trocco®️のQiitaのAdvent Calender2024 12月22日への寄稿記事です。
22日が月曜日だと勘違いして余裕こいてたら、日曜日だと気づいて急いで書いていますw
みなさん、troccoライフ楽しんでますか?
私はtroccoのおかげで、データエンジニアリング業務がかなり楽になりました。
おかげさまで、数百ものパイプラインが日々実行されるようになりました!
一方で、日々のデータ品質チェックの運用にツラみを感じるように…データマートの品質チェックは重要ですが、手動での確認作業は時間がかかり、効率が悪いと感じています。
そこで今回は生成系AIを使って、この課題を解決する方法を紹介したいと思います。
本記事の前提
使用する技術は以下の通りです。
- データマートおよびデータチェック: BigQuery
- 生成系AI: BigQuery ML (生成系AIリモートモデル)
データチェックの概要とツラみ
troccoのデータチェック機能とは以下のようにパイプラインに配置できます。

最右端のコンポーネントがデータチェック機能となります。
例えば以下のようなSQLを登録して、出力の1行1列の値がどうなればエラーを出すかという設定ができます。
WITH base as (
SELECT *
FROM `dummy_data.gemini_demo_source`
WHERE views > 20000
)
SELECT COUNT(*) FROM base
今回の例では、異常レコードをカウントしてこれが1以上であればアラートを出すようにしています。
こうすることで、日々のデータパイプラインでデータの品質に異常があってもすぐに気付けるようになります。
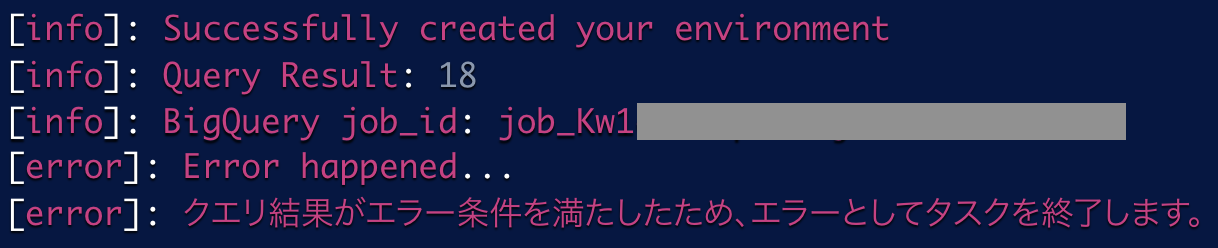
下図はエラーが発生したときの表示とログです。
これは大変便利な機能で、自前で作ろうとすると途方もない労力がかかるのですが、troccoならSQLさえ書ければポチポチと設定できるので私のお気に入りの機能です。
ただ、上記のログ(Query Result: 18)にあるように「異常レコードがいくつあったか」しかログにでないため、結局その異常データを手動で確認することになります。また、その原因を特定するためにデータマートのSQLや大量のログを確認したり、SQLを書き直したりする必要があります。
アラートが1日に数回しかないのなら問題ないのですが、たまに大量にアラートが上がる日もあり、こういう手動の運用がボディーブローのように効いてきて、これがツラいのです…
課題解決の方針
以上を受け、下記の課題を生成系AIを用いて解決したいと思います。
- 異常レコードを可視化する
- 原因を調査する
- そもそも、元のデータマートについて説明する
3つ目は地味に大事で、たまに開発メンバーや運用メンバーも「このデータマートってなんだっけ・・・?」となるようなこともあり、思い出したりドキュメントとを漁ったり、メンバーに聞いて回る負荷も下げたいと思っています。
解決方法
概要
後述に詳細を記述しますが、かなり複雑なのでまずは概要を述べます。
ポイントは以下のとおりです。
- BigQueryのINFORMATION_SCHEMA.JOBSを用いて、trocco上で実行された関連するクエリ文(データチェックSQL含む)を取得し、BigQuery MLのGENERATE_TEXT関数を用いて、生成系AIにレポートを書かせる。
- データチェック対象となるデータマートのSQLやデータチェックのSQLに共通のキーワードをコメントアウトでいれておき、後で紐づけられるようにする
実装詳細
最初に完成形のワークフローの図を記します。
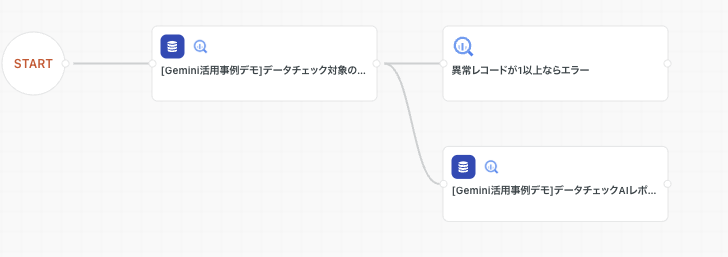
まず、BigQueryの元のデータマートを以下のように設定します。(ワークフロー図の[Gemini活用事例デモ]….の部分)
--- [Catch me, gemini:#1111/source_code]
SELECT
DATE(datehour) as day
, title
, SUM(views) as views
FROM `bigquery-public-data.wikipedia.pageviews_2024`
WHERE
TIMESTAMP_TRUNC(datehour,DAY) = "$ref_datetime$"
AND wiki LIKE "%ja%"
AND title not like "%メインページ%"
AND title not like "%特別:検索%"
group by 1,2
SQL部分はあくまでもサンプルですので無視してください。
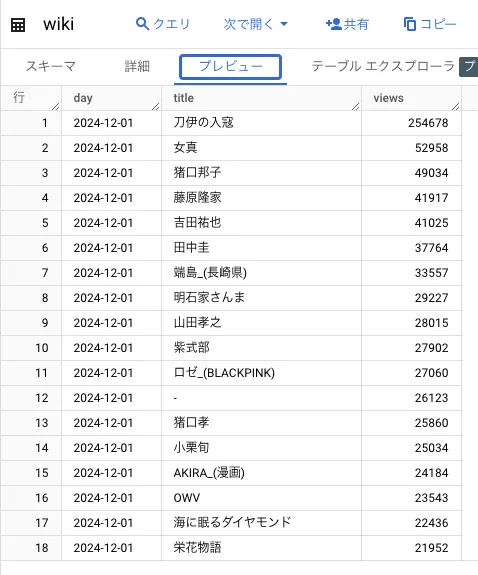
ちなみに、このサンプルはWikipediaの日本語版のページビュー数を取得して、各ページのタイトルと閲覧数を日毎に集計したものです。
ポイントなのはコメントアウトの最初の行に「Catch me, gemini:#1111/source_code」という識別子を入れていることです。この識別子により、後でデータマートのSQLとデータチェックのSQLを紐づけることができます。また、「#1111」の部分は任意の数字で、同じ数字を持つSQL同士が関連していることを示しています。
troccoワークフローのIDを入れておくと良いかもしれません。
「/source_code」部分は、このSQLの種別を表します。今回のデータチェック対象のSQLなので、ソースコードであるという意味を持たせたいため、そのように命名しています。
ちなみにこのSQLは以下のような出力結果になります。
次に、データチェックのSQLは以下のように書きます。(ワークフロー図の「異常レコードが1以上ならエラー」部分)
--- [Catch me, gemini:#1111/data_check]
WITH base as (
SELECT *
FROM `dummy_data.gemini_demo_source`
WHERE views > 20000
)
--- キリトリ線 ---
SELECT COUNT(*) FROM base
SQL部分は閾値を超えるレコードをカウントしているだけのシンプルなものです。
ポイントは、データチェックのSQLにも同様の識別子「Catch me, gemini:#1111/data_check」を入れることで、元のデータマートとデータチェックSQLを紐づけることができます。
/data_checkはデータチェックであるということが分かるように種別を記載しています。
また、データチェックのSQLの途中に「キリトリ線」を入れている点もポイントです。これにより、後述の対象クエリ取得SQLで、異常レコードの詳細を見るためにSELECT COUNT(*)の部分を書き換えることが容易になります。
最後に、生成系AIを活用したレポート生成のためのデータマートを用意します。(ワークフロー図右下の「データチェックAIレポート…」部分)
まず、対象のデータマートのSQLとデータチェックSQLをINFORMATION_SCHEMA.JOBSから取得し、それらに基づいて異常レコードの詳細を分析し、最後に生成系AIを用いてレポートを生成します。以下に、その具体的な実装を説明していきます。
データマートの設定は以下のとおりです
-
クエリ設定は「自由記述モード」
-
カスタム変数は以下
変数名 説明 $trace_id$上述のSQLにある[Catch me, gemini:#1111/data_checkの1111部分に相当] $model_path$BigQuery MLの生成系AIリモートモデルのパス $ai_report_table_path$AIレポートを出力したいテーブルパス -
リモートモデルについては本記事では触れません。具体的な実装は以下をご確認いただけますと幸いです。
https://cloud.google.com/bigquery/docs/generate-text-tutorial-gemini?hl=ja
具体的なSQLは以下の通りです。
-- Variable declarations
DECLARE datacheck_query_string STRING;
DECLARE modified_query STRING;
DECLARE excute_immediate_string STRING;
DECLARE prompt_info STRING;
DECLARE prompt STRING;
-- Create temporary table
CREATE TEMP TABLE src AS
WITH BASE AS (
SELECT
REGEXP_EXTRACT(query, 'Catch me, gemini:#([0-9]+)/') AS trace_id,
REGEXP_EXTRACT(query, 'Catch me, gemini:#[0-9]+/(.*)]') AS type,
creation_time,
query AS description
FROM (
SELECT
creation_time,
query
FROM `region-asia-northeast1`.INFORMATION_SCHEMA.JOBS
WHERE creation_time >= CURRENT_TIMESTAMP() - INTERVAL 1 MINUTE
AND query LIKE "%Catch me, gemini%"
AND query NOT LIKE "%INFORMATION_SCHEMA.JOBS%"
AND query NOT LIKE "%DO NOT Catch me, gemini%"
)
)
SELECT
trace_id,
creation_time,
type,
description
FROM BASE
WHERE trace_id = "$trace_id$";
-- Set variables
SET datacheck_query_string = (
SELECT description
FROM src
WHERE type = "data_check"
ORDER BY creation_time DESC
LIMIT 1
);
SET modified_query = (
SELECT REGEXP_REPLACE(
datacheck_query_string,
r'--- キリトリ線 ---\n.*$',
'\nSELECT * FROM base\n--- DO NOT Catch me, gemini'
)
);
-- Execute modified query
SET excute_immediate_string = FORMAT("""
CREATE TEMP TABLE data_check_output AS
SELECT TO_JSON(ARRAY_AGG(t)) AS output
FROM (%s) t
""", modified_query);
EXECUTE IMMEDIATE excute_immediate_string;
-- Set prompt information
SET prompt_info = (
WITH prompt_base AS (
SELECT * FROM src
UNION ALL
SELECT
"$trace_id$" AS trace_id,
CURRENT_TIMESTAMP() AS creation_time,
"data_check_output" AS type,
TO_JSON_STRING(output) AS query
FROM data_check_output
)
SELECT
TO_JSON_STRING(ARRAY_AGG(
STRUCT(
creation_time,
type,
description
)
ORDER BY creation_time
))
FROM prompt_base
);
-- Set final prompt
SET prompt = FORMAT(
"""
あなたは優秀なデータエンジニアでありQAエンジニアです。
後述のデータ処理にて、データの品質チェックを行ったところ、異常レコードが1つ以上検出されました。
保守担当エンジニアがすぐに次のアクションに取りかかれるように あなたは最高に分かりやすい具体的な原因と解決策を以下の情報に基づいて提示してください。
# データパイプラインの処理タイムラインの説明
* type="source_code"
* データマート処理について記述したもの。descriptionにはそのSQLが記載されている。
* 後述のデータチェックによって異常なレコードが無いか検証される。
* type="data_check"
* 先述のソースコードのSQLによって生成されたテーブルに対して、異常レコード数をカウントし、1つ以上の場合に異常であると判断するもの
* descriptionにはそのSQLが記載されている。
* type="data_check_output"
* 先述のデータチェックSQLについて異常レコード数ではなく、レコードそのものを出力したもの。
* 異常レコードの中身がdescriptionにjson形式で記載されている。
# 出力のフォーマット
```markdown
# 異常の概要
{{本件の異常について、どういう異常であるかの概要を記載する}}
# 異常レコード
{{type=data_check_outputのjsonにあるレコードを一言一句落とさず全て、完全な状態で、表形式で分かりやすく記載する}}
# 異常の原因
{{なぜ異常レコードが出力されているのか原因を可能な限り多く列挙する}}
# 改善点・解決策
{{改善すべき点・解決策について列挙する。source_codeに不備がある場合は、修正案を提示し、データ発生源に問題がある場合は考えられる対処方法を提示する。}}
# (ご参考) ソースコードの説明
{{source_codeに書かれているSQLを非エンジニアにも分かるように説明する}}
# (ご参考) データチェックの説明
{{data_checkに書かれているSQLを非エンジニアにも分かるように説明する}}
```
# 重大な罰則事項
あなたの出力が以下の事項に抵触する場合は、重大な罰則が課せられます。
* 上述の「異常レコード」について、タイムラインのtype="data_check_output"のレコードを十分に記載できていない。一部しか記載されていない。
* 異常の原因として挙げているものに、現実的に起こり得ない仮説が含まれてしまっている。
* エンジニアの専門用語が多く、非エンジニアに対して難解なレポートになってしまっている。
# データパイプラインのタイムライン情報
%s
"""
, prompt_info
);
-- Generate text using ML model
INSERT INTO $ai_report_table_path$
(creation_timestamp, trace_id, prompt, response)
SELECT
CURRENT_TIMESTAMP() as creation_timestamp,
"$trace_id$" as trace_id,
prompt,
ml_generate_text_llm_result AS response
FROM ML.GENERATE_TEXT(
MODEL $model_path$,
(SELECT prompt),
STRUCT(
0.2 AS temperature,
TRUE AS flatten_json_output,
4096 AS max_output_tokens
)
);
これは、BigQuery Scriptingを用いた複数SQLで構成されており、複雑ですので分割して解説します。大きく分けて以下の6つのパートで構成されています。
1. 変数の宣言パート
DECLARE datacheck_query_string STRING;
DECLARE modified_query STRING;
DECLARE excute_immediate_string STRING;
DECLARE prompt_info STRING;
DECLARE prompt STRING;
このパートでは、後で使用する変数を準備しています。文字列型の変数を5つ定義しており、これらは後続の処理で必要な情報を一時的に保存するために使用されます。
2. 一時テーブルの作成パート
CREATE TEMP TABLE src AS
WITH BASE AS (...)
SELECT ... FROM BASE
WHERE trace_id = "$trace_id$";
このパートでは、過去1分間の間に実行されたジョブの中から、特定の条件("Catch me, gemini"というキーワードを含むなど)に合致するものを抽出し、一時テーブルとして保存しています。これは、データの品質チェックのための基礎データとなります。
3. データチェッククエリの実行パート
SET datacheck_query_string = (...);
SET modified_query = (...);
SET excute_immediate_string = FORMAT(...);
EXECUTE IMMEDIATE excute_immediate_string;
このパートでは、整形したデータチェッククエリを実際に実行し、その結果を一時テーブルに保存します。結果はJSON形式でまとめられます。
具体的にはデータチェックSQLの「キリトリ線」以下に設定されてた異常レコードのカウント部分を、シンプルに異常レコードを出力させるSQLに書き換えます。その後、データチェックの結果を一時テーブルに保存し、後続の処理で活用できる形式に整えています。
4. プロンプト情報の準備パート
SET prompt_info = (...);
このパートでは、AIモデルに渡すプロンプトの一部となる情報を準備しています。元のデータと、データチェックの結果を組み合わせて、時系列順に並べた情報を作成します。
ここでかなり細かくプロンプトを与えています。
5. AIレポート生成パート
SET prompt = FORMAT(...);
INSERT INTO $ai_report_table_path$ ...
最後のパートでは、準備した情報を基に、AIモデルにデータチェック結果の分析を依頼するプロンプトを作成し、その結果をテーブルに保存します。
このスクリプト全体の目的は、データの品質チェックを自動化し、問題が見つかった場合にAIを使って分かりやすい形で報告することです。特に意識しているのは、エンジニアではない人にも理解できるような形でレポートを生成するようにプロンプトを工夫している点です。
以上を実行すると、このデータマートは以下のように出力します。

response列を展開すると以下のようになります。
# 異常の概要
データチェックの結果、`views`カラムの値が20,000を超えるレコードが17件検出されました。これは、想定されるアクセス数と比較して異常な値であり、データの品質に問題がある可能性があります。
# 異常レコード
| day | title | views |
|------------|-------------------|---------|
| 2024-12-01 | 山田孝之 | 28015 |
| 2024-12-01 | ロゼ_(BLACKPINK) | 27060 |
| 2024-12-01 | OWV | 23543 |
| 2024-12-01 | 紫式部 | 27902 |
| 2024-12-01 | 女真 | 52958 |
| 2024-12-01 | 猪口邦子 | 49034 |
| 2024-12-01 | 端島_(長崎県) | 33557 |
| 2024-12-01 | - | 26123 |
| 2024-12-01 | 猪口孝 | 25860 |
| 2024-12-01 | 田中圭 | 37764 |
| 2024-12-01 | 小栗旬 | 25034 |
| 2024-12-01 | 海に眠るダイヤモンド | 22436 |
| 2024-12-01 | 吉田祐也 | 41025 |
| 2024-12-01 | AKIRA_(漫画) | 24184 |
| 2024-12-01 | 刀伊の入寇 | 254678 |
| 2024-12-01 | 栄花物語 | 21952 |
| 2024-12-01 | 明石家さんま | 29227 |
| 2024-12-01 | 藤原隆家 | 41917 |
# 異常の原因
* **データソースの誤り:** `bigquery-public-data.wikipedia.pageviews_2024`テーブルに、本来は存在しないアクセス数が記録されている可能性があります。
* **データ処理の誤り:** `source_code`のSQLで、`views`カラムの集計処理に誤りがある可能性があります。例えば、`SUM(views)`ではなく`COUNT(views)`が意図されていた、など。
* **データチェックの誤り:** `data_check`のSQLで、`views`カラムの閾値が適切に設定されていない可能性があります。20,000という閾値が、実際のアクセス数の分布と合致していない可能性があります。
# 改善点・解決策
1. **データソースの確認:** `bigquery-public-data.wikipedia.pageviews_2024`テーブルのデータを確認し、異常なアクセス数が記録されているかどうかを調査します。もし異常なデータが存在する場合は、データソースの管理者に連絡し、修正を依頼します。
2. **ソースコードの修正:** `source_code`のSQLを確認し、`views`カラムの集計処理に誤りがないか確認します。もし誤りがある場合は、修正します。
3. **データチェックの修正:** `data_check`のSQLを確認し、`views`カラムの閾値が適切に設定されているかどうかを確認します。もし適切でない場合は、実際のアクセス数の分布に基づいて閾値を修正します。
4. **データの再処理:** データソース、ソースコード、データチェックのいずれかに問題がある場合は、データパイプラインを再処理し、異常なレコードを修正します。
# (ご参考) ソースコードの説明
SELECT
DATE(datehour) as day,
title,
SUM(views) as views
FROM `bigquery-public-data.wikipedia.pageviews_2024`
WHERE
TIMESTAMP_TRUNC(datehour,DAY) = ""2024-12-01""
AND wiki LIKE ""%ja%""
AND title not like ""%メインページ%""
AND title not like ""%特別:検索%""
GROUP BY 1,2
このSQLは、`bigquery-public-data.wikipedia.pageviews_2024`テーブルから、2024年12月1日の日本語版Wikipediaのページビューを集計しています。`title`と`views`をグループ化し、各ページの総ビュー数を計算しています。
# (ご参考) データチェックの説明
WITH base as (
SELECT *
FROM `dummy_data.gemini_demo_source`a
WHERE views > 20000
)
--- キリトリ線 ---
このSQLは、`dummy_data.gemini_demo_source`テーブルから、`views`カラムの値が20,000を超えるレコード数をカウントしています。このカウント結果が1以上であれば、データに異常があることを示します。
サンプルデータでの検証なのでこの出力がどれくらい確からしいかはわかりませんが、まあそれなりに最初の運用の取っ掛かりとしては良いレポートではないでしょうか?
このような生成系AIを活用したデータチェックレポートの自動化は、従来の手動作業と比べて大きな効率化が期待できます。特に、技術的な詳細をビジネス視点での分析に変換する部分で、AIの自然言語生成能力が効果を発揮しています。また、異常値の検出からレポートの生成まで一連の流れを自動化することで、データ品質管理の工数を大幅に削減することができます。
若干数字が間違っていたりしますが、ここらへんはプロンプトエンジニアリングをもう少し改善する必要がありそうですね…
(というより、そもそも数字系は考えさせないようにしたほうが良いかも)
他には、生成系AIの出力の質を高めるために、プロンプトの工夫以外にも、データの前処理や後処理の改善が必要かもしれません。例えば、異常値の検出に統計的な手法を組み合わせたり、AIの出力結果を構造化データとして保存し、より柔軟な分析や可視化を可能にすることなどが考えられます。
などなど、考えだしたらキリがありませんが、あとはこれをよしなにNotionや他ドキュメント、slackなどに通知する転送設定を作るなどして、運用しやすいようにワークフローを改善すれば、さらなる自動化が可能になりそうです。
(私の開発チームでは、Notion APIを叩く転送設定を後段にくっつけて、Notionのページに上記のレポートを貼り付けるようにしています。)
さいごに
めちゃくちゃゴリ押しした方法なので、ご使用する際は用法用量を守って正しくご参考ください…
また、上記の実装だと、エラーが起ころうがどうであろうが生成系AIを実行してしまうので、「エラーが起こったときだけ後段の処理を実行する」的な機能がtroccoに追加されると良いなあと思いました。
というか、そもそも生成系AIによる運用自動化機能をtroccoに実装してほs(ry
以上です!