はじめに
みなさん、Terraformを使ってAWSリソースを管理したことはありますか?Terraformは便利な一方で、思ったようにリソース作成できなかったり、ドキュメントや参考記事が英語ばかりだったりと大変なことも多いですよね。
この記事では、Terraformを使う中で「これ知っておけばもっと楽だったのに!」と思ったポイントをまとめてみました。具体例ではAWSのリソースを用いていますが、他のクラウドサービスにも応用できる内容になっています。ディレクトリ構成のベストプラクティスや構文の使い分けなど様々なトピックを紹介するのでぜひ最後までチェックしてみてください!
※ちなみにこの記事の執筆時点ではTerraformのバージョンは1.9.8が最新でした。それ以降のバージョンでの変更点については公式のリリースを確認してみてください。
本記事ではAWSの使い方については触れませんが、AWSについても知りたい!という方がいらっしゃったらこちらの記事ものぞいてみてくださいね。
弊社Nucoでは、他にも様々なお役立ち記事を公開しています。よろしければOrganizationのページも覗いてみてください。
また、Nucoでは一緒に働く仲間も募集しています!興味をお持ちいただいた方は、ぜひこちらまでご連絡ください。
初めてtfファイルを作る時に役立つTips
1. ファイルはモジュール構成を使って管理しよう
Terraformを使ってIaCを実現するとき最初に乗り越えるべき壁は、ディレクトリ構成でしょう。
Terraformを初めて触るときは、何も考えずに1つのファイルに全部書きたくなってしまうかもしれません。ただ、リソースが増えてくると当然のように可読性が低くなっていきます。こうなると後で読み返すのが大変なだけではなく、ミスも増えてしまいます。
Terraformの公式ドキュメントではディレクトリ構成として、「モジュール構成(Module Structure)」を勧めています。これは、いくつかのリソースをまとめて“モジュール(部品)”として再利用できるように管理する方法です。
役割ごとにモジュールを分割することで、コードもぐっと読みやすくなります。
具体的な使い方
モジュール構成を用いると、以下のような構成にすることができます。
(ここでは後で解説することを踏まえて、ルートモジュールは一つにしています)
project/
├── main.tf
├── modules/
│ ├── vpc/
| | ├── README.md
| | ├── variables.tf
| | ├── main.tf
| | ├── outputs.tf
| | ├── (modules/)
| | └── (examples/)
│ ├── ec2/
│ └── rds/
各モジュールのサブディレクトリ内に最低限追加すべきファイルとして、Terraform公式では README, main.tf, variables.tf, outputs.tf が挙げられていますが、 main.tf さえあればモジュールを使うことはできます。
複数のファイルにコードを分ける場合は、
- variable.tf ではモジュールごとに定義したい値
- outputs.tf ではモジュール外で利用したい値
- main.tf ではリソースの作成など
を行います。
参考
2. 環境ごとの設定ファイルを作ろう
Terraformで開発環境と本番環境の設定を分けて管理したいとき、1つのファイルに全部書いてしまうと冗長になってしまいます。
そこでおすすめなのが、環境ごとに設定ファイルを分けることです。開発用の設定は開発専用のファイルに、本番用は本番専用にしておけば、ミスで本番環境に変更を加えるようなことが減ります。環境ごとに微妙に設定を変えたい場合にも対応しやすいです。
具体的な使い方
具体的には、以下のようにして管理します。
project/
├──environments/
│ ├── dev/
│ │ ├── variables.tf
│ │ ├── main.tf
│ │ └── backend.tf
│ └── prod/
│ ├── variables.tf
│ ├── main.tf
│ └── backend.tf
├──modules/
こうしておけば、それぞれの環境のmain.tfのみをもとにして terraform apply をすることができます。「開発環境だけに新しいリソースを追加する」といったケースでも本番環境に変更を加える心配がなくなります。
参考
リソース作成時に役立つTips
3. はじめは公式ドキュメントを参考にしよう
AWSリソースをTerraformで作ろうと思ったとき、「どのパラメータが必須でどうやって設定すれば良いんだろう?」と考えてしまうかもしれません。そんなとき真っ先に行くべき場所がAWSプロバイダの公式ドキュメントです。
公式ドキュメントのサンプルコードや必須の設定を確認することでミスなくリソースを作成することが出来ます。
具体的な使い方
例として、EC2インスタンスを作る場合は Resource: aws_instance のページを参考にします。
AWSのAMIを用いてインスタンスを作る例には以下のものがあります。
data "aws_ami" "ubuntu" {
most_recent = true
filter {
name = "name"
values = ["ubuntu/images/hvm-ssd/ubuntu-jammy-22.04-amd64-server-*"]
}
filter {
name = "virtualization-type"
values = ["hvm"]
}
owners = ["099720109477"]
}
resource "aws_instance" "web" {
ami = data.aws_ami.ubuntu.id
instance_type = "t3.micro"
tags = {
Name = "HelloWorld"
}
}
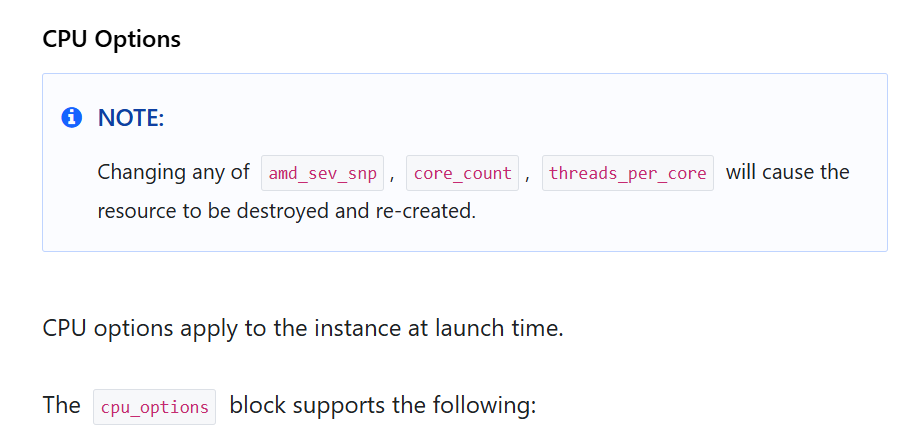
Argument Reference を見ると設定可能な項目を全て確認することができます。設定が必須のものは Required となっているので、これらは特に忘れないように設定しましょう。また、作成後に変更できない項目も下の画像のように注意書きがあるので、これらの設定も慎重に行うと良いでしょう。
4. 命名規則を決めておこう
Terraformに限った話ではありませんが、リソースなどを作るときの名前は初めで適当にしてしまうと後から管理が大変になります。特に複数人で作業しているときは、命名がバラバラだと混乱します。
そのため、リソースブロック名のルールは予め決めておくのがおすすめです。ここでは一般的に使われている命名規則をいくつか紹介します。全てに従う必要はありませんが、迷ったらこの方法に従っておくと良いです。他人が公開しているモジュールなどを利用する際にもリソースブロック命名のお気持ちが察しやすくなるでしょう。
具体的な使い方
一般的な命名規則として、
- "-" の利用は避けて "_" を使うようにする
Terraformのリソースタイプの指定と一貫した記法になる - 大文字は使わないようにする
同上 - リソースの種類はリソースブロック名に含めない
重複を避ける - ディレクトリ内で一つしかないときは "this" とする
同じリソースを複数作成する場合には役割に応じて名付ける必要がある
などがあります。
これ以外にも必要であれば、細かい命名規則をチーム内で決めて共有しておくとスムーズに開発を進められるでしょう。
また、リソースブロック以外にもAWS内でリソースを識別するためのIDを指定できる場合があります。S3バケット名やIAMロール名などがこれにあたります。これらの命名は異なる命名規則でも構いませんが、やはり一貫性と分かりやすさを意識して規則を作っておくのが良いでしょう。
参考
5. outputで値を共有しよう
Terraformを使っていると、「あるリソースで作った値を別のリソースでも使いたい」ということがありますよね。例えば、VPCのサブネットIDを取得して、それをEC2の起動時に指定したい場合などです。
output を使うとこれを楽に実現できます。output の機能を簡単に言うと、Terraformの設定ファイルから値を「出力」して、別の場所で使えるようにする仕組みです。これを使うと、ハードコードを避けてVPCのIDなどを受け渡せるようになります。
具体的な使い方
やり方としては、outputs.tf 内に main.tf で定義したリソースの値を記述することでモジュール外部から呼び出せるようになります。
output "vpc_id" {
value = aws_vpc.this.id
}
これを用いて、VPCモジュールを呼び出すルートモジュールでmodule.vpc.vpc_id を他のモジュールの変数に与えることで他のモジュールで参照できるようになります。
以下の例ではEC2インスタンスの配置先として作成したVPCのサブネットを指定しています。
module "ec2" {
...
subnet_id = module.vpc.vpc_id
...
}
参考
6. for_eachやcountでリソース数を制御しよう
同じ種類のリソースを複数作りたいとき、1つずつ手動で書くのは非効率ですよね。例えば、EC2を5台作りたいときに5回同じコードを書くのは大変ですし、ミスもしやすくなります。
Terraformでは一つのリソースブロックで複数のリソースを作成するための仕組みを用意しています。これがfor_eachやcountです。
具体的な使い方
例えば、count を用いて同じEC2インスタンスを複数作る場合は以下のように書けます。
resource "aws_instance" "example" {
count = 5
ami = "ami-12345678"
instance_type = "t2.micro"
}
for_eachを使うとmap型やset型を引数に入れることで複数のリソースに異なる設定値を渡すことができるようになります。
variable "web_instances" {
type = list(string)
description = "A list of instances for the web application"
default = [
"ui",
"api",
"db",
"metrics"
]
}
resource "aws_instance" "web" {
for_each = toset(var.web_instances)
ami = data.aws_ami.webapp.id
instance_type = "t3.micro"
tags = {
Name = "web_${each.key}"
}
}
また、応用として条件分岐を用いてリソースを作るか作らないかを制御することもできます。
variable "enable_metrics" {
description = "True if the metrics server should be deployed"
type = bool
default = true
}
resource "aws_instance" "web" {
count = var.enable_metrics ? 1 : 0
ami = data.aws_ami.webapp.id
instance_type = "t3.micro"
##...
}
これらの表現を使いこなせば同じリソースを何度も設定し直さずに簡単に制御できるでしょう。
参考
7. importで作成済みリソースを管理下に置こう
「もうすでにAWSで作ったリソースがあるけど、これをTerraformで管理したい!」ってこと、ありませんか?でも、手動でコードを書くのは間違えやすいし面倒ですよね。
Terraform の v1.5.0 以前はコマンドのterraform importを使ってリソースをTerraformの管理下におく方法が主でしたが、import ブロックの登場でコードにこの操作を組み込めるようになりました。
import ブロックは一度terraform applyをしてリソースを import した後はそれ以上何かをすることはありません。削除しても良いですし、import したという記録として残しておいても良いでしょう。
具体的な使い方
import.tf ファイルやリソース定義を行いたい tf ファイル内で以下のように書くことでterraform apply時に import が行われます。
import {
to = aws_instance.example
id = "i-abcd1234"
}
resource "aws_instance" "example" {
name = "hashi"
# (other resource arguments...)
}
idにはリソースの識別子、つまりバケット名やインスタンスIDなどを入れ、
toには import 後の"リソースタイプ.リソースブロック名"を入れることで実行できます。
参考
8. lifecycleでリソースの設定を管理対象から外そう
Terraformで管理しているリソースの一部を「Terraformからいじれないようにしたい」と思ったことはありませんか?例えば、手動で変更される可能性がある設定を間違って上書きしてしまうのを避けたい場合です。
こういった場面ではlifecycleの設定を使います。lifecycleブロックの中でignore_changesを使えば、特定の属性をTerraformの管理対象から外すことができます。
具体的な使い方
lifecycle ブロックの中では create_before_destroy, prevent_destroy, ignore_changes, replace_triggered_by の4つの属性を設定できます。
それぞれ名前の通り、
- create_before_destroy(bool): リソースを作り直すとき先に新しいリソースを作成してから古い方を壊す
- prevent_destroy(bool): リソースが壊されないようにする
- ignore_changes(list): リソースの属性の変更をTerraformで管理しない
- replace_triggered_by(list): 他リソースや属性の変更時にリソースを作り直す
という機能があります。
今回使うのは ignore_changes で、コードとしてパスワードなどを管理したくないときに使えます。
リソースの作成をterraform applyで行ってマネジメントコンソールで新しいパスワードを設定した後、コード側で古いパスワードを設定したままにしていてもTerraform側から新しいパスワードを上書きできなくなります。
resource "aws_db_instance" "example" {
allocated_storage = 10
engine = "mysql"
engine_version = "5.7"
instance_class = "db.t3.micro"
username = "user"
password = "sample_password"
lifecycle {
ignore_changes = [
password
]
}
}
AWSのSecret Managerでパスワードを自動ローテーションさせたい時にもこの設定をしておくと誤って上書きしてしまうことがなくなるので重宝します。
参考
9. consoleで関数の動作確認をしよう
Terraformでコードを書いていてちょっとしたときに関数の挙動や文法が想像通りかを確かめたくなること、ありますよね。文字列のフォーマットやリストの操作などシンプルなものだけでなく、coalesceやtrimなどの組み込み関数の挙動を再確認したいときもあるでしょう。
このような場面ではterraform consoleを用いると簡単にテストを行うことが出来ます。コマンドの実行によりシェルが起動するので、そこで確かめたい表現を入力すれば出力が想像通りか確かめられます。
単純にterraform consoleを使うと今のstateファイルの状態に基づいた結果しか出せませんが、terraform console -planを用いるとterraform planを行った状態のstateファイルに基づいた結果を出力するようになります。
具体的な使い方
ここでは以下の main.tf を作成する場合を考えます。
variable "apps" {
type = map(any)
default = {
"foo" = {
"region" = "us-east-1",
},
"bar" = {
"region" = "eu-west-1",
},
"baz" = {
"region" = "ap-south-1",
},
}
}
resource "random_pet" "example" {
for_each = var.apps
}
console コマンドを実行するとシェルが起動し、以下のような入力を与えて出力を確認することが出来ます。
> var.apps.foo
{
"region" = "us-east-1"
}
> random_pet.example
(known after apply)
参考
Terraformを用いた運用に役立つTips
10. TerraformのコードをGitで管理しよう
Terraformを使っていると、コードの変更履歴を追いたいことがよくあります。「誰がどの変更をしたのか」「元に戻したい場合はどうすればいいのか」など、チームでの運用では特に重要ですよね。
そんなときにはやはりGitの出番です。TerraformのコードをGitリポジトリで管理することで、バージョン管理やレビューの仕組みを簡単に導入できます。
運用としては、Terraformのコードを適切に分割した状態でリポジトリに保存し、チームで使います。さらに、CI/CDでterraform planやterraform applyを自動化すれば、効率が格段に上がります。
具体的な使い方
GitHubを使う場合を例に考えると、Pull RequestをOpenにするとterraform planが自動で走るようなワークフローをGitHub Actionsで設定しておいたり、mainにマージされたらterraform applyが自動で走るようなワークフローがあったりすると効率的に開発を進めることが出来るでしょう。
以下にPRのレビュー前にterraform planを実行するワークフローの簡単な流れを示します。
on:
pull_request:
types:
- opened
- synchronize
env:
AWS_ROLE_ARN: ロールarn
AWS_DEFAULT_REGION: 利用リージョン
permissions:
id-token: write
contents: read
jobs:
runs-on: ubuntu-latest
steps:
- name: Checkout branch
uses: actions/checkout@v3
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v4
with:
aws-region: ${{ env.AWS_DEFAULT_REGION }}
role-to-assume: ${{ env.AWS_ROLE_ARN }}
- name: Setup Terraform
uses: hashicorp/setup-terraform@v3
- name: Terraform fmt
id: fmt
run: terraform fmt -check
continue-on-error: true
- name: Terraform Init
id: init
run: terraform init
- name: Terraform Validate
id: validate
run: terraform validate -no-color
- name: Terraform Plan
id: plan
run: terraform plan -no-color
continue-on-error: true
GitHub Actionsを使えばPRのコメントに出力を表示させたり、terraform applyの結果をSlackに通知したりすることも可能になります。実現したい機能に応じて更に充実したワークフローを作成するのがおすすめです。
参考
11. リソースにタグをつけてコスト管理しよう
AWSでは、リソースのコストを可視化するために「タグ」を活用するのが一般的です。AWS Cost Explorerやコスト配分レポートを用いることでタグの分類ごとのコストを把握することが可能になります。
運用上は忘れないようにリソース作成時のチェック項目として「タグをつける」ことを記載しておけば、どのアプリケーションでコストが嵩んでいるのかを簡単に把握することができます。
具体的な使い方
タグの付け方自体はとてもシンプルです。公式ドキュメントで属性としてtagを受け付けているリソースで以下のように書いておくだけで十分です。
resource "aws_instance" "example" {
ami = data.aws_ami.ubuntu.id
instance_type = "t2.micro"
tags = {
Environment = "Production"
Owner = "Ops"
}
}
コスト管理を効率化するためにいくつかの分類を用いてタグをつけておくと運用時にとても便利に感じられるでしょう。
参考
12. stateファイルはS3に保存しよう
Terraformをチームで使うとき、stateファイル(tfstate)をどう管理するかが重要です。ローカルに保存したままだと他のメンバーが古いファイルを参照してしまうことになりかねません。
いくつかstateファイルを管理する方法はありますが、AWS環境の管理をしている場合はS3にstateファイルを保存するのが自然でしょう。S3をTerraformのbackendとして設定すれば、チーム全員で同じ状態を共有できるようになります。
具体的な使い方
S3をbackendとして使えるようになるための設定は以下のように書けます。
terraform {
backend "s3" {
bucket = "mybucket"
key = "path/to/my/key"
region = "us-east-1"
}
}
これ以外の認証情報を設定に含めることもできますが、terraform init を実行した際にターミナルなどで認証情報を直接入力することもできます。認証情報をハードコーディングしたくない場合には部分的に設定するだけに留めるのが良いでしょう。
また、複数人で同時にstateファイルを編集してしまわないように DynamoDB を用いてロックをかけるようにしておくと良いでしょう。
更に、stateファイルは通常では平文でパスワードなどを保持してしまうので暗号化しておくことが推奨されます。
terraform {
backend "s3" {
bucket = "myorg-terraform-states"
key = "myapp/production/tfstate"
region = "us-east-1"
dynamodb_table = "TableName"
encrypt = true
}
}
resource "aws_dynamodb_table" "terraform_locks" {
name = "terraform-state-locking"
hash_key = "LockID"
attribute {
name = "LockID"
type = "S"
}
}
実験的な仕様として、DynamoDBのテーブルを作成する代わりにS3上でstate lockingを行う機能が実装されたようです。まだ公式にはサポートされていない形ですが、興味のある方は個人プロジェクトなどで使ってみる分には面白いかもしれません。
terraform {
backend "s3" {
bucket = "tf-s3-state-lock-example-tfstate"
key = "terraform.tfstate"
use_lockfile = true
}
}
参考
13. target指定でplanやapplyの範囲を小さくしよう
大規模なTerraformプロジェクトでは、ちょっとしたデプロイ時のエラーに対応したい時などすべてのリソースを変更する必要がない場合もありますよね。でも、terraform planを実行すると全リソースをチェックしてしまうので時間がかかります。
こういうときには、-targetオプションを使いましょう。これを使うと、特定のリソースだけに対象を絞ってplanやapplyができます。
具体的な使い方
使い方は簡単で、以下のように-targetオプションの後ろに指定したいリソースを追加することでplanの範囲を絞れます。
$ terraform plan -target="aws_instance.example"
また、複数リソースを指定したい場合やモジュールを指定したい場合には以下のようにして実行することもできます。
$ terraform plan -target="aws_s3_object.objects[2]" -target="aws_s3_object.objects[3]"
$ terraform plan -target="module.s3_bucket"
日常的にこの-target指定を行うことは思わぬ箇所での変更に対応できなくなるため推奨されませんが、トラブル時に早急な対応を求められたらこの選択肢を持っておくのも大切でしょう。
参考
14. ディレクトリを細分化してplanやapplyを高速化しよう
上で説明した方法以外にもより普段の運用でplanやapplyを高速化したいですよね。やはり大規模なTerraformプロジェクトではこの時間が開発効率を下げる要因になりかねません。
これに対処する方法として最もよく知られているのが、ディレクトリを細分化する方法です。
terraform planやterraform applyでは、stateファイル内の変更を全て確認するための state refresh が毎回行われます。これは当然リソースが増えれば増えるほどTerraform側でAWSのAPIにリクエストを投げる必要があり、時間がかかります。
この工程を短縮するためにはstateファイルを小さく保つことが重要になります。もちろんコードの可読性などの都合を差し置いてディレクトリを細分化することは推奨されません。そのため、管理者にとって丁度良いバランスを保つことが必要になります。
補足
この他にも-parallelismオプションを使って並列数を上げることや-refresh=falseとすることも考えられますが、それぞれAPIのレート制限や更新を予め行う仕組みを導入する必要があるなどといった問題があります。全てのAWSサービスのAPIレート制限に対応することは難しいですし、stateファイルの更新をリアルタイムで行うのも公式でサポートされていないこともあってあまり現実的ではないのが現状です。
参考
15. 秘密情報はコンソール出力やログでは隠そう
Terraformで環境を構築するとき、パスワードやAPIキーなどの秘密情報を扱うことがあります。これらの情報がログやコンソールに出力されるとセキュリティ上の問題につながります。
Terraformでは、変数にsensitive属性を設定することで、秘密情報を隠すことができます。ただし、先にも述べたように一点注意が必要なのはstateファイルではこの情報は平文で記述されてしまうということです。そのため、stateファイルは基本的に暗号化して保存することが必要になります。
具体的な使い方
tfファイル内で以下のように属性を設定します。
variable "db_password" {
description = "Database administrator password"
type = string
sensitive = true
}
実際に変数に与える値は変数定義ファイル内に記述することが出来ます。
db_username = "admin"
db_password = "password"
この変数定義ファイルはGit管理しないことが推奨されていますが、ローカルに保存されたままというのもセキュリティ上の問題になるケースがあります。自動でパスワードをローテーションするSecrets Managerなどを使わない場合は、担当者の変更などの際には注意してパスワードを変更するなどの措置を忘れないようにする必要があります。
変数定義ファイルを参照してapplyを行うと確かにコンソール上では秘密情報が隠されていることが確認できます。
$ terraform apply -var-file="secret.tfvars"
## ...
# aws_db_instance.database will be updated in-place
~ resource "aws_db_instance" "database" {
+ domain = ""
+ domain_iam_role_name = ""
id = "terraform-20210113192204255400000004"
+ kms_key_id = ""
+ monitoring_role_arn = ""
+ name = ""
# Warning: this attribute value will be marked as sensitive and will
# not display in UI output after applying this change
~ password = (sensitive value)
...
}
Plan: 0 to add, 1 to change, 0 to destroy.
このようにして変数定義ファイルを用いる以外にも
$ export TF_VAR_db_username=admin TF_VAR_db_password=password
などのようにして環境変数を直接与えることもできます。この場合は作成した秘密情報を別の場所に保管しておく必要があるので、その点は注意が必要です。
参考
16. プロバイダーのバージョン指定を正しく行おう
Terraformのプロバイダーは頻繁にアップデートされるので、コードがいつの間にか動かなくなることも起こり得ます。こういったトラブルを防ぐためには、プロバイダーのバージョンを明示的に指定しておくことが大切です。
公式ドキュメントではルートモジュール及び各モジュールでバージョン指定を行うことを推奨しています。更にルートモジュールではプロバイダの設定を行う必要があります。これらは全て main.tf 内で行うこともできますが、バージョン指定は versions.tf に、プロバイダの設定は providers.tf で行うようにすると忘れずに済むでしょう。
具体的な使い方
terraform applyなどを行うディレクトリに配置する versions.tf ではルートモジュールのバージョン指定を行うことができます。ルートモジュールのバージョン指定ではTerraformが選びうるバージョンの上限を決めておくことが必要になります。
そこで使えるのが ~> の演算子です。以下の例でAWSプロバイダは 4.X.Y の形を満たすようなバージョンのみに制限されます。より正確には、一番右側にあるバージョンの数値(今回ならば0)が増えるようなバージョンのみに制限されることになります。こうすることで 5.X.Y のバージョンで動かなくなってしまう心配をせずに済みます。
terraform {
required_version = "~> 1.5"
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 4.0"
}
}
}
先に述べた通り、公式ドキュメントでは全てのモジュール内で versions.tf に必要最低限のバージョンを指定することを推奨しています。terraform init を実行するときには全てのモジュールのバージョン制限を満たすようなバージョンを選ぶのでそのときに参照される値が必要になります。
terraform {
required_version = ">= 1.5.0"
required_providers {
aws = {
source = "hashicorp/aws"
version = ">= 1.5.0"
}
}
}
この設定を行わない場合、ルートモジュールのバージョン制限のみが適応されるため、きちんとどのバージョンからサポートされているかを確認して記載するのが安全でしょう。
最後にプロバイダの設定については以下のように設定をします。
provider "aws" {
region = "us-east-1"
}
ここで指定するプロバイダの名前は上の required_providers ブロックに追加した名前と同じものを用います。
もし複数の設定で同じプロバイダを利用したい場合は以下のように alias 属性を追加することで設定できます。
provider "aws" {
region = "us-east-1"
}
provider "aws" {
alias = "west"
region = "us-west-2"
}
通常のリソース作成時にはデフォルトのプロバイダ( alias 属性がないもの)を利用しますが、ここで設定した別のプロバイダを使いたい場合は以下のようにしてプロバイダを指定することができます。
resource "aws_instance" "foo" {
provider = aws.west
# ...
}
複数の設定を行いたい理由としては、シンプルに遠い地域からのアクセスがある場合などが考えられます。この設定を活かして様々なリージョンにサービスを展開することで遠くのユーザにも不便なくアクセスしてもらうことができます。
参考
終わりに
ここで紹介した内容はほとんどが公式のドキュメントにも書いてある内容が多かったので、熟練したTerraform使いの方にとっては当然のように感じることも多かったかもしれません。しかし、隅々まで読んでみると新しい発見があるものです。参考にしたサイトのリンクをまとめて紹介するので、気になるトピックがまだある方はこちらから調べてみてください!
弊社Nucoでは、他にも様々なお役立ち記事を公開しています。よろしければOrganizationのページも覗いてみてください。
また、Nucoでは一緒に働く仲間も募集しています!興味をお持ちいただいた方は、ぜひこちらまでご連絡ください。