第1章 強化学習
教師あり学習、教師なし学習と並ぶ機械学習の一分野
AiphaGoなど有名だが、強化学習は今注目を浴びている。
現場では量子化・高速化技術が大事。
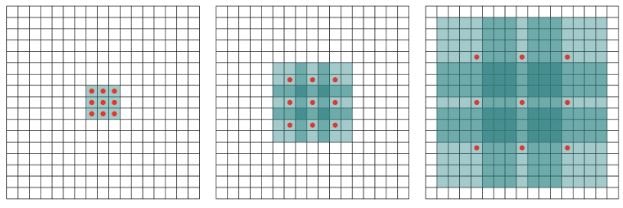
試行錯誤を通じて「環境において最も報酬が得られやすい行動」を「エージェント」が学習する。
長期的に報酬を最大化できるように環境の中で行動を選択できるエージェントを作ることを目標とする機械学習の一分野
⇒ 行動の結果として与えられる利益(報酬)をもとに行動を決定する原理を改善していく仕組み
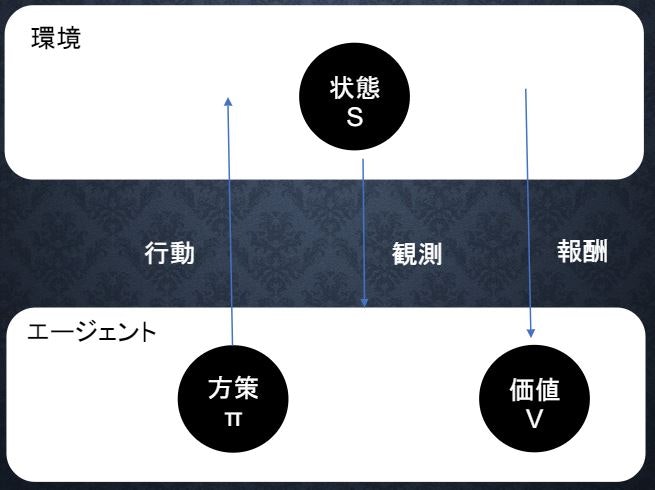
強化学習に必要な概念
1.行動:エージェントが環境に働きかけること。複数の行動の中から1つを選択する。
2.状態:エージェントが環境において置かれた状態。行動によって状態は変化する。
3.報酬:エージェントが受け取る報酬。報酬を元に、最適な行動を学習していく。
4.方策:状態を踏まえ、エージェントがどのように行動するのかを定めたルール
強化学習の応用例
マーケティングの場合
環境:会社の販売促進部
エージェント:プロフィールと購入履歴に基づいてキャンペーンを送る顧客を決めるソフトウェア
行動:顧客ごとに送信、非送信のふたつの行動を選ぶことになる
報酬:キャンペーンのコストという負の報酬とキャンペーンで生み出されると推測される売上という正の報酬を受ける
強化学習と通常の教師あり、教師なし学習との違い
結論:目標が違う
⇒ 教師なし、あり学習では、データに含まれるパターンを見つけ、データから予測することが目標・
⇒ 過学習では、優れた方策を見つけることが目標
強化学習について
・冬の時代があったが、計算速度の進展により大規模な状態をもつ場合の、強化学習を可能としつつある。
・関数近似法と、Q学習を組み合わせる手法の登場
1.1 Q学習
行動価値関数を行動する毎に更新することによって学習を進める方法
Q学習は、強化学習の一種で、各状態と行動の組合せにQ値を設定して、、エージェントが最もQ値の高い行動を選択する。
Q-tableの各値が最適化されることで学習する。
行動によるQ値の更新
Q値の更新量=学習係数×(報酬+割引率×次の状態で最大のQ値-現在のQ値)
Q学習の問題点
扱う状態の数が多いとQ-tableが大きくなり、学習がうまく進まなくなる。
⇒ 深層強化学習を利用する。
深層強化学習は、強化学習に深層学習を取り入れたもの。
Deep-Q-Network(DQN)は深層強化学習の一種で、Q-tableのかわりにNNを使用する。
強化学習の名前は、脳の学習メカニズム「オペラント学習」に由来。
スキナー博士は、「スキナーボックス」を開発。
「スキナーボックス」ではレバーを押すと餌が現れ、ラットは行動と報酬の関係を学習する。
Shultz博士らは1990年代後半、サルの脳に電極を刺してニューロンを電気刺激し、行動実験を行う。
学習前後で、ドーパミンを放出する神経細胞の活動が変化することを確認。
⇒強化学習は、実際の生物が行っている学習のアルゴリズムに近い。
累積報酬
強化学習では、最終的な累積報酬を最大化するように学習を行う。
方策$\pi$のよさは、得られる報酬の累積で決まる。
累積報酬
$$U_t=R_{t+1}+R_{t+2}+R_{t+3}+\cdots=\sum_{k=0}^{\infty}R_{t+k+1}$$
割引率$\gamma , (0<\gamma<1 )$ で割り引いた累積報酬
$$U_t=R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+\cdots=\sum_{k=0}^{\infty}\gamma^kR_{t+k+1}$$
$t$:現在の時刻、$R_t$:時刻 $t$ における報酬
1.2 関数近似法
価値関数や方策関数を関数近似する手法
昔は「この値があったら、これを返す」...のような表を使っていた。
その表を関数に変えて、関数を学習させればよいのでは...という発想。
1.3 価値反復法
方策の価値を定義し、これを最適化するアプローチ
1.3.1 価値関数
価値を表す関数としては「状態価値関数」と「行動価値関数」の2種類がある。
Q学習では「行動価値関数」を使う。
ある状態の価値に注目する場合は、状態価値関数状態と価値を組み合わせた価値に注目する場合は、行動価値関数を使う。
エージェントが目的にゴールするまで今の方策を続けた場合の報酬の予測値を得る関数。
1.3.2 状態価値関数
$V^{\pi}(s)$:状態 $s$ において、方策 $\pi$ により得られる累積報酬の期待値を表す関数
$$V^{\pi}(s)=E_{\pi}\left[R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+\cdots \right]=E_{\pi}\left[\sum_{k=0}^{\infty}\gamma^kR_{t+k+1}\right]$$
$S$:状態、$R_t$:報酬、$\gamma$:割引率
1.3.3 行動価値関数
$Q^{\pi}(s,a)$:状態 $s$ で、行動 $a$ を取ったとき、方策 $\pi$ により得られる累積報酬の期待値(価値)を表す関数
$$Q^{\pi}(s,a)=E_{\pi}\left[R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+\cdots \right]=E_{\pi}\left[\sum_{k=0}^{\infty}\gamma^kR_{t+k+1}\right]$$
1.4 方策関数
方策関数 $\pi(s,a)$ とは、方策ベースの強化学習手法において、ある状態 $s$ でどのような行動 $a$ を採るのかの確率を与える関数のこと。
方策関数$\pi(s,a)$が出した結果で、エージェントは環境の中で何かをする。
$\pi(s,a)$:方策関数⇒ $V^{\pi}(s)$ や$Q^{\pi}(s,a)$ を基にどういう行動をとるか
⇒経験を生かすorチャレンジする
⇒その瞬間・瞬間の行動をどうするか?
$V^{\pi}(s)$:状態価値関数 ⇒ 状態のみ
$Q^{\pi}(s,a)$:行動価値関数 ⇒状態+行動関数
⇒やり続けたら最終的にどうなるのか?
1.5 方策勾配法
方策を最適化したいが、現実的には困難な場合が多い
⇒ 方策をモデル化して最適化する手法
⇒ 方策勾配法
方策勾配法は方策をパラメータで表される関数とし、そのパラメータを最適化することで学習する。
⇒AlphaGoなどで採用
$$\theta^{(t+1)}=\theta^{(t)}+\epsilon \nabla J(\theta)$$
(ニューラルネットワークの重みの更新式に似ている。)
$t$:時間
$\theta$:方策関数のパラメータ(ニューラルネットワークでいう重み$W$)
$\epsilon$:学習率
$J$:方策の良さ、期待収益(報酬)を計算する関数(ニューラルネットワークでいう誤差関数)
ニューラルネットワークでは誤差を「小さく」⇒符号が「-」
強化学習では期待収益(報酬)を「大きく」⇒符号が「+」
方策関数のどう更新するのか?式にすると
\nabla_{\theta}J(\theta)=\mathbb{E}_{\pi_{\theta}}[\nabla_{\theta}\log \pi_{\theta}(a|s)Q^{\pi}(s,a)]
$\pi_{\theta}(a|s)$:方策関数(エージェントが取る行動の確率)
$Q^{\pi}(s,a)$:行動価値関数:状態$s$にあるときに、行動$a$を取った後に、方策$\pi$に従ったときの価値
$\pi_{\theta}(a|s)Q^{\pi}(s,a)$:ある行動をとるときの報酬
元の式:$\nabla_{\theta}\sum_{a\in A}\pi_{\theta}(a|s)Q^{\pi}(s,a)$
価値反復法
方策の価値を定義し、これを最適化するアプローチ
第2章 AlphaGo
2種類のAlphaGoがあり、
1つはAlphaGo Lee、2つはAlphaGo Zero
AlphaGoは基盤の状況認識にCNNを用いて(画像認識ではなく盤面の情報を付加して入力)、次の手の選択にモンテカルロ木を用いて成果を挙げた。
Google DeepMindによって開発された強化学習によるコンピュータ囲碁プログラム。
2016年3月9日、世界最強の韓国囲碁棋士を4勝1敗で倒したことによりニュースに度々取り挙げられた。
ニュースになった背景
それまでは、チェスや将棋はトッププロとコンピュータが互角以上になっていたが、
手数の多い囲碁はトップレベルに達するのに10年はかかるだろう...と予測されていたことが背景にあります。
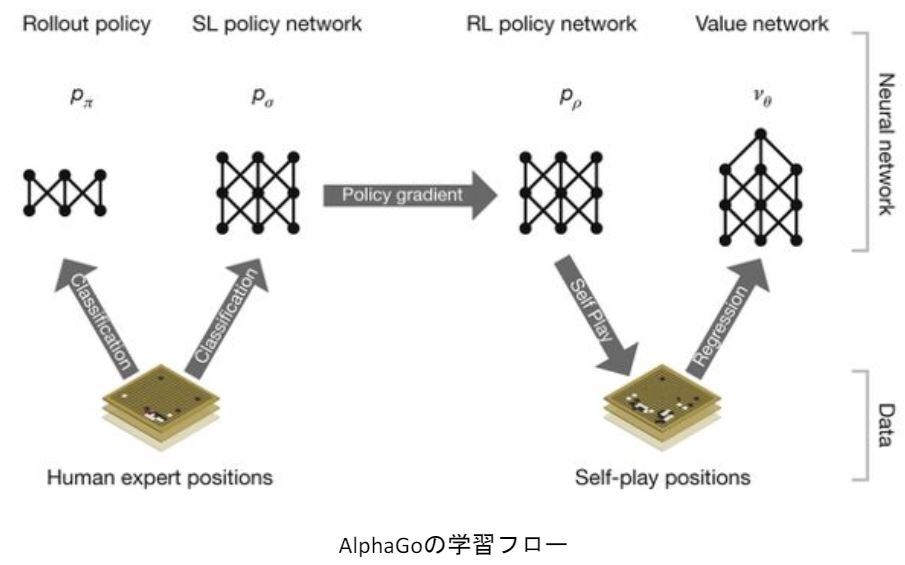
AlphaGoの学習は以下のステップで行われる
教師あり学習によるRollOutPolicyとPolicyNetの学習
↓
強化学習によるPolicyNetの学習
↓
強化学習によるValueNetの学習
2.1 AlphaGo Lee
PolicyNet、ValueNetいずれも畳み込みニューラルネットワーク。
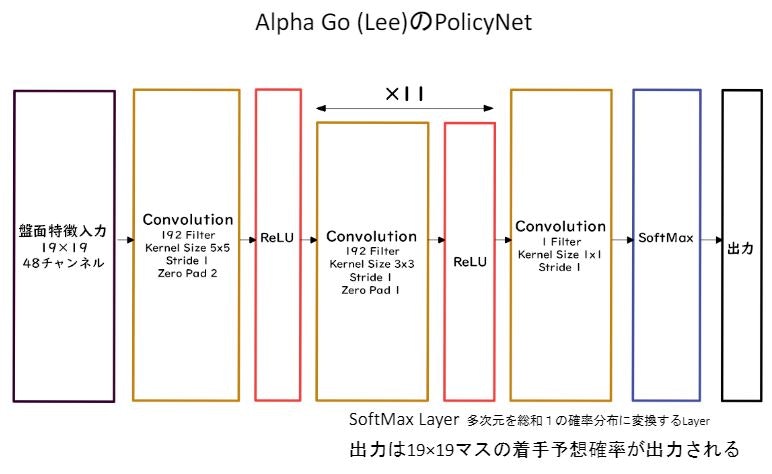
2.1.1 PolicyNet(方策関数)の強化学習
19x19マスの盤面特徴(48チャンネル)を入力とする。
通常のカラー画像ではRGBの3チャンネルだったが、48チャンネル持っている(石が自石・敵石・空白か、着手履歴、取れる石の数はいくつか等)。
出力はソフトマックス関数によって19x19の着手予想確率(どこに打つと良いか)が得られる。
2.1.2 ValueNet(価値関数)
19x19マスだけの盤面の特徴を入力とする。手番というチャンネルが増えているだけでほかはPolicyNetと同じ
出力は$\tan h$関数によって現局面の勝率を-1~1の範囲で得られる。
PolicyNetと違い、出力は2次元ではなく1次元(単一値)であるため平滑化(Flatten)をする。
2.1.3 Alpha Go Leeの学習ステップ
1.教師あり学習でRollOutPolicyとPolicyNetの学習を行う。
2.強化学習でPolicyNetの学習を行う。
3.強化学習でValueNetの学習を行う。
RollOutPolicy
ニューラルネットワークではなく線形の方策関数。
探索中に高速に着手確率を出すために使用される。
特徴が19×19マス分あり、出力はそのマスの着手予想確率となる。
PolicyNet、RollOutPolicyの教師あり学習
過去の棋譜データから教師データを用意して教師と同じ着手を予測できるよう学習する。
教師データの着手点のみを1、19x19の他を0とした分類問題として扱う。
2.1.4 モンテカルロ木探索
強化学習の手法の1つ。
価値観数を学習する時に使用する。
コンピュータ囲碁ソフトでは現在もっとも有効とされている探索法。
具体的には、現局面から末端局面までPlayOutと呼ばれるランダムシミュレーションを多数回行い、その勝敗を集計して着手の優劣を決定する。
Alpha Goのモンテカルロ木探索は選択、評価、バックアップ、成長という4つのステップで構成される。
2.2 AlphaGo Zero
2.2.1 AlphaGo LeeとAlphaGo Zeroの違い
AlphaGo Leeは教師あり学習をするが、AlphaGo Zeroは強化学習のみで作成
特徴入力からヒューリスティックな要素を排除し、石の配置のみにした3、PolicyNetとValueNetを1つのネットワークに統合した4、Residual Networkを導入した5、モンテカルロ木探索からRollOutシミュレーションをなくした。
ヒューリスティック:経験的な発見的なと言う意味もあるが、探索を効率化するのに有効な」と言う意味。
2.2.2 PolicyValueNet
PolicyNetとValueNetが統合されたが、それぞれ方策関数と価値観数の出力が得たいため途中で枝分かれしたニューラルネットワークとなる。
Residual Net(Residual Block)を導入することで勾配消失、勾配爆発を防いでいる。
Residual Blockの考え方はResNetと同じ。
2.2.3 Residual Blockの工夫
Bottleneck:Residual Blockの工夫として次元削減を取り入れることで2層のものと計算量はほぼ同じとしつつも1層増やしたもの。
PreActivation:Residual Blockの並びをBatchNorm、ReLU、Convolution、BatchNorm、ReLU、Convolution、Addにして性能向上したもの。
2.2.4 ネットワークの工夫
WideResNet:Convolutionのフィルタを$k$倍に段階的に幅を増やしていくResNet
⇒ フィルタを増やすことで、層が浅くても深い層のものと同等以上の性能を発揮
PyramidNet:WideResNetのように段階的にフィルタを増やすのではなく、各層でフィルタを増やすResNet
第3章 分散深層学習
深層学習は多くのデータを使用したりハイパーパラメータのチューニング等に多くの時間を要すため高速な計算が求められる。
複数の計算資源(ワーカー)を使用し、並列的にニューラルネットを構成することで、効率の良い学習を行いたい。
データ並列化、モデル並列化、GPUによる高速技術は不可欠である
3.2 データ並列
親モデルを各ワーカーに $n$ 個のレプリカ(子モデル)としてコピーして、分割したデータを与えて各ワーカーごとに計算させる。
同じ構造のモデルでデータを分けて学習するため、データが多いほど速度向上が見込めるため、データ並列化はデータが多い場合に選択すべきである。
3.2.1 データ並列:同期型
データ並列化は各モデルのパラメータの合わせ方で、同期型か非同期型か決まる。
同期型のパラメータ更新の流れ。各ワーカーが計算が終わるのを待ち、全ワーカーの勾配が出たところで勾配の平均を計算し、親モデルのパラメータを更新する。
3.2.2 データ並列:非同期型
同期型と違って全ワーカーの学習が終わるのを待たず、子モデルのパラメータを更新する。
学習が終わったらそのワーカーはパラメータ更新した子モデルをサーバにPushされる。
新しく学習を始める時は、パラメータサーバからPopしたモデルに対して学習していく。
処理のスピードは、お互いのワーカーの計算を待たない非同期型の方が早い。
しかし、非同期型は最新のモデルのパラメータを利用できないので、学習が不安定になりやすい。参考:Stale Gradient Problem
現在は同期型の方が精度が良いことが多いので、主流となっている
3.3 モデル並列
親モデルを各ワーカーに分割し、それぞれのモデルを学習させる。全てのデータで学習が終わった後で、一つのモデルに復元。
モデルが大きい時はモデル並列化を、データが大きい時はデータ並列化をすると良い。
モデルのパラメータ数が多いほど、スピードアップの効率も向上する。
3.4 GPUによる高速化
3.4.1 GPU
分岐等様々な処理を得意とするCPUと違い、GPUは画像処理に関する演算を担う。映像や3Dグラフィックスなどを処理するには大規模な並列計算が必要となる。
これをCPUで行うのは効率的ではない。そこで、大規模な並列演算処理に特化したモデルとしてGPUが作られた。
膨大な行列計算を行うニューラルネットワークにとって並列計算できるGPUは高速化に役立つ。
3.4.2 GPGPU(General-purpose on GPU)
同じような計算処理が大規模で行われる場合、GPUが適任。
もともとGPUは画像処理に最適化されたものになるが、
現在のGPUは画像以外の計算にも使えるように改良されている。
また、現在はGPUなしでは、学習できない巨大なネットワークが当たり前のように試されている。こうした画像以外の目的での使用に最適化されたGPUをGPGPU(General-purpose on GPU)という。
3.4.3 CUDA
GPUの開発でリードしているNVIDIA社のGPUで使える並列コンピューティングプラットフォーム。
Deep Learning用に提供されているので、使いやすい
NVIDIA社以外のものはサポートしていないライブラリがほとんど。
3.4.4 OpenCL
オープンな並列コンピューティングのプラットフォーム
NVIDIA社以外の会社(Intel, AMD, ARMなど)のGPUからでも使用可能。
Deep Learning用の計算に特化しているわけではない。
なお、Google社はテンソル計算処理に最適化された演算処理を開発しておりTPUと呼ばれている。
第4章 軽量化
軽量化の手法代表的な手法として下記の3つある
1.量子化
2.蒸留
3.プルーニング
4.1.量子化(Quantaization)
ニューラルネットワークの軽量化技術の1つに量子化がある。
量子化は32bitもしくは16bit精度の浮動小数点で表現されるニューラルネットワーク内のデータをそれより小さいbit数で表現することにより、計算の高速化や小メモリ化を図ること。
ネットワークが大きくなるとパラメータも多くなっていくため、計算の高速化や省メモリ化を図る必要がある。
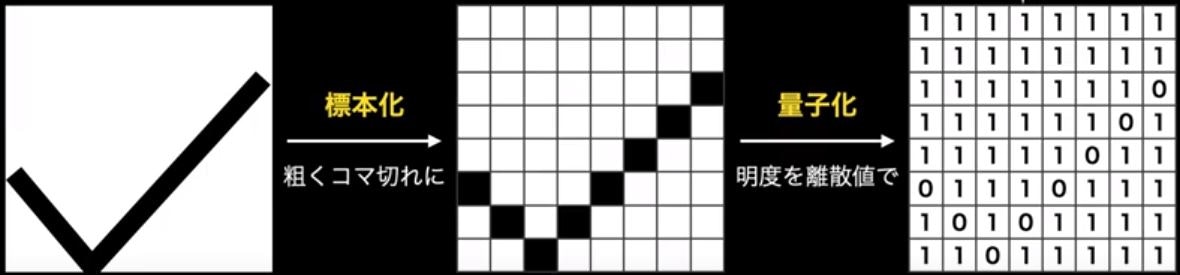
量子化のうち1bitで表現することを特に二値化(binarizaiton)という。
パラメータ、活性化、勾配はいずれも量子化の対象となる。
量子化の利点としては、計算の高速化と省メモリである。
逆に、量子化の欠点としては精度の低下が考えられ、bit数を減らすと浮動小数点数で表現できる小数点数の精度が落ちる。
しかし、それほど問題ではない。
4.2 蒸留(Distillation)
蒸留とは、大きなモデルが獲得した知識を小さなモデルに転移させる方法であり、一般に軽量化の手法に位置づけられる。
(大きなネットワーク入出力を小さいネットワークで再学習させること)
具体的には、学習済の大きなモデルを教師、知識を移したい小さなモデルを生徒とする。教師は正解ラベルを用いて通常の学習を行い、教師の学習後に生徒の学習を行う。
教師モデルの重みを固定し、生徒モデルの重みを更新していく。
誤差は教師のモデルと生徒のモデルのそれぞれの誤差を使い重みを更新していく
4.3 プルーニング(Pruning)
プルーニングは精度に大きな影響を与えない、ノードやエッジなどを刈ることによってデータ量と計算回数を削減する方法である。
複雑なモデルになればなるほどパラメータが膨大な数となっていくが、全てのニューロンが精度に影響を与えるわけではない。
そこで、影響の少ないニューロンを刈って有用なニューロンのみ残して再学習することでモデルの複雑さを軽減して軽量化につなげることがプルーニングである。。
チャンネルをプルーニングする方法の1つとして、ラッソに基づいてチャンネルを選択し選択されたチャンネルだけ使って特徴マップを再構成する方法がある。
第5章 MobileNet
Depthwise Separable Convolution(Depthwise ConvolutionとPointwise Convolution)という仕組みを用いて画像認識において軽量化・高速化・高精度化したモデル。
全体の計算量はDepthwise Convolutionの計算量+Pointwise Convolutionの計算量となる。
5.1 一般的な畳込みの計算量
高さ $H$、幅 $W$、カーネルのサイズ $K$、チャンネル $C$、フィルタ数 $M$とすると以下のようになる。
入力特徴マップ(チャネル数):$H\times W\times C$
カーネル:$K\times K\times C$
出力マップ:$H\times W\times M$
ストライド1でパディングありの場合の畳み込み計算量
ある1点の計算量:$K\times K\times C \times M$
全出力マップの計算量:$H\times W \times K\times K\times C \times M$
5.2 Depthwise Convolution
入力マップのチャンネルごとに畳み込みをする
出力マップとそれらと結合
フィルタは1つ固定
入力マップ:$H\times W\times C$
カーネル:$K\times K\times 1$
出力マップ:$H\times W\times C$
全出力マップの計算量:$H\times W \times K\times K\times C $
5.3 Pointwise Convolution
$1\times 1$ convとも呼ばれる(正確には$1\times 1\times C$)
・入力マップのポイントごとに畳み込みを実施
・出力マップ(チャネル数)はフィルタ数分だけ作成可能(任意のサイズが指定可能)
入力マップ:$H\times W\times C$
カーネル:$1\times 1\times C$
出力マップ:$H\times W\times C$
全出力マップの計算量:$H\times W\times C\times M$
第6章 DenseNet
Dense Blockという仕組みを用いた画像認識モデル。
6.1 DenseNetの流れ
畳み込み
↓
Dense Block
↓
Transition Layer
↓
Dense Block
↓
Transition Layer
↓
Dense Block
↓
プーリング層
↓
全結合層の流れ。
Dense Blockで前の各層の入力を使うことでチャンネル数が増え、Transition Layerで特徴量の抽出を繰り返していく。
6.2 Dense Block
Dense Blockは複数の層で構成されており、各層を通り抜けるとチャンネルが増加していく。
特徴マップの入力に対してバッチ正規化、ReLU関数による変換、3x3による畳み込みを行う。
DenseNet内で使用されるDenseBlockと呼ばれるモジュールでは成⻑率$k$と呼ばれるハイパーパラメータが存在する。
⇒ DenseBlock内の各ブロック毎に$k$個ずつ特徴マップのチャネル数が増加していく時、$k$を成⻑率と呼ぶ
6.3 Transition Layer(変換レイヤー)
Dense Blockで増えた特徴量マップをダウンサンプリングして削減、次のDense Blockにつなぐ。
第7章 正規化
7.1 Batch Normalization
ミニバッチ単位で平均が0、分散(標準偏差)が1になるように正規化。
学習時間の短縮や初期値への依存低減、過学習の抑制効果が期待できる。
$N$個のデータの同一チャンネルが正規化の単位となり、特徴マップごとに正規化された結果を出力する。
ただし、バッチサイズに影響を受けるため、バッチサイズが小さいと学習が収束しないこともある。
このバッチサイズはマシンスペックによって調整せざるおえないため、正確に効果を確認しづらくなる。
7.2 Layer Normalization
各データ1つの全チャンネルに対して正規化する。
全てのチャンネルで正規化して特徴マップごとに出力する。
特徴
入力データのスケールに関してロバスト
重み行列のスケールやシフトに関してロバスト
※ロバスト性:頑強性のこと。外からの影響を抑える仕組みや性質。
7.3 Instance Normalization
各データ1つの各チャンネルに対して正規化する。
コントラストの正規化等で使用される。
第8章 WaveNet
8.1 WaveNet
WaveNetは、時系列データである音声に畳込みニューラルネットワーク(Dilated Convolution)を用いた音声生成モデル。
音声合成と音声認識の両者を行うことができる。
次元間でのつながりがある場合、畳込みができる。
畳込みは2次元(画像)だけでなく1次元や3次元等も可能である。
WaveNetではDilated Causal Convolutionを採用することにより、少ないパラメータで長い時間の特徴を考慮することができる。
8.2 Dilated Causal Convolution
層が深くなるにつれて畳み込むリンクを離す。
受容野を簡単に増やすことができるという利点がある。
通常の畳込みと同じ層の深さでもより幅広い時系列を扱うことができる。
演習問題:深層学習を用いて結合確率を学習する際に、効率的に学習が行えるアーキテクチャを提案したことがWaveNetの大きな貢献の1つである。提案された新しいConvolution型アーキテクチャは(あ)と呼ばれ、結合確率を効率的に学習できるようになっている。
答:(あ)⇒Dilated Causal Convolution
演習問題:(あ:Dilated Causal Convolution)を用いた際の大きな利点は、単純なConvolution Layerと比べて(い)ことである。
答:(い)⇒パラメータ数に対する受容野が広い。
第9章 Seq2seq
9.1 BERTまでのロードマップ
Seq2Seq
Encoder-Decoder Model
↓
Transformer
Encoder-Decoder Model × Attention
↓
BERT
9.2 再掲:Seq2Seqは、Sequence(系列)を受け取り、別のSequence(系列)に変換するモデル。
自然言語処理でよく用いられる。
RNNをベースにした文章などの入力を圧縮する(Encode)と、出力を展開する(Decode)からなるモデル(Encoder-Decoderモデルの一種)
入力系列がEncodeされ、内部状態からDecodeする
機械翻訳(英語→日本語、文章要約、対話(自分の発言⇒相手の発言、チャットボット:テキスト⇒テキスト)、音声認識(波形⇒テキスト)などに用いられる。
9.3 Seq2Seqの理解に必要な材料
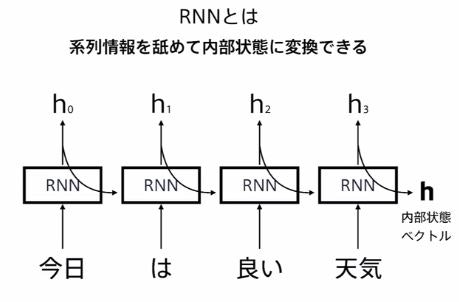
1.RNNの理解
RNNの動作原理、LSTMなどの改良版RNNの理解
2.言語モデルの理解
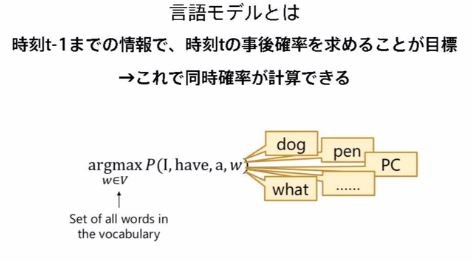
I have a に続く言葉
dog,pen,PCはあり得る ⇒ 確率は高い
what はあまりない ⇒ 確率は低い
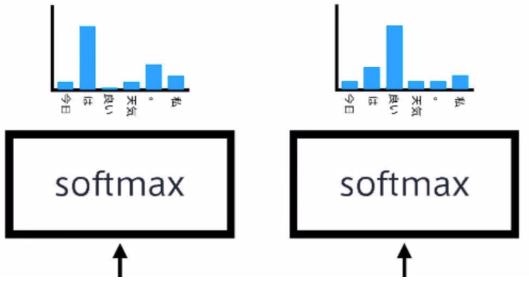
「今日」の次の言葉は「は」である確率が高い。
「今日は」の次の言葉は「良い」である確率が高い。
9.4 RNN×言語モデルをまとめると
・RNNは系列情報を内部状態に変換することができる。
・文章の各単語が現れる際の同時確率は、事後確率で分解できる。
⇒したがって、事後確率を求めることがRNNの目標になる。
・言語モデルを再現するようにRNNの重みが学習されていれば、ある時点の次の単語を予測することができる。
・先頭単語を与えれば文章を生成することも可能。
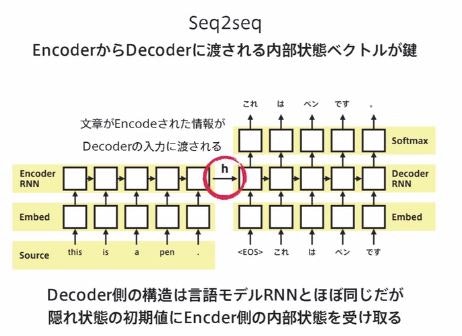
9.5 Seq2Seqの具体的な用途
⇒ 機械対話や機械翻訳等に使用されている。
例えば機械翻訳の場合、Encoderに日本語を入力し、Decoderの出力で英語を得る等といった形となる。
一問一答しかできないという課題がある。
文脈もなくただ応答するというイメージ。
そして、Seq2seqの理解にはRNNと言語モデルの理解が必要。
RNNは系列情報を内部状態に変換することができる。
文章の各単語が現れる際の同時確率は、事後確率で分解でき、事後確率を求めることがRNNの目標になる
言語モデルを再現するようにRNNの重みが学習されていれば、ある時点での次の単語を予測することができ、先頭単語を与えれば文章を生成することも可能
第10章 Transformer
10.1 Transformerの概説
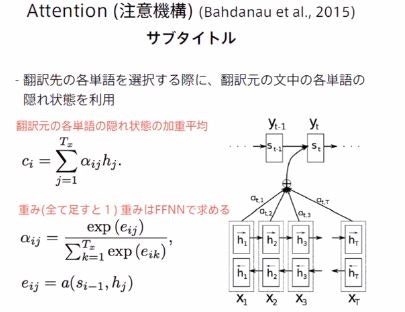
Attentionの再掲
⇒ 文章中のどの単語に注目すればよいのかを表すスコア
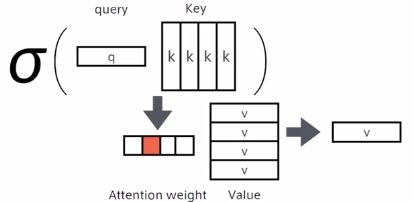
⇒ Query、key、Valueの3つのベクトルで計算される。
Query:Inputのうち検索をかけたいもの。
Key:検索対象とQueryの近さを測る
Value:keyにもとづき適切なValueを出力する。
Transformerは、アメリカのHugging Face社が提供
⇒ 分類、情報抽出、要約、翻訳、テキスト生成などのための事前学習モデルを100以上の言語で提供
⇒ 最先端の自然言語処理技術が簡単に使用可能
⇒ PyTorch と TensorFlow で利用可能。
RNNを使用せず、Attentionのみ使用しているモデル。
機械翻訳のみならず様々な自然言語処理で使用されている。
Decoderは次の単語を予測するが、RNNを使っていないため系列全ての単語が一度に与えられる。
そのため、未来の単語が見えないようにするため、Decoderでは未来の単語をマスクする。
Source Target-Attentionに加えてSelf-Attentionも用いられ、正規化としてLayer Normalizationが用いられる。
10.2 Encorderの構造
Position Encodingによって位置情報を加える。
文章の中でどの位置にあるか、情報を加える。
TransfomerではRNNを使っていないため、単語の語順情報を与える。
↓
Multihead Attention層
↓
normalization層
データの偏りを無くす。
通常のNNではバッチ正規化を行うが、Transfomerでは
layer normalizationというデータ内の正規化が行われる。
↓
位置単位の順伝播ネットワーク
Position-Wise Feed Forward Network
(位置情報を保持したまま順伝播させる。)
↓
normalization層
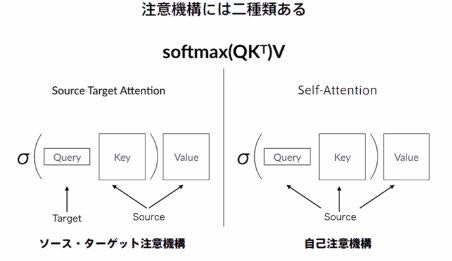
10.3 Source Target-Attention(ソースターゲット注意機構)
Queryに正解となる系列を与え、Key、Valueに入力となる系列を与えるAttention。
10.4 自己注意層(Self-attention Layer)
Queryに正解となる系列を与えるSource Target Attentionと違い、
Self-AttentionではQuery、Key、Value全て入力となる系列を与える。
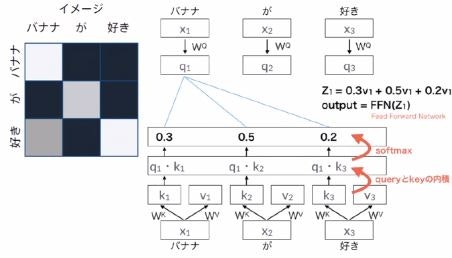
10.5 Scaled dot product attention
全単語に関するAttentionをまとめて計算する。
Attention(Q,K,V)=softmax \left(\frac{QK^T}{\sqrt{d_k}}\right)V\\
Attention(Q,K,V)=softmax\left(QK^Td_k\right)V
$d_k$:内部状態の次元数。内積の値が大きくなって誤差逆伝播に影響が出るためスケーリング。
10.6 Multi-Head Attention
8個のScaled dot product attentionを出力をconcat
それぞれのヘッドが異なる種類の情報を収集。
10.7 Residual Connection
入出力の差分を与えることで学習の効率化を図る手法。
10.8 Position-Wise Feed Forward Network
⇒2層の全結合ニューラルネットワーク
⇒単語の位置ごとに個別の順伝播ネットワーク
⇒他単語との影響関係を排除
⇒パラメータはすべてのネットワークで共通
線形変換⇒ ReLu ⇒線形変換
$$FFN(\mathbb{x})=\max \left(0,\mathbb{x}W_1+\mathbb{b_1}\right)W_2+\mathbb{b_2}$$
10.9 Position Encoding
TransfomerではRNNを使っていないため、単語の語順情報を与える。
PE_{(pos,2i)}=\sin\left(pos/10000^{2i/d_{model}}\right)\\
PE_{(pos,2i+1)}=\cos\left(pos/10000^{2i/d_{model}}\right)
pos:単語の位置
$2i$、$2i+1$:Embeddingの何番目か
$d_{model}$:次元数(512)
第11章 物体検知
入力は画像(カラー・モノクロは問わない)
出力に応じて認識タスクが4つに分かれる
| 日本語訳 | 出力 | 備考 | |
|---|---|---|---|
| Classification | 分類問題 | 単一or複数のクラスラベル | 分けるのみ |
| Object Detection | 物体検知 | bounding box | どこに、何があるか?物体検出位置 |
| Semantic Segmentation | 意味領域分割 | ピクセルに対しクラスラベル | 書くピクセルに対してラベルを割り当てる |
| Instance Segmentation | 個体領域分割 | ピクセルに対しクラスラベル | さらに区別も付けられる |
今までの分類問題 ⇒ 物体が写っているかどうかに興味がない。
これからは ⇒ 物体の位置(どこに何が?写っているか)も興味がある。
さらには ⇒ 物体の個々に興味があるかどうか?
11.1 物体検知(bounding box)
物体検知一般的な出力は、どこに何がどんなコンフィデンス(信頼度)で?出力されているのか、セットで与えられるのが一般的。
物体の位置(bounding box)、予測ラベル、コンフィデンスの3つを合わせて出力することが多い。
その物体検知のモデルの性能を判断する上で、コンペティションでも用いられる4つの代表的なデータセットがある。
そもそも、なぜデータセット?
さまざまなアルゴリズムが開発されるにつれ、精度を見るために、
共通として制度評価に用いられるデータセットが必要になる。
目的に応じた学習が行われるように、判断ができるようにさまざまなデータセットがある。
物体検知コンペティション(チャレンジ)で用いられたデータセットは、次の通り
どのような特徴(クラス、Traindata、Box÷画像)があるのかを抑える。
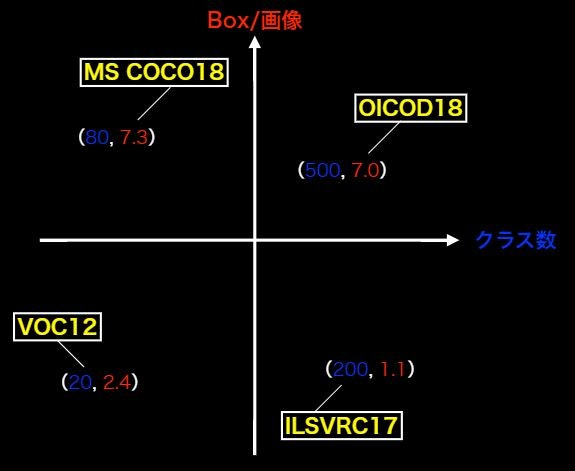
| コンペ | クラス | Train+Val | Box÷画像 | 画像サイズ |
|---|---|---|---|---|
| VOC12 | 20 | 11,540 | 2.4 | 470×380 |
| ILSVRC17 | 200 | 476,668 | 1.1 | 500×400 |
| MS COCO18 | 80 | 123,287 | 7.3 | 640×480 |
| OICOD18 | 500 | 1,743,042 | 7.0 | 一様ではない |
ILSVRC17以外は、Instance Annotationが与えられている。
つまり物体個々のラベルがなされている。
VOC:Visual Object Classes
主要貢献者が2012年に他界ためコンペは終了
ILSVRC:ImageNet Scale Visual Recognition Challenge
ImageNetのサブセット、ILSVRCは有名なコンペだが2017年に終了
Open Images Challengeに後継がなされた。
コンペに勝つことでモデルが勝つ ⇒ 商業で有名になる ⇒・・・。
2015年ちょっとまずいことがあった。サーバーに不正アクセス事案。
MS COCO:Common Object in Context
マイクロソフトが作ったデータセット。
新たな評価指標を提唱(mAPcoco(mean Average Precision coco) )
OICOD:Open Images Challenge Object Detection
Open Images V4のサブセット
ILSVRCとMS COCOとは異なるannotation processを取っている。
他のデータセットとしては、
CIFAR-10:クラスごとに6,000イメージ、5万個のトレーニング画像、1万個のテスト画像
Food-101:食べ物だけの画像のデータセット
楽天データセット
「Box÷画像」の意味
一画像当たりのBox数の平均数。
⇒なぜ重要なのか?
Box÷画像が少ない:ほぼアイコンのような画像(画像の中心に物体が1つ)⇒日常感がない。自動運転などにはいかせない。
(アイコンのような写りにはよい。)
Box÷画像が多い:1個1個の物体が小さい。⇒ 日常生活の画像に近くなる。
目的に応じた選択を
⇒ 画像の物体がアイコン的か?それとも複数か?
クラス数が多いことは嬉しいか?
⇒ 同じものなのに違う名づけがされていて、クラスが違うかも。
LaptopとNotebookは違うラベル。
葉っぱの上のテントウムシ⇒アリというラベル??
評価指標の前に分類問題の評価指標
混合行列の復習(再掲)
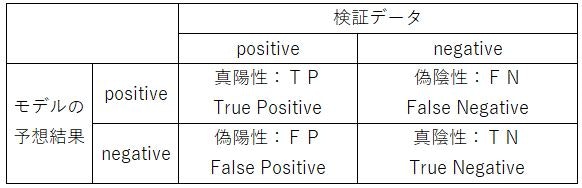
1.真陽性:TP(True Positive) ⇒ 正しくPositiveと判別した数
2.偽陽性:FP(False Positive) ⇒ 間違えてPositiveと判別した数
3.真陰性:TN(True Negative) ⇒ 正しくNegativeと判別した数
4.偽陰性;FN(False Negative) ⇒ 間違えてNegativeと判別した数
正解率(Accuracy):全データ($TP+FN+FP+TN$)のうち、正しく判別した($TP+TN$)確率
$$\frac{TP+TN}{TP+FN+FP+TN}$$
再現率(Recall):Positiveなデータ($TP+FN$)から、Positiveと予想($TP$)できる確率
$$\frac{TP}{TP+FN}$$
適合率(Precision):モデルがPositiveと予想したデータ$TP+FP$から、Positiveと予想($TP$)できる確率
$$\frac{TP}{TP+FP}$$
F値(F score):再現率(Recall)と適合率(Precision)の調和平均
$$\frac{2}{\frac{1}{Recall}+\frac{1}{Precision}}=\frac{2(Precision)(Recall)}{Recall+Precision}$$
11.2 IOU(Intersection Over Union)
目的 ⇒ 物体検出においてはクラスラベルだけでなく, 物体位置の予測精度も評価したい!
⇒そのためのbounding box
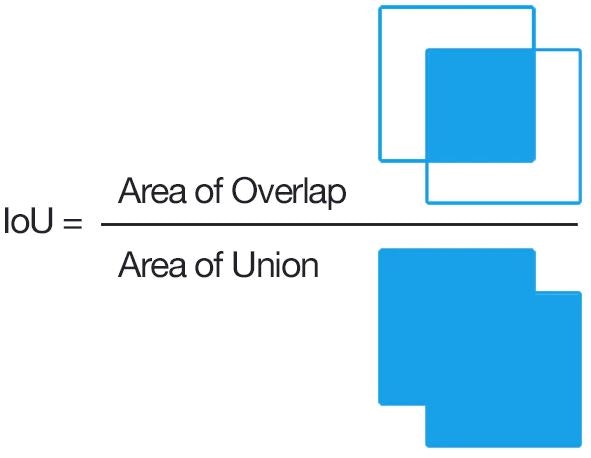
$$IoU=\frac{TP}{TP+FP+FN}$$
IOUの直感的理解は難しい ⇒ IOUにはよくある誤りがある。
計算:
| conf | pred | IoU | 判定 | |
|---|---|---|---|---|
| P1 | 0.92 | 人 | 0.88 | IoU>0.5=TP |
| P2 | 0.85 | 車 | 0.46 | IoU<0.5=FP |
| P3 | 0.81 | 車 | 0.92 | IoU>0.5=TP |
| P4 | 0.70 | 犬 | 0.83 | IoU>0.5=TP |
| P5 | 0.69 | 人 | 0.76 | IoU>0.5=TPだが人は検出済みのためFP |
| P6 | 0.54 | 車 | 0.20 | IoU<0.5=FP |
適合率(Precision):モデルがPositiveと予想したデータ$TP+FP$から、Positiveと予想($TP$)できる確率
$$\frac{TP}{TP+FP}=\frac{3}{3+3}=0.5$$
再現率(Recall):Positiveなデータ($TP+FN$)から、Positiveと予想($TP$)できる確率
$$\frac{TP}{TP+FN}=\frac{3}{3+0}=1$$
11.3 AP:Average Precision(PR曲線の下側面積)
confの閾値を$\beta$とするとき、Recall$=$R($\beta$)、
Precision$=$ P($\beta$)
$$AP=\int_0^1P(R)dR$$
11.4 mAP:mean Average Precision
AP:Average Precisionの平均
$$mAP=\frac{1}{C}\sum_{i=1}^C AP_i$$
11.5 mAPcoco(mean Average Precision coco)
IOUの閾値は0.5 で固定 ⇒ IOUの閾値を0.5~0.95まで0.05刻みでのmAPを計算し算術平均をとった値
(MS COCOで導入された新たな指標)
$$mAP_{COCO}=\frac{mAP_{0.5}+mAP_{0.55}+mAP_{0.6}+mAP_{0.65}+\cdots +mAP_{0.95}}{10}$$
位置を厳しくしながら評価していったもの。
$mAP_{0.75}$:あたりがよく使われる??
11.6 FPS(Flames per Second)
物体検出の検出速度に対する評価指標(精度も大事だが、速度も大事)
リアルタイム検出も大事。
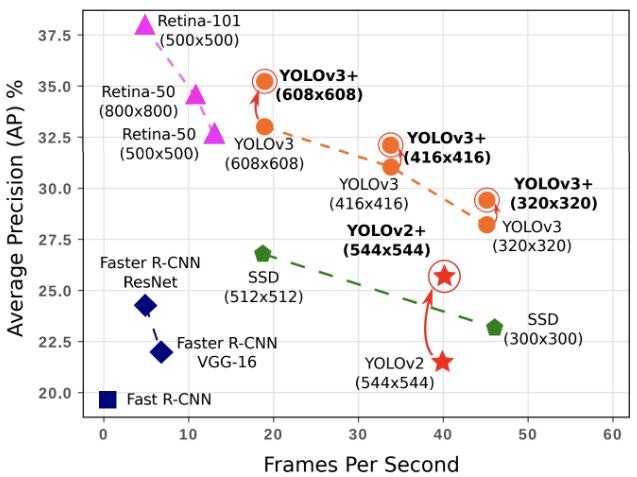
⇒ 右に行けば行くほど良い。
1フレームに何秒 ⇒ inference time
縦軸はAPで用いられることが多い。
11.7 2段階検出器(Two-stage detector)
候補領域の検出とクラス推定を別々に行う。
1段階検出器と比べて精度が高い傾向
1段階検出器と比べて計算量が大きいため予測も遅い傾向
⇒別々に推定を行うので時間がかかる。(リアルタイム検出には向かない)
11.8 1段階検出器(One-stage detector)
候補領域の検出とクラス推定を同時に行う。
2段階検出器と比べて精度が低い傾向
2段階検出器と比べて計算量が小さく予測も早い傾向
⇒リアルタイム検出には、2段階検出器より向いている。
11.9 SSD(Single Shot Detector)
1段階検出器のモデルの1つ。
初めにデフォルトボックスを用意する(一般的には複数用意される。)
デフォルトボックスを変形して、プレディクテッド・バウンディングボックスとする。
VGG16をベースとしたアーキテクチャ。
11.10 Non-Maximum Suppression
デフォルトボックスを複数用意したことで1つの物体に対して複数のバウンディングボックスが予測される問題
⇒IoUを計算する。閾値で複数の予測があるのであれば最もconfidenceが高いものだけを残す
RCNNでもすでに用いられており、SSDで初めて出てきた概念ではない。
11.11 Hard Negative Mining
VOCの21クラス目である背景のようなクラスがある場合、背景とそれ以外の物体で検出数が不均衡となる。
⇒ 最大でもposittive:negative=1:3となるように制約をかける
11.12 損失関数
$$L(x,c,l,g)=\frac{1}{N}\left(L_{conf}(x,c)+\alpha L_{loc}(x,l,g)\right)$$
$L_{conf}$:confidenceに対する損失
$L_{loc}$:検出位置に対する損失
11.13 参考論文
DSSD : Deconvolutional Single Shot Detector
⇒ https://arxiv.org/abs/1701.06659
(オススメ)
第12章 Semantic Segmentation
covolutionやpooling をかますことにより入力画像の解像度がどんどん落ちる。
⇒ 解像度が落ちることがSemantic Segmentationにとっては問題
Semantic Segmentationは、入力サイズと同じサイズの画像があり各ピクセルに対してクラス分類が行われるのが基本
解像度が落ちている状態、つまり入力時の画像の解像度とは違う
⇒ どうやって入力時の画像のサイズに戻すのか?
⇒ covolutionやpooling で落ちた解像度を元に戻す→Up-sampling
12.1 Up-sampling
covolutionやpooling で落ちる解像度を元に戻すことをUp-samplingという。
Up-samplingの壁、Up-samplingを如何に行うかが肝
無邪気な質問:Q.そもそもpoolingしなきゃいいのでは?
⇒ 正しく認識するためには受容野にある程度の大きさが必要。
受容野を広げる方法
① 深いcovolution層を用いる → 多層化に伴う演算、メモリの問題がある
② pooling and stride ⇒ 受容野を広げるために、poolingが必要。
12.2 Deconvolution(Transposed convolution)の処理手順
Up-samplingの手法の1つ
通常のcovolution層と同様にカーネルサイズ、パディング、ストライドを指定する
1.特徴マップのPixel感覚をstrideだけ空ける
2.特徴マップのまわりに(Kernel size -1) -paddingだけ余白を作る
3.畳み込み演算を行う。
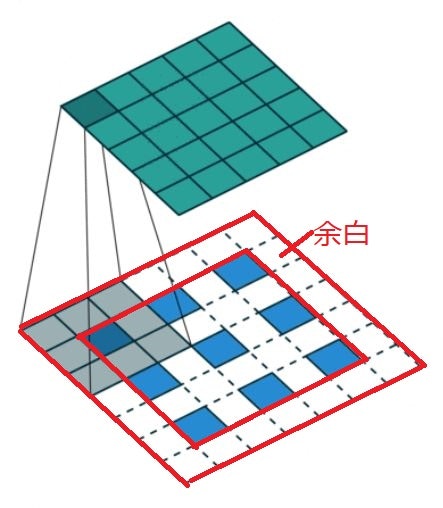
12.3 Dilated Convolution
poolingを用いずにConvolutionの段階で、受容野を広げられないか?
⇒ Convolutionの段階で受容野を広げる工夫がDilated Convolution
Dilated Convolutionはカーネルの隙間を開けることで、受容野を広げる