spacy_streamlitとは
streamlitはpythonの数行のコードでウェブアプリが作れる最近注目度急上昇中のライブラリである。
そしてspacyはpython上で色々試せる自然言語処理ライブラリである。
そのstreamlitとspacyが手を組んだだと・・
それが、spacy_streamlitである(あまり説明になっていない)。

基本的にはspacy_streamlitのgithub上のQuickstartに書かれていることと変わりないが、Quickstartは英語版のモデルを利用しているので、日本語版のモデルでも動作するか確認した。
※なお、以下の試したソースコードはここに置いた。
インストールなど
※今回の実行環境は、windows10(64bit)で実施。
spacy-streamlitのインストール
pip install spacy-streamlit --pre
spacyの日本語モデルのダウンロード
spacyには3種類の日本語モデル(ja_core_news_sm, ja_core_news_md, ja_core_news_lg)が
公開されているが、軽く試したかったので今回はja_core_news_sm,ja_core_news_mdの二つをダウンロードした。
python -m spacy download ja_core_news_sm
python -m spacy download ja_core_news_md
コード(実質4行)
以下コードをjapanese_spacy_streamlit_sample.pyとして保存。
import spacy_streamlit
models = ["ja_core_news_md", "ja_core_news_sm"]
default_text = "もうすぐ梅雨。日本のオリンピックはどうなる?"
spacy_streamlit.visualize(models, default_text)
・・以上。
早速以下コマンドを実行してみる。
streamlit run japanese_spacy_streamlit_sample.py
以下のようなウェブ画面が表示されれば成功である。
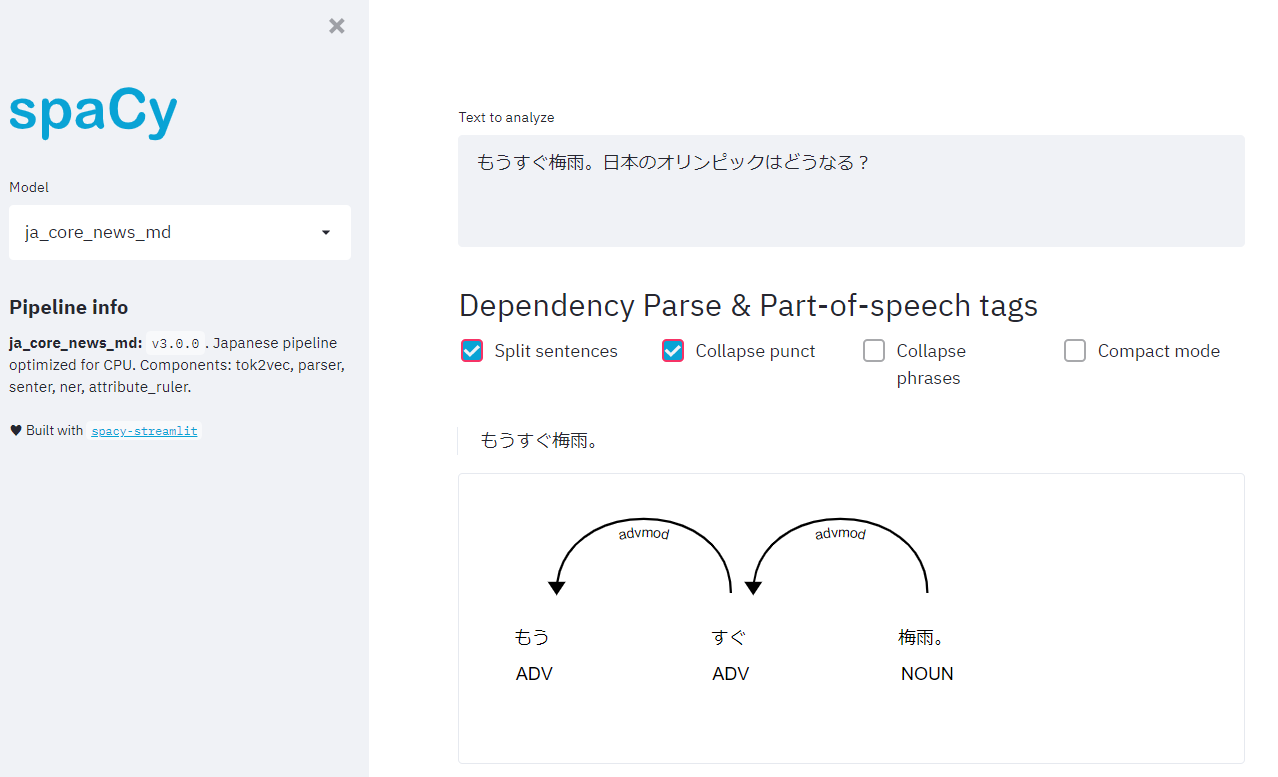
上記画面のように、Split sentencesにデフォルトでチェックが入っているので、文章毎に係り受け解析を可視化してくれる。
- ちなみに「日本のオリンピックはどうなる?」の係り受け結果はこちら。
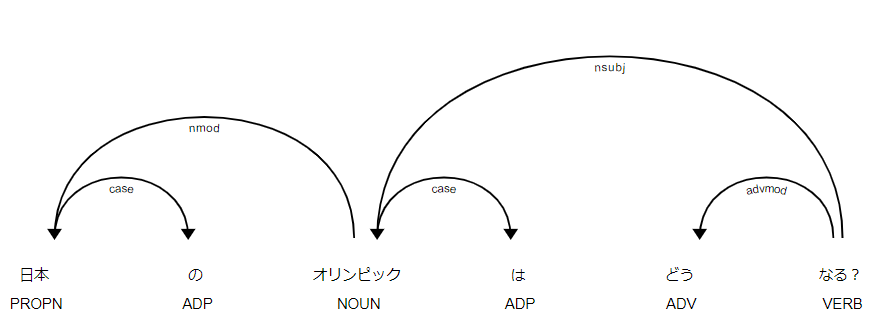
もちろん、ウェブアプリなので、Text to analyze上に別の文章を入力すると、入力した文章の係り受け結果を表示してくれる。
他にも
幾つかの結果を可視化してくれる。
※Text Classificationはspacyを理解しないと表示できなそうなので今後確認したい。
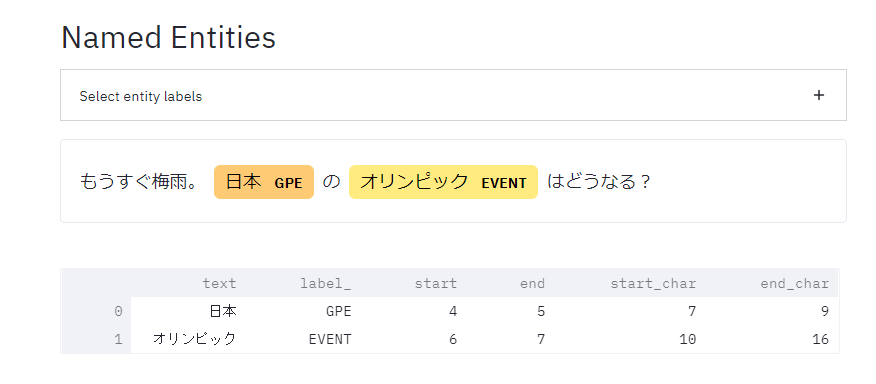
Named Entities(固有表現)
オリンピックがちゃんとイベントとして認識されている。
※GPE: Geopolitical entity, i.e. countries, cities, states.
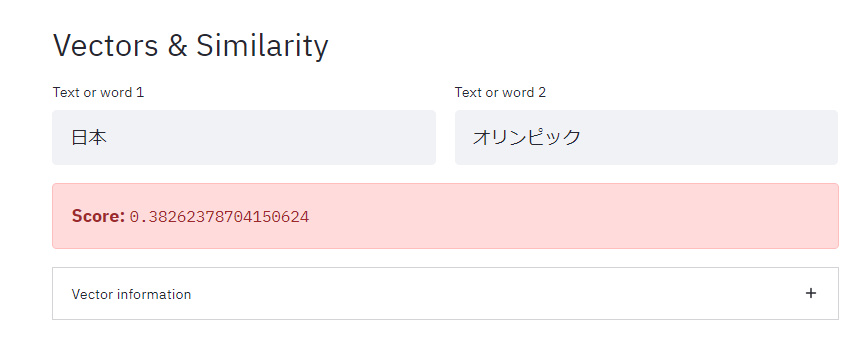
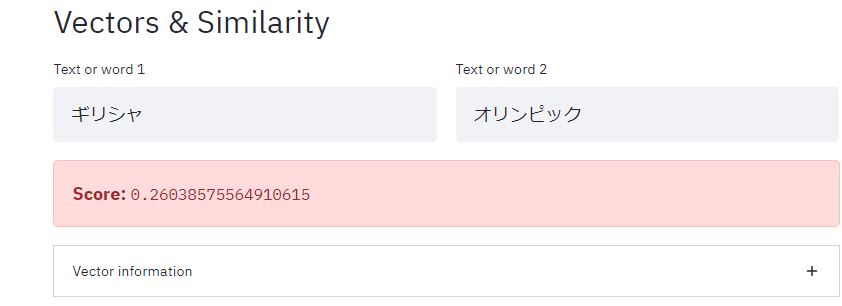
Vectors & Similarity(単語類似度)
※1 デフォルトは"apple"と"orange"が入力されている。
※2 以下はspacyのja_core_news_mdモデルの結果を表示。
「日本」と「オリンピック」の単語の類似度の方が、「ギリシャ」と「オリンピック」の類似度より高い、ということを発見したりする。
Token attributes(トークンの属性)

所感
どんな結果が出るのか試しに見たい時に、ウェブ画面上で文章や単語を入れると可視化してくれるので非常に便利で楽しい。
参考
- spacy_streamlit:https://github.com/explosion/spacy-streamlit
- spacy:https://spacy.io/models/ja
- streamlit:https://streamlit.io/