はじめに
1月10日に開催されたOracleの「MySQL 8.0入門セミナー (チューニング基礎編、SQLチューニング編)」に参加したため、そのまとめと称して学べた点等々振り返ります。
講演資料は[MySQL 8.0入門セミナー講演資料 (チューニング基礎編、SQLチューニング編)](MySQL 8.0入門セミナー講演資料 (チューニング基礎編、SQLチューニング編))からご確認ください。
※会員登録が必要です。
目次
パフォーマンスチューニングの目的
チューニングの目的は、「限られたシステム・リソースの中で、最大限のパフォーマンス効果を出すこと」にある。
これを念頭に置き、チューニングすべき点を明確にすることが重要。
チューニング指標
チューニングの際に指標となるものには、例えば
- スループット:単位時間当たりの処理能力
- レスポンスタイム:処理を実行してから結果が返ってくるまでの時間
- スケーラビリティ:DBやテーブルの拡張可能性
等がある。
レスポンスタイムを向上したことでスループットの向上に繋がることもあれば、
特定処理のレスポンスタイムをインデックスをつけることで向上したことによって、
テーブルを更新する際の処理能力が低下してしまうこともある。
そのため、ただ単に一つの処理に対するパフォーマンスの向上が正となるわけではない点に注意。
キューイング
レスポンスタイムを向上させる際の考慮事項として、「キューイング」がある。
キューイングは「先入れ先出し」によって処理順序を管理することを言い、
データ通信時間 < 処理時間の時に処理をキューで待たせて順番に実行する。
複数ユーザ/リクエストがある場合、処理はキューで待たされることになる。
レスポンスタイムは「キューイングによる遅延+実行時間」から成り、
同時接続数が増大し続けると、ある時点からキューイングによる遅延が急激に増大する。
そのため、レスポンスタイムを改善する場合、キューイングによる遅延を改善するか、
実行時間を短縮させる必要がある。
キューイングによる遅延を改善する手段として、同時実行可能数を増やすことがあげられる。
例えば、コールセンターのオペレータを増やすことで、全体の待ち数を減らすができる。
また、実行時間の短縮を考慮する場合、どこで実行時間が使われているかという
ボトルネックを見極めることが重要。
直接的にクエリ実行時間を計測することはもちろん、通信速度やCPU処理性能/CPU利用率など、
間接的な計測方法の考慮も必要である。
しかし、どのようなパフォーマンスチューニングにもコストは必ずかかってしまう。
時には、アプリの修正よりもハードウェア交換の方がコストが抑えられる場合もある。
"コストに対するパフォーマンス"
一つひとつの改善に対してチューニングの必要性は常に考えなければならない。
実行時間の計測方法
上記理由から実行時間を計測することがパフォーマンス向上の前提とされるわけだが、その実行方法について、コマンドで実際の通信をキャプチャする方法や、提供されているツールを利用する方法などがある。
「tcpdump」というコマンドによって特定通信のパケットを見ることができる。
各処理のパフォーマンスをtcpdumpを用いて比較することが可能。
使い方は超絶初心者むけtcpdumpの使い方やtcpdumpの使い方を参照。
セミナーではMySQLのベンチマークツールとしてmysqlslapやSysBenchなども紹介されていた。
チューニングのアプローチ
ここから、実際のパフォーマンスチューニング方法について解説していく。
チューニングのアプローチとして、DBチューニングとSQLチューニングの二つがある。
1. DBチューニング(全体最適)
サーバ全体のパフォーマンス向上を目的とする(主にスループットの向上)。
サーバ自体の設定を考える。
2. SQLチューニング(個別最適)
個別の処理のパフォーマンス向上を目的とする(主にレスポンスタイムの向上)。
処理効率の良いクエリやDB/テーブル構成を考える。
DBチューニング
MySQL Serverチューニングの流れは以下の通り。
- ステータス変数などの情報からMySQL Serverの稼働情報を確認
- システム変数の設定値が適切かどうかを判断
- 必要に応じて設定値を調整する。
サーバの状態を確認
以下の記述はCLIから確認を行っているが、GUIで確認を行いたい場合は「MySQL Workbench」という公式ツールから。
システム変数:MySQL Serverの設定を確認
オプションファイル(my.cnfやmy.ini)から設定する方法と、コマンドによって設定する方法がある。
以下のコマンドで、まずは全システム変数の状態を確認する。
SHOW variables;
オプションファイルを直接書き換えて設定を変更した場合は、サーバを再起動する必要がある。
サーバを再起動せずに設定を変更したい場合は、下記コマンドから変更可能。こちらは一時的な変更となる。
SET [GLOBAL] <variable> = <value>;
/* [GLOBAL]:サーバ全体での変更 */
/* [LOCAL]:セッション単位の変更 */
各システム変数についての詳細はこちら。
ステータス変数:MySQL Serverの動作を監視
特定のクエリに対して調査を行う場合は、下記コマンドを実行。
FLUSH STATUS; <クエリ実行>; SHOW STATUS;
各ステータス変数についての詳細はこちら。
パフォーマンス・スキーマからシステム変数/ステータス変数を確認
パフォーマンス・スキーマという性能統計情報分析のための仕組みがある。
performance_schemaストレージエンジンとして実装されており、MySQLサーバ内の「イベント」ごとの処理時間が記録されている。
パフォーマンス・スキーマから両変数を確認する場合は、以下を実行。
/* システム変数の確認例 */
SELECT * FROM performance_schema.global_variables;
/* ステータス変数の確認例 */
SELECT * FROM performance_schema.global_status;
また、sysスキーマという、パフォーマンス・スキーマを便利に使うためのビュー、プロシージャー、ファンクションのセットがある。
sysスキーマのビューにより、コスト高のSQL文情報の確認や、レイテンシ/待ち時間の分析などができる。
サーバのチューニング
上記によってサーバの現状を確認したら、実際にチューニングを行う。
ここでは中でも重要なパラメータを紹介。※( )はデフォルト値
-
max_connections (151)
サーバ許容可能なコネクション数。多すぎるとメモリを消費しきってしまう可能性があるため調整が必要。 -
max_used_connections
過去の最大コネクション数。max_connectionsの最適値の指標としてmax_connectionsと合わせてチェック。 -
thread_cache_size (9)
スレッドをコネクションの切断後にもキャッシュ。一般的な値はmax_connections/3。
※デフォルトは 8+(max_connections/100) の値が自動で計算されて設定 -
sort_buffer_size (256KB)
ソート用のメモリサイズ。このサイズを超えるソートはディスクを利用する。
スキーマのデザイン
以上のようにサーバ自体の設定は必要に応じて変更できるが、DB内のテーブル定義やデータ型を考えることも重要。
データ型
・tinyint/smallint/mediumintなど、可能な限り小さなデータ型を使用しデータ量を削減
・JOINに使う列は同じデータ型に
・charではなくvarcharを使う
・可能なところはNOT NULLを宣言
・INTが使える場合は、NUMERIC/DECIMALよりINTを優先する
インデックス
・複数列にインデックスを貼る
SQLチューニング
SQLチューニングの流れは以下の通り。
1. 問題となるSQLの特定
2. 実行計画やSQL実行時の稼働統計等を確認
3. SQLチューニングの実施
1. 問題となるSQLの特定
まずは問題となっている実行時間の長いクエリを特定する。
スロークエリログ
実行時間が指定した時間以上のクエリを出力する。
デフォルトではOFFになっており出力されていないので、システム変数slow_query_logをONに設定して出力。
※クエリの実行が完了してからでないとスロークエリログに出力されない
/* slow_query_logの設定を確認しONに設定 */
SHOW variables LIKE 'slow%';
SET slow_query_log = ON;
-
long_query_time
実行時間を秒単位で指定。0.5と指定すれば500msと設定できる。短すぎると大量に出力されるので注意。 -
log_queries_not_using_indexes
インデックスを使用していないクエリを出力。
上記設定によってslow_query_log_fileからクエリを確認できる。
また、mysqldumpslowというスロークエリログの集計ツールで、スロークエリログの出力が多いときに優先してチューニングすべきクエリを特定してくれる。
しかし、特定時間帯のクエリのみを抽出するにはMySQL Query Analyzerというツールが必要になるとのこと。
mysqldumpslow -s at <スロークエリログファイル名>
/* "-s at"はクエリ実行時間または平均クエリ実行時間でソートするオプション */
SHOW FULL PROCESSLIST
現在実行中の時間がかかっているクエリを特定可能。FULLをつけることですべてのプロセスを表示。
クライアントホスト名など、問題のあるクエリの追跡に役立つ情報もある。
定期的に監視するためにはスクリプト等を作成する必要がある。
/* 例 */
mysql> SHOW FULL PROCESSLIST;
+-----+--------+-----------+--------+---------+---------+-------+----------------+
| Id | User | Host | db | Command | Time | State | Info |
+-----+--------+-----------+--------+---------+---------+-------+----------------+
| 1 | MyUser | localhost | dbname | Query | 1030455 | init | <query> |
+-----+--------+-----------+--------+---------+---------+-------+----------------+
パフォーマンス・スキーマのThreadsテーブル
SHOW FULL PROCESSLIST+αの情報が確認できる。
SHOW FULL PROCESSLISTよりもパフォーマンス上のオーバーヘッドが少ない。
SELECT * FROM performance_schema.threads WHERE <中略> ;
2. 実行計画やSQL実行時の稼働統計等を確認
実行計画とは
SQL処理する時の内部的処理手順(インデックススキャン、テーブルスキャン、JOIN順番、サブクエリ処理方法など)のことで、同じSQL結果であっても実行計画が異なればパフォーマンスが大きく変わることも多い。
SQLチューニングをするということは、より良い実行計画を選択することとも言えるほど重要。
実行計画は**オプティマイザ(Optimizer)**と呼ばれるものが作成している。コストに基づいて最適な(最もコストが低い)実行計画を作成してくれる。
※オプティマイザが作成した実行計画が必ずしも正しいとは限らないので注意
EXPLAINコマンド
実行計画を確認できるコマンド。クエリを実行する前に必ず確認すべき。
使い方は以下の通り。
EXPLAIN <実行したいクエリ>
/* 例 */
mysql> EXPLAIN SELECT * FROM example_db.tbl where id = 123;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | tbl | NULL | ALL | id | id | NULL | NULL | 10 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| 項目 | 概要 |
|---|---|
| id | クエリのID(テーブルのIDではない) |
| select_type | クエリの種類 |
| table | 対象のテーブル |
| partitions | 対象のパーティション (テーブルにパーティションがない場合はNULL) |
| type | レコードアクセスタイプ (どのようにテーブルにアクセスされるか) |
| possible_keys | 利用可能なインデックス |
| key | 選択されたインデックス |
| key_len | 選択されたインデックスの長さ |
| ref | インデックスと比較される列 |
| rows | 行数の概算見積もり |
| filtered | 条件によってフィルタリングされる行の割合 |
| Extra | クエリを解決する方法に関する追加情報 Using Indexが理想的で、Using where,Using filesort, Using temporaryは可能な限り回避 |
この中でも特に重要な***"type"と"possible_keys"***を解説する。
type
前述の通り、そのクエリがどのようにテーブルにアクセスするのかを表している。
下記のパターンがあり、**indexとALL**は特に要注意で、チューニングの余地があるクエリであることを示す。
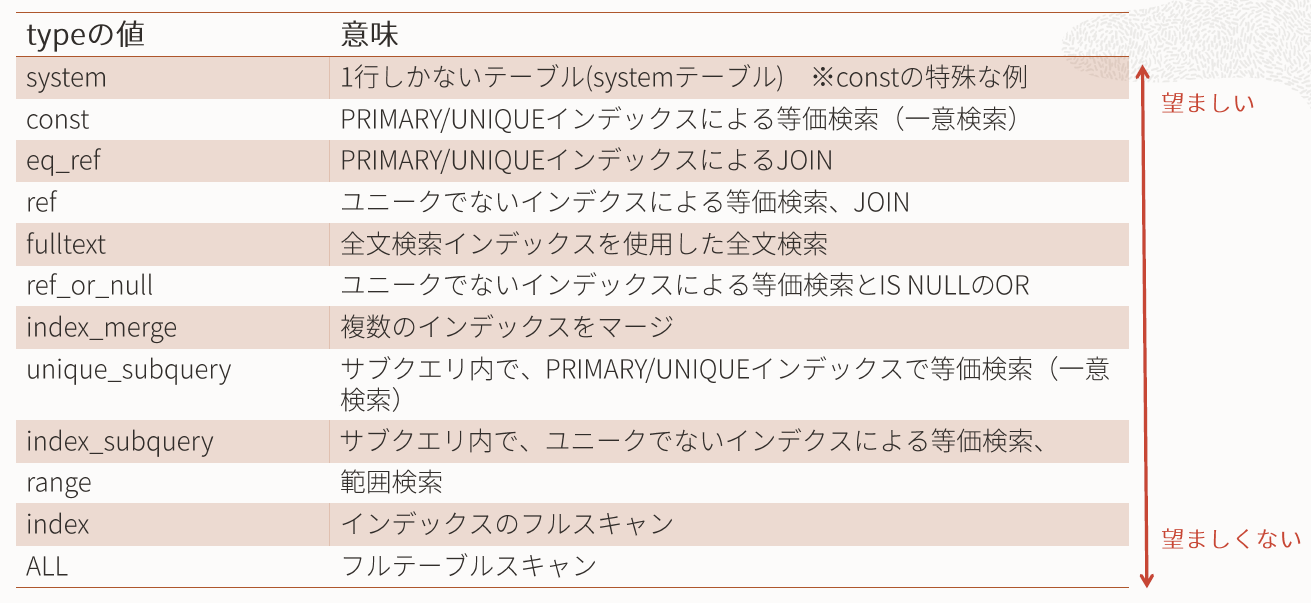
-
index
名前によらず、実際は重い。refまたはeq_refになるようにテーブル構造かSQLを変更すべき。
ただし、ORDER BY + LIMITが入っている場合や、対象行数が極端に少ない場合は問題ない。 -
ALL
データの多いテーブルで実行されると危険。テーブルをフルスキャンしている。
JOINの中で出てきたら最悪。
possible_keys
テーブルへのアクセスに利用可能なインデックスの候補を出してくれる。
以下で、テーブルにあるインデックスを確認できる。
SHOW INDEX FROM tbl_name;
3. SQLチューニングの実施
では、実際にどういった観点でチューニングを行うかについてまとめていく。
インデックスの活用
インデックスは必ず使用する。また、「インデックスを設定した」という思い込みに注意。
これが基本であるが、以下の点にも注意が必要。
-
インデックスをつけすぎない
前述のチューニング指標内にもある通り、テーブル参照時の一時的なレスポンスタイムの向上には繋がるかもしれないが、テーブル更新時にはオーバーヘッドになる。 -
重複するようなインデックスは利用しない
keyにid_1とid_2が選択されているなら、どちらかは削除。 -
カーディナリティが低い(取りうる値の種類が少ない)列にはインデックスを付けない
性別のような数種類しかないものでは結果の行数にあまり貢献できない。 -
インデックス列は計算に使わない
計算に使うとインデックスとして利用できない。
複数テーブルのJOIN
JOINの順番や、各テーブルに対するアクセスパスが重要になる。
小さなテーブル(取り出す行数が少量のテーブル)から順番にJOINするのが基本である。
また、2テーブルのJOINでも、どちらのテーブルに先にアクセスするかによっても効率は変わる。
3テーブル以上をJOINする場合、結果セットが少量になるテーブルからJOINするほうが効率が良くなる(より絞り込みができるテーブルからJOINする)。
さらに、JOIN対象の列で絞り込みをする場合などは、where句による絞り込みをどのテーブルに対して実施する方が効率的になるかも考えると尚よい。
サブクエリに関する補足
MySQL5.6以降、オプティマイザの改善によりサブクエリの最適化が強化されている。
そのため、従来はサブクエリをJOINに書き換えることが多かったが、5.6以降はサブクエリのままでもパフォーマンス良く実行できるケースが多い(必ずしもというわけではないが)。
オプティマイザの制御
オプティマイザが選択する実行計画ではないものをどうしても選択したいとき、オプティマイザの判断を制御することも可能である。
設定そのもの(コスト調整やバッファサイズなど)を変更することもできるが、ヒントを使用することでオプティマイザに指示を出し、より直接的な実行計画の指定が可能。
インデックスヒント
使用する(使用しない)インデックスを指定。USE INDEX、FORCE INDEX、IGNORE INDEXの3種類。
また、FOR句を使って対象を指定することも可能。
-
USE INDEX
特定のインデックスを使用するように、オプティマイザに指示を出す。 -
FORCE INDEX
USE INDEXに加えて「テーブルスキャンを選択しない」という指示も同時に出す。
オプティマイザが「テーブルスキャンしたほうが効率がいい」とどうしても判断した場合は、
これでインデックスの使用を強制する。 -
IGNORE INDEX
特定のインデックスを使用しないように、オプティマイザに指示を出す。
SELECT * FROM example_db.tbl FORCE INDEX(id) WHERE id = 123;
STRAIGHT_JOINヒント
JOINの順番を指定。記述した順番の通りにJOINしていく。
通常の"JOIN"という文字を"STRAIGHT_JOIN"に変えて使用。
※ただし、OUTER JOINの際は、結合条件に一致しない行を含むテーブルを先に読み取る必要があるため
使用できないので注意
おわりに
個人的にかなり内容が濃く学んだことが大量にあったため、まとめるのに時間も行数もかかってしまいました。
欠損部分等ありますので、是非冒頭にある講義資料から、直接内容を一瞥していただくことをお勧めします。
入門セミナーと聞いて参加しましたが、自身の知識がまだ浅いからなのかとても入門のようには感じませんでした(参加者がMySQL利用中の技術者の方ばかりであったこともあるとは思いますが)。
しかしながら、「MySQLを少しでも触ったことがある」「SQLを実行すると処理が重くなってしまうことが多い」という経験がある方には、かなり充実した時間になるのではないかなと感じました。
また、女性の参加者も多い印象でした!その点も含めて参加しやすい講義ではあるかなとも思いました。
私的に一番驚いたのが、DBチューニングの話でした。
チューニングセミナーと聞いてもはやクエリチューニングしか考えていなかったのが恥ずかしくなるくらいに、まだまだ奥が深い180分でありました。。。
実行計画はすぐにでも使えるので、大満足でした。