はじめに
いつも話しているアノ人はもしかしたら「人」ではなく「化身」かも・・。
CLIP(Contrastive Language-Image Pre-Training) とは
冗談はさておき、本題のCLIPについて。
※想定よりも長い記事になったので、CLIP説明編、CLIP動作確認編に分けることにしました。
違和感の少ない文章生成を行うGPT3や自然文で指示すると画像を生成するDALL·Eなど、
腰を抜かすような発表を立て続けに行うOpenAIが2021年に発表した事前学習モデルが、CLIPです。
(論文:Learning Transferable Visual Models From Natural Language Supervision)
この提案手法のポイントは、インターネットから集めた4億もの画像とテキストをペアとした事前学習モデルである点です。
提案手法のサマリーは以下の通りです。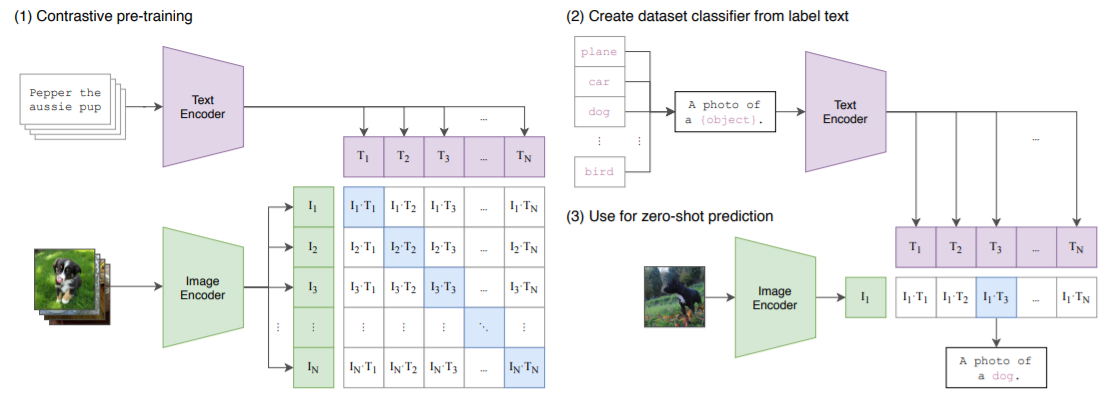
手順は大きく3種類。
1.Cotrastive pre-training
インターネットから収集した4億の画像とテキストのペアを用いて学習を行います。
テキストはTransfomerを用いてText Encoder、画像はResNet-50, Vision Transformer(ViT)を用いてImage Encoderを学習。
Image embeddingsとText embeddingのコサイン類似度が最大となるようなText encoder, Image Encoderを学習することで、multi-modal embedding spaceを習得します。
つまり、画像に最適なキャプションを選定するような事前学習モデルと言えます。
この部分がCLIPの核です。
論文中に記載されている疑似コード↓はイメージが湧きやすいです。

2.Create dataset classifier from label text
文章分類を行いたいラベルを全て、キャプションに変換(例:ラベル名を"A photo of a {object}"のようなキャプションに変更するため {"object"}にラベル名を挿入)し、1でpre-trainしたText Encoderに通し、Text embeddingを出力します。
3.Use for zero-shot prediction
予測を行いたい画像を1でpre-trainしたImage Encoderに通し、Image embeddingを出力します。
このImage embeddingsと最もコサイン類似度が近くなるようなText embeddingsを2の中から選びだすことで、zero-shotを可能にしています。
CLIPの性能・弱点
性能について
論文中に27種類のデータセットを使って、ResNet-50と精度比較を行っています。
(他にも論文では色んな検証を行ってますが、すいません、全部は理解できていません・・)
27データセット中、ImageNetなど16のデータセットで性能を上回ったと記述されています。
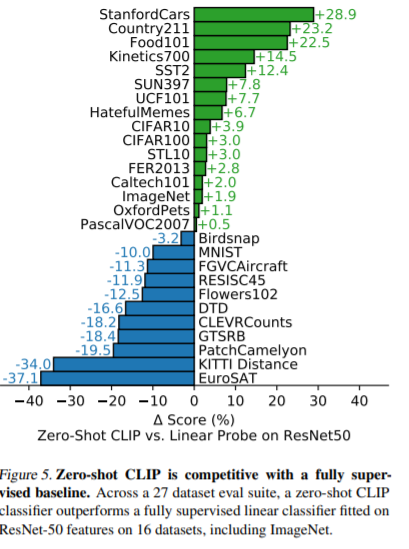
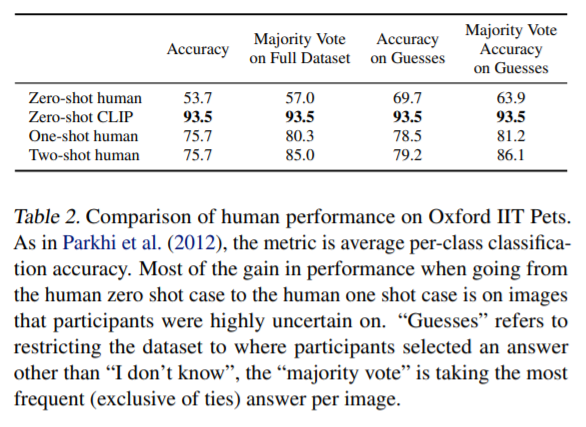
個人的に面白かったのが人との性能評価です。
The Oxford-IIIT Petという37カテゴリのペットのデータセットを用いて、人が一度も画像を見なかった場合(Zero-shot human)、一度見た場合(One-shot human)、二度見た場合(Two-shot human)と比較し、CLIPが最も精度が高い結果となっています。
更に更にペットデータセットのカテゴリを横軸に並べた結果が↓です。
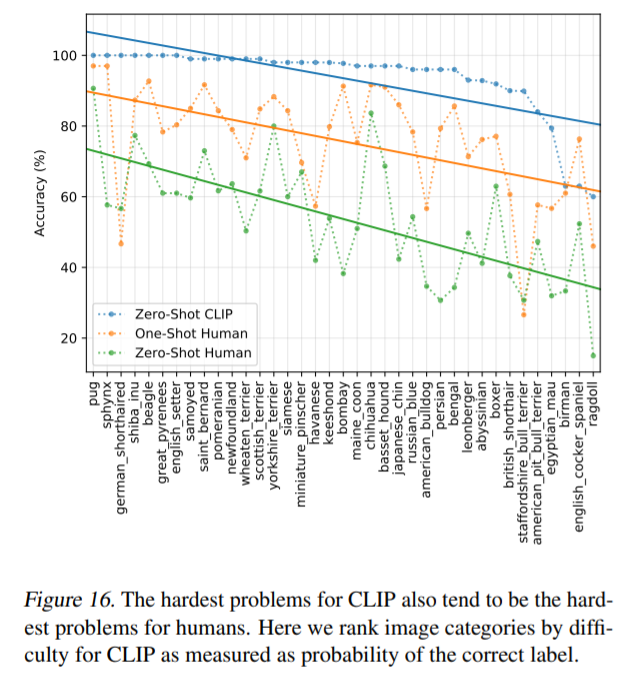
人とCLIPの精度の傾向が似ています。
つまり、人が見分けることが困難なカテゴリは、CLIPにとってもしんどいと言えます。
一番右端のカテゴリの「ragdoll」、どんなペットなのかわからなかったのでcreative commonsの画像検索サイトで探してみました。

なるほど、この猫ちゃんが「ragdoll」でしたか。
最後:弱点について
前述で27データセット中16でCLIPはResNet-50よりも精度を上回ったと記載しましたが、
まだまだ最先端の手法の精度には到達していません。
論文の6節 Limitationsに記載されていますが、
(中略)we estimate around a 1000x increase in compute is required for zero-shot CLIP to reach overall
state-of-the-art performance. This is infeasible to train with current hardware.
(DeepL翻訳) ゼロショットCLIPが全体的に最先端の性能に到達するためには、約1,000倍の計算量の増加が必要であると推定されます。これは、現在のハードウェアでトレーニングするには無理があります。今後は、CLIPの計算効率とデータ効率を向上させるための研究が必要です。
だそうです。今後計算効率やデータ効率を改善した提案手法が出てくれば、更に精度の高いzero-shotのモデルが誕生しそうです。
またまた引用ですが、
(中略)the performance of CLIP is poor on several types of fine grained classification such as differentiating models of cars, species of flowers, and variants of aircraft. CLIP also struggles with more abstract and systematic tasks such as counting the number of objects in an image.
Finally for novel tasks which are unlikely to be included in CLIP’s pre-training dataset, such as classifying the distance to the nearest car in a photo, CLIP’s performance can be near random.
(DeepL翻訳) **CLIP は、自動車のモデル、花の種類、航空機の種類を区別するような、細かい分類を行うことができません。**また、画像内のオブジェクトの数を数えるといった、より抽象的でシステマティックなタスクでもCLIPは苦戦します。
最後に、写真に写っている最も近い車までの距離を分類するなど、CLIPの事前学習データセットには含まれていない可能性が高い新規タスクでは、CLIPの性能はほぼランダムになります。
このような弱点を踏まえて、CLIPを利用することが大切です。
(しかしDeepLの機械翻訳精度は高いなぁ・・)
次回、ようやくCLIPを試した記事を書きます!