lightGBMの使い方についての記事はたくさんあるんですが、importanceを出す手順が書かれているものがあまりないようだったので、自分用メモを兼ねて書いておきます。
lightgbm.train()で学習した場合とlightGBMClassifier()でモデルを定義してからfitメソッドで学習した場合でimportanceのある場所と呼び方が変わっちゃうのでちょっとややこしいですね。
試行環境
- Windows 10 64bit
- Python 3.6.6
- lightgbm 2.2.2
- jupyter notebook
lightgbm.train()を使う場合
import numpy as np
import pandas as pd
import lightgbm as lgb
from sklearn import datasets
from sklearn.model_selection import train_test_split
# Iris データセットを読み込む
iris = datasets.load_iris()
X, y = iris.data, iris.target
# 学習データとテストデータを分ける
X_train, X_test, y_train, y_test = train_test_split(X, y)
# データを格納する
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
# 学習条件を設定
params = {'task': 'train',
'boosting_type': 'gbdt',
'objective': 'multiclass',
'metric': {'multi_logloss'},
'num_class': 3,
'learning_rate': 0.02,
'num_leaves': 23,
'min_data_in_leaf': 1,
'num_iteration': 1000,
'verbose': 0}
# 学習する
model = lgb.train(params,
lgb_train,
num_boost_round=50,
valid_sets=lgb_eval,
early_stopping_rounds=20)
# テストデータで予測する
y_pred = model.predict(X_test, num_iteration=model.best_iteration)
y_pred_max = np.argmax(y_pred, axis=1)
# Accuracy を計算する
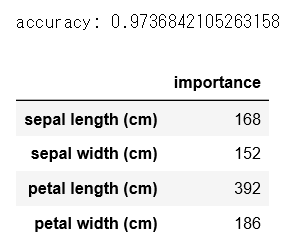
accuracy = sum(y_test == y_pred_max) / len(y_test)
print('accuracy:', accuracy)
# importanceを表示する
importance = pd.DataFrame(model.feature_importance(), index=iris.feature_names, columns=['importance'])
display(importance)

lightGBMClassifier()を使う場合
import numpy as np
import pandas as pd
import lightgbm as lgb
from sklearn import datasets
from sklearn.model_selection import train_test_split
# Iris データセットを読み込む
iris = datasets.load_iris()
X, y = iris.data, iris.target
# 学習データとテストデータを分ける
X_train, X_test, y_train, y_test = train_test_split(X, y)
# 学習条件を設定
model = lgb.LGBMClassifier(objective='multiclass',
num_leaves = 23,
learning_rate=0.1,
n_estimators=100)
# 学習する
result = model.fit(X_train, y_train,
eval_set=[(X_test, y_test)],
eval_metric='multi_logloss',
early_stopping_rounds=20)
# テストデータで予測する
y_pred = model.predict(X_test, num_iteration=result.best_iteration_)
# Accuracy を計算する
accuracy = sum(y_test == y_pred) / len(y_test)
print()
print('accuracy:', accuracy)
# importanceを表示する
importance = pd.DataFrame(model.feature_importances_, index=iris.feature_names, columns=['importance'])
display(importance)