NLPモデル版CheckListの提案。バグが早期に見つけられるようになる..??
0.はじめに
この記事はMicrosoft ResearchのMarco Tulio Ribeiro他によるBeyond Accuracy: Behavioral Testing of NLP Models with CheckList(ACL 2020 のベストペーパー)とそのgithubを一部試した内容について書いてみました。
この論文ではNLPタスクのデバッグ用CheckListを提案しています。
CheckListの一部を使用すると、経験の少ないユーザーがわずか2時間でSOTA1モデルの重大なバグを見つけることができる効果があったようです。
またこのCheckListはブラックボックスな商用モデル2の比較(どのクラウドサービス使おうかな)にも使えます。
以下の順番で説明します。
1. CheckListの簡単な紹介
2. githubを動かして日本語版のCheckList用の文章が生成できそうか(google colab利用)
3. 所感
1.CheckListの簡単な紹介
実はSansanの高橋さんが書かれたブログ【Techの道も一歩から】第33回「文献紹介:Beyond Accuracy: Behavioral Testing of NLP Models with CheckList」で丁寧に解説されているので、ざっくりと説明します。
CheckListの種類は3種類です。
1.1 Minimum Functionality test(MFT,最小機能テスト)
穴埋めの文章のように、部分的に単語が抜けたテンプレートを用意し、単語を色々変えて正しく予測できるかを確認します。
具体的に以下の極性判定で用いた場合の例を見るとわかりやすいです。

テンプレートは***I {NEGATION} {POS_VERB} the {THING}.***で、
- {NEGATION} = {"can't",didn't}
- {POS_VERB} = {"say I recommend","love"}
- {THING} = {"food","flight"}
の単語をそれぞれ挿入しています。本来negativeと判定して欲しいところを予測ではpos,neutralと
間違えています。
1.2 Invariance test(INV,不変性テスト)
タイプミスや、単語の一部(地名などの固有表現抽出)の入れ替えや追加を行っても推論結果が変わらないかを確認します。
以下具体例です。

1文目ではChicagoからDallasに変更した結果、posからneutralに推論結果の極性が変わってしまった例です。
1.3 Directional Expectation test(DIR,方向性期待テスト)
INVと似ていますが、期待するような結果を出力するかを確認します。
negativeな文章に否定的な文章を加えてもnegativeと推測するかや、neutralの単語の前に否定形(not)があってもneutralのままか、などを確認します。
以下、具体例です。
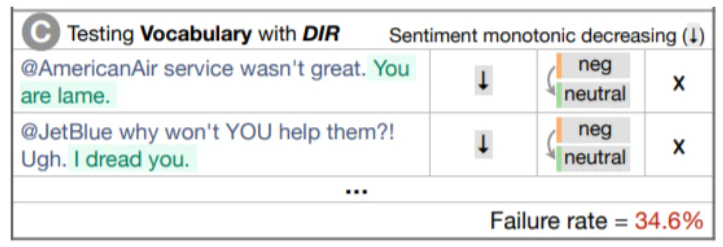
1文目はAmericanAir service wasn't great.がnegativeな文章です。それにYou are lame.(あなたは時代遅れだ。)を追加するとneutralと極性が変わり誤判定をするようになってしまいました。
2.githubを動かして日本語版のCheckList用の文章が生成できそうか(google colab利用)
冷静に考えると、CheckList用の文章を用意するのは結構大変です。
この論文のgithubを見てみると、RoBERTaを用いた文章生成をサジェストしてくれそうです。

更に読み進めるとMultilingual suggestionsとして、ポルトガル語の事例が載っています。
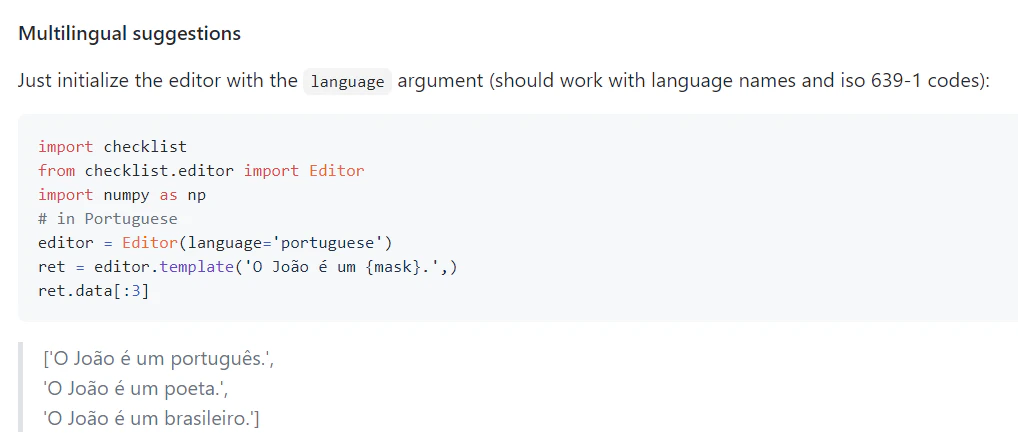
これは・・・ 日本語版の文章も文章生成してくれるのでは・・・(三点リーダー症候群)
2.1 日本語版のsuggestion検証
google colablatoryを用いて検証をしてみました。
インストールはgithubの通りに実行すればできました。
-
例1)
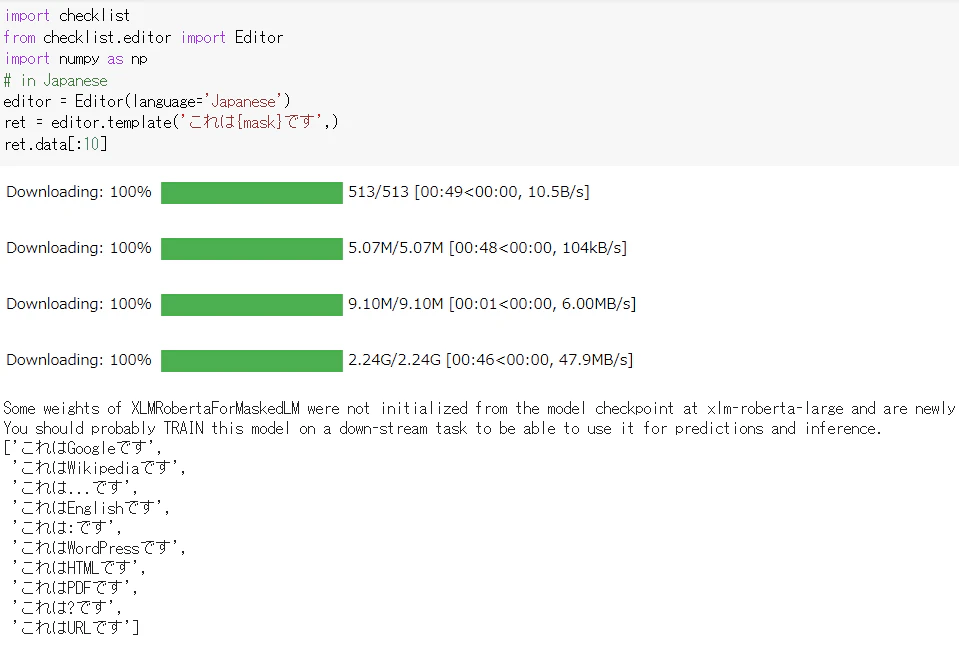
こ、これは...
-
例2)

こ、こいつは...微妙そうだ...
ちなみに、マルチリンガルのレキシコン(語彙)を利用して英語文の中で指定した国特有の人名や国名を挿入することもできるようです。
以下はgithubでgermanを選択した例です。

こういう事例を見ると、日本語版を試したくなります。
-
例3)
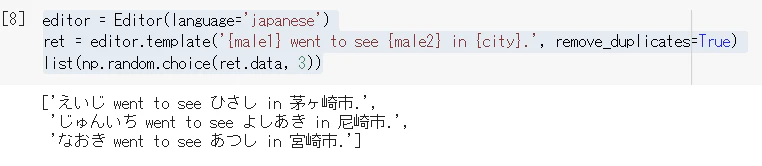
男性名や地名のバリエーションを増やす時に利用できるかも。
-
例4)

女性名も違和感のない名前が生成される。
3.所感
日本語の文章生成の結果はやや微妙でしたが、CheckListにより、
- ベンチマークをしてどのクラウドサービスを使うか判断材料の一つになる。
- 学習モデルの弱点に早めに気づける
などのメリットがあると感じました。
論文中には、文章の最後にURL http://...や@...を追加したとたん誤判定になる事例や、
性別や人種に関するバイアスにも触れており興味深かったです(詳細はぜひ元論文を読んでください)。
※誤った記述があればご指摘頂けると嬉しいです!
-参考文献 -
ありがとうございました!
- 元論文:"Beyond Accuracy: Behavioral Testing of NLP Models with CheckList"
- [CheckListのgithub](https://github.com/marcotcr/checklist
- 【Techの道も一歩から】第33回「文献紹介:Beyond Accuracy: Behavioral Testing of NLP Models with CheckList」