Keras用のハイパーパラメータチューニングツールであるKerasTunerの使い方メモです
keras.ioに公式ドキュメントがあります
https://keras.io/keras_tuner/
apiリファレンスはここ
https://keras.io/api/keras_tuner/
1. 探索アルゴリズム
探索アルゴリズムとしてはランダムサーチ、ベイズ最適化、Hyperbandが使えます。ランダムサーチはその名の通りで単純にランダムにハイパーパラメータを試行していくもの、ベイズ最適化はハイパーパラメータを引数とするブラックボックス関数をガウス過程により推定して損失関数の期待値が最小となるハイパーパラメータを試行していくもの、Hyperbandは探索自体はベイズ最適化するけどBanditアルゴリズムで早期打ち切りすることで無駄を減らすというもので、基本的にはベイズ最適化が中心となるライブラリであるようです
Hyperbandの論文が以下にあるので読んでおくと良さげ
https://jmlr.org/papers/volume18/16-558/16-558.pdf
optunaのpruningは学習は最後まで実施しながら見込みのないハイパーパラメータの探索をやめていくというものですが、Hyperbandの場合は学習単位で途中打ち切りをやるのが違うところのようですね
ベイズ最適化以外にもハイパーパラメータ探索のアルゴリズムは色々ありますので、その中でどういう位置づけになるかを知っておくと良いと思います。以下の記事やスライドが分かりやすいでしょう
https://logmi.jp/tech/articles/322678
https://speakerdeck.com/nmasahiro/hpo-theory-practice?slide=75
2. install
tensorflow.kerasが入っている環境で動作しますので、そこまでは別途準備してください
keras_tuner自体はpipで入ります
pip install keras-tuner
3. 使い方
keras modelを返す関数を作るかkeras_tuner.HyperModelクラスを作って、keras_tunerのSearchメソッドに渡せばハイパーパラメータ探索をやってくれます。ここではまず簡単な例として、RandomSearchメソッドで探索をやってみます
3-1. 適当にサンプルデータをつくる
mnistでも何でも良いですが、とりあえず適当な曲線でやってみます
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 10, 1000)
y = np.sin(x)
plt.scatter(x, y)
plt.show()
ということで正弦波カーブをつくりました

3-2. modelを作る関数をつくる
ハイパーパラメータを引数として受け取ってkeras modelを作って返してくれる関数をつくります
以下では入出力とも1次元で途中にunit数がunits、Sigmoidを活性化関数とするDenseレイヤーがdepth段の隠れ層を持つシーケンシャルなモデルを作る関数になっています
import tensorflow as tf
def make_model(units=4, depth=2):
network = inputs = tf.keras.layers.Input(1)
for _ in range(depth):
network = tf.keras.layers.Dense(units, activation='sigmoid')(network)
outputs = tf.keras.layers.Dense(1, activation='linear')(network)
model = tf.keras.models.Model(inputs, outputs)
model.compile(loss='mse', optimizer='adam')
return model
model = make_model()
model.summary()

3-3. ハイパーパラメータの選択肢を定義する
keras_tunerのSearchメソッドはkeras_tuner.HyperParametersオブジェクトを引数として渡してきます。このオブジェクトからハイパーパラメータを受け取ってモデルをつくって返すようにしてやります
下記の場合はhp.Choiceメソッドにより第2引数で渡した選択肢から選んでもらう設計です
def build_model(hp):
units = hp.Choice('units', [1, 2, 4, 8, 16, 32])
depth = hp.Choice('depth', [1, 2, 3, 4, 5, 6])
model = make_model(units, depth)
return model
上記のhp.Choiceでdefaultを渡すと初期値をそれにしてくれます
HyperParameters.Choice('optimizer', ['sgd', 'adam', 'RMSprop'], default='adam')
数値を選択肢とする場合、stepで選択肢の間隔、samplingで整数間隔にするか対数間隔にするかを指定できます
HyperParameters.Float('dropout', 1e-6, 1e-1, step=None, sampling='log', default=1e-3)
HyperParameters.Int('depth', 1, 6, step=1, sampling='linear', default=2)
HyperParameters.Boolean('dropout', default=False)
この辺はoptunaとだいたい同じですね
3-4. Tunerをつくって探索を実行する
tunerを作ってsearch()メソッドを呼ぶと学習を実行してくれます
以下ではRandomSearchを最大試行回数5、目的変数をval_lossとして実行しています。本来は学習データと検証データを分けるべきですけどとりあえずの動作確認なので同じデータでやってしまいます
import keras_tuner
tuner = keras_tuner.RandomSearch(
build_model,
objective='val_loss',
max_trials=5)
x_train = x_val = x
y_train = y_val = y
tuner.search(x_train, y_train, epochs=1000, validation_data=(x_val, y_val))
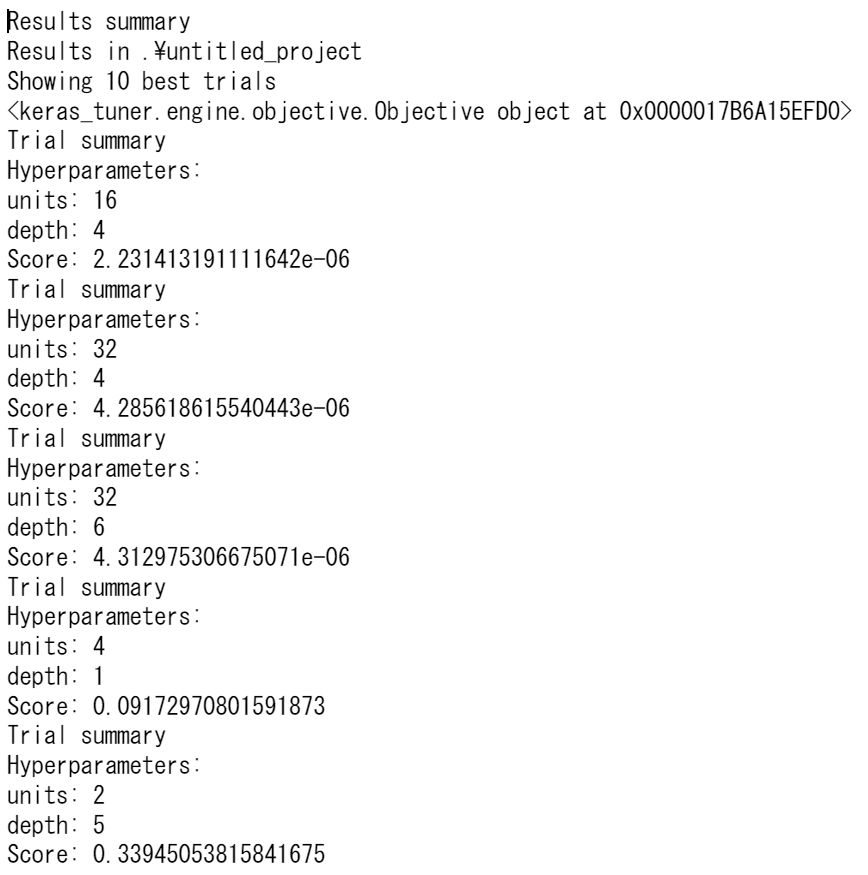
5回実行したところ、units=16, depth=4のval_loss=4.2856e-6が一番良い結果となったようです

tunerは上記のRandomSearchの他にBayesianOptimizationや
Hyperbandが選択できます。また、keras以外にもsklearnにも対応できるようにSklearnTunerが用意されています
3-5. 結果を確認する
結果をざっと眺める場合はresults_summary()で取得できます
tuner.results_summary()
試行したハイパーパラメータを良い方から順に受け取ることも出来ます
best_hps = tuner.get_best_hyperparameters()[0]
print(best_hps.values)

3-6. modelの読み込み
get_best_models()メソッドにより一番良かったものから順に指定の数の試行過程で作られたモデルを受け取ることができます。keras専用に作られているのでこの辺りは他のライブラリより便利ですね
best_models = tuner.get_best_models(num_models=2)
best_model = best_models[0]
best_model
受け取ったモデルはkeras modelなので普通に推定したりweightを取り出したりできます
best_model.evaluate(x, y)
best_model.weights

3-7. 保存先
keras_tunerは自動でモデルと試行履歴を保存してくれます。特に指定しない場合はワーキングディレクトリに保存しますが、保存先を指定して保存することができます。また、DBに保存して分散処理することも出来ます
tuner = keras_tuner.RandomSearch(
build_model,
objective='val_loss',
max_trials=5,
directory='./results'
)
メソッドの選択肢は以下のAPIリファレンスがあります
https://keras.io/api/keras_tuner/hyperparameters/#choice-method
4. 前処理条件も混みで探索する
データに前処理をかける条件をハイパーパラメータに含めたり、model.fit()するときに指定するepochsやshuffleも探索条件に含めたい場合は、以下のようにkeras_tuner.HyperModelクラスのbuild()とfit()をoverrideしたものをSearchメソッドに渡してやれば同様に上手く含めてやってくれます
import keras_tuner
class MyHyperModel(keras_tuner.HyperModel):
def build(self, hp):
units = hp.Choice('units', [1, 2, 4, 8, 16, 32])
depth = hp.Choice('depth', [1, 2, 3, 4, 5, 6])
model = make_model(units, depth)
return model
def fit(self, hp, model, x, y, **kwargs):
if hp.Boolean("normalize"):
x = tf.keras.layers.Normalization()(x)
return model.fit(
x,
y,
# Tune whether to shuffle the data in each epoch.
shuffle=hp.Boolean("shuffle"),
epochs=1000,
**kwargs,
)
tuner = keras_tuner.RandomSearch(
MyHyperModel(),
objective='val_loss',
max_trials=5)
tuner.search(x_train, y_train, validation_data=(x_val, y_val))
best_model = tuner.get_best_models()[0]
tuner.results_summary()

best_hps = tuner.get_best_hyperparameters(5)
for hps in best_hps:
print(hps.values)

5. 探索するハイパーパラメータを制限する
learning rateだけ探索して残りは固定しておいたり、逆にlearning rateを固定して残りを探索したりということができます。ベイズ最適化はパラメータが多い対象が苦手なので、探索対象のハイパーパラメータの一部を固定して探索できるようにしているという事なのかな?
やり方はhyperparametersを渡して、tune_new_entriesを指定するだけです。以下の場合はunitsを[1, 2, 4, 8, 16, 32]から探索して、残りは固定となります
import keras_tuner
hp = keras_tuner.HyperParameters()
units = hp.Choice('units', [1, 2, 4, 8, 16, 32]) # ← 探索するハイパーパラメータを定義
tuner = keras_tuner.RandomSearch(
build_model,
hyperparameters=hp,
tune_new_entries=False, # ← 未設定のエントリーが新しくbuild_model内で新たに定義されたときにtuneしない
objective='val_loss',
overwrite=True,
max_trials=5)
x_train = x_val = x
y_train = y_val = y
tuner.search(x_train, y_train, epochs=1000, validation_data=(x_val, y_val))
best_model = tuner.get_best_models()[0]
逆に以下のようにすればunitsを固定して残りを探索となります
import keras_tuner
hp = keras_tuner.HyperParameters()
units = hp.Fixed('units', 8) # ← 探索するハイパーパラメータを定義
tuner = keras_tuner.RandomSearch(
build_model,
hyperparameters=hp,
tune_new_entries=True, # ← 未設定のエントリーが新しくbuild_model内で新たに定義されたときにtuneしない
objective='val_loss',
overwrite=True,
max_trials=5)
x_train = x_val = x
y_train = y_val = y
tuner.search(x_train, y_train, epochs=1000, validation_data=(x_val, y_val))
best_model = tuner.get_best_models()[0]
6. 探索過程をTensorBoardで見る
TensorBoardで探索過程を見られるようにもなっています
6-1. 学習
tuner.search()の引数にTensorBoardのcallbackを渡してやればTensorBoard用のログファイルが書き出されます
import keras_tuner
tuner = keras_tuner.RandomSearch(
build_model,
objective='val_loss',
directory='./tmp/tb',
max_trials=5)
x_train = x_val = x
y_train = y_val = y
tuner.search(x_train,
y_train,
epochs=1000,
validation_data=(x_val, y_val),
callbacks=[tf.keras.callbacks.TensorBoard("./tmp/tb_logs")])
tuner.results_summary()
6-2. TensorBoardを表示する
後は先程callbackに指定したPATHを対象にTensorBoardを起動してやればOKです
%load_ext tensorboard
%tensorboard --logdir ./tmp/tb_logs --host=127.0.0.1
tensorboard --logdir ./tmp/tb_logs --host=127.0.0.1
上記を実行すると http://127.0.0.1:6006 にTensorBoardが待機します
学習曲線を比較したり

パラレルプロットを表示したり

散布図プロットを表示したりできます

これにより探索した全体像を理解するのが容易になります。これが使えるのはkeras_tunerの大きなメリットでしょう
7. その他
train_stepをカスタマイズしてGANや蒸留に対応したり、作業データをDBに置いて分散コンピューティングやったりできるようです
まとめ
やりたい事はだいたい出来るようになっていますし、各探索で作ったモデルの自動保存やTensorBoardを使った可視化はとても便利です。主にkerasを使っている方にはオススメです
レッツトライ