featuretoolsとは
機械学習を行う際に対象ドメインについての知識がある場合は適切な特徴量を考えて特徴量として与えることで精度向上を図ることができますが、ドメイン知識がない場合も足し合わせたりaggregateしたりして偶然当たりの特徴量を見出すことを期待するという作戦を取ることができます。あり得る組み合わせを片っ端から試すという総当たりアプローチであるので、総当り特徴量エンジニアリング(brute force feature engineering)と呼んだりするようです。
featuretoolsは手作業でやってると面倒な特徴量づくりを半自動化しちゃおうというpythonライブラリです。とても便利です。
featuretools公式チュートリアル
https://docs.featuretools.com/en/stable/
本記事ではこちらのブログのコードに沿ってやっていきます
https://blog.amedama.jp/entry/featuretools-brute-force-feature-engineering
1. install
pipで入ります
pip install featuretools
addonを追加でインストールすることで別ライブラリと連携することもできます
https://docs.featuretools.com/en/stable/install.html
2. Deep Feature Synthesis
複数のDataFrameが与えられたとき、aggregateしたり統計量を算出したり特徴量間の四則演算をやって特徴量を作成しますが、これらの作業をいい塩梅にやってくれるのがDeep Feature Synthesisであり、これをやってくれる関数がfeaturetools.dfs()です。
https://docs.featuretools.com/en/stable/getting_started/afe.html
このいい塩梅の自動化を実現するためにpandas.DataFrameよりも詳細な細かいデータ型の指定が必要になります。例えば時間を表現するデータ型だけでもDatetime、DateOfBirth、DatetimeTimeIndex、NumericTimeIndexなどがあり、不適切な組み合わせが生じにくいようにしてくれます。
https://docs.featuretools.com/en/stable/getting_started/variables.html
3. entity1つの場合
featuretoolsは入力されたデータをentityと呼びます。pandas.DataFrameでデータをもってくる事が多いかと思いますが、その場合1つのpandas.DataFrameが1つのentityという事になります。
3-1. trans_primitivesのみ
trans_primitivesは特徴量間の計算を行います
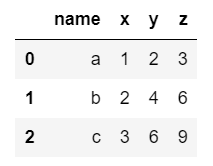
使うDataFrameをつくる
import pandas as pd
data = {'name': ['a', 'b', 'c'],
'x': [1, 2, 3],
'y': [2, 4, 6],
'z': [3, 6, 9],}
df = pd.DataFrame(data)
df
EntitySetをつくる
まず空のfeaturetools.EntitySetを作ります。EntitySetはentity同士の関係や処理する内容を定義しておく為のオブジェクトですが以下ではまだidしか書かれていません。idについては省略可能ですが、以下ではid='example'としています。
import featuretools as ft
es = ft.EntitySet(id='example')
es
EntitySetにentityを追加
以下では先程作ったdfを登録して'locations'という名前で呼べるようにしています。index=はそのままindexを指定する為の引数で、省略するとDataFrameの最初の列をindexとして扱うようになっています。
es = es.entity_from_dataframe(entity_id='locations',
dataframe=df,
index='name')
es
Entityset: example
Entities:
locations [Rows: 3, Columns: 4]
Relationships:
No relationships
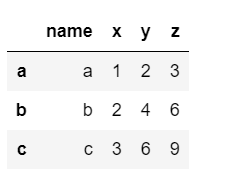
EntitySetに登録されているentityは以下のように呼び出すことができます
es['locations']
Entity: locations
Variables:
name (dtype: index)
x (dtype: numeric)
y (dtype: numeric)
z (dtype: numeric)
Shape:
(Rows: 3, Columns: 4)
es['locations'].df
dfsを実行する
EntitySetができたので、後はft.dfs()に渡すだけで特徴量を作ってくれます。target_entityはメインとするentity、trans_primitivesが特徴量間の組み合わせに適用する計算方法、agg_primitivesがaggregateに使う計算方法です。
使用可能なprimitiveは以下にまとまっています
https://primitives.featurelabs.com/
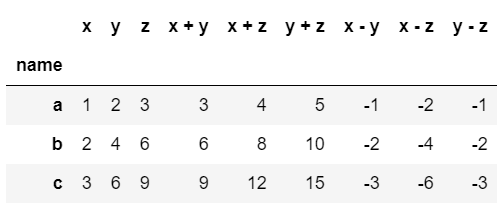
以下ではadd_numericで特徴量間の和を、subtract_numericで特徴量間の差を追加するように指示しています
feature_matrix, feature_defs = ft.dfs(entityset=es,
target_entity='locations',
trans_primitives=['add_numeric', 'subtract_numeric'],
agg_primitives=[],
max_depth=1)
feature_matrix
元々あったのがx, y, zで、それらの和であるx+y, x+z, y+zと差のx-y, x-z, y-zが追加されています
3-2. aggregateのみ
agg_primitivesにはaggregateをつくる計算方法を指定します
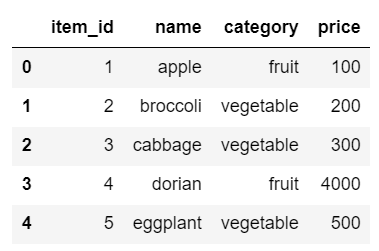
使うDataFrameをつくる
data = {'item_id': [1, 2, 3, 4, 5],
'name': ['apple', 'broccoli', 'cabbage', 'dorian', 'eggplant'],
'category': ['fruit', 'vegetable', 'vegetable', 'fruit', 'vegetable'],
'price': [100, 200, 300, 4000, 500]}
item_df = pd.DataFrame(data)
item_df
aggregateに使うカテゴリー変数を2つもつDataFrameができました
EntitySetをつくる
entityの追加までは先程と同じです
es = ft.EntitySet(id='example')
es = es.entity_from_dataframe(entity_id='items',
dataframe=item_df,
index='item_id')
es
ここにaggregateに使う為のrelationshipを追加します。
以下ではitemsというentityをベースに、新たにcategoryというentityを作り、そのときのindexをcategoryとせよという指示になっています。
es = es.normalize_entity(base_entity_id='items',
new_entity_id='category',
index='category')
es
Entityset: example
Entities:
items [Rows: 5, Columns: 4]
category [Rows: 2, Columns: 1]
Relationships:
items.category -> category.category
これでどうなっているかというと、まずitemsは入れたそのままになっています。
es['items'].df
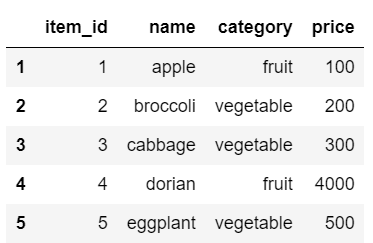
一方、categoryというentityは新しく指定したcategory列でindexされているので以下のようになっています。
es['category'].df

dfsを実行する
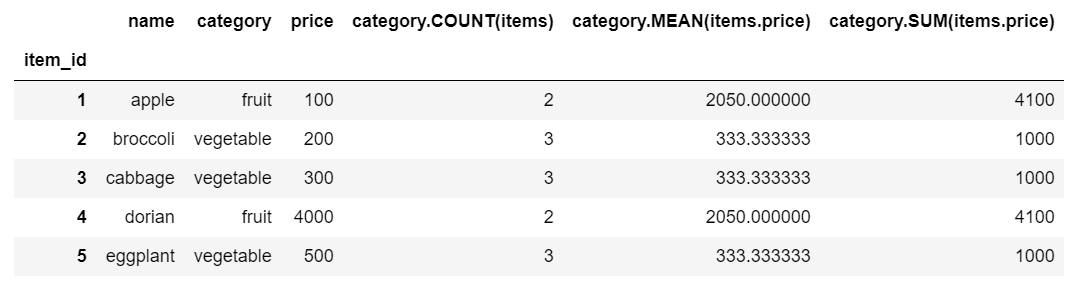
agg_primitivesにcount, sum, meanを指定して実行してみます
feature_matrix, feature_defs = ft.dfs(entityset=es,
target_entity='items',
trans_primitives=[],
agg_primitives=['count', 'sum', 'mean'],
max_depth=2)
feature_matrix
aggregateできる列がitems.priceしかないのでCOUNT(), category.MEAN(), category.SUM()がそれぞれ算出されて、3列追加されたDataFrameができました。
4. entity2つの場合
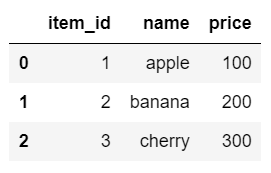
DataFrameをつくる
data = {'item_id': [1, 2, 3],
'name': ['apple', 'banana', 'cherry'],
'price': [100, 200, 300]}
item_df = pd.DataFrame(data)
item_df
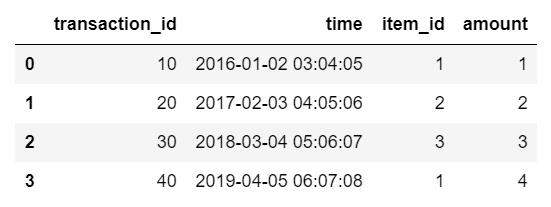
from datetime import datetime
data = {'transaction_id': [10, 20, 30, 40],
'time': [
datetime(2016, 1, 2, 3, 4, 5),
datetime(2017, 2, 3, 4, 5, 6),
datetime(2018, 3, 4, 5, 6, 7),
datetime(2019, 4, 5, 6, 7, 8),
],
'item_id': [1, 2, 3, 1],
'amount': [1, 2, 3, 4]}
tx_df = pd.DataFrame(data)
tx_df
EntitySetをつくる
先ほどと同様にentityを足していきます
es = ft.EntitySet(id='example')
es = es.entity_from_dataframe(entity_id='items',
dataframe=item_df,
index='item_id')
es = es.entity_from_dataframe(entity_id='transactions',
dataframe=tx_df,
index='transaction_id',
time_index='time')
es
2つのentityを繋ぐrelationshipをつくります。
itemsのitem_id列とtransactionsのitem_id列でマージするわけですね。
relationship = ft.Relationship(es['items']['item_id'], es['transactions']['item_id'])
es = es.add_relationship(relationship)
es
Entityset: example
Entities:
items [Rows: 3, Columns: 3]
transactions [Rows: 4, Columns: 4]
Relationships:
transactions.item_id -> items.item_id
dfsを実行する
feature_matrix, feature_defs = ft.dfs(entityset=es,
target_entity='items',
trans_primitives=['add_numeric', 'subtract_numeric'],
agg_primitives=['count', 'sum', 'mean'],
max_depth=2)
feature_matrix

列見出しだけ書き出すと以下のような感じ。aggregateと特徴量間の計算の両方をやってくれてますね。
['name',
'price',
'COUNT(transactions)',
'MEAN(transactions.amount)',
'SUM(transactions.amount)',
'COUNT(transactions) + MEAN(transactions.amount)',
'COUNT(transactions) + SUM(transactions.amount)',
'COUNT(transactions) + price',
'MEAN(transactions.amount) + SUM(transactions.amount)',
'MEAN(transactions.amount) + price',
'price + SUM(transactions.amount)',
'COUNT(transactions) - MEAN(transactions.amount)',
'COUNT(transactions) - SUM(transactions.amount)',
'COUNT(transactions) - price',
'MEAN(transactions.amount) - SUM(transactions.amount)',
'MEAN(transactions.amount) - price',
'price - SUM(transactions.amount)']
max_depthはどう効いてくるか
上記のコードでmax_depthをだんだん増やしていくとどうなるか見てみましょう
['name',
'price',
'COUNT(transactions)',
'MEAN(transactions.amount)',
'SUM(transactions.amount)']
['COUNT(transactions) + MEAN(transactions.amount)',
'COUNT(transactions) + SUM(transactions.amount)',
'COUNT(transactions) + price',
'MEAN(transactions.amount) + SUM(transactions.amount)',
'MEAN(transactions.amount) + price',
'price + SUM(transactions.amount)',
'COUNT(transactions) - MEAN(transactions.amount)',
'COUNT(transactions) - SUM(transactions.amount)',
'COUNT(transactions) - price',
'MEAN(transactions.amount) - SUM(transactions.amount)',
'MEAN(transactions.amount) - price',
'price - SUM(transactions.amount)']
['MEAN(transactions.amount + items.price)',
'MEAN(transactions.amount - items.price)',
'SUM(transactions.amount + items.price)',
'SUM(transactions.amount - items.price)']
['COUNT(transactions) + MEAN(transactions.amount + items.price)',
'COUNT(transactions) + MEAN(transactions.amount - items.price)',
'COUNT(transactions) + SUM(transactions.amount + items.price)',
'COUNT(transactions) + SUM(transactions.amount - items.price)',
'MEAN(transactions.amount + items.price) + MEAN(transactions.amount - items.price)',
'MEAN(transactions.amount + items.price) + MEAN(transactions.amount)',
'MEAN(transactions.amount + items.price) + SUM(transactions.amount + items.price)',
'MEAN(transactions.amount + items.price) + SUM(transactions.amount - items.price)',
'MEAN(transactions.amount + items.price) + SUM(transactions.amount)',
'MEAN(transactions.amount + items.price) + price',
'MEAN(transactions.amount - items.price) + MEAN(transactions.amount)',
'MEAN(transactions.amount - items.price) + SUM(transactions.amount + items.price)',
'MEAN(transactions.amount - items.price) + SUM(transactions.amount - items.price)',
'MEAN(transactions.amount - items.price) + SUM(transactions.amount)',
'MEAN(transactions.amount - items.price) + price',
'MEAN(transactions.amount) + SUM(transactions.amount + items.price)',
'MEAN(transactions.amount) + SUM(transactions.amount - items.price)',
'SUM(transactions.amount + items.price) + SUM(transactions.amount - items.price)',
'SUM(transactions.amount + items.price) + SUM(transactions.amount)',
'SUM(transactions.amount - items.price) + SUM(transactions.amount)',
'price + SUM(transactions.amount + items.price)',
'price + SUM(transactions.amount - items.price)',
'COUNT(transactions) - MEAN(transactions.amount + items.price)',
'COUNT(transactions) - MEAN(transactions.amount - items.price)',
'COUNT(transactions) - SUM(transactions.amount + items.price)',
'COUNT(transactions) - SUM(transactions.amount - items.price)',
'MEAN(transactions.amount + items.price) - MEAN(transactions.amount - items.price)',
'MEAN(transactions.amount + items.price) - MEAN(transactions.amount)',
'MEAN(transactions.amount + items.price) - SUM(transactions.amount + items.price)',
'MEAN(transactions.amount + items.price) - SUM(transactions.amount - items.price)',
'MEAN(transactions.amount + items.price) - SUM(transactions.amount)',
'MEAN(transactions.amount + items.price) - price',
'MEAN(transactions.amount - items.price) - MEAN(transactions.amount)',
'MEAN(transactions.amount - items.price) - SUM(transactions.amount + items.price)',
'MEAN(transactions.amount - items.price) - SUM(transactions.amount - items.price)',
'MEAN(transactions.amount - items.price) - SUM(transactions.amount)',
'MEAN(transactions.amount - items.price) - price',
'MEAN(transactions.amount) - SUM(transactions.amount + items.price)',
'MEAN(transactions.amount) - SUM(transactions.amount - items.price)',
'SUM(transactions.amount + items.price) - SUM(transactions.amount - items.price)',
'SUM(transactions.amount + items.price) - SUM(transactions.amount)',
'SUM(transactions.amount - items.price) - SUM(transactions.amount)',
'price - SUM(transactions.amount + items.price)',
'price - SUM(transactions.amount - items.price)']
[]
[]
agg_primitives、trans_primitives、agg_primitives、trans_primitivesと適用して終了という仕様になっているようです。
CUSTOM primitives
自前のprimitiveを追加して計算することもできるようです
https://docs.featuretools.com/en/stable/getting_started/primitives.html#simple-custom-primitives
まとめ
便利!!!