顔検出をOpenCVでやってみました
1. 手法の選択肢
OpenCVでは3つの選択肢があるようです
A: cv2.CascadeClassifier
B: cv2.dnn_DetectionModel
C: cv2.FaceDetectorYN
B, Cはモデルをダウンロードしてきて使うようになってるんですが、モデルの置き場所も公式ドキュメントからすぐ分かるようになっていないし、そもそも公式ドキュメントが何言ってるかよく分からないので、TensorFlowやPyTorchが使える人はそっちでやった方が良いと思います。
2. OpenCVのインストールとimport
pipで入ります
pip install opencv-python
importするときはcv2で呼びます
import cv2
3. 画像を読み込む
画像ACさんの画像をサンプルに使いたいと思います
https://www.photo-ac.com/
image = cv2.imread('./img/sample.jpg')
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.show()

4. cv2.CascadeClassifierで検出
Haar-Like特徴量を使ったカスケード分類器で検出するクラスです
https://docs.opencv.org/4.x/db/d28/tutorial_cascade_classifier.html
4-1. グレースケールにする
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
plt.imshow(image_gray, cmap='gray')
plt.show()

4-2. モデルをダウンロードする
OpenCVをインストールしたときに一緒に入っている記載もあるんですが、見つけられなかったのでOpenCV公式からダウンロードしてきました。今回はhaarcascade_frontalface_default.xmlを使用します。
https://github.com/opencv/opencv/tree/master/data/haarcascades
4-3. 顔検出する
cv2.CascadeClassifierに先程のxmlファイルのPATHを渡して分類器オブジェクトを作ったら、detectMultiScale()メソッドで検出できます。
cascade = cv2.CascadeClassifier('./data/haarcascades/haarcascade_frontalface_default.xml')
boxes = cascade.detectMultiScale(image_gray)
boxes

4-4. バウンディングボックスをつけて表示
検出結果はバウンディングボックスの [左端の位置、上端の位置, 幅、高さ] の順で入っているので、以下のようにして検出位置を確認できます
image_output = image.copy()
for x, y, w, h in boxes:
face = image[y: y + h, x: x + w]
cv2.rectangle(image_output, (x, y), (x + w, y + h), (255, 0, 0), 2)
plt.imshow(cv2.cvtColor(image_output, cv2.COLOR_BGR2RGB))
plt.show()

検出漏れ1箇所、誤検出1箇所がありますが、それなりに優秀な検出器ですね
5. cv2.dnn_DetectionModelで検出
caffeやtensorflow, PyTorchなどのモデルを利用できるクラスであるcv2.dnn_DetectionModelで検出します
https://docs.opencv.org/4.x/d3/df1/classcv_1_1dnn_1_1DetectionModel.html
5-1. モデルをダウンロードする
以下からYOLOv4モデルをダウンロードして使ってみます
https://github.com/AlexeyAB/darknet
上記からyolov4.cfg、yolov4.weightsをダウンロードしました
5-2. 検出する
ニューラルネットワークモデルは画像の入力サイズが決まっているので、cv2.dnn_DetectionModelがモデルの入力サイズがいくらなのか教えてあげて、閾値を指定して画像を渡すと検出してくれます
# モデルの読み込み
net = cv2.dnn.readNet('./models/yolov4.cfg', './models/yolov4.weights')
model = cv2.dnn_DetectionModel(net)
model.setInputParams(scale=1 / 255, size=(416, 416), swapRB=True)
# 物体検出
detect_result = model.detect(image, confThreshold=0.6, nmsThreshold=0.4)
detect_result

ラベル, confidence, 位置の順で返してくれますが、ラベルの付番はモデルごとに違うので、そちらを確認する必要があります
5-3. バウンディングボックスを表示する
image_output = image.copy()
for object_class, [x, y, w, h] in zip(detect_result[0], detect_result[2]):
if object_class == 0:
face = image[y: y + h, x: x + w]
cv2.rectangle(image_output, (x, y), (x + w, y + h), (0, 255, 0), 2)
plt.imshow(cv2.cvtColor(face, cv2.COLOR_BGR2RGB))
plt.show()
plt.imshow(cv2.cvtColor(image_output, cv2.COLOR_BGR2RGB))
plt.show()

顔検出モデルではなくて人物を身体ごと検出するモデルなので、顔だけ出てる人は上手く見つけられていません。顔検出に特化したモデルもあるので、そちらを使えばもっと良くなる筈ですが情報があまりにもなさ過ぎてこれ以上やる意味を見いだせず断念しました。
6. cv2.FaceDetectorYN
YuNetという顔検出モデルを使うクラスです
https://docs.opencv.org/4.x/df/d20/classcv_1_1FaceDetectorYN.html
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9429909
外部モデルをダウンロードしてきて使うのはcv2.dnn_DetectionModelと同じだし、わざわざクラスを分ける意味がよく分からないのですが何故だか分けて実装されています
6-1. モデルをダウンロードする
以下のリポジトリからyunet.onnxをダウンロードします
https://github.com/ShiqiYu/libfacedetection.train/tree/master/tasks/task1/onnx
公式外からダウンロードしてきて使う、しかもよく知ってるPyTorchやTensorFlowの公式から落としてくるんでもなくというのがどうも気になるんですが、せめて公式のサンプルコードに載せるモデルぐらい公式リポジトリに置けなかったんでしょうか?どうも変な運用に思えます。
6-2. 検出する
入力サイズを指定して検出するのはcv2.dnn_DetectionModelとだいたい同じです
face_detector = cv2.FaceDetectorYN.create("./models/yunet.onnx", "", (0, 0))
# 入力サイズを指定する
height, width, _ = image.shape
face_detector.setInputSize((width, height))
# 顔を検出する
_, faces = face_detector.detect(image)
faces = faces if faces is not None else []
faces
6-3. バウンディングボックスを表示する
image_output = image.copy()
for face in faces:
x, y, w, h = list(map(int, face[:4]))
cv2.rectangle(image_output, (x, y), (x + w, y + h), (0, 255, 0), 2)
plt.imshow(cv2.cvtColor(image_output, cv2.COLOR_BGR2RGB))
plt.show()

モデル自体は優秀です
7. cv2.FaceRecognizerSFで顔認識する
cv2.FaceRecognizerSFを使うと顔認識もできますので、ついでにやってみたいと思います
https://docs.opencv.org/4.x/da/d09/classcv_1_1FaceRecognizerSF.html
https://ieeexplore.ieee.org/document/9318547
先程検出した顔部分だけを切り出して、その画像を顔認識用のモデルに通して特徴量を出して、特徴量が近いものは同じ人の顔であろうという方法を取ります
7-1. モデルをダウンロードする
以下からダウンロードすることができます
https://ieeexplore.ieee.org/document/9318547
7-2. 検出した顔画像を切り出す
検出済みの顔画像を切り出します
# モデルを読み込む
face_recognizer = cv2.FaceRecognizerSF.create("./models/face_recognizer_fast.onnx", "")
# 検出された顔を切り抜く
aligned_faces = []
for face in faces:
aligned_face = face_recognizer.alignCrop(image, face)
aligned_faces.append(aligned_face)
plt.imshow(cv2.cvtColor(aligned_face, cv2.COLOR_BGR2RGB))
plt.show()
len(aligned_faces)






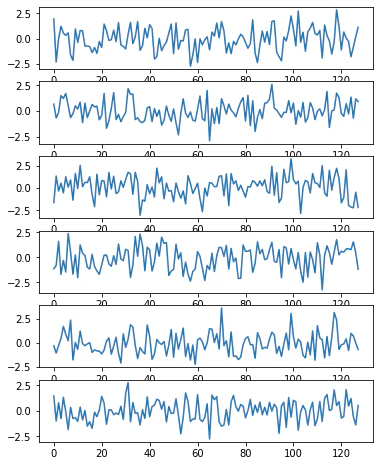
7-3. 特徴量を算出する
学習済みの顔認識モデルで切り出した先程検出した顔画像から特徴量を算出して、dictに入れておけば顔認識の準備は完了です
# 特徴を抽出する
fig, ax = plt.subplots(len(faces), 1, figsize=(6, 8))
face_features = dict()
aligned_faces = list()
for k, face in enumerate(faces):
# 検出した顔画像を切り出し
aligned_face = face_recognizer.alignCrop(image, face)
aligned_faces.append(aligned_face)
# 切り出した顔画像から特徴量を算出してdictに入れる
face_feature = face_recognizer.feature(aligned_face)
user_id = 'face{:03d}'.format(k) # face001.npy -> face001
face_features[user_id] = face_feature
ax[k].plot(face_feature[0])
plt.show()
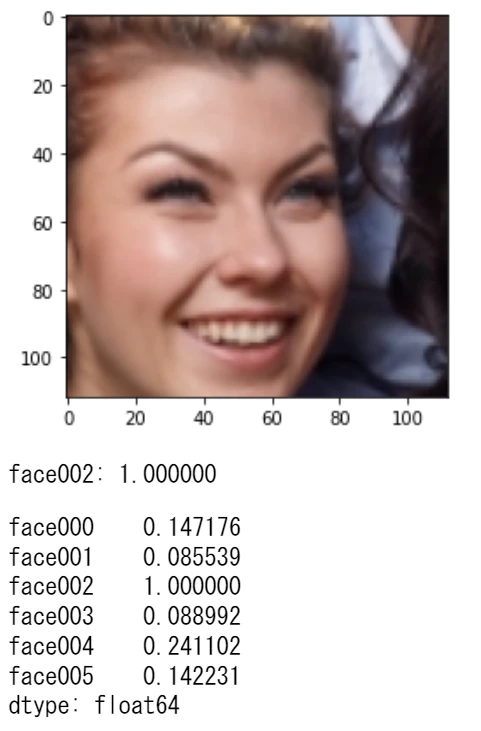
7-4. 算出した特徴量から顔認識する
とりあえず同じ画像で正しく認識できるかやってみます
特徴量を算出するところまでは同じで、その後比較したい特徴量をcv2.FaceRecognizerSF.match()に渡してやればconfidenceを返してくれます。以下では特徴量の比較にコサイン類似度を使ってますので普通に自分で計算しても構わないと思います。
# 特徴を辞書と比較してマッチしたユーザーとスコアを返す関数
def match(recognizer, feature1, face_features):
d = dict()
for user_id in face_features.keys():
score = recognizer.match(feature1, face_features[user_id], cv2.FaceRecognizerSF_FR_COSINE)
d[user_id] = score
s = pd.Series(d)
user = s.index[s.argmax()]
score = s[user]
return s, user, score
for aligned_face in aligned_faces:
plt.imshow(cv2.cvtColor(aligned_face, cv2.COLOR_BGR2RGB))
plt.show()
# 特徴量を算出
feature = face_recognizer.feature(aligned_face)
# 辞書とマッチングする
result, user, score = match(face_recognizer, feature, face_features)
print('{}: {:1.6f}'.format(user, score))
display(result)
当然ながら、特徴量が完全に一致すればconfidence≒1.0になります
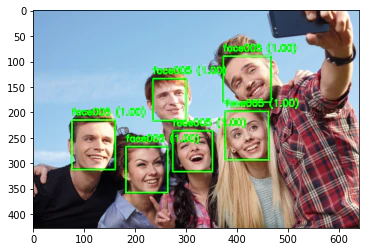
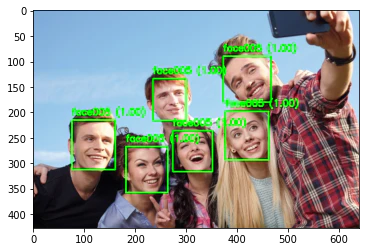
7-5. バウンディングボックスを表示する
画像上に描画して確認する際にはラベルやconfidenceを書き出しておくと分かりやすいと思います
# 顔を検出する
_, faces = face_detector.detect(image)
image_output = image.copy()
for face in faces:
# 顔のバウンディングボックスを描画する
box = list(map(int, face[:4]))
color = (0, 255, 0)
thickness = 2
cv2.rectangle(image_output, box, color, thickness, cv2.LINE_AA)
# 顔認識を実行
aligned_face = face_recognizer.alignCrop(image, face)
face_feature = face_recognizer.feature(aligned_face)
result, user, score = match(face_recognizer, feature, face_features)
# 認識の結果を描画する
text = "{0} ({1:.2f})".format(user, score)
position = (box[0], box[1] - 10)
font = cv2.FONT_HERSHEY_SIMPLEX
scale = 0.6
cv2.putText(image_output, text, position, font, scale, color, thickness, cv2.LINE_AA)
plt.imshow(cv2.cvtColor(image_output, cv2.COLOR_BGR2RGB))
plt.show()
8. まとめ
OpenCVのドキュメントが分かりにくすぎるのとモデルをどこだか知らないリポジトリから取ってくるのが嫌なので、僕は仕事ではこれ使わないと思います。速度もonnxで普通にやるのと変わらないようですし、Python環境だとOpenCVで読んだ画像はnumpy.ndarrayになっていて機械学習系ライブラリがそのまま扱える状態なので、検出/認識部分だけonnx等で書く方がはるかに分かりやすく便利で安全だと思います。
やったので一応まとめましたが、オススメしません。