はじめに
東京都知事選が終わりましたが、候補者に対して賛否両論さまざまな意見が挙がっています。今回、意見をいくつか収集して VADERを用いた Sentiment 解析を行い、発言をクラス分けできるかやってみました。
使用ライブラリ
googletransは、PythonでGoogle翻訳APIを使用するためのライブラリです。
VADER (Valence Aware Dictionary and sEntiment Reasoner) 感情分析は、ソーシャル メディアのテキストで表現された感情を分析するために設計された、語彙とルールに基づく感情分析ツールです。
AgglomerativeClusteringは、階層的なクラスタリング手法です。
!pip install --upgrade googletrans==3.1.0a0
import pandas as pd
import matplotlib.pyplot as plt
from googletrans import Translator
from nltk.sentiment.vader import SentimentIntensityAnalyzer
from sklearn.cluster import AgglomerativeClustering
データ収集
🪨⭕️候補に対する有名人の意見をGeminiに問い合わせ収集しました。データ数は少ないですが、モデルがトレーニング済みなので、少数データに対しても学習無しで解析できます。
japanese_sentences = [
("Shinjiro","彼のようなバイタリティ溢れる人物が都知事になれば、東京は大きく変わるだろう。彼に期待している。"),
("Ryuuki","彼は、自由な発想を持つ政治家だ。彼の今後の活躍が楽しみだ。"),
("Mitsuru","彼の発言は、炎上覚悟で本音を言っているように聞こえる。政治家に必要な勇気だと思う。"),
("Ikkei","彼は、分かりやすい言葉で政治を語る政治家だ。彼は国民の支持を集めるだろう。"),
("Ikou","彼の公約は具体性がない。数字や財源の裏付けを示すべきだ。"),
("Naoki","彼は政策よりもパフォーマンスに力を入れているようだ。都知事として期待できない。"),
("Ichiro","彼は政治家としての経験が浅いため、都知事という大役を果たせるかどうか心配だ。"),
("Yukio","彼は行政経験や財政知識が不足している。彼は都知事として必要な能力を備えているのか疑問だ。"),
("Chiharu","彼は質問を遮ったり、答えなかったりするなど、傲慢な態度だった。"),
("Yuichiro","彼の発言は、多様性を尊重する社会の実現に向けた重要な議論を呼び起こすものだ。"),
("Ruri","彼はカリスマ性がある一方で、傲慢で独りよがりな面もある。政治家としてふさわしい人物かどうか判断が難しい。"),
("Soichiro","彼はカリスマ性だけで政治を運営することはできない。実績を積み重ねていくことが重要だ。"),
]
VADER解析する前に英訳するので、日本語は少し手を加えています。
英訳およびVADER解析
VADERは、テキストごとに 4 つの感情スコアを提供します。
- 肯定スコア (pos): 肯定的として分類されるテキストの割合。
- ネガティブ スコア (neg): ネガティブとして分類されるテキストの割合。
- ニュートラル スコア (neu): ニュートラルとして分類されるテキストの割合。
- 複合スコア (comp): すべてのレキシコン評価の合計を計算し、-1 (最もネガティブ) から +1 (最もポジティブ) の間で正規化された集計正規化スコア。
translator = Translator()
vader_analyzer = SentimentIntensityAnalyzer()
names=[]
ja=[]
en=[]
pos=[]
neu=[]
neg=[]
comp=[]
for name,sentence in japanese_sentences:
##英訳
translated_text = translator.translate(sentence, src='ja', dest='en').text
##VADER解析
score = vader_analyzer.polarity_scores(translated_text)
names+=[name]
ja+=[sentence]
en+=[translated_text]
pos+=[score['pos']]
neu+=[score['neu']]
neg+=[score['neg']]
comp+=[score['compound']]
data=pd.DataFrame()
data['name']=names
data['ja']=ja
data['en']=en
data['positive']=pos
data['neutral']=neu
data['negative']=neg
data['comp']=comp
display(data)
Agglomerativeクラスタリング
明確な肯定的な人、明確に否定的な人、それ以外に分けることを目的としました。nclust=3では上手く分けることができませんでしたが、nclust=5にすることで、明確な肯定的な人、明確に否定的な人、のクラスターを取り出すことができました。
def doAgglomerative(X, nclust=2):
model = AgglomerativeClustering(n_clusters=nclust, affinity = 'euclidean', linkage = 'ward')
clust_labels = model.fit_predict(X)
return clust_labels
clust_labels = doAgglomerative(data.iloc[:,3:],5)
agglomerative = pd.DataFrame(clust_labels)
data.insert((data.shape[1]),'cluster',agglomerative)
display(data)
df=data
cluster = df.groupby('cluster')['name'].apply(list).reset_index()
print(cluster)
cluster name
0 0 [Shinjiro, Mitsuru, Ikkei, Yuichiro]
1 1 [Chiharu, Ruri]
2 2 [Yukio, Soichiro]
3 3 [Ikou, Naoki]
4 4 [Ryuuki, Ichiro]
Compound Score (comp) と Neutral Score (neu):¶
テキストの感情の強さと中立的な要素のバランスを確認できます。
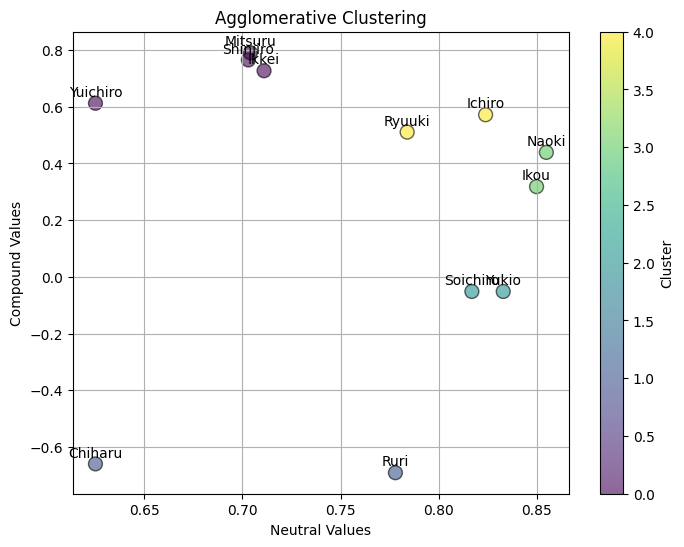
Compound Score (comp) と Neutral Score (neu):¶
テキストの感情の強さと中立的な要素のバランスを確認できます。
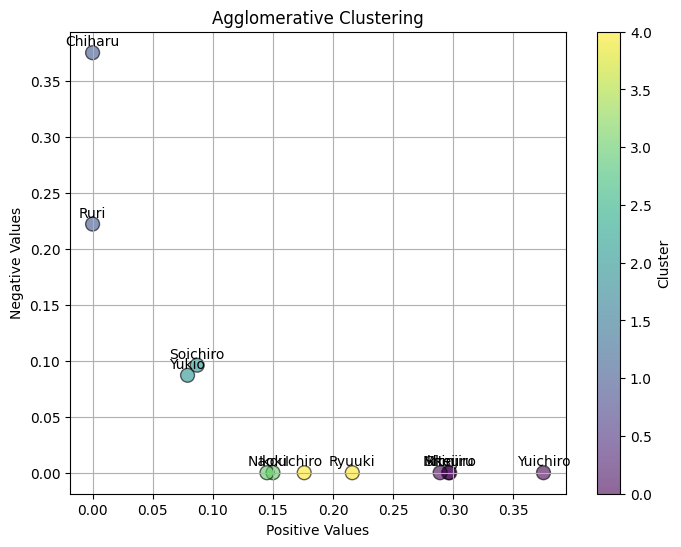
終わりに
VADERは学習なしに少ないデータも解析できるので便利です。また、4種類のスコアを返すので、データ数が多ければさらに多面的なクラス分けも可能になるかもしれません。
こちらに全体をアップしているので、興味のある方は参照してください。
こちら