機械学習モデルのハイパーパラメーターの最適化の為に作られたベイズ最適化packageであるoptunaの使い方を調べたのでまとめます
optunaには何ができるか
ベイズ最適化の中でも新しい手法であるTPEを用いた最適化をやってくれます。シングルプロセスで手軽に使う事もできますし、多数のマシンで並列に学習する事もできます。並列処理を行う場合はデータベース上にoptunaファイルを作成して複数マシンから参照する事でこれを実現しますので、当該DBにアクセスできるマシンすべてが学習に参加できるのが素晴らしいところです。optunaファイルがあれば途中再開も出来ますのでお盆に会社が停電になって連休明けに再開するような場合にも安心です。
公式チュートリアル
https://optuna.readthedocs.io/en/stable/tutorial/first.html
APIリファレンス
https://optuna.readthedocs.io/en/stable/reference/index.html
本記事の内容
- シングルプロセスでの基本的な使い方
- ローカルにSQLite DBを置いて並列処理する方法
- 最適化の様子を可視化するコードと結果
サーバー上にDBを置いて使うやり方はこの記事では扱いません。
基本の使い方
ざっくり以下のような手順で使います
- optuna.create_study()でoptuna.studyインスタンスをつくる
- 最小化したいスコアを返り値とする関数を定義する
- studyインスタンスのoptimize()に2でつくった関数を渡して最適化する
公式チュートリアルのコードを実行してみます
import optuna
def objective(trial):
x = trial.suggest_uniform('x', -10, 10)
score = (x - 2) ** 2
print('x: %1.3f, score: %1.3f' % (x, score))
return score
study = optuna.create_study()
study.optimize(objective, n_trials=100)
何をどう最適化するかはすべて関数に書いて渡す仕組みです。最適化する変数はまとめてoptuna.trial.Trialとして受け取り、関数内で[x = trial.suggest_uniform('x', -10, 10)]のようにして変数に置き換えて使います。複数の変数を渡したい場合も[x2 = trial.suggest_loguniform('x2', 0.0001, 1000)]などのように書き足していけばoptuna.studyインスタンスの方でtrialに追加してくれます。どういう動作なのか分からなくて最初戸惑ったんですが、めちゃめちゃ簡潔に書けるのが素晴らしいです。
デバッグするときの変数の渡し方
optuna用の関数は変数をoptuna.trial.Trialオブジェクトとして渡さないといけないので、引数に定数を与えて動作を確認したい場合はTrialオブジェクトに変換しなければなりません。その為にあるのがoptuna.trial.FixedTrial()で、辞書型にして放り込めば変換してくれます。
objective(optuna.trial.FixedTrial({'x': 1}))
結果の見方
ベストスコアが得られたときの結果は以下のように見られます
>>> study.best_params # best_valueを出したときのparameter
{'x': 1.9515800599830937}
>>> study.best_value # 一番良いスコア
0.0023444905912408044
>>> study.best_trial #best_valueを出したときの試行内容
FrozenTrial(number=95, state=<TrialState.COMPLETE: 1>, value=0.0023444905912408044, datetime_start=datetime.datetime(2019, 8, 27, 14, 14, 46, 915766), datetime_complete=datetime.datetime(2019, 8, 27, 14, 14, 46, 922766), params={'x': 1.9515800599830937}, user_attrs={}, system_attrs={'_number': 95}, intermediate_values={}, params_in_internal_repr={'x': 1.9515800599830937}, trial_id=95)
各試行の結果もすべて保存されています
>>> type(study.trials) # 試行結果はlist型で入ってます
list
>>> study.trials[0] # 1回目の試行結果
FrozenTrial(number=0, state=<TrialState.COMPLETE: 1>, value=13.19350872351688, datetime_start=datetime.datetime(2019, 8, 27, 14, 14, 45, 722910), datetime_complete=datetime.datetime(2019, 8, 27, 14, 14, 45, 727912), params={'x': 5.6322869825382575}, user_attrs={}, system_attrs={'_number': 0}, intermediate_values={}, params_in_internal_repr={'x': 5.6322869825382575}, trial_id=0)
>>> study.trials[0].value # 1回目の試行でのスコア
13.19350872351688
>>> study.trials[0].datetime_start # 開始時間
2019-08-27 14:14:45.722910
>>> study.trials[0].datetime_complete # 終了時間
2019-08-27 14:14:45.727912
>>> study.trials[0].params_in_internal_repr # 1回目の試行のparameter
{'x': 5.6322869825382575}
個人的に開始終了時間が入っているのがポイント高いです
変数の設定方法いろいろ
最初のサンプルコードで使ったtrial.suggest_uniform()による均一分布の探索以外にもいろいろ種類があります。
def objective(trial):
# Categorical parameter
optimizer = trial.suggest_categorical('optimizer', ['MomentumSGD', 'Adam'])
# Int parameter
num_layers = trial.suggest_int('num_layers', 1, 3)
# Uniform parameter
dropout_rate = trial.suggest_uniform('dropout_rate', 0.0, 1.0)
# Loguniform parameter
learning_rate = trial.suggest_loguniform('learning_rate', 1e-5, 1e-2)
# Discrete-uniform parameter
drop_path_rate = trial.suggest_discrete_uniform('drop_path_rate', 0.0, 1.0, 0.1)
listから選ぶ、指定範囲の整数から選ぶ、指定範囲の均一分布から選ぶ、指定範囲の指数分布から選ぶ、指定範囲の離散値から選ぶなどがありますので、普通にハイパーパラメーターの最適化をするのに不足する事はないと思います。
これ以外にもいくつかありますので詳しくは以下を参照してください
https://optuna.readthedocs.io/en/stable/reference/trial.html
ローカルにSQLite DBを置いて使う
DBを使うと以下のメリットがあります
- 途中で終了しても再開できる
- 複数プロセスで並列処理ができる
ローカルにDBを置くだけなら特別に用意する必要はありません。optuna.create_study()するときにstorageとstudy_nameを設定するだけでoptunaがSQLite DBファイルをつくってくれます。load_if_exists=Trueにしておけばファイルが存在する場合は読んできて続きをやってくれますのでTrueにしておきます。
study_name = 'example-study'
study = optuna.create_study(study_name=study_name,
storage='sqlite:///../optuna_study.db',
load_if_exists=True)
study.optimize(objective, n_trials=100)
並列処理したい場合は同じstorageとstudy_nameを指定して複数プロセス実行するだけです。1つのマシンで実行する場合はterminalをずらっと並べて同じコードを実行するだけで出来ちゃうという驚異的簡単さ。
ただし、大規模に並列処理したい場合は複数の書き込みが同時に来たときに処理できないSQLiteでは上手く動きません。多分遅くなっちゃうのかな?その場合は公式ドキュメントを参照してMySQLかPostgreSQLのDBを立てて使ってください。
https://optuna.readthedocs.io/en/stable/tutorial/rdb.html
最適化の様子を可視化してみる
ipywidgetsで最適化していく様子を確認してみました。再生ボタンを押すと1つずつ点を打っていく様子が確認できます。
import numpy as np
import matplotlib.pyplot as plt
from ipywidgets import Play, IntSlider, jslink, HBox, interactive_output
values = [each.value for each in study.trials]
best_values = [np.min(values[:k+1]) for k in range(len(values))]
x = [each.params_in_internal_repr['x'] for each in study.trials]
def f(k):
plt.figure(figsize=(9,4.5))
ax = plt.subplot(121)
ax.set_xlim(np.min(x)-0.5, np.max(x)+0.5)
ax.set_ylim(np.min(values)-5, np.max(values)+5)
ax.scatter(x[:k], values[:k], alpha=0.3)
ax.scatter(x[k-1], values[k-1])
ax = plt.subplot(122)
ax.plot(best_values[:k])
ax.set_yscale('log')
plt.show()
play = Play(value=1, min=0, max=len(study.trials), step=1, interval=500, description="Press play",)
slider = IntSlider(min=0, max=len(study.trials))
jslink((play, 'value'), (slider, 'value'))
ui = HBox([play, slider])
out = interactive_output(f, {'k': slider})
display(ui, out)
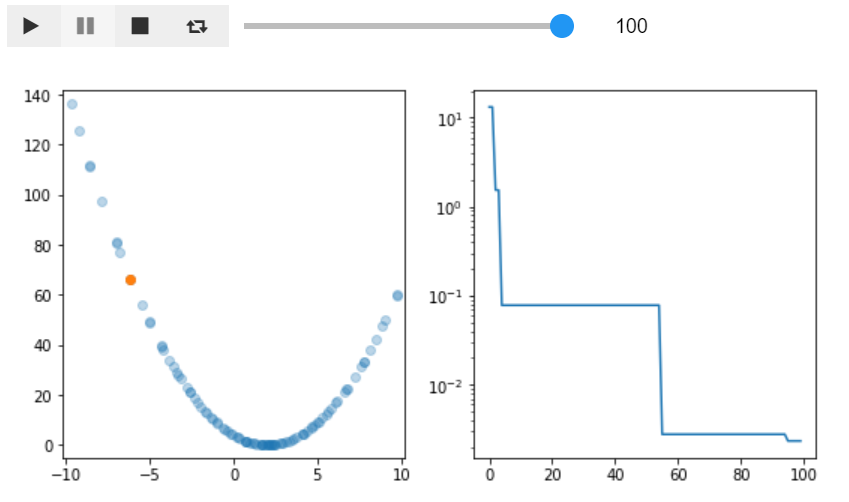
とりあえず見たい方はこちらもどうそ
https://twitter.com/studio_haneya/status/1166195464984616961
最適化の様子を可視化してみる: その2
import optuna
import numpy as np
import matplotlib.pyplot as plt
from ipywidgets import Play, IntSlider, jslink, HBox, interactive_output
# 正弦波を足してlocal minimumのある関数を作成
def objective(trial):
x = trial.suggest_uniform('x', -50, 60)
score = x ** 2 + np.sin(x/5)*2000 + 1939.7
print('x: %1.3f, score: %1.3f' % (x, score))
return score
# 最適化を実行
study = optuna.create_study()
study.optimize(objective, n_trials=200)
# 結果をプロットする為に値を加工
values = [each.value for each in study.trials]
best_values = [np.min(values[:k+1]) for k in range(len(values))]
x = [each.params_in_internal_repr['x'] for each in study.trials]
# プロットする関数
def f(k):
plt.figure(figsize=(9,4.5))
ax = plt.subplot(121)
ax.set_xlim(np.min(x)-5, np.max(x)+5)
ax.set_ylim(np.min(values)-300, np.max(values)+300)
ax.scatter(x[:k], values[:k], alpha=0.3)
ax.scatter(x[k-1], values[k-1])
ax = plt.subplot(122)
ax.plot(best_values[:k])
ax.set_yscale('log')
plt.show()
# ipywidgetで表示
play = Play(value=1, min=0, max=len(study.trials), step=1, interval=500, description="Press play",)
slider = IntSlider(min=0, max=len(study.trials))
jslink((play, 'value'), (slider, 'value'))
ui = HBox([play, slider])
out = interactive_output(f, {'k': slider})
display(ui, out)
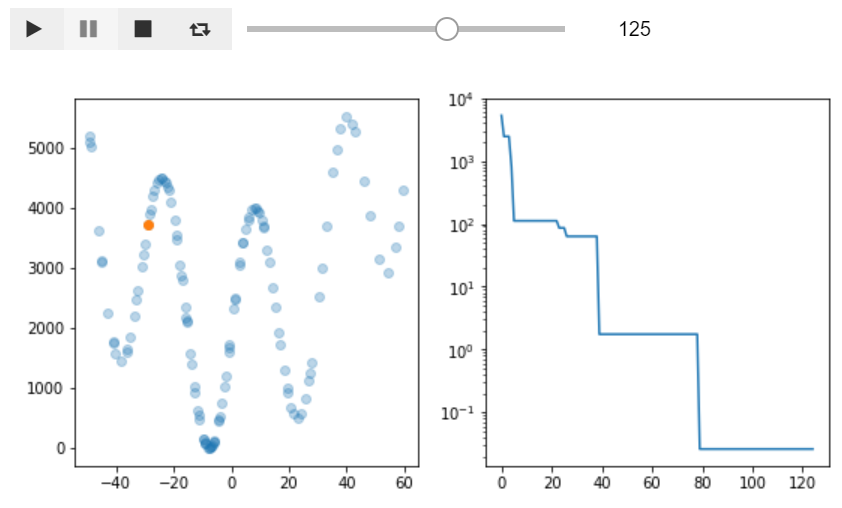
全体像を的確に探りつつlocal minimumにひっかかる事なく最適値付近にたどり着いているのが素晴らしいです。
まとめ
optunaめっちゃ良いのでみんな使うべき
更新履歴
20190829 ローカルにSQLite DBを置いて使う方法を追記