はじめまして,すばるたろです.
山田さんから書いてもいいと言われたので勝手にPEZY&ExaScalerスパコンシリーズの最強最大マシン暁光について書きます.
自己紹介
おまえだれやって思われると思うので自己紹介しておくと,学部生のときに分子シミュレーションをやる研究室配属されてスパコンさわってみたい!って言ったらほぼプログラム書いたことないのにCUDAの勉強から入って,学生時代はNVIDIAのGPUとかKNCとかPEZY-SCとかさわりつつ,いまはPEZY-SC2とかA64FXとかいじっておまんまたべてます.
あんまりMPIとかOpenMPとか得意ではないのでチップ単体の性能チューニングが専門ということになると思います.そういう意味ではスパコンを語るのは微妙ですかね?
実際に計算を流したことのあるスパコン歴はTSUBAME2.0,皐月,紫陽花,菖蒲システムB,暁光,国立天文台のXC50,富岳くらいです.アカウント持ってただけで使ってなかったのはOFPとか京とかもありますが.
暁光
さて,今日は私が人生で初めてグラチャレをしたマシンの暁光の紹介です(他にグラチャレしたマシンはないです).暁光はPEZY ComputingとExaScalerが開発したスパコンです.

(写真提供感謝!)
PEZYスパコンはこれまでに水槽一つ(か二つ)のスパコンでGreen500のトップ&上位をとってきましたが,満を持して作られ,2017/NovでTop500の4位に入った巨大スパコンです.この規模でもしっかりGreen500で5位(ちなみにTop3つもPEZYスパコン).すごい.もし今も残っていたら17位かなってことでこのタイトルになっています.
2017年12月から(全部)稼働して18年の4月まで稼働していたというとても寿命の短いスパコンです.短い生涯を閉じた理由はみなさんご存知(本当の詳細は私も知らないっちゃ知らないんだけど)だと思うのでここでは触れません.
寿命が決まったときからギリギリまでチューニングして計算を流したあの1ヶ月くらいは一生忘れないと思います.昼間は(半分以上は後輩氏が)論文書きながら,ひたすらカーネルチューニングして,深夜に他のひとが測定し終わって暁光使っていいよって言われたら朝まで格闘していました.スパコン業界のデスマって本当にあるんだなぁと思った春.
頑張って計算投げてたんだけどついぞフルノードでは計算流せませんでした.1万プロセスの壁は大きい(こんなしょぼいやつがこの記事書いていていいのか…)
ちなみに暁光では適当にログインしてジョブ投げるとかじゃなくて直接mpirunで計算ぶん投げてました.だめになってるPEZY-SC2のカードとかノードとかとか自分で探すんですが結構辛かった.
PEZY&ExaScalerのスパコンといえばまず液浸槽!
ブリックと呼ばれる複数のノードの集合体の板がフロリナートのお風呂に浸かっています.この冷却装置がGreen500のトップと上位をキープし続けたPEZY&ExaScalerのスパコン勢を縁の下で支えていたわけですね.
わたしは運悪く暁光を実際に見ることなく終わってしまったのですが,水槽を満たしているフロリナートは人体には無害というのを聞いて他のマシンを見学したときにぺろっとなめたりしました.とくに味もしないので感想はないです.汚いからやめたほうがいいよって若干引き気味に言われました.
体積あたりだとシャンパンくらい高い液体らしいけど水槽一つに安い焼酎のボトルみたいなのでどぼどぼ入れます.機械に油かけるのたのしい.揮発するから使ってるとたまに追加しないといけません.比重的にかなり重いので気軽に持とうとすると腰が逝くので気をつけような.温室効果的にはちょっとあれみたいです…
液浸スパコンといえば他にはTSUBAME-KFCなどがありますね.
耳にしただけなのでほんとか知りませんが,消防法をクリアする油の選定がめんどかったとか,計算回して温度が上がったら膨張して油が溢れちゃったとか,液浸するのにもいろいろ苦労がありそうな話を聞いています.Zettascalerシリーズ(暁光はこのシリーズの2.2)のこのへんの詳しい苦労話はあまり聞いたことがないのでだれか話してくれないかな…
この液浸槽が26個つながってできているのが暁光です.
ノードあたりXeon D-1571が一つにPEZY-SC2が8枚(!?),インターコネクトがInfiniband EDR1本という尖った構成でした.このノードが4個集まったのが1ブリックと呼ばれ,1つの水槽に12本このブリックが詰まっています.トータルで10000枚のPEZY-SC2が搭載されていました.
最近のNVIDIAのやつに比べると質素だけどムービーかっこいいのでみんな見てくれな.
https://youtu.be/_-z8ErBlBSo
Xeon Dに8個のPEZY-SC2がぶら下がっているというのはかなり大変で,PCIe Gen 3のx16に8個のPEZY-SC2がぶら下がっていて,データのやり取りには頭を悩ませられます.残りのx16はInfiniband.
さらにXeon Dが16コアのDDR4のデュアルチャネルですが,8個のコプロセッサを使うのに8プロセス2スレッド立ち上げてやるのでホストでなにかしていると基本的に間に合いません.ちょっとソートとか配列コピーとかしてると結構足を引っ張られる.
そして1つのPEZY-SC2に乗っているメモリが64GBで,ホストのメモリが32GBなので,ホストとコプロセッサの比率が普通と逆で,目一杯メモリを使い切ろうと思うとプログラムに工夫がいります.
使っているときの基本的な戦略としては遅いところだけとか言わずに全部PEZY-SC2にもっていこうね,という感じでした.
さて,私はあまりトータルのマシンについては多くを語れないので,
暁光の話はこのくらいにして使われているコプロセッサPEZY-SC2の話に入ります.
PEZY-SC2
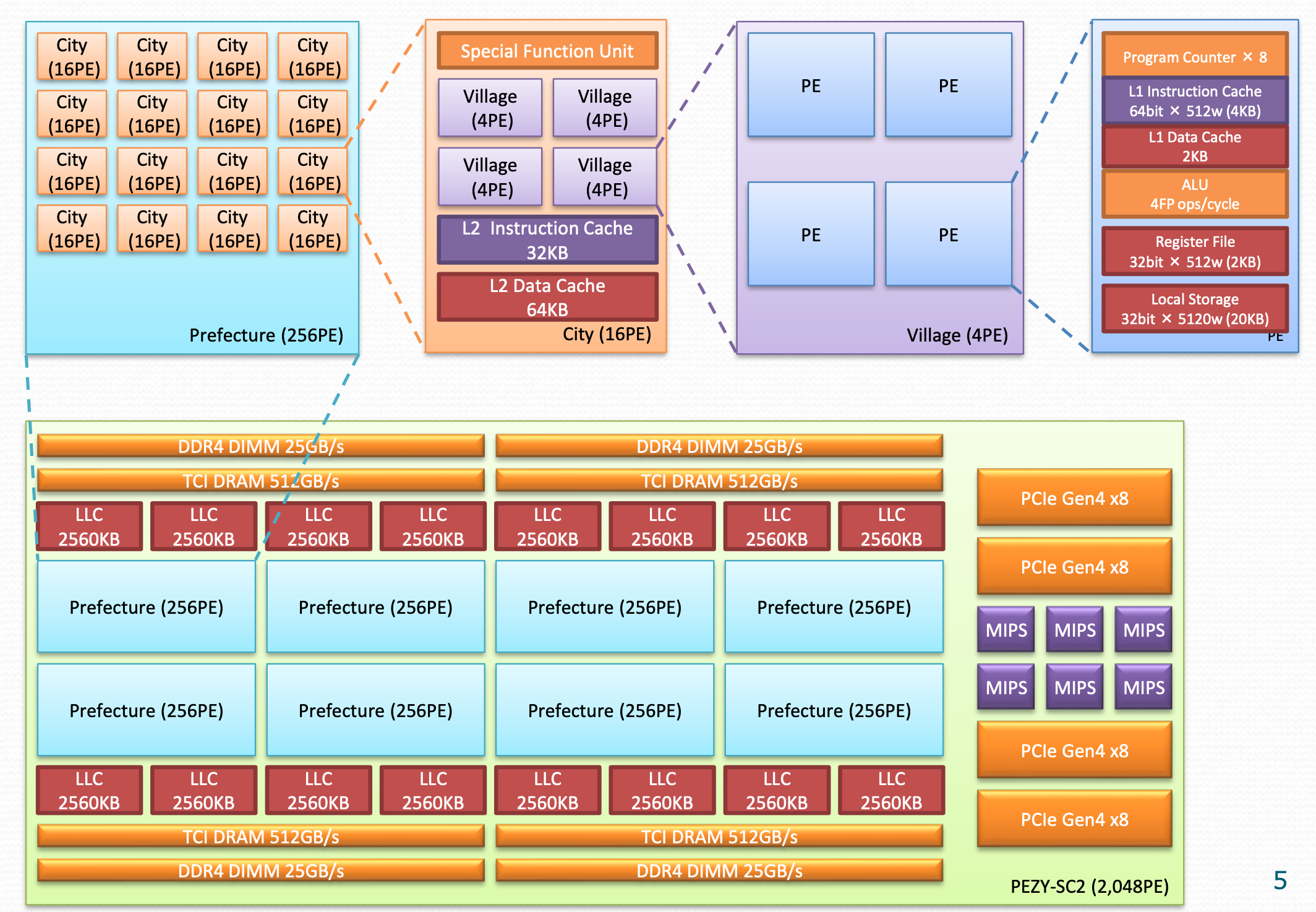
(https://www2.slideshare.net/RyoSakamoto/pezysc より)
PEZY-SC2は2048コアのMIMDマシン(たしか暁光のときは歩留まりの関係で1984コア)です.700 MHz駆動時で倍精度ピーク2.78 Tflops / 単精度ピーク5.56 TFlopsです.メモリはクアッドチャネルのDDR4です.B/F比でいうと京コンピュータの20分の1くらい.
Last Level / L2 / L1 の階層キャッシュで,キャッシュ間のコヒーレンシはユーザが管理するというちょっと変わったものです.コードの中で明示的にL1とかL2とかキャッシュのフラッシュなどを書きます.コアはグループ化されてますがプログラムするときもキャッシュの階層で考えるのでCityとPEの単位でしか考えたことないです.
PEごとにローカルメモリが結構あるのがとてもうれしいですね.重宝しました.
1つのコアに対して8個のスレッドが起動され,8個のスレッドは4個ずつで表と裏に分けられており,ロードストアや割り算,逆数平方根などのレイテンシの長い命令に到達したときなどに反転することで,そのレイテンシをうまく隠蔽することができます.いま取り組んでる某マシンにもほしい.
PEZY-SC2にはMIPSのコアも載っていて,通信などのマネージメントもしてくれる…はずだったのですが,私が暁光を使っていた頃はまだこの機能は使えませんでした.暁光がなくなったあとだと思いますがいろいろ試させてはもらいました.
あまり使い倒すことはできてないのでこれに関しては割愛.SC3ではこの辺がしっかりしてくるだろうからさらに使い勝手が上がりそう.
開発環境はOpenCL風のPZCLというものが用意されており,カーネルを書いてホストから起動して使うという意味では,CUDAでGPU使うのと労力的にほぼ違いはありません.CUDAより考えることは少ないかも.
単精度や半精度で到達できるピーク性能に近いものを出そうと思うとSIMD化しないといけませんが,キャッシュのフラッシュを入れたり,スレッドの反転する命令をいれる以外は特殊なことはなく,素直に書けます.
高みを目指して最適化するときは結局インラインアセンブラでがりがり書いてたけど.
ポエム要素
最近いろいろ別のマシンを使っていると思うのは,PEZY-SC2はインオーダで書いたとおりに命令が実行されていくこともあり,中で何が起きてるのかわかりやすくとても最適化しやすい石だったということです(石の気持ちがわかりやすい).
ちゃんとサイクルごとに2命令ずつ発行されて,どっかで変に待つことがないように命令を詰めていくとどんどん理想(目標)の性能に近づいていってくれた気がします.
石の使いやすさは,このくらいでるはずと思って頑張ってコード書いたら素直に性能がでる,これが一番大事なことだと私は思っています.その点が良いのでPEZY-SC2は今のところ私が一番好きな石です.
PEZY-SC(無印)も割とがんばって使いたおしたほうなのですが,SC2は2世代目だけあってとても使いやすくなっていました.チップ開発の積み重ねの大事さを感じますね.後継のPEZY-SC3を触ってみたかったな…いやまだこれからか.
おわりに
本稿では暁光およびPEZY-SC2について紹介させていただきました.
PEZY-SC2,私はとても好きなのでみなさんもさわってみてね.
PEZY-SC3の発表,心待ちにしています!