トレーニング) = 0.07
: 30. 正答率(テスト) = 0.101
Generation: 40. 正答率(トレーニング) = 0.11
: 40. 正答率(テスト) = 0.1009
Generation: 50. 正答率(トレーニング) = 0.09
: 50. 正答率(テスト) = 0.0982
Generation: 60. 正答率(トレーニング) = 0.09
: 60. 正答率(テスト) = 0.1009
Generation: 70. 正答率(トレーニング) = 0.14
: 70. 正答率(テスト) = 0.1028
Generation: 80. 正答率(トレーニング) = 0.1
: 80. 正答率(テスト) = 0.1135
Generation: 90. 正答率(トレーニング) = 0.11
: 90. 正答率(テスト) = 0.1135
Generation: 100. 正答率(トレーニング) = 0.06
: 100. 正答率(テスト) = 0.101
Generation: 110. 正答率(トレーニング) = 0.09
: 110. 正答率(テスト) = 0.1135
Generation: 120. 正答率(トレーニング) = 0.06
: 120. 正答率(テスト) = 0.1135
Generation: 130. 正答率(トレーニング) = 0.06
: 130. 正答率(テスト) = 0.0958
Generation: 140. 正答率(トレーニング) = 0.11
: 140. 正答率(テスト) = 0.1135
Generation: 150. 正答率(トレーニング) = 0.11
: 150. 正答率(テスト) = 0.1028
Generation: 160. 正答率(トレーニング) = 0.05
: 160. 正答率(テスト) = 0.1032
Generation: 170. 正答率(トレーニング) = 0.12
: 170. 正答率(テスト) = 0.1028
Generation: 180. 正答率(トレーニング) = 0.13
: 180. 正答率(テスト) = 0.1135
Generation: 190. 正答率(トレーニング) = 0.09
: 190. 正答率(テスト) = 0.0958
Generation: 200. 正答率(トレーニング) = 0.09
: 200. 正答率(テスト) = 0.1135
Generation: 210. 正答率(トレーニング) = 0.09
: 210. 正答率(テスト) = 0.0958
Generation: 220. 正答率(トレーニング) = 0.09
: 220. 正答率(テスト) = 0.1028
Generation: 230. 正答率(トレーニング) = 0.11
: 230. 正答率(テスト) = 0.1135
Generation: 240. 正答率(トレーニング) = 0.14
: 240. 正答率(テスト) = 0.0958
Generation: 250. 正答率(トレーニング) = 0.17
: 250. 正答率(テスト) = 0.0958
Generation: 260. 正答率(トレーニング) = 0.14
: 260. 正答率(テスト) = 0.1009
Generation: 270. 正答率(トレーニング) = 0.14
: 270. 正答率(テスト) = 0.1135
Generation: 280. 正答率(トレーニング) = 0.1
: 280. 正答率(テスト) = 0.1135
Generation: 290. 正答率(トレーニング) = 0.08
: 290. 正答率(テスト) = 0.1135
Generation: 300. 正答率(トレーニング) = 0.1
: 300. 正答率(テスト) = 0.1135
Generation: 310. 正答率(トレーニング) = 0.07
: 310. 正答率(テスト) = 0.1135
Generation: 320. 正答率(トレーニング) = 0.14
: 320. 正答率(テスト) = 0.1135
Generation: 330. 正答率(トレーニング) = 0.09
: 330. 正答率(テスト) = 0.1135
Generation: 340. 正答率(トレーニング) = 0.06
: 340. 正答率(テスト) = 0.101
Generation: 350. 正答率(トレーニング) = 0.11
: 350. 正答率(テスト) = 0.1135
Generation: 360. 正答率(トレーニング) = 0.07
: 360. 正答率(テスト) = 0.1135
Generation: 370. 正答率(トレーニング) = 0.08
: 370. 正答率(テスト) = 0.0982
Generation: 380. 正答率(トレーニング) = 0.11
: 380. 正答率(テスト) = 0.1135
Generation: 390. 正答率(トレーニング) = 0.16
: 390. 正答率(テスト) = 0.1135
Generation: 400. 正答率(トレーニング) = 0.07
: 400. 正答率(テスト) = 0.1135
Generation: 410. 正答率(トレーニング) = 0.11
: 410. 正答率(テスト) = 0.1135
Generation: 420. 正答率(トレーニング) = 0.12
: 420. 正答率(テスト) = 0.1028
Generation: 430. 正答率(トレーニング) = 0.07
: 430. 正答率(テスト) = 0.1028
Generation: 440. 正答率(トレーニング) = 0.13
: 440. 正答率(テスト) = 0.1009
Generation: 450. 正答率(トレーニング) = 0.11
: 450. 正答率(テスト) = 0.1135
Generation: 460. 正答率(トレーニング) = 0.09
: 460. 正答率(テスト) = 0.1135
Generation: 470. 正答率(トレーニング) = 0.13
: 470. 正答率(テスト) = 0.1135
Generation: 480. 正答率(トレーニング) = 0.11
: 480. 正答率(テスト) = 0.1135
Generation: 490. 正答率(トレーニング) = 0.1
: 490. 正答率(テスト) = 0.1135
Generation: 500. 正答率(トレーニング) = 0.06
: 500. 正答率(テスト) = 0.101
Generation: 510. 正答率(トレーニング) = 0.09
: 510. 正答率(テスト) = 0.101
Generation: 520. 正答率(トレーニング) = 0.1
: 520. 正答率(テスト) = 0.1135
Generation: 530. 正答率(トレーニング) = 0.08
: 530. 正答率(テスト) = 0.1135
Generation: 540. 正答率(トレーニング) = 0.09
: 540. 正答率(テスト) = 0.1135
Generation: 550. 正答率(トレーニング) = 0.15
: 550. 正答率(テスト) = 0.1135
Generation: 560. 正答率(トレーニング) = 0.09
: 560. 正答率(テスト) = 0.1135
Generation: 570. 正答率(トレーニング) = 0.09
: 570. 正答率(テスト) = 0.1135
Generation: 580. 正答率(トレーニング) = 0.14
: 580. 正答率(テスト) = 0.1135
Generation: 590. 正答率(トレーニング) = 0.12
: 590. 正答率(テスト) = 0.1135
Generation: 600. 正答率(トレーニング) = 0.23
: 600. 正答率(テスト) = 0.1135
Generation: 610. 正答率(トレーニング) = 0.1
: 610. 正答率(テスト) = 0.1135
Generation: 620. 正答率(トレーニング) = 0.19
: 620. 正答率(テスト) = 0.1135
Generation: 630. 正答率(トレーニング) = 0.11
: 630. 正答率(テスト) = 0.1135
Generation: 640. 正答率(トレーニング) = 0.09
: 640. 正答率(テスト) = 0.1135
Generation: 650. 正答率(トレーニング) = 0.07
: 650. 正答率(テスト) = 0.1135
Generation: 660. 正答率(トレーニング) = 0.15
: 660. 正答率(テスト) = 0.1135
Generation: 670. 正答率(トレーニング) = 0.08
: 670. 正答率(テスト) = 0.1028
Generation: 680. 正答率(トレーニング) = 0.13
: 680. 正答率(テスト) = 0.1028
Generation: 690. 正答率(トレーニング) = 0.11
: 690. 正答率(テスト) = 0.1135
Generation: 700. 正答率(トレーニング) = 0.07
: 700. 正答率(テスト) = 0.1135
Generation: 710. 正答率(トレーニング) = 0.06
: 710. 正答率(テスト) = 0.1028
Generation: 720. 正答率(トレーニング) = 0.13
: 720. 正答率(テスト) = 0.1135
Generation: 730. 正答率(トレーニング) = 0.09
: 730. 正答率(テスト) = 0.1135
Generation: 740. 正答率(トレーニング) = 0.12
: 740. 正答率(テスト) = 0.1028
Generation: 750. 正答率(トレーニング) = 0.08
: 750. 正答率(テスト) = 0.1135
Generation: 760. 正答率(トレーニング) = 0.17
: 760. 正答率(テスト) = 0.1135
Generation: 770. 正答率(トレーニング) = 0.11
: 770. 正答率(テスト) = 0.101
Generation: 780. 正答率(トレーニング) = 0.08
: 780. 正答率(テスト) = 0.1135
Generation: 790. 正答率(トレーニング) = 0.13
: 790. 正答率(テスト) = 0.101
Generation: 800. 正答率(トレーニング) = 0.11
: 800. 正答率(テスト) = 0.1135
Generation: 810. 正答率(トレーニング) = 0.05
: 810. 正答率(テスト) = 0.1135
Generation: 820. 正答率(トレーニング) = 0.18
: 820. 正答率(テスト) = 0.1135
Generation: 830. 正答率(トレーニング) = 0.12
: 830. 正答率(テスト) = 0.1135
Generation: 840. 正答率(トレーニング) = 0.1
: 840. 正答率(テスト) = 0.1135
Generation: 850. 正答率(トレーニング) = 0.13
: 850. 正答率(テスト) = 0.1135
Generation: 860. 正答率(トレーニング) = 0.15
: 860. 正答率(テスト) = 0.1135
Generation: 870. 正答率(トレーニング) = 0.11
: 870. 正答率(テスト) = 0.1135
Generation: 880. 正答率(トレーニング) = 0.09
: 880. 正答率(テスト) = 0.1135
Generation: 890. 正答率(トレーニング) = 0.09
: 890. 正答率(テスト) = 0.1028
Generation: 900. 正答率(トレーニング) = 0.08
: 900. 正答率(テスト) = 0.1135
Generation: 910. 正答率(トレーニング) = 0.06
: 910. 正答率(テスト) = 0.1135
Generation: 920. 正答率(トレーニング) = 0.15
: 920. 正答率(テスト) = 0.1135
Generation: 930. 正答率(トレーニング) = 0.12
: 930. 正答率(テスト) = 0.1135
Generation: 940. 正答率(トレーニング) = 0.1
: 940. 正答率(テスト) = 0.1135
Generation: 950. 正答率(トレーニング) = 0.11
: 950. 正答率(テスト) = 0.1135
Generation: 960. 正答率(トレーニング) = 0.09
: 960. 正答率(テスト) = 0.1135
Generation: 970. 正答率(トレーニング) = 0.06
: 970. 正答率(テスト) = 0.1135
Generation: 980. 正答率(トレーニング) = 0.09
: 980. 正答率(テスト) = 0.1135
Generation: 990. 正答率(トレーニング) = 0.14
: 990. 正答率(テスト) = 0.1135
Generation: 1000. 正答率(トレーニング) = 0.18
: 1000. 正答率(テスト) = 0.1135
Generation: 1010. 正答率(トレーニング) = 0.12
: 1010. 正答率(テスト) = 0.1135
Generation: 1020. 正答率(トレーニング) = 0.15
: 1020. 正答率(テスト) = 0.1135
Generation: 1030. 正答率(トレーニング) = 0.11
: 1030. 正答率(テスト) = 0.1135
Generation: 1040. 正答率(トレーニング) = 0.07
: 1040. 正答率(テスト) = 0.101
Generation: 1050. 正答率(トレーニング) = 0.11
: 1050. 正答率(テスト) = 0.1135
Generation: 1060. 正答率(トレーニング) = 0.12
: 1060. 正答率(テスト) = 0.1135
Generation: 1070. 正答率(トレーニング) = 0.13
: 1070. 正答率(テスト) = 0.1028
Generation: 1080. 正答率(トレーニング) = 0.13
: 1080. 正答率(テスト) = 0.1028
Generation: 1090. 正答率(トレーニング) = 0.11
: 1090. 正答率(テスト) = 0.0974
Generation: 1100. 正答率(トレーニング) = 0.08
: 1100. 正答率(テスト) = 0.1028
Generation: 1110. 正答率(トレーニング) = 0.15
: 1110. 正答率(テスト) = 0.1135
Generation: 1120. 正答率(トレーニング) = 0.18
: 1120. 正答率(テスト) = 0.1135
Generation: 1130. 正答率(トレーニング) = 0.14
: 1130. 正答率(テスト) = 0.1135
Generation: 1140. 正答率(トレーニング) = 0.16
: 1140. 正答率(テスト) = 0.1135
Generation: 1150. 正答率(トレーニング) = 0.08
: 1150. 正答率(テスト) = 0.1135
Generation: 1160. 正答率(トレーニング) = 0.12
: 1160. 正答率(テスト) = 0.1009
Generation: 1170. 正答率(トレーニング) = 0.07
: 1170. 正答率(テスト) = 0.1135
Generation: 1180. 正答率(トレーニング) = 0.09
: 1180. 正答率(テスト) = 0.1135
Generation: 1190. 正答率(トレーニング) = 0.13
: 1190. 正答率(テスト) = 0.1135
Generation: 1200. 正答率(トレーニング) = 0.16
: 1200. 正答率(テスト) = 0.1135
Generation: 1210. 正答率(トレーニング) = 0.15
: 1210. 正答率(テスト) = 0.1028
Generation: 1220. 正答率(トレーニング) = 0.12
: 1220. 正答率(テスト) = 0.1135
Generation: 1230. 正答率(トレーニング) = 0.12
: 1230. 正答率(テスト) = 0.1135
Generation: 1240. 正答率(トレーニング) = 0.1
: 1240. 正答率(テスト) = 0.1135
Generation: 1250. 正答率(トレーニング) = 0.13
: 1250. 正答率(テスト) = 0.1135
Generation: 1260. 正答率(トレーニング) = 0.09
: 1260. 正答率(テスト) = 0.1135
Generation: 1270. 正答率(トレーニング) = 0.1
: 1270. 正答率(テスト) = 0.1135
Generation: 1280. 正答率(トレーニング) = 0.1
: 1280. 正答率(テスト) = 0.1135
Generation: 1290. 正答率(トレーニング) = 0.08
: 1290. 正答率(テスト) = 0.1135
Generation: 1300. 正答率(トレーニング) = 0.09
: 1300. 正答率(テスト) = 0.1135
Generation: 1310. 正答率(トレーニング) = 0.05
: 1310. 正答率(テスト) = 0.1135
Generation: 1320. 正答率(トレーニング) = 0.13
: 1320. 正答率(テスト) = 0.1135
Generation: 1330. 正答率(トレーニング) = 0.09
: 1330. 正答率(テスト) = 0.1135
Generation: 1340. 正答率(トレーニング) = 0.11
: 1340. 正答率(テスト) = 0.1135
Generation: 1350. 正答率(トレーニング) = 0.15
: 1350. 正答率(テスト) = 0.1135
Generation: 1360. 正答率(トレーニング) = 0.13
: 1360. 正答率(テスト) = 0.1135
Generation: 1370. 正答率(トレーニング) = 0.13
: 1370. 正答率(テスト) = 0.1135
Generation: 1380. 正答率(トレーニング) = 0.09
: 1380. 正答率(テスト) = 0.0958
Generation: 1390. 正答率(トレーニング) = 0.11
: 1390. 正答率(テスト) = 0.0958
Generation: 1400. 正答率(トレーニング) = 0.2
: 1400. 正答率(テスト) = 0.1135
Generation: 1410. 正答率(トレーニング) = 0.15
: 1410. 正答率(テスト) = 0.1135
Generation: 1420. 正答率(トレーニング) = 0.08
: 1420. 正答率(テスト) = 0.1135
Generation: 1430. 正答率(トレーニング) = 0.08
: 1430. 正答率(テスト) = 0.1135
Generation: 1440. 正答率(トレーニング) = 0.12
: 1440. 正答率(テスト) = 0.1135
Generation: 1450. 正答率(トレーニング) = 0.06
: 1450. 正答率(テスト) = 0.0958
Generation: 1460. 正答率(トレーニング) = 0.06
: 1460. 正答率(テスト) = 0.1135
Generation: 1470. 正答率(トレーニング) = 0.13
: 1470. 正答率(テスト) = 0.1135
Generation: 1480. 正答率(トレーニング) = 0.11
: 1480. 正答率(テスト) = 0.1135
Generation: 1490. 正答率(トレーニング) = 0.15
: 1490. 正答率(テスト) = 0.1135
Generation: 1500. 正答率(トレーニング) = 0.11
: 1500. 正答率(テスト) = 0.1135
Generation: 1510. 正答率(トレーニング) = 0.17
: 1510. 正答率(テスト) = 0.1135
Generation: 1520. 正答率(トレーニング) = 0.08
: 1520. 正答率(テスト) = 0.1135
Generation: 1530. 正答率(トレーニング) = 0.1
: 1530. 正答率(テスト) = 0.1135
Generation: 1540. 正答率(トレーニング) = 0.08
: 1540. 正答率(テスト) = 0.1028
Generation: 1550. 正答率(トレーニング) = 0.12
: 1550. 正答率(テスト) = 0.0982
Generation: 1560. 正答率(トレーニング) = 0.11
: 1560. 正答率(テスト) = 0.098
Generation: 1570. 正答率(トレーニング) = 0.16
: 1570. 正答率(テスト) = 0.1135
Generation: 1580. 正答率(トレーニング) = 0.1
: 1580. 正答率(テスト) = 0.1135
Generation: 1590. 正答率(トレーニング) = 0.15
: 1590. 正答率(テスト) = 0.1135
Generation: 1600. 正答率(トレーニング) = 0.14
: 1600. 正答率(テスト) = 0.1135
Generation: 1610. 正答率(トレーニング) = 0.06
: 1610. 正答率(テスト) = 0.1135
Generation: 1620. 正答率(トレーニング) = 0.11
: 1620. 正答率(テスト) = 0.1135
Generation: 1630. 正答率(トレーニング) = 0.09
: 1630. 正答率(テスト) = 0.1028
Generation: 1640. 正答率(トレーニング) = 0.06
: 1640. 正答率(テスト) = 0.1135
Generation: 1650. 正答率(トレーニング) = 0.17
: 1650. 正答率(テスト) = 0.1135
Generation: 1660. 正答率(トレーニング) = 0.19
: 1660. 正答率(テスト) = 0.1135
Generation: 1670. 正答率(トレーニング) = 0.11
: 1670. 正答率(テスト) = 0.1135
Generation: 1680. 正答率(トレーニング) = 0.08
: 1680. 正答率(テスト) = 0.1135
Generation: 1690. 正答率(トレーニング) = 0.16
: 1690. 正答率(テスト) = 0.1135
Generation: 1700. 正答率(トレーニング) = 0.07
: 1700. 正答率(テスト) = 0.101
Generation: 1710. 正答率(トレーニング) = 0.11
: 1710. 正答率(テスト) = 0.1135
Generation: 1720. 正答率(トレーニング) = 0.15
: 1720. 正答率(テスト) = 0.1135
Generation: 1730. 正答率(トレーニング) = 0.13
: 1730. 正答率(テスト) = 0.1135
Generation: 1740. 正答率(トレーニング) = 0.12
: 1740. 正答率(テスト) = 0.1135
Generation: 1750. 正答率(トレーニング) = 0.1
: 1750. 正答率(テスト) = 0.1135
Generation: 1760. 正答率(トレーニング) = 0.14
: 1760. 正答率(テスト) = 0.1135
Generation: 1770. 正答率(トレーニング) = 0.13
: 1770. 正答率(テスト) = 0.1135
Generation: 1780. 正答率(トレーニング) = 0.13
: 1780. 正答率(テスト) = 0.1135
Generation: 1790. 正答率(トレーニング) = 0.09
: 1790. 正答率(テスト) = 0.1135
Generation: 1800. 正答率(トレーニング) = 0.11
: 1800. 正答率(テスト) = 0.1135
Generation: 1810. 正答率(トレーニング) = 0.14
: 1810. 正答率(テスト) = 0.1135
Generation: 1820. 正答率(トレーニング) = 0.09
: 1820. 正答率(テスト) = 0.1135
Generation: 1830. 正答率(トレーニング) = 0.12
: 1830. 正答率(テスト) = 0.101
Generation: 1840. 正答率(トレーニング) = 0.13
: 1840. 正答率(テスト) = 0.1135
Generation: 1850. 正答率(トレーニング) = 0.12
: 1850. 正答率(テスト) = 0.1135
Generation: 1860. 正答率(トレーニング) = 0.14
: 1860. 正答率(テスト) = 0.1135
Generation: 1870. 正答率(トレーニング) = 0.1
: 1870. 正答率(テスト) = 0.1135
Generation: 1880. 正答率(トレーニング) = 0.15
: 1880. 正答率(テスト) = 0.1135
Generation: 1890. 正答率(トレーニング) = 0.1
: 1890. 正答率(テスト) = 0.1135
Generation: 1900. 正答率(トレーニング) = 0.12
: 1900. 正答率(テスト) = 0.1135
Generation: 1910. 正答率(トレーニング) = 0.14
: 1910. 正答率(テスト) = 0.1135
Generation: 1920. 正答率(トレーニング) = 0.13
: 1920. 正答率(テスト) = 0.1135
Generation: 1930. 正答率(トレーニング) = 0.12
: 1930. 正答率(テスト) = 0.1135
Generation: 1940. 正答率(トレーニング) = 0.09
: 1940. 正答率(テスト) = 0.1135
Generation: 1950. 正答率(トレーニング) = 0.09
: 1950. 正答率(テスト) = 0.1135
Generation: 1960. 正答率(トレーニング) = 0.15
: 1960. 正答率(テスト) = 0.1135
Generation: 1970. 正答率(トレーニング) = 0.1
: 1970. 正答率(テスト) = 0.1135
Generation: 1980. 正答率(トレーニング) = 0.13
: 1980. 正答率(テスト) = 0.1135
Generation: 1990. 正答率(トレーニング) = 0.1
: 1990. 正答率(テスト) = 0.1135
Generation: 2000. 正答率(トレーニング) = 0.05
: 2000. 正答率(テスト) = 0.1135
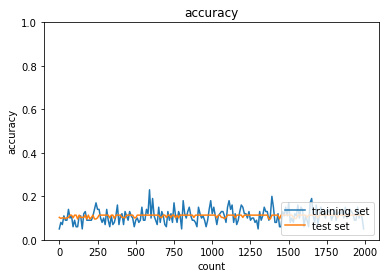
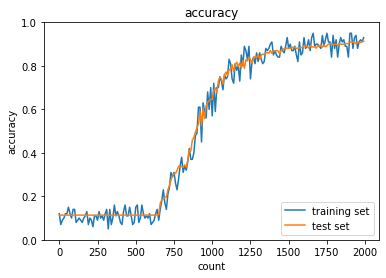
勾配消失していることが分かる。
続いてReLU関数を利用。
import numpy as np
from data.mnist import load_mnist
from PIL import Image
import pickle
from common import functions
import matplotlib.pyplot as plt
# mnistをロード
(x_train, d_train), (x_test, d_test) = load_mnist(normalize=True, one_hot_label=True)
train_size = len(x_train)
print("データ読み込み完了")
# 重み初期値補正係数
wieght_init = 0.01
# 入力層サイズ
input_layer_size = 784
# 中間層サイズ
hidden_layer_1_size = 40
hidden_layer_2_size = 20
# 出力層サイズ
output_layer_size = 10
# 繰り返し数
iters_num = 2000
# ミニバッチサイズ
batch_size = 100
# 学習率
learning_rate = 0.1
# 描写頻度
plot_interval=10
# 初期設定
def init_network():
network = {}
network['W1'] = wieght_init * np.random.randn(input_layer_size, hidden_layer_1_size)
network['W2'] = wieght_init * np.random.randn(hidden_layer_1_size, hidden_layer_2_size)
network['W3'] = wieght_init * np.random.randn(hidden_layer_2_size, output_layer_size)
network['b1'] = np.zeros(hidden_layer_1_size)
network['b2'] = np.zeros(hidden_layer_2_size)
network['b3'] = np.zeros(output_layer_size)
return network
# 順伝播
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
########### 変更箇所 ##############
hidden_f = functions.relu
#################################
u1 = np.dot(x, W1) + b1
z1 = hidden_f(u1)
u2 = np.dot(z1, W2) + b2
z2 = hidden_f(u2)
u3 = np.dot(z2, W3) + b3
y = functions.softmax(u3)
return z1, z2, y
# 誤差逆伝播
def backward(x, d, z1, z2, y):
grad = {}
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
########### 変更箇所 ##############
hidden_d_f = functions.d_relu
#################################
# 出力層でのデルタ
delta3 = functions.d_softmax_with_loss(d, y)
# b3の勾配
grad['b3'] = np.sum(delta3, axis=0)
# W3の勾配
grad['W3'] = np.dot(z2.T, delta3)
# 2層でのデルタ
delta2 = np.dot(delta3, W3.T) * hidden_d_f(z2)
# b2の勾配
grad['b2'] = np.sum(delta2, axis=0)
# W2の勾配
grad['W2'] = np.dot(z1.T, delta2)
# 1層でのデルタ
delta1 = np.dot(delta2, W2.T) * hidden_d_f(z1)
# b1の勾配
grad['b1'] = np.sum(delta1, axis=0)
# W1の勾配
grad['W1'] = np.dot(x.T, delta1)
return grad
# パラメータの初期化
network = init_network()
accuracies_train = []
accuracies_test = []
# 正答率
def accuracy(x, d):
z1, z2, y = forward(network, x)
y = np.argmax(y, axis=1)
if d.ndim != 1 : d = np.argmax(d, axis=1)
accuracy = np.sum(y == d) / float(x.shape[0])
return accuracy
for i in range(iters_num):
# ランダムにバッチを取得
batch_mask = np.random.choice(train_size, batch_size)
# ミニバッチに対応する教師訓練画像データを取得
x_batch = x_train[batch_mask]
# ミニバッチに対応する訓練正解ラベルデータを取得する
d_batch = d_train[batch_mask]
z1, z2, y = forward(network, x_batch)
grad = backward(x_batch, d_batch, z1, z2, y)
if (i+1)%plot_interval==0:
accr_test = accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
# パラメータに勾配適用
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
network[key] -= learning_rate * grad[key]
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()
データ読み込み完了
Generation: 10. 正答率(トレーニング) = 0.12
: 10. 正答率(テスト) = 0.1135
Generation: 20. 正答率(トレーニング) = 0.07
: 20. 正答率(テスト) = 0.1135
Generation: 30. 正答率(トレーニング) = 0.09
: 30. 正答率(テスト) = 0.1135
Generation: 40. 正答率(トレーニング) = 0.1
: 40. 正答率(テスト) = 0.1135
Generation: 50. 正答率(トレーニング) = 0.12
: 50. 正答率(テスト) = 0.1135
Generation: 60. 正答率(トレーニング) = 0.12
: 60. 正答率(テスト) = 0.1135
Generation: 70. 正答率(トレーニング) = 0.15
: 70. 正答率(テスト) = 0.1135
Generation: 80. 正答率(トレーニング) = 0.12
: 80. 正答率(テスト) = 0.1135
Generation: 90. 正答率(トレーニング) = 0.1
: 90. 正答率(テスト) = 0.1135
Generation: 100. 正答率(トレーニング) = 0.14
: 100. 正答率(テスト) = 0.1135
Generation: 110. 正答率(トレーニング) = 0.14
: 110. 正答率(テスト) = 0.1135
Generation: 120. 正答率(トレーニング) = 0.08
: 120. 正答率(テスト) = 0.1135
Generation: 130. 正答率(トレーニング) = 0.09
: 130. 正答率(テスト) = 0.1135
Generation: 140. 正答率(トレーニング) = 0.1
: 140. 正答率(テスト) = 0.1135
Generation: 150. 正答率(トレーニング) = 0.09
: 150. 正答率(テスト) = 0.1135
Generation: 160. 正答率(トレーニング) = 0.08
: 160. 正答率(テスト) = 0.1135
Generation: 170. 正答率(トレーニング) = 0.1
: 170. 正答率(テスト) = 0.1135
Generation: 180. 正答率(トレーニング) = 0.11
: 180. 正答率(テスト) = 0.1135
Generation: 190. 正答率(トレーニング) = 0.13
: 190. 正答率(テスト) = 0.1135
Generation: 200. 正答率(トレーニング) = 0.07
: 200. 正答率(テスト) = 0.1135
Generation: 210. 正答率(トレーニング) = 0.1
: 210. 正答率(テスト) = 0.1135
Generation: 220. 正答率(トレーニング) = 0.09
: 220. 正答率(テスト) = 0.1135
Generation: 230. 正答率(トレーニング) = 0.06
: 230. 正答率(テスト) = 0.1135
Generation: 240. 正答率(トレーニング) = 0.11
: 240. 正答率(テスト) = 0.1135
Generation: 250. 正答率(トレーニング) = 0.11
: 250. 正答率(テスト) = 0.1135
Generation: 260. 正答率(トレーニング) = 0.09
: 260. 正答率(テスト) = 0.1135
Generation: 270. 正答率(トレーニング) = 0.13
: 270. 正答率(テスト) = 0.1135
Generation: 280. 正答率(トレーニング) = 0.1
: 280. 正答率(テスト) = 0.1135
Generation: 290. 正答率(トレーニング) = 0.11
: 290. 正答率(テスト) = 0.1135
Generation: 300. 正答率(トレーニング) = 0.09
: 300. 正答率(テスト) = 0.1135
Generation: 310. 正答率(トレーニング) = 0.12
: 310. 正答率(テスト) = 0.1135
Generation: 320. 正答率(トレーニング) = 0.14
: 320. 正答率(テスト) = 0.1135
Generation: 330. 正答率(トレーニング) = 0.05
: 330. 正答率(テスト) = 0.1135
Generation: 340. 正答率(トレーニング) = 0.14
: 340. 正答率(テスト) = 0.1135
Generation: 350. 正答率(トレーニング) = 0.07
: 350. 正答率(テスト) = 0.1135
Generation: 360. 正答率(トレーニング) = 0.1
: 360. 正答率(テスト) = 0.1135
Generation: 370. 正答率(トレーニング) = 0.16
: 370. 正答率(テスト) = 0.1135
Generation: 380. 正答率(トレーニング) = 0.11
: 380. 正答率(テスト) = 0.1135
Generation: 390. 正答率(トレーニング) = 0.13
: 390. 正答率(テスト) = 0.1135
Generation: 400. 正答率(トレーニング) = 0.11
: 400. 正答率(テスト) = 0.1135
Generation: 410. 正答率(トレーニング) = 0.08
: 410. 正答率(テスト) = 0.1135
Generation: 420. 正答率(トレーニング) = 0.07
: 420. 正答率(テスト) = 0.1135
Generation: 430. 正答率(トレーニング) = 0.13
: 430. 正答率(テスト) = 0.1135
Generation: 440. 正答率(トレーニング) = 0.16
: 440. 正答率(テスト) = 0.1135
Generation: 450. 正答率(トレーニング) = 0.11
: 450. 正答率(テスト) = 0.1135
Generation: 460. 正答率(トレーニング) = 0.11
: 460. 正答率(テスト) = 0.1135
Generation: 470. 正答率(トレーニング) = 0.15
: 470. 正答率(テスト) = 0.1135
Generation: 480. 正答率(トレーニング) = 0.11
: 480. 正答率(テスト) = 0.1135
Generation: 490. 正答率(トレーニング) = 0.07
: 490. 正答率(テスト) = 0.1135
Generation: 500. 正答率(トレーニング) = 0.08
: 500. 正答率(テスト) = 0.1135
Generation: 510. 正答率(トレーニング) = 0.15
: 510. 正答率(テスト) = 0.1135
Generation: 520. 正答率(トレーニング) = 0.16
: 520. 正答率(テスト) = 0.1135
Generation: 530. 正答率(トレーニング) = 0.08
: 530. 正答率(テスト) = 0.1135
Generation: 540. 正答率(トレーニング) = 0.1
: 540. 正答率(テスト) = 0.1135
Generation: 550. 正答率(トレーニング) = 0.16
: 550. 正答率(テスト) = 0.1135
Generation: 560. 正答率(トレーニング) = 0.12
: 560. 正答率(テスト) = 0.1135
Generation: 570. 正答率(トレーニング) = 0.1
: 570. 正答率(テスト) = 0.1135
Generation: 580. 正答率(トレーニング) = 0.11
: 580. 正答率(テスト) = 0.1135
Generation: 590. 正答率(トレーニング) = 0.1
: 590. 正答率(テスト) = 0.1135
Generation: 600. 正答率(トレーニング) = 0.12
: 600. 正答率(テスト) = 0.1135
Generation: 610. 正答率(トレーニング) = 0.07
: 610. 正答率(テスト) = 0.1135
Generation: 620. 正答率(トレーニング) = 0.08
: 620. 正答率(テスト) = 0.1135
Generation: 630. 正答率(トレーニング) = 0.09
: 630. 正答率(テスト) = 0.1135
Generation: 640. 正答率(トレーニング) = 0.12
: 640. 正答率(テスト) = 0.1135
Generation: 650. 正答率(トレーニング) = 0.14
: 650. 正答率(テスト) = 0.1153
Generation: 660. 正答率(トレーニング) = 0.09
: 660. 正答率(テスト) = 0.1151
Generation: 670. 正答率(トレーニング) = 0.14
: 670. 正答率(テスト) = 0.1686
Generation: 680. 正答率(トレーニング) = 0.18
: 680. 正答率(テスト) = 0.1836
Generation: 690. 正答率(トレーニング) = 0.23
: 690. 正答率(テスト) = 0.1869
Generation: 700. 正答率(トレーニング) = 0.17
: 700. 正答率(テスト) = 0.1943
Generation: 710. 正答率(トレーニング) = 0.14
: 710. 正答率(テスト) = 0.197
Generation: 720. 正答率(トレーニング) = 0.21
: 720. 正答率(テスト) = 0.2298
Generation: 730. 正答率(トレーニング) = 0.24
: 730. 正答率(テスト) = 0.2495
Generation: 740. 正答率(トレーニング) = 0.31
: 740. 正答率(テスト) = 0.274
Generation: 750. 正答率(トレーニング) = 0.29
: 750. 正答率(テスト) = 0.2963
Generation: 760. 正答率(トレーニング) = 0.31
: 760. 正答率(テスト) = 0.3039
Generation: 770. 正答率(トレーニング) = 0.26
: 770. 正答率(テスト) = 0.3058
Generation: 780. 正答率(トレーニング) = 0.23
: 780. 正答率(テスト) = 0.3196
Generation: 790. 正答率(トレーニング) = 0.28
: 790. 正答率(テスト) = 0.3382
Generation: 800. 正答率(トレーニング) = 0.34
: 800. 正答率(テスト) = 0.3324
Generation: 810. 正答率(トレーニング) = 0.38
: 810. 正答率(テスト) = 0.338
Generation: 820. 正答率(トレーニング) = 0.31
: 820. 正答率(テスト) = 0.333
Generation: 830. 正答率(トレーニング) = 0.34
: 830. 正答率(テスト) = 0.3447
Generation: 840. 正答率(トレーニング) = 0.32
: 840. 正答率(テスト) = 0.335
Generation: 850. 正答率(トレーニング) = 0.36
: 850. 正答率(テスト) = 0.3658
Generation: 860. 正答率(トレーニング) = 0.42
: 860. 正答率(テスト) = 0.4131
Generation: 870. 正答率(トレーニング) = 0.37
: 870. 正答率(テスト) = 0.408
Generation: 880. 正答率(トレーニング) = 0.37
: 880. 正答率(テスト) = 0.4596
Generation: 890. 正答率(トレーニング) = 0.4
: 890. 正答率(テスト) = 0.4708
Generation: 900. 正答率(トレーニング) = 0.48
: 900. 正答率(テスト) = 0.4951
Generation: 910. 正答率(トレーニング) = 0.49
: 910. 正答率(テスト) = 0.5156
Generation: 920. 正答率(トレーニング) = 0.61
: 920. 正答率(テスト) = 0.5322
Generation: 930. 正答率(トレーニング) = 0.61
: 930. 正答率(テスト) = 0.5901
Generation: 940. 正答率(トレーニング) = 0.45
: 940. 正答率(テスト) = 0.5238
Generation: 950. 正答率(トレーニング) = 0.63
: 950. 正答率(テスト) = 0.6074
Generation: 960. 正答率(トレーニング) = 0.59
: 960. 正答率(テスト) = 0.5574
Generation: 970. 正答率(トレーニング) = 0.56
: 970. 正答率(テスト) = 0.6164
Generation: 980. 正答率(トレーニング) = 0.68
: 980. 正答率(テスト) = 0.6329
Generation: 990. 正答率(トレーニング) = 0.6
: 990. 正答率(テスト) = 0.6398
Generation: 1000. 正答率(トレーニング) = 0.7
: 1000. 正答率(テスト) = 0.6462
Generation: 1010. 正答率(トレーニング) = 0.57
: 1010. 正答率(テスト) = 0.6459
Generation: 1020. 正答率(トレーニング) = 0.72
: 1020. 正答率(テスト) = 0.6863
Generation: 1030. 正答率(トレーニング) = 0.59
: 1030. 正答率(テスト) = 0.6977
Generation: 1040. 正答率(トレーニング) = 0.7
: 1040. 正答率(テスト) = 0.6774
Generation: 1050. 正答率(トレーニング) = 0.7
: 1050. 正答率(テスト) = 0.7294
Generation: 1060. 正答率(トレーニング) = 0.75
: 1060. 正答率(テスト) = 0.7486
Generation: 1070. 正答率(トレーニング) = 0.73
: 1070. 正答率(テスト) = 0.74
Generation: 1080. 正答率(トレーニング) = 0.69
: 1080. 正答率(テスト) = 0.7162
Generation: 1090. 正答率(トレーニング) = 0.76
: 1090. 正答率(テスト) = 0.7583
Generation: 1100. 正答率(トレーニング) = 0.74
: 1100. 正答率(テスト) = 0.7716
Generation: 1110. 正答率(トレーニング) = 0.75
: 1110. 正答率(テスト) = 0.7557
Generation: 1120. 正答率(トレーニング) = 0.83
: 1120. 正答率(テスト) = 0.7813
Generation: 1130. 正答率(トレーニング) = 0.81
: 1130. 正答率(テスト) = 0.7858
Generation: 1140. 正答率(トレーニング) = 0.74
: 1140. 正答率(テスト) = 0.8051
Generation: 1150. 正答率(トレーニング) = 0.72
: 1150. 正答率(テスト) = 0.772
Generation: 1160. 正答率(トレーニング) = 0.81
: 1160. 正答率(テスト) = 0.8061
Generation: 1170. 正答率(トレーニング) = 0.78
: 1170. 正答率(テスト) = 0.8167
Generation: 1180. 正答率(トレーニング) = 0.8
: 1180. 正答率(テスト) = 0.7966
Generation: 1190. 正答率(トレーニング) = 0.73
: 1190. 正答率(テスト) = 0.8139
Generation: 1200. 正答率(トレーニング) = 0.85
: 1200. 正答率(テスト) = 0.79
Generation: 1210. 正答率(トレーニング) = 0.8
: 1210. 正答率(テスト) = 0.8253
Generation: 1220. 正答率(トレーニング) = 0.89
: 1220. 正答率(テスト) = 0.789
Generation: 1230. 正答率(トレーニング) = 0.87
: 1230. 正答率(テスト) = 0.8283
Generation: 1240. 正答率(トレーニング) = 0.83
: 1240. 正答率(テスト) = 0.8225
Generation: 1250. 正答率(トレーニング) = 0.89
: 1250. 正答率(テスト) = 0.8397
Generation: 1260. 正答率(トレーニング) = 0.74
: 1260. 正答率(テスト) = 0.8274
Generation: 1270. 正答率(トレーニング) = 0.82
: 1270. 正答率(テスト) = 0.8126
Generation: 1280. 正答率(トレーニング) = 0.84
: 1280. 正答率(テスト) = 0.8339
Generation: 1290. 正答率(トレーニング) = 0.81
: 1290. 正答率(テスト) = 0.843
Generation: 1300. 正答率(トレーニング) = 0.86
: 1300. 正答率(テスト) = 0.8383
Generation: 1310. 正答率(トレーニング) = 0.82
: 1310. 正答率(テスト) = 0.8503
Generation: 1320. 正答率(トレーニング) = 0.86
: 1320. 正答率(テスト) = 0.8306
Generation: 1330. 正答率(トレーニング) = 0.83
: 1330. 正答率(テスト) = 0.8501
Generation: 1340. 正答率(トレーニング) = 0.81
: 1340. 正答率(テスト) = 0.8529
Generation: 1350. 正答率(トレーニング) = 0.82
: 1350. 正答率(テスト) = 0.8545
Generation: 1360. 正答率(トレーニング) = 0.88
: 1360. 正答率(テスト) = 0.8597
Generation: 1370. 正答率(トレーニング) = 0.87
: 1370. 正答率(テスト) = 0.8606
Generation: 1380. 正答率(トレーニング) = 0.88
: 1380. 正答率(テスト) = 0.8576
Generation: 1390. 正答率(トレーニング) = 0.9
: 1390. 正答率(テスト) = 0.8706
Generation: 1400. 正答率(トレーニング) = 0.91
: 1400. 正答率(テスト) = 0.8573
Generation: 1410. 正答率(トレーニング) = 0.85
: 1410. 正答率(テスト) = 0.8697
Generation: 1420. 正答率(トレーニング) = 0.87
: 1420. 正答率(テスト) = 0.8675
Generation: 1430. 正答率(トレーニング) = 0.85
: 1430. 正答率(テスト) = 0.8703
Generation: 1440. 正答率(トレーニング) = 0.84
: 1440. 正答率(テスト) = 0.8686
Generation: 1450. 正答率(トレーニング) = 0.84
: 1450. 正答率(テスト) = 0.8553
Generation: 1460. 正答率(トレーニング) = 0.89
: 1460. 正答率(テスト) = 0.8695
Generation: 1470. 正答率(トレーニング) = 0.87
: 1470. 正答率(テスト) = 0.8753
Generation: 1480. 正答率(トレーニング) = 0.86
: 1480. 正答率(テスト) = 0.8792
Generation: 1490. 正答率(トレーニング) = 0.89
: 1490. 正答率(テスト) = 0.8796
Generation: 1500. 正答率(トレーニング) = 0.93
: 1500. 正答率(テスト) = 0.8814
Generation: 1510. 正答率(トレーニング) = 0.88
: 1510. 正答率(テスト) = 0.8815
Generation: 1520. 正答率(トレーニング) = 0.9
: 1520. 正答率(テスト) = 0.8813
Generation: 1530. 正答率(トレーニング) = 0.87
: 1530. 正答率(テスト) = 0.8812
Generation: 1540. 正答率(トレーニング) = 0.87
: 1540. 正答率(テスト) = 0.8865
Generation: 1550. 正答率(トレーニング) = 0.89
: 1550. 正答率(テスト) = 0.8846
Generation: 1560. 正答率(トレーニング) = 0.85
: 1560. 正答率(テスト) = 0.8806
Generation: 1570. 正答率(トレーニング) = 0.82
: 1570. 正答率(テスト) = 0.8814
Generation: 1580. 正答率(トレーニング) = 0.91
: 1580. 正答率(テスト) = 0.8824
Generation: 1590. 正答率(トレーニング) = 0.85
: 1590. 正答率(テスト) = 0.8837
Generation: 1600. 正答率(トレーニング) = 0.86
: 1600. 正答率(テスト) = 0.8848
Generation: 1610. 正答率(トレーニング) = 0.93
: 1610. 正答率(テスト) = 0.8913
Generation: 1620. 正答率(トレーニング) = 0.88
: 1620. 正答率(テスト) = 0.889
Generation: 1630. 正答率(トレーニング) = 0.89
: 1630. 正答率(テスト) = 0.8897
Generation: 1640. 正答率(トレーニング) = 0.92
: 1640. 正答率(テスト) = 0.882
Generation: 1650. 正答率(トレーニング) = 0.87
: 1650. 正答率(テスト) = 0.8924
Generation: 1660. 正答率(トレーニング) = 0.93
: 1660. 正答率(テスト) = 0.8869
Generation: 1670. 正答率(トレーニング) = 0.95
: 1670. 正答率(テスト) = 0.8863
Generation: 1680. 正答率(トレーニング) = 0.89
: 1680. 正答率(テスト) = 0.8879
Generation: 1690. 正答率(トレーニング) = 0.9
: 1690. 正答率(テスト) = 0.8812
Generation: 1700. 正答率(トレーニング) = 0.9
: 1700. 正答率(テスト) = 0.8937
Generation: 1710. 正答率(トレーニング) = 0.89
: 1710. 正答率(テスト) = 0.887
Generation: 1720. 正答率(トレーニング) = 0.88
: 1720. 正答率(テスト) = 0.896
Generation: 1730. 正答率(トレーニング) = 0.94
: 1730. 正答率(テスト) = 0.8853
Generation: 1740. 正答率(トレーニング) = 0.89
: 1740. 正答率(テスト) = 0.897
Generation: 1750. 正答率(トレーニング) = 0.92
: 1750. 正答率(テスト) = 0.8877
Generation: 1760. 正答率(トレーニング) = 0.95
: 1760. 正答率(テスト) = 0.8924
Generation: 1770. 正答率(トレーニング) = 0.91
: 1770. 正答率(テスト) = 0.9009
Generation: 1780. 正答率(トレーニング) = 0.91
: 1780. 正答率(テスト) = 0.9015
Generation: 1790. 正答率(トレーニング) = 0.84
: 1790. 正答率(テスト) = 0.9025
Generation: 1800. 正答率(トレーニング) = 0.94
: 1800. 正答率(テスト) = 0.8979
Generation: 1810. 正答率(トレーニング) = 0.88
: 1810. 正答率(テスト) = 0.8984
Generation: 1820. 正答率(トレーニング) = 0.92
: 1820. 正答率(テスト) = 0.8994
Generation: 1830. 正答率(トレーニング) = 0.84
: 1830. 正答率(テスト) = 0.8934
Generation: 1840. 正答率(トレーニング) = 0.9
: 1840. 正答率(テスト) = 0.9023
Generation: 1850. 正答率(トレーニング) = 0.93
: 1850. 正答率(テスト) = 0.9003
Generation: 1860. 正答率(トレーニング) = 0.91
: 1860. 正答率(テスト) = 0.8989
Generation: 1870. 正答率(トレーニング) = 0.92
: 1870. 正答率(テスト) = 0.9001
Generation: 1880. 正答率(トレーニング) = 0.89
: 1880. 正答率(テスト) = 0.9032
Generation: 1890. 正答率(トレーニング) = 0.89
: 1890. 正答率(テスト) = 0.9017
Generation: 1900. 正答率(トレーニング) = 0.84
: 1900. 正答率(テスト) = 0.9033
Generation: 1910. 正答率(トレーニング) = 0.95
: 1910. 正答率(テスト) = 0.9076
Generation: 1920. 正答率(トレーニング) = 0.95
: 1920. 正答率(テスト) = 0.9118
Generation: 1930. 正答率(トレーニング) = 0.88
: 1930. 正答率(テスト) = 0.9078
Generation: 1940. 正答率(トレーニング) = 0.93
: 1940. 正答率(テスト) = 0.9092
Generation: 1950. 正答率(トレーニング) = 0.94
: 1950. 正答率(テスト) = 0.9015
Generation: 1960. 正答率(トレーニング) = 0.88
: 1960. 正答率(テスト) = 0.9084
Generation: 1970. 正答率(トレーニング) = 0.91
: 1970. 正答率(テスト) = 0.9078
Generation: 1980. 正答率(トレーニング) = 0.92
: 1980. 正答率(テスト) = 0.907
Generation: 1990. 正答率(トレーニング) = 0.91
: 1990. 正答率(テスト) = 0.913
Generation: 2000. 正答率(トレーニング) = 0.93
: 2000. 正答率(テスト) = 0.9125
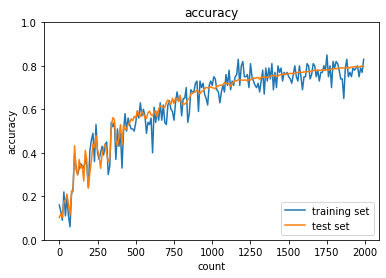
1.2.2 重みの初期値設定(Xavier)
乱数を使って初期化するのが主で、その1つがXavier(ザビエル)
通常は正規分布に従った乱数の設定をする。
初期化を工夫して勾配消失を解消。
⇒ Xavier(ザビエル)の初期値を設定するとき
各重みに対して前のノード数($n$)に対して、$\times\frac{1}{\sqrt{n}}$ した値を初期値とするアルゴリズム。
(前のノード数のルート[平方根]で割る)
活性化関数はシグモイド(ロジスティック)関数、双曲線正接関数(tanh)
⇒ S字カーブになっている活性化関数に対してXavier(ザビエル)はうまく働く。
self.params['W1'] = np.random.randn(input_size, hidden_size) / nq.sqrt(input_layer_size)
self.params['W2'] = np.random.randn(hidden_size, output_size) / nq.sqrt(hidden_layer_size)
実装
import numpy as np
from data.mnist import load_mnist
from PIL import Image
import pickle
from common import functions
import matplotlib.pyplot as plt
# mnistをロード
(x_train, d_train), (x_test, d_test) = load_mnist(normalize=True, one_hot_label=True)
train_size = len(x_train)
print("データ読み込み完了")
# 入力層サイズ
input_layer_size = 784
# 中間層サイズ
hidden_layer_1_size = 40
hidden_layer_2_size = 20
# 出力層サイズ
output_layer_size = 10
# 繰り返し数
iters_num = 2000
# ミニバッチサイズ
batch_size = 100
# 学習率
learning_rate = 0.1
# 描写頻度
plot_interval=10
# 初期設定
def init_network():
network = {}
########### 変更箇所 ##############
# Xavierの初期値
network['W1'] = np.random.randn(input_layer_size, hidden_layer_1_size) / (np.sqrt(input_layer_size))
network['W2'] = np.random.randn(hidden_layer_1_size, hidden_layer_2_size) / (np.sqrt(hidden_layer_1_size))
network['W3'] = np.random.randn(hidden_layer_2_size, output_layer_size) / (np.sqrt(hidden_layer_2_size))
#################################
network['b1'] = np.zeros(hidden_layer_1_size)
network['b2'] = np.zeros(hidden_layer_2_size)
network['b3'] = np.zeros(output_layer_size)
return network
# 順伝播
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
hidden_f = functions.sigmoid
u1 = np.dot(x, W1) + b1
z1 = hidden_f(u1)
u2 = np.dot(z1, W2) + b2
z2 = hidden_f(u2)
u3 = np.dot(z2, W3) + b3
y = functions.softmax(u3)
return z1, z2, y
# 誤差逆伝播
def backward(x, d, z1, z2, y):
grad = {}
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
hidden_d_f = functions.d_sigmoid
# 出力層でのデルタ
delta3 = functions.d_softmax_with_loss(d, y)
# b3の勾配
grad['b3'] = np.sum(delta3, axis=0)
# W3の勾配
grad['W3'] = np.dot(z2.T, delta3)
# 2層でのデルタ
delta2 = np.dot(delta3, W3.T) * hidden_d_f(z2)
# b2の勾配
grad['b2'] = np.sum(delta2, axis=0)
# W2の勾配
grad['W2'] = np.dot(z1.T, delta2)
# 1層でのデルタ
delta1 = np.dot(delta2, W2.T) * hidden_d_f(z1)
# b1の勾配
grad['b1'] = np.sum(delta1, axis=0)
# W1の勾配
grad['W1'] = np.dot(x.T, delta1)
return grad
# パラメータの初期化
network = init_network()
accuracies_train = []
accuracies_test = []
# 正答率
def accuracy(x, d):
z1, z2, y = forward(network, x)
y = np.argmax(y, axis=1)
if d.ndim != 1 : d = np.argmax(d, axis=1)
accuracy = np.sum(y == d) / float(x.shape[0])
return accuracy
for i in range(iters_num):
# ランダムにバッチを取得
batch_mask = np.random.choice(train_size, batch_size)
# ミニバッチに対応する教師訓練画像データを取得
x_batch = x_train[batch_mask]
# ミニバッチに対応する訓練正解ラベルデータを取得する
d_batch = d_train[batch_mask]
z1, z2, y = forward(network, x_batch)
grad = backward(x_batch, d_batch, z1, z2, y)
if (i+1)%plot_interval==0:
accr_test = accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
# パラメータに勾配適用
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
network[key] -= learning_rate * grad[key]
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()
データ読み込み完了
Generation: 10. 正答率(トレーニング) = 0.16
: 10. 正答率(テスト) = 0.1028
Generation: 20. 正答率(トレーニング) = 0.13
: 20. 正答率(テスト) = 0.119
Generation: 30. 正答率(トレーニング) = 0.09
: 30. 正答率(テスト) = 0.1027
Generation: 40. 正答率(トレーニング) = 0.22
: 40. 正答率(テスト) = 0.1775
Generation: 50. 正答率(トレーニング) = 0.11
: 50. 正答率(テスト) = 0.1799
Generation: 60. 正答率(トレーニング) = 0.2
: 60. 正答率(テスト) = 0.2105
Generation: 70. 正答率(トレーニング) = 0.11
: 70. 正答率(テスト) = 0.161
Generation: 80. 正答率(トレーニング) = 0.06
: 80. 正答率(テスト) = 0.1148
Generation: 90. 正答率(トレーニング) = 0.21
: 90. 正答率(テスト) = 0.2231
Generation: 100. 正答率(トレーニング) = 0.24
: 100. 正答率(テスト) = 0.2214
Generation: 110. 正答率(トレーニング) = 0.4
: 110. 正答率(テスト) = 0.4325
Generation: 120. 正答率(トレーニング) = 0.33
: 120. 正答率(テスト) = 0.323
Generation: 130. 正答率(トレーニング) = 0.3
: 130. 正答率(テスト) = 0.2982
Generation: 140. 正答率(トレーニング) = 0.33
: 140. 正答率(テスト) = 0.3687
Generation: 150. 正答率(トレーニング) = 0.35
: 150. 正答率(テスト) = 0.3297
Generation: 160. 正答率(トレーニング) = 0.34
: 160. 正答率(テスト) = 0.3389
Generation: 170. 正答率(トレーニング) = 0.33
: 170. 正答率(テスト) = 0.2706
Generation: 180. 正答率(トレーニング) = 0.37
: 180. 正答率(テスト) = 0.4114
Generation: 190. 正答率(トレーニング) = 0.34
: 190. 正答率(テスト) = 0.3654
Generation: 200. 正答率(トレーニング) = 0.24
: 200. 正答率(テスト) = 0.2383
Generation: 210. 正答率(トレーニング) = 0.41
: 210. 正答率(テスト) = 0.3074
Generation: 220. 正答率(トレーニング) = 0.46
: 220. 正答率(テスト) = 0.3669
Generation: 230. 正答率(トレーニング) = 0.49
: 230. 正答率(テスト) = 0.4403
Generation: 240. 正答率(トレーニング) = 0.36
: 240. 正答率(テスト) = 0.4248
Generation: 250. 正答率(トレーニング) = 0.53
: 250. 正答率(テスト) = 0.4794
Generation: 260. 正答率(トレーニング) = 0.4
: 260. 正答率(テスト) = 0.4134
Generation: 270. 正答率(トレーニング) = 0.37
: 270. 正答率(テスト) = 0.3877
Generation: 280. 正答率(トレーニング) = 0.4
: 280. 正答率(テスト) = 0.329
Generation: 290. 正答率(トレーニング) = 0.43
: 290. 正答率(テスト) = 0.3922
Generation: 300. 正答率(トレーニング) = 0.39
: 300. 正答率(テスト) = 0.4222
Generation: 310. 正答率(トレーニング) = 0.44
: 310. 正答率(テスト) = 0.4386
Generation: 320. 正答率(トレーニング) = 0.45
: 320. 正答率(テスト) = 0.395
Generation: 330. 正答率(トレーニング) = 0.3
: 330. 正答率(テスト) = 0.3593
Generation: 340. 正答率(トレーニング) = 0.34
: 340. 正答率(テスト) = 0.3742
Generation: 350. 正答率(トレーニング) = 0.54
: 350. 正答率(テスト) = 0.5203
Generation: 360. 正答率(トレーニング) = 0.52
: 360. 正答率(テスト) = 0.5615
Generation: 370. 正答率(トレーニング) = 0.54
: 370. 正答率(テスト) = 0.554
Generation: 380. 正答率(トレーニング) = 0.37
: 380. 正答率(テスト) = 0.4514
Generation: 390. 正答率(トレーニング) = 0.51
: 390. 正答率(テスト) = 0.4318
Generation: 400. 正答率(トレーニング) = 0.43
: 400. 正答率(テスト) = 0.473
Generation: 410. 正答率(トレーニング) = 0.49
: 410. 正答率(テスト) = 0.5297
Generation: 420. 正答率(トレーニング) = 0.33
: 420. 正答率(テスト) = 0.4382
Generation: 430. 正答率(トレーニング) = 0.5
: 430. 正答率(テスト) = 0.5263
Generation: 440. 正答率(トレーニング) = 0.58
: 440. 正答率(テスト) = 0.5059
Generation: 450. 正答率(トレーニング) = 0.5
: 450. 正答率(テスト) = 0.5113
Generation: 460. 正答率(トレーニング) = 0.56
: 460. 正答率(テスト) = 0.5296
Generation: 470. 正答率(トレーニング) = 0.53
: 470. 正答率(テスト) = 0.5391
Generation: 480. 正答率(トレーニング) = 0.51
: 480. 正答率(テスト) = 0.5567
Generation: 490. 正答率(トレーニング) = 0.51
: 490. 正答率(テスト) = 0.5474
Generation: 500. 正答率(トレーニング) = 0.5
: 500. 正答率(テスト) = 0.5674
Generation: 510. 正答率(トレーニング) = 0.54
: 510. 正答率(テスト) = 0.5598
Generation: 520. 正答率(トレーニング) = 0.59
: 520. 正答率(テスト) = 0.5938
Generation: 530. 正答率(トレーニング) = 0.56
: 530. 正答率(テスト) = 0.5751
Generation: 540. 正答率(トレーニング) = 0.63
: 540. 正答率(テスト) = 0.567
Generation: 550. 正答率(トレーニング) = 0.57
: 550. 正答率(テスト) = 0.5893
Generation: 560. 正答率(トレーニング) = 0.6
: 560. 正答率(テスト) = 0.5806
Generation: 570. 正答率(トレーニング) = 0.57
: 570. 正答率(テスト) = 0.5597
Generation: 580. 正答率(トレーニング) = 0.49
: 580. 正答率(テスト) = 0.5581
Generation: 590. 正答率(トレーニング) = 0.54
: 590. 正答率(テスト) = 0.5847
Generation: 600. 正答率(トレーニング) = 0.53
: 600. 正答率(テスト) = 0.5911
Generation: 610. 正答率(トレーニング) = 0.56
: 610. 正答率(テスト) = 0.575
Generation: 620. 正答率(トレーニング) = 0.4
: 620. 正答率(テスト) = 0.5704
Generation: 630. 正答率(トレーニング) = 0.61
: 630. 正答率(テスト) = 0.5865
Generation: 640. 正答率(トレーニング) = 0.54
: 640. 正答率(テスト) = 0.5935
Generation: 650. 正答率(トレーニング) = 0.59
: 650. 正答率(テスト) = 0.5656
Generation: 660. 正答率(トレーニング) = 0.55
: 660. 正答率(テスト) = 0.602
Generation: 670. 正答率(トレーニング) = 0.63
: 670. 正答率(テスト) = 0.6167
Generation: 680. 正答率(トレーニング) = 0.55
: 680. 正答率(テスト) = 0.6122
Generation: 690. 正答率(トレーニング) = 0.62
: 690. 正答率(テスト) = 0.6104
Generation: 700. 正答率(トレーニング) = 0.54
: 700. 正答率(テスト) = 0.609
Generation: 710. 正答率(トレーニング) = 0.53
: 710. 正答率(テスト) = 0.6311
Generation: 720. 正答率(トレーニング) = 0.62
: 720. 正答率(テスト) = 0.6429
Generation: 730. 正答率(トレーニング) = 0.64
: 730. 正答率(テスト) = 0.6308
Generation: 740. 正答率(トレーニング) = 0.6
: 740. 正答率(テスト) = 0.6234
Generation: 750. 正答率(トレーニング) = 0.59
: 750. 正答率(テスト) = 0.6503
Generation: 760. 正答率(トレーニング) = 0.55
: 760. 正答率(テスト) = 0.6273
Generation: 770. 正答率(トレーニング) = 0.63
: 770. 正答率(テスト) = 0.6529
Generation: 780. 正答率(トレーニング) = 0.68
: 780. 正答率(テスト) = 0.6481
Generation: 790. 正答率(トレーニング) = 0.64
: 790. 正答率(テスト) = 0.6359
Generation: 800. 正答率(トレーニング) = 0.66
: 800. 正答率(テスト) = 0.6649
Generation: 810. 正答率(トレーニング) = 0.57
: 810. 正答率(テスト) = 0.6255
Generation: 820. 正答率(トレーニング) = 0.65
: 820. 正答率(テスト) = 0.6234
Generation: 830. 正答率(トレーニング) = 0.65
: 830. 正答率(テスト) = 0.6241
Generation: 840. 正答率(トレーニング) = 0.7
: 840. 正答率(テスト) = 0.6304
Generation: 850. 正答率(トレーニング) = 0.54
: 850. 正答率(テスト) = 0.6462
Generation: 860. 正答率(トレーニング) = 0.58
: 860. 正答率(テスト) = 0.6492
Generation: 870. 正答率(トレーニング) = 0.69
: 870. 正答率(テスト) = 0.6706
Generation: 880. 正答率(トレーニング) = 0.68
: 880. 正答率(テスト) = 0.6731
Generation: 890. 正答率(トレーニング) = 0.68
: 890. 正答率(テスト) = 0.6775
Generation: 900. 正答率(トレーニング) = 0.72
: 900. 正答率(テスト) = 0.6805
Generation: 910. 正答率(トレーニング) = 0.73
: 910. 正答率(テスト) = 0.6895
Generation: 920. 正答率(トレーニング) = 0.59
: 920. 正答率(テスト) = 0.6793
Generation: 930. 正答率(トレーニング) = 0.73
: 930. 正答率(テスト) = 0.6712
Generation: 940. 正答率(トレーニング) = 0.7
: 940. 正答率(テスト) = 0.6826
Generation: 950. 正答率(トレーニング) = 0.72
: 950. 正答率(テスト) = 0.6852
Generation: 960. 正答率(トレーニング) = 0.67
: 960. 正答率(テスト) = 0.6934
Generation: 970. 正答率(トレーニング) = 0.65
: 970. 正答率(テスト) = 0.7011
Generation: 980. 正答率(トレーニング) = 0.62
: 980. 正答率(テスト) = 0.6988
Generation: 990. 正答率(トレーニング) = 0.71
: 990. 正答率(テスト) = 0.6981
Generation: 1000. 正答率(トレーニング) = 0.73
: 1000. 正答率(テスト) = 0.7041
Generation: 1010. 正答率(トレーニング) = 0.71
: 1010. 正答率(テスト) = 0.699
Generation: 1020. 正答率(トレーニング) = 0.75
: 1020. 正答率(テスト) = 0.6981
Generation: 1030. 正答率(トレーニング) = 0.74
: 1030. 正答率(テスト) = 0.6935
Generation: 1040. 正答率(トレーニング) = 0.69
: 1040. 正答率(テスト) = 0.7085
Generation: 1050. 正答率(トレーニング) = 0.68
: 1050. 正答率(テスト) = 0.7075
Generation: 1060. 正答率(トレーニング) = 0.63
: 1060. 正答率(テスト) = 0.7109
Generation: 1070. 正答率(トレーニング) = 0.68
: 1070. 正答率(テスト) = 0.7102
Generation: 1080. 正答率(トレーニング) = 0.71
: 1080. 正答率(テスト) = 0.7129
Generation: 1090. 正答率(トレーニング) = 0.68
: 1090. 正答率(テスト) = 0.7234
Generation: 1100. 正答率(トレーニング) = 0.76
: 1100. 正答率(テスト) = 0.7184
Generation: 1110. 正答率(トレーニング) = 0.71
: 1110. 正答率(テスト) = 0.7185
Generation: 1120. 正答率(トレーニング) = 0.78
: 1120. 正答率(テスト) = 0.7172
Generation: 1130. 正答率(トレーニング) = 0.69
: 1130. 正答率(テスト) = 0.7056
Generation: 1140. 正答率(トレーニング) = 0.73
: 1140. 正答率(テスト) = 0.7202
Generation: 1150. 正答率(トレーニング) = 0.71
: 1150. 正答率(テスト) = 0.7234
Generation: 1160. 正答率(トレーニング) = 0.75
: 1160. 正答率(テスト) = 0.7319
Generation: 1170. 正答率(トレーニング) = 0.76
: 1170. 正答率(テスト) = 0.7309
Generation: 1180. 正答率(トレーニング) = 0.83
: 1180. 正答率(テスト) = 0.7365
Generation: 1190. 正答率(トレーニング) = 0.71
: 1190. 正答率(テスト) = 0.7361
Generation: 1200. 正答率(トレーニング) = 0.8
: 1200. 正答率(テスト) = 0.7352
Generation: 1210. 正答率(トレーニング) = 0.82
: 1210. 正答率(テスト) = 0.7332
Generation: 1220. 正答率(トレーニング) = 0.75
: 1220. 正答率(テスト) = 0.7347
Generation: 1230. 正答率(トレーニング) = 0.75
: 1230. 正答率(テスト) = 0.7353
Generation: 1240. 正答率(トレーニング) = 0.76
: 1240. 正答率(テスト) = 0.7305
Generation: 1250. 正答率(トレーニング) = 0.7
: 1250. 正答率(テスト) = 0.7371
Generation: 1260. 正答率(トレーニング) = 0.81
: 1260. 正答率(テスト) = 0.7342
Generation: 1270. 正答率(トレーニング) = 0.75
: 1270. 正答率(テスト) = 0.7427
Generation: 1280. 正答率(トレーニング) = 0.73
: 1280. 正答率(テスト) = 0.7444
Generation: 1290. 正答率(トレーニング) = 0.71
: 1290. 正答率(テスト) = 0.742
Generation: 1300. 正答率(トレーニング) = 0.7
: 1300. 正答率(テスト) = 0.746
Generation: 1310. 正答率(トレーニング) = 0.72
: 1310. 正答率(テスト) = 0.7458
Generation: 1320. 正答率(トレーニング) = 0.68
: 1320. 正答率(テスト) = 0.7387
Generation: 1330. 正答率(トレーニング) = 0.73
: 1330. 正答率(テスト) = 0.7481
Generation: 1340. 正答率(トレーニング) = 0.78
: 1340. 正答率(テスト) = 0.748
Generation: 1350. 正答率(トレーニング) = 0.67
: 1350. 正答率(テスト) = 0.7486
Generation: 1360. 正答率(トレーニング) = 0.79
: 1360. 正答率(テスト) = 0.7475
Generation: 1370. 正答率(トレーニング) = 0.73
: 1370. 正答率(テスト) = 0.7486
Generation: 1380. 正答率(トレーニング) = 0.79
: 1380. 正答率(テスト) = 0.7482
Generation: 1390. 正答率(トレーニング) = 0.74
: 1390. 正答率(テスト) = 0.7517
Generation: 1400. 正答率(トレーニング) = 0.81
: 1400. 正答率(テスト) = 0.7543
Generation: 1410. 正答率(トレーニング) = 0.69
: 1410. 正答率(テスト) = 0.7553
Generation: 1420. 正答率(トレーニング) = 0.77
: 1420. 正答率(テスト) = 0.7563
Generation: 1430. 正答率(トレーニング) = 0.7
: 1430. 正答率(テスト) = 0.7511
Generation: 1440. 正答率(トレーニング) = 0.8
: 1440. 正答率(テスト) = 0.7528
Generation: 1450. 正答率(トレーニング) = 0.77
: 1450. 正答率(テスト) = 0.7587
Generation: 1460. 正答率(トレーニング) = 0.79
: 1460. 正答率(テスト) = 0.7589
Generation: 1470. 正答率(トレーニング) = 0.73
: 1470. 正答率(テスト) = 0.761
Generation: 1480. 正答率(トレーニング) = 0.77
: 1480. 正答率(テスト) = 0.7626
Generation: 1490. 正答率(トレーニング) = 0.76
: 1490. 正答率(テスト) = 0.7613
Generation: 1500. 正答率(トレーニング) = 0.77
: 1500. 正答率(テスト) = 0.7642
Generation: 1510. 正答率(トレーニング) = 0.75
: 1510. 正答率(テスト) = 0.7641
Generation: 1520. 正答率(トレーニング) = 0.74
: 1520. 正答率(テスト) = 0.7651
Generation: 1530. 正答率(トレーニング) = 0.72
: 1530. 正答率(テスト) = 0.7657
Generation: 1540. 正答率(トレーニング) = 0.76
: 1540. 正答率(テスト) = 0.7641
Generation: 1550. 正答率(トレーニング) = 0.8
: 1550. 正答率(テスト) = 0.765
Generation: 1560. 正答率(トレーニング) = 0.75
: 1560. 正答率(テスト) = 0.7682
Generation: 1570. 正答率(トレーニング) = 0.73
: 1570. 正答率(テスト) = 0.7697
Generation: 1580. 正答率(トレーニング) = 0.8
: 1580. 正答率(テスト) = 0.7733
Generation: 1590. 正答率(トレーニング) = 0.75
: 1590. 正答率(テスト) = 0.7701
Generation: 1600. 正答率(トレーニング) = 0.69
: 1600. 正答率(テスト) = 0.7696
Generation: 1610. 正答率(トレーニング) = 0.75
: 1610. 正答率(テスト) = 0.773
Generation: 1620. 正答率(トレーニング) = 0.75
: 1620. 正答率(テスト) = 0.7707
Generation: 1630. 正答率(トレーニング) = 0.81
: 1630. 正答率(テスト) = 0.7731
Generation: 1640. 正答率(トレーニング) = 0.8
: 1640. 正答率(テスト) = 0.7739
Generation: 1650. 正答率(トレーニング) = 0.74
: 1650. 正答率(テスト) = 0.7738
Generation: 1660. 正答率(トレーニング) = 0.76
: 1660. 正答率(テスト) = 0.7763
Generation: 1670. 正答率(トレーニング) = 0.81
: 1670. 正答率(テスト) = 0.7777
Generation: 1680. 正答率(トレーニング) = 0.8
: 1680. 正答率(テスト) = 0.7807
Generation: 1690. 正答率(トレーニング) = 0.75
: 1690. 正答率(テスト) = 0.7786
Generation: 1700. 正答率(トレーニング) = 0.78
: 1700. 正答率(テスト) = 0.7807
Generation: 1710. 正答率(トレーニング) = 0.73
: 1710. 正答率(テスト) = 0.7798
Generation: 1720. 正答率(トレーニング) = 0.77
: 1720. 正答率(テスト) = 0.7796
Generation: 1730. 正答率(トレーニング) = 0.77
: 1730. 正答率(テスト) = 0.7822
Generation: 1740. 正答率(トレーニング) = 0.8
: 1740. 正答率(テスト) = 0.7789
Generation: 1750. 正答率(トレーニング) = 0.78
: 1750. 正答率(テスト) = 0.7813
Generation: 1760. 正答率(トレーニング) = 0.85
: 1760. 正答率(テスト) = 0.7816
Generation: 1770. 正答率(トレーニング) = 0.75
: 1770. 正答率(テスト) = 0.7808
Generation: 1780. 正答率(トレーニング) = 0.8
: 1780. 正答率(テスト) = 0.7826
Generation: 1790. 正答率(トレーニング) = 0.7
: 1790. 正答率(テスト) = 0.7867
Generation: 1800. 正答率(トレーニング) = 0.82
: 1800. 正答率(テスト) = 0.7857
Generation: 1810. 正答率(トレーニング) = 0.79
: 1810. 正答率(テスト) = 0.7872
Generation: 1820. 正答率(トレーニング) = 0.82
: 1820. 正答率(テスト) = 0.7859
Generation: 1830. 正答率(トレーニング) = 0.81
: 1830. 正答率(テスト) = 0.7886
Generation: 1840. 正答率(トレーニング) = 0.78
: 1840. 正答率(テスト) = 0.7896
Generation: 1850. 正答率(トレーニング) = 0.74
: 1850. 正答率(テスト) = 0.7901
Generation: 1860. 正答率(トレーニング) = 0.74
: 1860. 正答率(テスト) = 0.7912
Generation: 1870. 正答率(トレーニング) = 0.65
: 1870. 正答率(テスト) = 0.7899
Generation: 1880. 正答率(トレーニング) = 0.79
: 1880. 正答率(テスト) = 0.7919
Generation: 1890. 正答率(トレーニング) = 0.83
: 1890. 正答率(テスト) = 0.7899
Generation: 1900. 正答率(トレーニング) = 0.75
: 1900. 正答率(テスト) = 0.7928
Generation: 1910. 正答率(トレーニング) = 0.77
: 1910. 正答率(テスト) = 0.79
Generation: 1920. 正答率(トレーニング) = 0.75
: 1920. 正答率(テスト) = 0.7947
Generation: 1930. 正答率(トレーニング) = 0.79
: 1930. 正答率(テスト) = 0.7944
Generation: 1940. 正答率(トレーニング) = 0.78
: 1940. 正答率(テスト) = 0.7963
Generation: 1950. 正答率(トレーニング) = 0.79
: 1950. 正答率(テスト) = 0.7971
Generation: 1960. 正答率(トレーニング) = 0.8
: 1960. 正答率(テスト) = 0.7943
Generation: 1970. 正答率(トレーニング) = 0.75
: 1970. 正答率(テスト) = 0.7946
Generation: 1980. 正答率(トレーニング) = 0.79
: 1980. 正答率(テスト) = 0.798
Generation: 1990. 正答率(トレーニング) = 0.77
: 1990. 正答率(テスト) = 0.799
Generation: 2000. 正答率(トレーニング) = 0.83
: 2000. 正答率(テスト) = 0.7975
1.2.3 重みの初期値設定(He)
S字カーブになっている活性化関数に対してXavier(ザビエル)はうまく働く。
⇒S字カーブではないときの活性化関数(例:ReLu)の場合はHe
各重みに対して前の層のノード数($n$)に対して$\times\sqrt{\frac{2}{n}}$した値を初期値とするアルゴリズム。
Heで初期値を設定する際に合わせて用いられる活性化関数がReLU関数。
self.params['W1'] = np.random.randn(input_size, hidden_size) / nq.sqrt(input_layer_size) * np.sqrt(2)
self.params['W2'] = np.random.randn(hidden_size, output_size) / nq.sqrt(hidden_layer_size) * np.sqrt(2)
実装
import numpy as np
from data.mnist import load_mnist
from PIL import Image
import pickle
from common import functions
import matplotlib.pyplot as plt
# mnistをロード
(x_train, d_train), (x_test, d_test) = load_mnist(normalize=True, one_hot_label=True)
train_size = len(x_train)
print("データ読み込み完了")
# 重み初期値補正係数
wieght_init = 0.01
# 入力層サイズ
input_layer_size = 784
# 中間層サイズ
hidden_layer_1_size = 40
hidden_layer_2_size = 20
# 出力層サイズ
output_layer_size = 10
# 繰り返し数
iters_num = 2000
# ミニバッチサイズ
batch_size = 100
# 学習率
learning_rate = 0.1
# 描写頻度
plot_interval=10
# 初期設定
def init_network():
network = {}
########### 変更箇所 ##############
# Heの初期値
network['W1'] = np.random.randn(input_layer_size, hidden_layer_1_size) / np.sqrt(input_layer_size) * np.sqrt(2)
network['W2'] = np.random.randn(hidden_layer_1_size, hidden_layer_2_size) / np.sqrt(hidden_layer_1_size) * np.sqrt(2)
network['W3'] = np.random.randn(hidden_layer_2_size, output_layer_size) / np.sqrt(hidden_layer_2_size) * np.sqrt(2)
#################################
network['b1'] = np.zeros(hidden_layer_1_size)
network['b2'] = np.zeros(hidden_layer_2_size)
network['b3'] = np.zeros(output_layer_size)
return network
# 順伝播
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
########### 変更箇所 ##############
hidden_f = functions.relu
#################################
u1 = np.dot(x, W1) + b1
z1 = hidden_f(u1)
u2 = np.dot(z1, W2) + b2
z2 = hidden_f(u2)
u3 = np.dot(z2, W3) + b3
y = functions.softmax(u3)
return z1, z2, y
# 誤差逆伝播
def backward(x, d, z1, z2, y):
grad = {}
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
########### 変更箇所 ##############
hidden_d_f = functions.d_relu
#################################
# 出力層でのデルタ
delta3 = functions.d_softmax_with_loss(d, y)
# b3の勾配
grad['b3'] = np.sum(delta3, axis=0)
# W3の勾配
grad['W3'] = np.dot(z2.T, delta3)
# 2層でのデルタ
delta2 = np.dot(delta3, W3.T) * hidden_d_f(z2)
# b2の勾配
grad['b2'] = np.sum(delta2, axis=0)
# W2の勾配
grad['W2'] = np.dot(z1.T, delta2)
# 1層でのデルタ
delta1 = np.dot(delta2, W2.T) * hidden_d_f(z1)
# b1の勾配
grad['b1'] = np.sum(delta1, axis=0)
# W1の勾配
grad['W1'] = np.dot(x.T, delta1)
return grad
# パラメータの初期化
network = init_network()
accuracies_train = []
accuracies_test = []
# 正答率
def accuracy(x, d):
z1, z2, y = forward(network, x)
y = np.argmax(y, axis=1)
if d.ndim != 1 : d = np.argmax(d, axis=1)
accuracy = np.sum(y == d) / float(x.shape[0])
return accuracy
for i in range(iters_num):
# ランダムにバッチを取得
batch_mask = np.random.choice(train_size, batch_size)
# ミニバッチに対応する教師訓練画像データを取得
x_batch = x_train[batch_mask]
# ミニバッチに対応する訓練正解ラベルデータを取得する
d_batch = d_train[batch_mask]
z1, z2, y = forward(network, x_batch)
grad = backward(x_batch, d_batch, z1, z2, y)
if (i+1)%plot_interval==0:
accr_test = accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
# パラメータに勾配適用
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
network[key] -= learning_rate * grad[key]
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()
データ読み込み完了
Generation: 10. 正答率(トレーニング) = 0.43
: 10. 正答率(テスト) = 0.4439
Generation: 20. 正答率(トレーニング) = 0.65
: 20. 正答率(テスト) = 0.6509
Generation: 30. 正答率(トレーニング) = 0.69
: 30. 正答率(テスト) = 0.7344
Generation: 40. 正答率(トレーニング) = 0.83
: 40. 正答率(テスト) = 0.798
Generation: 50. 正答率(トレーニング) = 0.82
: 50. 正答率(テスト) = 0.7791
Generation: 60. 正答率(トレーニング) = 0.86
: 60. 正答率(テスト) = 0.8467
Generation: 70. 正答率(トレーニング) = 0.88
: 70. 正答率(テスト) = 0.8248
Generation: 80. 正答率(トレーニング) = 0.81
: 80. 正答率(テスト) = 0.8384
Generation: 90. 正答率(トレーニング) = 0.85
: 90. 正答率(テスト) = 0.8583
Generation: 100. 正答率(トレーニング) = 0.88
: 100. 正答率(テスト) = 0.8682
Generation: 110. 正答率(トレーニング) = 0.88
: 110. 正答率(テスト) = 0.8734
Generation: 120. 正答率(トレーニング) = 0.86
: 120. 正答率(テスト) = 0.8832
Generation: 130. 正答率(トレーニング) = 0.89
: 130. 正答率(テスト) = 0.8788
Generation: 140. 正答率(トレーニング) = 0.88
: 140. 正答率(テスト) = 0.8843
Generation: 150. 正答率(トレーニング) = 0.87
: 150. 正答率(テスト) = 0.897
Generation: 160. 正答率(トレーニング) = 0.9
: 160. 正答率(テスト) = 0.8811
Generation: 170. 正答率(トレーニング) = 0.93
: 170. 正答率(テスト) = 0.9041
Generation: 180. 正答率(トレーニング) = 0.9
: 180. 正答率(テスト) = 0.9014
Generation: 190. 正答率(トレーニング) = 0.9
: 190. 正答率(テスト) = 0.8973
Generation: 200. 正答率(トレーニング) = 0.88
: 200. 正答率(テスト) = 0.9005
Generation: 210. 正答率(トレーニング) = 0.91
: 210. 正答率(テスト) = 0.8983
Generation: 220. 正答率(トレーニング) = 0.9
: 220. 正答率(テスト) = 0.908
Generation: 230. 正答率(トレーニング) = 0.89
: 230. 正答率(テスト) = 0.8923
Generation: 240. 正答率(トレーニング) = 0.93
: 240. 正答率(テスト) = 0.9117
Generation: 250. 正答率(トレーニング) = 0.93
: 250. 正答率(テスト) = 0.9071
Generation: 260. 正答率(トレーニング) = 0.96
: 260. 正答率(テスト) = 0.9167
Generation: 270. 正答率(トレーニング) = 0.89
: 270. 正答率(テスト) = 0.9129
Generation: 280. 正答率(トレーニング) = 0.88
: 280. 正答率(テスト) = 0.9161
Generation: 290. 正答率(トレーニング) = 0.89
: 290. 正答率(テスト) = 0.9028
Generation: 300. 正答率(トレーニング) = 0.93
: 300. 正答率(テスト) = 0.9141
Generation: 310. 正答率(トレーニング) = 0.92
: 310. 正答率(テスト) = 0.9204
Generation: 320. 正答率(トレーニング) = 0.9
: 320. 正答率(テスト) = 0.917
Generation: 330. 正答率(トレーニング) = 0.91
: 330. 正答率(テスト) = 0.9041
Generation: 340. 正答率(トレーニング) = 0.94
: 340. 正答率(テスト) = 0.9179
Generation: 350. 正答率(トレーニング) = 0.95
: 350. 正答率(テスト) = 0.9208
Generation: 360. 正答率(トレーニング) = 0.87
: 360. 正答率(テスト) = 0.9111
Generation: 370. 正答率(トレーニング) = 0.88
: 370. 正答率(テスト) = 0.9245
Generation: 380. 正答率(トレーニング) = 0.89
: 380. 正答率(テスト) = 0.9229
Generation: 390. 正答率(トレーニング) = 0.93
: 390. 正答率(テスト) = 0.9235
Generation: 400. 正答率(トレーニング) = 0.94
: 400. 正答率(テスト) = 0.9258
Generation: 410. 正答率(トレーニング) = 0.95
: 410. 正答率(テスト) = 0.9217
Generation: 420. 正答率(トレーニング) = 0.9
: 420. 正答率(テスト) = 0.9208
Generation: 430. 正答率(トレーニング) = 0.93
: 430. 正答率(テスト) = 0.9261
Generation: 440. 正答率(トレーニング) = 0.92
: 440. 正答率(テスト) = 0.9288
Generation: 450. 正答率(トレーニング) = 0.96
: 450. 正答率(テスト) = 0.9255
Generation: 460. 正答率(トレーニング) = 0.94
: 460. 正答率(テスト) = 0.9292
Generation: 470. 正答率(トレーニング) = 0.92
: 470. 正答率(テスト) = 0.9213
Generation: 480. 正答率(トレーニング) = 0.95
: 480. 正答率(テスト) = 0.9276
Generation: 490. 正答率(トレーニング) = 0.92
: 490. 正答率(テスト) = 0.9276
Generation: 500. 正答率(トレーニング) = 0.93
: 500. 正答率(テスト) = 0.9272
Generation: 510. 正答率(トレーニング) = 0.94
: 510. 正答率(テスト) = 0.9274
Generation: 520. 正答率(トレーニング) = 0.93
: 520. 正答率(テスト) = 0.9261
Generation: 530. 正答率(トレーニング) = 0.93
: 530. 正答率(テスト) = 0.9326
Generation: 540. 正答率(トレーニング) = 0.94
: 540. 正答率(テスト) = 0.9274
Generation: 550. 正答率(トレーニング) = 0.97
: 550. 正答率(テスト) = 0.9344
Generation: 560. 正答率(トレーニング) = 0.91
: 560. 正答率(テスト) = 0.927
Generation: 570. 正答率(トレーニング) = 0.9
: 570. 正答率(テスト) = 0.924
Generation: 580. 正答率(トレーニング) = 0.94
: 580. 正答率(テスト) = 0.9303
Generation: 590. 正答率(トレーニング) = 0.93
: 590. 正答率(テスト) = 0.9338
Generation: 600. 正答率(トレーニング) = 0.97
: 600. 正答率(テスト) = 0.9281
Generation: 610. 正答率(トレーニング) = 0.9
: 610. 正答率(テスト) = 0.9361
Generation: 620. 正答率(トレーニング) = 0.96
: 620. 正答率(テスト) = 0.933
Generation: 630. 正答率(トレーニング) = 0.93
: 630. 正答率(テスト) = 0.9315
Generation: 640. 正答率(トレーニング) = 0.93
: 640. 正答率(テスト) = 0.9355
Generation: 650. 正答率(トレーニング) = 0.94
: 650. 正答率(テスト) = 0.9312
Generation: 660. 正答率(トレーニング) = 0.93
: 660. 正答率(テスト) = 0.9332
Generation: 670. 正答率(トレーニング) = 0.94
: 670. 正答率(テスト) = 0.9277
Generation: 680. 正答率(トレーニング) = 0.94
: 680. 正答率(テスト) = 0.9339
Generation: 690. 正答率(トレーニング) = 0.93
: 690. 正答率(テスト) = 0.9255
Generation: 700. 正答率(トレーニング) = 0.95
: 700. 正答率(テスト) = 0.9299
Generation: 710. 正答率(トレーニング) = 0.94
: 710. 正答率(テスト) = 0.9315
Generation: 720. 正答率(トレーニング) = 0.96
: 720. 正答率(テスト) = 0.9381
Generation: 730. 正答率(トレーニング) = 0.94
: 730. 正答率(テスト) = 0.9348
Generation: 740. 正答率(トレーニング) = 0.87
: 740. 正答率(テスト) = 0.9238
Generation: 750. 正答率(トレーニング) = 0.94
: 750. 正答率(テスト) = 0.9382
Generation: 760. 正答率(トレーニング) = 0.93
: 760. 正答率(テスト) = 0.9358
Generation: 770. 正答率(トレーニング) = 0.93
: 770. 正答率(テスト) = 0.9334
Generation: 780. 正答率(トレーニング) = 0.93
: 780. 正答率(テスト) = 0.9351
Generation: 790. 正答率(トレーニング) = 0.92
: 790. 正答率(テスト) = 0.9396
Generation: 800. 正答率(トレーニング) = 0.92
: 800. 正答率(テスト) = 0.9386
Generation: 810. 正答率(トレーニング) = 0.94
: 810. 正答率(テスト) = 0.9396
Generation: 820. 正答率(トレーニング) = 0.96
: 820. 正答率(テスト) = 0.9229
Generation: 830. 正答率(トレーニング) = 0.93
: 830. 正答率(テスト) = 0.9355
Generation: 840. 正答率(トレーニング) = 0.96
: 840. 正答率(テスト) = 0.9381
Generation: 850. 正答率(トレーニング) = 0.93
: 850. 正答率(テスト) = 0.9383
Generation: 860. 正答率(トレーニング) = 0.93
: 860. 正答率(テスト) = 0.9365
Generation: 870. 正答率(トレーニング) = 0.93
: 870. 正答率(テスト) = 0.9403
Generation: 880. 正答率(トレーニング) = 0.91
: 880. 正答率(テスト) = 0.9414
Generation: 890. 正答率(トレーニング) = 0.97
: 890. 正答率(テスト) = 0.9402
Generation: 900. 正答率(トレーニング) = 0.91
: 900. 正答率(テスト) = 0.9342
Generation: 910. 正答率(トレーニング) = 0.93
: 910. 正答率(テスト) = 0.9395
Generation: 920. 正答率(トレーニング) = 0.94
: 920. 正答率(テスト) = 0.9431
Generation: 930. 正答率(トレーニング) = 0.94
: 930. 正答率(テスト) = 0.9386
Generation: 940. 正答率(トレーニング) = 0.92
: 940. 正答率(テスト) = 0.9415
Generation: 950. 正答率(トレーニング) = 0.9
: 950. 正答率(テスト) = 0.9397
Generation: 960. 正答率(トレーニング) = 0.95
: 960. 正答率(テスト) = 0.9405
Generation: 970. 正答率(トレーニング) = 0.95
: 970. 正答率(テスト) = 0.9432
Generation: 980. 正答率(トレーニング) = 0.95
: 980. 正答率(テスト) = 0.9396
Generation: 990. 正答率(トレーニング) = 0.93
: 990. 正答率(テスト) = 0.9428
Generation: 1000. 正答率(トレーニング) = 0.93
: 1000. 正答率(テスト) = 0.945
Generation: 1010. 正答率(トレーニング) = 0.98
: 1010. 正答率(テスト) = 0.9451
Generation: 1020. 正答率(トレーニング) = 0.93
: 1020. 正答率(テスト) = 0.9423
Generation: 1030. 正答率(トレーニング) = 0.94
: 1030. 正答率(テスト) = 0.9415
Generation: 1040. 正答率(トレーニング) = 0.95
: 1040. 正答率(テスト) = 0.9413
Generation: 1050. 正答率(トレーニング) = 0.96
: 1050. 正答率(テスト) = 0.938
Generation: 1060. 正答率(トレーニング) = 0.96
: 1060. 正答率(テスト) = 0.9426
Generation: 1070. 正答率(トレーニング) = 0.97
: 1070. 正答率(テスト) = 0.9458
Generation: 1080. 正答率(トレーニング) = 0.95
: 1080. 正答率(テスト) = 0.9442
Generation: 1090. 正答率(トレーニング) = 0.95
: 1090. 正答率(テスト) = 0.9424
Generation: 1100. 正答率(トレーニング) = 0.94
: 1100. 正答率(テスト) = 0.947
Generation: 1110. 正答率(トレーニング) = 0.99
: 1110. 正答率(テスト) = 0.9461
Generation: 1120. 正答率(トレーニング) = 0.95
: 1120. 正答率(テスト) = 0.9463
Generation: 1130. 正答率(トレーニング) = 0.94
: 1130. 正答率(テスト) = 0.9477
Generation: 1140. 正答率(トレーニング) = 0.88
: 1140. 正答率(テスト) = 0.9398
Generation: 1150. 正答率(トレーニング) = 0.97
: 1150. 正答率(テスト) = 0.9378
Generation: 1160. 正答率(トレーニング) = 0.93
: 1160. 正答率(テスト) = 0.9439
Generation: 1170. 正答率(トレーニング) = 0.93
: 1170. 正答率(テスト) = 0.9469
Generation: 1180. 正答率(トレーニング) = 0.95
: 1180. 正答率(テスト) = 0.9482
Generation: 1190. 正答率(トレーニング) = 0.94
: 1190. 正答率(テスト) = 0.948
Generation: 1200. 正答率(トレーニング) = 0.95
: 1200. 正答率(テスト) = 0.949
Generation: 1210. 正答率(トレーニング) = 0.95
: 1210. 正答率(テスト) = 0.9464
Generation: 1220. 正答率(トレーニング) = 0.92
: 1220. 正答率(テスト) = 0.9462
Generation: 1230. 正答率(トレーニング) = 0.94
: 1230. 正答率(テスト) = 0.9496
Generation: 1240. 正答率(トレーニング) = 0.97
: 1240. 正答率(テスト) = 0.9468
Generation: 1250. 正答率(トレーニング) = 0.95
: 1250. 正答率(テスト) = 0.9496
Generation: 1260. 正答率(トレーニング) = 0.97
: 1260. 正答率(テスト) = 0.9475
Generation: 1270. 正答率(トレーニング) = 0.93
: 1270. 正答率(テスト) = 0.9464
Generation: 1280. 正答率(トレーニング) = 0.94
: 1280. 正答率(テスト) = 0.9468
Generation: 1290. 正答率(トレーニング) = 0.89
: 1290. 正答率(テスト) = 0.9466
Generation: 1300. 正答率(トレーニング) = 0.93
: 1300. 正答率(テスト) = 0.9489
Generation: 1310. 正答率(トレーニング) = 0.97
: 1310. 正答率(テスト) = 0.946
Generation: 1320. 正答率(トレーニング) = 0.97
: 1320. 正答率(テスト) = 0.9465
Generation: 1330. 正答率(トレーニング) = 0.97
: 1330. 正答率(テスト) = 0.9508
Generation: 1340. 正答率(トレーニング) = 0.98
: 1340. 正答率(テスト) = 0.9511
Generation: 1350. 正答率(トレーニング) = 0.98
: 1350. 正答率(テスト) = 0.9511
Generation: 1360. 正答率(トレーニング) = 0.94
: 1360. 正答率(テスト) = 0.9474
Generation: 1370. 正答率(トレーニング) = 0.98
: 1370. 正答率(テスト) = 0.9511
Generation: 1380. 正答率(トレーニング) = 0.93
: 1380. 正答率(テスト) = 0.9508
Generation: 1390. 正答率(トレーニング) = 0.96
: 1390. 正答率(テスト) = 0.9498
Generation: 1400. 正答率(トレーニング) = 0.96
: 1400. 正答率(テスト) = 0.9466
Generation: 1410. 正答率(トレーニング) = 0.97
: 1410. 正答率(テスト) = 0.9486
Generation: 1420. 正答率(トレーニング) = 0.97
: 1420. 正答率(テスト) = 0.9492
Generation: 1430. 正答率(トレーニング) = 0.97
: 1430. 正答率(テスト) = 0.9492
Generation: 1440. 正答率(トレーニング) = 0.93
: 1440. 正答率(テスト) = 0.9516
Generation: 1450. 正答率(トレーニング) = 0.93
: 1450. 正答率(テスト) = 0.95
Generation: 1460. 正答率(トレーニング) = 0.97
: 1460. 正答率(テスト) = 0.953
Generation: 1470. 正答率(トレーニング) = 0.96
: 1470. 正答率(テスト) = 0.9498
Generation: 1480. 正答率(トレーニング) = 0.96
: 1480. 正答率(テスト) = 0.951
Generation: 1490. 正答率(トレーニング) = 0.93
: 1490. 正答率(テスト) = 0.9494
Generation: 1500. 正答率(トレーニング) = 0.94
: 1500. 正答率(テスト) = 0.9534
Generation: 1510. 正答率(トレーニング) = 0.95
: 1510. 正答率(テスト) = 0.9519
Generation: 1520. 正答率(トレーニング) = 0.98
: 1520. 正答率(テスト) = 0.9514
Generation: 1530. 正答率(トレーニング) = 0.95
: 1530. 正答率(テスト) = 0.9516
Generation: 1540. 正答率(トレーニング) = 0.93
: 1540. 正答率(テスト) = 0.9501
Generation: 1550. 正答率(トレーニング) = 0.97
: 1550. 正答率(テスト) = 0.9489
Generation: 1560. 正答率(トレーニング) = 0.95
: 1560. 正答率(テスト) = 0.9535
Generation: 1570. 正答率(トレーニング) = 0.98
: 1570. 正答率(テスト) = 0.9514
Generation: 1580. 正答率(トレーニング) = 0.98
: 1580. 正答率(テスト) = 0.9525
Generation: 1590. 正答率(トレーニング) = 0.92
: 1590. 正答率(テスト) = 0.9555
Generation: 1600. 正答率(トレーニング) = 0.95
: 1600. 正答率(テスト) = 0.9486
Generation: 1610. 正答率(トレーニング) = 0.96
: 1610. 正答率(テスト) = 0.9504
Generation: 1620. 正答率(トレーニング) = 0.97
: 1620. 正答率(テスト) = 0.9485
Generation: 1630. 正答率(トレーニング) = 0.94
: 1630. 正答率(テスト) = 0.9508
Generation: 1640. 正答率(トレーニング) = 0.97
: 1640. 正答率(テスト) = 0.9533
Generation: 1650. 正答率(トレーニング) = 0.96
: 1650. 正答率(テスト) = 0.9516
Generation: 1660. 正答率(トレーニング) = 0.98
: 1660. 正答率(テスト) = 0.9518
Generation: 1670. 正答率(トレーニング) = 0.97
: 1670. 正答率(テスト) = 0.9544
Generation: 1680. 正答率(トレーニング) = 0.95
: 1680. 正答率(テスト) = 0.9546
Generation: 1690. 正答率(トレーニング) = 0.97
: 1690. 正答率(テスト) = 0.954
Generation: 1700. 正答率(トレーニング) = 0.97
: 1700. 正答率(テスト) = 0.9542
Generation: 1710. 正答率(トレーニング) = 0.93
: 1710. 正答率(テスト) = 0.94
Generation: 1720. 正答率(トレーニング) = 0.95
: 1720. 正答率(テスト) = 0.9545
Generation: 1730. 正答率(トレーニング) = 0.96
: 1730. 正答率(テスト) = 0.9546
Generation: 1740. 正答率(トレーニング) = 0.98
: 1740. 正答率(テスト) = 0.9516
Generation: 1750. 正答率(トレーニング) = 0.97
: 1750. 正答率(テスト) = 0.9553
Generation: 1760. 正答率(トレーニング) = 0.96
: 1760. 正答率(テスト) = 0.9535
Generation: 1770. 正答率(トレーニング) = 0.95
: 1770. 正答率(テスト) = 0.9536
Generation: 1780. 正答率(トレーニング) = 0.98
: 1780. 正答率(テスト) = 0.9538
Generation: 1790. 正答率(トレーニング) = 0.98
: 1790. 正答率(テスト) = 0.9502
Generation: 1800. 正答率(トレーニング) = 0.96
: 1800. 正答率(テスト) = 0.9512
Generation: 1810. 正答率(トレーニング) = 0.96
: 1810. 正答率(テスト) = 0.9535
Generation: 1820. 正答率(トレーニング) = 0.91
: 1820. 正答率(テスト) = 0.9523
Generation: 1830. 正答率(トレーニング) = 0.94
: 1830. 正答率(テスト) = 0.9536
Generation: 1840. 正答率(トレーニング) = 0.97
: 1840. 正答率(テスト) = 0.9504
Generation: 1850. 正答率(トレーニング) = 0.99
: 1850. 正答率(テスト) = 0.9571
Generation: 1860. 正答率(トレーニング) = 0.95
: 1860. 正答率(テスト) = 0.9517
Generation: 1870. 正答率(トレーニング) = 0.94
: 1870. 正答率(テスト) = 0.9495
Generation: 1880. 正答率(トレーニング) = 0.97
: 1880. 正答率(テスト) = 0.9578
Generation: 1890. 正答率(トレーニング) = 0.91
: 1890. 正答率(テスト) = 0.9464
Generation: 1900. 正答率(トレーニング) = 0.94
: 1900. 正答率(テスト) = 0.9527
Generation: 1910. 正答率(トレーニング) = 0.95
: 1910. 正答率(テスト) = 0.9558
Generation: 1920. 正答率(トレーニング) = 0.98
: 1920. 正答率(テスト) = 0.9573
Generation: 1930. 正答率(トレーニング) = 0.99
: 1930. 正答率(テスト) = 0.9531
Generation: 1940. 正答率(トレーニング) = 0.93
: 1940. 正答率(テスト) = 0.9578
Generation: 1950. 正答率(トレーニング) = 0.96
: 1950. 正答率(テスト) = 0.9528
Generation: 1960. 正答率(トレーニング) = 0.91
: 1960. 正答率(テスト) = 0.9514
Generation: 1970. 正答率(トレーニング) = 0.96
: 1970. 正答率(テスト) = 0.9561
Generation: 1980. 正答率(トレーニング) = 0.96
: 1980. 正答率(テスト) = 0.9593
Generation: 1990. 正答率(トレーニング) = 1.0
: 1990. 正答率(テスト) = 0.9553
Generation: 2000. 正答率(トレーニング) = 0.95
: 2000. 正答率(テスト) = 0.9555
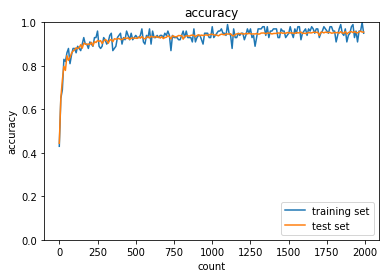
確認テスト:重みの初期値を0に設定すると、どのような問題が発生するか。簡潔に説明せよ。
答:重みを0で初期化すると、正しい学習が行えない。
⇒すべての重みの値が均一に更新されるため、多数の重みをもつ意味がなくなる。
(重みに個性がない状態。その状態で学習しても、ニューラルネットワークとしては機能しない。)
1.2.4 バッチ正規化
ミニバッチ単位で入力値のデータの偏りを抑制する方法。
ニューラルネットワークで学習を行うとき、多くの場合ミニバッチと言う小さなデータの塊に分割して学習を進めていく。
CPU・・・汎用
GPU・・・ゲーム用⇒AIにも利用
TPU・・・AI専用

メリット:中間層の重みの安定度が増す。過学習を抑えることができる。
ミニバッチでデータの分布をある程度正規化する。その過程で、学習データの極端なバラつきを抑えられる。
活性化関数に値を渡す前後に、バッチ正規化の処理を含む層を加える。
ミニバッチ$t$全体の平均
$$\mu_t=\frac{1}{N_t}\sum_{i=1}^{N_t}x_{ni}$$
ミニバッチ$t$全体の分散
$$\mu_t=\frac{1}{N_t}\sum_{i=1}^{N_t}\left(x_{ni}-\mu_t\right)^2$$
ミニバッチ$t$全体の標準偏差
$$\mu_t=\sqrt{\frac{1}{N_t}\sum_{i=1}^{N_t}\left(x_{ni}-\mu_t\right)^2}$$
ミニバッチ$t$の正規化
$$\hat{x_{ni}}=\frac{x_{ni}-\mu_t}{\sqrt{\sigma_t^2+\theta}}$$
$y_{ni}$ミニバッチのインデックス地$x_{ni}$とスケーリングをかけてシフトパラメータ$\beta$を足した値
$$y_{ni}=\gamma x_{ni}+\beta$$
逆伝播において、正規化するための最適な値へ $\gamma$,$\beta$を学習していく。
確認テスト:バッチ正規化の効果を2点挙げよ
答:中間層の重みの安定度が増し、勾配消失が起こりづらい。
計算が高速で、過学習を抑えることができる。
実装:
from google.colab import drive
drive.mount('/content/drive')
import sys
sys.path.append('/content/drive/My Drive/DNN_code')
sys.path.append('/content/drive/My Drive/DNN_code/lesson_2')
バッチ正規化
import numpy as np
from collections import OrderedDict
from common import layers
from data.mnist import load_mnist
import matplotlib.pyplot as plt
from multi_layer_net import MultiLayerNet
from common import optimizer
# バッチ正則化 layer
class BatchNormalization:
'''
gamma: スケール係数
beta: オフセット
momentum: 慣性
running_mean: テスト時に使用する平均
running_var: テスト時に使用する分散
'''
def __init__(self, gamma, beta, momentum=0.9, running_mean=None, running_var=None):
self.gamma = gamma
self.beta = beta
self.momentum = momentum
self.input_shape = None
self.running_mean = running_mean
self.running_var = running_var
# backward時に使用する中間データ
self.batch_size = None
self.xc = None
self.std = None
self.dgamma = None
self.dbeta = None
def forward(self, x, train_flg=True):
if self.running_mean is None:
N, D = x.shape
self.running_mean = np.zeros(D)
self.running_var = np.zeros(D)
if train_flg:
mu = x.mean(axis=0) # 平均
xc = x - mu # xをセンタリング
var = np.mean(xc**2, axis=0) # 分散
std = np.sqrt(var + 10e-7) # スケーリング
xn = xc / std
self.batch_size = x.shape[0]
self.xc = xc
self.xn = xn
self.std = std
self.running_mean = self.momentum * self.running_mean + (1-self.momentum) * mu # 平均値の加重平均
self.running_var = self.momentum * self.running_var + (1-self.momentum) * var #分散値の加重平均
else:
xc = x - self.running_mean
xn = xc / ((np.sqrt(self.running_var + 10e-7)))
out = self.gamma * xn + self.beta
return out
def backward(self, dout):
dbeta = dout.sum(axis=0)
dgamma = np.sum(self.xn * dout, axis=0)
dxn = self.gamma * dout
dxc = dxn / self.std
dstd = -np.sum((dxn * self.xc) / (self.std * self.std), axis=0)
dvar = 0.5 * dstd / self.std
dxc += (2.0 / self.batch_size) * self.xc * dvar
dmu = np.sum(dxc, axis=0)
dx = dxc - dmu / self.batch_size
self.dgamma = dgamma
self.dbeta = dbeta
return dx
データ読み込み完了
Generation: 10. 正答率(トレーニング) = 0.15
: 10. 正答率(テスト) = 0.2072
Generation: 20. 正答率(トレーニング) = 0.28
: 20. 正答率(テスト) = 0.2847
Generation: 30. 正答率(トレーニング) = 0.27
: 30. 正答率(テスト) = 0.3116
Generation: 40. 正答率(トレーニング) = 0.28
: 40. 正答率(テスト) = 0.3368
Generation: 50. 正答率(トレーニング) = 0.39
: 50. 正答率(テスト) = 0.3558
Generation: 60. 正答率(トレーニング) = 0.32
: 60. 正答率(テスト) = 0.3755
Generation: 70. 正答率(トレーニング) = 0.37
: 70. 正答率(テスト) = 0.3891
Generation: 80. 正答率(トレーニング) = 0.51
: 80. 正答率(テスト) = 0.4013
Generation: 90. 正答率(トレーニング) = 0.48
: 90. 正答率(テスト) = 0.4161
Generation: 100. 正答率(トレーニング) = 0.48
: 100. 正答率(テスト) = 0.43
Generation: 110. 正答率(トレーニング) = 0.4
: 110. 正答率(テスト) = 0.4415
Generation: 120. 正答率(トレーニング) = 0.42
: 120. 正答率(テスト) = 0.4514
Generation: 130. 正答率(トレーニング) = 0.41
: 130. 正答率(テスト) = 0.4682
Generation: 140. 正答率(トレーニング) = 0.45
: 140. 正答率(テスト) = 0.4802
Generation: 150. 正答率(トレーニング) = 0.5
: 150. 正答率(テスト) = 0.4978
Generation: 160. 正答率(トレーニング) = 0.49
: 160. 正答率(テスト) = 0.5089
Generation: 170. 正答率(トレーニング) = 0.56
: 170. 正答率(テスト) = 0.5232
Generation: 180. 正答率(トレーニング) = 0.48
: 180. 正答率(テスト) = 0.5312
Generation: 190. 正答率(トレーニング) = 0.6
: 190. 正答率(テスト) = 0.5481
Generation: 200. 正答率(トレーニング) = 0.57
: 200. 正答率(テスト) = 0.564
Generation: 210. 正答率(トレーニング) = 0.49
: 210. 正答率(テスト) = 0.5725
Generation: 220. 正答率(トレーニング) = 0.5
: 220. 正答率(テスト) = 0.5859
Generation: 230. 正答率(トレーニング) = 0.59
: 230. 正答率(テスト) = 0.5961
Generation: 240. 正答率(トレーニング) = 0.62
: 240. 正答率(テスト) = 0.6057
Generation: 250. 正答率(トレーニング) = 0.45
: 250. 正答率(テスト) = 0.6171
Generation: 260. 正答率(トレーニング) = 0.6
: 260. 正答率(テスト) = 0.6282
Generation: 270. 正答率(トレーニング) = 0.65
: 270. 正答率(テスト) = 0.6376
Generation: 280. 正答率(トレーニング) = 0.62
: 280. 正答率(テスト) = 0.6497
Generation: 290. 正答率(トレーニング) = 0.67
: 290. 正答率(テスト) = 0.6608
Generation: 300. 正答率(トレーニング) = 0.68
: 300. 正答率(テスト) = 0.6645
Generation: 310. 正答率(トレーニング) = 0.61
: 310. 正答率(テスト) = 0.6751
Generation: 320. 正答率(トレーニング) = 0.61
: 320. 正答率(テスト) = 0.6799
Generation: 330. 正答率(トレーニング) = 0.68
: 330. 正答率(テスト) = 0.686
Generation: 340. 正答率(トレーニング) = 0.75
: 340. 正答率(テスト) = 0.6943
Generation: 350. 正答率(トレーニング) = 0.66
: 350. 正答率(テスト) = 0.6961
Generation: 360. 正答率(トレーニング) = 0.72
: 360. 正答率(テスト) = 0.7011
Generation: 370. 正答率(トレーニング) = 0.67
: 370. 正答率(テスト) = 0.7088
Generation: 380. 正答率(トレーニング) = 0.71
: 380. 正答率(テスト) = 0.7186
Generation: 390. 正答率(トレーニング) = 0.66
: 390. 正答率(テスト) = 0.7229
Generation: 400. 正答率(トレーニング) = 0.75
: 400. 正答率(テスト) = 0.7299
Generation: 410. 正答率(トレーニング) = 0.67
: 410. 正答率(テスト) = 0.7357
Generation: 420. 正答率(トレーニング) = 0.73
: 420. 正答率(テスト) = 0.7392
Generation: 430. 正答率(トレーニング) = 0.74
: 430. 正答率(テスト) = 0.7403
Generation: 440. 正答率(トレーニング) = 0.72
: 440. 正答率(テスト) = 0.7409
Generation: 450. 正答率(トレーニング) = 0.75
: 450. 正答率(テスト) = 0.7474
Generation: 460. 正答率(トレーニング) = 0.83
: 460. 正答率(テスト) = 0.7436
Generation: 470. 正答率(トレーニング) = 0.77
: 470. 正答率(テスト) = 0.7446
Generation: 480. 正答率(トレーニング) = 0.73
: 480. 正答率(テスト) = 0.7503
Generation: 490. 正答率(トレーニング) = 0.81
: 490. 正答率(テスト) = 0.7521
Generation: 500. 正答率(トレーニング) = 0.72
: 500. 正答率(テスト) = 0.7541
Generation: 510. 正答率(トレーニング) = 0.73
: 510. 正答率(テスト) = 0.7567
Generation: 520. 正答率(トレーニング) = 0.79
: 520. 正答率(テスト) = 0.7572
Generation: 530. 正答率(トレーニング) = 0.72
: 530. 正答率(テスト) = 0.7624
Generation: 540. 正答率(トレーニング) = 0.64
: 540. 正答率(テスト) = 0.7677
Generation: 550. 正答率(トレーニング) = 0.72
: 550. 正答率(テスト) = 0.7693
Generation: 560. 正答率(トレーニング) = 0.76
: 560. 正答率(テスト) = 0.767
Generation: 570. 正答率(トレーニング) = 0.78
: 570. 正答率(テスト) = 0.7697
Generation: 580. 正答率(トレーニング) = 0.71
: 580. 正答率(テスト) = 0.7726
Generation: 590. 正答率(トレーニング) = 0.83
: 590. 正答率(テスト) = 0.7729
Generation: 600. 正答率(トレーニング) = 0.85
: 600. 正答率(テスト) = 0.7756
Generation: 610. 正答率(トレーニング) = 0.78
: 610. 正答率(テスト) = 0.7714
Generation: 620. 正答率(トレーニング) = 0.78
: 620. 正答率(テスト) = 0.7766
Generation: 630. 正答率(トレーニング) = 0.76
: 630. 正答率(テスト) = 0.7744
Generation: 640. 正答率(トレーニング) = 0.8
: 640. 正答率(テスト) = 0.7797
Generation: 650. 正答率(トレーニング) = 0.74
: 650. 正答率(テスト) = 0.7792
Generation: 660. 正答率(トレーニング) = 0.74
: 660. 正答率(テスト) = 0.7788
Generation: 670. 正答率(トレーニング) = 0.86
: 670. 正答率(テスト) = 0.7803
Generation: 680. 正答率(トレーニング) = 0.71
: 680. 正答率(テスト) = 0.7833
Generation: 690. 正答率(トレーニング) = 0.86
: 690. 正答率(テスト) = 0.7834
Generation: 700. 正答率(トレーニング) = 0.81
: 700. 正答率(テスト) = 0.7826
Generation: 710. 正答率(トレーニング) = 0.83
: 710. 正答率(テスト) = 0.7848
Generation: 720. 正答率(トレーニング) = 0.74
: 720. 正答率(テスト) = 0.784
Generation: 730. 正答率(トレーニング) = 0.76
: 730. 正答率(テスト) = 0.7882
Generation: 740. 正答率(トレーニング) = 0.78
: 740. 正答率(テスト) = 0.7881
Generation: 750. 正答率(トレーニング) = 0.81
: 750. 正答率(テスト) = 0.7854
Generation: 760. 正答率(トレーニング) = 0.78
: 760. 正答率(テスト) = 0.7838
Generation: 770. 正答率(トレーニング) = 0.75
: 770. 正答率(テスト) = 0.7872
Generation: 780. 正答率(トレーニング) = 0.83
: 780. 正答率(テスト) = 0.7867
Generation: 790. 正答率(トレーニング) = 0.76
: 790. 正答率(テスト) = 0.7876
Generation: 800. 正答率(トレーニング) = 0.78
: 800. 正答率(テスト) = 0.7913
Generation: 810. 正答率(トレーニング) = 0.78
: 810. 正答率(テスト) = 0.7859
Generation: 820. 正答率(トレーニング) = 0.77
: 820. 正答率(テスト) = 0.7892
Generation: 830. 正答率(トレーニング) = 0.81
: 830. 正答率(テスト) = 0.7915
Generation: 840. 正答率(トレーニング) = 0.78
: 840. 正答率(テスト) = 0.7942
Generation: 850. 正答率(トレーニング) = 0.82
: 850. 正答率(テスト) = 0.7961
Generation: 860. 正答率(トレーニング) = 0.76
: 860. 正答率(テスト) = 0.7969
Generation: 870. 正答率(トレーニング) = 0.83
: 870. 正答率(テスト) = 0.7972
Generation: 880. 正答率(トレーニング) = 0.78
: 880. 正答率(テスト) = 0.7983
Generation: 890. 正答率(トレーニング) = 0.76
: 890. 正答率(テスト) = 0.801
Generation: 900. 正答率(トレーニング) = 0.78
: 900. 正答率(テスト) = 0.8024
Generation: 910. 正答率(トレーニング) = 0.76
: 910. 正答率(テスト) = 0.8008
Generation: 920. 正答率(トレーニング) = 0.8
: 920. 正答率(テスト) = 0.7989
Generation: 930. 正答率(トレーニング) = 0.78
: 930. 正答率(テスト) = 0.7991
Generation: 940. 正答率(トレーニング) = 0.8
: 940. 正答率(テスト) = 0.801
Generation: 950. 正答率(トレーニング) = 0.78
: 950. 正答率(テスト) = 0.8012
Generation: 960. 正答率(トレーニング) = 0.84
: 960. 正答率(テスト) = 0.8044
Generation: 970. 正答率(トレーニング) = 0.82
: 970. 正答率(テスト) = 0.8042
Generation: 980. 正答率(トレーニング) = 0.73
: 980. 正答率(テスト) = 0.8031
Generation: 990. 正答率(トレーニング) = 0.81
: 990. 正答率(テスト) = 0.8035
Generation: 1000. 正答率(トレーニング) = 0.8
: 1000. 正答率(テスト) = 0.8051
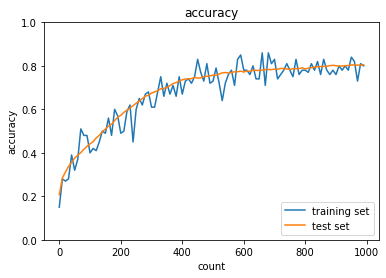
第2章 学習率の決め方
初期は大きく設定し、学習が進むにつれて徐々に学習率を小さくする。
パラメータごとに学習率を可変させる。
学習率最適化手法を利用して学習率を最適化する。
学習率最適化手法は
・モメンタム
・AdaGrad
・RMSprop
・Adam
がある。
2.1 モメンタム
勾配の移動平均を出して振動を抑える(過去の勾配たちを考慮することで急な変化を抑える)。
誤差をパラメータで微分した値と学習率$\varepsilon$ の積をひき算(←勾配降下法と同様)した後、現在の重みに前回の重みを減算した値と慣性(ハイパーパラメータ)$\mu$ のかけ算を加える。
モメンタムは、動いたら動き続ける特徴がある。
\begin{eqnarray}
V_t &=&\mu V_{t−1}−\varepsilon \nabla E\\
\mathbb{w}^{(t+1)}&=&\mathbb{w}^{(t)}+V_t\\
慣性&:&\mu
\end{eqnarray}
$V_{t-1}$:前回の学習の時の重み
参考:勾配降下法
\begin{eqnarray}
\mathbb{w}^{(t+1)}&=&\mathbb{w}^{(t)}-\varepsilon \nabla E
\end{eqnarray}
モメンタムのメリット
局所的最適解にはならず、比較的大域的最適解になりやすい。
⇒ 谷間についてから最も低い位置(最適値)にいくまでの時間が早い
モメンタムは、株価の移動平均に近い動きをする。
(参考:勾配降下法はジグザグ運転)
2.2 AdaGrad
次元ごとに学習率を変化させるようにしたもの。
誤差をパラメータで微分したもの$\nabla E$と再定義した学習率$\varepsilon\frac{1}{\sqrt{h_t}+\theta}$のかけ算して引く。
学習率が徐々に小さくなっていく。
何かしらの値$\theta$で$h$を初期化$h_0$、$h_t$は$h$が学習率を決める重要な要素
\begin{eqnarray}
h_0&=&\theta\\
h_t&=&h_{t−1}+\left(\nabla E\right)^2\\
\mathbb{w}^{(t+1)}&=&\mathbb{w}^{(t)}-\varepsilon\frac{1}{\sqrt{h_t}+\theta} \nabla E
\end{eqnarray}
メリット
・勾配の緩やかな斜面に対して最小値に近づける。
・誤差関数が極端に深くなっていかない。
鞍点(サドルポイント)問題を引き起こすことがある。
(鞍点:ある方向で見れば極大値だが別の方向で見れば極小値となる点)
鞍点問題:大域的最適解にたどり着きづらい。
2.3 RMSprop
AdaGradの改良版(そのため、結果がAdaGradに似通ることもある。)
一度学習率が$0$に近づくとほとんど変化しなくなるAdaGradの問題を改良したもの。
前回までの勾配情報をどの程度使うのか$\alpha$でコントロールする。
$\alpha\quad (-<\alpha<1)$:勾配を何倍して取り込むか。
\begin{eqnarray}
h_t&=&\alpha h_{t−1}+(1−\alpha)\left(\nabla E\right)^2\\
\mathbb{w}^{(t+1)}&=&\mathbb{w}^{(t)}-\varepsilon\frac{1}{\sqrt{h_t}+\theta} \nabla E
\end{eqnarray}
AdaGradと比較して局所最適解にならず大域的最適解となる。
AdaGradは$\theta$、$\varepsilon$をうまく調整しないといけないが、RMSpropはハイパーパラメータの調整が必要な場合が少ない利点がある。
2.4 Adam
Adamは、今までの学習率最適化手法のいいとこどりで、良くなかった部分がつぶれるようにした最強の方法。そのため一番使われる。具体的には、
モメンタム:過去の勾配の指数的減衰平均(進が良い方向に一気に進む)
RMSprop:過去の勾配の2乗の指数的減衰平均(学習率の調整をうまくする。)
の2つを含んだ最適解アルゴリズムで、鞍点を抜ける能力がある。
確認テスト:モメンタム、AdaGrad、RMSpropの特徴をそれぞれ簡潔に説明せよ。
答:
モメンタム:大局的局所解になりやすい。
AdaGrad:勾配が緩やな場合でも最適解が見つけられる
RMSprop:AdaGradの改良版。局所最適解にならず大域的最適解になりやすい。モメンタムやAdaGradと比較して、ハイパーパラメータの調整が必要な場合が少ない
実装
SGD
学習率を変えて変化を見る。
勾配消失を起こしてたようなので活性化関数もシグモイド関数からReLU関数に変更。
import sys, os
sys.path.append(os.pardir) # 親ディレクトリのファイルをインポートするための設定
import numpy as np
from collections import OrderedDict
from common import layers
from data.mnist import load_mnist
import matplotlib.pyplot as plt
from multi_layer_net import MultiLayerNet
# データの読み込み
(x_train, d_train), (x_test, d_test) = load_mnist(normalize=True, one_hot_label=True)
print("データ読み込み完了")
# batch_normalizationの設定 ================================
# use_batchnorm = True
use_batchnorm = False
# ====================================================
network = MultiLayerNet(input_size=784, hidden_size_list=[40, 20], output_size=10, activation='sigmoid', weight_init_std=0.01,
use_batchnorm=use_batchnorm)
iters_num = 1000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.01
train_loss_list = []
accuracies_train = []
accuracies_test = []
plot_interval=10
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
# 勾配
grad = network.gradient(x_batch, d_batch)
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
if (i + 1) % plot_interval == 0:
accr_test = network.accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = network.accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()
データ読み込み完了
Generation: 10. 正答率(トレーニング) = 0.14
: 10. 正答率(テスト) = 0.1032
Generation: 20. 正答率(トレーニング) = 0.11
: 20. 正答率(テスト) = 0.1032
Generation: 30. 正答率(トレーニング) = 0.08
: 30. 正答率(テスト) = 0.1032
Generation: 40. 正答率(トレーニング) = 0.11
: 40. 正答率(テスト) = 0.1032
Generation: 50. 正答率(トレーニング) = 0.1
: 50. 正答率(テスト) = 0.1032
Generation: 60. 正答率(トレーニング) = 0.1
: 60. 正答率(テスト) = 0.0958
Generation: 70. 正答率(トレーニング) = 0.15
: 70. 正答率(テスト) = 0.1135
Generation: 80. 正答率(トレーニング) = 0.11
: 80. 正答率(テスト) = 0.1135
Generation: 90. 正答率(トレーニング) = 0.12
: 90. 正答率(テスト) = 0.1135
Generation: 100. 正答率(トレーニング) = 0.16
: 100. 正答率(テスト) = 0.1135
Generation: 110. 正答率(トレーニング) = 0.12
: 110. 正答率(テスト) = 0.1135
Generation: 120. 正答率(トレーニング) = 0.12
: 120. 正答率(テスト) = 0.1135
Generation: 130. 正答率(トレーニング) = 0.09
: 130. 正答率(テスト) = 0.1135
Generation: 140. 正答率(トレーニング) = 0.16
: 140. 正答率(テスト) = 0.1135
Generation: 150. 正答率(トレーニング) = 0.05
: 150. 正答率(テスト) = 0.1135
Generation: 160. 正答率(トレーニング) = 0.15
: 160. 正答率(テスト) = 0.1135
Generation: 170. 正答率(トレーニング) = 0.16
: 170. 正答率(テスト) = 0.1135
Generation: 180. 正答率(トレーニング) = 0.09
: 180. 正答率(テスト) = 0.1135
Generation: 190. 正答率(トレーニング) = 0.15
: 190. 正答率(テスト) = 0.1135
Generation: 200. 正答率(トレーニング) = 0.09
: 200. 正答率(テスト) = 0.1135
Generation: 210. 正答率(トレーニング) = 0.15
: 210. 正答率(テスト) = 0.1135
Generation: 220. 正答率(トレーニング) = 0.11
: 220. 正答率(テスト) = 0.1135
Generation: 230. 正答率(トレーニング) = 0.16
: 230. 正答率(テスト) = 0.1135
Generation: 240. 正答率(トレーニング) = 0.09
: 240. 正答率(テスト) = 0.1135
Generation: 250. 正答率(トレーニング) = 0.1
: 250. 正答率(テスト) = 0.1135
Generation: 260. 正答率(トレーニング) = 0.15
: 260. 正答率(テスト) = 0.1135
Generation: 270. 正答率(トレーニング) = 0.09
: 270. 正答率(テスト) = 0.1135
Generation: 280. 正答率(トレーニング) = 0.15
: 280. 正答率(テスト) = 0.1135
Generation: 290. 正答率(トレーニング) = 0.09
: 290. 正答率(テスト) = 0.1135
Generation: 300. 正答率(トレーニング) = 0.16
: 300. 正答率(テスト) = 0.1135
Generation: 310. 正答率(トレーニング) = 0.1
: 310. 正答率(テスト) = 0.1135
Generation: 320. 正答率(トレーニング) = 0.09
: 320. 正答率(テスト) = 0.1135
Generation: 330. 正答率(トレーニング) = 0.13
: 330. 正答率(テスト) = 0.1135
Generation: 340. 正答率(トレーニング) = 0.11
: 340. 正答率(テスト) = 0.1135
Generation: 350. 正答率(トレーニング) = 0.12
: 350. 正答率(テスト) = 0.1135
Generation: 360. 正答率(トレーニング) = 0.14
: 360. 正答率(テスト) = 0.1135
Generation: 370. 正答率(トレーニング) = 0.12
: 370. 正答率(テスト) = 0.1135
Generation: 380. 正答率(トレーニング) = 0.14
: 380. 正答率(テスト) = 0.1135
Generation: 390. 正答率(トレーニング) = 0.14
: 390. 正答率(テスト) = 0.1135
Generation: 400. 正答率(トレーニング) = 0.09
: 400. 正答率(テスト) = 0.1135
Generation: 410. 正答率(トレーニング) = 0.1
: 410. 正答率(テスト) = 0.1135
Generation: 420. 正答率(トレーニング) = 0.14
: 420. 正答率(テスト) = 0.1135
Generation: 430. 正答率(トレーニング) = 0.1
: 430. 正答率(テスト) = 0.1135
Generation: 440. 正答率(トレーニング) = 0.15
: 440. 正答率(テスト) = 0.1135
Generation: 450. 正答率(トレーニング) = 0.11
: 450. 正答率(テスト) = 0.1135
Generation: 460. 正答率(トレーニング) = 0.09
: 460. 正答率(テスト) = 0.1135
Generation: 470. 正答率(トレーニング) = 0.12
: 470. 正答率(テスト) = 0.1135
Generation: 480. 正答率(トレーニング) = 0.14
: 480. 正答率(テスト) = 0.1135
Generation: 490. 正答率(トレーニング) = 0.08
: 490. 正答率(テスト) = 0.1135
Generation: 500. 正答率(トレーニング) = 0.16
: 500. 正答率(テスト) = 0.1135
Generation: 510. 正答率(トレーニング) = 0.11
: 510. 正答率(テスト) = 0.1135
Generation: 520. 正答率(トレーニング) = 0.09
: 520. 正答率(テスト) = 0.1135
Generation: 530. 正答率(トレーニング) = 0.06
: 530. 正答率(テスト) = 0.1135
Generation: 540. 正答率(トレーニング) = 0.12
: 540. 正答率(テスト) = 0.1135
Generation: 550. 正答率(トレーニング) = 0.18
: 550. 正答率(テスト) = 0.1135
Generation: 560. 正答率(トレーニング) = 0.11
: 560. 正答率(テスト) = 0.1135
Generation: 570. 正答率(トレーニング) = 0.13
: 570. 正答率(テスト) = 0.1135
Generation: 580. 正答率(トレーニング) = 0.09
: 580. 正答率(テスト) = 0.1135
Generation: 590. 正答率(トレーニング) = 0.06
: 590. 正答率(テスト) = 0.1135
Generation: 600. 正答率(トレーニング) = 0.1
: 600. 正答率(テスト) = 0.1135
Generation: 610. 正答率(トレーニング) = 0.15
: 610. 正答率(テスト) = 0.1135
Generation: 620. 正答率(トレーニング) = 0.09
: 620. 正答率(テスト) = 0.1135
Generation: 630. 正答率(トレーニング) = 0.09
: 630. 正答率(テスト) = 0.1135
Generation: 640. 正答率(トレーニング) = 0.11
: 640. 正答率(テスト) = 0.1135
Generation: 650. 正答率(トレーニング) = 0.1
: 650. 正答率(テスト) = 0.1135
Generation: 660. 正答率(トレーニング) = 0.11
: 660. 正答率(テスト) = 0.1135
Generation: 670. 正答率(トレーニング) = 0.09
: 670. 正答率(テスト) = 0.1135
Generation: 680. 正答率(トレーニング) = 0.11
: 680. 正答率(テスト) = 0.1135
Generation: 690. 正答率(トレーニング) = 0.16
: 690. 正答率(テスト) = 0.1135
Generation: 700. 正答率(トレーニング) = 0.12
: 700. 正答率(テスト) = 0.1135
Generation: 710. 正答率(トレーニング) = 0.09
: 710. 正答率(テスト) = 0.1135
Generation: 720. 正答率(トレーニング) = 0.15
: 720. 正答率(テスト) = 0.1135
Generation: 730. 正答率(トレーニング) = 0.07
: 730. 正答率(テスト) = 0.1135
Generation: 740. 正答率(トレーニング) = 0.07
: 740. 正答率(テスト) = 0.1135
Generation: 750. 正答率(トレーニング) = 0.14
: 750. 正答率(テスト) = 0.1135
Generation: 760. 正答率(トレーニング) = 0.11
: 760. 正答率(テスト) = 0.1135
Generation: 770. 正答率(トレーニング) = 0.14
: 770. 正答率(テスト) = 0.1135
Generation: 780. 正答率(トレーニング) = 0.12
: 780. 正答率(テスト) = 0.1135
Generation: 790. 正答率(トレーニング) = 0.15
: 790. 正答率(テスト) = 0.1135
Generation: 800. 正答率(トレーニング) = 0.13
: 800. 正答率(テスト) = 0.1135
Generation: 810. 正答率(トレーニング) = 0.09
: 810. 正答率(テスト) = 0.1135
Generation: 820. 正答率(トレーニング) = 0.11
: 820. 正答率(テスト) = 0.1135
Generation: 830. 正答率(トレーニング) = 0.09
: 830. 正答率(テスト) = 0.1135
Generation: 840. 正答率(トレーニング) = 0.09
: 840. 正答率(テスト) = 0.1135
Generation: 850. 正答率(トレーニング) = 0.16
: 850. 正答率(テスト) = 0.1135
Generation: 860. 正答率(トレーニング) = 0.15
: 860. 正答率(テスト) = 0.1135
Generation: 870. 正答率(トレーニング) = 0.1
: 870. 正答率(テスト) = 0.1135
Generation: 880. 正答率(トレーニング) = 0.14
: 880. 正答率(テスト) = 0.1135
Generation: 890. 正答率(トレーニング) = 0.13
: 890. 正答率(テスト) = 0.1135
Generation: 900. 正答率(トレーニング) = 0.11
: 900. 正答率(テスト) = 0.1135
Generation: 910. 正答率(トレーニング) = 0.11
: 910. 正答率(テスト) = 0.1135
Generation: 920. 正答率(トレーニング) = 0.13
: 920. 正答率(テスト) = 0.1135
Generation: 930. 正答率(トレーニング) = 0.13
: 930. 正答率(テスト) = 0.1135
Generation: 940. 正答率(トレーニング) = 0.11
: 940. 正答率(テスト) = 0.1135
Generation: 950. 正答率(トレーニング) = 0.13
: 950. 正答率(テスト) = 0.1135
Generation: 960. 正答率(トレーニング) = 0.06
: 960. 正答率(テスト) = 0.1135
Generation: 970. 正答率(トレーニング) = 0.12
: 970. 正答率(テスト) = 0.1135
Generation: 980. 正答率(トレーニング) = 0.03
: 980. 正答率(テスト) = 0.1135
Generation: 990. 正答率(トレーニング) = 0.11
: 990. 正答率(テスト) = 0.1135
Generation: 1000. 正答率(トレーニング) = 0.11
: 1000. 正答率(テスト) = 0.1135
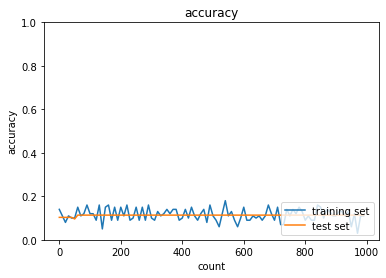
正答率(トレーニング) = 0.11
正答率(テスト) = 0.1135
モメンタム
# データの読み込み
(x_train, d_train), (x_test, d_test) = load_mnist(normalize=True, one_hot_label=True)
print("データ読み込み完了")
# batch_normalizationの設定 ================================
# use_batchnorm = True
use_batchnorm = False
# ====================================================
network = MultiLayerNet(input_size=784, hidden_size_list=[40, 20], output_size=10, activation='sigmoid', weight_init_std=0.01,
use_batchnorm=use_batchnorm)
iters_num = 1000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.01
# 慣性
momentum = 0.9
train_loss_list = []
accuracies_train = []
accuracies_test = []
plot_interval=10
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
# 勾配
grad = network.gradient(x_batch, d_batch)
if i == 0:
v = {}
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
if i == 0:
v[key] = np.zeros_like(network.params[key])
v[key] = momentum * v[key] - learning_rate * grad[key]
network.params[key] += v[key]
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
if (i + 1) % plot_interval == 0:
accr_test = network.accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = network.accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()
慣性:$\mu =0.9$
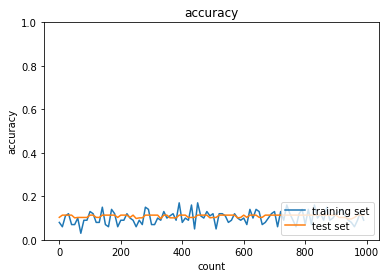
慣性:$\mu =0.4$
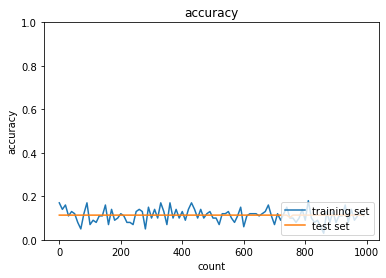
AdaGrad
# AdaGradを作ってみよう
# データの読み込み
(x_train, d_train), (x_test, d_test) = load_mnist(normalize=True, one_hot_label=True)
print("データ読み込み完了")
# batch_normalizationの設定 ================================
# use_batchnorm = True
use_batchnorm = False
# ====================================================
network = MultiLayerNet(input_size=784, hidden_size_list=[40, 20], output_size=10, activation='sigmoid', weight_init_std=0.01,
use_batchnorm=use_batchnorm)
iters_num = 1000
# iters_num = 500 # 処理を短縮
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.01
# AdaGradでは不必要
# =============================
momentum = 0.9
# =============================
train_loss_list = []
accuracies_train = []
accuracies_test = []
plot_interval=10
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
# 勾配
grad = network.gradient(x_batch, d_batch)
if i == 0:
h = {}
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
# 変更しよう
# ===========================================
if i == 0:
h[key] = np.zeros_like(network.params[key])
h[key] = momentum * h[key] - learning_rate * grad[key]
network.params[key] += h[key]
# ===========================================
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
if (i + 1) % plot_interval == 0:
accr_test = network.accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = network.accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()
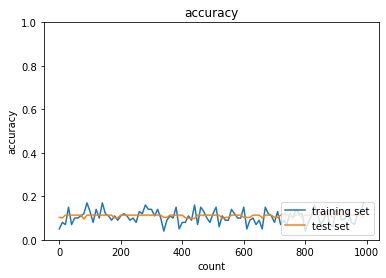
RSMprop
# データの読み込み
(x_train, d_train), (x_test, d_test) = load_mnist(normalize=True, one_hot_label=True)
print("データ読み込み完了")
# batch_normalizationの設定 ================================
# use_batchnorm = True
use_batchnorm = False
# ====================================================
network = MultiLayerNet(input_size=784, hidden_size_list=[40, 20], output_size=10, activation='sigmoid', weight_init_std=0.01,
use_batchnorm=use_batchnorm)
iters_num = 1000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.01
decay_rate = 0.99
train_loss_list = []
accuracies_train = []
accuracies_test = []
plot_interval=10
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
# 勾配
grad = network.gradient(x_batch, d_batch)
if i == 0:
h = {}
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
if i == 0:
h[key] = np.zeros_like(network.params[key])
h[key] *= decay_rate
h[key] += (1 - decay_rate) * np.square(grad[key])
network.params[key] -= learning_rate * grad[key] / (np.sqrt(h[key]) + 1e-7)
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
if (i + 1) % plot_interval == 0:
accr_test = network.accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = network.accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()
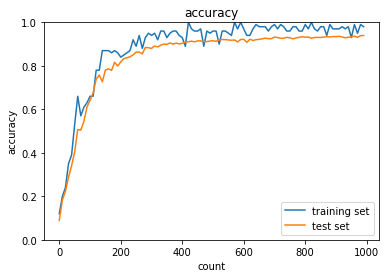
正答率(トレーニング) = 0.98
正答率(テスト) = 0.9397
Adam
# データの読み込み
(x_train, d_train), (x_test, d_test) = load_mnist(normalize=True, one_hot_label=True)
print("データ読み込み完了")
# batch_normalizationの設定 ================================
# use_batchnorm = True
use_batchnorm = False
# ====================================================
network = MultiLayerNet(input_size=784, hidden_size_list=[40, 20], output_size=10, activation='sigmoid', weight_init_std=0.01,
use_batchnorm=use_batchnorm)
iters_num = 1000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.01
beta1 = 0.9
beta2 = 0.999
train_loss_list = []
accuracies_train = []
accuracies_test = []
plot_interval=10
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
# 勾配
grad = network.gradient(x_batch, d_batch)
if i == 0:
m = {}
v = {}
learning_rate_t = learning_rate * np.sqrt(1.0 - beta2 ** (i + 1)) / (1.0 - beta1 ** (i + 1))
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
if i == 0:
m[key] = np.zeros_like(network.params[key])
v[key] = np.zeros_like(network.params[key])
m[key] += (1 - beta1) * (grad[key] - m[key])
v[key] += (1 - beta2) * (grad[key] ** 2 - v[key])
network.params[key] -= learning_rate_t * m[key] / (np.sqrt(v[key]) + 1e-7)
if (i + 1) % plot_interval == 0:
accr_test = network.accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = network.accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()
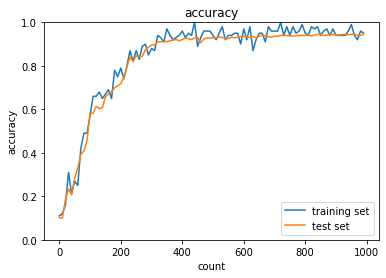
正答率(トレーニング) = 0.95
正答率(テスト) = 0.9458
第3章 過学習
テストごとの訓練誤差と学習誤差が乖離すること。
3.1 過学習の原因
パラメータの数が多い。
パラメータの値が適切ではない。
ノードの数が多い...etc
⇒ネットワークの自由度(層数、ノード数、パラメータの値...etc)が高い
データややりたいタスクに対してニューラルネットワークが複雑すぎる(自由度が高い)ということ。
学習が進むと重みの値にばらつきが発生する。重みが大きいほど重要な値であることを示すが大きいことによって過学習の原因となる。
確認テスト:機械学習で使われる線形モデル(線形回帰、PCA、…etc)の正則化は、
モデルの重みを制限することで可能となる。
前述の線形モデルの正則化手法の中にリッジ回帰という手法があり、
その特徴として正しいものを選択しなさい
(a)ハイパーパラメータを大きな値に設定すると、すべての重みが限りなく0に近づく
(b)ハイパーパラメータを0に設定すると、非線形回帰となる
(c)バイアス項についても、正則化される
(d)リッジ回帰の場合、隠れ層に対して正則化項を加える
答:(a)
3.2 正則化
3.2.1 L1, L2正則化
誤差関数に加えることで重みを抑制する。
\begin{eqnarray}
L_p=\|x \|_p =\left(|x_1|^p+| x_2 |^p+| x_3 |^p+\cdots +| x_n|^p\right)^{\frac{1}{p}}=\left(\sum_{i=1}^n|x_i|^p\right)^{\frac{1}{p}}
\end{eqnarray}
$p=1$のとき、$L_1$正則化
$p=2$のとき、$L_2$正則化
$\lambda$は減衰させるスケーリングのための値。
\begin{eqnarray}
E_n(w)+\frac{1}{p}\lambda \|x\|_p
\end{eqnarray}
L2正則化はL1正則化より計算量があるためリソースを食うが、性能向上には良い。
下図について、$L^1$正則化を表しているグラフはどちらか答えよ。
答:右図のLasso推定量
3.3 ドロップアウト
過学習の課題⇒ノードの数が多い。
そこで、とろっぷアウトは
ランダムにノードを削除して学習させること。
(擬似的なアンサンブル学習ができる)
メリットとしては、データ量を変化させずに、異なるモデルを学習させていると解釈できる。
第4章 畳み込みニューラルネットワーク(Convolutional Neural Network)の概念
畳み込みニューラルネットワーク(Convolutional Neural Network:CNN)は、主に画像認識等で使用されているニューラルネットワーク。
画像だけにしか使えないわけではなく、1次元CNNを使うことで時系列データを扱うことも出来る。
例えば画像の場合、縦、横、チャンネル(RGBやグレースケール)について学習できる。
4.1 畳み込み層
画像とフィルタ(カーネル)の積の総和にバイアスを加えることで算出することで特徴を抽出する。
例えば横線を抽出するフィルタに対する畳み込みの結果が大きければ横線の特徴を抽出(横線が画像に存在する)し、小さければ横線がないということになる。
フィルタは3x3, 5x5等のサイズ。
活性化関数に負数を0にできるReLUを使うことで、あきらかにそのフィルタに対する特徴を持っていない箇所をないものとして扱うことができ、学習に悪影響を与えることを防げる。
4.1.1 パディング
画像の周囲に固定値(0を使うことが多い)を埋め込むこと。
パディングなしで畳み込みをすると元の画像より小さくなるが、パディングをすることでサイズを維持することが出来る。
また、パディングなしの場合、画像の端の方は他の部分と比べて畳み込みに使われる回数が少なくなり、特徴として抽出されにくいが、パディングをすることによってより端の方も特徴を抽出できるようになる。
パディングに使う値は0でなくとも良いが、学習に影響を与える可能性があるため0とすることが一般的。
4.1.2 ストライド
フィルタをどれだけずらして畳み込みを行うかということ。
画像に対してフィルタを少しずつずらしながら畳み込みは行っていくが、この時、ストライドを1とした場合、次の畳み込みは1ピクセルずらして行うことになる。
ストライドが2なら2ピクセルずらすこととなる。
4.1.3 チャンネル
空間的な奥行き。
チャンネルが1つだと例えばカラー画像でもRGBの違いを区別せずに畳み込みすることになり、正確な結果とならない。
例えばカラー画像の場合はRGBの3チャンネルに分けて畳み込みを行う。
4.2 プーリング層
対象領域の中から1つの値を取得する層。
畳み込んだ後に行うことでそれらしい特徴を持った値のみを抽出できる。
4.2.1 最大値プーリング
3x3等の対象領域の中で最大値を取得する。
4.2.2 平均値プーリング
3x3等の対象領域の中で平均値を取得する。
確認テスト
サイズ6×6の入力画像を、サイズ2×2のフィルタで畳み込んだ時の出力画像のサイズを答えよ。なおストライドとパディングは1とする
答:7×7
\begin{eqnarray}
O_H&=&\frac{6+2\times 1-2}{1}+1=7\\
O_W&=&\frac{6+2\times 1-2}{1}+1=7
\end{eqnarray}
参考:公式
\begin{eqnarray}
O_H&=&\frac{(画像の高さ)+2\times (パディング)-(フィルターの高さ)}{ストライド}+1\\
O_W&=&\frac{(画像の幅)+2\times (パディング)-(フィルターの幅)}{ストライド}+1\\
\end{eqnarray}
実装の結果
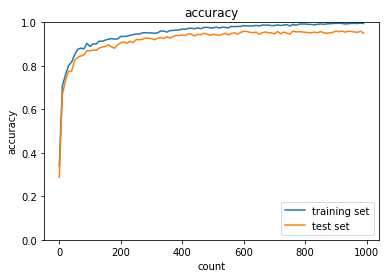
第5章 最新のCNN(初期の頃のNNです。)
5.1 AlexNet
2012年にILSVRC(ImageNet Large Scale Visual Recognition Challenge)で優勝したモデル。
ILSVRC:AIを用いて画像認識の正確性を競うコンテスト
AlexNetはそれまで(2011年まで)主要だった、サポートベクターマシーンを使ったモデルをなぎ倒して優勝したモデル。
なお、2012年2位だったのは、サポートベクターマシーンを使った東京大学の原田研究室(中心は牛久祥孝氏)
5層の畳み込み層およびプーリング層、それに続いて2層の全結合層という構造。
ドロップアウトを使用して過学習を抑えている。
5.2 その他(ILSVRC関係)
| 年 | 順位 | モデル | エラー率 | 機関 |
|---|---|---|---|---|
| 2012 | 1位 | AlexNet | 0.16 | トロント大学 |
| 2012 | 2位 | 東京大学(原田研究室) | ||
| 2013 | 1位 | ZFNet | 0.12 | ニューヨーク大学 |
| 2014 | 1位 | GoogLeNet | 0.07 | Google Xlab |
| 2014 | 2位 | VGGNet | 0.07 | オックスフォード大学 |
| 2015 | 1位 | ResNet | 0.036 | Microsoft Research |
| 2016 | 1位 | ensembled networks | 0.03 | 香港中文大学 |
| 2017 | 1位 | Squeeze and Excitation Nework (SENet) | 0.023 | 中国科学アカデミー |