forest plotとはそもそもメタ解析の結果表示につかう図表です。
ただ、交互作用の検討をしたり、いわゆるサブセット解析をした時にそのサブセットごとで結果が違うかどうかを考えたりする場合の視覚化にも有効です。
多くの場合この方法はrelative riskやodds ratioを考えるときに使われますが、医学統計の場合盲目的にcox回帰を用いることも多いですので、その時のhazard ratio(HR)でも同じことを考えることが出来ます。
Rではパッケージとしてrmetaなどが準備されていますが、実はこれはオッズを考える場合の分割表を想定して作っているので、HRのforest plotを考えるときは、自作しなくてはなりません。
自作となると単にplot関数をうまく使うのもいいのですが、前々からggplotという関数群に興味があったので、今回はこれを使ってみることにしました。
準備するデータの形式
| 変数 | HR | lower | upper |
|---|---|---|---|
| type1 | 1.6 | 1.5 | 2 |
| type2 | 1.4 | 1.2 | 2.6 |
type3 | 1.1 | 1 |1.4
type4| 1.3 | 1.2 |1.9
type5| 1.1 | .9 |1.2
type6| 7 | .8 |14
それぞれ確かめたいHRを調べて、変数の名前、点推定値(HR)、95%信頼区間の下限(lower),95%信頼区間の上限(upper)を表にしておきます。HRの計算法は他のトピックで取り上げます。
Rでの解析
まず必要なパッケージを読み込ませます。
require(ggplot2)
require(survival)
もちろんない人はinstall.packages()で落としてみてください。
なお、ggplot2もあまり古い物の場合使えない可能性があるので、Rでははできるだけ最新のものの方が良いです。
次にデータを読み込みます。
DATA<-read.csv(file.choose(),header=T)
もちろんディレクトリをいつも意識して仕事ができている人はfile.choose()である必要はありません。
なお一行一行読んでいく人のために補足ですが、最後のスクリプトで縦横を逆転させます。
また医学統計でサブセット解析をするときは、往々にして症例数の少ないサブセットで大きなHRになることが多いですので、はじめからHRはlogを付けて表示するようにしています。
re<-ggplot(DATA,aes(x=変数, y=log(HR))) #変数はいわゆるサブセット解析した時の項目です。
re<-re+ylim(-1,5)#ここではHR(log(HR))の大きさ(横軸の最小値、最大値)を規定しています。
re<-re+geom_point(size=5,sharp=7) #信頼区間の設定1
re<-re+theme_bw()+theme(panel.grid.major.x=element_blank()) #信頼区間の設定2
re<-re+geom_errorbar(aes(ymin=log(lower),ymax=log(upper)),width=0.2,size=.50) #信頼区間の設定3
re<-re+geom_hline(yintercept=log(1),linetype=2,col="blue") #ハザード比1.0に点線挿入
re<-re+coord_flip() #図を横に
これで
re
と押すと結果が出てきます。
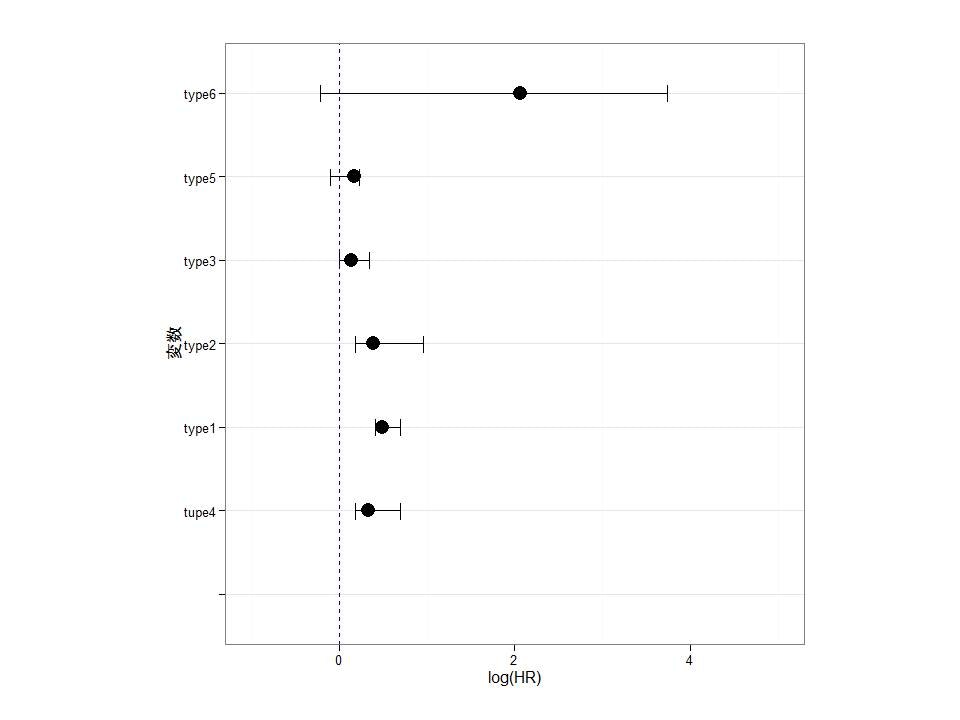
logをとっているのがよくわからないかな?いや、log(1)=0なのでわかっていただけるか・・・。
ちなみに今回はこの投稿を参考にさせていただきました。