やったこと
pythonで2次元配列データを一時保存するときによく使う
- pickle.dump
- joblib.dump
- pyarrowに変換してparquet保存
- pd.write_csv
のそれぞれについて読み書き速度と保存容量を比較しました。
結論
- 圧縮率と速度ならpickle protocol=4
- 一部だけ読んだり書いたりを繰り返すような場合はpyarrowでparquet保存
が良さそう
試行環境
CPU: Xeon E5-2630 x 2 chip
VRAM: 128GB
Windows8 64bit
python 3.6
比較に使ったデータ
機械学習用の特徴量データで試行しました
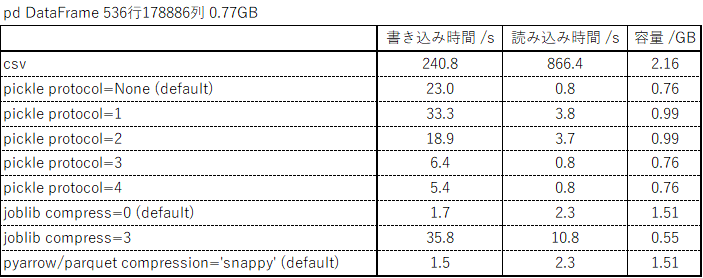
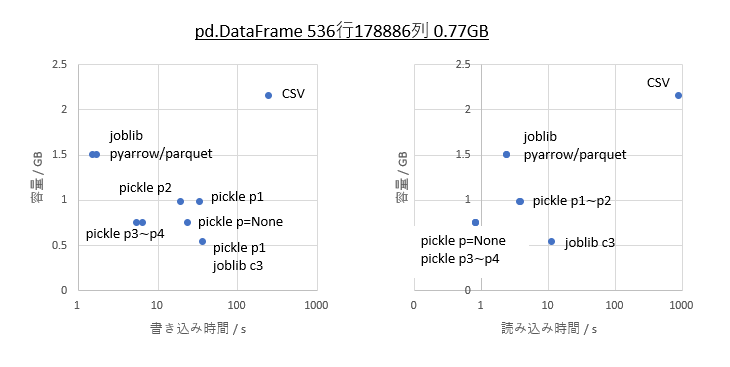
・pandas.DataFrameの 536行178886列 0.77GB
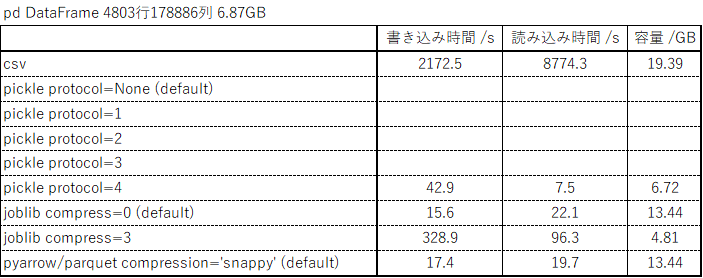
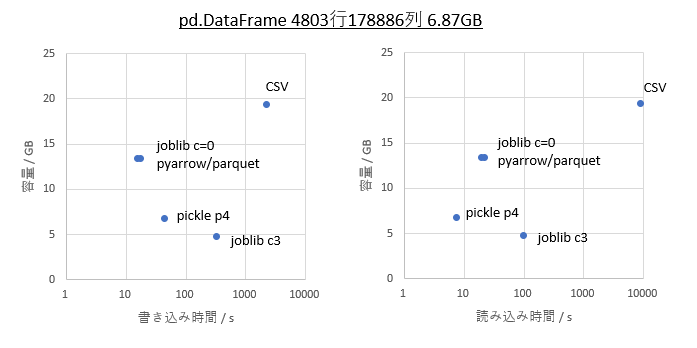
・pandas.DataFrameの4803行178886列 6.87GB
比較結果
0.77GBのDataFrame
6.87GBのDataFrame
結果について
pickle
圧縮率と速度だけ見るとpickleのprotocol=3以降が優秀で、特にprotocol=4は4GB以上の書き出しにも対応しているのでめちゃめちゃ便利です。ただし、ubuntu環境のpython3.6以前ではprotocol=4に問題があるのか読み書きともそのままでは動きません。python3.7以降では正常に動きますので、環境が確保できる場合、または容量が小さい場合はpickleが良さそうです。
joblib
pickleと比べると圧縮率も読み書き速度もちょっと中途半端ですが、python3.6環境でも4GB以上の読み書きが可能なのでpackageの都合でpythonを新しく出来ない環境の方はこちらでも良いかもしれません。
pyarrow => parquet
joblib compress=0と同等の圧縮率と読み書きの速度がありながら、指定行指定列の読み書きが可能というのが魅力です。特に書き込みが速いのでランダムに読み書きが入る場合はこれが良さそうです。
環境の影響
環境の影響はすごく大きいようで、別マシンでOSも違う環境で実験したら20倍違うところが4倍しか違わなかったりしました。実際にお使いになる環境でテストした方がよさそうです。