この記事は HDL Advent Calendar 2021 18日目の記事です。
序文
高性能な回路(ASIC,FPGA)を設計する上で避けては通れないのが、設計した回路で生じる配線遅延。論理的に高性能な回路を設計できたとしても、チップ上で巧妙に回路を配置配線できなければ、余計な配線遅延が生じ、回路の性能を最大限に発揮することができなくなります。しかし、配線遅延が性能に直結することは回路設計をやっている人は存じ上げているとして、実際に配線遅延ってどのくらい生じるのかを調べることってそうそう無いですよね。(というより,配線遅延をわざわざ調べるよりも配線遅延を想定した回路設計を行うほうが早いです)
ということで、今回はFPGAチップ上で配線遅延がどのくらい生じるのかについて実際に調査してみます。
※もし間違ってるところ等があれば遠慮なくコメントして下さい。
前提知識
FPGAについて
FPGA は Field Programmable Gate Array の略で、日本語に直訳すると「現場で構成可能な回路アレイ」となります。内部の集積回路を自由に書き換え可能なので、ハードウェアでありながらソフトウェア的な設計が可能なのが特徴です。よくASICと比較されますが、ASICとFPGAは共にユーザが集積回路を自由にカスタマイズできる一方、ASICは一度製造すると回路情報の修正ができない点や、用途に合わせてICを製造するため費やす時間や費用が大きい点がFPGAと異なります。ただし、ASICはユーザ向けに配線や実装面積を最適な内容で設計可能であるため、FPGAと比べてより高性能な集積回路が期待できます。
ざっくり説明しましたが、本題ではないため詳細な内容はXillinxの公式ページを読むと良いです。FPGAのこと知らないよーという方は開いてみてください。
配置配線とは?
さて、FPGAを用いた回路設計を行う際、基本的には以下の図のようなフローを辿って設計が行われます。

"XilinxのHPより引用"
FPGAを用いた回路設計を行う場合、「全体設計→HDLによるコーディング→論理合成→RTL/実遅延シミュレーション→配置配線→実機テスト」といったプロセスを踏むことが多いです。HDLで記述された回路を合成し、シミュレーションや実機テストで正常な回路動作を確認することがゴールなら気にすることは無い(設計ツールが自動的に行ってくれるため)ですが、設計した回路の性能向上を目指すならば、配置配線のプロセスが重要になってきます。
配置配線とは、論理合成によって出力された回路をFPGA内部へ実装する際の配置場所を決定する作業のことです。
FPGAチップ内部には、あらかじめ書き換え可能な専用回路が構築されており、回路間を接続するための配線も準備されています。配置配線を行うことで、論理合成で変換されたFPGA回路の配置場所や、回路同士が接続される経路の決定をします。各回路の規模に応じて配置面積を指定することで、回路規模・配線範囲が不必要に大きくなることを抑制できます。また、巧妙に配置配線を行うことによって、配線遅延のコントロールが可能となり、設計回路特有のタイミング制約を考慮した設計を行うことができます。
以上から、FPGA回路設計において、配置配線のプロセスは重要な役割を担っていることが分かります。
この配置配線をユーザが実施する場合、IntelFPGAではLogicLock機能、XillinxFPGAではPblock機能を使用することで実現できます。
FPGA設計における配線遅延の影響
配置配線を行うことによって、回路のタイミング制約を考慮した設計が可能となり、配線遅延の影響を減らせることは前述の通りです。しかし、実際に回路を配置した際にどのくらいの配線遅延が生じるのか、最大でどのくらいの配線遅延が生じるのかを検証することは滅多に無いと思われます。えっあります...?あったらごめんなさい
そこで、本記事ではFPGAチップ上に回路実装した際の配線遅延がどのくらい生じるのかを検証していきます。
調査
調査環境
今回はIntel(発売時はALTERA)のMAX10(10M50DAF484C6GES)チップを対象に検証を行います。
回路記述言語:VerilogHDL
FPGA設計ツール:Quartus Prime 18.1
Compiler Setting:Performance(high effort - increases runtime)
使用モデル:Slow 1200mV 0C Model
調査内容
1bitレジスタを2個用意し、Quartus Prime(以下Quartus)のLogicLock機能を用いて任意の場所に配置配線を行い、タイミング解析結果からそれぞれの配線遅延を算出し、比較します。
回路構成
使用した回路構成とVerilogコードを以下に記します。

回路構成は上図のようになっています。1bitのレジスタを持つDLを2個繋げた簡単な構成となっています。
module TOP(
clock,
dl_in,
dl_out
);
input wire clock;
input wire dl_in;
output wire dl_out;
wire dl_wire;
DL DL1 (
.IN(dl_in),
.CLK(clock),
.OUT(dl_wire)
);
DL DL2 (
.IN(dl_wire),
.CLK(clock),
.OUT(dl_out)
);
endmodule
module DL (
IN,
CLK,
OUT
);
input wire IN;
input wire CLK;
output reg OUT;
always @(posedge CLK) begin
OUT <= IN;
end
endmodule
回路記述はこちらになります。要は1bitレジスタを2個繋げているだけです。
回路の設計ができたら論理合成を行います。このとき、ピンアサインも同時に行います。
配置配線
Quartusに付属している、ChipPlannerを用いて回路の配置配線を行います。ChipPlannerではLogicLock機能を利用することができ、回路を論理ブロック単位で固定することで配置配線を決定可能となり、これによって回路を自由に配置することが可能です。
今回の調査では、
- 同一論理ブロック内に回路を配置した場合
- 論理ブロックを隣り合わせに配置した場合
- 論理ブロックを斜め隣に配置した場合
- FPGAチップ全体を使って配置した場合
の大きく4つのパターンについて検証を行いました。配置した様子については後述します。
LogicLockの設定が行えたら、再度回路合成を行います。
タイミング解析
再合成した回路をタイミング解析し、配線遅延を調査します。今回のタイミング解析ではQuartusに付属しているTimingAnalyzer機能をGUI画面で利用します。TCL文を使ってCUIでタイミング解析するのも良いと思います。
-
QuartusのTable of Contents のTiming Analyzerの中にあるSlow 1200 0C Modelの項目を右クリックし、Generate report in Timing Analyzerを選択。
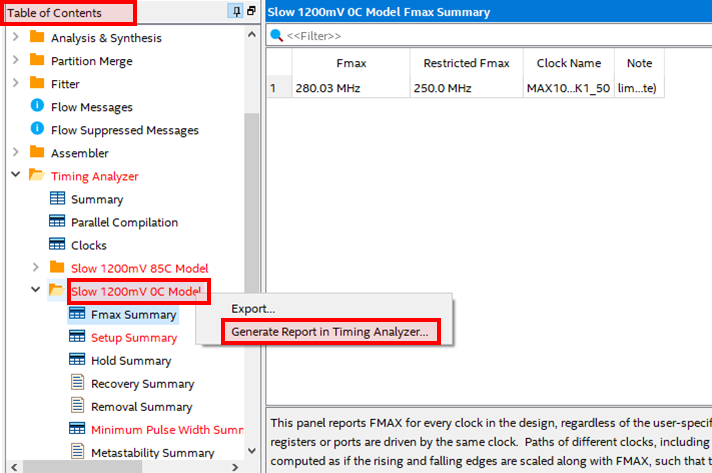
-
Timing Analyzerのウィンドウが開くので、Clock Nameが自身で設定した名前(この例ではピンアサインの際にMAX10_CLK1_50と設定)になっていることを確認。Clock Nameを右クリックし、Report Timing...を選択。
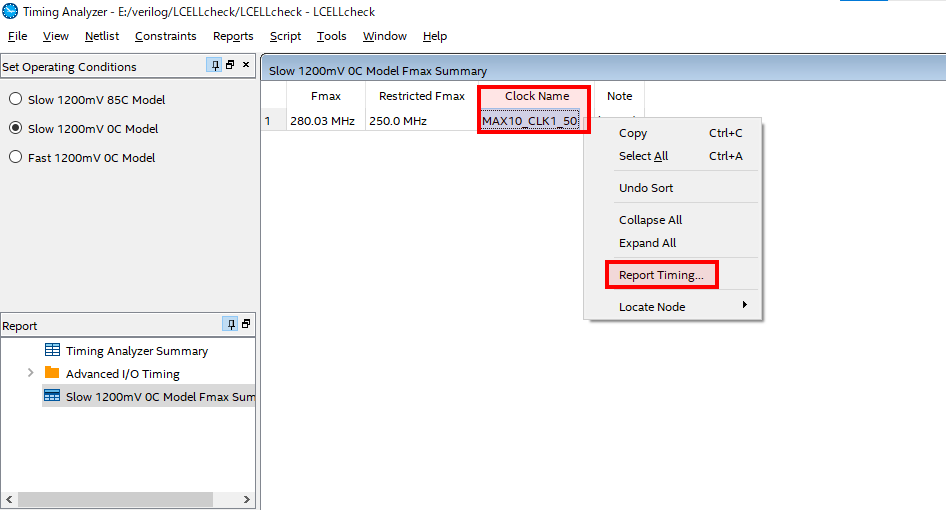
-
Report Timingのウィンドウが開くため、最下部のReport Timingをクリック。(この画面ではTimingReportの設定が行え、私の設定は画像の通りとなっています。ウィンドウが開いたらデフォルトの設定でReportの出力を行っています。)
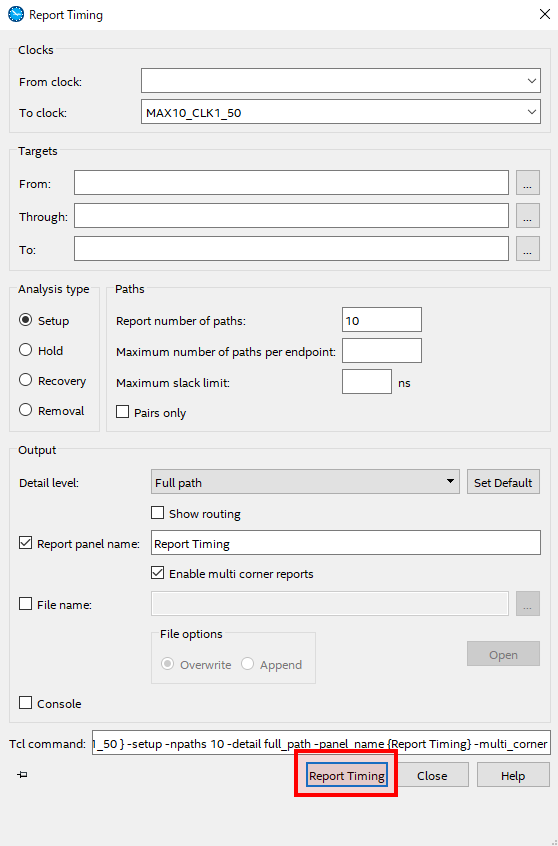
-
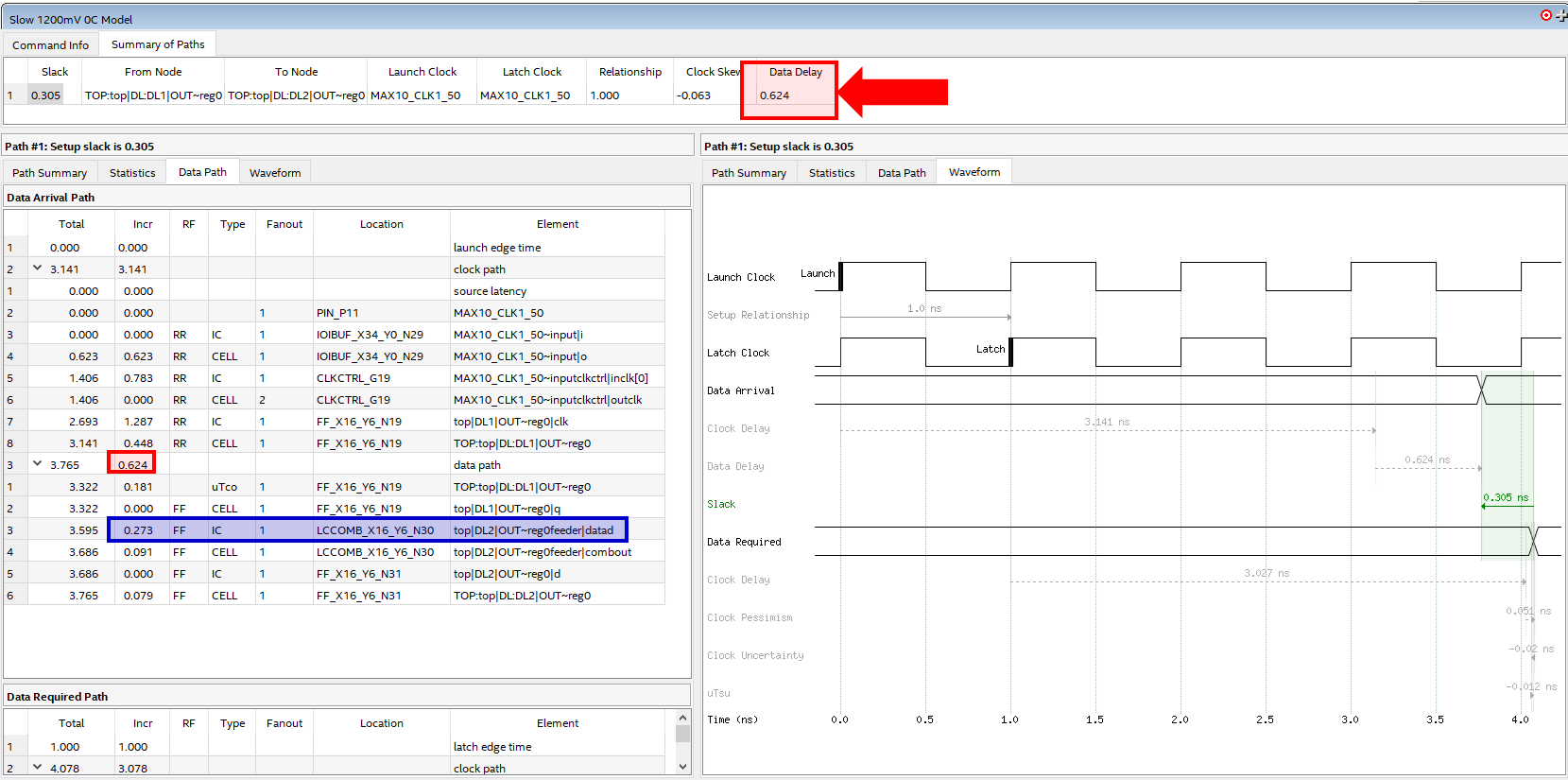
タイミング解析の結果が画面に出力される。信号の経路情報と遅延時間のグラフが表示されていることを確認。入力用レジスタから出力用レジスタまでの経路における遅延時間がData Delayに示されているため確認。
※配線遅延による影響を直接受けると考えられる経路は青枠で囲われた行だと推測されますが、本記事ではレジスタの入出力にかかる時間を含めた赤枠で囲われた時間について調査します。
以上がタイミング解析の流れとなります。これを各配置配線のパターンにおいて実行し、遅延時間の調査を行います。
調査結果
各配置配線について、調査した結果について記します。
同一論理ブロック内に回路を配置した場合
同一論理ブロック内に回路を配置した場合の一例を以下の図に示します。
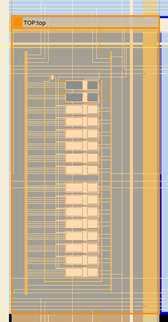
論理ブロックは16個の論理素子からなっており、本調査においてはそれぞれの論理素子が入力レジスタと出力レジスタに対応しています。論理素子の配置を変更し、配置間隔を大きくすることで、配線遅延にどのくらい影響が現れたかを調査しました。
同一論理ブロック内の論理素子の位置による配線遅延の比較を以下のグラフに示します。
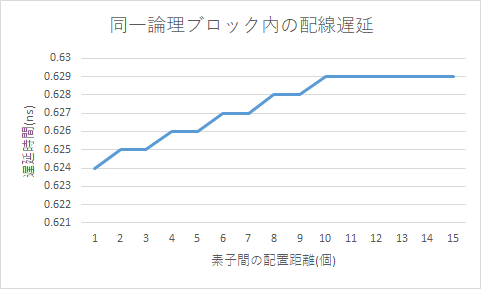
論理素子間の距離が延びることで、配線遅延も長くなることが確認できました。また同時に、遅延時間の目盛りから時間の変動は0.624ns~0.629nsの間で起こっていることから、論理ブロック内の配線遅延はほとんど差異が無いことも分かりました。
論理ブロックを隣り合わせに配置した場合
入力レジスタから隣り合わせに論理ブロックを配置した場合について以下の図に示します。
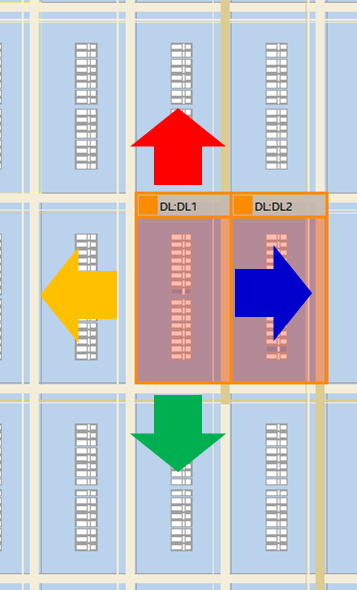
図の例では出力レジスタを入力レジスタの右に配置した場合について示しており、矢印の青の向きに信号が伝達されます。
各矢印方向に出力レジスタを含む論理ブロックを配置した場合について調査した結果を、表にまとめました。なお、前節の調査で論理ブロック内での遅延時間がほとんど変わらなかったことから、論理素子の配置についてはQuartusの自動配置に任せるものとします。
| 配置位置 | 遅延時間(ns) |
|---|---|
| 左ー右(青色経路) | 0.731 |
| 上ー下(緑色経路) | 0.893 |
| 右ー左(黄色経路) | 0.747 |
| 下ー上(赤色経路) | 0.747 |
| 平均 | 0.7795 |
同一論理ブロックで配置配線したときと比較して、0.1~0.25ns遅延時間が延びました。下-上の経路が他の経路と比較して値が大きいことが少々気になりますが、予想できる範囲の結果が返ってきています。TimingReportを確認したところ、下ー上の経路だけレジスタ入力にかかる時間が長くなっていました。よって、他の経路と配線遅延に大きな差異はないと考えられます。
論理ブロックを斜め隣に配置した場合
入力レジスタから斜め隣に論理ブロックを配置した場合について以下の図に示します。
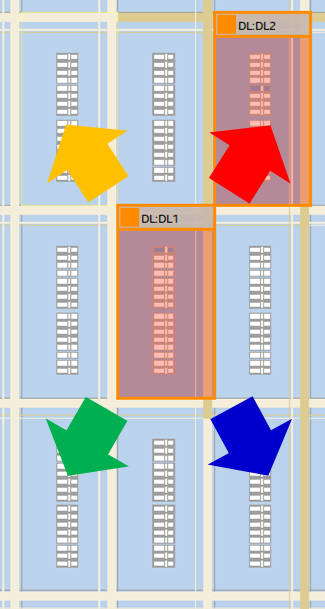
図の例では出力レジスタを入力レジスタの右上に配置した場合について示しており、矢印の赤の向きに信号が伝達されます。
各矢印方向に出力レジスタを含む論理ブロックを配置した場合について調査した結果を、表にまとめました。こちらも論理素子をQuartusの自動配置に任せるものとします。
| 配置位置 | 遅延時間(ns) |
|---|---|
| 左下ー右上(赤色経路) | 1.017 |
| 左上ー右下(青色経路) | 0.979 |
| 右上ー左下(緑色経路) | 1.051 |
| 右下ー左上(黄色経路) | 0.923 |
| 平均 | 0.9925 |
論理ブロックを隣り合わせに配置した場合よりも遅延時間が0.213ns増加しました。隣り合わせの場合よりも配線距離が延びたことが配線遅延が増加した要因だと考えられます。特に、隣り合わせの場合は縦か横のどちらかの配線を利用していましたが、この場合は縦と横の両方の配線を利用していることも影響していると考えられます。
FPGAチップ全体を使って配置した場合
MAX10FPGAチップの全体図を以下に示します。図の矢印の位置にそれぞれ入力レジスタと出力レジスタを配置し、配線遅延を調査しました。
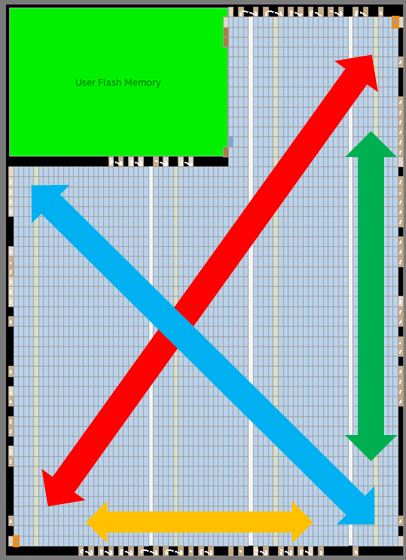
調査はチップの左下から右上までの経路(斜め方向)、右下から左上までの経路(斜め方向)、左下から右下の経路(横方向)、右上から右下の経路(縦方向)について行いました。今回対象としているMAX10FPGAは左上にFlash Memoryのブロックが存在するため、斜め方向の経路は2種類用意しています。
調査結果は以下のようになりました。
| 配置位置 | 遅延時間(ns) |
|---|---|
| 左下ー右上(赤色経路) | 3.784 |
| 右下ー左上(青色経路) | 3.472 |
| 左下ー右下(黄色経路) | 2.398 |
| 右上ー右下(緑色経路) | 2.387 |
FPGAチップ全体を使った場合、距離に対応して配線遅延も大きくなることが確認できました。配線遅延は最大で3.784nsとなり、縦・横のみの経路の場合(緑色・黄色の経路)よりも斜めの経路(赤色・青色の経路)のほうが配線遅延が大きくなることも数字で確認することができました。
ちょっとした考察
配線遅延の調査を行った結果、最小遅延時間が0.624ns(論理ブロック内での配線遅延)、最大遅延時間が3.784ns(FPGAチップの端から端までの配線遅延)となりました。
配線距離が長くなることで配線遅延も大きくなることは予想できましたが、実際に数値で確認することで気づけることも多くあったと思われます。
また、このような配線遅延の検証を行うことで、設計した回路の性能向上を図るための検討要素としても利用できるのではないかと思われます。いや、必要ないかもしれないけど
今回はMAX10FPGAについて調査しましたが、XillinxFPGAはもちろんのこと、IntelFPGAでもArriaシリーズやStratixシリーズ等、沢山の製品が展開されているため、製品によって結果が異なることが予想されます。
まとめ
本記事では、FPGAで回路設計する際に生じるであろう配線遅延について調査を行いました。
MAX10のFPGAを用いて調査した結果、同一ブロック内なら0.35ns、隣合わせのブロックなら0.7ns、チップ上の端から端まで配線した場合の最大値が3.784nsという結果となりました。数字にちゃんと現れると楽しいね!
なお、FPGAチップによって回路面積やアーキテクチャが違うため、本記事の検証結果と同じ結果になることはまず無いとは思います。あくまで一例として身に留めて頂けると嬉しいです。XillinxFPGAで似たようなこと試している人とかいないかな...
いかがでしたでしょうか?????????
参考文献
- ザイリンクス FPGA 講座 第一章 FPGA とは, https://japan.xilinx.com/japan/fpga-koza/chapter01.html
- Tech Village 電子・組み込み技術の総合サイト FPGAを使い始めるための基礎知識 ―― 開発フローとやるべき作業を理解する, http://www.kumikomi.net/archives/2009/04/fpga.php?page=2
- Quartus II - Chip Planner クイック・ガイド - マクニカ, https://www.macnica.co.jp/assets/arc/members/japanese/download/chipplan_v90.pdf
- Timing Analyzer - インテル, https://www.intel.co.jp/content/dam/altera-www/global/ja_JP/pdfs/literature/ug/ug-qpp-timing-analyzer-j.pdf