はじめに
@taishi-i さんのawesome-japanese-nlp-resourcesという日本語NLPを使う際に有用なOSSをまとめているgithubを知り、幾つか試したくなりました。
こちらのgithubでは、複数のOSSがdownloads、starsが記載してされており、非常に見やすいです。
今回は、
-
文章分割:Sentence spliter
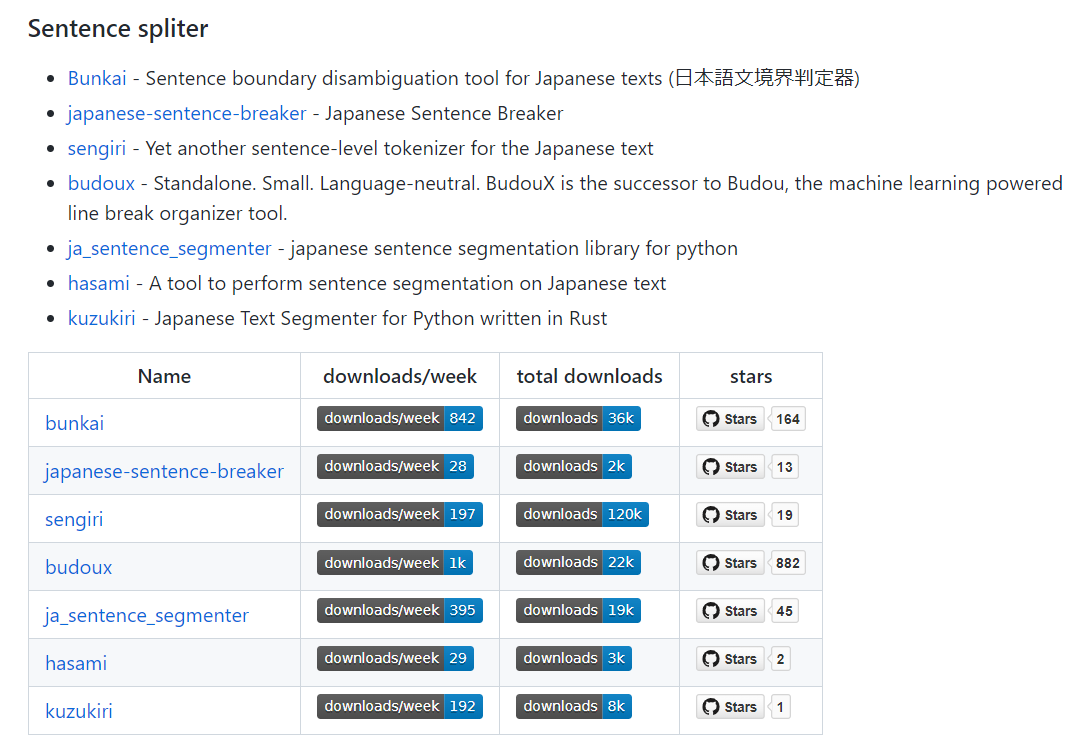
-
ネガポジ判定:Sentiment analysis
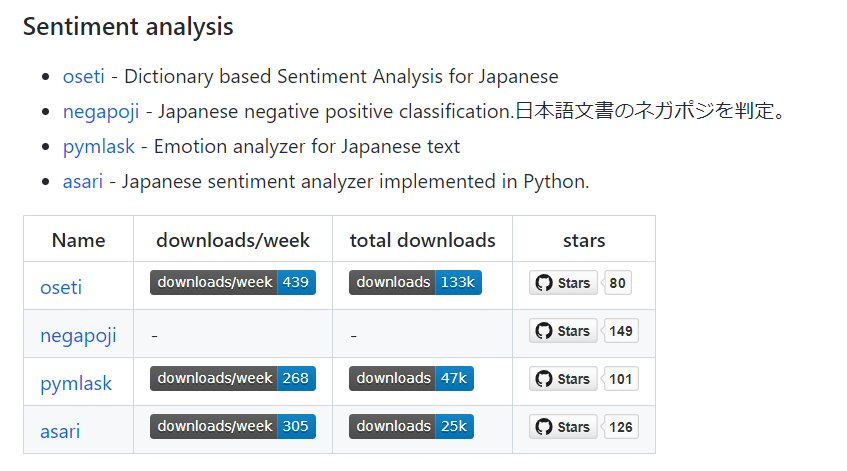
に注目することにする。
実験で試した環境
- Python 3.8.10 ※python 3.6では動作しなかったライブラリがあったので、バージョンは注意すること
- Sentence spliter -> bunkai 1.5.7
- Sentiment analysis -> oseti 0.4.2
インストール
今回紹介するOSSは非常にインストールしやすかったです。
$ pip install -U bunkai
$ pip install oseti
実験で使用した文章
これから飲み会♪旅行行きたい★でも、花粉やばい。。。。この時期涙が止まらないから大嫌いだ!!!花粉対策用の眼鏡買うかな?
旅行のことを考え考えると楽しみでやばい。。
と言いつつ、、、夜更かしをして明日は昼まで寝ちゃうかも(≧▽≦)最近眠いから起きれないかも、、
この文章にしたのは、
- 文末が「★」「。。。。」 「!!!」や「(≧▽≦)」のような「。」以外の記号があったとしても文章分割されるか
- 「大嫌いだ!」などの明らかにネガティブとわかる文章を「ネガティブ」と判定するか
- 「やばい」が含まれる文章が文脈によってネガポジが変化するか
この点が気になってこのような文章にしました。この文章を"sample.txt"として保存し、動作確認しました。
ソースコード例
今回は分割した文章毎のネガポジ値を表示するスクリプトにしています。
まずはインポート。
from bunkai import Bunkai
import oseti
import pandas as pd
呼び出していきます。
bunkai = Bunkai()
analyzer = oseti.Analyzer()
"bunkai"というOSSは、
1行は1つの文書を表します.文書中の改行は ▁ (U+2581) で与えてください.
という注意書きがgithub上にあり、以下ソースコードでは
sentence = s.replace("\n","_")と変換しています。
path = "sample.txt"
sentence_list = []
sentiment_list = []
with open(path, encoding='utf-8') as f:
s = f.read()
sentence = s.replace("\n","_")
for sentence in bunkai(sentence):
print(sentence)
sentence_list.append(sentence)
sentiment_list.append(analyzer.analyze(sentence)[0])
df = pd.DataFrame(columns = ["sentence", "sentiment"])
df["sentence"] = sentence_list
df["sentiment"] = sentiment_list
df.to_csv("output.csv")
結果表示と考察
| sentence | sentiment | |
|---|---|---|
| 0 | これから飲み会♪ | 0 |
| 1 | 旅行行きたい★ | 1 |
| 2 | でも、花粉やばい。。。。 | -1 |
| 3 | この時期涙が止まらないから大嫌いだ!!! | -1 |
| 4 | 花粉対策用の眼鏡買うかな? | 0 |
| 5 | _旅行のことを考え考えると楽しみでやばい。。 | 0.333333333333333 |
| 6 | _と言いつつ、、、夜更かしをして明日は昼まで寝ちゃうかも(≧▽≦) | 1 |
| 7 | 最近眠いから起きれないかも、、 | 0 |
- 「これから飲み会♪」は、語尾の"♪"から個人的にはポジティブと判定して欲しかった。
- 「花粉やばい」の場合は「ネガティブ」と判定され、「旅行のことを考え考えると楽しみでやばい。」の場合「ポジティブ」寄りになっている(「楽しみ」という単語の影響か?)。
- 「、、、」はうまく分割できなかったが、色んな文末記号に対し、文章分割できている
- おおむねニュートラルっぽい文章をsentiment「0」と判定している
その他
- osetiでは、github上にユーザー辞書を登録できる機能も紹介されているので、今後カスタマイズもしてみたい。
- sentimentの他のOSSでは、「大嫌い」を「ネガティブ」と判定できないものもあり、事前にサンプル文を用いて上手く評価できるか確認してから利用した方が良いと思った。
参考(ありがとうございます!)
- github:awesome-japanese-nlp-resources
- github:bunkai
- github:oseti