やったこと
先日購入したニューマシンにtensorflow2.0.0alphaを入れたんですが、kerasがtensorflowに統合されてtensorflow.kerasから呼ぶようになってて、keras+tensorflow1系で書いてたコードとは何やら違いそう、何が違うのかなという事で公式チュートリアルを読みながら動かしてみました。
結論
from keras import hogeだったのをfrom tensorflow.keras import hogeに変えるだけで動きます。旧kerasユーザーはimportのとこだけ書き換えて使ってください。
試行環境
OS: Windows10
CPU: core i9-9900K
GPU: RTX2080Ti
tensorflow==2.0.0alpha
CUDA10.0
cuDNN7.5 for CUDA10
ドキュメント
tensorflow公式
https://www.tensorflow.org/alpha/tutorials/quickstart/beginner
moduleについてのドキュメント
https://www.tensorflow.org/versions/r2.0/api_docs/python/tf
mnistをダウンロード
とりあえずmnistをダウンロードします。
import tensorflow as tf
# mnistをダウンロード
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 0-255の値が入っているので、0-1に収まるよう正規化します
x_train, x_test = x_train / 255.0, x_test / 255.0
# データを確認
print(x_train.shape, x_test.shape)
(60000, 28, 28) (10000, 28, 28)
いつもの奴が落ちてきたようです。numpy.arrayになってるのでimshowでそのまま画像表示できます。
# 画像を表示してみます
import matplotlib.pyplot as plt
%matplotlib inline
k = 0
print(y_train[k])
plt.imshow(x_train[k].reshape((28, 28)), cmap='gray')
plt.show()
うん、いつもの奴ですね
全結合NNで学習してみる
チュートリアル通り全結合NNで学習してみます。普通の全結合NNの場合はSequentialを使います。8bitグレースケール28x28pixelの画像は2次元ですので、入力データの次元(28x28)を指定してflattenしてから、活性化関数としてreluを使う128ノードの隠れ層に2割をDropoutしながら学習するように設定しています。出力は0~9の10クラス分類になるので、10ノードのsoftmaxになってます。
最適化はadam、損失関数はsparse_categorical_crossentropyで、accuracyも算出するようにモデルをcompileして、fitで学習という流れは完全に以前のkerasと同じです。validationの設定も変わってないようです。importするときに同じ名前で呼べるようにしておけばコードの書き換えも最小限で済みそう。ありがたいです。
# Sequentialモデルを定義します
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
# モデルをcompileします
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 学習します
hist = model.fit(x_train, y_train, validation_split=0.1, epochs=5)
# テストデータの予測精度を計算します
model.evaluate(x_test, y_test)
Epoch 1/5
60000/60000 [==============================] - 5s 90us/sample - loss: 0.2927 - accuracy: 0.9163
Epoch 2/5
60000/60000 [==============================] - 5s 89us/sample - loss: 0.1428 - accuracy: 0.9572
Epoch 3/5
60000/60000 [==============================] - 5s 76us/sample - loss: 0.1071 - accuracy: 0.9670
Epoch 4/5
60000/60000 [==============================] - 4s 72us/sample - loss: 0.0884 - accuracy: 0.9723
Epoch 5/5
60000/60000 [==============================] - 4s 73us/sample - loss: 0.0754 - accuracy: 0.9755
10000/10000 [==============================] - 1s 53us/sample - loss: 0.0772 - accuracy: 0.9763
[0.07715519992336631, 0.9763]
testデータで97.6%の精度が得られました。
モデルのsummaryを表示する
model.summaryでcompileしたモデルの情報が見られます
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
_________________________________________________________________
dense (Dense) (None, 128) 100480
_________________________________________________________________
dropout (Dropout) (None, 128) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 1290
=================================================================
Total params: 101,770
Trainable params: 101,770
Non-trainable params: 0
学習曲線を見る
学習曲線を出してみます。epochごとの損失関数とmetricsはmodel.fitしたときの返り値にhistoryオブジェクトが返ってくるので、さっき学習したコードだとhist.history['loss']みたいに呼んできます
historyオブジェクトのドキュメント
https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/callbacks/History
import matplotlib.pyplot as plt
plt.figure(figsize=(5,4))
plt.plot(hist.epoch, hist.history['loss'], label='loss')
plt.plot(hist.epoch, hist.history['val_loss'], label='val_loss')
plt.xlabel('epoch')
plt.ylabel('loss: sparse_categorical_crossentropy')
plt.legend()
plt.show()
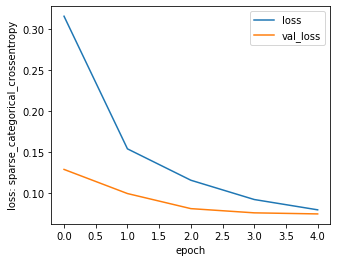
epoch少なめなので過学習はしてないようですね。
予測してみる
続いて、モデルを使て予測してみます。model.fitしてからmodel.predictで推定かけるのも同じです。
model.predict(x_train)
array([[2.0879418e-09, 9.4415634e-07, 1.9093848e-06, ..., 1.6121115e-08,
6.0788541e-10, 2.0305754e-07],
[9.9999857e-01, 1.6418764e-09, 1.1759599e-06, ..., 8.3453759e-09,
7.2786988e-10, 1.9110008e-08],
[5.0992586e-08, 1.3978712e-06, 2.6872063e-05, ..., 1.3347615e-04,
1.7704754e-06, 9.1211135e-05],
...,
[3.1196892e-10, 6.1884357e-08, 9.2593599e-11, ..., 6.7778595e-11,
1.5898895e-07, 1.3192109e-06],
[8.3424224e-05, 9.5248462e-05, 2.7588433e-06, ..., 1.3730063e-07,
2.2271463e-08, 3.1710453e-08],
[3.3357418e-03, 1.6606524e-06, 9.0457121e-05, ..., 4.0862447e-05,
9.9632746e-01, 9.0121212e-05]], dtype=float32)
softmaxの値が出てきます。判定結果が欲しい場合はpredict_classesですね。
model.predict_classes(x_train)
array([5, 0, 4, ..., 5, 6, 8], dtype=int64)
いちばん良かったモデルを使う
一般にepochは最適な回数があって、少なすぎると学習不足、epochを増やすと過学習という感じになります。でも何回まわすのが良いのかはやってみないと分からないので適当に多めのepochを設定しておいていちばん良かったモデルを使いたいわけです。でもmodel.fitした後のmodelは最後まで学習したmodelなので、epoch多めだと過学習済みモデルを使うことになっちゃいます。
そうならないように指定した指標が前より良くなった時のモデルを取り出して保存しといてくれるのがtensorflow.keras.callbacks.ModelCheckPointです。
import tensorflow as tf
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.models import load_model
import matplotlib.pyplot as plt
# mnistを読みこみます
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 0-255の値が入っているので、0-1に収まるよう正規化します
x_train, x_test = x_train / 255.0, x_test / 255.0
# データを確認
print(x_train.shape, x_test.shape); print()
# Sequentialモデルを定義します
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
# モデルをcompileします
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# ベストを更新したときだけモデルを保存しておく
modelCheckpoint = ModelCheckpoint(filepath = '../tmp.h5',
monitor = 'val_loss',
verbose = 1,
save_best_only = True,)
# 学習します
hist = model.fit(x_train, y_train, validation_split=0.1, epochs=100, verbose=1,
callbacks=[modelCheckpoint])
# テストデータの予測精度を計算します
print('modelのスコア')
print(model.evaluate(x_test, y_test), '\n')
# 保存されてるモデルによるテストデータの予測精度を計算します
best_model = load_model('../tmp.h5')
print('ModelCheckPointのスコア')
print(best_model.evaluate(x_test, y_test))
# 学習曲線を出力しておきます
plt.figure(figsize=(5,4))
plt.plot(hist.epoch, hist.history['loss'], label='loss')
plt.plot(hist.epoch, hist.history['val_loss'], label='val_loss')
plt.xlabel('epoch')
plt.ylabel('loss: sparse_categorical_crossentropy')
plt.legend()
plt.show()
やってみるとepoch=9ぐらいで更新しなくなってます。学習曲線でもそれぐらいなのでバッチリですね。
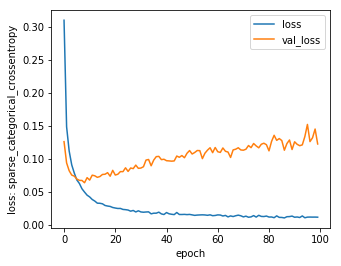
グラフの読み取りからvalidationデータのlossは最終的に0.14ぐらいになってますので、以下で得られてるtestデータの0.1405と概ね一致してます。それに対し、ModelCheckPointが保存してくれたモデルはtestデータに対してlossが0.0702とvalidationデータのベストと同じぐらい。ちゃんとベストなモデルが拾えていますね。
modelのスコア
10000/10000 [==============================] - 1s 65us/sample - loss: 0.1405 - accuracy: 0.9797
[0.1404532007291029, 0.9797]
ModelCheckPointのスコア
10000/10000 [==============================] - 1s 68us/sample - loss: 0.0702 - accuracy: 0.9792
[0.07015186320864596, 0.9792]
EarlyStoppingを使う
一応EarlyStoppingもやってみます。
import tensorflow as tf
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.models import load_model
import matplotlib.pyplot as plt
# mnistを読みこみます
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 0-255の値が入っているので、0-1に収まるよう正規化します
x_train, x_test = x_train / 255.0, x_test / 255.0
# データを確認
print(x_train.shape, x_test.shape); print()
# Sequentialモデルを定義します
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
# モデルをcompileします
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# ベストを更新したときだけモデルを保存しておく
modelCheckpoint = ModelCheckpoint(filepath = '../tmp.h5',
monitor = 'val_loss',
verbose = 1,
save_best_only = True,)
# Early Stoppingを設定
EarlyStopping = EarlyStopping(monitor='val_loss', patience=2, verbose=1, mode='auto')
# 学習します
hist = model.fit(x_train, y_train, validation_split=0.1, epochs=100, verbose=1,
callbacks=[modelCheckpoint, EarlyStopping])
# テストデータの予測精度を計算します
print(model.evaluate(x_test, y_test))
# 保存されてるモデルによるテストデータの予測精度を計算します
best_model = load_model('../tmp.h5')
print(best_model.evaluate(x_test, y_test))
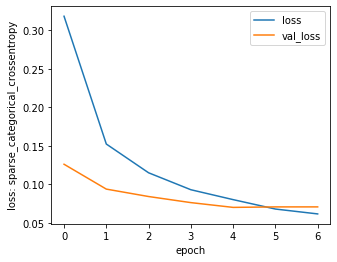
plt.figure(figsize=(5,4))
plt.plot(hist.epoch, hist.history['loss'], label='loss')
plt.plot(hist.epoch, hist.history['val_loss'], label='val_loss')
plt.xlabel('epoch')
plt.ylabel('loss: sparse_categorical_crossentropy')
plt.legend()
plt.show()
(60000, 28, 28) (10000, 28, 28)
Train on 54000 samples, validate on 6000 samples
54000/54000 [==============================] - 4s 74us/sample - loss: 0.0801 - accuracy: 0.9749 - val_loss: 0.0700 - val_accuracy: 0.9803
Epoch 6/100
53568/54000 [============================>.] - ETA: 0s - loss: 0.0680 - accuracy: 0.9786
Epoch 00006: loss improved from 0.08006 to 0.06783, saving model to ../tmp.h5
54000/54000 [==============================] - 4s 74us/sample - loss: 0.0678 - accuracy: 0.9787 - val_loss: 0.0706 - val_accuracy: 0.9797
Epoch 7/100
53888/54000 [============================>.] - ETA: 0s - loss: 0.0616 - accuracy: 0.9801
Epoch 00007: loss improved from 0.06783 to 0.06150, saving model to ../tmp.h5
54000/54000 [==============================] - 4s 74us/sample - loss: 0.0615 - accuracy: 0.9802 - val_loss: 0.0706 - val_accuracy: 0.9795
Epoch 00007: early stopping
10000/10000 [==============================] - 0s 45us/sample - loss: 0.0754 - accuracy: 0.9779
[0.07538763607138535, 0.9779]
10000/10000 [==============================] - 0s 50us/sample - loss: 0.0754 - accuracy: 0.9779
[0.07538763607138535, 0.9779]
patientが少ないとすぐあきらめちゃうので、もうちょい多めが良いかもですね。
畳み込みNNをやってみる
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D, Reshape
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.models import load_model
import matplotlib.pyplot as plt
# mnistを読みこみます
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 0-255の値が入っているので、0-1に収まるよう正規化します
x_train, x_test = x_train / 255.0, x_test / 255.0
# データを確認
print(x_train.shape, x_test.shape); print()
# 畳み込みNNモデルを定義します
model = Sequential([
Reshape((28, 28, 1), input_shape=(28, 28)),
Conv2D(50, (5, 5), activation='relu'),
Conv2D(50, (3, 3), activation='relu'),
MaxPooling2D(pool_size=(2, 2)),
Flatten(),
Dropout(0.2),
Dense(100, activation='relu'),
Dropout(0.4),
Dense(10, activation='softmax')
])
# モデルをcompileします
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# ベストを更新したときだけモデルを保存しておく
modelCheckpoint = ModelCheckpoint(filepath = '../tmp.h5',
monitor = 'val_loss',
verbose = 1,
save_best_only = True,)
# Early Stoppingを設定
EarlyStopping = EarlyStopping(monitor='val_loss', patience=2, verbose=1, mode='auto')
# 学習します
hist = model.fit(x_train, y_train, validation_split=0.1, epochs=100, verbose=1,
callbacks=[modelCheckpoint, EarlyStopping])
# テストデータの予測精度を計算します
print(model.evaluate(x_test, y_test))
# 保存されてるモデルによるテストデータの予測精度を計算します
best_model = load_model('../tmp.h5')
print(best_model.evaluate(x_test, y_test))
plt.figure(figsize=(5,4))
plt.plot(hist.epoch, hist.history['loss'], label='loss')
plt.plot(hist.epoch, hist.history['val_loss'], label='val_loss')
plt.xlabel('epoch')
plt.ylabel('loss: sparse_categorical_crossentropy')
plt.legend()
plt.show()
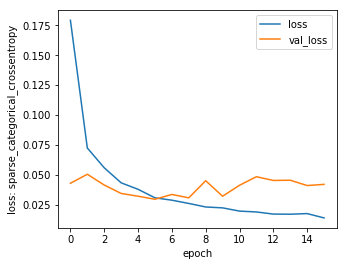
10000/10000 [==============================] - 1s 87us/sample - loss: 0.0238 - accuracy: 0.9929
[0.023802761797390486, 0.9929]
99.29%まで上がりましたね。
おしまい