はじめに
Salesforceフローにおける 「バルク化(Bulkification)」 について、聞いたことがある人はいるでしょうか。この振る舞いは、通常Salesforceフローを使ってフローを作成しているときにはあまり意識することはないのですが、Salesforceフローという仕組みを理解する上でとても重要かつ非常に特徴的なものになります。
特に、Apexコードを書くことのあるデベロッパーは、これについてちゃんと理解してないと、Salesforceフローというものを単なるあまり使い勝手の良くないヴィジュアルプログラミング環境だと捉えてしまうかもしれません。
本記事では今まで日本語文献であまり取り上げられることのなかったこの「バルク化」について、おそらく知っている人は知っているけども、知らない人は目から鱗になるかもしれない、そんな期待をもって記したいと思います。
本記事の目標
- Salesforceフローにおける「バルク化」について意味を理解し、裏側の動きをイメージする。
- ノーコードプログラミングとしてのSalesforceフローの良い点を正しく見極める。
想定されるオーディエンス
本記事の対象読者
- Apexコードでトリガー処理を書いたことのあるプログラマー
- Salesforceフローを組むよりよりもApexコードのほうが手慣れているプログラマー
本記事の対象読者ではない人
- Salesforceフローを勉強して業務に活用したいアドミン
Apexトリガーの歴史
最初に、みなさんはApexトリガーでこんなコードを見たことがありますか?
trigger AccTrigger on Account (after insert) {
Account acc = Trigger.new
acc.Name = acc.Name + " !!!"
update acc;
}
『ダウト!これはApexトリガーじゃない。こんなコードはSalesforceでは動かないよ』
日々Apexコードに親しんでいるような開発者であれば、すぐにそう気づくかもしれません。
しかし、残念ながら、実はこれも立派なApexトリガーです。ただしもう利用することはできません。
実はこれは2006年当時、ApexコードがSalesforceのプラットフォームに最初に出てきたときのトリガーのコードです。
この書き方はすぐに廃止され、以下のような記述方法になりました。
trigger AccTrigger on Account (after insert) {
Account accs[] = new Account[];
for (Account acc: Trigger.new) {
acc.Name = acc.Name + " !!!"
accs.add(acc);
}
update accs;
}
上記のように、トリガのコードに対して複数のレコードが渡されるトリガ形式を 「バルクトリガー」 といいます。
この書き方を当たり前だと思っているApexコード中心主義者の皆さん、Apexトリガーのネタ元である主要DBMSのトリガーの実装では、バルクでレコードを取り扱うことはありません。なので黎明期のApexコードもそのとおりでした。しかしながらそれでは都合が悪いということで、早々に廃止され、もはや生き残っていません(ちなみに自分の妄言でないことを示すためにソースを探したのですが、15年以上前では流石に無理でした…。どこかのSalesforce老人もとい仙人で証拠をお持ちの人がいたらメンションいただけると嬉しいです)
では、なぜこのような形式にしたのでしょうか?
1つのトリガには複数のレコードが同時に作用することが多くあります。例としてデータローダで一括登録した場合や、リストビューの編集機能を利用したり、いくつかのレコードをまとめて変更して保存、というシーンを思い浮かべてもらえばよいでしょう。その際に、トリガーが1つ1つのレコードに対して起動すると、最後のupdate accというDML文での処理が1つ1つのレコードごとに発生する、ということになります。
ここで、ApexにおいてはDML文にはガバナ制限が設けられており、1レコード単位でDMLを発行しているとすぐに制限に達してしまいます(というか、ApexにおいてDML文が負荷が高い処理であるからガバナ制限が設けられているはずなので、因果の説明としては本来は逆になります)。これを回避するため、バルクトリガの形式にすることで、Apexコードを記述する側でレコードの更新処理をバルク化してもらい、制限にひっかからないようにする、という対応ができるようになりました。
みなさんがApexコード初心者の頃に習った「ループ内でSOQL/DMLを記述しない」という規約というかイディオムは、そのような経緯で生まれたものです。
Salesforceフローのレコードトリガーフロー
さて、頭がApex考古学の沼に浸かってしまう前に、現代に目を向け直しましょう(⇐Trailheadでよく見られる文章)。
Salesforceフローでも、Apexトリガと同じように、レコードの登録/更新などをきっかけとして動作するロジックを記述できます。これはレコードトリガーフローと呼ばれます。
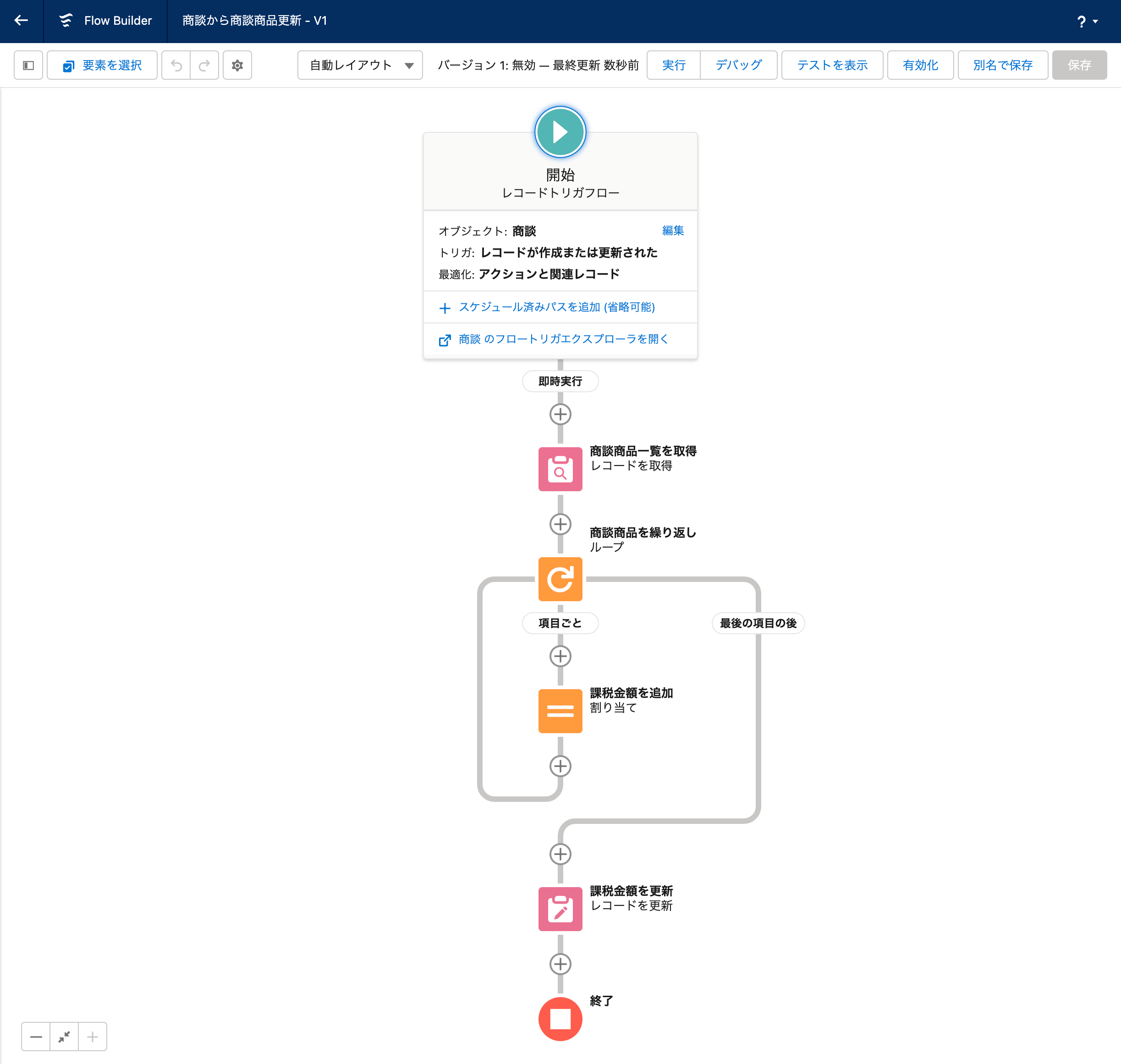
レコードトリガーフローのフロー内では、フローに渡ってくるレコードの情報は、あくまで1つだけで、$Recordという変数に渡ってくることになっています。そしてそのレコードに対して処理を行い、必要に応じて結果をデータベースに保存します。
さて、ここでこう疑問に思った人はいないでしょうか。レコードトリガーフローで同時に複数レコードが一括登録/更新されたら一体どうなるの、と。
Apexトリガでは、トリガごとに1つのレコードの処理を行っていると、DML発行による高負荷から抜け出せないため、バルクトリガという形式が持ち込まれたという歴史は、先に述べたとおりです。ではなぜレコードトリガーフローではこのようになっていないのでしょうか? 単一レコードでなくレコードコレクションを渡してくれるべきではないでしょうか? さもなければSalesforceフローではついにガバナ地獄に陥るしかないのでしょうか?
Salesforceフローにおけるバルク化の効用
ここで、冒頭に上げた 「バルク化 (Bulkification)」 が出てきます。実は、Salesforceフローにおけるデータベースへのレコード取得・更新処理は、単なるSOQL/DMLの内部表現ではありません。実際に実行される中身はフローの画面で設定されている内容とは少し異なります。
例を元に説明していきます。

上の図は、商談の更新時に起動するレコードトリガーフロー(商談商品の一覧から課税金額を計算し、商談のカスタム項目を更新する)が、どのようにバルク化されて実行されているかを表したものです。
まず、レコードトリガーフローが設定されているオブジェクト(商談)に対して同時に複数のレコードが更新されたとき、その対象となるレコードの数の分だけ、フローに記述されている処理が起動します。
この1つ1つの処理をSalesforceフローでは「インタビュー」という言い方をしますが、プロセスやスレッドが立ち上がるイメージのほうがプログラマ的には受け入れられやすいかもしれません。つまり 並行して処理が動く というところがポイントです。以降、インタビューという耳慣れない言葉ではなく、スレッドとしてあえて説明していきます(気になる方はスレッド⇒インタビューと読み替えてください)。
次に、それぞれのスレッドでフローに記述された処理を実行していくわけですが、バルク化対象の要素があった場合には、それぞれのスレッドが同じ位置に来るまで一旦待ちます。そしてすべてのスレッドが揃ったタイミングで、初めてそのバルク化対応した処理を実行します。
例に上げているフローでは、まず最初に商談商品を取得するレコードの取得要素がそのバルク化対象の要素になっています。このレコード取得要素は、商談レコードのIDを利用して商談商品を検索し、複数レコードを検索しています。
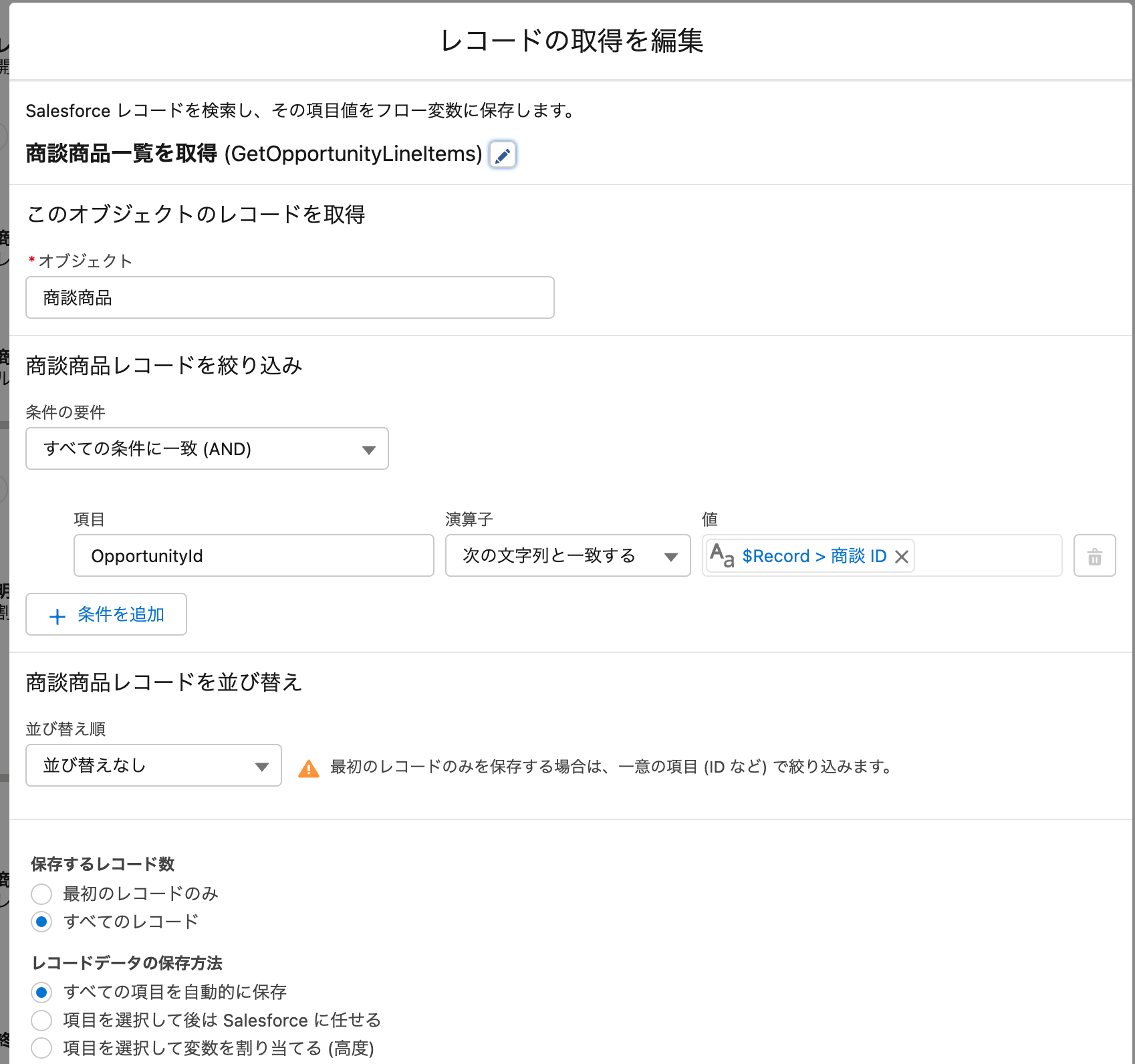
ここで、レコード取得要素は、バルク化において、すべてのスレッドから渡ってきた商談IDをまとめて、1つのIN句相当の条件をもつ(あるいはOR句で条件をつなげた)SOQLとして実行し、レコードを一括で取得するように実行します。具体的には以下のようなSOQLが発行されているのと同等になります。
/* opp1, opp2, opp3 ...はそれぞれのスレッドにおける対象の商談レコード */
SELECT FIELDS(ALL)
FROM OpportunityLineItem
WHERE OpportunityId IN (opp1.Id, opp2.Id, opp3.Id, …)
こうして一括取得されたレコードは、それぞれのスレッドにマッチするものが分配され、以降の処理のために出力として各スレッドで利用される形になります。
その後、次のバルク化処理に到達するまで、それぞれのスレッドで処理が走ります。このフローでは商談商品レコードに応じてループ処理をしているので、商談商品レコードが少ない商談については早目にループを抜けてしまうかもしれませんが、ここではループを抜けた後に商談レコードの更新処理が控えています。そのため、ループを抜けたスレッドもバルク化処理のためにすべてのスレッドが揃うまで待つことになります。
最後に、商談レコード更新の要素がバルク化対応した処理として実行されます。フローの要素の設定では、トリガ元となった商談レコード1件を更新の対象とし、商談商品をループして得られた計算結果の値を利用してそのレコードの項目値を更新しています。
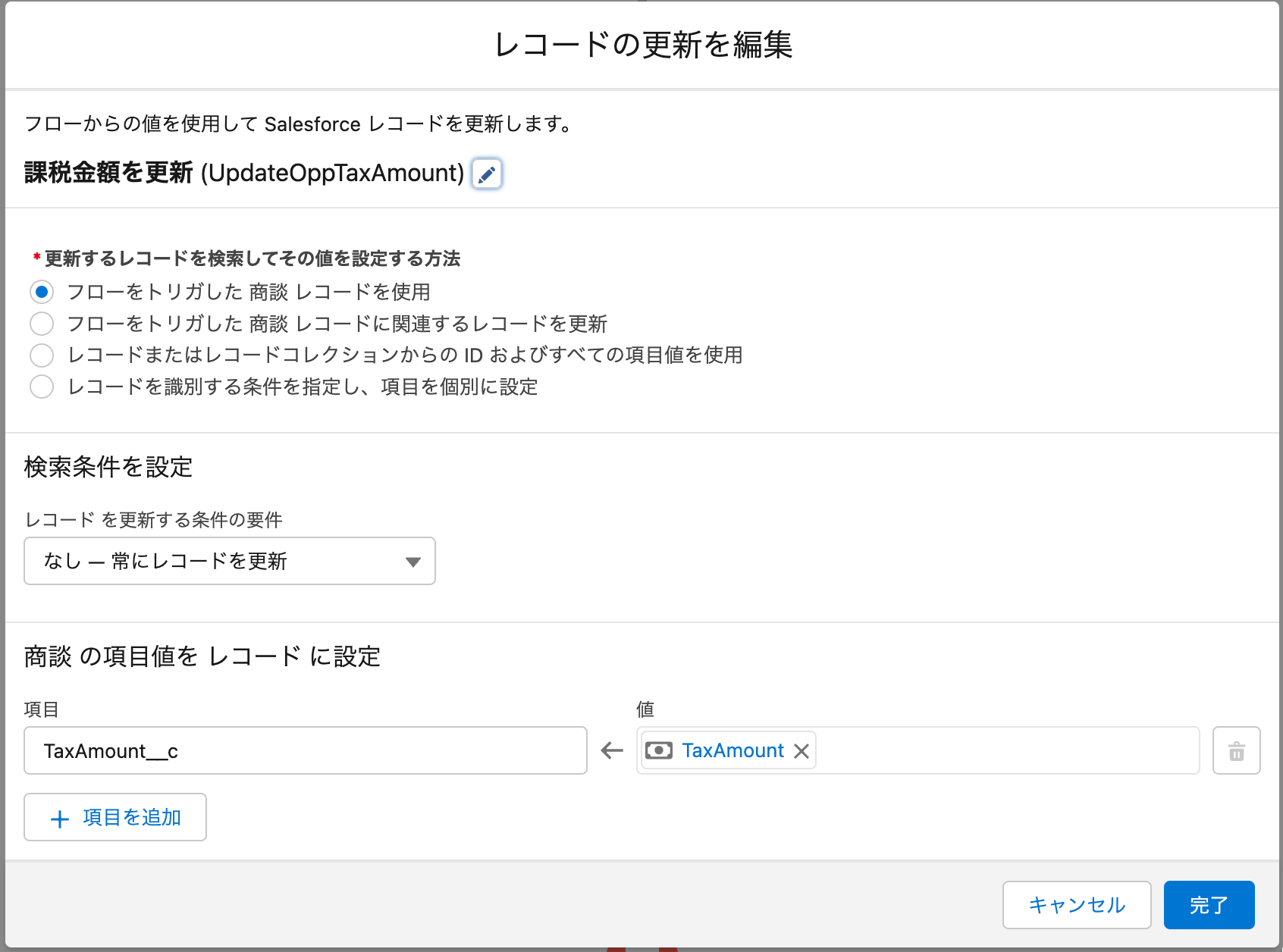
実際には、すべてのスレッドの商談レコードを更新するDML実行が1回のみ、バルク化によって行われます。ほぼ以下のApexコードの内容と同等の処理となります。
// opp1, opp2, opp3 ...はそれぞれのスレッドにおける対象の商談レコード
// TaxAmount1, 2, 3 ...はそれぞれのスレッドにおける計算結果の値
opp1.TaxAmount__c = TaxAmount1;
opp2.TaxAmount__c = TaxAmount2;
opp3.TaxAmount__c = TaxAmount3;
…
UPDATE new Opportunity[] {
opp1, opp2, opp3, …
};
こうしてバルク化の結果、複数のレコードが一括更新された場合でも、リソースをできるかぎり消費しないような実行パスでフローに記述された処理が行われます。
複数レコード処理の際のフローのインタビューがプロセスやスレッドで分離されて実施されていると主張するものではないです。あくまで、スレッドのように並行に行われていると擬似的に見ることができる、という話です。
Apexアクションとバルク化
Apexの上級者であれば、InvocableMethodのアノテーションが付与されたApexコードを実装したことがある人も多いでしょう。これはSalesforceフローからApexアクションとしてApexの処理を呼び出すための仕組みなのですが、Invocable Methodを実装したメソッドのパラメータや戻り値がリストで囲われた形式になっているのに、なぜだろうと思った人はいませんか?
public class AccountQueryAction {
@InvocableMethod(label='Get Account Names' description='Returns the list of account names corresponding to the specified account IDs.' category='Account')
public static List<String> getAccountNames(List<ID> ids) {
List<String> accountNames = new List<String>();
Map<ID, Account> accounts = new Map<ID, Account>(
[SELECT Id, Name FROM Account WHERE Id in :ids]
);
for (ID id : ids) {
accountNames.add(accounts.get(id)?.Name);
}
return accountNames;
}
}
上のコードは以下のようなApexアクションとしてSalesforceフロー側で利用されます。先のメソッドはID型のリストを受け取り文字列型のリストを返しているにも関わらず、ここでは入力も出力もコレクションではありません。
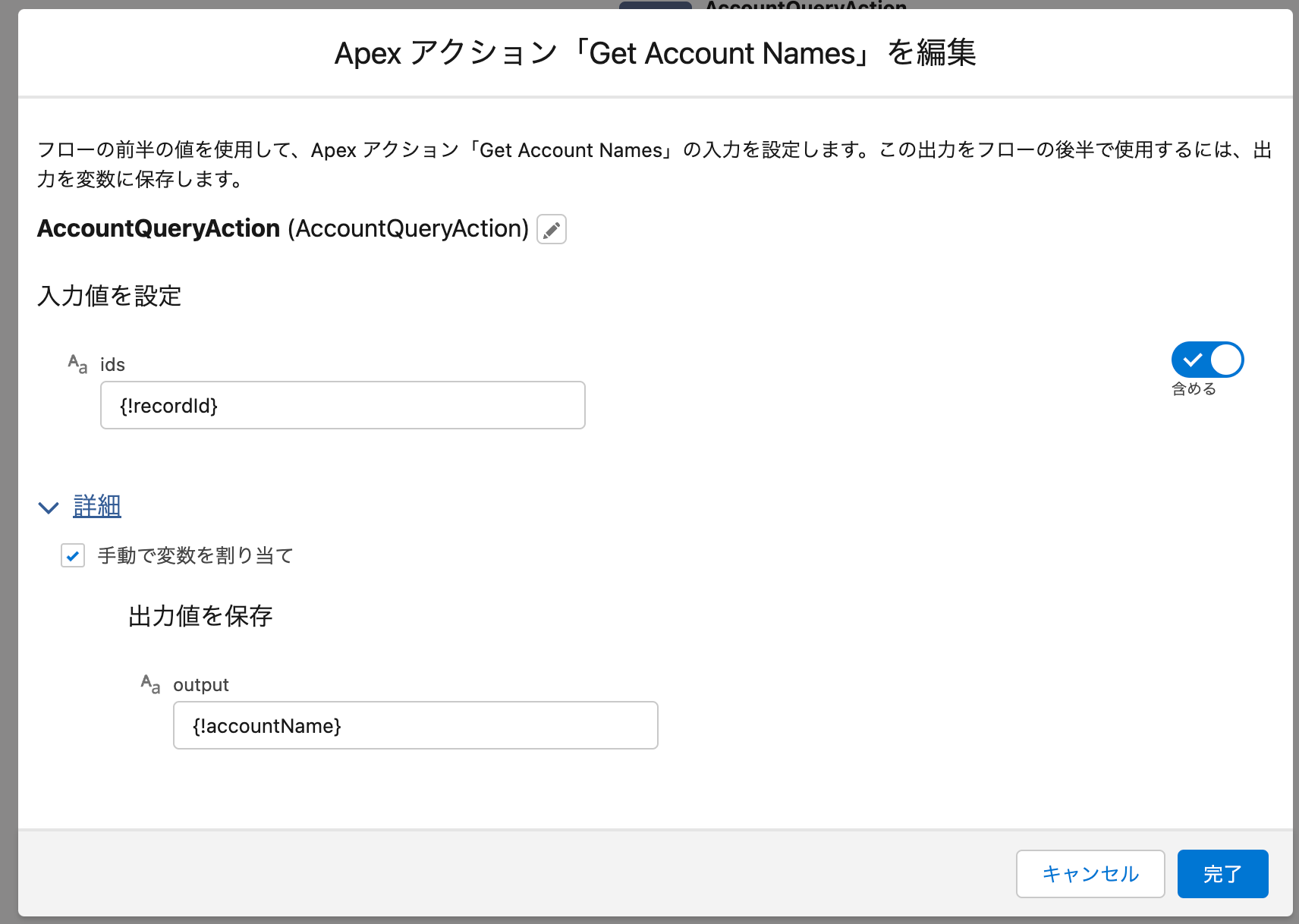
もちろん今までのバルク化の話を知っていればわかることですが、これはそのApexアクションが、バルク化対応するために必要なインターフェースだったのです。つまり、複数インタビューが同時に実行されていても、バルク化されているApexアクションの呼び出しは1回だけで済むようにしています。
おかげでApex側ではリストのラップを解いたりまた包んだりと面倒な手間が入っていますが、一旦その実装を行ってしまえばスケールするモジュールとして利用できることになります。
まとめ:「イディオム」を疑う
Salesforceフローでは、フロー定義で記述されている内容をそのままに実行するのではなく、実際には同時並行の処理をまとめて実行することができるようになっていました。これは処理記述がそのまま実行に密接につながっているApexでは難しいものです。
つまり、Apexでは当たり前のようにやっている、ループ展開とリスト詰め込みのイディオムは、あくまでそれは言語およびランタイムの制約であるということです。イディオムとして普段やっていた内容は本質的なものではなく、本当ならSalesforceフローでできるように局所的なレコードのみに着目し一直線でコードが書けたほうが見通しがよいのは一目瞭然でしょう。
いわゆるノーコードプログラミングは、単にわかりやすさとか初心者から見たとっつきの良さというだけでなく、宣言的な記述による処理をランタイムが最適化してチューンナップできるという点も大きな特質かと思います。Salesforceフローは初学者にはとっつきにくい点も多く、その点は大きな課題ですが、こと「バルク化」という点に関しては、プロセスがプラットフォームに統合されている利点を活かし、Apexでのコード記述の倦怠感を晴らすことに成功しているように見受けられます。
参考資料
公式ヘルプドキュメント
Salesforceフローのバルク化について、ヘルプに記載されているドキュメントです。ちょっとわかりにくいですが、よく読めば今まで書いていたことを詳しく説明しています。
https://help.salesforce.com/s/articleView?id=sf.flow_concepts_bulkification.htm&type=5
こちらの日本語ヘルプでは"Bulkification"を「一括処理」と訳していますが、一般的な一括処理と混同するので、あくまで「Bulkification」というSalesforceフローにおける特殊な仕組みであることを念頭に読んでいくのがコツです。
YouTube動画: Demystifying Flow Bulkification
2020年のVirtualDreaminのセッションの公開動画です(英語)。本記事では触れることができなかった、フローのバルク化について間違えやすいポイント(フローのインタビューが複数実行される場合にバルク化されるのであって1つのインタビュー内での処理が自動的にバルク化されるわけではないという点)を説明しています。実際に実行時のデバッグログを見てバルク化されていることを確認しているところも注目ポイントです。