この記事は、フラー株式会社 Advent Calendar 2021 の 24 日目の記事です
23日目は @m-coderさんで 「Chromebookでも使えるアプリ」にする でした
稀によくおかしな表現が見受けられるかもしれませんが、ご容赦ください
■ 摩訶不思議なコンテナ船
「おい、地獄さ行ぐんだで!」
現在、アプリケーションの構築・実行環境の選択肢の一つとして**クラウド環境が白鯨のような圧倒的存在感もって位置していることは、経済合理性、開発者体験などの観点から多くの人が認める事実かと思います
こうした潮流は、CNCF(Cloud Native Computing Foundation)のような業界団体を成熟させる土台となり、相乗効果を生みながら、開発者にとっての当たり前開発**の軸足を大きくシフトさせる結果をもたらしています
- クラウドネイティブへの第一歩
開発者にとって**当たり前開発となりつつある、クラウド環境上でベンダーロックインされることなく、スケーラブルなアプリケーションを構築・実行するクラウドネイティブと総称される技術軸足
その軸足にシフトするためのロードマップの第一歩としてCNCFは下記に示されるようにコンテナ化**(Containerization)を提示しています

https://github.com/cncf/trailmap
第一歩に位置づけられるコンテナを用いた代表的な開発ライフサイクルとして
下記に簡略的に示すDocker社の**Build** Share Run のフロー図を一瞥しただけでスッと理解できる開発者は多いかと思います(たぶん)
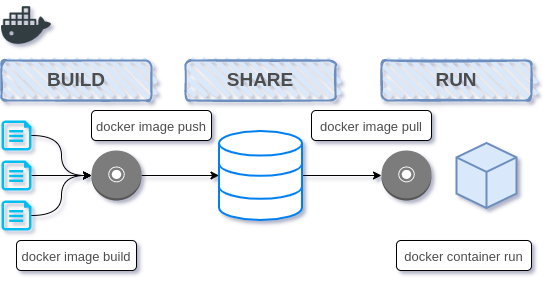
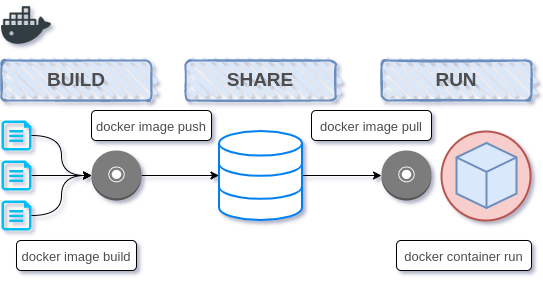
ところで私、このうちの赤丸箇所(コンテナ)
実はよく分かってないのでは?という哲学的問答に囚われてしまったため、遠洋航海することにしました
TL;DR
- 遠洋航海(コンテナ周辺技術の時系列整理)
- コンテナは制約付けられたリソースのもとに動作するプロセス
- コンテナはLinuxカーネル機能に依存
- 主要コンテナはchrootではなくpivot_rootに依存
- **seccomp(mode2)**しゅごい
- 低レベルランタイム(runc)どきどきウォッチング
- 俺でなきゃ見逃しちゃう名前空間の分離処理
- 遮二無二Init()
■ 歴史海の遠洋航海
静かに波を揺らしながら、少しずつ沖合に進んでいきたいと思います
- 1979年 chroot
Version7 UNIX における新機能としてchrootが登場しました
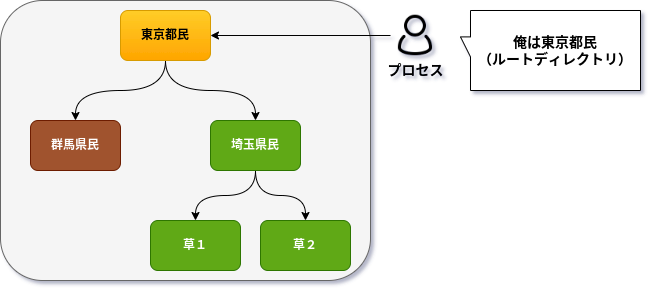
chrootは、特定プロセスが自己認識する「見かけ上のルートディレクトリ」を操作する機能を提供しています
誤解を恐れずにイメージ重視に表現をすると
「俺(プロセス)は名誉東京都民だ」と自己認識しているプロセスに「俺(プロセス)はそのへんの草でも食べていればよい埼玉県民だ...」と自己認識させることが可能な高等魔術です
-
chrootしていないプロセス
-
chrootしたプロセス
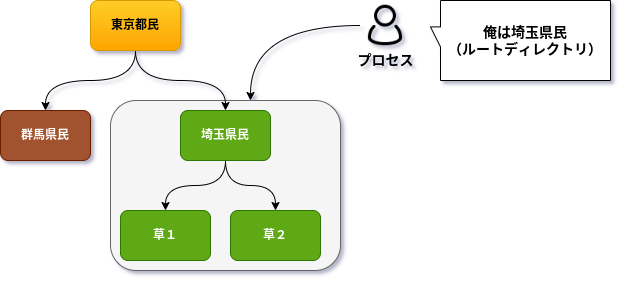
草しか勝たん
他方、実装重視で紐解くと
chrootはプロセスに紐づくタスク構造体 task_struct が保有するファイルシステム情報 fs_struct のルートディレクトリ情報(東京都民 or 埼玉県民)を書き換えます
下記にtorvalds/linux v5.16-rc4時点におけるchroot実装を示します
SYSCALL_DEFINE1(chroot, const char __user *, filename)
{
struct path path;
int error;
unsigned int lookup_flags = LOOKUP_FOLLOW | LOOKUP_DIRECTORY;
retry:
error = user_path_at(AT_FDCWD, filename, lookup_flags, &path);
if (error)
goto out;
error = path_permission(&path, MAY_EXEC | MAY_CHDIR);
if (error)
goto dput_and_out;
error = -EPERM;
if (!ns_capable(current_user_ns(), CAP_SYS_CHROOT))
goto dput_and_out;
error = security_path_chroot(&path);
if (error)
goto dput_and_out;
set_fs_root(current->fs, &path);
error = 0;
dput_and_out:
path_put(&path);
if (retry_estale(error, lookup_flags)) {
lookup_flags |= LOOKUP_REVAL;
goto retry;
}
out:
return error;
}
上記chrootの処理単位のうち
要所はset_fs_root(current->fs, &path);で指示されている命令です
set_fs_root(current->fs, &path);は
指定プロセスが保有するファイルシステムのルートディレクトリ情報を第二引数で指定したパス情報に書き換えています
下記に見るところのfs->root = *path;が埼玉県民にされている箇所です
/*
* Replace the fs->{rootmnt,root} with {mnt,dentry}. Put the old values.
* It can block.
*/
void set_fs_root(struct fs_struct *fs, const struct path *path)
{
struct path old_root;
path_get(path);
spin_lock(&fs->lock);
write_seqcount_begin(&fs->seq);
old_root = fs->root;
fs->root = *path; //そのへんの草でも喰っていなさい
write_seqcount_end(&fs->seq);
spin_unlock(&fs->lock);
if (old_root.dentry)
path_put(&old_root);
}
しかし、ここで朗報があります
特定の条件を満たす場合に、埼玉県民から抜け出すことができます
詳しくは下記をご参照ください
chroot の問題点
とはいえ、管理者の立場から言えば、埼玉県民であると自己認識をさせたプロセスが自発的に東京都民であると脱埼玉するのは由々しき事態です
そのため、Dockerに代表される現在の主要なコンテナではchrootを使用していません
もっと強力に埼玉県民化させる仕組みが必要です
出港して間もない現段階において、一部界隈のうねる激情の荒波をひしと感じます
※ 教育的資材としてご容赦ください
- 2000年 pivot_root
Linux2.3.41 においてpivot_rootシステムコールが追加されました
pivot_rootは特定マウント名前空間に紐づくプロセスの「ルートファイルシステムそのもの」を入れ替える機能を提供しています
誤解を恐れずにイメージ重視に表現をすると
chrootにおいては提供していなかった、もっと強力に埼玉県民化させる(脱埼玉するという概念がそもそも存在しえない)機能です
(イメージ図は自重させていただきます)
他方、実装重視で紐解くと
pivot_rootは特定条件の組み合わせを満たすことを確認したのちにattach_mntを呼び出してルートフィルシステムの入れ替えをしています
下記にtorvalds/linux v5.16-rc4時点におけるpivot_root実装を示します
SYSCALL_DEFINE2(pivot_root, const char __user *, new_root,
const char __user *, put_old)
{
struct path new, old, root;
struct mount *new_mnt, *root_mnt, *old_mnt, *root_parent, *ex_parent;
struct mountpoint *old_mp, *root_mp;
int error;
if (!may_mount())
return -EPERM;
error = user_path_at(AT_FDCWD, new_root,
LOOKUP_FOLLOW | LOOKUP_DIRECTORY, &new);
if (error)
goto out0;
error = user_path_at(AT_FDCWD, put_old,
LOOKUP_FOLLOW | LOOKUP_DIRECTORY, &old);
if (error)
goto out1;
error = security_sb_pivotroot(&old, &new);
if (error)
goto out2;
get_fs_root(current->fs, &root);
old_mp = lock_mount(&old);
error = PTR_ERR(old_mp);
if (IS_ERR(old_mp))
goto out3;
error = -EINVAL;
new_mnt = real_mount(new.mnt);
root_mnt = real_mount(root.mnt);
old_mnt = real_mount(old.mnt);
ex_parent = new_mnt->mnt_parent;
root_parent = root_mnt->mnt_parent;
if (IS_MNT_SHARED(old_mnt) ||
IS_MNT_SHARED(ex_parent) ||
IS_MNT_SHARED(root_parent))
goto out4;
if (!check_mnt(root_mnt) || !check_mnt(new_mnt))
goto out4;
if (new_mnt->mnt.mnt_flags & MNT_LOCKED)
goto out4;
error = -ENOENT;
if (d_unlinked(new.dentry))
goto out4;
error = -EBUSY;
if (new_mnt == root_mnt || old_mnt == root_mnt)
goto out4; /* loop, on the same file system */
error = -EINVAL;
if (root.mnt->mnt_root != root.dentry)
goto out4; /* not a mountpoint */
if (!mnt_has_parent(root_mnt))
goto out4; /* not attached */
if (new.mnt->mnt_root != new.dentry)
goto out4; /* not a mountpoint */
if (!mnt_has_parent(new_mnt))
goto out4; /* not attached */
/* make sure we can reach put_old from new_root */
if (!is_path_reachable(old_mnt, old.dentry, &new))
goto out4;
/* make certain new is below the root */
if (!is_path_reachable(new_mnt, new.dentry, &root))
goto out4;
lock_mount_hash();
umount_mnt(new_mnt);
root_mp = unhash_mnt(root_mnt); /* we'll need its mountpoint */
if (root_mnt->mnt.mnt_flags & MNT_LOCKED) {
new_mnt->mnt.mnt_flags |= MNT_LOCKED;
root_mnt->mnt.mnt_flags &= ~MNT_LOCKED;
}
/* mount old root on put_old */
attach_mnt(root_mnt, old_mnt, old_mp);
/* mount new_root on / */
attach_mnt(new_mnt, root_parent, root_mp);
mnt_add_count(root_parent, -1);
touch_mnt_namespace(current->nsproxy->mnt_ns);
/* A moved mount should not expire automatically */
list_del_init(&new_mnt->mnt_expire);
put_mountpoint(root_mp);
unlock_mount_hash();
chroot_fs_refs(&root, &new);
error = 0;
out4:
unlock_mount(old_mp);
if (!error)
mntput_no_expire(ex_parent);
out3:
path_put(&root);
out2:
path_put(&old);
out1:
path_put(&new);
out0:
return error;
}
カーネルコードの難解さに圧倒されてしまいそうになりますが
ここにおいて重要なのは「(新しいファイルシステムからは)抜け出せない」という制約を課すことができるようになった点です
- 2001年 bind mount
Linux2.4.0 においてbind mountシステムコールが追加されました
bind mountはディレクトリツリーの一部を別のディレクトリー以下にマウントし、同一コンテンツに対して異なる場所からアクセス可能にする機能を提供しています
もう随分と沖合に出てきたため、埼玉県民の存在を感じることが難しくなってきました
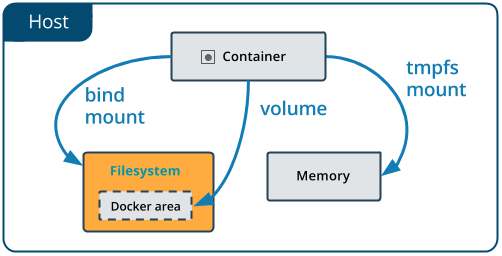
そこで、bind mountのイメージ理解のためには、Dockerドキュメントを参照することにしましょう
バインドマウントを利用すると「ホストマシン」上のファイルやディレクトリがコンテナー内にマウントされます。 そのファイルやディレクトリは、ホストマシン上の絶対パスにより参照できます。
https://matsuand.github.io/docs.docker.jp.onthefly/storage/bind-mounts/
- 2002年 mount namespace
Linux2.4.19においてMount Namaspace機能が追加されました
Mount Namespaceはマウントポイントを分離する機能を提供しています
マウント名前空間を用いると、異なるマウント名前空間に属するプロセス間において、他のプロセス上で行われたマウント操作が見えない分離状態を作ることができます
「異なるマウント名前空間をもつプロセスのマウント状態は、他のプロセスには反映されない」ことのデモとして、下記に示す記事が分かりよいです
※ 特に「まとめ」に入る前のマウント名前空間のイメージ図が理解を助けてくれます
- 2006〜2008年 名前空間の充実
このあたりで現在のコンテナ技術が依存している主要な名前空間が揃いました
- Linux2.6.19
UTS Namespace- ホスト名をホストと別にできる
- Linux2.6.19
IPC Namespace- IPCをホストと分離することでメッセージキューなどの利用を制限できる
- Linux2.6.24
PID Namespace- プロセスを分離することで、ホストのプロセスを操作することを制限できる
- Linux2.6.24
Network Namespace- ネットワークを分離して、コンテナ間のネットワークを作ることができる
※ User Namespaceはこの段階ではまだ追加されておらず Linux3.8(2013年)までおあずけです
また、コンテナ用の仮想インタフェース機能(veth)が追加されたのもこのあたりですね
- 2008〜2012年 cgroups
このあたりでcgroups(コントロールグループ)機能が登場(Linux2.6.24)、充実します
cgroupsはシステムリソースの割当て、優先度設定、拒否、管理、モニタリングに対して細かな粒度で制御をする機能を提供しています
下記にCentOS8環境(byebye...)におけるコントローラ例を示します
# lssubsys -am
cpuset /sys/fs/cgroup/cpuset
cpu,cpuacct /sys/fs/cgroup/cpu,cpuacct
blkio /sys/fs/cgroup/blkio
memory /sys/fs/cgroup/memory
devices /sys/fs/cgroup/devices
freezer /sys/fs/cgroup/freezer
net_cls,net_prio /sys/fs/cgroup/net_cls,net_prio
perf_event /sys/fs/cgroup/perf_event
hugetlb /sys/fs/cgroup/hugetlb
pids /sys/fs/cgroup/pids
rdma /sys/fs/cgroup/rdma
- 2013年 Docker元年
Dockerが登場します(どーん)
PyCon で Solomon Hykes さんが発表しました
当時のDockerは、使いづらいことで評判のLXCをラップして イイ感じに インタフェースを提供するソリューションとして、コンテナ界隈の活性化を強く促進する存在となりました
chrootが登場した1979年から考えると、随分と沖合に出てからDockerが登場していることが分かりますね
- 2014年以降
続々とセキュリティ強化支援機能が追加されていきます
-
seccomp- システムコールとその引数の制限
-
capability- 権限の削ぎ落とし
User Namespace-
LSM(Linux Security Module)- SELinux, AppArmor
- MAC(Mandatory Access Control)
また、コンテナにおけるイメージを支える要素技術であるユニオンファイルシステムのOverlayFSはLinux3.18(2014年)に機能追加されています
- 現在
なんかいろいろしゅごい
上記(=しゅごい)に加えて、Linuxカーネル機能に大きく依存していることの裏付けを理解できれば十分かと思います
■ 主要技術への釣り針
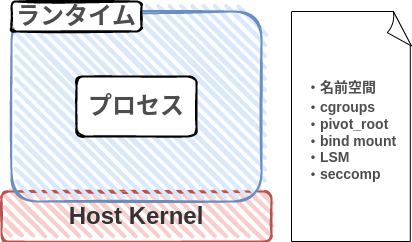
遠洋航海日誌を簡略にまとめると
コンテナを支える主たる要素技術セットは下記メモあたりであると言えそうです(たぶん)
seccomp
主要技術のなかから、セキュリティ的に熱いという理由でseccompを取り上げます(どの要素技術も重要ではありますが)
もりたこさんの資料をご参照ください(神では?)
上記を通読して理解できれば seccomp 関連のコンテキストとしては十分かと思います
■ 海底探索〜低レベルランタイムのお仕事ウォッチング〜
埼玉の薫香に鼻をうごめかし、えいやえいやと続けた遠洋航海
知的探究心や憎悪の荒波にもまれながらもコンテナ要素技術の概要をさらってきました
では実のところ、これらの要素技術を用いてコンテナを作成している、つまり、ホストから分離されたプロセスを作成するにあたり、背景にはどのような登場人物が存在しており、どのような役割を遂行しているのでしょうか
それらを整理するに際して、まずは「高レベル(レイヤ)ランタイム」と「低レベル(レイヤ)ランタイム」の存在を認識する必要があります
その理解のためには、下記資料が参考になります(神では?)
日本の八百万の神の霊圧をこうした神資料から感じ取ることができます
簡単に整理付けると、それぞれ下記のような役割を担っていると言えます
-
高レベル(レイヤ)ランタイム
- コンテナ、イメージ、ネットワーク等の全般的な管理を行う
-
低レベル(レイヤ)ランタイム
- ホスト環境から分離した実行環境をコンテナとして生成し、操作可能にする
つまり、ホストから分離されたプロセス(コンテナ)を作成しているのは低レベルランタイムです
そこで低レベルランタイムの一つであるruncが実際に行っている初期化処理を眺めてみることにしましょう
runcが環境隔離のために行う初期化処理を追跡するために、下記init.goを入り口とします
package main
import (
"os"
"runtime"
"strconv"
"github.com/opencontainers/runc/libcontainer"
_ "github.com/opencontainers/runc/libcontainer/nsenter"
"github.com/sirupsen/logrus"
)
func init() {
if len(os.Args) > 1 && os.Args[1] == "init" {
// This is the golang entry point for runc init, executed
// before main() but after libcontainer/nsenter's nsexec().
runtime.GOMAXPROCS(1)
runtime.LockOSThread()
level, err := strconv.Atoi(os.Getenv("_LIBCONTAINER_LOGLEVEL"))
if err != nil {
panic(err)
}
logPipeFd, err := strconv.Atoi(os.Getenv("_LIBCONTAINER_LOGPIPE"))
if err != nil {
panic(err)
}
logrus.SetLevel(logrus.Level(level))
logrus.SetOutput(os.NewFile(uintptr(logPipeFd), "logpipe"))
logrus.SetFormatter(new(logrus.JSONFormatter))
logrus.Debug("child process in init()")
factory, _ := libcontainer.New("")
if err := factory.StartInitialization(); err != nil {
// as the error is sent back to the parent there is no need to log
// or write it to stderr because the parent process will handle this
os.Exit(1)
}
panic("libcontainer: container init failed to exec")
}
}
実はここにおいて既に名前空間の隔離処理が行われています
なにげなくブランクインポートされている下記一文によって、cgo(go言語からc言語の機能を利用する)によるC言語処理を実行し、名前空間の隔離をしています
_ "github.com/opencontainers/runc/libcontainer/nsenter"
//go:build linux && !gccgo
// +build linux,!gccgo
package nsenter
/*
# cgo CFLAGS: -Wall
extern void nsexec();
void __attribute__((constructor)) init(void) {
nsexec();
}
*/
import "C"
出会って5秒でバトルどころの話ではない神速名前空間隔離作業着手です(超絶初見殺しといっても過言ではありません)
気を取り直してinit.goに戻り、次にfactory.StartInitialization()にダイブしてみます
// StartInitialization loads a container by opening the pipe fd from the parent to read the configuration and state
// This is a low level implementation detail of the reexec and should not be consumed externally
func (l *LinuxFactory) StartInitialization() (err error) {
// Get the INITPIPE.
envInitPipe := os.Getenv("_LIBCONTAINER_INITPIPE")
pipefd, err := strconv.Atoi(envInitPipe)
if err != nil {
err = fmt.Errorf("unable to convert _LIBCONTAINER_INITPIPE: %w", err)
logrus.Error(err)
return err
}
pipe := os.NewFile(uintptr(pipefd), "pipe")
defer pipe.Close()
... 略
i, err := newContainerInit(it, pipe, consoleSocket, fifofd, logPipeFd, mountFds)
if err != nil {
return err
}
// If Init succeeds, syscall.Exec will not return, hence none of the defers will be called.
return i.Init()
}
下記においてコンテナ初期化のための構造体を生成しています
newContainerInit(it, pipe, consoleSocket, fifofd, logPipeFd, mountFds)
そして、初期化のための構造体をレシーバーとしてInit()メソッドを呼び出し、コンテナプロセスの初期化を行っています
このInit()こそが、分離されたプロセスを生み出すために遮二無二働いている箇所です(名前空間は言語仕様上cgo機能を利用していますが)
つまり、ワンピースで言うところのひとつなぎの大秘宝は下記に埋蔵されているということです
詳細に興味のある方は、是非、大航海時代のうねりに身を任せダイブしてみてください(解説に疲れた)
■ まとめ
chroot(1979年)から航海を始めてもう随分と沖合に出てしまいましたが、帰路の燃料はありません
ここはもう引き返せない海域です
あとはお好きに心の羅針盤に従って航海なさってください
(あれ、群馬に触れていないな ... ? まあ、あそこは秘境なので ... )
次は、フラー株式会社 Advent Calendar 2021 の 25 日目
okuzawatsさんで GitHub ActionsでAndroid Room / Realmの自動テスト です
■ リファレンス
- https://www.pref.saitama.lg.jp/
- https://sourcegraph.com/github.com/util-linux/util-linux@master
- https://sourcegraph.com/github.com/torvalds/linux@master
- https://sourcegraph.com/github.com/opencontainers/runc
- https://github.com/cncf/trailmap/blob/master/README.md
- https://linuxjm.osdn.jp/html/LDP_man-pages/man2/pivot_root.2.html
- https://linuxjm.osdn.jp/html/LDP_man-pages/man2/chroot.2.html
- https://linuxjm.osdn.jp/html/util-linux/man8/mount.8.html
- https://man7.org/linux/man-pages/man7/cgroups.7.html
- https://docs.docker.com/storage/bind-mounts/
- https://access.redhat.com/documentation/ja-jp/red_hat_enterprise_linux/6/html/resource_management_guide/ch01
- https://container-security.dev/
- https://gihyo.jp/magazine/SD/archive/2021/202112
- https://medium.com/nttlabs/runc-overview-263b83164c98
- https://eh-career.com/engineerhub/entry/2019/02/05/103000#%E3%82%B3%E3%83%B3%E3%83%86%E3%83%8A%E3%82%92%E4%BD%9C%E3%82%8B
- https://speakerdeck.com/tenforward/cndt2019
- https://tenforward.hatenablog.com/entry/2020/06/21/232558