なぜ Language Translator を試したのか
2017年10月27日に、機能を絞って無期限・無料で利用できる「IBM Cloudライト・アカウント」がリリースされました。
ライト・アカウントで無料で使える範囲で Watson で何ができるのか試してみるべく、私も Language Translator という言語翻訳用の API を試してみることにしました。
Watson の API にもいろいろある中で Language Translator を選んだ理由は下記の通りです。
- 仕事面では、既存のアプリケーションに翻訳機能を組み込みたい場合に使えそう。 ちなみに、2017/11/20 時点でのサポート対象言語についてのドキュメントでは、ニュース(News)については英語と日本語との間で翻訳できるようになっているらしいです。 会話(Conversational)や特許(Patent)については未対応らしいです。
- 言語サポートのドキュメントは 2018年6月時点では 翻訳モデルを見ると良いでしょう
- プライベート面では、いろいろな言語のテキストを読み込ませて言語判別するのに使えそう。上記のサポート対象言語についてのドキュメントによると、62種類の言語を識別できるそうです。
Language Translator を使って何を試すのか
ちょっと試してみるだけなら、日本語と英語との間の翻訳なんてネタはもうとっくにいろいろな人が取り組んでいそうですよね。仕事に応用できそうなネタだと、Notes から Java 経由で呼び出したい場合にすぐ参考になりそうな記事を書いていただいている方もいます。
そこで、ここでは単純に翻訳するだけではなく、62種類の言語を識別する機能も活用して、下記のようなチャットbot を作成してみましょう。
仕様は次の通りです。
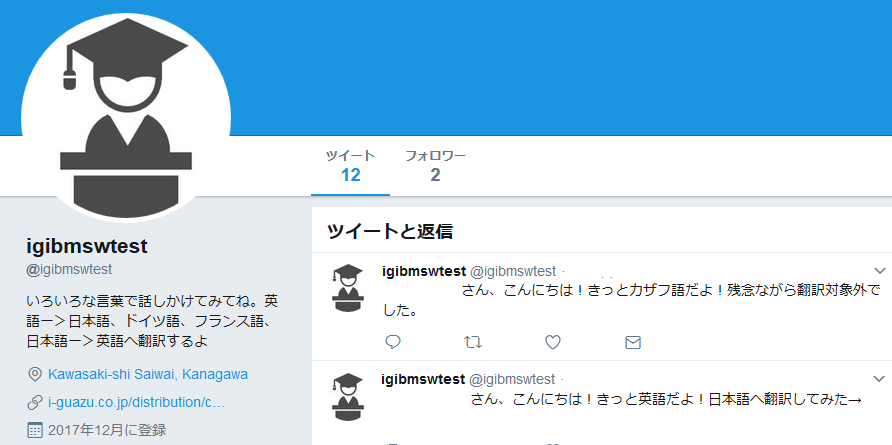
- @igibmswtest に話しかけると、言語を識別する。
- 識別結果を元に、News 翻訳機能を使って英語なら日本語へ翻訳する。
- 英語へ翻訳可能な言語の場合、英語へ翻訳する。
- 2018/01/09 時点では、下記の言語のニュースを英語へ翻訳可能ですが、このうちフランス語、ドイツ語、日本語を英語へ翻訳します。
- Arabic (アラビア語), Brazilian Portuguese (ブラジル・ポルトガル語), French (フランス語), German (ドイツ語), Italian (イタリア語), Japanese (日本語), Korean (韓国語), Spanish (スペイン語)
- 話しかけてきたアカウントへ識別した言語、信頼度および翻訳結果を返信する。
- 識別の信頼度 (最高は 1、最低は 0) が低すぎる場合は、翻訳しない。信頼度と言語名を返信する。
- 識別できたが翻訳に対応していない言語の場合も信頼度と言語名を返信する。
Bot のイメージです
どうやって試したか
概要
NODE-RED 上のフローと、各ノードの概要です。
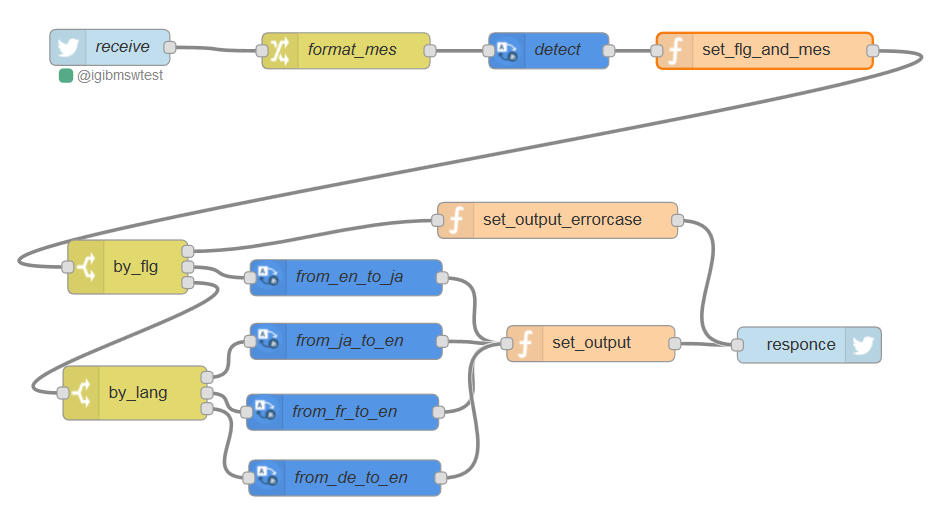
| ノード名 | ノードの種類 | 作用 |
|---|---|---|
| receive | ソーシャル > twitter in | 他のアカウントからの話しかけを拾う |
| format_mes | 機能 > change | つぶやきの中で不要な文字列を除去 |
| detect | IBM Watson > language.identify | 言語を識別 |
| set_flg_and_mes | 機能 > function | 識別結果を元に、 直後の処理分岐に使うフラグおよび出力メッセージを準備 |
| by_flg, by_lang | 機能 > switch | 処理分岐 |
| from_en_to_ja | IBM Watson > language.translator | 英語から日本語への翻訳 |
| from_ja_to_en, from_fr_to_en, from_de_to_en | 同上 | 英語への翻訳 |
| set_output, set_output_errocase | 機能 > function | 出力メッセージの設定 |
| responce | ソーシャル > twitter out | 話しかけてきたアカウントへ返信 |
receive ノードから detect ノードまで
他のアカウントからの話しかけを拾うには、つぶやきの中に @igibmswtest が含まれているものを拾う必要があるので、検索条件に @igibmswtest を指定しています。条件に合致したつぶやきがあると、msg オブジェクトとして返されます。
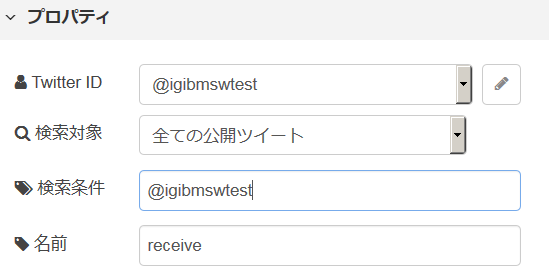
msg オブジェクトのうち、msg.payload がつぶやきテキストに該当します。このうち、receive ノードの検索条件に指定した文字列は、残しておく必要は無いので除去します。
- 他のアカウントへ返信するときにもそのまま含まれていると、そのつぶやきをまた receive ノードで拾って永久ループみたいになってしまいます。
- 言語を識別するときも邪魔になります。
後にスペースが複数ある可能性と、文字列そのものが複数回繰り返されている可能性を考えて正規表現でスペース一個へ置換しています。 - msg.payload をデバッグノードを使って確認すると、Web ページ上のテキストをコピーしてきてつぶやきに使うと、URL もこっそり含まれてしまうようです。この URL データも言語の識別には邪魔になるので、正規表現で可能な限り除去してみました。
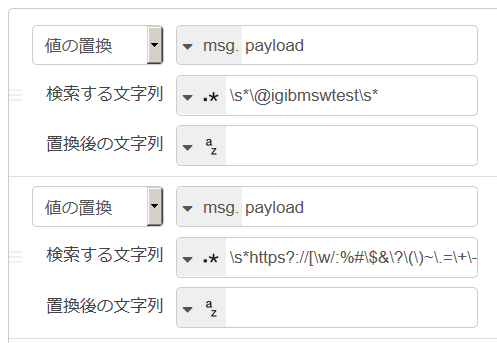
以上を detect ノードに与えると、msg オブジェクトの中に msg.lang.なんとか というプロパティーが増えて識別された言語を示す ID (msg.lang.language)、信頼度 (msg.lang.confidence)、複数の言語についての判定結果の配列などが返ってきます。
set_flg_and_mes ノード
msg.lang.language および msg.lang.confidence をもとに出力メッセージの一部を組み立てます。
このメッセージをどこかに取っておく必要があります。一箇所にまとまっているほうが私にはわかりやすいので、msg オブジェクトの中に新しいプロパティー (msg.lang.mydetect)を作ってそこに保存することにしました。 これだと、言語関係の何か、しかも自分が追加したプロパティーだ、ということがしばらく時間たってからコードを見返してもわかりやすいはず。
by_flg ノードで日本語への翻訳、英語への翻訳および翻訳しない場合を分岐させるためのプロパティーも新しく msg.lang.myflg を作って保存することにしました。新しいプロパティーは、保存したときに作られます。
var langname = {
'af':'アフリカーンス','ar':'アラビア','az':'アゼルバイジャン',
'ba':'バシキール','be':'ベラルーシ','bg':'ブルガリア',
'bn':'ベンガル','bs':'ボスニア',
'ca':'カタルーニャ(カタロニア)','cs':'チェコ','cv':'チュヴァシ',
'da':'デンマーク','de':'ドイツ',
'el':'ギリシャ','en':'英','eo':'エスペラント',
'es':'スペイン','et':'エストニア','eu':'バスク',
'fa':'ペルシア','fi':'フィンランド','fr':'フランス',
'ga':'アイルランド','gu':'グジャラート',
'he':'ヘブライ','hi':'ヒンディ','hr':'クロアチア',
'ht':'ハイチ','hu':'ハンガリー','hy':'アルメニア',
'id':'インドネシア','is':'アイスランド','it':'イタリア',
'ja':'日本',
'ka':'ジョージア(グルジア)','kk':'カザフ','km':'中央クメール',
'ko':'韓国・朝鮮','ku':'クルド','ky':'キルギス',
'lt':'リトアニア','lv':'ラトビア',
'ml':'マラヤーラム','mn':'モンゴル',
'ms':'マレー','mt':'マルタ',
'nb':'(ブークモール)ノルウェー','nl':'オランダ','nn':'(ニーノシュク)ノルウェー',
'pa':'パンジャーブ','pl':'ポーランド','ps':'パシュトー',
'pt':'ポルトガル',
'ro':'ルーマニア・モルドバ','ru':'ロシア',
'sk':'スロバキア','sl':'スロベニア',
'so':'ソマリ','sq':'アルバニア',
'sr':'セルビア','sv':'スウェーデン',
'ta':'タミール','te':'テルグ','th':'タイ',
'tr':'トルコ','uk':'ウクライナ','ur':'ウルドゥー',
'vi':'ベトナム',
'zh':'中国','zh-TW':'繁体字中国'
};
var msgtemp ,msgtemp2, swflag;
//自分以外から呼びかけられたら返信を作成
if (msg.tweet.user.screen_name !== 'igibmswtest') {
msgtemp = '@' + msg.tweet.user.screen_name + ' こんにちは!';
}
msg.params = {in_reply_to_status_id:msg.tweet.id_str};
if (msg.lang.language in langname === false) {
msg.mydetect = msgtemp + "ごめんなさい、どこの言葉かわかりませんでした。";
msg.myflg = -1;
return msg;
}
var translatable_to_en = [
'ar', 'bg', 'cs', 'da', 'de', 'el', 'es', 'et',
'fi', 'fr', 'he', 'hi', 'hr', 'hu', 'it', 'ja', 'ko',
'nb', 'nl', 'pt', 'pl', 'ro', 'ru', 'sk', 'sl', 'sv',
'tr', 'zh', 'zh-TW'
];
var do_translate_to_en = [
'ja', 'ru', 'tr', 'zh', 'zh-TW',
//test new languages
'bg', 'et'
];
var translatable_to_ja = ['en'];
if (msg.lang.confidence >= 0.9) {
msgtemp += "きっと";
msgtemp2 = "語だよ!";
} else if (msg.lang.confidence >= 0.6) {
msgtemp += "たぶん";
msgtemp2 = "語かなぁ。";
} else if (msg.lang.confidence >= 0.3) {
msgtemp += "もしかしたら";
msgtemp2 = "語かも。";
} else {
msgtemp += "ひょっとして"
msgtemp2 = "語かも?";
}
msgtemp += langname[msg.lang.language] + msgtemp2 ;
if (msg.lang.confidence >= 0.3) {
if (translatable_to_ja.indexOf(msg.lang.language) >= 0) {
msgtemp += "日本語へ翻訳してみた→";
swflag = 1;
} else if (translatable_to_en.indexOf(msg.lang.language) >= 0) {
if (do_translate_to_en.indexOf(msg.lang.language) >= 0) {
msgtemp += "英語へ翻訳できます→";
swflag = 2;
} else {
msgtemp += "英語へ翻訳できますが、今はテスト対象外です。";
swflag = -1;
}
} else {
msgtemp += "残念ながら翻訳対象外でした。";
swflag = -1;
}
} else {
msgtemp += "他にも試してみてね。";
swflag = -1;
}
msg.lang.mydetect = msgtemp;
msg.lang.myflg = swflag;
return msg;
by_flg ノードから最後まで
by_flg ノードでは、msg.lang.myflg の値により分岐させた後、by_lang ノードでは msg.lang.language の値により分岐させています。
今は格好悪いですが、日本語から英語への翻訳、フランス語からの翻訳、ドイツ語からの翻訳でそれぞれノードを用意しています。
翻訳元の言語コードを変数で渡す方法がわかり次第、by_lang ノードによる分岐は不要になります。
最後に、翻訳結果の文字列を set_output ノードで追加して、responce ノードでつぶやきます。返信先のアカウントは、すでに set_flg_and_mes ノードの処理で msg.lang.mydetect の先頭に設定済みです。
msg.payload = msg.lang.mydetect + msg.payload;
if (msg.payload.length > 200) {
msg.payload = msg.payload.substr(0, 200) + ' (以下略)';
}
return msg;
終わりに
最初はマニュアルを見てもわからないことだらけでつまづいていたのですが、作業の途中でデバッグノードを各所で使用して、msg オブジェクトの各プロパティーの値を確認しながら作業を進めていくことにより、想定していた仕様にあう動作をしているかどうか確信を持ちながら開発を進めていくことができました。
他の仕事の合間を縫って、2017年12月22日金曜日から着手し、28日水曜日に完成しました。何とか 2017年のうちにリリースしたいと思っていたので間に合いました。
- 2019/03/26 追記。Node.js エディターからエクスポートしたフロー、および function 部分は重複してコードをコピーして Github に共有 しておきました。
参考文献
-
はじめてのNode‐RED
- 特に、28ページから47ページの 3.1「Node-RED」 の基本、3.2「フロー」の作り方、3.3「functionノード」でデータ加工。
-
初めてのWatson APIの用例と実践プログラミング
- 特に、172ページから 177ページの 5.4.5 Twitter との連携を実装、5.4.6 function 部品の設定。
- set_flg_and_mes の返信作成で msg.params を設定していますが、これは、Node-REDのTwitter botでリプライ形式にする を参考にさせていただきました。
2019/09/19 追記
- set_flg_and_mes にて、英語へ翻訳可能な言語の配列を用意しました。2019/08/22 時点では 29 種類です。カタルーニャ語 (言語コードは ca) は、英語ではなくスペイン語 (同じくes) との間だけで翻訳可能なため配列から省いています。
- 2019/08/22 時点で識別可能な言語 70 種類を反映しました。
- グルジア語はジョージア(グルジア)語、カタロニア語はカタルーニャ(カタロニア)語と表示されるように変更しました。
- 私の趣味で、下記の言語を話しかけた時に英語へ翻訳できるかテストするロジックにしました。日本語、ロシア語、トルコ語、繁体字中国語、中国語、ブルガリア語、エストニア語
- ブルガリア語およびエストニア語は、2019/08/22 時点で新たに翻訳対象として使用できるようになった6種類の東ヨーロッパ言語のうちの2種類です。このほかクロアチア語、スロバキア語、スロベニア語、ルーマニア語が使用できるようになっていました。
- set_output にて、文字列の長さを見て最後を省略する処理を追加しました。ローマ字だけであれば理論上 280 文字まで可能だそうですが、日本語文字も混在するので余裕をもたせた判断条件にしています。